L’intérêt de Python dans le cadre du SEO n’est plus un secret. Cependant, avec peu d’expérience en programmation, il peut être difficile d’importer et d’utiliser un grand nombre de bibliothèques ou de pousser des résultats au-delà de ce qu’un crawler peut faire.
C’est pourquoi une bibliothèque Python créée spécifiquement pour le SEO, le SEM, le SMO et l’analyse de contenu peut être utile au plus grand monde.
Dans cet article, nous allons examiner quelques-unes des choses qui peuvent être faites avec la bibliothèque Python Advertools pour le SEO, créée et développée par Elias Dabbas, et pour laquelle je vois un grand potentiel. De plus, nous utiliserons des scripts Python personnalisés avec d’autres bibliothèques Python d’une manière éducative et adaptative.
Nous allons examiner ce que l’on peut apprendre d’un sitemap grâce à la fonction sitemap_to_df d’Elias Dabbas qui aide à télécharger et à analyser les sitemaps XML . Pour rappel, un sitemap est un document au format XML utilisé pour signaler les URLs crawlables et indexables aux moteurs de recherche.
Cet article vous montrera comment écrire des codes Python personnalisés pour analyser différents sites web en fonction de leur structure, comment interpréter les données en termes de SEO et comment penser comme un moteur de recherche lorsqu’il s’agit de profils de contenu, d’URL et de structures de sites.
Analyse de l’échelle de contenu et de la stratégie d’un site en fonction de son sitemap
Un sitemap est un élément d’un site web qui peut saisir de nombreux types de données différentes, telles que la fréquence de publication d’un contenu, les catégories de contenu, les dates de publication, les informations sur l’auteur, le sujet du contenu…
Dans des conditions normales, vous pouvez scrapper un sitemap avec scrapy, le convertir en DataFrame avec Pandas et l’interpréter avec de nombreuses bibliothèques annexes si vous le souhaitez.
Mais dans cet article, nous n’utiliserons que les Advertools et quelques méthodes et attributs de la bibliothèque Pandas. Certaines bibliothèques seront activées pour visualiser les données que nous avons acquises.
Il est temps de plonger dans le sujet et de sélectionner un site web pour utiliser son sitemap !
Extraction et création de données à partir de sitemaps à l’aide d’Advertools
Dans Advertools, vous pouvez découvrir, parcourir et combiner tous les sitemaps d’un site web avec une seule ligne de code.
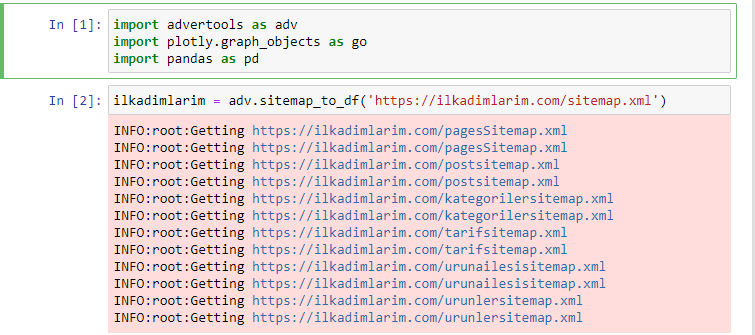
J’aime utiliser Jupyter Notebook au lieu d’un éditeur de code ou d’un IDE.
Dans la première cellule, nous avons importé avec Pandas, Advertools pour la collecte des données et Plotly.graph_objects pour la visualisation.
La commande adv.sitemap_to_df(‘sitemap address’) collecte simplement tous les sitemaps et va les unifier sous forme de DataFrame.
Si vous faites la même chose en utilisant Pandas et Advertools, vous pouvez découvrir quelle URL est disponible dans quel sitemap.
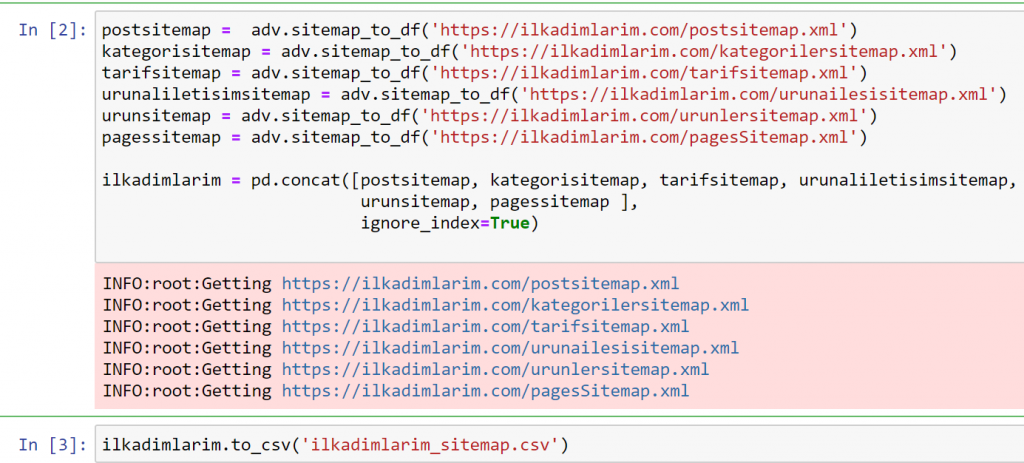
Dans l’exemple ci-dessus, nous avons extrait les mêmes sitemaps séparément, puis nous les avons combinés avec la commande pd.concat et avons transféré le résultat en CSV. L’exemple précédent utilisait le fichier d’index des sitemaps, auquel cas la fonction va chercher tous les autres sitemaps. Vous avez donc la possibilité de sélectionner des sitemaps spécifiques comme nous l’avons fait ici si vous êtes intéressés par une section particulière du site web.
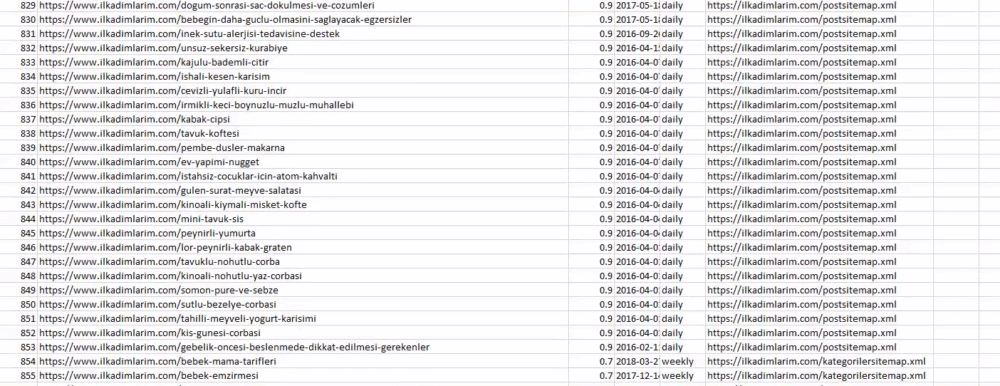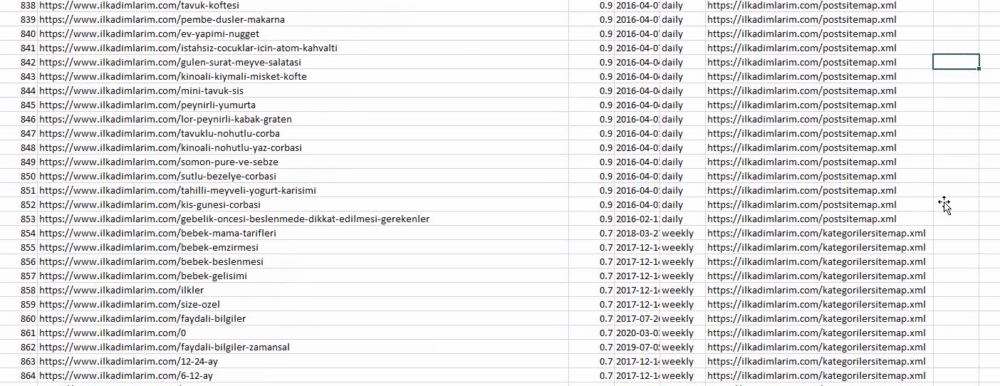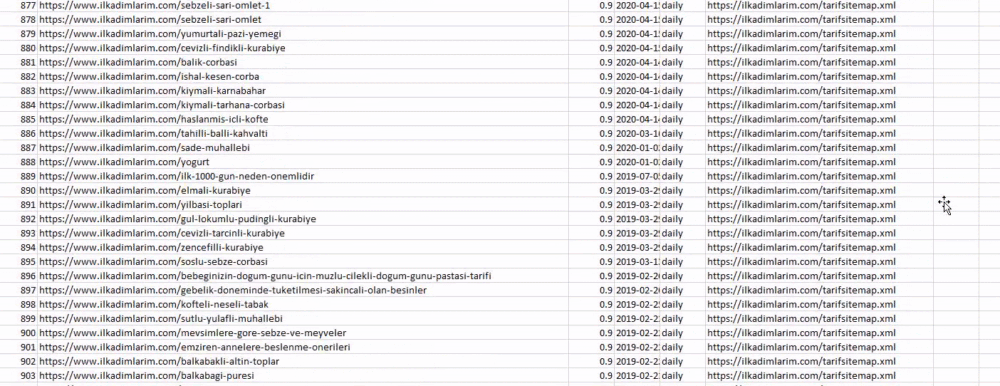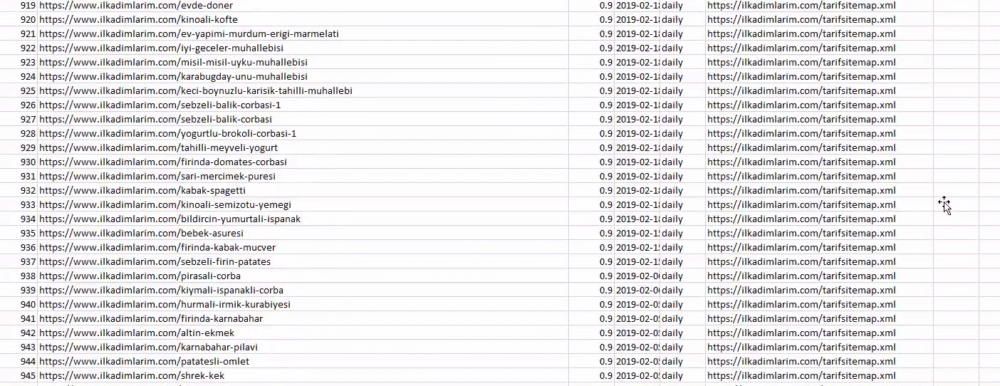
Ci-dessus, nous avons une colonne avec différents noms de sitemaps. La section ignore_index=True sert à ordonner proprement les numéros d’index des différents DataFrames si vous en avez fusionné plusieurs ensemble.
Nettoyage et préparation du cadre des données du sitemap pour l’analyse du contenu avec Python
Pour comprendre le profil du contenu d’un site web à travers un sitemap, nous devons le préparer afin d’examiner le DataFrame que nous avons obtenu avec Advertools.
Nous utiliserons quelques commandes de base de la bibliothèque Pandas pour façonner nos données :
Ilkadimlarim = pd.read_csv(‘ilkadimlarim_sitemap.csv’)
ilkadimlarim = ilkadimlarim.drop(columns = ‘Unnamed: 0’)
ilkadimlarim[‘lastmod’] = pd.to_datetime(ilkadimlarim[‘lastmod’])
ilkadimlarim = ilkadimlarim.set_index(‘lastmod’)
« İlkadımlarım » signifie « mes premiers pas » en turc, et comme vous pouvez l’imaginer, c’est un site pour les bébés, la grossesse et la maternité.
Nous avons réalisé trois opérations avec ces lignes.
- Unnamed : Nous avons retiré une colonne vide nommée 0 du DataFrame. De plus, si vous utilisez « index = False » avec la fonction pd.to_csv(), vous ne verrez pas cette colonne « Unnamed 0 » au début.
- Nous avons converti les données de la colonne « Dernière modification » en « Date et heure ».
- Nous avons amené la colonne « lastmod » à la position d’index.
Vous pouvez voir ci-dessous la version finale du DataFrame.
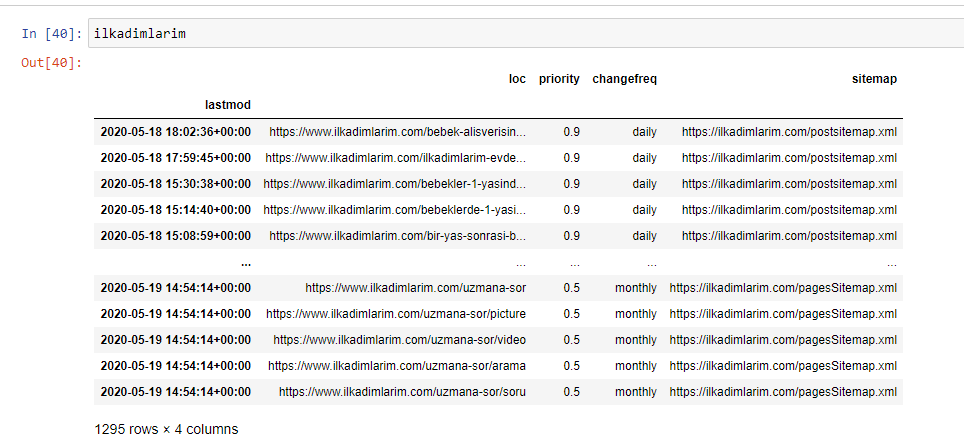
Nous savons que Google n’utilise pas les informations de priorité et de fréquence des sitemaps. Ils appellent cela du « bruit ». Mais si vous accordez de l’importance aux performances de votre site pour les autres moteurs de recherche, vous pouvez trouver utile de les examiner. Personnellement, je ne me soucie pas beaucoup de ces données, mais je n’ai toujours pas besoin de les supprimer du DataFrame.
Nous avons besoin d’une ligne de code supplémentaire pour classer les sitemaps dans une autre colonne.
ilkadimlarim[‘sitemap_cat’] = ilkadimlarim[‘sitemap’].str.split(‘/’).str[3]
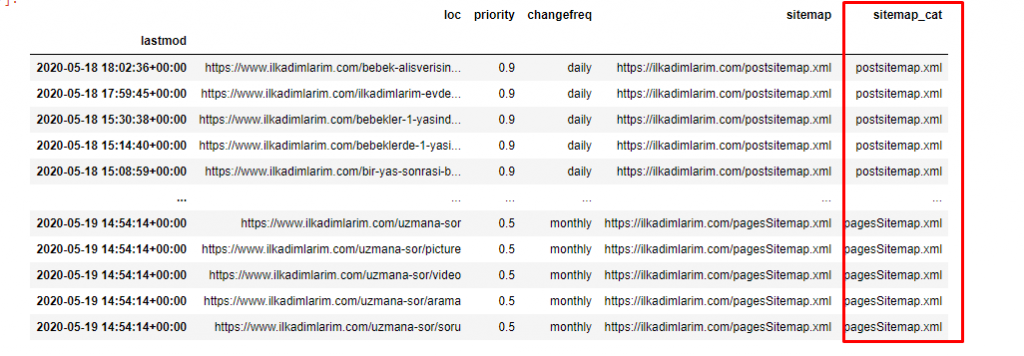
Dans Pandas, vous pouvez ajouter de nouvelles colonnes ou lignes à un DataFrame ou vous pouvez les mettre à jour facilement. Nous avons créé une nouvelle colonne avec un extrait de code DataFrame[‘new_columns’]. DataFrame[‘column_name’].str nous permet d’effectuer différentes opérations en changeant le type de données dans une colonne. Nous divisons les données de la chaîne dans la colonne relative au .split (‘/’) par le caractère / et nous les plaçons dans une liste. Avec .str [number], nous créons le contenu de la nouvelle colonne en sélectionnant un élément particulier dans cette liste.
Analyse du profil de contenu en fonction du nombre et des types
Après avoir placé les sitemaps dans une colonne différente selon leur type, nous pouvons vérifier quel est le pourcentage du contenu de chaque sitemap. Ainsi, nous pouvons également déduire quelle partie du site est la plus importante.
ilkadimlarim[‘sitemap_cat’].value_counts(normalize = True) * 100
- DataFrame[‘column_name’] sélectionne la colonne que nous voulons traiter.
- value_counts() compte la fréquence des valeurs dans la colonne.
- normalize=True prend le rapport des valeurs en décimal.
- Nous le rendons plus facile à lire en augmentant les nombres décimaux avec *100.
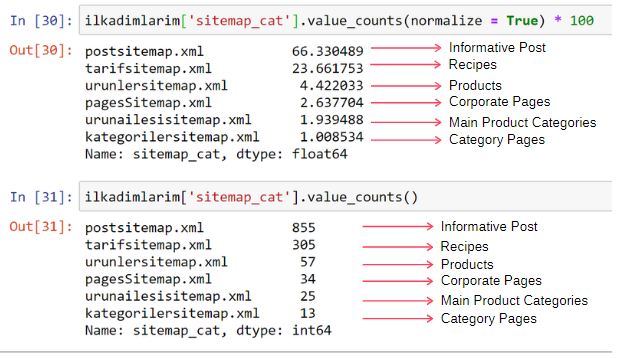
Nous constatons que 65 % du contenu se trouve dans le Post Sitemap et 23 % dans Recipe Sitemap. Le sitemap des produits ne contient que 2 % du contenu.
Cela montre que nous avons un site web qui doit créer du contenu informatif pour un large public afin de commercialiser ses propres produits. Vérifions si notre thèse est correcte. Avant de poursuivre, nous devons changer le nom de la colonne ilkadimlarim[‘sitemap_cat’] en ‘URL_Count’ avec le code ci-dessous :
ilkadimlarim.rename(columns={‘sitemap_cat’ : ‘URL_Count’}, inplace=True)
- La fonction rename() est utile pour modifier le nom de vos colonnes ou index afin de relier les données et leur signification à un niveau plus profond.
- Nous avons changé le nom de la colonne pour qu’il soit permanent grâce à l’attribut « inplace=True ».
- Vous pouvez également modifier le style des lettres de vos colonnes et index avec ilkadimlarim.rename(str.capitalize, axis=’columns’, inplace=True). Cela permet d’écrire uniquement les premières lettres en majuscules de chaque colonne dans İlkadimlarim.

Maintenant, nous pouvons poursuivre.
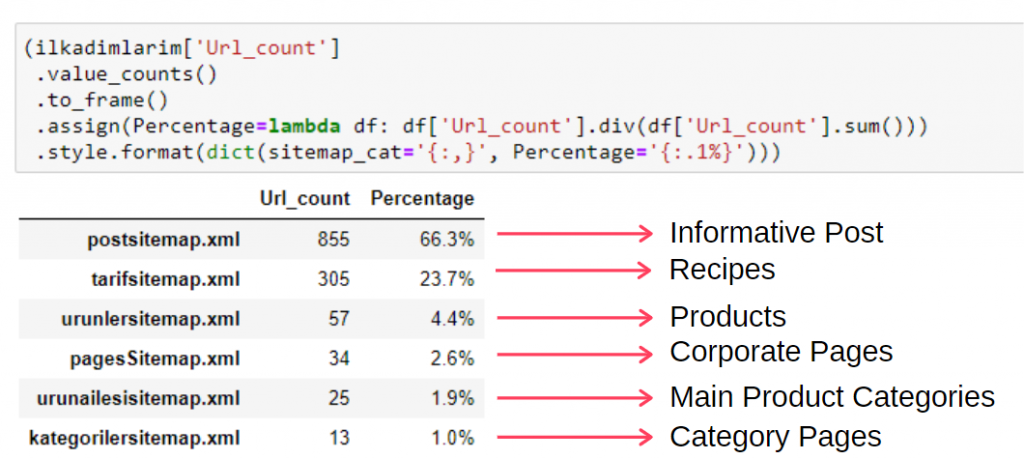
Pour voir ces informations dans un cadre unique, vous pouvez utiliser le code ci-dessous :
(ilkadimlarim[‘sitemap_cat’])
.value_counts()
.to_frame()
.assign(percentage=lambda df : df[‘sitemap_cat’].div(df[‘sitemap_cat’].sum())
.style.format(dict(sitemap_cat='{ :,}’, percentage='{ :.1%}’))
- to_frame() est utilisé pour encadrer les valeurs mesurées par value_counts() dans la colonne sélectionnée.
- assign() est utilisé pour ajouter certaines valeurs au cadre.
- lambda fait référence aux fonctions anonymes en Python.
- Ici, les types de fonction Lambda et de sitemap sont divisés par le nombre total de sitemaps par la méthode div() de Pandas.
- style() détermine comment les valeurs finales spécifiées sont écrites.
- Ici, nous définissons combien de chiffres sont écrits après le point avec la méthode format().
Examination des tendances de publication de contenu par année
Nous avons fait correspondre le contenu et l’intention du site web examiné selon les catégories du sitemap, mais nous n’avons pas encore procédé à une classification basée sur le temps. Nous utiliserons la méthode resample() pour y parvenir.
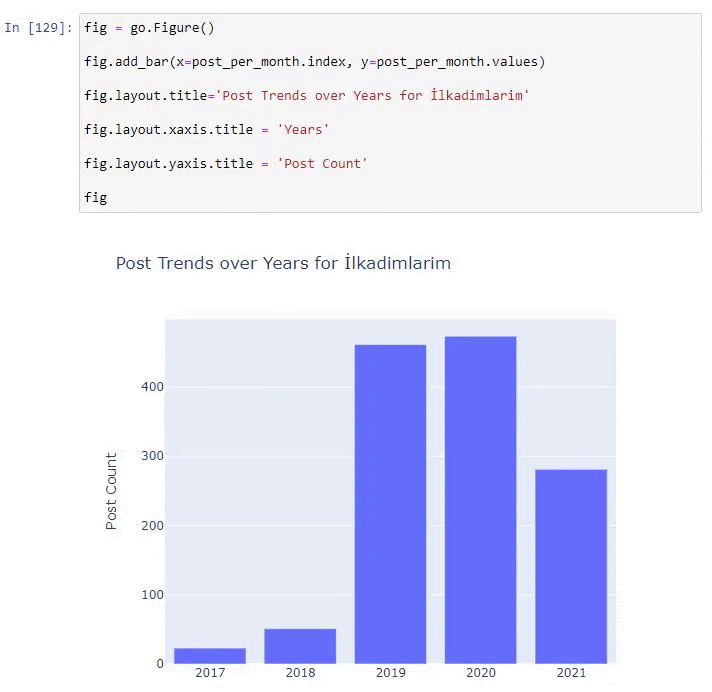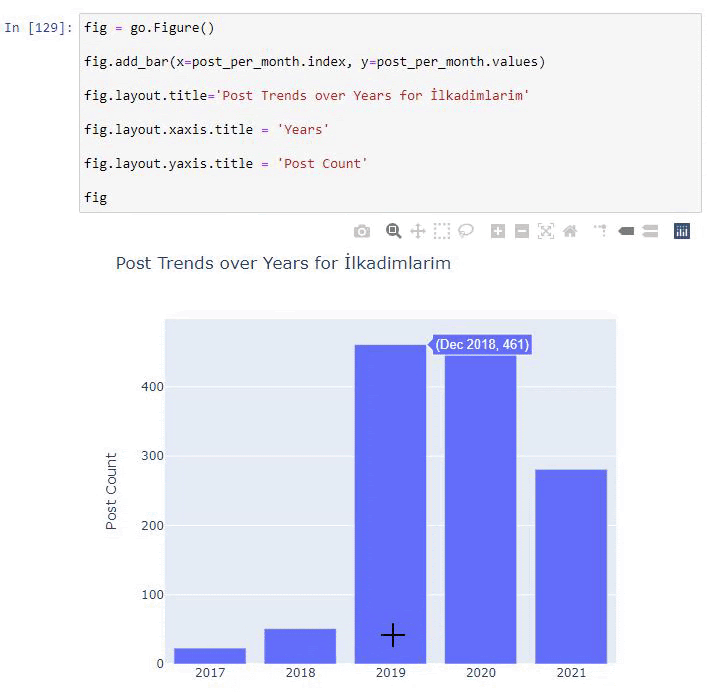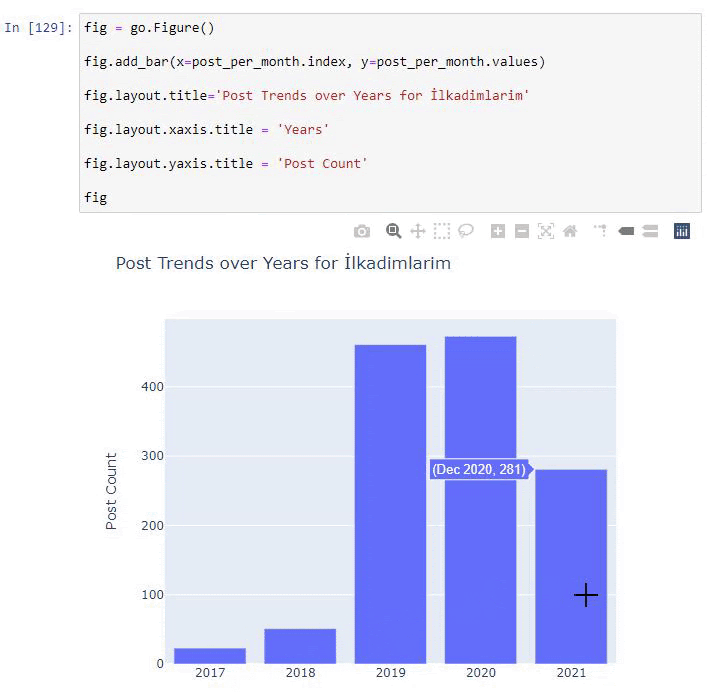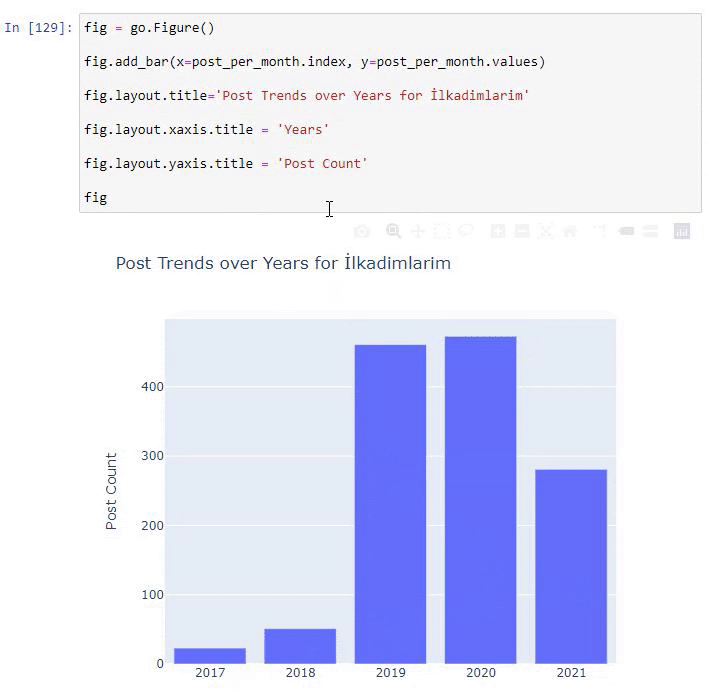
post_per_month = ilkadimlarim.resample(‘A’)[‘loc’].count()
post_per_month.to_frame()
Resample est une méthode de la bibliothèque Pandas. resample(‘A’) vérifie les séries de données pour une DataFrame annuelle. Pour les semaines, vous pouvez utiliser « W« , pour les mois, vous pouvez utiliser « M« .
Loc symbolise ici l’index ; count signifie que vous voulez compter la somme des exemples de données.
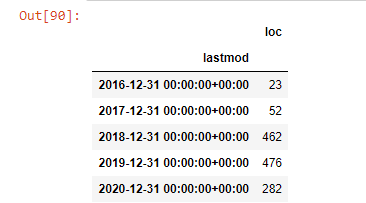
Nous voyons qu’ils ont commencé à publier des articles en 2016 mais leur principale tendance de publication a augmenté après 2017. Nous pouvons également mettre cela dans un graphique à l’aide de Plotly Graph Objects.
Explication de cet extrait de code du Plotly Bar Plot :
- fig = go.Figure() sert à créer une figure.
- fig.add_bar() est pour ajouter un barplot dans la figure. Nous déterminons également quels seront les axes X et Y entre les parenthèses.
- Fig.layout sert à créer un titre général pour la figure et les axes.
- À la dernière ligne, nous appelons le tracé que nous avons créé avec la commande fig qui est go.Figure()
Ci-dessous, vous trouverez les mêmes données par mois, avec un nuage de points et un diagramme à barres :
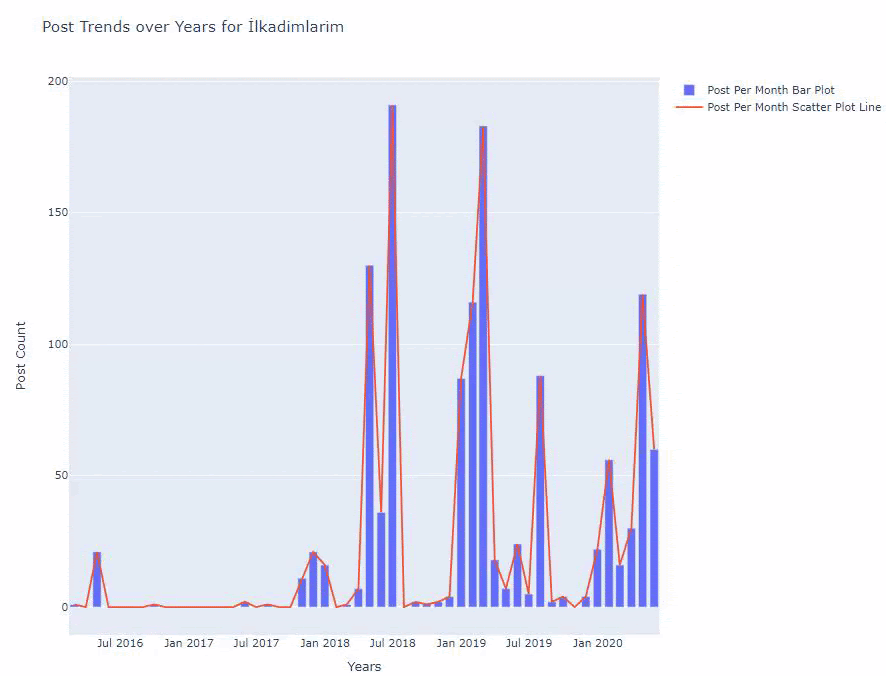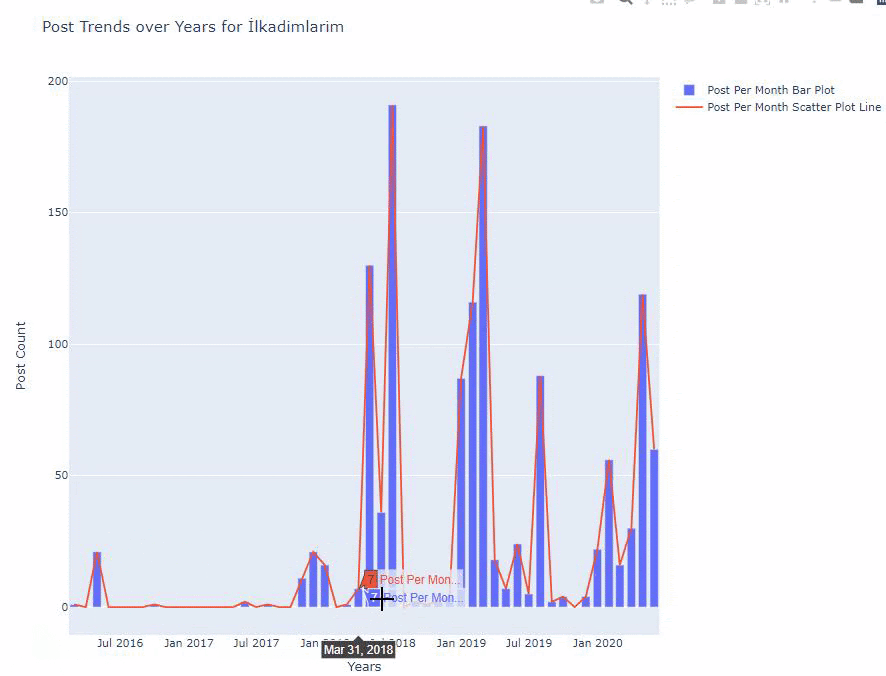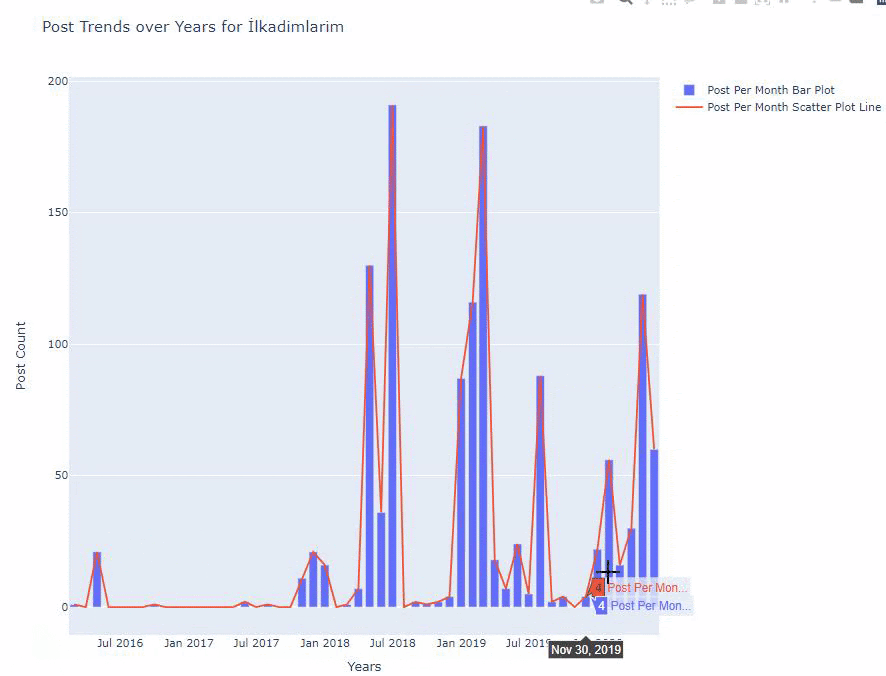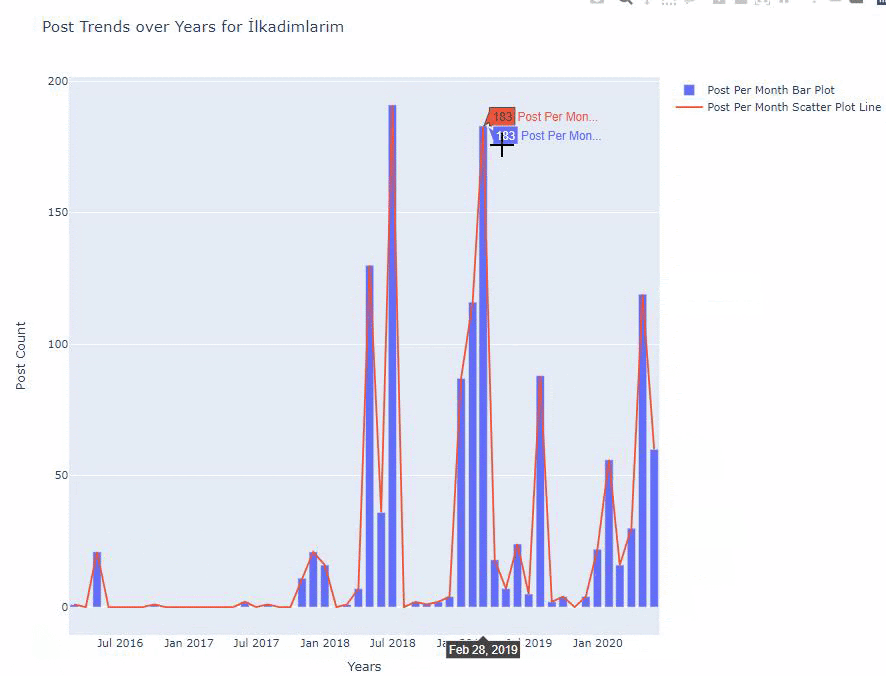
Voici les codes permettant de créer cette figure :
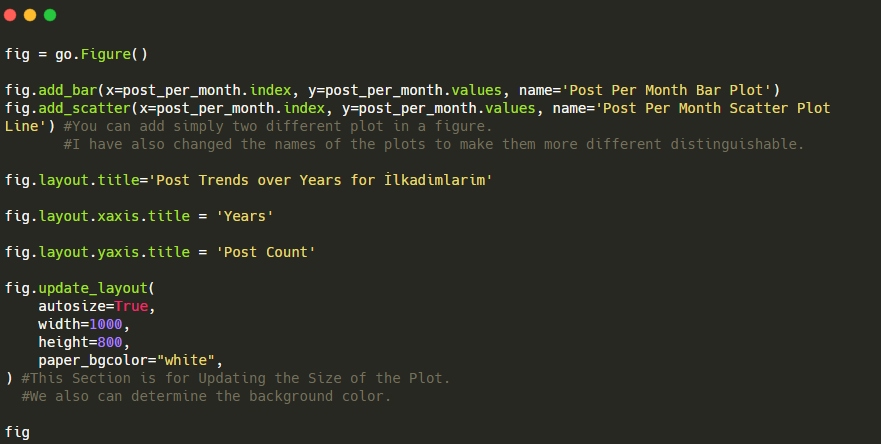
Nous avons ajouté une deuxième parcelle avec fig.add_scatter(), et nous avons également changé les noms en utilisant l’attribut name. fig.update_layout() qui sert à changer la taille et la couleur de fond de la parcelle.
Vous pouvez également modifier le mode de survol, la distance entre les barres, et plus encore. Je pense qu’il est suffisant de ne partager que les codes, car expliquer chaque code séparément ici peut nous éloigner du sujet principal.
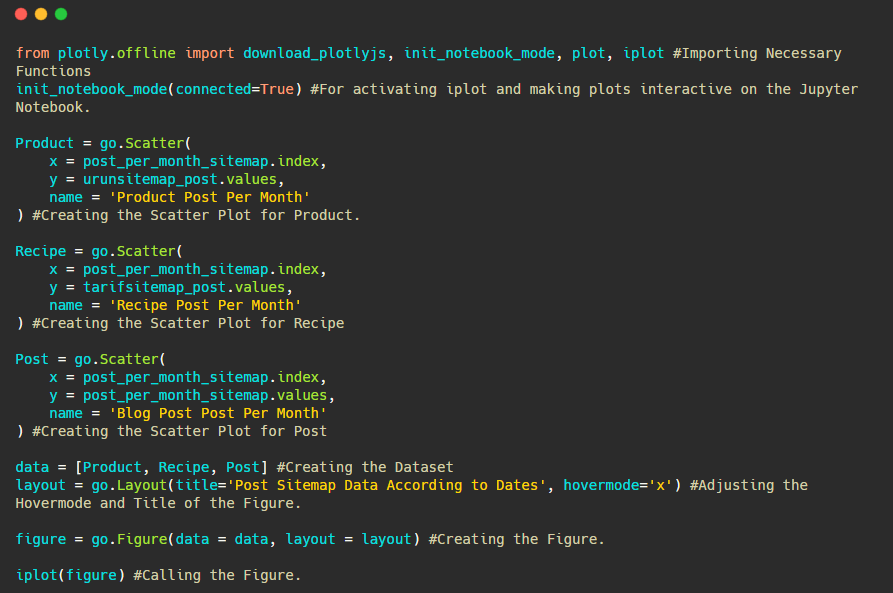
Nous pouvons également comparer les tendances des concurrents en matière de publication de contenu en fonction des catégories comme ci-dessous.
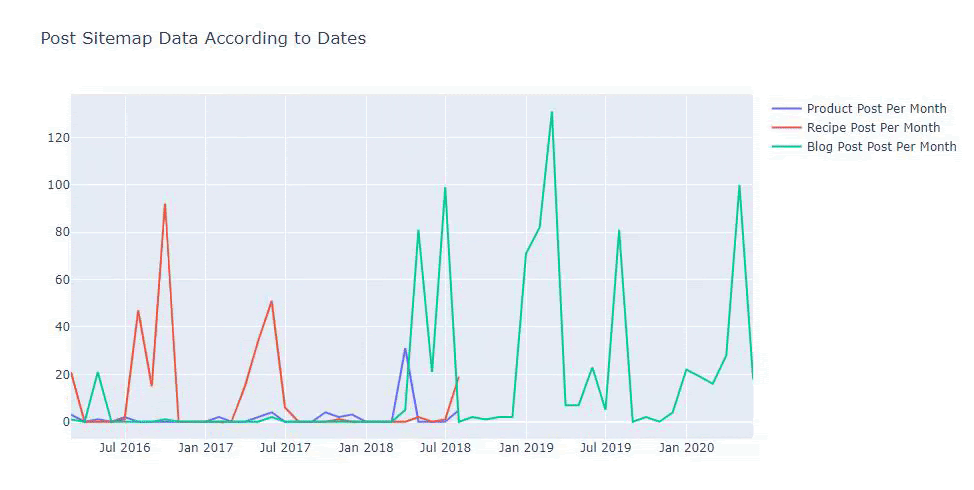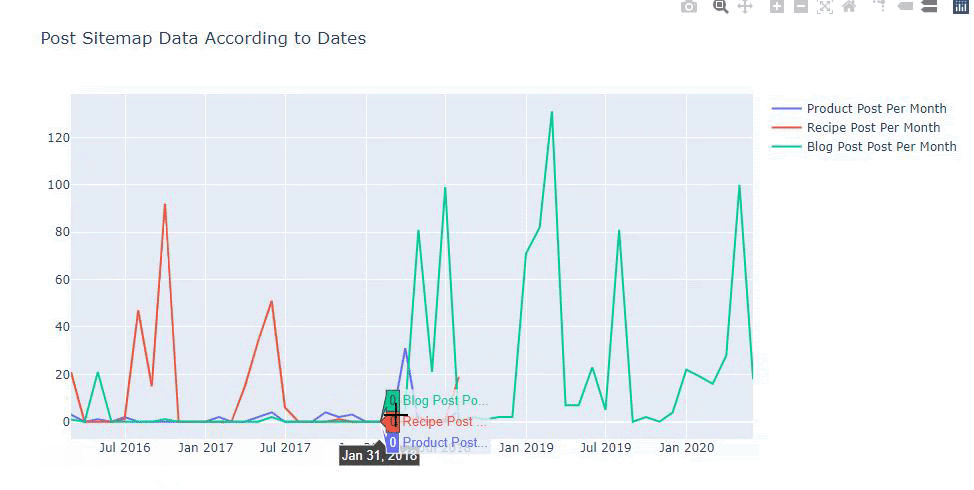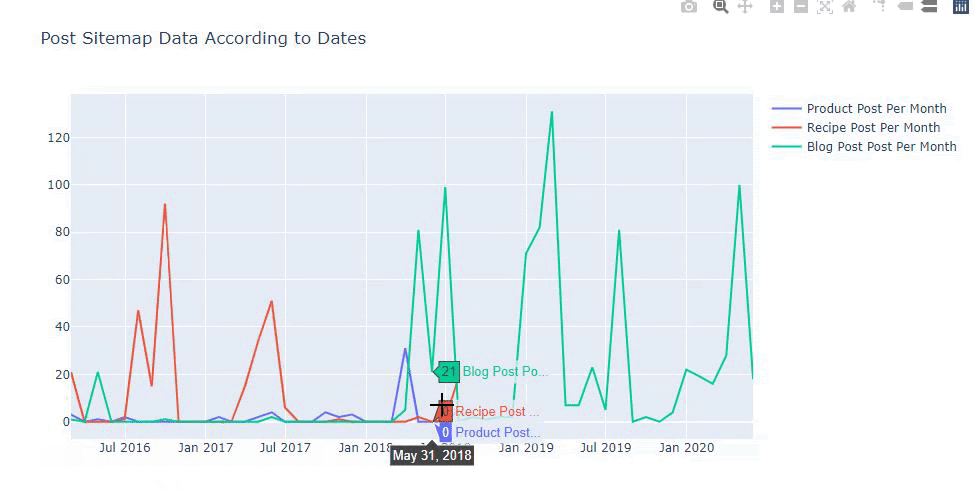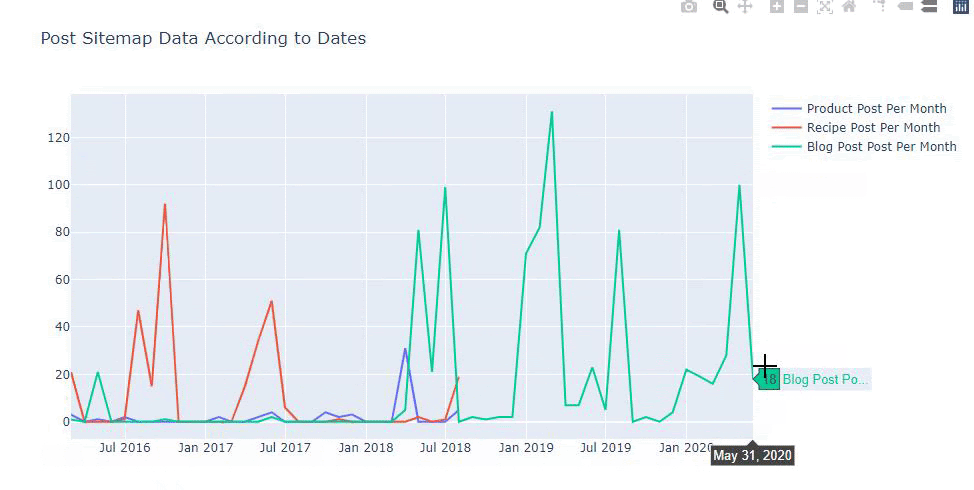
Ce tableau a été créé avec la deuxième méthode, comme vous pouvez le voir, il n’y a pas de différence mais l’une d’entre elles est assez simple.
Afin de déterminer la fréquence et la tendance de la publication de contenu à partir de trois sitemaps distincts, nous devons placer le sitemap qui présente l’intervalle le plus long sur l’axe X. Ainsi, nous pouvons comparer la fréquence à laquelle le site web que nous examinons publie chaque type de contenu pour différentes intentions de recherche.
Lorsque vous examinerez les codes pertinents ci-dessous, vous verrez qu’ils ne sont pas très différents de ceux mentionnés ci-dessus.
Pour créer un diagramme de dispersion avec plusieurs axes Y, vous pouvez utiliser le code ci-dessous.

Il existe d’autres méthodes telles que l’unification de différents sitemaps et l’utilisation d’une boucle pour les colonnes afin d’utiliser plusieurs axes Y dans le diagramme de dispersion, mais pour un site aussi petit, nous n’en avons pas besoin. Dans la plupart des cas, il serait plus logique d’utiliser cette méthode sur des sites web comportant des centaines de sitemaps.
De plus, comme le site est petit, le graphique peut sembler peu profond, mais comme vous le verrez plus loin dans l’article sur un site web avec des millions d’URLs, de tels graphiques sont un excellent moyen de comparer différents sites ainsi que de comparer différentes catégories d’un même site web.
Examination des catégories de contenu, de l’intention et des tendances de publication
Dans cette section, nous allons vérifier qu’ils ont écrit un grand nombre de contenus dans un domaine spécifique pour commercialiser un petit nombre de produits, comme mentionné au début de l’article. Grâce à cela, nous pourrons voir s’ils ont un partenariat de contenu avec d’autres marques ou non.
Pour présenter ce que l’on peut trouver d’autre sur les sitemaps, nous allons continuer à creuser. Nous pouvons également obtenir certaines informations dans la partie « loc » du sitemap.
Il n’y a pas de ventilation par catégorie dans les URLs de İlkadımlarım. Si un site web a une ventilation par catégorie dans ses URLs, nous pouvons en apprendre beaucoup plus sur la distribution du contenu. Sinon, nous pouvons accéder aux mêmes données en écrivant un code supplémentaire, mais avec moins de certitude.
a = ilkadimlarim[‘loc’].str.contains(« bebek|hamile|haftalik »)
Bebek : bébé
Hamile : enceinte
Haftalik : hebdomadaire ou « semaines de grossesse ».
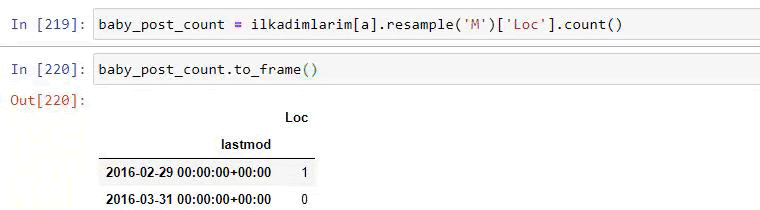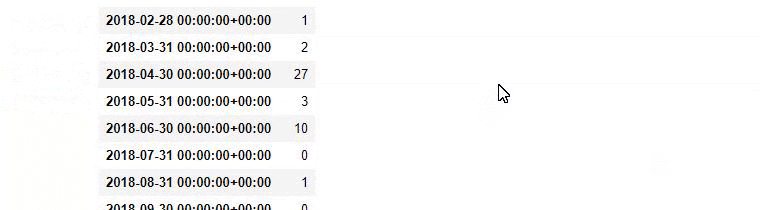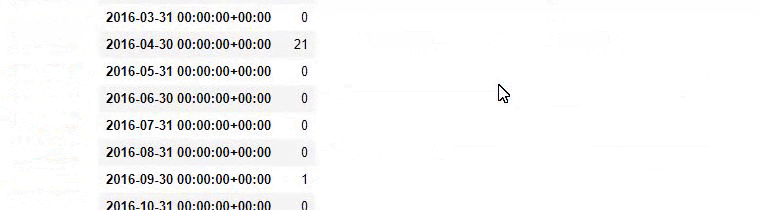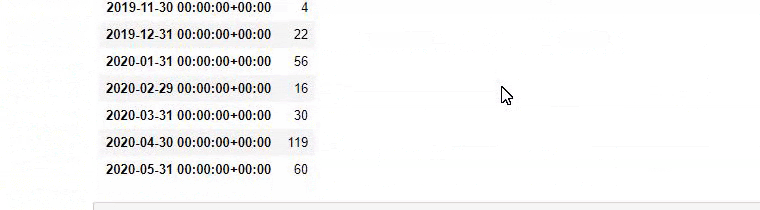
baby_post_count = ilkadimlarim[a].resample(‘M’)[‘loc’].count()
baby_post_count.to_frame()
- La méthode str() nous permet ici aussi de définir la colonne dans laquelle nous sélectionnons certaines opérations.
- Avec la méthode contains(), nous déterminons les données pour vérifier si elles sont incluses dans les données converties en une chaîne de caractères.
- Ici, « | » entre les termes signifie « ou« .
- Ensuite, nous attribuons les données que nous avons filtrées à une variable et utilisons la méthode resample() que nous avons utilisée précédemment.
- La méthode count, quant à elle, mesure quelles données sont utilisées et combien de fois.
- Le résultat obtenu avec count() est à nouveau joint à la méthode to_frame().
- En outre, str.contains() prend les valeurs Regex par défaut, ce qui signifie que vous pouvez créer des conditions de filtrage plus compliquées avec moins de code.
En d’autres termes et à ce stade, nous attribuons les URLs contenant les mots « baby », « weekly », « pregnant » à une variable dans ilkadimlarim, puis nous mettons la date de publication des URLs dans les conditions appropriées pour le filtre que nous avons créé.
Nous faisons ensuite la même chose pour les URLs contenant le mot « aptamil ». Aptamil est le nom d’un produit nutritionnel pour bébé lancé par İlkadımlarım. Par conséquent, nous pouvons également prêter attention à la densité de diffusion du contenu informatif et commercial.
Et vous pouvez voir les deux groupes de contenu différents publier des calendriers au fil des années pour des intentions de recherche différentes avec plus de certitude et des informations précises à partir des URLs.
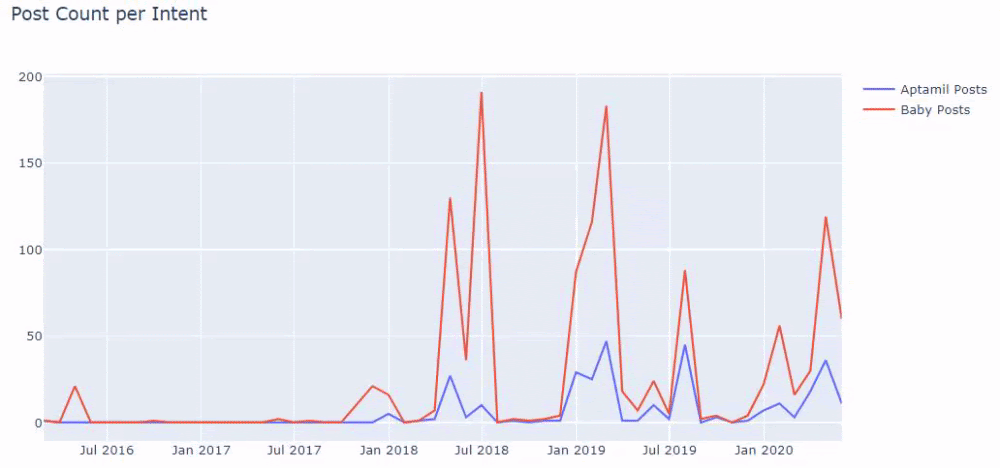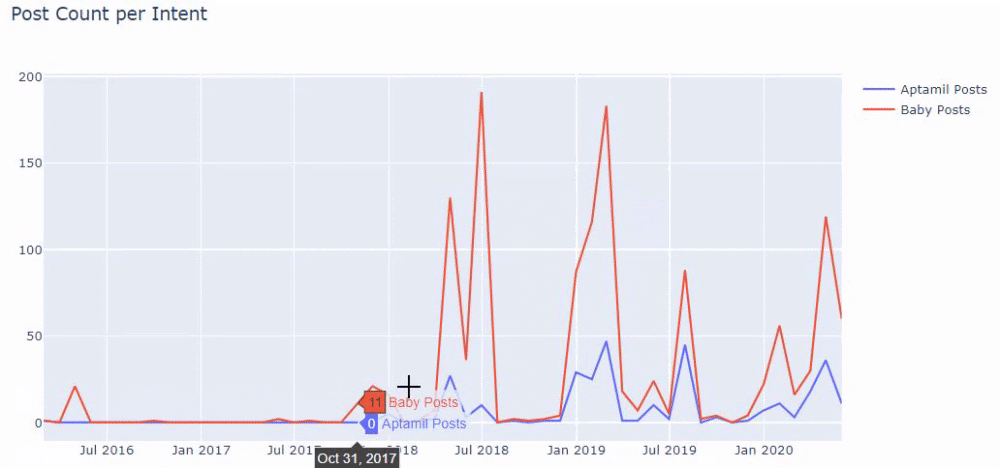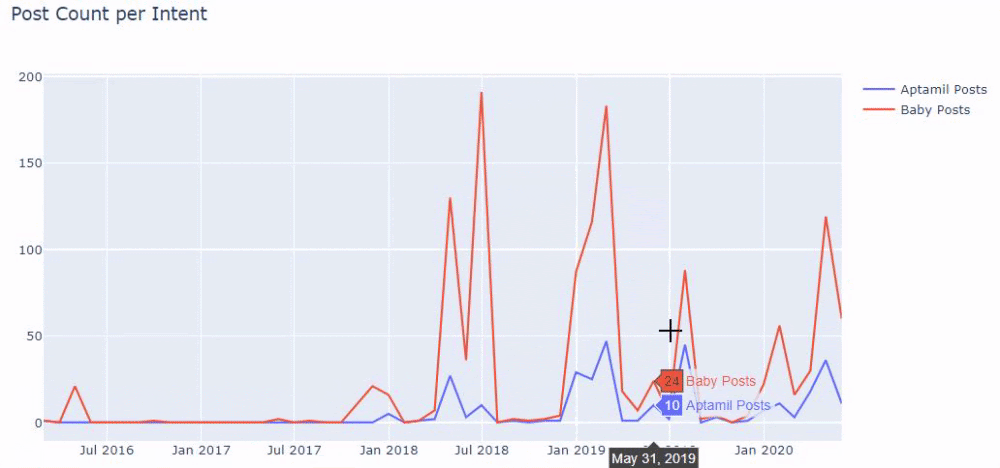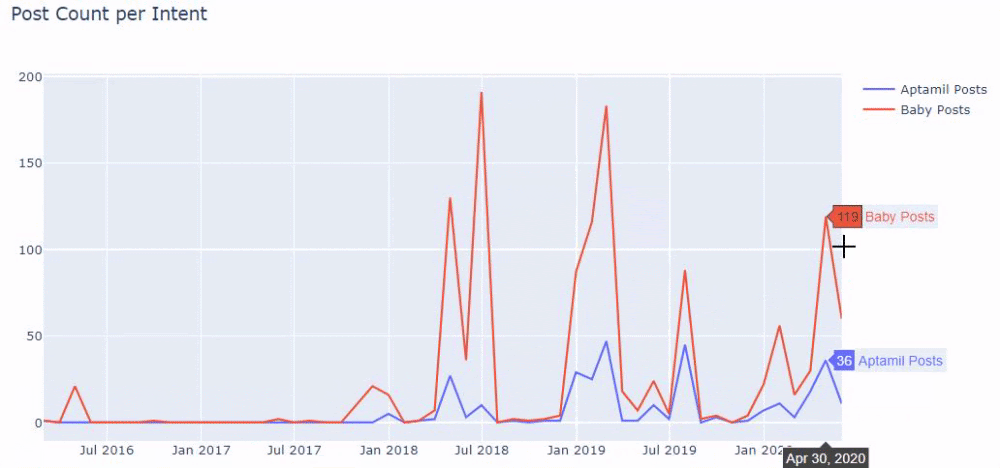
Le code pour produire ce tableau n’a pas été partagé car il est le même que celui utilisé pour le tableau précédent
Avec l’aide des opérateurs de recherche Google, j’obtiens 38 résultats pour les pages où le mot Aptamil est utilisé dans le texte d’ancrage sur İlkadimlarim.com. Un nombre important de ces pages sont informatives et renvoient à des contenus commerciaux.
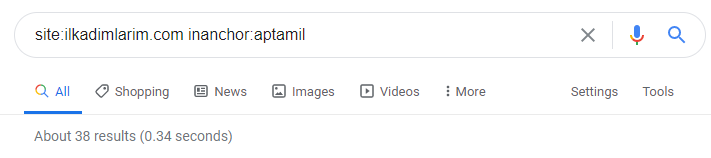
Notre thèse a fait ses preuves.
« Mes premiers pas » utilise des centaines de contenus informatifs sur la maternité, les soins aux bébés et la grossesse pour atteindre son public cible. « İlkadımlarım » relie les pages contenant les produits Aptamil à partir de ce contenu et y dirige les utilisateurs.
Comparatif des profils de contenu et analyse de la stratégie de contenu via des sitemaps en Python
Faisons maintenant la même chose pour une entreprise du même secteur et faisons une comparaison pour comprendre les différences de stratégie entre ces deux marques.
Comme deuxième exemple, j’ai choisi Prima.com.tr, ou Pampers, mais qui utilise la marque Prima en Turquie. Comme Prima a un sitemap unique, nous ne pourrons pas faire de classement par sitemap, mais au moins ils ont des coupures différentes dans leurs URL. Nous avons donc beaucoup de chance !
Imaginez combien cela coûte à Google si votre site est difficile à comprendre et à lire ! Cela peut vous aider à rendre le calcul du coût de crawl plus juste, ne serait-ce qu’en ce qui concerne la structure de l’URL.
Afin de ne pas augmenter davantage le volume de l’article, nous ne plaçons pas les codes des processus qui sont similaires à ceux que nous avons déjà fait.
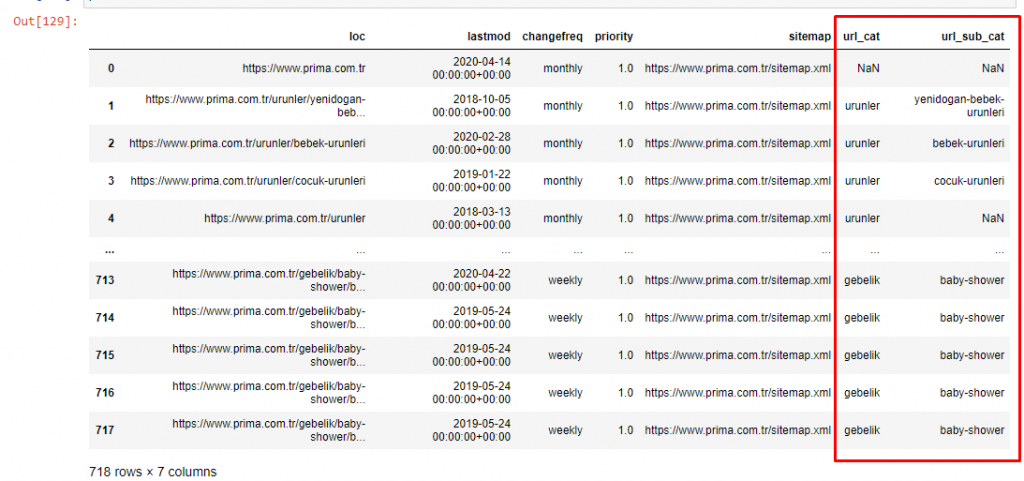
Nous pouvons maintenant examiner leur répartition par catégories d’URL et sous-catégories d’URL. Nous constatons qu’ils ont une quantité excessive de pages web d’entreprise. Ces pages web sont placées dans la section « prima-hakkinda » (« À propos de Prima »). Mais quand je les vérifie avec Python, je vois qu’ils ont unifié leurs produits et leurs pages web d’entreprise dans une seule catégorie. Vous pouvez voir la répartition de leur contenu ci-dessous :

Nous pouvons faire de même pour les sous-catégories suivantes.
Il est intéressant de noter que Prima utilise « gebelik » (grossesse en turc) qui est une variante de « hamilelik » (grossesse en arabe), et que les deux signifient « période de grossesse ».

Nous constatons maintenant une catégorisation plus poussée de leur contenu. 9,2 % du contenu concerne la grossesse saine, 7,3 % le processus de croissance des bébés, 8,3 % les activités qui peuvent être faites avec les bébés, 0,7 % l’ordre de sommeil des bébés. Il y a même des sujets comme la dentition avec 3,9 %, la sécurité des bébés avec 1,9 % et la révélation d’une grossesse à la famille avec 1,4 %. Comme vous pouvez le voir, vous pouvez faire connaissance avec un secteur d’activité avec seulement les URLs et leur pourcentage de distribution.
Ce n’est pas la catégorisation parfaite, mais au moins nous pouvons voir l’état d’esprit et les tendances du marketing de contenu de nos concurrents, et le contenu de leur site web par catégories. Vérifions maintenant la fréquence de publication du contenu par mois.
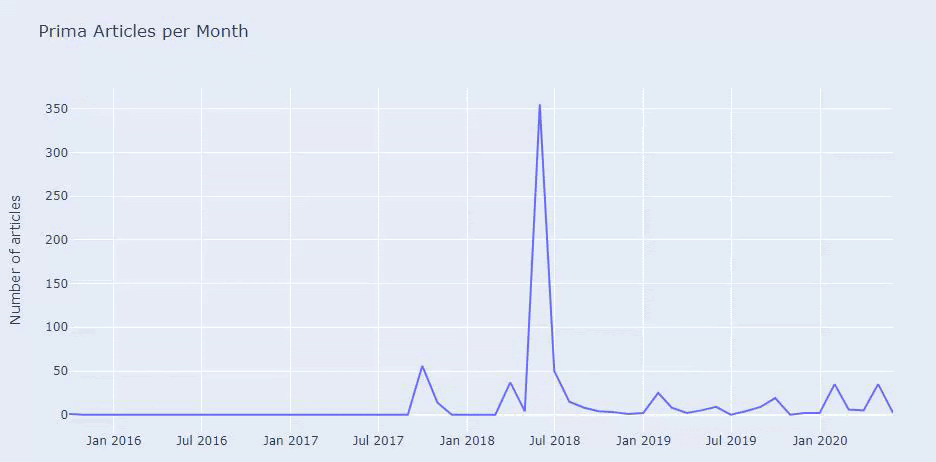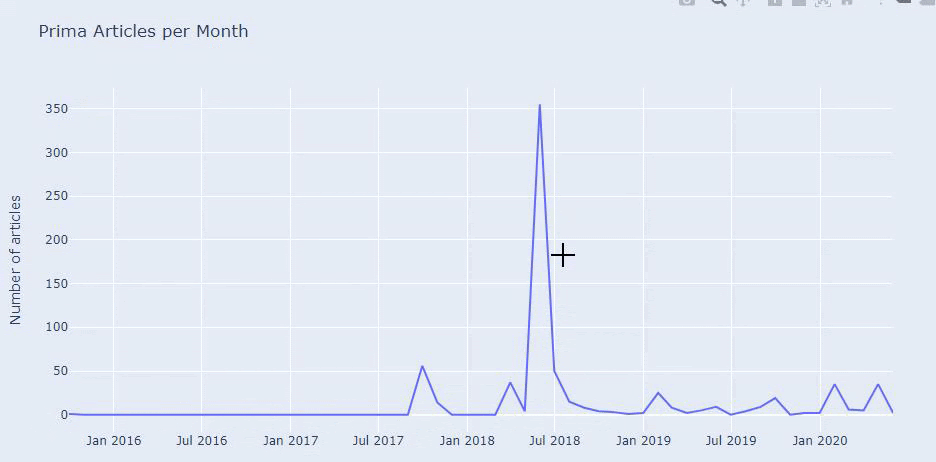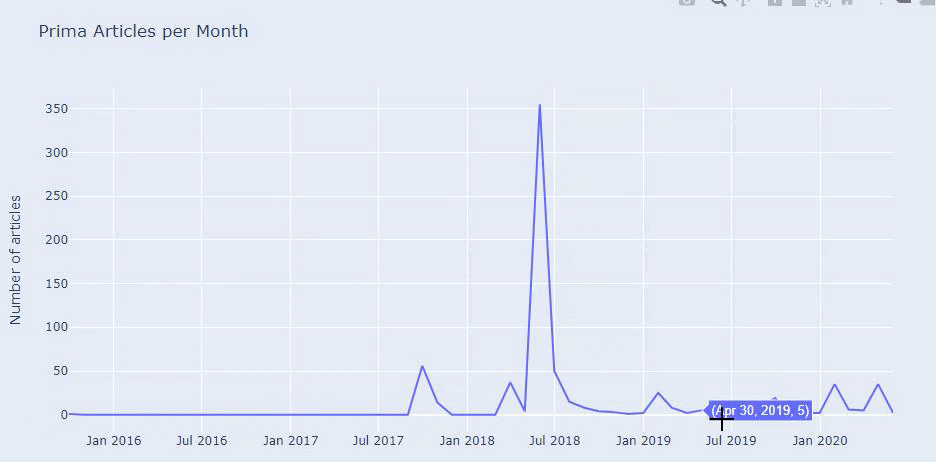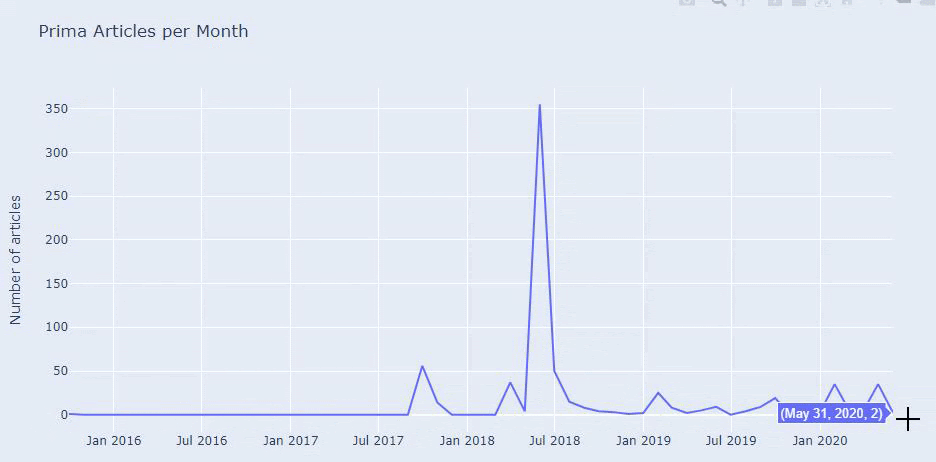
Nous constatons qu’ils ont publié 355 articles en juillet 2018 et selon le sitemap, leur contenu n’a pas été actualisé depuis. Nous pouvons également comparer les tendances de publication de leur contenu selon les catégories au fil des années. Comme vous pouvez le voir, leur contenu se situe principalement dans quatre catégories différentes et la plupart d’entre eux sont publiés le même mois.
Avant de poursuivre, je dois dire que les données du sitemap ne sont pas toujours correctes. Par exemple, les données de Lastmod peuvent avoir été mises à jour pour toutes les URLs parce qu’elles ont renouvelé tous les sitemaps à cette date. Pour contourner ce problème, nous pouvons également vérifier qu’ils n’ont pas modifié leur contenu en utilisant une machine à remonter dans le temps.
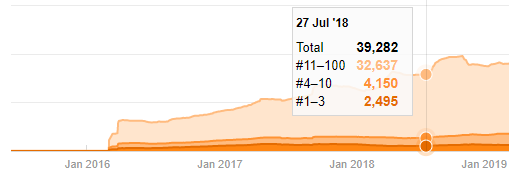
Même si elles semblent suspectes, ces données peuvent être réelles. De nombreuses entreprises en Turquie ont tendance à donner un grand nombre de commandes et à publier un contenu pendant un instant avant. Lorsque je vérifie leur nombre de mots-clés, je constate un saut dans ce laps de temps. Donc, si vous effectuez une analyse comparative du profil de contenu et de la stratégie, vous devez également réfléchir à ces questions.
Voici une comparaison entre les tendances de publication de contenu de chaque catégorie sur plusieurs années pour Prima.com.tr
Nous pouvons maintenant comparer les catégories de contenu des deux sites et leurs tendances en matière de publication.
Lorsque nous examinons la fréquence de publication d’articles sur la croissance des bébés, la grossesse et la maternité par Prima, nous constatons une similitude avec le site İlkadımlarım :
- La plupart des articles ont été publiés à une certaine époque.
- Ils n’avaient pas été mis à jour depuis longtemps.
- Le nombre de produits et de pages était très faible par rapport au nombre de pages de contenu informatif.
- Ils viennent d’ajouter récemment de nouveaux produits sur leurs sites.
Nous pouvons considérer que ces quatre caractéristiques sont l’état d’esprit par défaut du secteur d’activité et nous pouvons utiliser ces faiblesses en faveur de notre campagne. Après tout, la qualité exige de la fraîcheur.
À ce stade, nous constatons également que le secteur d’activité n’est pas familier avec le comportement du Googlebot. Au lieu de télécharger 250 contenus en une journée et de ne faire aucun changement pendant un an, il vaut mieux ajouter périodiquement de nouveaux contenus et
mettre à jour les anciens régulièrement. Ainsi, vous pourrez maintenir la qualité du contenu, le Googlebot pourra comprendre votre site plus facilement et vos valeurs de fréquence en terme de crawl seront plus élevées que celles de vos concurrents.
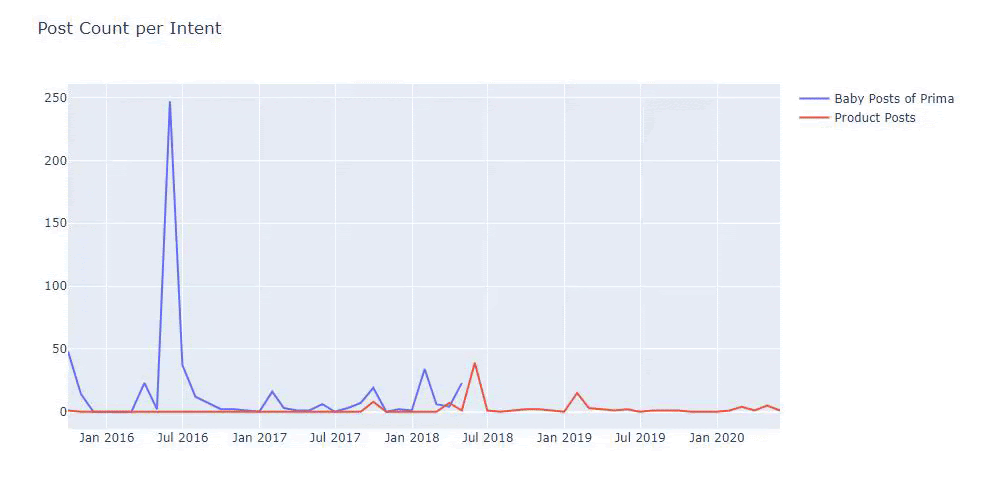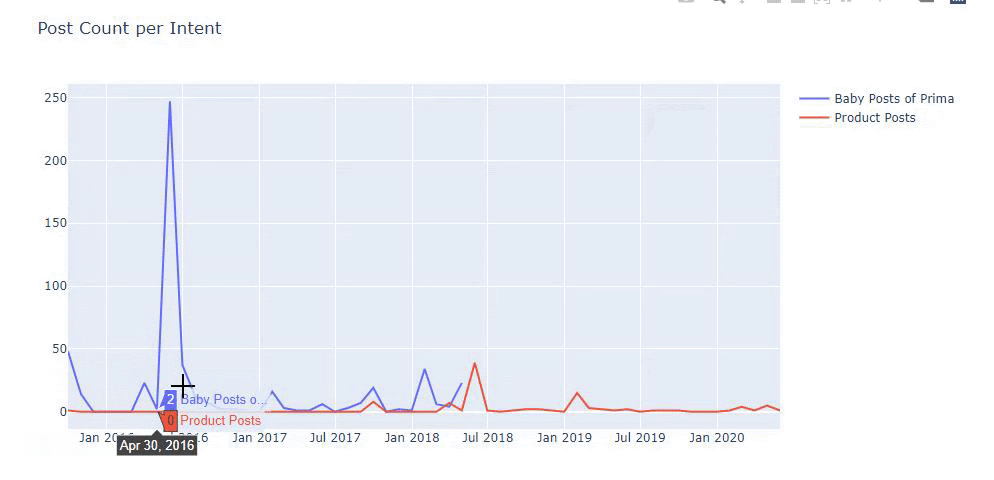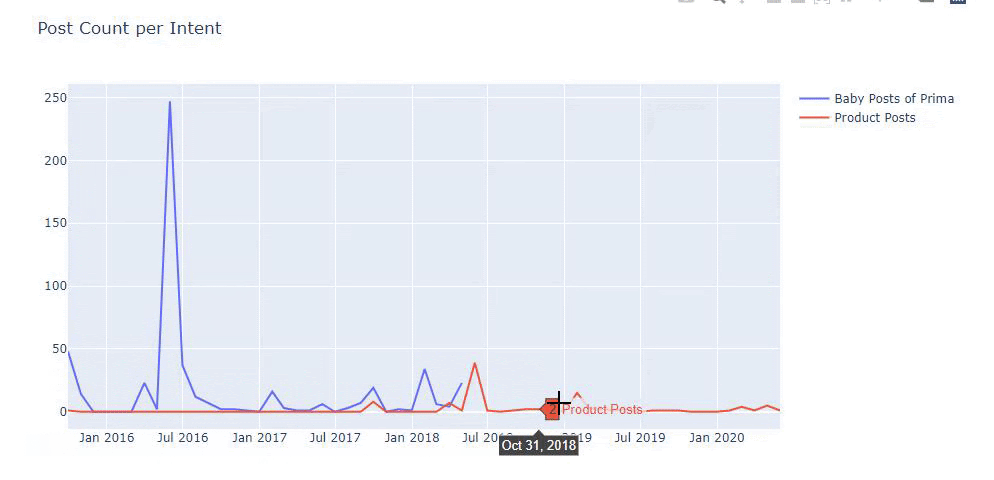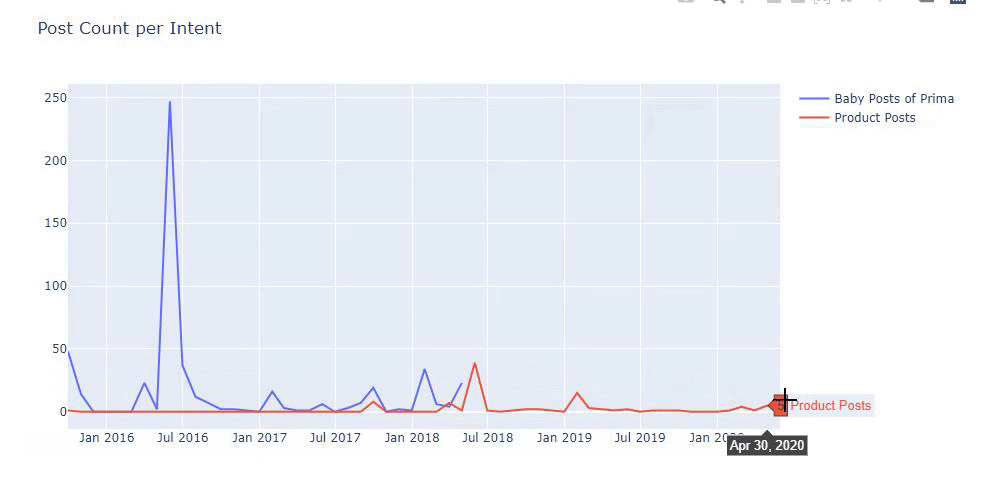
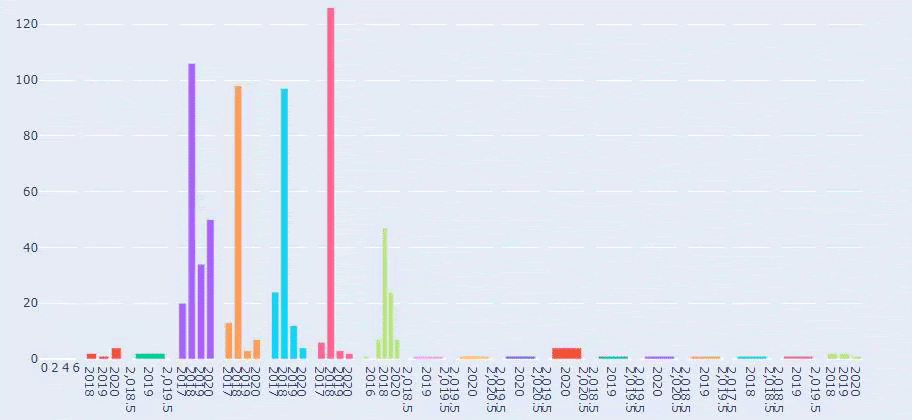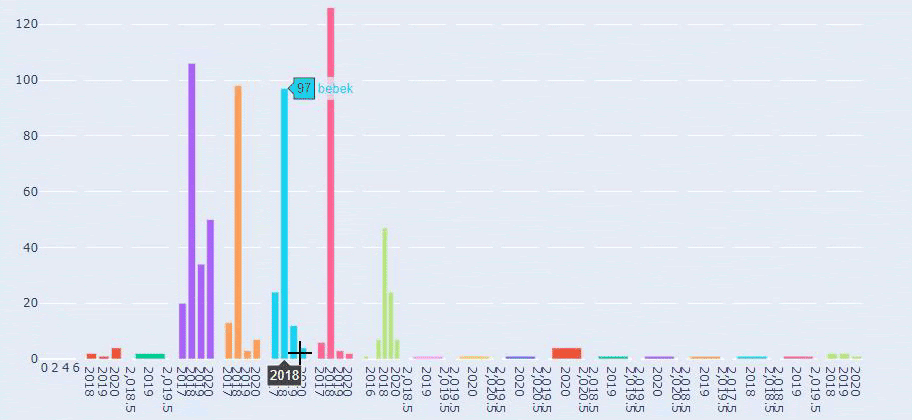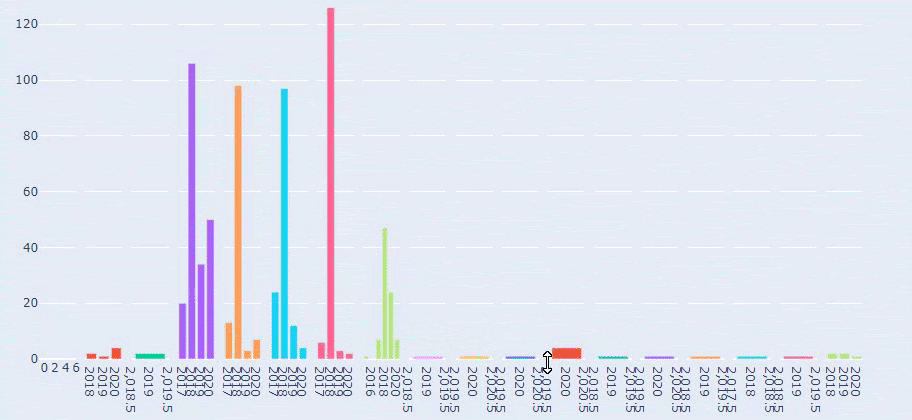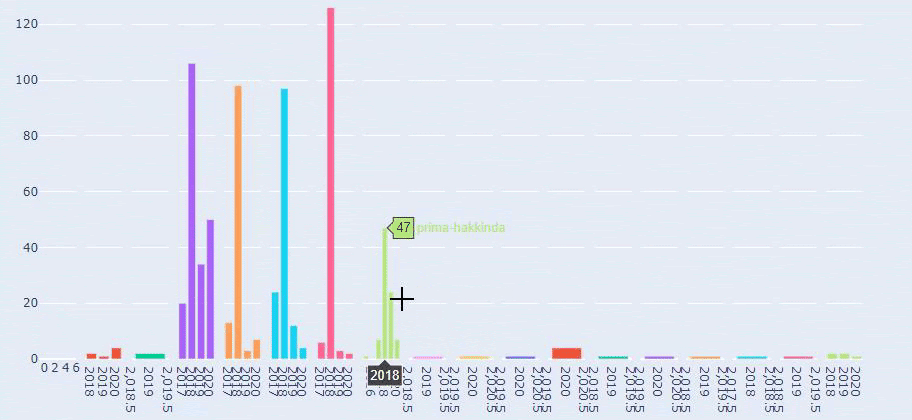
J’ai utilisé les méthodes précédentes pour distinguer les pages produits des pages de contenu informatif et j’ai profilé les mots les plus utilisés dans les URLs. Les Baby Posts signifient ici qu’il s’agit de contenu informatif.
Comme vous pouvez le constater, ils ont ajouté 247 contenus en une seule journée. En outre, ils n’ont pas publié ni actualisé de contenu informatif pendant plus d’un an, et ils ajoutent juste de temps en temps de nouvelles pages de produits.
Comparons maintenant leurs tendances de publication en un seul chiffre mais avec deux tracés différents. J’ai utilisé les codes ci-dessous pour créer cette figure :
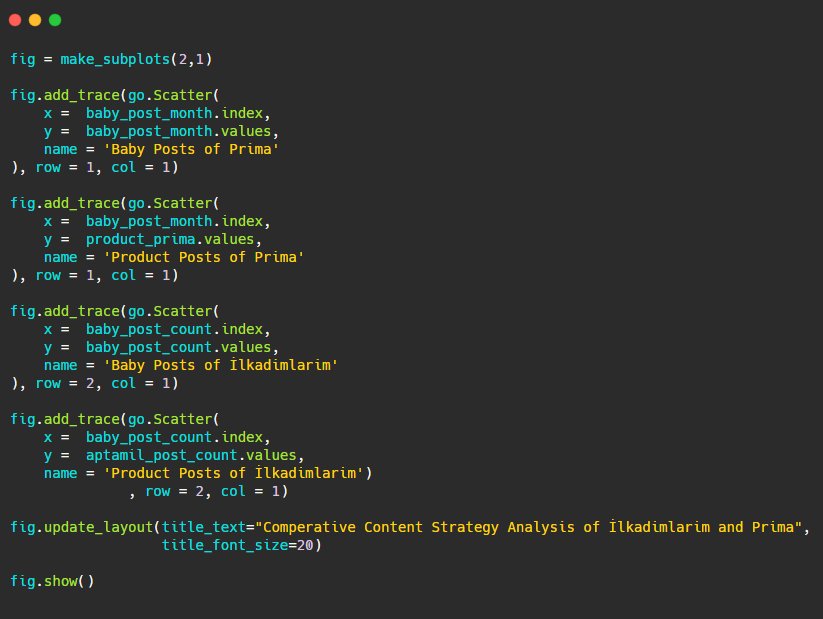
Comme ce graphique est différent des précédents, je voulais vous montrer le code. Ici, deux parcelles séparées sont placées dans la même figure. Pour cela, la méthode make_subplots a été appelée avec la commande de plotly.subplots import make_subplots.
Elle a été créée sous la forme d’une figure à deux lignes et une colonne avec make_subplots (2,1).
Par conséquent, col et row sont écrits à la fin des traces et leurs positions sont spécifiées. C’est un système que toute personne familière avec le système de grille en CSS peut facilement reconnaître.
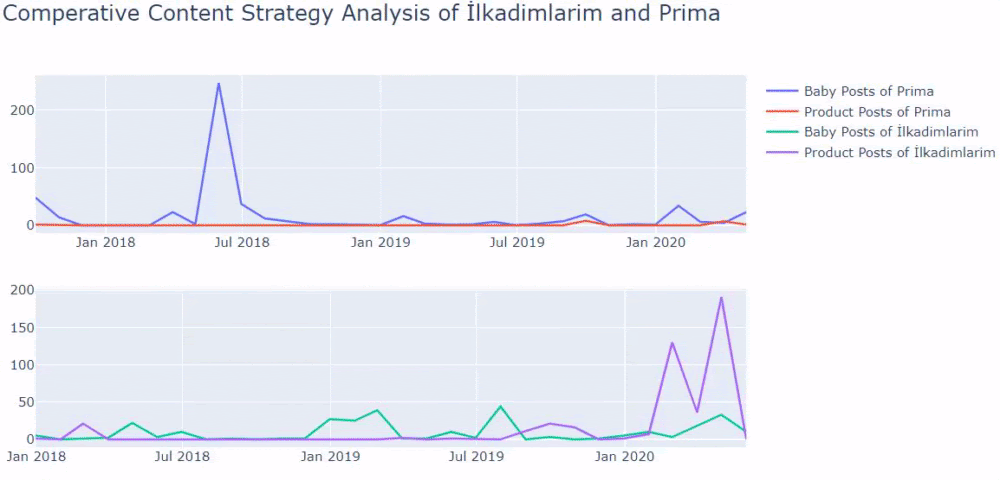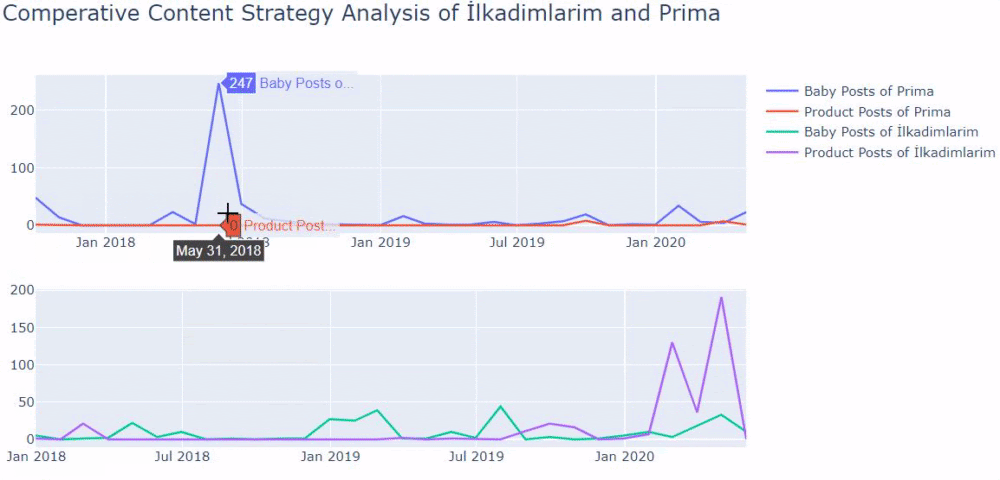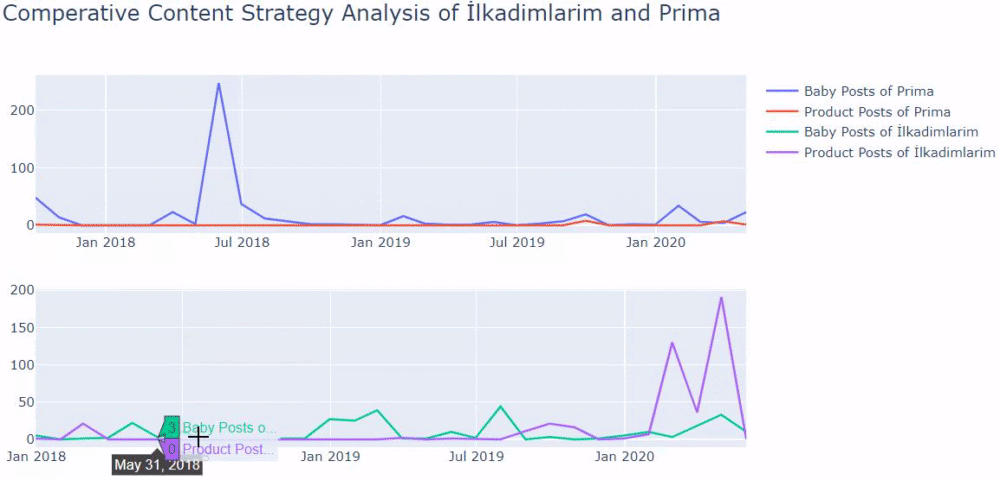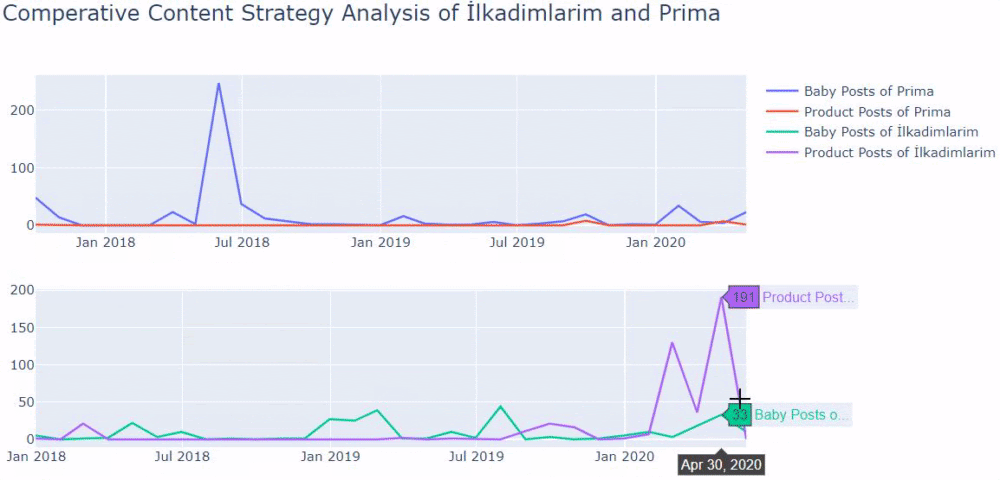
Si vous avez un client dans le même secteur, vous pouvez utiliser ces données pour créer une stratégie de contenu, pour voir les faiblesses de vos concurrents et leur réseau de pages d’interrogation/landing sur les SERP. Vous pouvez également comprendre quelle quantité de contenu vous devez publier dans le même domaine de connaissance ou pour la même intention d’utilisateur.
Conclusion et points à retenir
Je pense que nous avons vu combien il est facile de comprendre un site web, grâce à une structure URL lisse et sémantique. Nous devrions également nous rappeler combien une structure URL correcte peut être précieuse pour Google.
À l’avenir, nous verrons beaucoup de SEO être de plus en plus familiers avec la data science, la visualisation des données, la programmation, et plus encore… Je considère ce processus comme le début d’un changement inévitable : le fossé entre les SEO et les développeurs sera complètement inexistant dans quelques années.
Avec Python, vous pouvez pousser ce genre d’analyse encore plus loin : il est possible d’obtenir des données à partir de la compréhension d’un site, de qui écrit sur quoi, à quelle fréquence et avec quels sentiments. Je préfère ne pas aborder ce sujet ici, car ces processus relèvent davantage de la data science que du SEO (et cet article est déjà assez long).
Mais si cela vous intéresse, il existe de nombreux autres types d’audits qui peuvent être réalisés via les sitemaps et Python, comme la vérification des status codes des URLs dans un sitemap.
Je suis impatient d’expérimenter et de partager d’autres tâches SEO que vous pouvez effectuer avec Python et Advertools.
