
Le scraping nous offre un moyen très rapide et facile d’extraire des informations d’un site web et de les sauvegarder dans un format utilisable. Que vous créiez des flux d’achats, des visualisations de données ou que vous migriez le contenu d’un site préexistant, le scraping rend tout cela possible !
Pour donner un autre exemple d’utilisation du scraping que vous n’auriez peut-être pas envisagé, je vais vous expliquer comment utiliser Oncrawl pour extraire du contenu existant afin de remplir un nouveau site où ensuite, il sera possible de mener des expériences que vous ne voulez pas tester sur un environnement réel.
Qu’est ce que le scraping de contenu ?
Le scraping de contenu consiste à copier du contenu (ou des données) d’une source web et à l’utiliser ailleurs. Parfois, le scraping peut être considéré comme du vol ou du plagiat. Dans la grande majorité des cas, c’est un robot automatisé qui effectue le scraping, bien que les raisons qui le motivent puissent varier considérablement.
Google (et le Googlebot) est l’un des scrapeurs de contenu les plus prolifiques. La plupart du temps, il le fait pour ensuite indexer et analyser le contenu scrapé afin de comprendre ce qu’il contient. Les informations obtenues de cette manière sont ensuite utilisées pour rechercher des résultats, c’est-à-dire le contenu qui se classe lorsque vous recherchez quelque chose. Certains diront que cette utilisation du scraping est intéressante.
Le scraping peut être assez « stupide » et se contenter d’aspirer tout le contenu en recherchant des éléments d’information particuliers. La plupart des scraping se font sans que le propriétaire du contenu en soit conscient, ni même sans son consentement.
Le scraping éthique
Même si vous n’étiez pas familier avec le scraping avant de lire ceci, vous vous demandez peut-être si le scraping est éthique ou non. Dans certains cas, les activités de scraping sont non seulement contraires à l’éthique, mais elles sont également illégales. Publier le contenu (propriété intellectuelle) de quelqu’un d’autre sans son consentement ou son attribution n’est pas à faire.
Il existe de très bonnes raisons de supprimer un contenu, ce qui peut être fait de manière éthique, même dans l’intérêt du créateur !
Si le fait de supprimer un site entier et d’utiliser son contenu pour alimenter un nouveau site web semble suspect d’un point de vue éthique, c’est que la plupart du temps, c’est bien le cas. Cependant, grâce aux migrations web, j’ai utilisé cette technique pour récupérer des contenus qui ont été « oubliés » à plusieurs reprises. Je reviendrai plus tard sur certains de ces scénarios.
Pour l’instant, sachez que je ne recommande pas de prendre et publier du contenu sans l’autorisation explicite du propriétaire du contenu.
Extraction (scraping) à l’aide d’Oncrawl
Oncrawl dispose d’un grand nombre de puissantes fonctionnalités (et de nouvelles fonctionnalités sont ajoutées assez fréquemment), mais beaucoup d’outils ont des utilisations qui dépassent celles auxquelles vous pourriez vous attendre. Les crawlers basés sur le cloud sont très efficaces pour couvrir facilement les sites web, analyser et stocker les informations, mais ils peuvent également aider à extraire certaines informations, ce qui permet d’économiser d’innombrables heures de travail manuel.
Il faut d’abord configurer un nouveau crawl et activer le scraping. Vous pouvez lancer un crawl normal à partir d’une page d’accueil qui permet à Oncrawl de découvrir les pages OU vous pouvez télécharger une liste d’URLs si vous savez de quelles pages vous voulez extraire du contenu.
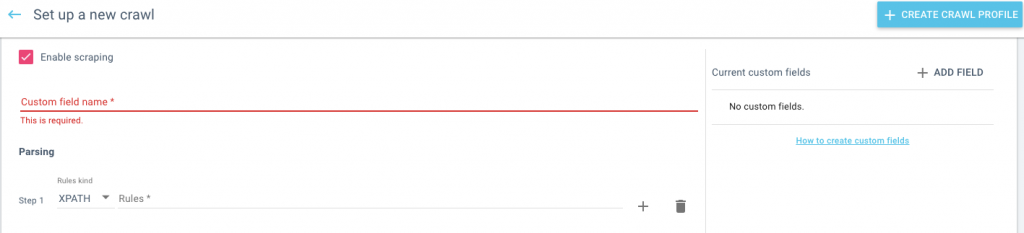
Pour scraper efficacement le contenu, vous devez savoir quelles informations vous voulez tirer de la page et comment les définir lorsque vous établissez le crawl. Vous pouvez dresser une liste des différentes informations que vous souhaitez extraire avant de commencer à mettre en place le crawl.
Pour chaque élément séparé que vous souhaitez extraire, vous devrez créer un champ et une règle d’extraction qui indique au robot quelles informations de chaque page il doit utiliser pour remplir le champ.
Dans la configuration du crawl, définissez le nom du champ et assurez-vous qu’il est descriptif, c’est ce qui sera indiqué dans le champ une fois le processus terminé. Oncrawl vous permet d’utiliser soit REGEX soit XPATH pour définir les différents éléments, vous devez utiliser celui que vous connaissez le mieux.
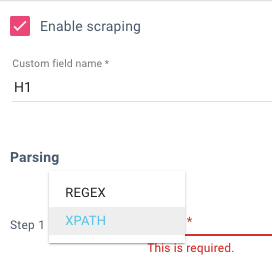
La façon la plus simple d’extraire le XPATH dont vous avez besoin est de visualiser une des pages avec le contenu que vous voulez extraire et d’inspecter l’élément dont vous avez besoin. Faites un clic droit et choisissez ensuite « Copier XPath ».
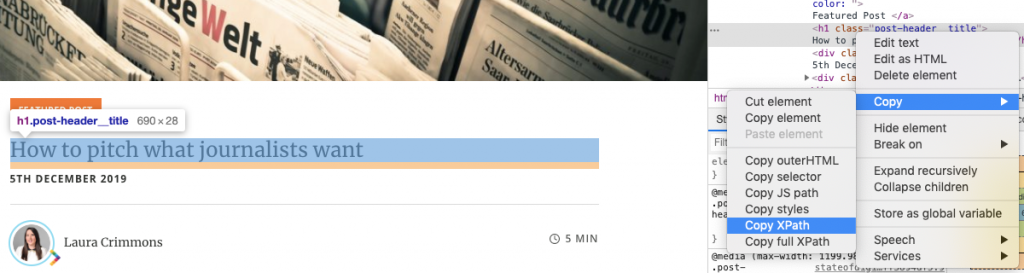
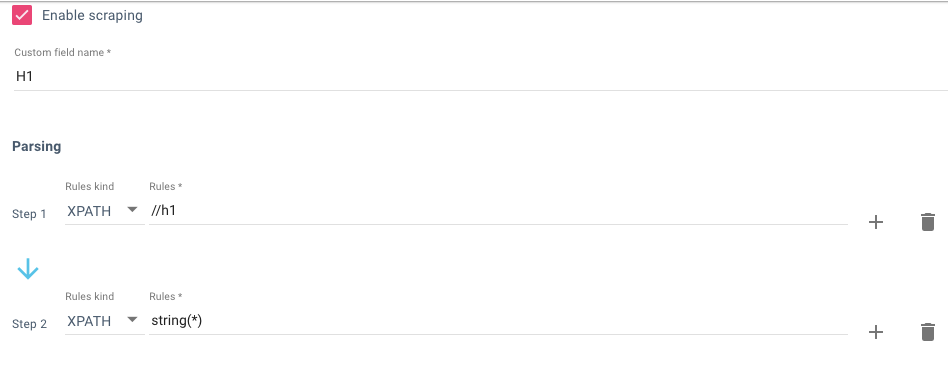
De retour dans Oncrawl, collez l’XPATH dans l’étape n°1, puis dans l’étape 2, définissez ce que vous voulez dans l’XPATH. Ainsi, dans l’exemple ci-dessous, nous voulons la balise <h1> qui est </h1> – puis extraire la chaîne de caractères de ces balises – « string(*) ».
Sans cette deuxième étape, le résultat serait « <h1>Certains contenus </h1> » pour les besoins de cette tâche, je ne veux pas que le HTML gâche tout !
Avant de commencer le crawl et de scraper votre site, vous pouvez tester votre règle pour voir quel est le résultat. Il vaut mieux vérifier plutôt que attendre de voir si elle a échoué après le crawl.
Collez un exemple de page dans le champ URL, puis cliquez sur valider, vous verrez le résultat sur la droite ! C’est simple !
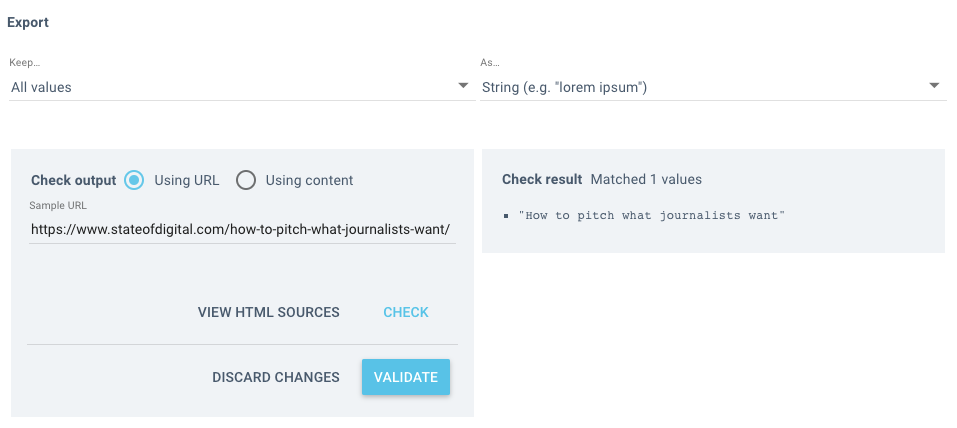
Une fois que vous avez fait cela avec le premier élément que vous vouliez scraper, vous devez le répéter pour le reste en créant un champ personnalisé pour chacun.
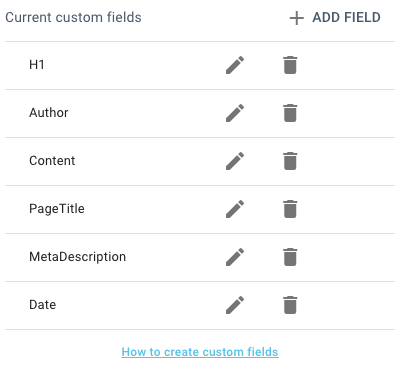
L’ensemble du processus est beaucoup plus rapide, plus efficace et plus agréable sur le site web que vous scrapez si vous savez quelles pages vous voulez qu’Oncrawl vérifie. Vous pouvez limiter votre crawl à ces seules pages en utilisant le mode liste d’URL. J’ai utilisé un sitemaps XML pour construire une liste d’URLs pour les articles de WordPress en particulier.
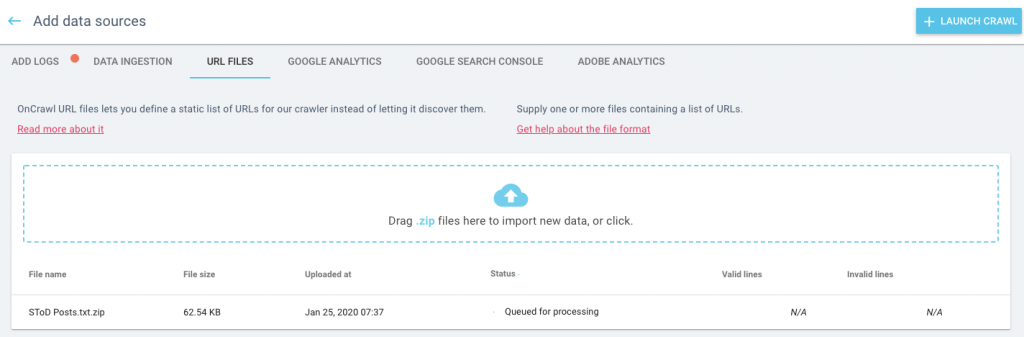
Une fois qu’il a été téléchargé, cliquez sur « lancer le crawl » et c’est parti !
Une fois le crawl terminé, accédez à l’explorateur de données et modifiez les champs pour qu’ils reflètent les champs personnalisés que vous avez définis précédemment. De cette façon, vous verrez les informations uniquement liées au scrap.
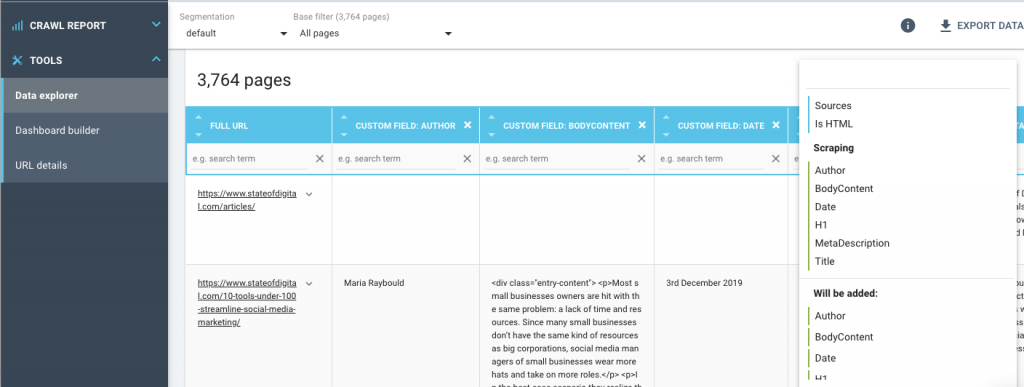
Vous pouvez le télécharger au format CSV et en faire ce que vous voulez !
Utilisation de contenu scrapé pour alimenter un nouveau site web (WordPress)
Les champs que j’ai sélectionnés lors de la mise en place du scraping étaient ceux dont j’aurais besoin pour faire passer ce contenu sur un nouveau site WordPress afin de remplir les articles (blog). Dans cet exemple, je crée un site sandbox pour expérimenter ce qui se passerait si je changeais le lien interne du site sans avoir à le faire à l’aveuglette sur le site en direct.
WordPress est l’exemple que j’utilise ici (parce que c’est relativement facile), mais vous pouvez le faire avec la plupart des CMS ou mettre le contenu scrapé directement dans une base de données si vous le souhaitez.
Par souci de simplicité, j’utilise le plugin WP All Import (sous licence libre) pour faire le gros du travail.
Tout d’abord, vous devez prendre votre exportation CSV d’Oncrawl et lancer l’importation.
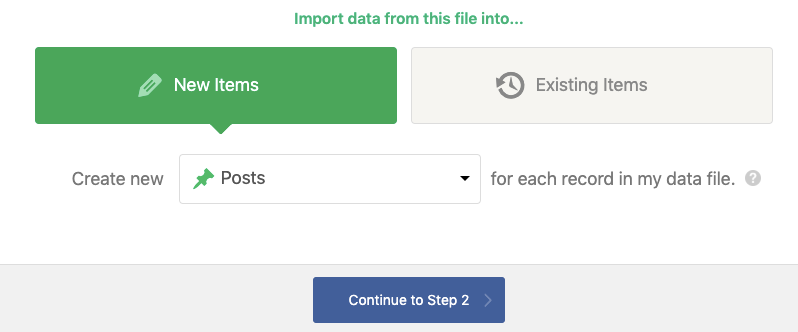
Comme je l’ai mentionné, je veux que ce soit des articles mais ces informations pourraient alimenter des produits (avec WooCommerce installé), des catégories, des pages, etc.
Cela peut prendre un certain temps, mais soyez patient, cela en vaut la peine !
Une fois le fichier analysé, vous devez ensuite faire correspondre les différentes valeurs du CSV aux champs du blog. Vous dites à WordPress quel est le titre de l’article, où va le contenu, la catégorie, etc.
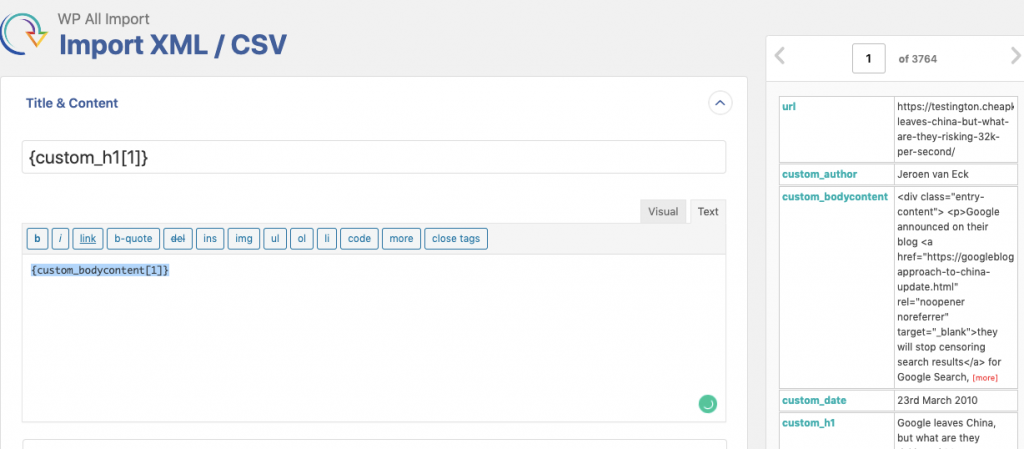
C’est là que vous découvrez si vous avez scrapé tout le contenu dont vous aviez besoin ou s’il vous manque des informations !
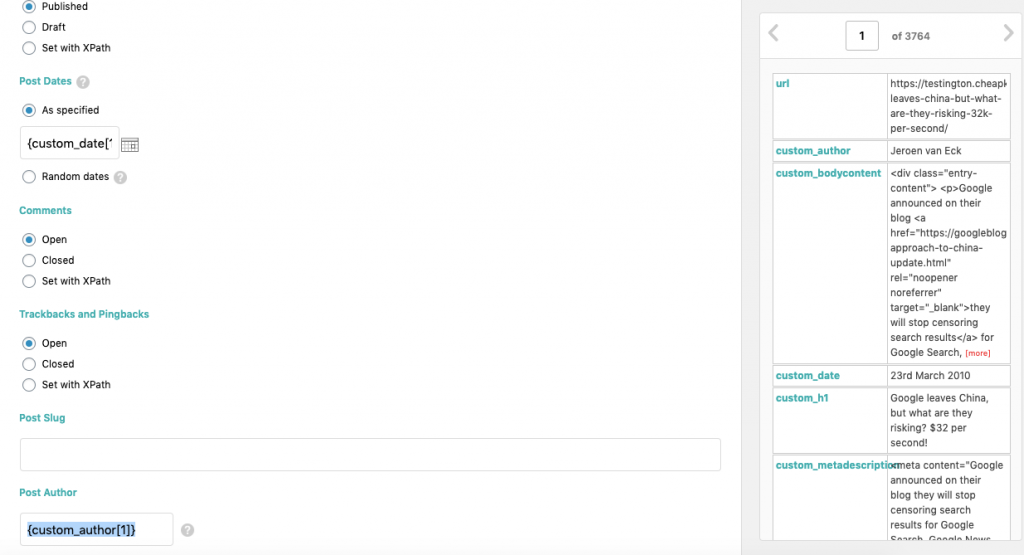
Une fois que vous êtes satisfait et que les champs ont été correctement mappés, vous pouvez vérifier le nombre total de messages (lignes) qui seront importés et si le contenu est correct ou non.
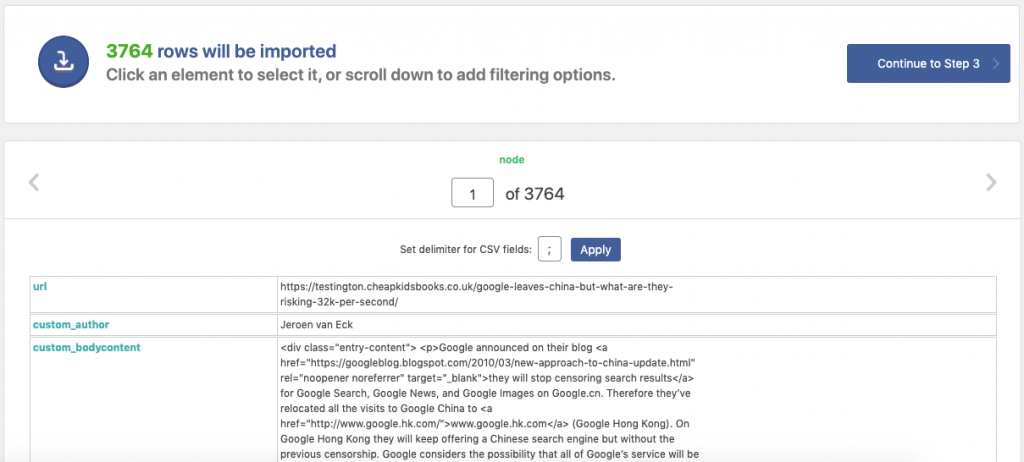
Commencez l’importation (ne fermez pas la fenêtre pendant qu’elle est en cours) et vous y êtes presque.
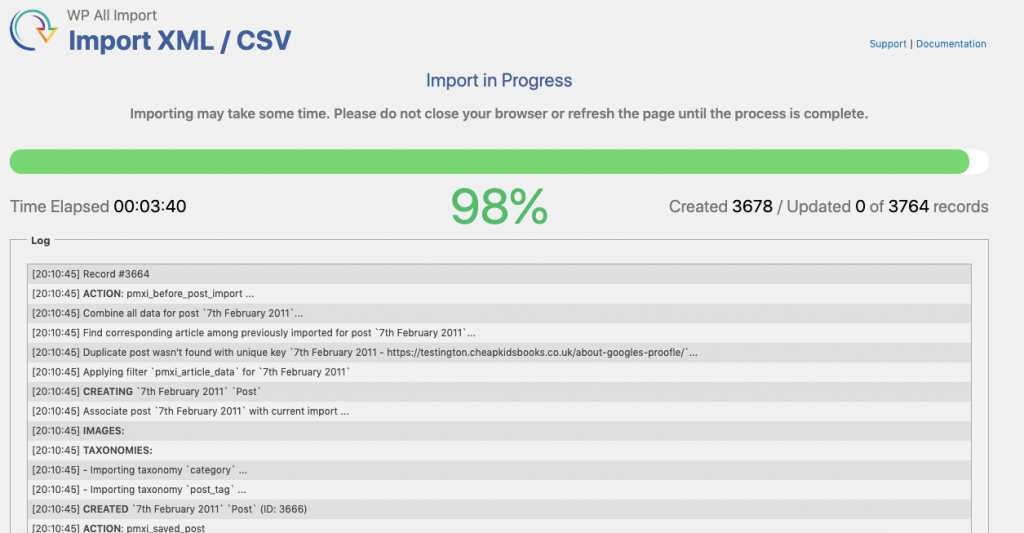
Vous constaterez peut-être que certains documents n’ont pas été correctement importés (ce qui n’est pas inhabituel lorsque vous scrapez le contenu). Vous pouvez examiner les erreurs éventuelles dans les rapports à la fin du processus mais à part cela, vous avez terminé.
Scénarios de scraping plus éthiques
Le scraping de contenu devient une addiction quand on s’y met, il y a de réelles applications qui permettent de gagner du temps (et de l’argent). Aucune de ces applications n’est la solution « parfaite » à tous les problèmes, mais elles constituent des solutions de rechange intéressantes lorsque vous devez agir rapidement.
Pré migration de site
Si vous migrez vers un nouveau site web, il n’y a pas de mal à faire une sauvegarde informelle du contenu du site, surtout si vous savez que certains contenus seront supprimés/fusionnés dans le cadre du changement. J’ai arrêté de compter le nombre de fois où j’ai vu des projets sans sauvegardes avant la migration, ou bien les sauvegardes sont faites par un développeur web mécontent ou encore sont corrompues/inutilisables.
Sauvegardes de migration de contenu
Malheureusement, les SEOs ne s’impliquent pas souvent dans un processus de migration de site aussitôt qu’ils le devraient. L’un des scénarios les plus courants est que les blogs sont « oubliés », qu’ils ne sont pas pris en compte dans la migration OU que quelqu’un décide de les laisser de côté. D’après mon expérience, environ 4 décisions sur 5 vont nuire au nouveau site. Proposer de supprimer/importer le contenu rapidement et facilement (selon la méthode décrite ci-dessus) peut très souvent l’emporter.
Création de flux de produits
Aussi frustrant que cela puisse être, tous les sites e-commerce sur lesquels j’ai travaillé n’ont pas eu la possibilité ou le budget nécessaire pour établir un flux d’achats à partir de la plateforme elle-même. Ce n’est jamais bon mais il est possible de récupérer les données du site et de les regrouper selon les modèles de données de Google.
L’audit au service des liens internes
Il n’est pas facile de trouver des possibilités de liens internes sur un grand site de contenu, mais j’ai réussi à scraper le contenu des pages et à l’importer dans des fiches, en utilisant REGEXMATCH pour trouver des mentions spécifiques de termes clés. Vous pouvez également utiliser une formule comme (=SUM(LEN(F2:F2)-LEN(SUBSTITUTE(F2:F2, « <a », « »)))/LEN(« <a »)) pour compter le nombre de balises dans la zone de contenu et également pour donner la priorité au contenu comportant moins de liens contextuels.
Analyse des commentaires
Si vous avez un blog avec une section de commentaires florissante et que vous voulez comprendre le sentiment ou les tendances du contenu lui-même, le fait de scraper les commentaires en CSV vous donne la possibilité de faire une analyse spécifique avec celui-ci via Excel, Sheets ou Python.
Quelle est la prochaine étape ?
Lorsque vous vous habituerez au scraping, cela vous donnera BEAUCOUP d’options et de possibilités dont vous n’étiez pas conscient auparavant. Pour en tirer le meilleur parti, entraînez-vous à travailler avec Xpath et testez toujours des échantillons d’extraction avant de vous lancer dans des scrapings importants afin de vous assurer que votre temps est bien utilisé.
Dans certains des exemples et méthodes que j’ai évoqués, l’extraction du contenu n’est jamais la meilleure option. Les bases de données et les APIs offrent presque toujours un moyen plus rapide, plus propre et plus efficace d’obtenir les données que vous souhaitez. Cependant, d’après mon expérience, les budgets, les calendriers et les décisions antérieures (erreurs) ne permettent pas de les utiliser. Voulez-vous être le marketeur victime de ces limites, ou préférez-vous trouver des solutions alternatives ?
