Dans toute stratégie axée sur l’optimisation des moteurs de recherche (SEO), l’analyse des données est essentielle. De plus en plus de spécialistes choisissent de développer leur carrière dans l’analyse du trafic de recherche organique, qui a en soi un comportement et des particularités bien différents du reste : paid search, email, social organique, direct, etc. Grâce à une large gamme d’outils disponibles aujourd’hui, ce type d’études a réussi à évoluer à un degré impensable par rapport à il y a seulement quelques années.
Ce grand pas en avant est principalement dû à l’apparition de nouvelles méthodologies et de développements qui nous ont permis de générer des modèles analytiques sans avoir à recourir à des opérations mathématiques compliquées. Nous avons la chance d’avoir à notre disposition des techniques et des algorithmes déjà testés et prêts à travailler avec eux.
Dans l’article ci-dessous, nous allons nous concentrer sur la création d’un modèle prédictif pour un ensemble de données d’une série chronologique où la tendance calculée est ajustée à la saisonnalité et à la périodicité antérieure. Plus précisément, nous allons prédire le trafic de recherche organique de notre site à partir de Google Analytics 4 (ci-après GA4). Il existe de nombreuses options pour effectuer cette prédiction, mais pour ce cas particulier, j’ai décidé d’exécuter le développement entièrement en Python.
Le script sur lequel se base cet article est composé de trois parties clairement différenciées :
- L’extraction des données. Comment utiliser la nouvelle API GA4 étape par étape pour collecter le trafic de recherche organique.
- Modélisation des données. Utilisation de Prophet, la bibliothèque open-source de Facebook, pour faire des prédictions de séries temporelles.
- Visualisation des données. Montrez les changements de tendance et les prédictions modélisées.
Extraction des données de GA4 via son API en utilisant Python
La première chose que nous devons savoir lorsque nous traitons de l’API de données Google Analytics (GA4) est son statut de développement. Comme l’explique Google sur sa page, il s’agit d’une version préliminaire. Plus précisément, à la date de rédaction de cet article, il est encore en phase bêta.
Il convient de noter que GA4 a été publié le 14 octobre 2020. Quelques mois seulement se sont écoulés. En fait, ceux qui avaient déjà une propriété Universal Analytics et qui en créent une nouvelle GA4 pourront continuer à utiliser les deux versions côte à côte, sans aucune restriction. On ne sait pas avec certitude quand les propriétés Universal Analytics cesseront de fonctionner. Dans tous les cas, je vous recommande de créer une nouvelle propriété de type GA4 dès que possible. De cette façon, vous disposerez d’un historique de données plus large. Il faut également considérer que chaque jour qui passe GA4 intègre de nouvelles fonctionnalités ou améliore celles existantes. Pour l’instant, il est en constante évolution.
Pour cette raison, il peut bien sûr y avoir de petits changements dans le code décrit ci-dessous. Mais il est certain qu’ils seront minimes. À titre d’exemple, j’ai déjà renommé le champ « entity » (phase Alpha) en « property » (phase Beta) dans la classe RunReportRequest().
Avant toute chose, avant de construire la requête API, il faut comprendre quels sont les éléments disponibles. En gros, il s’agit de suivre la structure ci-dessous :
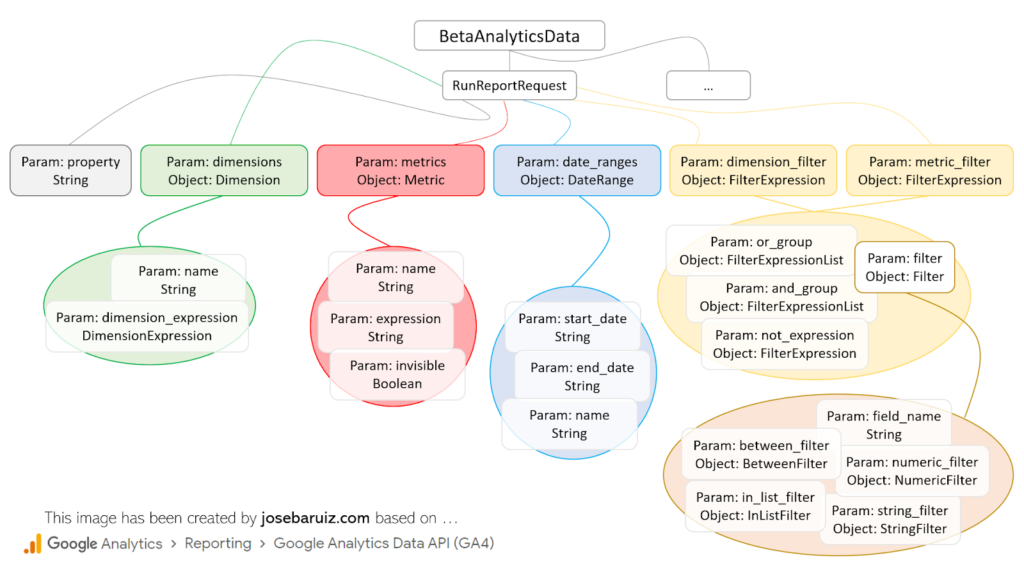
Types pour RunReportRequest de l’API GA4 Data v1 Beta
À première vue, c’est assez intuitif, bien que la réalité soit tout autre. Pour effectuer une requête, il est nécessaire d’avoir toujours à portée de main au moins la documentation suivante :
Cela s’explique simplement par le fait que les noms des champs varient légèrement par rapport à la documentation officielle, qui représente les champs au format JSON. Un exemple est le champ fieldname de la classe Filter. En Python, nous devrions le décrire comme field_name. Une bonne règle générale consistera toujours à passer d’un champ de type camel case (comme « fieldName ») à un champ de type snake case (comme « field_name »).
Avant de continuer, arrêtons-nous un instant pour initialiser notre projet. Comme dans la grande majorité des cas lors du développement de scripts en Python, nous devons passer un peu de temps à importer les bibliothèques nécessaires et à préparer l’environnement d’exécution.
- Créez un nouveau projet en Python. Dans ce cas, le logiciel PyCharm a été utilisé.
- Activez l’API de données Google Analytics dans Google Cloud Platform, téléchargez le fichier de compte de service créé (de type JSON) et enregistrez-le dans le dossier où le projet Python a été créé. En ouvrant ce fichier, il faut copier la valeur du champ client_email, qui sera quelque chose comme name-mail@project-id.iam.gserviceaccount.com.
- Ajoutez cette valeur client_email à la propriété GA4 dont les données seront extraites. Vous devrez le faire dans la section de gestion des utilisateurs. Au minimum, il sera nécessaire de lui accorder le niveau de permission ‘Read & Analysis’.
- Via le terminal client (PyCharm), installez la bibliothèque Google Analytics Data dans le répertoire du projet avec lequel les requêtes API seront effectuées :
pip install google-analytics-data
À partir de là, tout ce que vous devez faire est de créer la requête qui, comme vous pouvez le voir ci-dessous, se compose essentiellement de trois parties (client, requête et réponse), et de visualiser ou de sauvegarder les données collectées.
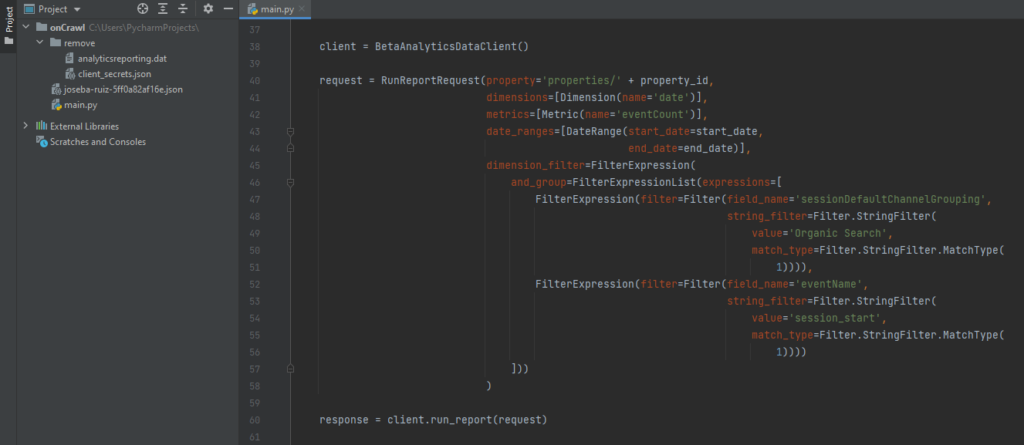
Code pour faire une requête simple à GA4
Toute dimension, métrique, filtre, ordre de données, plage de dates, etc. ajoutée à la variable de la requête doit être ajoutée en tant que classe (voir l’image précédente « Types pour RunReportRequest ») liée à une variable (metrics = [Metric (..)]). Cela permet de comprendre beaucoup plus facilement la structure des données à collecter. En ce sens, pour chaque classe du plus haut niveau, une importation spécifique doit être effectuée. C’est-à-dire que si vous voulez ajouter une dimension et une métrique pour une période spécifique, il faudra au moins les objets suivants…
from google.analytics.data_v1beta import BetaAnalyticsDataClient from google.analytics.data_v1beta.types import RunReportRequest from google.analytics.data_v1beta.types import DateRange from google.analytics.data_v1beta.types import Dimension from google.analytics.data_v1beta.types import Metric
Bien entendu, il est également possible d’ajouter des valeurs spécifiques à certaines variables (name = ‘eventCount’). Pour cette raison, il est essentiel de comprendre et de se plonger dans la documentation décrite précédemment.
En plus de cela, une attention particulière doit être portée à la variable os.environ [« GOOGLE_APPLICATION_CREDENTIALS »], qui contiendra le chemin d’accès au fichier précédemment téléchargé à l’étape 2. Cette ligne de code permettra d’éviter certains problèmes lors de la gestion des permissions de l’API Google.
Si le code a été exécuté correctement, vous verrez un résultat qui ressemble à ceci : {Date, Events}, {20210418, 934}, {…}, ….
Prédiction de données par Facebook Prophet
De nos jours, il existe de nombreuses options gratuites et existantes pour effectuer tout type de prédiction basée sur l’historique des données. Dans ce cas précis, j’ai choisi la bibliothèque Prophet, mais de quoi s’agit-il ?
Il s’agit d’une bibliothèque open-source (disponible pour R et Python) créée par l’équipe Data Science de Facebook pour estimer le comportement d’un ensemble de données de séries temporelles basé sur un modèle additif où les tendances non linéaires sont ajustées à une saisonnalité quotidienne, hebdomadaire et annuelle en tenant compte des effets des jours de vacances.
Pour en revenir à l’implémentation proposée (prédiction du trafic de recherche organique), la première chose à faire est d’installer les bibliothèques suivantes :
- Pandas (pip install pandas). Gère et analyse les structures de données.
- Plotly (pip install plotly). Création de graphiques de toutes sortes.
- Prophet (conda install -c conda-forge fbprophet -y).
Ensuite, comme toujours, vous devez effectuer les importations associées à ces bibliothèques. Après cela, il ne vous reste plus qu’à effectuer la modélisation de la prédiction et sa visualisation correspondante. Pour ce faire, dans le cas de Prophet, il vous suffit de suivre ce processus :
- Initialiser un nouvel objet Prophet avec les attributs souhaités pour générer la prédiction.
- Demander la méthode d’ajustement, en lui passant les données extraites de GA4 sous forme de dataframe. Cette requête peut prendre plusieurs secondes dans certains cas. Le dataframe contenant les données collectées ne doit comporter que deux colonnes dont les noms sont toujours les mêmes : ds (champ de type date) et y (métrique à étudier).
- Créer un nouveau dataframe futur en définissant le nombre de périodes jusqu’auxquelles la prédiction doit aller à partir de la plage de dates sélectionnée et la fréquence à laquelle les données seront agrégées (hebdomadaire, mensuelle, etc.).
- Demander la méthode predict, qui attribuera à chaque ligne du nouveau cadre de données futur une valeur prédite (yhat).
- Demander la méthode plot pour pouvoir visualiser les prédictions générées.
- Demander la méthode plot_components qui permet de comprendre visuellement la tendance et la saisonnalité des données.
m = Prophet() m.fit(df) future = m.make_future_dataframe(periods=365) forecast = m.predict(future) m.plot(forecast) m.plot_components(forecast) plt.show()
Bien que la prédiction souhaitée ait été générée en seulement six étapes et qu’elle semble relativement simple, il faut prendre en compte plusieurs éléments qui seront déterminants pour la génération de la prédiction. Ils affectent tous la pertinence de la prédiction d’une manière ou d’une autre. Au final, il s’agit de générer une prédiction conforme à la logique, dans le cas de cet article, de notre trafic de recherche organique. Pour cela, il est nécessaire de comprendre certains paramètres plus avancés de Prophet.
- Jours spéciaux et vacances. Il est possible d’ajouter des jours spéciaux.
- Les valeurs aberrantes. Elles doivent être éliminées si elles affectent l’estimation.
- Points de changement. Détection des changements de tendance au cours de la période analysée.
- Diagnostic. Validation basée sur la mesure de l’erreur de prédiction en fonction de l’étude historique des données.
- Augmentation. Sélection entre linéaire ou logistique.
- Saisonnalité. Choix entre additif ou multiplicatif.
Tout ceci et bien d’autres options sont parfaitement détaillées dans cette documentation de la bibliothèque Prophet.
Création du script complet pour pouvoir visualiser la prédiction de trafic
Il ne reste plus qu’à réunir toutes les pièces du puzzle en un seul script. La façon habituelle d’aborder ce type de puzzle est de créer une fonction pour chacun des processus détaillés précédemment, de manière à ce qu’ils puissent être exécutés de manière ordonnée et propre :
def ga4(property_id, start_date, end_date): […] def forecasting(dim, met, per, freq): […] if __name__ == "__main__": dimension, metric = ga4(PROPERTY_ID, START_DATE, END_DATE) forecasting(dimension, metric, PERIODS, FREQ)
Avant de visualiser le résultat final de la prédiction, il est bon d’examiner le trafic de recherche organique analysé.
Au premier coup d’œil, vous pouvez voir comment les différentes stratégies et actions entreprises ont eu un effet au fil du temps. Contrairement à d’autres canaux (par exemple, les campagnes de recherche payante), le trafic généré par la recherche organique présente généralement peu d’oscillations appréciables (creux ou pics). Il a tendance à augmenter ou à diminuer progressivement dans le temps et est parfois influencé par des événements saisonniers. Habituellement, les fluctuations notables sont associées aux mises à jour de l’algorithme du moteur de recherche (Google, Bing, etc.).
Le résultat du script est visible dans l’image suivante, où sont détaillés des facteurs importants tels que la tendance, la saisonnalité, la prédiction ou la fréquence des données.
Si nous analysons la prédiction obtenue, on pourrait conclure de manière générique que « si nous continuons avec la même stratégie SEO mise en œuvre jusqu’à présent, le trafic provenant des moteurs de recherche continuera à augmenter progressivement ». Nous pouvons assurer que « nos efforts pour améliorer les performances du site web, générer du contenu de qualité, fournir des liens pertinents, etc. en ont valu la peine ».
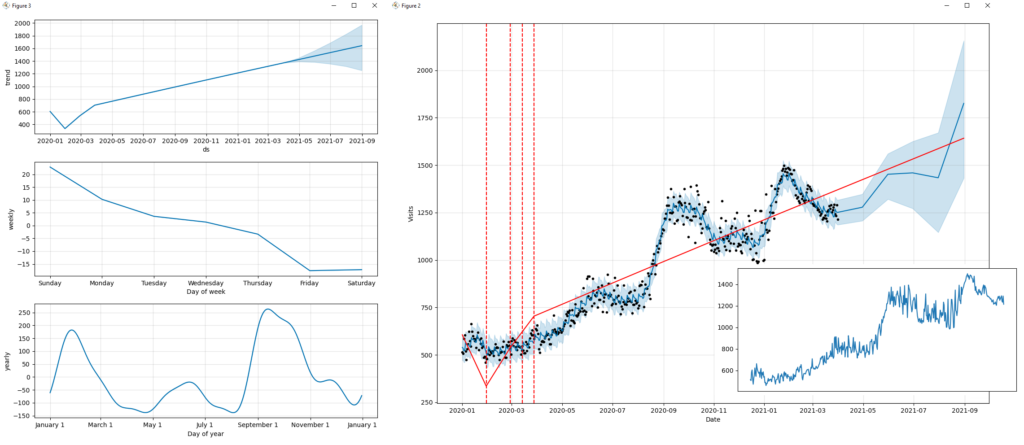
Visualisation de la tendance, de la saisonnalité et de la prédiction, tendance du trafic de recherche organique.
Pour conclure, je vais partager le code dans son intégralité afin que vous n’ayez qu’à le copier et l’exécuter dans votre IDE (Integrated Development Environment) de Python. Il va sans dire que toutes les bibliothèques mentionnées ci-dessus doivent avoir été installées pour que cela fonctionne correctement.
import pandas as pd
import fbprophet
from fbprophet import Prophet
from fbprophet.plot import add_changepoints_to_plot
import matplotlib.pyplot as plt
import os
from google.analytics.data_v1beta import BetaAnalyticsDataClient
from google.analytics.data_v1beta.types import DateRange
from google.analytics.data_v1beta.types import Dimension
from google.analytics.data_v1beta.types import Metric
from google.analytics.data_v1beta.types import Filter
from google.analytics.data_v1beta.types import FilterExpression
from google.analytics.data_v1beta.types import FilterExpressionList
from google.analytics.data_v1beta.types import RunReportRequest
PROPERTY_ID = '[Add here the GA4 property_id]'
START_DATE = '2020-01-01'
END_DATE = '2021-03-31'
PERIODS = 4
FREQ = 'M'
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "[Add here the path of the json file with the credentials]"
def ga4(property_id, start_date, end_date):
client = BetaAnalyticsDataClient()
request = RunReportRequest(property='properties/' + property_id,
dimensions=[Dimension(name='date')],
metrics=[Metric(name='eventCount')],
date_ranges=[DateRange(start_date=start_date,
end_date=end_date)],
dimension_filter=FilterExpression(
and_group=FilterExpressionList(expressions=[
FilterExpression(filter=Filter(field_name='sessionDefaultChannelGrouping',
string_filter=Filter.StringFilter(
value='Organic Search',
match_type=Filter.StringFilter.MatchType(
1)))),
FilterExpression(filter=Filter(field_name='eventName',
string_filter=Filter.StringFilter(
value='session_start',
match_type=Filter.StringFilter.MatchType(
1))))
]))
)
response = client.run_report(request)
x, y = ([] for i in range(2))
for row in response.rows:
x.append(row.dimension_values[0].value)
y.append(row.metric_values[0].value)
print(row.dimension_values[0].value, row.metric_values[0].value)
return x, y
def forecasting(x, y, p, f):
print('Prophet %s' % fbprophet.__version__)
data = {'ds': x, 'y': y}
df = pd.DataFrame(data, columns=['ds', 'y'])
m = Prophet(growth='linear',
changepoint_prior_scale=0.5,
seasonality_mode='additive',
daily_seasonality=False,
weekly_seasonality=True,
yearly_seasonality=True,
holidays=None,
)
m.fit(df)
future = m.make_future_dataframe(periods=p, freq=f)
forecast = m.predict(future)
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head())
fig = m.plot(forecast, xlabel='Date', ylabel='Visits')
add_changepoints_to_plot(fig.gca(), m, forecast)
m.plot_components(forecast)
plt.show()
if __name__ == "__main__":
channel_group, event_count = ga4(PROPERTY_ID, START_DATE, END_DATE)
forecasting(channel_group, event_count, PERIODS, FREQ)
J’espère que cet article vous a servi d’inspiration et qu’il vous sera d’une grande utilité dans vos prochains projets. Si vous souhaitez continuer à apprendre sur ce type de mise en œuvre ou en savoir plus sur le marketing digital plus technique, n’hésitez pas à me contacter. Vous pouvez trouver plus d’informations dans mon profil d’auteur ci-dessous.
