
Les bots, également connus sous le nom de Crawlers ou Spiders, sont des programmes qui « voyagent » automatiquement de site en site en utilisant les liens comme route. Bien qu’ils aient toujours attiré certaines curiosités, les fichiers robots.txt peuvent être des outils très efficaces. Les moteurs de recherche tels que Google et Bing utilisent des robots pour crawler le contenu du web. Le fichier robots.txt fournit des indications aux différents robots sur les pages qu’ils ne doivent pas crawler sur votre site. Vous pouvez également créer un lien vers votre sitemap XML à partir du fichier robots.txt afin que le robot dispose d’un plan de chaque page qu’il doit crawler.
Pourquoi un robot.txt est-il utile ?
Le Robots.txt limite le nombre de pages qu’un robot doit parcourir et indexer. Si vous voulez éviter que Google ne crawl les pages d’administration de votre site, vous pouvez les bloquer sur votre robots.txt afin d’essayer de garder une page hors des serveurs de Google.
En plus d’empêcher les pages d’être indexées, les robots.txt sont parfaits pour optimiser le budget de crawl. Le budget de crawl est le nombre de pages que Google explorera sur votre site. En général, les sites web ayant plus d’autorité et plus de pages ont un budget de crawl plus important que les sites web ayant un nombre de pages et une autorité plus faibles. Comme nous ne savons pas quel est le budget d’indexation alloué à notre site, nous voulons profiter au maximum de ce temps en permettant au Googlebot d’accéder aux pages les plus importantes au lieu de parcourir des pages que nous ne voulons pas voir indexées.
Un détail très important que vous devez savoir à propos de robots.txt est que si Google ne crawlera pas les pages qui sont bloquées par robots.txt, elles peuvent néanmoins être indexées si la page est liée à un autre site web. Pour éviter que vos pages ne soient indexées et n’apparaissent dans les résultats de recherche Google, vous devez protéger par mot de passe les fichiers sur votre serveur, utiliser la balise meta noindex ou l’en-tête de réponse, ou supprimer entièrement la page (répondre par 404 ou 410). Pour plus d’informations sur le crawling et le contrôle de l’indexation, vous pouvez consulter le guide robots.txt de Oncrawl.
[Étude de cas] Gérer le crawl du robot de Google

Syntaxe correcte de Robots.txt
La syntaxe de robots.txt peut parfois être un peu délicate, car les crawlers interprètent la syntaxe différemment. De plus, certains crawlers non fiables considèrent les directives robots.txt comme des suggestions et non comme une règle précise qu’ils doivent suivre. Si vous avez des informations confidentielles sur votre site, il est important d’utiliser une protection par mot de passe en plus du blocage des crawlers utilisant le fichier robots.txt.
J’ai énuméré ci-dessous quelques éléments à garder à l’esprit lorsque vous travaillez sur votre robot.txt :
- Le fichier robots.txt doit se trouver sous le domaine et non dans un sous-répertoire. Les crawlers ne recherchent pas les fichiers robots.txt dans les sous-répertoires.
- Chaque sous-domaine a besoin de son propre fichier robots.txt :
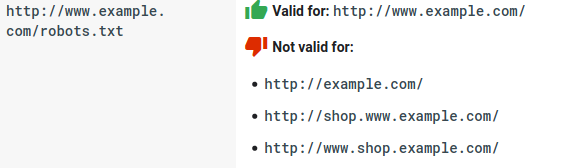
- Le robots.txt est un cas sensible :
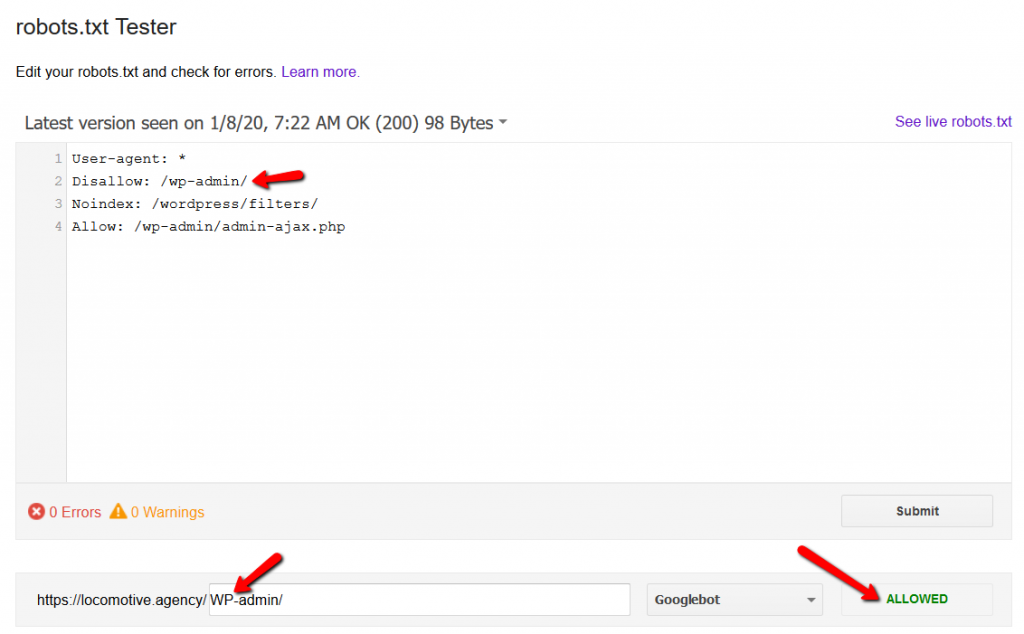
- La directive noindex : Lorsque vous utilisez noindex dans le fichier robots.txt, cela fonctionne de la même manière que le disallow. Google cessera de parcourir la page mais la conservera dans son index. @jroakes et moi avons créé un test dans lequel nous avons utilisé la directive noindex sur l’article /wordpress/filters/ et soumis la page dans Google. Vous pouvez voir sur la capture d’écran ci-dessous qu’elle montre que l’URL a été bloquée :
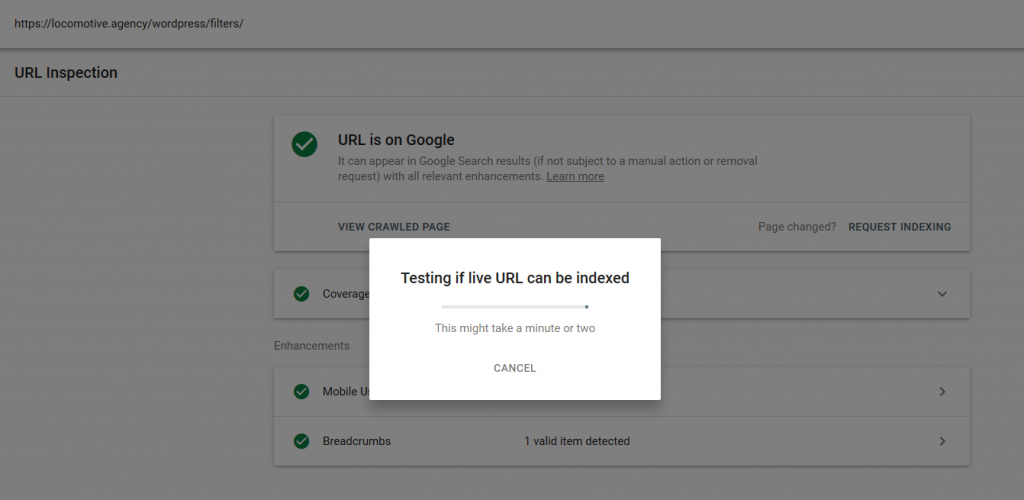
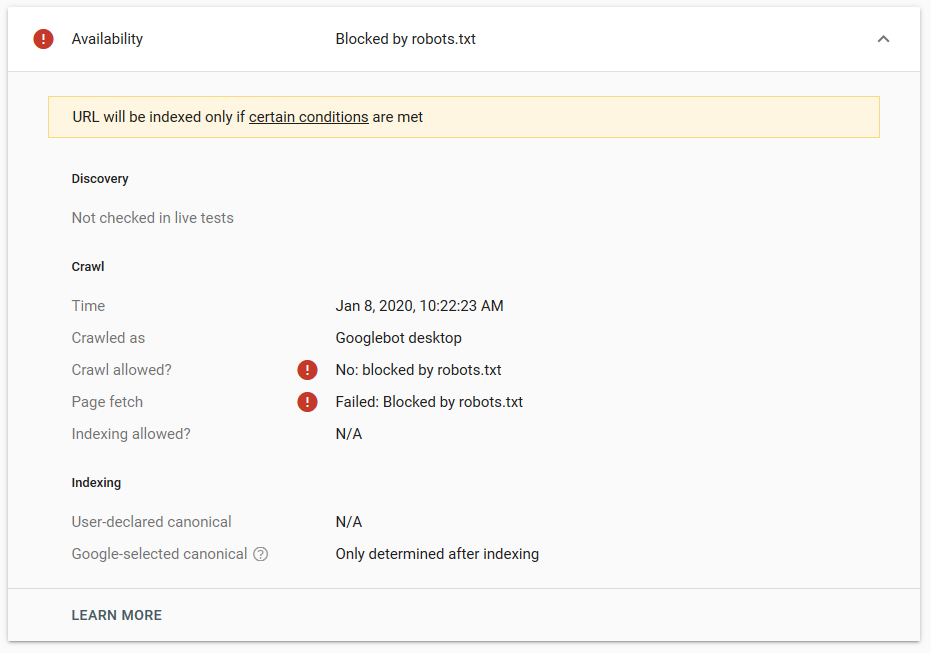
Nous avons fait plusieurs tests dans Google et la page n’a jamais été retirée de l’index :
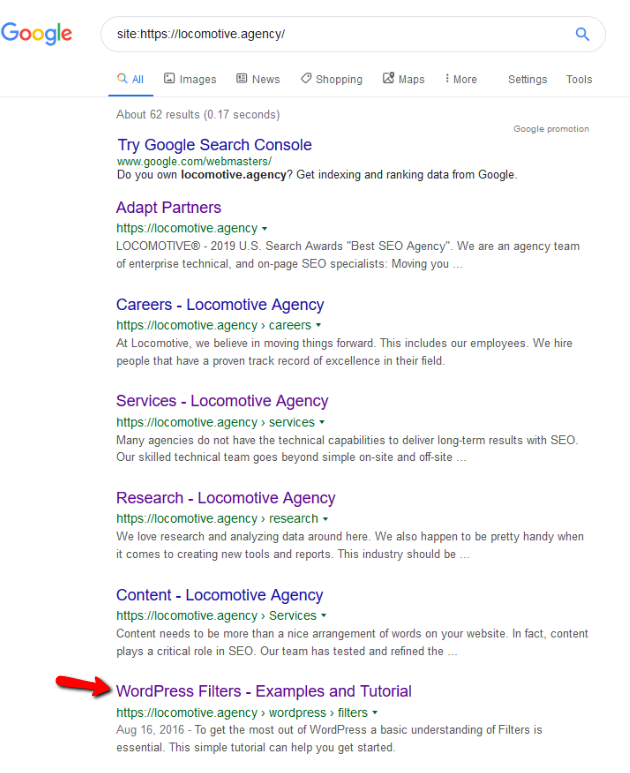
L’année dernière, il y a eu une discussion sur la directive « noindex » qui fonctionne dans le fichier robots.txt et qui supprime les pages mais pas avec Google. Voici un fil de discussion où Gary Illyes a déclaré que le fichier allait disparaître. Sur ce test, nous pouvons voir que la solution de Google est en place, puisque la directive noindex n’a pas supprimé la page des résultats de recherche.
Récemment, il y a eu un autre fil de discussion intéressant sur Twitter de Christian Oliveira, où il a partagé plusieurs détails à prendre en considération lors de l’élaboration de votre robot.txt.
- Si nous voulons avoir des règles génériques et des règles uniquement pour le Googlebot, nous devons dupliquer toutes les règles génériques sous le User-agent : Ensemble de règles pour les robots Google. Si elles ne sont pas incluses, Googlebot ignorera toutes les règles :

- Un autre règle déroutante est que la priorité des règles (au sein d’un même groupe de User-agent) n’est pas déterminée par leur ordre, mais par la longueur de la règle.
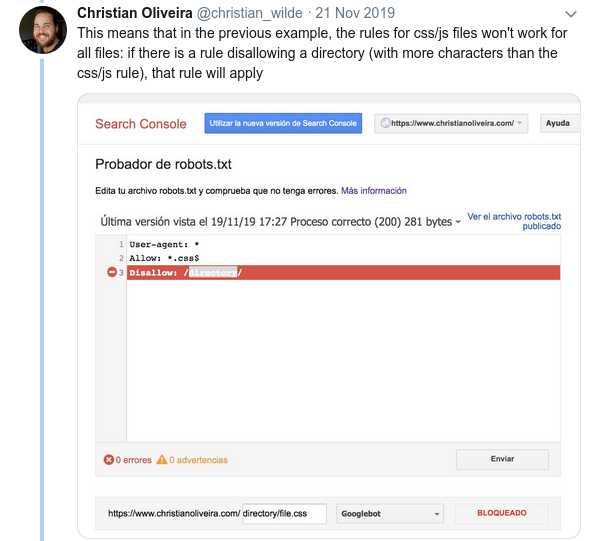
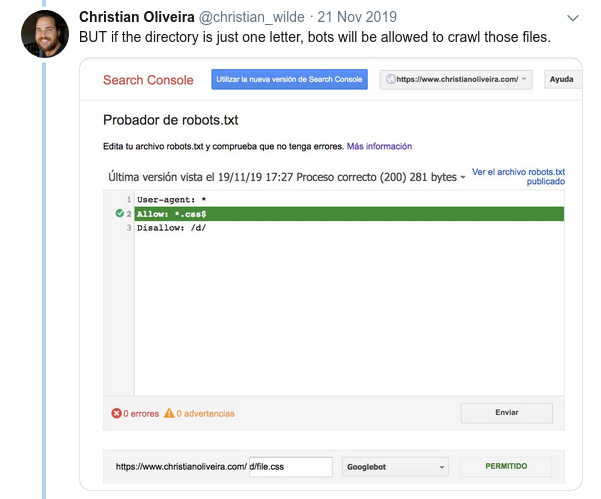
- Maintenant, lorsque vous avez deux règles, de même longueur et de comportement opposé (l’une autorisant le crawling et l’autre le refusant), la règle la moins restrictive s’applique :
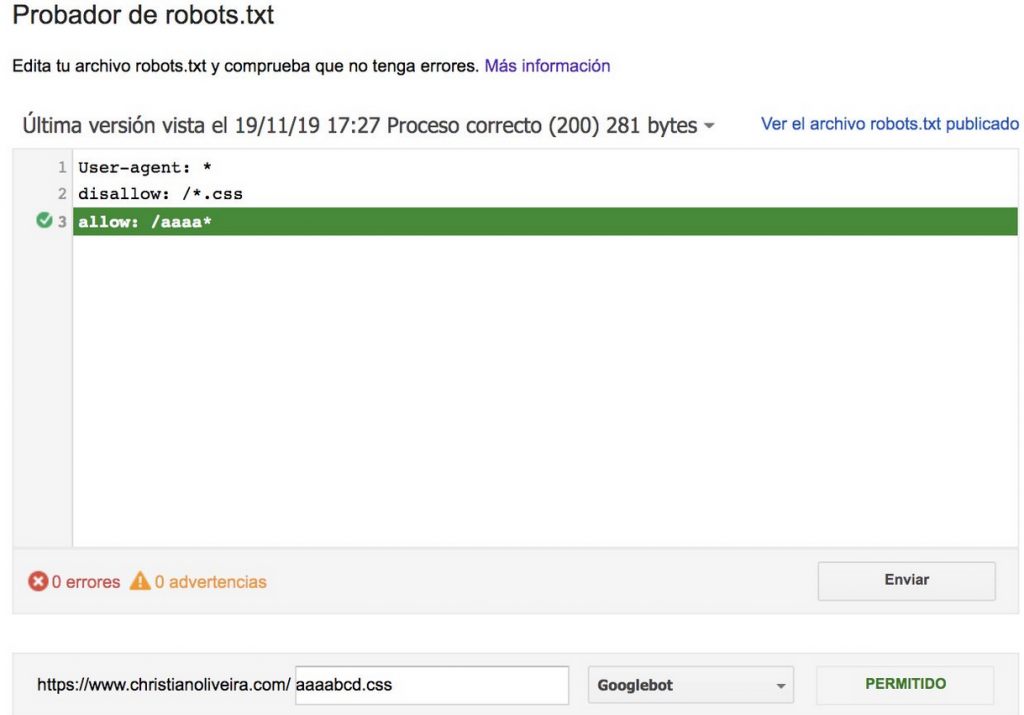
Pour plus d’exemples, veuillez lire les spécifications de robots.txt fournies par Google.
Outils pour tester votre Robots.txt
Si vous souhaitez tester votre fichier robots.txt, il existe plusieurs outils qui peuvent vous aider :
- Distilled
- Google a laissé l’outil de test robots.txt de l’ancienne Google Search Console ici
- Sur Python
- Sur C++
Exemples de résultats : utilisation efficace d’un Robots.txt pour le e-commerce
J’ai inclus ci-dessous un cas où nous travaillions avec un site Magento qui n’avait pas de fichier robots.txt. Magento ainsi que d’autres CMS ont des pages d’administration et des répertoires avec des fichiers dont nous voulons éviter le crawl par Google. Nous avons mis ci-dessous un exemple de certains des répertoires que nous avons inclus dans le fichier robots.txt :
# # General Magento directories Disallow: / app / Disallow: / downloader / Disallow: / errors / Disallow: / includes / Disallow: / lib / Disallow: / pkginfo / Disallow: / shell / Disallow: / var / # # Do not index the search page and non-optimized link categories Disallow: /catalog/product_compare/ Disallow: /catalog/category/view/ Disallow: /catalog/product/view/ Disallow: /catalog/product/gallery/ Disallow: /catalogsearch/
L’énorme quantité de pages qui ne devaient pas être crawlées affectait leur budget de crawl et le Googlebot n’arrivait pas à crawler toutes les pages produits sur le site.
Vous pouvez voir sur l’image ci-dessous comment les pages indexées ont augmenté après le 25 octobre, date à laquelle le site robots.txt a été mis en place :
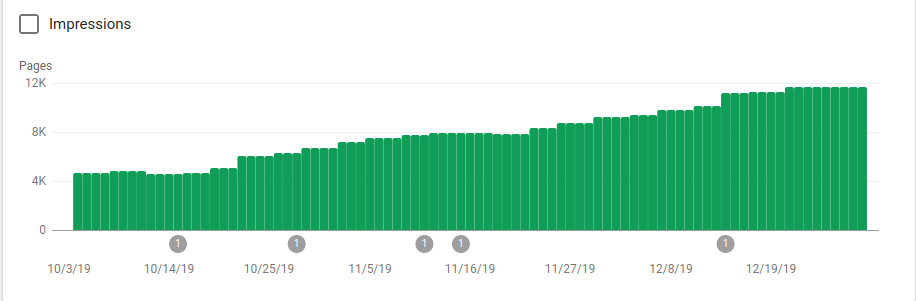
En plus de bloquer plusieurs répertoires qui n’étaient pas destinés à être crawlé, les robots ont inclus un lien vers la sitemap. Sur la capture d’écran ci-dessous, vous pouvez voir comment le nombre de pages indexées a augmenté par rapport aux pages exclues :
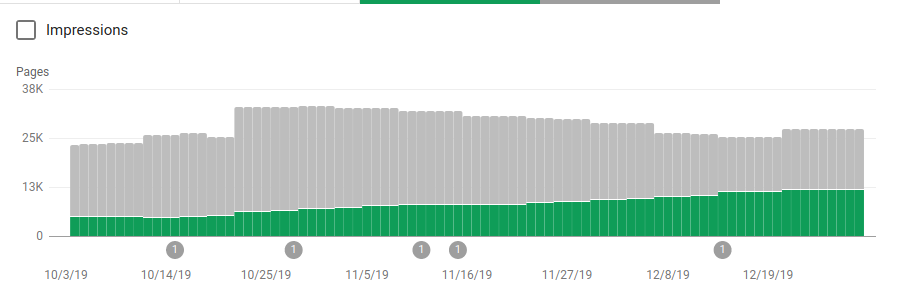
Il y a une tendance positive sur les pages indexées valides, comme le montrent les barres vertes, et une tendance négative sur les pages exclues, représentées par les barres grises.
Conclusion
L’importance du robots.txt peut parfois être sous-estimée et comme vous avez pu le voir dans cet article, il y a beaucoup de détails à prendre en compte lors de la création de celui-ci. Mais le travail est payant ! J’ai mis en avant certains des résultats positifs que l’on peut obtenir en configurant correctement un fichier robots.txt. N’hésitez plus !
