
Google Search Console (GSC) est certainement l’un des outils les plus utiles pour les spécialistes du SEO, car il vous permet d’obtenir des informations sur la couverture de l’index et surtout sur les requêtes pour lesquelles vous êtes actuellement positionné. Sachant cela, beaucoup de gens analysent les données de la GSC en utilisant des feuilles de calcul et c’est très bien, tant que vous comprenez qu’il y a beaucoup plus de possibilités d’amélioration avec des outils tels que les langages de programmation.
Malheureusement, l’interface du GSC est assez limitée à la fois en termes de lignes affichées (seulement 5000) et de période disponible, seulement 16 mois. Il est clair que cela peut sérieusement limiter votre capacité à obtenir des informations et que cela n’est pas adapté aux sites Web de grande taille.
Python vous permet d’obtenir facilement des données GSC et d’automatiser des calculs plus complexes qui demanderaient beaucoup plus d’efforts dans un tableur traditionnel.
C’est la solution à l’un des plus gros problèmes d’Excel, à savoir la limite de lignes et la vitesse. Aujourd’hui, vous disposez de bien plus d’alternatives pour analyser les données qu’auparavant et c’est là que Python entre en jeu.
Il n’est pas nécessaire d’avoir des connaissances avancées en codage pour suivre ce tutoriel, il suffit de comprendre certains concepts de base et de s’entraîner avec Google Colab.
Mise en route de l’API Google Search Console
Avant de commencer, il est important de configurer l’API Google Search Console. Le processus est assez simple, tout ce dont vous avez besoin est un compte Google. Les étapes sont les suivantes :
- Créez un nouveau projet sur Google Cloud Platform. Vous devez avoir un compte Google et je suis sûr que vous en avez un. Allez dans la console et vous devriez trouver une option en haut pour créer un nouveau projet.
- Cliquez sur le menu à gauche et sélectionnez « API et services », vous arriverez à un autre écran.
- Dans la barre de recherche en haut, recherchez « Google Search Console API » et activez-la.
- Passez ensuite à l’onglet « Credentials », vous avez besoin d’une sorte d’autorisation pour utiliser l’API.
- Configurez l’écran « consentement », car il est obligatoire. Peu importe, pour l’utilisation que nous allons faire, qu’elle soit publique ou non.
- Vous pouvez choisir « Desktop App » pour le type d’application.
- Nous allons utiliser OAuth 2.0 pour ce tutoriel, vous devriez télécharger un fichier json et maintenant vous avez terminé.
C’est en fait la partie la plus difficile pour la plupart des gens, surtout ceux qui ne sont pas habitués aux API de Google. Ne vous inquiétez pas, les étapes suivantes seront beaucoup plus faciles et moins problématiques.
Obtenir des données de l’API Google Search Console avec Python
Je vous recommande d’utiliser un notebook comme “Jupyter Notebook” ou Google Colab. Ce dernier est mieux car vous n’avez pas à vous soucier des exigences. Par conséquent, ce que je vais expliquer est basé sur Google Colab.
Avant de commencer, mettez à jour votre fichier json vers Google Colab avec le code suivant :
from google.colab import files files.upload()
Ensuite, installons toutes les bibliothèques dont nous aurons besoin pour notre analyse et améliorons la visualisation des tableaux avec cet extrait de code :
%%capture #load what is needed !pip install git+https://github.com/joshcarty/google-searchconsole import pandas as pd import numpy as np import matplotlib.pyplot as plt from google.colab import data_table !git clone https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip install umap-learn data_table.enable_dataframe_formatter() #for better table visualization
Enfin, vous pouvez charger la bibliothèque searchconsole, qui offre le moyen le plus simple de le faire sans s’appuyer sur de longues fonctions. Exécutez le code suivant avec les arguments que j’utilise et assurez-vous que client_config a le même nom que le fichier json téléchargé.
import searchconsole account = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Vous serez redirigé vers une page Google pour autoriser l’application, sélectionnez votre compte Google et ensuite copiez et collez le code que vous obtiendrez dans la barre Google Colab.
Nous n’avons pas encore fini, vous devez sélectionner la propriété pour laquelle vous allez avoir besoin de données. Vous pouvez facilement vérifier vos propriétés via account.webproperties pour voir ce que vous devez choisir.
property_name = input('Insert the name of your website as listed in GSC: ')
webproperty=account[str(property_name)]
Une fois que vous avez terminé, vous allez exécuter une fonction personnalisée pour créer un objet contenant nos données.
def extract_gsc_data(webproperty, start, stop, *args):
if webproperty is not None:
print(f'Extracting data for {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
return gsc_data
else:
print('Webproperty not found, please select the correct one')
return None
L’idée de cette fonction est de prendre la propriété que vous avez définie précédemment et un délai, sous la forme de dates de début et de fin, ainsi que des dimensions.
Le choix de pouvoir sélectionner des dimensions est crucial pour les spécialistes du SEO car il vous permet de comprendre si vous avez besoin d’un certain niveau de granularité. Par exemple, il se peut que la dimension de la date ne vous intéresse pas, dans certains cas.
Ma suggestion est de toujours choisir la requête et la page, car l’interface de Google Search Console peut les exporter séparément et il est très ennuyeux de les fusionner à chaque fois. C’est un autre avantage de l’API Search Console.
Dans notre cas, nous pouvons également obtenir directement la dimension date, afin de montrer quelques scénarios intéressants où vous devez prendre en compte le temps.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'query', 'page', 'date')
Sélectionnez une période de temps appropriée, en considérant que pour les propriétés plus importantes, vous devrez attendre beaucoup plus longtemps. Pour cet exemple, je ne prends en compte qu’une période de 3 mois, ce qui est suffisant pour obtenir des informations précieuses à partir de la plupart des ensembles de données, en moyenne.
Vous pouvez même choisir une semaine si vous avez affaire à une énorme quantité de données, ce qui nous intéresse c’est le processus.
Ce que je vais vous montrer ici est soit basé sur des données synthétiques, soit sur des données réelles modifiées dans le but de servir d’exemples. Par conséquent, ce que vous voyez ici est totalement réaliste et peut refléter des scénarios du monde réel.
Nettoyage des données
Pour ceux qui ne le savent pas, nous ne pouvons pas utiliser nos données telles quelles, il y a quelques étapes supplémentaires pour s’assurer que nous travaillons correctement. Tout d’abord, nous devons convertir notre objet en un dataframe Pandas, une structure de données avec laquelle vous devez être familier car elle est la base de l’analyse de données en Python.
df = pd.DataFrame(data=ex) df.head()
La méthode head permet d’afficher les 5 premières lignes de votre jeu de données, c’est très pratique pour avoir un aperçu de ce à quoi ressemblent vos données. Nous pouvons compter le nombre de pages que nous avons en utilisant une fonction simple.
Une bonne façon de supprimer les doublons est de convertir un objet en un ensemble, car les ensembles ne peuvent pas contenir d’éléments “duplicate”.
Certains des extraits de code ont été inspirés par le carnet d’Hamlet Batista et un autre par Masaki Okazawa.
Suppression des termes “brandés”
La toute première chose à faire est de supprimer les mots-clés de marque. Nous recherchons les requêtes qui ne contiennent pas nos termes liés à la marque. C’est assez simple à faire avec une fonction personnalisée et vous aurez généralement un ensemble de termes brandés.
À des fins de démonstration, vous n’avez pas besoin de tous les filtrer, mais faites-le pour les analyses réelles. C’est l’une des étapes de nettoyage des données les plus importantes en SEO, sinon vous risquez de présenter des résultats trompeurs.
domain_name = str(input('Insert brand terms separated by a comma: ')).replace(',', '|')
import re
domain_name = re.sub(r"\s+", "", domain_name)
print('Remove all spaces using RegEx:\n')
df['Brand/Non-branded'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Non-branded'
Nous allons ajouter une nouvelle colonne à notre ensemble de données pour reconnaître la différence entre les deux classes. Nous pouvons visualiser, par le biais de tableaux ou de diagrammes à barres, leur part dans le nombre total de requêtes.
Je ne vous montrerai pas le diagramme à barres car il est très simple et je pense qu’un tableau est mieux adapté à ce cas.
brand_count_df = df['Brand/Non-branded'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Percentage'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Vous pouvez rapidement voir quel est le ratio entre les mots-clés de marque et les mots-clés sans marque pour avoir une idée de la quantité que vous allez retirer de votre ensemble de données. Il n’y a pas de ratio idéal ici, bien que vous souhaitiez certainement avoir un pourcentage plus élevé de mots-clés non brandés.
Ensuite, nous pouvons simplement laisser tomber toutes les lignes marquées comme étant brandées et procéder aux autres étapes.
#only select non-branded keywords df = df.loc[df['Brand/Non-branded'] == 'Non-branded']
Remplissage des valeurs manquantes et autres étapes
Si votre ensemble de données comporte des valeurs manquantes (ou NA dans le jargon), vous avez plusieurs options. Les plus courantes consistent à les supprimer toutes ou à les remplir avec une valeur de remplacement comme 0 ou la moyenne de cette colonne.
Il n’y a pas de réponse correcte et les deux approches présentent des avantages et des inconvénients, ainsi que des risques. Pour les données de Google Search Console, mon meilleur conseil est de mettre une valeur de remplacement comme 0, pour sous-estimer l’effet de certaines mesures.
df.fillna(0, inplace = True)
Avant de passer à l’analyse des données proprement dite, nous devons ajuster nos caractéristiques, à savoir les colonnes de notre ensemble de données. La position est particulièrement intéressante, car nous voulons l’utiliser pour des tableaux croisés dynamiques.
Nous pouvons arrondir la position pour qu’elle soit un nombre entier, ce qui sert notre objectif.
df['position'] = df['position'].round(0).astype('int64')
Vous devez suivre toutes les autres étapes de nettoyage décrites ci-dessus, puis ajuster la colonne de la date.
Nous extrayons les mois et les années à l’aide de Pandas. Vous n’avez pas besoin d’être aussi spécifique si vous travaillez avec une période plus courte, voici un exemple qui prend en compte une demi-année.
#convert date to proper format df['date'] = pd.to_datetime(df['date']) #extract months df['month'] = df['date'].dt.month #extract years df['year'] = df['date'].dt.year
[Ebook] Data SEO : La prochaine grande aventure

Analyse exploratoire des données
Le principal avantage de Python est que vous pouvez faire les mêmes choses que vous faites dans Excel, mais avec beaucoup plus d’options et de facilité. Commençons par quelque chose que tout analyste connaît bien : les tableaux croisés dynamiques.
Analyse du CTR moyen par groupe de positions
L’analyse du CTR moyen, Avg. CTR, par groupe de positions est l’une des activités les plus perspicaces car elle vous permet de comprendre la situation générale d’un site Web. Appliquez le pivot, puis traçons-le.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Avg. Position')
ax.set_ylabel('CTR')
ax.set_title('CTR by avg. position')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(rotation=0)
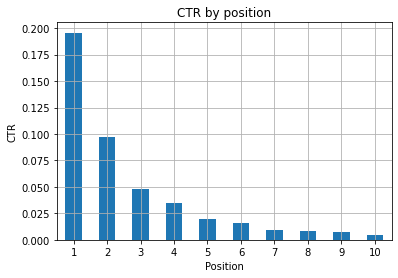
Figure 1 : Représentation du CTR par position pour repérer les anomalies.
Le scénario idéal ici est d’avoir un meilleur CTR sur le côté gauche du graphique, car normalement les résultats de la position 1 devraient présenter un CTR beaucoup plus élevé. Attention cependant, il se peut que dans certains cas, les trois premières positions aient un CTR plus faible que prévu et que vous deviez enquêter.
Veuillez également tenir compte des cas limites, par exemple ceux où la position 11 est meilleure que la première. Comme l’explique la documentation de Google pour Search Console, cette mesure ne suit pas l’ordre auquel on pourrait penser au départ.
De plus, elle ajoute que cette métrique est une moyenne, car la position du lien change à chaque fois et il est impossible d’avoir une précision à 100 %.
Parfois, vos pages sont bien positionnées mais ne sont pas assez convaincantes, vous pouvez donc essayer de corriger le titre. Comme il s’agit d’une vue d’ensemble de haut niveau, vous ne verrez pas de différences granulaires, alors attendez-vous à devoir agir rapidement si le problème est à grande échelle.
Sachez également qu’un groupe de pages occupant des positions inférieures a un CTR moyen plus élevé que les pages mieux placées.
Pour cette raison, vous pouvez étendre votre analyse jusqu’à la position 15 ou plus, afin de repérer des modèles étranges.
Nombre de requêtes par position et mesure des efforts SEO
Une augmentation du nombre de requêtes pour lesquelles vous êtes positionné est toujours un bon signal, mais cela ne signifie pas nécessairement que vous serez mieux positionné à l’avenir. Le comptage des requêtes est le processus qui consiste à compter le nombre de requêtes pour lesquelles vous êtes positionné. C’est l’une des tâches les plus importantes que vous pouvez effectuer avec les données de la GSC.
Les tableaux croisés dynamiques sont une fois de plus d’une grande aide, et nous pouvons tracer les résultats.
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
En tant que spécialiste du référencement, vous souhaitez que le nombre de requêtes soit plus élevé dans la partie la plus à gauche, c’est-à-dire dans les premières positions. La raison est tout à fait naturelle, les positions élevées obtiennent un meilleur CTR en
moyenne, ce qui peut se traduire par plus de personnes cliquant sur votre page.
ax = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Count of queries')
ax.set_xlabel('Position')
ax.set_title('Ranking distribution')
ax.grid('on')
ax.get_legend().remove()
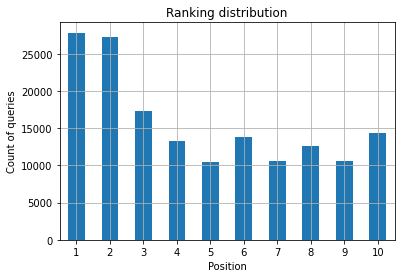
Figure 2 : Combien de requêtes ai-je par position ?
Ce qui vous intéresse, c’est d’augmenter le nombre de requêtes dans les premières positions au fil du temps.
Jouer avec la dimension de la date
Voyons comment les clics varient dans un intervalle de temps donné, obtenons d’abord la somme des clics :
clicks_sum = df.groupby('date')['clicks'].sum()
Nous regroupons les données par la dimension date et obtenons la somme des clics pour chacune d’entre elles, c’est un type de résumé.
Nous sommes maintenant prêts à tracer ce que nous avons obtenu, le code va être assez long juste pour améliorer la visualisation, ne soyez pas effrayé par cela.
# Sum of clicks across period
%config InlineBackend.figure_format = 'retina'
from matplotlib.pyplot import figure
figure(figsize=(8, 6), dpi=80)
ax = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel('Sum of clicks')
ax.set_xlabel('Month')
ax.set_title('How clicks varied on a monthly basis')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('italic')
xlab.set_size(10)
ylab.set_style('italic')
ylab.set_size(10)
ttl = ax.title
ttl.set_weight('bold')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
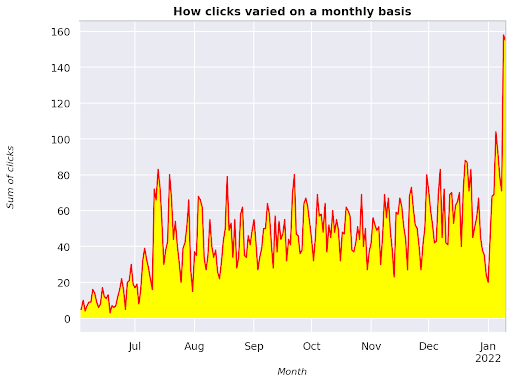
Figure 3 : Tracé de la somme des clics en fonction de la variable mois
Cet exemple part de juin 2021 et va directement jusqu’à la moitié de janvier 2022. Toutes les lignes que vous voyez ci-dessus ont pour rôle de rendre cette visualisation plus jolie, vous pouvez essayer de jouer avec pour voir ce qui se passe.
Nombre de requêtes par position, aperçu mensuel
Une autre visualisation intéressante que nous pouvons tracer en Python est la carte thermique, qui est encore plus visuelle qu’un simple diagramme à barres. Je vais vous montrer comment afficher le nombre de requêtes dans le temps et en fonction de leur position.
import seaborn as sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # Load the example flights dataset and convert to long-form df_heat = df_new.pivot_table(index = "position", columns = "month", values = "query", aggfunc='count') # Draw a heatmap with the numeric values in each cell f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["September", "October", "November", "December"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Month', ylabel='Position', title = 'How query count per position changes with time') #rotate Position labels to make them more readable plt.yticks(rotation=0)
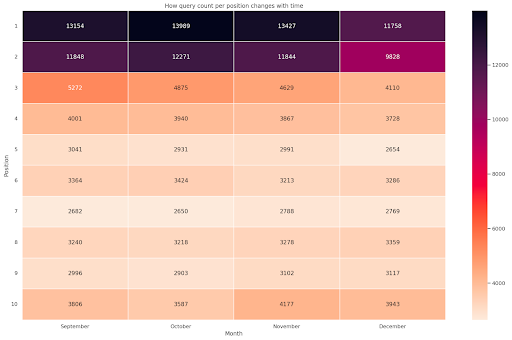
Figure 4 : Heatmap montrant la progression du nombre de requêtes en fonction de la position et du mois.
C’est une de mes préférées, les heatmaps peuvent être très efficaces pour afficher des tableaux croisés dynamiques, comme dans cet exemple. La période s’étend sur 4 mois et si vous la lisez horizontalement, vous pouvez voir comment le nombre de requêtes évolue au fil du temps. Pour la position 10, vous avez une légère augmentation de septembre à décembre, mais pour la position 2, vous avez une diminution frappante, comme le montre la couleur violette.
Dans le scénario suivant, vous avez la majorité des requêtes dans les premières positions, ce qui peut être inhabituel. Si cela se produit, vous pouvez revenir en arrière et analyser la trame de données, en recherchant les éventuels termes brandés, le cas échéant.
Comme vous pouvez le voir dans le code, il n’est pas difficile de créer des graphiques complexes, tant que vous comprenez la logique sous-jacente.
Le nombre de requêtes devrait augmenter avec le temps si vous faites les « bonnes » choses et nous pouvons tracer la différence sur deux périodes différentes. Dans l’exemple que j’ai fourni, ce n’est clairement pas le cas, surtout pour les positions de tête, où vous êtes censé avoir un CTR plus élevé.
Introduction à quelques concepts de base du NLP
Le traitement du langage naturel (NLP) est une aubaine pour le SEO et il n’est pas nécessaire d’être un expert pour appliquer les algorithmes de base. Les N-grammes sont l’une des idées les plus puissantes, mais aussi les plus simples, qui peuvent vous permettre de mieux comprendre les données du GSC.
Les N-grammes sont des séquences contiguës de lettres, de syllabes ou de mots. Pour notre analyse, les mots seront l’unité de mesure. Un n-gramme est appelé bigramme lorsque les éléments adjacents sont deux (une paire) et trigramme s’ils sont trois, et ainsi de suite. Je vous suggère de tester différentes combinaisons et d’aller jusqu’à 5-grammes au maximum.
De cette façon, vous serez en mesure de repérer les phrases les plus courantes dans les pages de vos concurrents ou d’évaluer les vôtres. Étant donné que Google peut s’appuyer sur une indexation basée sur les phrases, il est préférable d’optimiser les phrases plutôt que les mots clés individuels, comme le montrent les brevets de Google sur ce sujet.
Comme indiqué dans la page ci-dessus par Bill Slawski lui-même, la valeur de la compréhension des termes connexes est d’une grande utilité pour l’optimisation et pour vos utilisateurs.
La bibliothèque nltk est très célèbre pour les applications NLP et nous offre la possibilité de supprimer les “stop words” dans une langue donnée, comme l’anglais. Considérez-les comme du bruit que vous voulez supprimer, en effet, les articles et les mots très fréquents n’ajoutent aucune valeur à la compréhension d’un texte.
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stoplist = stopwords.words('english')
from sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# matrix of ngrams
ngrams = c_vec.fit_transform(df['query'])
# count frequency of ngrams
count_values = ngrams.toarray().sum(axis=0)
# list of ngrams
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequency', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
Nous prenons la colonne de requête et comptons la fréquence des bi-grammes pour créer un cadre de données stockant les bi-grammes et leur nombre d’occurrences.
Cette étape est en fait très importante pour analyser les sites Web des concurrents également. Vous pouvez simplement scrapper leur texte et vérifier quels sont les n-grammes les plus courants, en ajustant le n à chaque fois pour voir si vous repérez des modèles différents sur les pages à haut positionnement.
Si vous y réfléchissez une seconde, cela a beaucoup plus de sens, car un mot-clé individuel ne vous dit rien sur le contexte.
Les occasions faciles à saisir
L’une des premières choses à réaliser est de vérifier les solutions à portée de main, c’est-à-dire les pages que vous pouvez améliorer facilement pour obtenir de bons résultats le plus tôt possible. Il s’agit d’une étape cruciale dans les premières étapes de chaque projet de SEO pour convaincre vos parties prenantes. Par conséquent, si vous avez l’occasion d’exploiter de telles pages, faites-le !
Nos critères pour considérer une page comme telle sont les quantiles d’impressions et de CTR. En d’autres termes, nous filtrons les rangées qui se situent dans les 80 % supérieurs d’impressions, mais qui font partie des 20 % qui reçoivent le CTR le plus faible. Ces lignes auront un CTR plus mauvais que 80% des autres.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascending = False))
Maintenant vous avez une liste avec toutes les opportunités triées par Impressions, dans l’ordre décroissant.
Vous pouvez penser à d’autres critères pour définir ce qui est à portée de main, en fonction des besoins de votre site Web et de sa taille.
Pour les petits sites, vous pouvez envisager de rechercher des pourcentages plus élevés, alors que pour les grands sites, vous devriez déjà obtenir beaucoup d’informations avec les critères que j’utilise.
[Ebook] Automatisation du SEO avec Oncrawl

Présentation de querycat : classification et associations
Querycat est une bibliothèque simple mais puissante qui propose l’extraction de règles d’association pour le regroupement de mots-clés et bien plus encore. Je ne vous montrerai que les associations car elles sont plus précieuses dans ce type d’analyse.
Vous pouvez en apprendre davantage sur cette bibliothèque impressionnante en consultant le dépôt GitHub de querycat.
Brève introduction à l’apprentissage des règles d’association
L’apprentissage des règles d’association est une méthode permettant de trouver des règles qui définissent les associations et les cooccurrences entre des ensembles d’éléments. Cette méthode est légèrement différente d’une autre méthode de machine learning non supervisée, le « clustering ».
L’objectif final est cependant le même : obtenir des groupes de mots-clés pour comprendre comment notre site Web se comporte pour certains sujets.
Querycat vous donne la possibilité de choisir entre deux algorithmes : Apriori et FP-Growth. Nous allons choisir ce dernier pour de meilleures performances, vous pouvez donc ignorer le premier.
FP-Growth est une version améliorée d’Apriori pour trouver des modèles fréquents dans des ensembles de données. L’apprentissage des règles d’association est également très utile pour les transactions d’e-commerce. Vous pouvez être intéressé par la compréhension de ce que les gens achètent ensemble, par exemple.
Dans ce cas, nous nous concentrons sur les requêtes, mais l’autre application que j’ai mentionnée peut être une autre idée utile pour les données de Google Analytics.
Expliquer ces algorithmes du point de vue de la structure des données est assez difficile et, à mon avis, pas nécessaire pour vos tâches de SEO. Je vais juste expliquer quelques concepts de base pour comprendre la signification des paramètres.
Les 3 éléments principaux de ces 2 algorithmes sont :
- Support – Il exprime la popularité d’un élément ou d’un ensemble d’éléments. En termes techniques, il s’agit du nombre de transactions où la requête X et la requête Y apparaissent ensemble, divisé par le nombre total de transactions.De plus, il peut être utilisé comme seuil pour éliminer les éléments peu fréquents. Très utile pour augmenter la signification statistique et les performances. Il est très bon de fixer un bon support minimum.
- Confiance – on peut la considérer comme la probabilité de cooccurrence des termes.
- Lift – Le rapport entre le support pour (terme 1 et terme 2) et le support du terme 1. Nous pouvons examiner sa valeur pour avoir un aperçu de la relation entre les termes. S’il est supérieur à 1, les termes sont corrélés ; s’il est inférieur à 1, il est peu probable qu’il y ait une association entre les termes : si lift est exactement égal à 1 (ou proche), il n’y a pas de relation significative.
De plus amples détails sont fournis dans cet article sur querycat écrit par l’auteur de la bibliothèque.
Maintenant nous sommes prêts à passer à la partie pratique.
import querycat
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#create group to filter categories with less than 15 clicks (arbitrary number)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
filtergroup
#apply filter
df = df.merge(filtergroup, on=['category','category'], how='inner')
Nous avons filtré les catégories moins fréquentes dans le processus, j’ai choisi 15 comme référence dans mon cas. C’est juste un nombre arbitraire, il n’y a aucun critère derrière.
Vérifions nos catégories avec l’extrait suivant :
df['category'].value_counts()
Qu’en est-il des 10 catégories les plus cliquées ? Vérifions combien de requêtes nous avons pour chacune d’entre elles.
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
Le nombre à choisir est arbitraire, assurez-vous d’en choisir un qui filtre un bon pourcentage de groupes. Une idée potentielle est d’obtenir la médiane des impressions et de laisser tomber les 50% les plus bas, à condition de vouloir exclure les petits groupes.
Obtenir des clusters et que faire avec le résultat
Je vous recommande d’exporter votre nouveau cadre de données pour éviter de relancer FP-Growth, faites-le pour gagner du temps.
Dès que vous avez obtenu des clusters, vous souhaitez connaître les clics et les impressions pour chacun d’entre eux afin d’évaluer les zones qui nécessitent le plus d’améliorations.
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
Avec une certaine manipulation des données, nous sommes en mesure d’améliorer nos résultats d’association et d’avoir des clics et des impressions pour chaque cluster.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#remove duplicate queries and then sort them alphabetically
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
Vous avez maintenant un fichier CSV avec tous vos groupes de mots-clés avec les clics et les impressions.
#save csv file and download it to your local machine. If you use Safari, please consider switching to Chrome for downloading these files as it may not work.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
En fait, il y a de meilleures méthodes pour le clustering, ceci est juste un exemple sur la façon dont vous pouvez utiliser querycat pour effectuer plusieurs tâches pour une utilisation immédiate. L’objectif principal est d’obtenir autant d’informations que possible, en particulier pour les nouveaux sites Web où vous n’avez pas beaucoup de connaissances.
Actuellement, les meilleures approches impliquent la sémantique, donc si vous voulez vous concentrer sur le clustering, je vous suggère de considérer l’apprentissage de graphes ou d’embeddings.
Cependant, il s’agit de sujets avancés si vous êtes novice et vous pouvez simplement essayer certaines applications Streamlit pré-construites disponibles en ligne.
Conclusion et prochaines étapes
Python peut offrir une aide majeure dans l’analyse de votre site Web et peut vous aider à combiner le nettoyage, la visualisation et l’analyse des données en un seul endroit. L’extraction de données à partir de l’API de la GSC est certainement nécessaire pour des tâches plus avancées et constitue une introduction “en douceur” à l’automatisation des données.
Bien que vous puissiez effectuer de nombreux calculs plus avancés avec Python, je vous recommande de vérifier ce qui a du sens en termes de valeur SEO.
Par exemple, le nombre de requêtes est beaucoup plus important dans son ensemble à long terme, car vous souhaitez que votre site Web soit pris en compte pour un plus grand nombre de requêtes.
L’utilisation de notebooks est d’une grande aide pour entourer le code avec des commentaires et c’est la principale raison pour laquelle je vous suggère de vous habituer à Google Colab.
Ce n’est que le début de ce que l’analyse de données peut vous offrir, car les meilleures idées viennent de la fusion de différents ensembles de données.
Google Search Console est en soi un outil puissant et totalement gratuit, la quantité d’informations pratiques que vous pouvez en tirer est presque illimitée entre de bonnes mains.
