
Nous sommes très heureux de vous proposer un ensemble de nouvelles améliorations pour rendre l’analyse de vos crawls et l’interprétation des résultats aussi plaisant qu’une journée d’été. Si vous avez été fidèle à votre poste au cours des dernières semaines, vous avez certainement déjà remarqué quelques-uns de ces changements. Si vous n’étiez pas au bureau, nous espérons que vous avez profité de vos vacances ! Voici ce à quoi vous pouvez vous attendre à votre retour.
Nous allons vous présenter les mises à jour produits suivantes :
- Raccourcis des réponses à vos questions pour chaque URL
- Nouvelles fonctionnalités de segmentation automatique
- Nouveau mode de crawl : URL list
- Améliorations bonus
Raccourcis des réponses à vos questions pour chaque URL
Nous avons ajouté un menu de raccourcis de navigation URL dans le Data Explorer et presque partout ailleurs où vous pouvez voir un tableau d’URLs.
À côté de chaque URL dans le tableau de résultats, vous trouverez maintenant une flèche qui ouvre un menu de raccourcis.
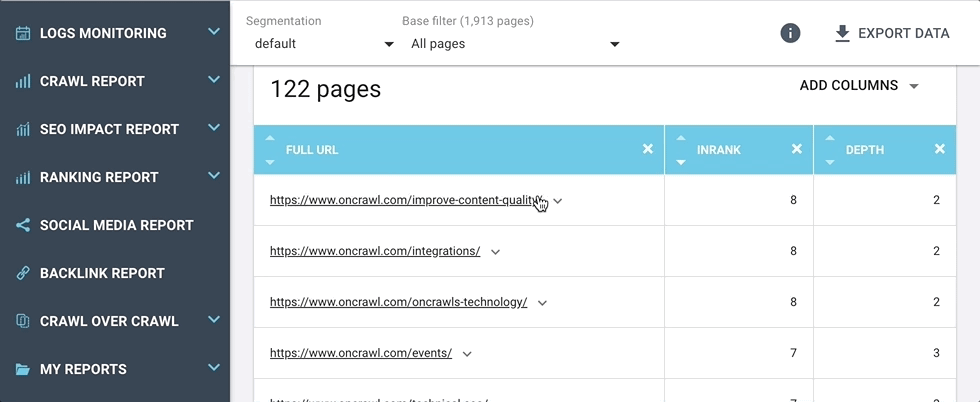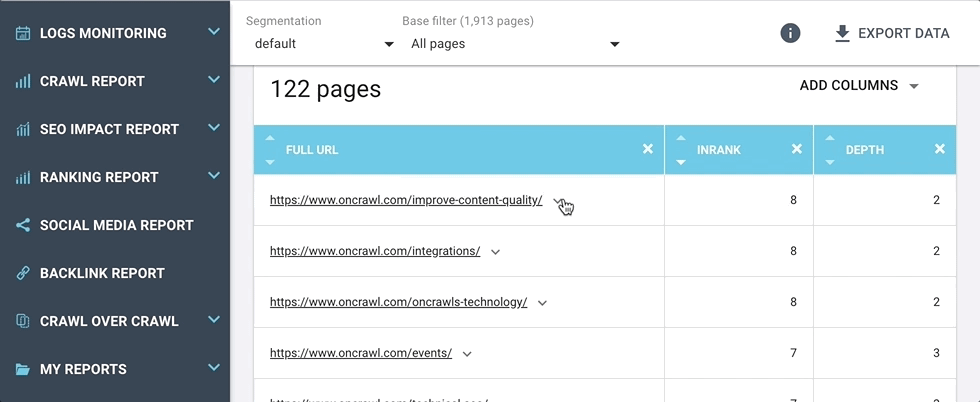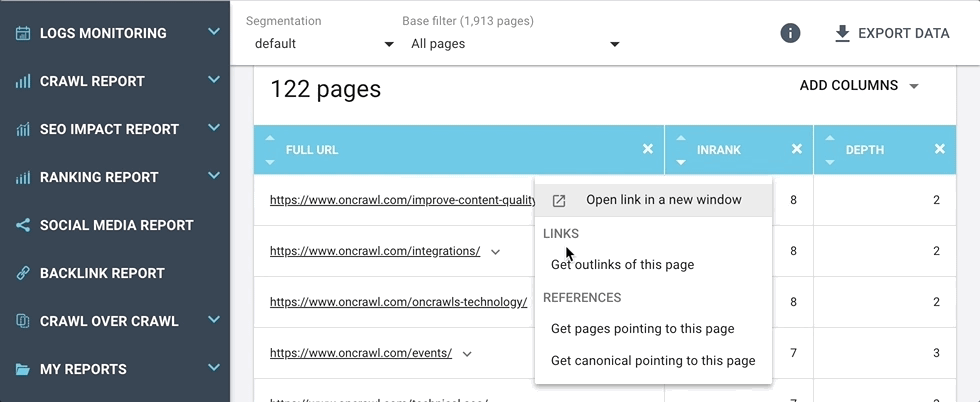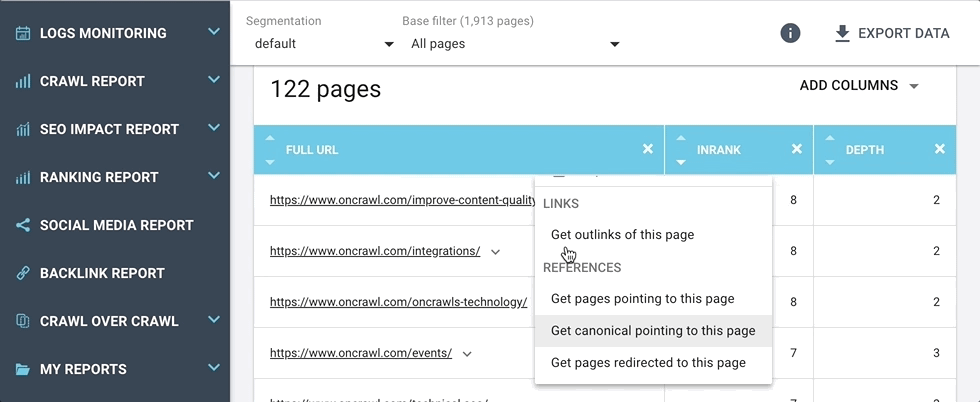
Ces raccourcis vous emmènent directement aux réponses des questions que vous pourriez vous poser à propos de l’URL, par exemple :
- D’où vient cette URL à l’apparence douteuse ?
- Je vois que cette page à des problèmes de duplication pour la description, mais quelles pages ont la même description ?
- Je sais que cette page fait partie d’un groupe pour hreflangs ou de contenu dupliqué, mais quelles sont les autres pages dans le groupe ?
- Si cette page dispose d’une canonique équivalente, c’est super. Mais quelles sont les pages qui répertorient cette URL comme leur page canonique ?
- Je sais qu’un groupe de pages redirige vers cette URL, mais lesquelles sont-elles ?
Ce menu est dynamique, et, selon le contexte, vous pouvez y trouver des raccourcis aux informations suivantes :
- Listes des pages liées (incluant les liens internes, externes, redirections, canoniques, hreflangs) ;
- Listes des pages avec du contenu dupliqué partagé ;
- Listes des événements pour cette page ;
- Listes des passages de bots pour cette page.
Nouvelles fonctionnalités de segmentation automatique
Nous avons étendu les capacités de création des segmentations.
Par défaut, nous vous offrons toujours une segmentation basée sur le premier répertoire (« URL first path ») des URLs crawlées.
Lorsque vous créez une segmentation personnalisée, nous vous offrons désormais une analyse automatique d’un crawl précédent, nous vous proposons une segmentation basée sur des champs personnalisés, ou encore sur l’hôte de l’URL.
Toutes les segmentations sont disponibles pour les logs et les crawls. Cependant, si vous essayez d’utiliser des critères de segmentation qui ne peuvent pas être appliqués aux logs ou aux résultats de crawl, nous vous avertirons immédiatement que votre segmentation ne pourra pas être utilisée pour tous les types de rapports. Si vous avez reçu un avertissement qui indique que votre segmentation ne peut pas être utilisée sur les rapports de résultats de crawl, par exemple, le rapport ne sera pas disponible en tant que choix lorsque vous consulterez les résultats de crawl.
Comment segmenter les résultats de crawl basés sur des champs personnalisés
Pour utiliser un champ personnalisé, vous devez disposer au préalable d’un crawl avec des champs personnalisés. Oncrawl utilisera Nous allons utiliser ces champs pour créer automatiquement une segmentation pour vous. Consultez notre documentation si vous avez besoin d’un coup de pouce lors de la création de champs personnalisés pour un crawl.
Depuis la page d’accueil du projet, cliquez sur “Manage segmentation”, puis sur “+ Create segmentation”.
Vous verrez apparaître la nouvelle option “From field automatically” ainsi que les options déjà existantes : “From existing or import” et “From scratch”. Choisissez “From field automatically” puis cliquez sur « Continue ».
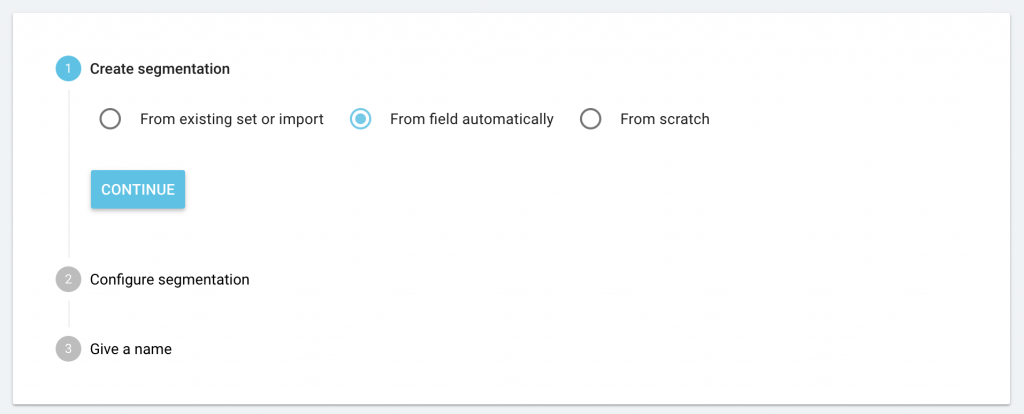
Depuis le menu déroulant, sélectionnez le crawl existant avec les champs personnalisés que vous souhaiteriez utiliser.
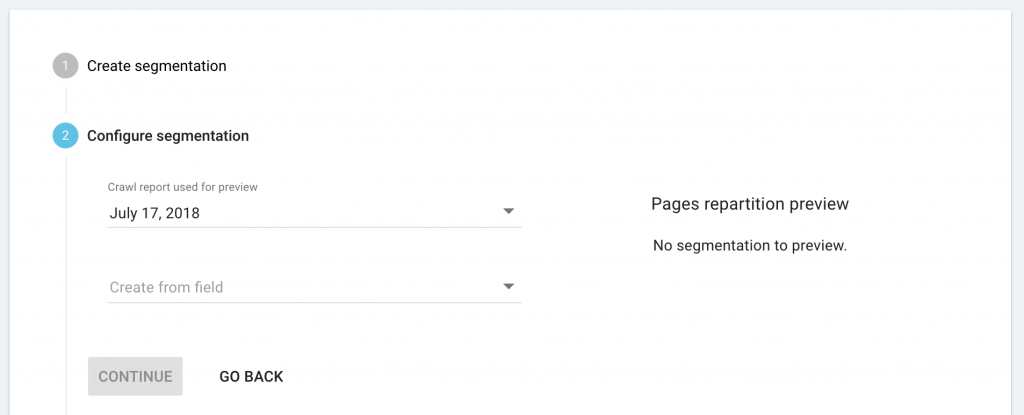
Depuis le menu déroulant, sélectionnez les champ personnalisés que vous souhaiteriez utiliser pour créer une segmentation automatique.
Cliquez sur “Continue” afin de renseigner un nom pour la nouvelle segmentation puis enregistrez-la
Votre nouvelle segmentation ne sera certainement pas utilisable pour le monitoring de log, à moins que le champ personnalisé que vous avez choisi soit basé sur l’URL de la page, ou sur d’autres données disponibles dans vos logs.
Comment segmenter vos résultats de crawl basés sur l’hôte de l’URL (lorsque vous crawlez des sous-domaines ou des domaines multiples)
Pour utiliser l’hôte de l’URL afin de générer une segmentation automatique, vous devez avoir déjà conduit un crawl avec des sous-domaines ou un crawl avec des domaines multiples.
Depuis la page d’accueil du projet, cliquez sur “Manage segmentation”, puis sur “+ Create segmentation”.
Vous verrez la nouvelle option “From field automatically” ainsi que les options déjà existantes : “From existing or import” et “From scratch”. Choisissez “From field automatically” puis cliquez sur « Continue ».
Depuis le menu déroulant, sélectionnez les crawls existants avec les domaines multiples ou les sous-domaines que vous souhaitez utiliser.
Depuis le menu déroulant, sélectionnez le champ “URL host”.
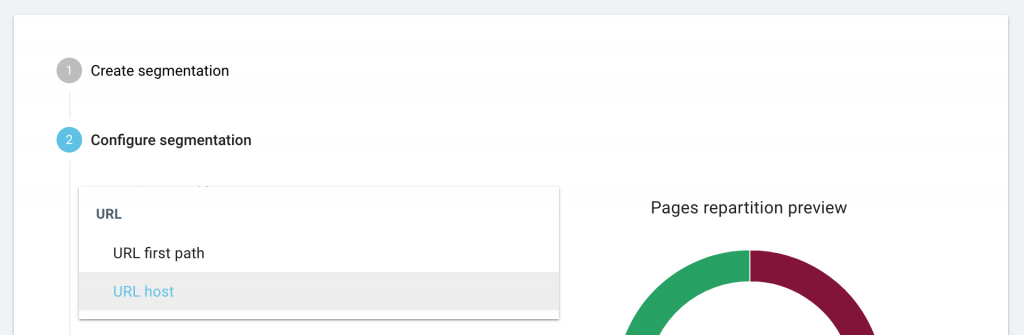
Cliquez sur “Continue” pour renseigner un nom pour la nouvelle segmentation et sauvegardez là.
Cette segmentation est basée sur l’URL et peut ainsi s’appliquer à tous vos rapports.
Nouveau mode de crawl : URL list
Vous nous l’avez demandé, nous l’avons fait. Vous pouvez désormais crawler une liste d’URLs.
Comment crawler une liste d’URLs ?
Lorsque vous configurez un crawl, vous pouvez maintenant décider si vous préférez crawler le site avec un crawler standard qui explore la structure en suivant les liens de chaque page qu’il visite, ou bien crawler une liste statique d’URLs.
Lorsque vous crawlez une liste d’URLs, le crawler va visiter chaque page de la liste que vous fournissez, mais ne va suivre aucun des liens. Cette fonctionnalité limite le crawl aux URLs dans la liste.
Dans les paramètres de crawl, sélectionnez “URL mode” puis téléchargez une liste d’URLs. Vous pouvez également sélectionner une liste d’URLs que vous avez précédemment téléchargée. Lorsque vous lancez un crawl, seules les URLs dans la liste seront crawlées.
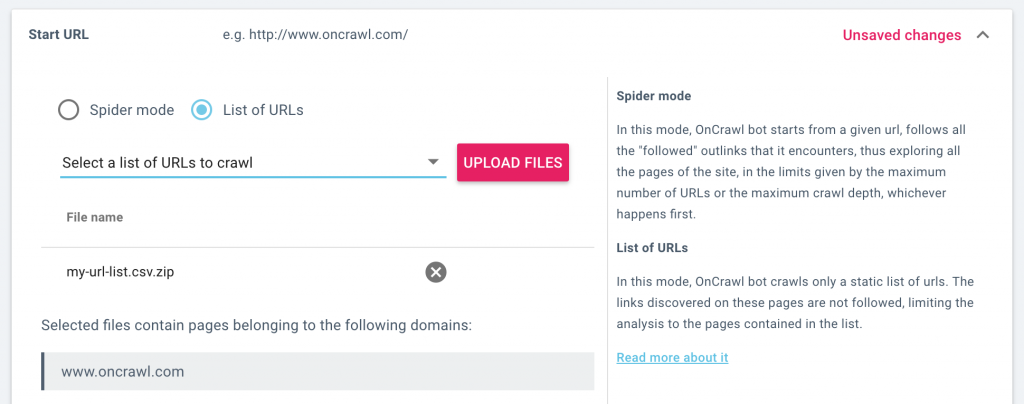
Vous pouvez consulter, gérer et télécharger vos listes d’URL dans la page Data sources. Depuis la page d’accueil du projet, cliquez sur “Add data sources” puis sur “URL lists”.
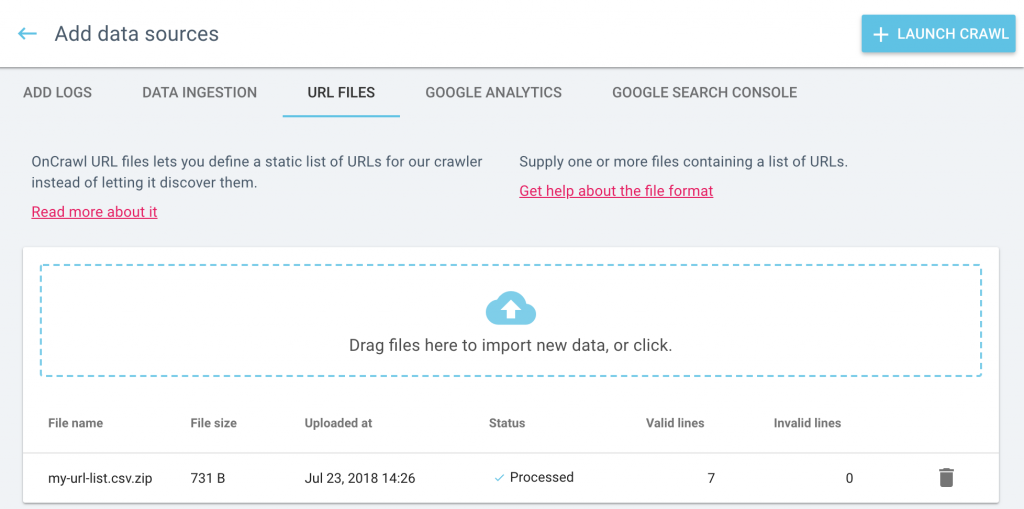
Consultez notre documentation pour plus de détails sur les différences entre le crawl en mode spider et en mode URL list.
Améliorations bonus
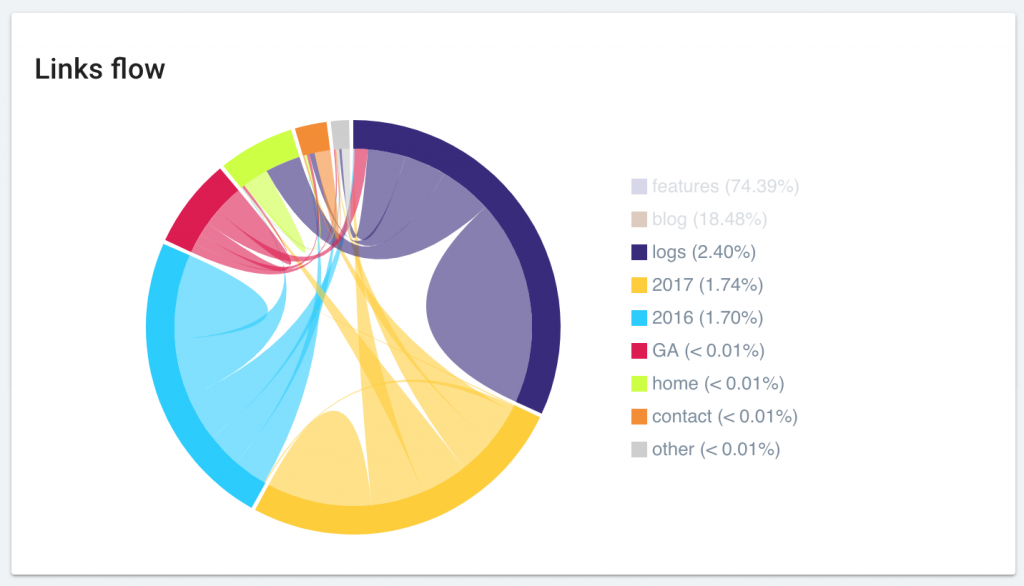
Optimisation du diagramme Link Flow
Nous avons amélioré l’affichage du diagramme “Link Flow”. Votre graphique favoris est maintenant plus beau que jamais et plus simple à interpréter.
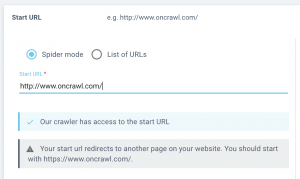
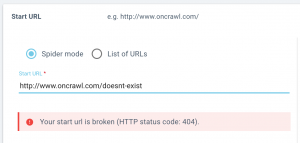
Plus d’accompagnement lors du paramétrage de la start URL
Nous vous ferons savoir si les pages start que vous avez listées peuvent être atteintes par notre crawler, ou s’il est redirigé.
Lorsque vous configurez un crawl, vous saurez immédiatement si le crawl sera en mesure de passer votre start URL. Si nous rencontrons un problème, nous vous ferons savoir si :
- Votre start URL ne peut pas être atteinte (renvoie une erreur 4xx ou 5xx)
- Votre start URL est redirigée (renvoie un status code 3xx)
- Votre start URL ne peut pas être crawlée (les robots sont interdits par les robots.txt)
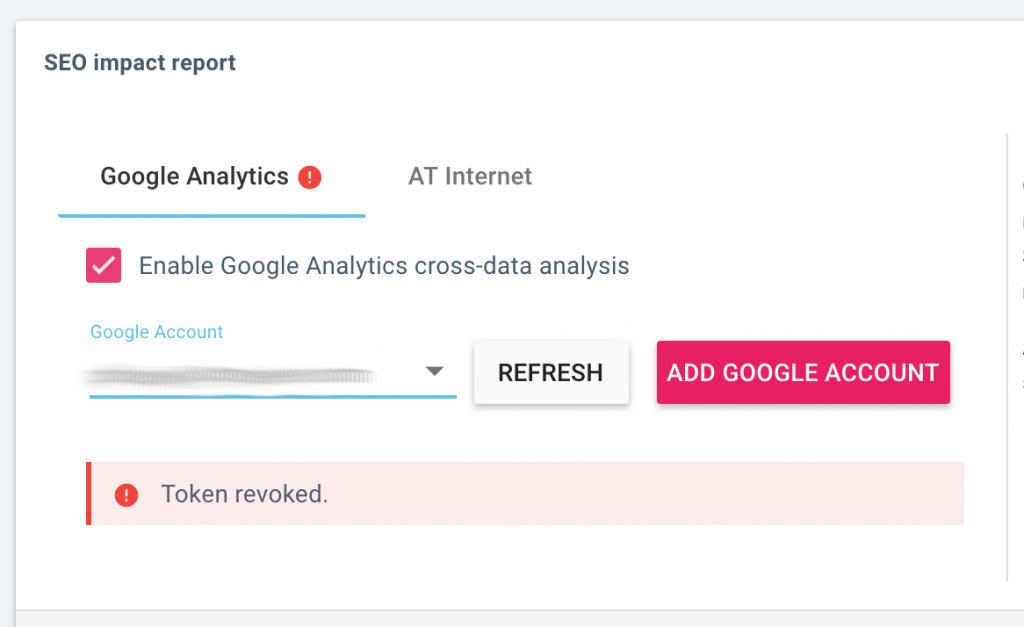
Plus d’accompagnement lors de la connexion d’un service tiers
Lorsque vous configurez un nouveau crawl, nous vous faisons maintenant immédiatement savoir si la connexion à un service tiers a été réussie, ou si nous avons rencontré un problème.
Cela s’applique aux paramètres de crawl dans les sections suivantes :
- Rapport d’impact SEO : connexion à Google Analytics ou AT Internet
- Rapport de classement : connexion à la Google Search Console
- Rapport de backlink : connexion à Majestic
Retrouvez toutes vos données externes et intégrations au même endroit
Nous avons renommé le bouton “Add integrations” en “Add data sources”.
Lorsque vous cliquez sur le bouton “Add data sources”, vous pouvez naviguer à travers les différentes sources en cliquant sur les onglets en haut de l’écran.
Vos données externes et tierces peuvent être ajoutées ici :
- Fichiers de log utilisés pour le monitoring de log, rapports de visites SEO et analyse du budget de crawl ;
- Fichiers du Data ingestion, utilisés pour ajouter des champs personnalisés à l’analyse de chaque URL ;
- Fichiers d’URL, utilisés pour crawler une liste d’URLs ;
- Comptes Google Analytics, utilisés pour les rapports de visites SEO et le comportement du googlebot ;
- Google Search Console, utilisée pour les rapports de classement et les information de mots-clés.
Il s’agit d’un emplacement “tout-en-un” où tout est facile à trouver.
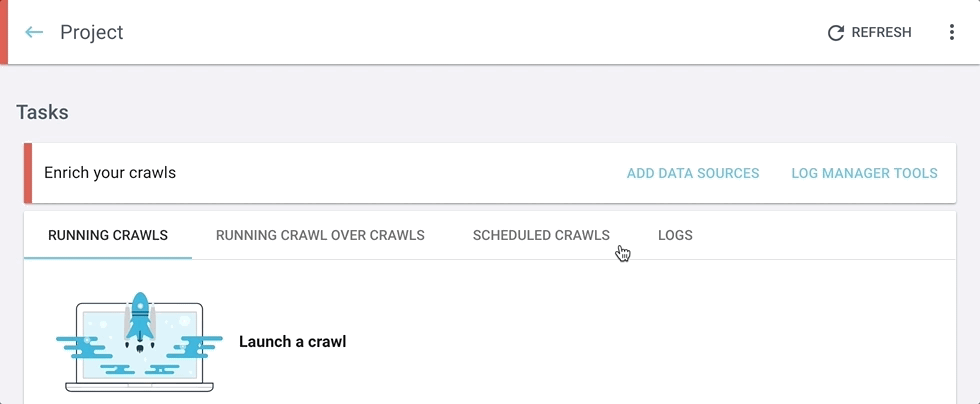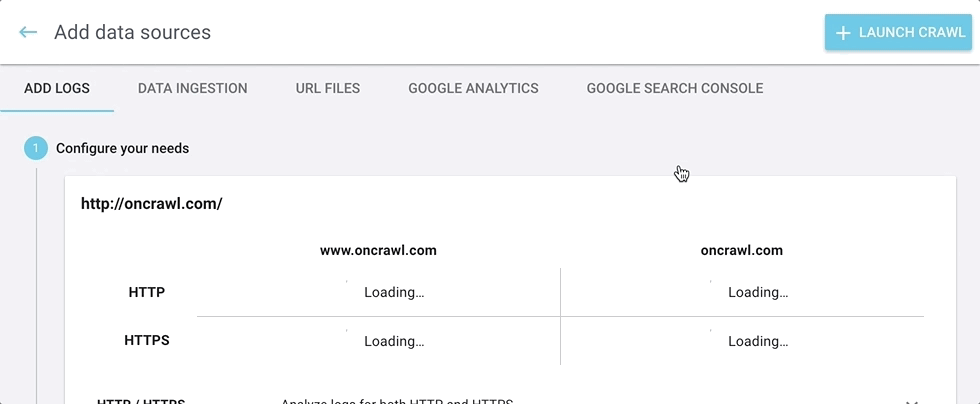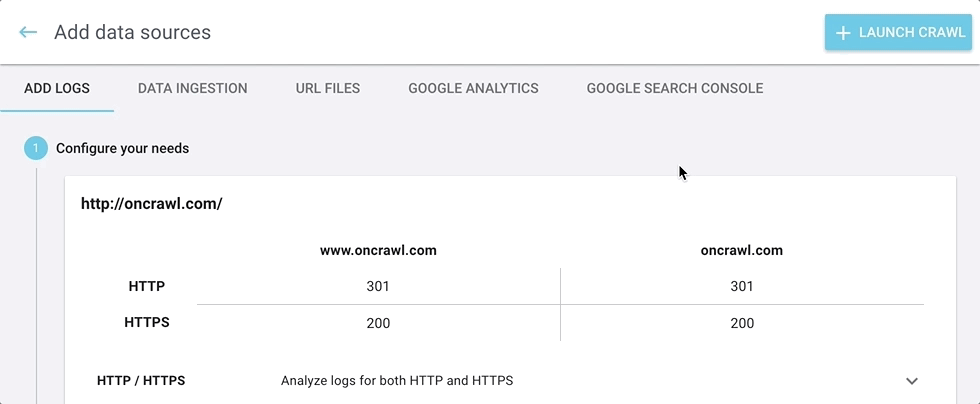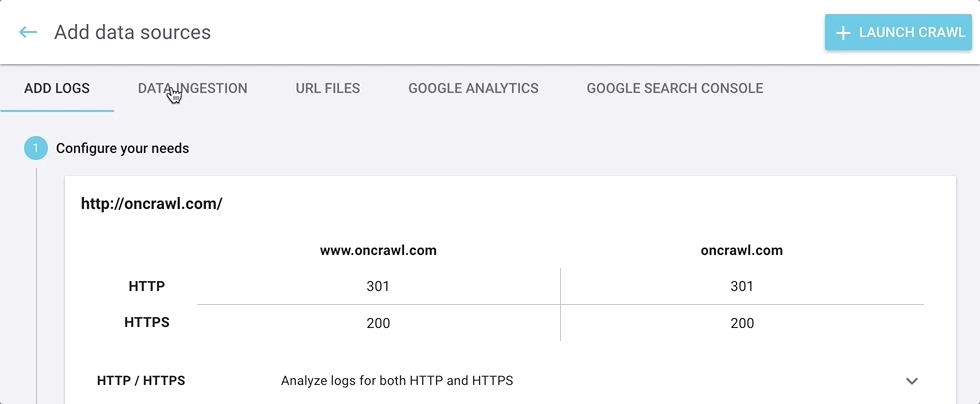
Vous pouvez toujours trouver l’outil de gestion de log à son emplacement habituel, à droite de l’onglet “Enrich your crawls” sous “Tasks” sur la page d’accueil de votre projet.
