
Dans un monde rempli de mythes sur le marketing digital, nous pensons qu’il est nécessaire de trouver des solutions pratiques aux problèmes quotidiens.
Sur Pemavor, nous partageons toujours notre expertise et nos connaissances pour répondre aux besoins des passionnés de marketing digital. Ainsi, nous publions souvent des scripts Python gratuits pour vous aider à augmenter votre ROI.
Notre SEO Keyword Clustering with Python a ouvert la voie à l’acquisition de nouvelles connaissances pour les grands projets SEO, avec seulement moins de 50 lignes de code Python.
L’idée derrière ce script était de vous permettre de regrouper des mots-clés sans payer des » frais exagérés » à… eh bien, nous savons qui… 😊.
Mais nous avons réalisé que ce script n’est pas suffisant à lui seul. Il faut un autre script, pour que vous puissiez approfondir votre compréhension de vos mots-clés : vous devez être capable de « regrouper les mots-clés par signification et relations sémantiques. »
Maintenant, il est temps d’aller plus loin avec Python pour le SEO.
La méthode traditionnelle de regroupement sémantique
Comme vous le savez, la méthode traditionnelle pour la sémantique consiste à construire des modèles word2vec, puis à regrouper les mots-clés avec la distance de Word Mover.
Mais la construction et l’entraînement de ces modèles demandent beaucoup de temps et d’efforts. Nous aimerions donc vous proposer une solution plus simple.
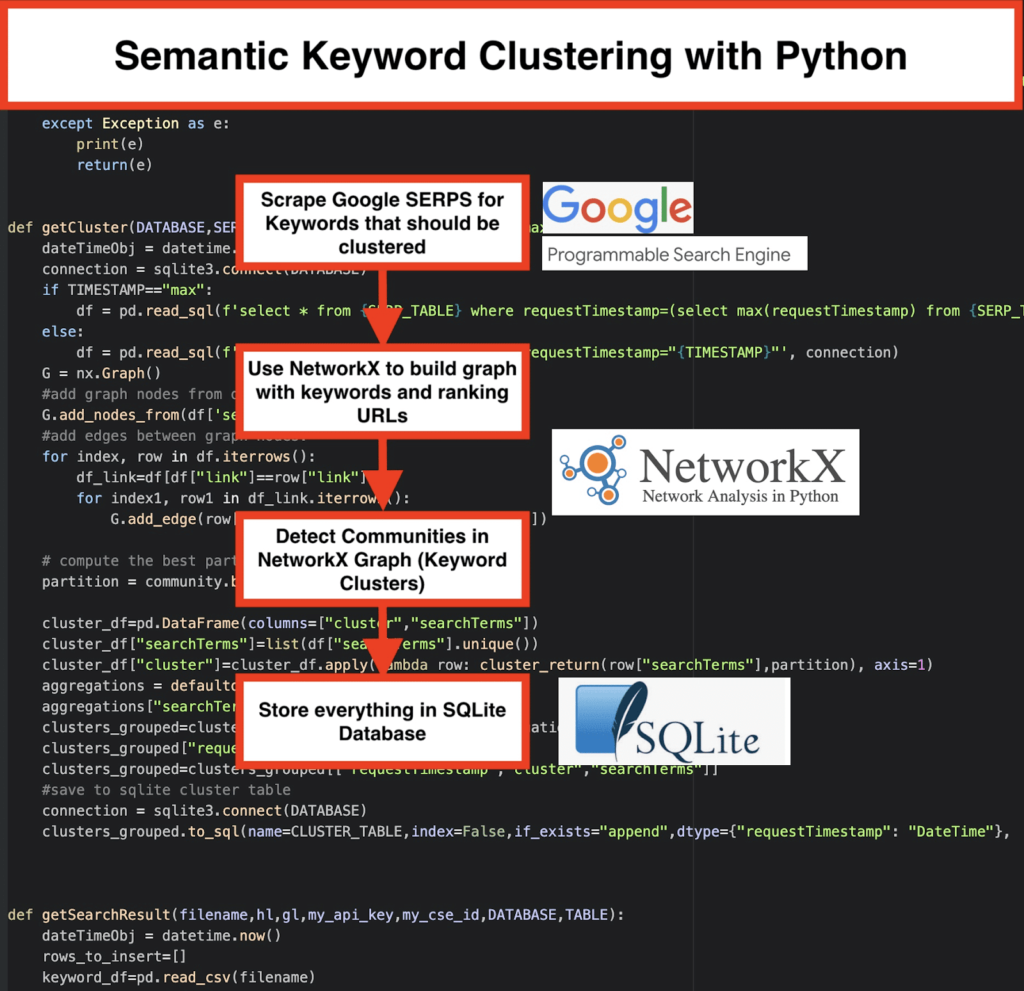
Résultats SERP de Google et découverte de la sémantique
Google utilise des modèles NLP pour offrir les meilleurs résultats de recherche. C’est comme une boîte de Pandore à ouvrir.
Cependant, plutôt que de construire nos modèles, nous pouvons utiliser cette boîte pour regrouper les mots-clés selon leur sémantique et leur signification.
Voici comment nous procédons :
✔️ Tout d’abord, venez avec une liste de mots-clés pour un sujet.
✔️ Ensuite, scrappez les données SERP pour chaque mot-clé.
✔️ Ensuite, on crée un graphique avec la relation entre les pages de classement et les mots-clés.
✔️ Tant que les mêmes pages se positionnent pour différents mots-clés, cela signifie qu’elles sont liées entre elles. C’est le principe de base derrière la création de clusters sémantiques de mots-clés.
Il est temps d’assembler le tout en Python
Le script Python offre les fonctions ci-dessous :
- En utilisant le moteur de recherche personnalisé de Google, téléchargez les SERPs pour la liste de mots-clés. Les données sont enregistrées dans une base de données SQLite. Ici, vous devez configurer une API de recherche personnalisée.
- Ensuite, utilisez le quota gratuit de 100 demandes par jour. Mais si vous ne voulez pas attendre ou si vous avez de grands ensembles de données, vous pouvez également opter pour un plan payant de 5 $ par 1000 requêtes.
- Il est préférable d’opter pour les solutions SQLite si vous n’êtes pas pressé – les résultats SERP seront ajoutés à la table à chaque exécution. (Il suffit de prendre une nouvelle série de 100 mots-clés lorsque vous avez le quota le lendemain).
En attendant, vous devez configurer ces variables dans le script Python.
- CSV_FILE= »keywords.csv » => stockez vos mots-clés ici
- LANGUE = « en »
- COUNTRY = « en
- API_KEY= » xxxxxxx «
- CSE_ID= »xxxxxxx »
L’exécution de getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) écrira les résultats SERP dans la base de données.
Le clustering est effectué par networkx et le module de détection de communauté. Les données sont extraites de la base de données SQLite – le clustering est appelé avec getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)
.
Les résultats du clustering peuvent être trouvés dans la table SQLite – tant que vous ne changez pas, le nom est « keyword_clusters » par défaut.
Ci-dessous, vous verrez le code complet :
# Semantic Keyword Clustering by Pemavor.com
# Author: Stefan Neefischer (stefan.neefischer@gmail.com)
from googleapiclient.discovery import build
import pandas as pd
import Levenshtein
from datetime import datetime
from fuzzywuzzy import fuzz
from urllib.parse import urlparse
from tld import get_tld
import langid
import json
import pandas as pd
import numpy as np
import networkx as nx
import community
import sqlite3
import math
import io
from collections import defaultdict
def cluster_return(searchTerm,partition):
return partition[searchTerm]
def language_detection(str_lan):
lan=langid.classify(str_lan)
return lan[0]
def extract_domain(url, remove_http=True):
uri = urlparse(url)
if remove_http:
domain_name = f"{uri.netloc}"
else:
domain_name = f"{uri.netloc}://{uri.netloc}"
return domain_name
def extract_mainDomain(url):
res = get_tld(url, as_object=True)
return res.fld
def fuzzy_ratio(str1,str2):
return fuzz.ratio(str1,str2)
def fuzzy_token_set_ratio(str1,str2):
return fuzz.token_set_ratio(str1,str2)
def google_search(search_term, api_key, cse_id,hl,gl, **kwargs):
try:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10, cx=cse_id, **kwargs).execute()
return res
except Exception as e:
print(e)
return(e)
def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs):
try:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10, cx=cse_id, **kwargs).execute()
return res
except Exception as e:
print(e)
return(e)
def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"):
dateTimeObj = datetime.now()
connection = sqlite3.connect(DATABASE)
if TIMESTAMP=="max":
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', connection)
else:
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', connection)
G = nx.Graph()
#add graph nodes from dataframe columun
G.add_nodes_from(df['searchTerms'])
#add edges between graph nodes:
for index, row in df.iterrows():
df_link=df[df["link"]==row["link"]]
for index1, row1 in df_link.iterrows():
G.add_edge(row["searchTerms"], row1['searchTerms'])
# compute the best partition for community (clusters)
partition = community.best_partition(G)
cluster_df=pd.DataFrame(columns=["cluster","searchTerms"])
cluster_df["searchTerms"]=list(df["searchTerms"].unique())
cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partition), axis=1)
aggregations = defaultdict()
aggregations["searchTerms"]=' | '.join
clusters_grouped=cluster_df.groupby("cluster").agg(aggregations).reset_index()
clusters_grouped["requestTimestamp"]=dateTimeObj
clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]]
#save to sqlite cluster table
connection = sqlite3.connect(DATABASE)
clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE):
dateTimeObj = datetime.now()
rows_to_insert=[]
keyword_df=pd.read_csv(filename)
keywords=keyword_df.iloc[:,0].tolist()
for query in keywords:
if hl=="default":
result = google_search_default_language(query, my_api_key, my_cse_id,gl)
else:
result = google_search(query, my_api_key, my_cse_id,hl,gl)
if "items" in result and "queries" in result :
for position in range(0,len(result["items"])):
result["items"][position]["position"]=position+1
result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"])
result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query)
result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query)
result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query)
result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query)
result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"])
for position in range(0,len(result["items"])):
rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl,
"totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"],
"displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"],
"position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"],
"snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"],
"snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"],
"title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"],
})
df=pd.DataFrame(rows_to_insert)
#save serp results to sqlite database
connection = sqlite3.connect(DATABASE)
df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
##############################################################################################################################################
#Read Me: #
##############################################################################################################################################
#1- You need to setup a google custom search engine. #
# Please Provide the API Key and the SearchId. #
# Also set your country and language where you want to monitor SERP Results. #
# If you don't have an API Key and Search Id yet, #
# you can follow the steps under Prerequisites section in this page https://developers.google.com/custom-search/v1/overview#prerequisites #
# #
#2- You need also to enter database, serp table and cluster table names to be used for saving results. #
# #
#3- enter csv file name or full path that contains keywords that will be used for serp #
# #
#4- For keywords clustering enter the timestamp for serp results that will used for clustering. #
# If you need to cluster last serp results enter "max" for timestamp. #
# or you can enter specific timestamp like "2021-02-18 17:18:05.195321" #
# #
#5- Browse the results through DB browser for Sqlite program #
##############################################################################################################################################
#csv file name that have keywords for serp
CSV_FILE="keywords.csv"
# determine language
LANGUAGE = "en"
#detrmine city
COUNTRY = "en"
#google custom search json api key
API_KEY="ENTER KEY HERE"
#Search engine ID
CSE_ID="ENTER ID HERE"
#sqlite database name
DATABASE="keywords.db"
#table name to save serp results to it
SERP_TABLE="keywords_serps"
# run serp for keywords
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)
#table name that cluster results will save to it.
CLUSTER_TABLE="keyword_clusters"
#Please enter timestamp, if you want to make clusters for specific timestamp
#If you need to make clusters for the last serp result, send it with "max" value
#TIMESTAMP="2021-02-18 17:18:05.195321"
TIMESTAMP="max"
#run keyword clusters according to networks and community algorithms
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)Résultats SERP de Google et découverte de la sémantique
Nous espérons que vous avez apprécié ce script et son raccourci pour regrouper vos mots-clés en clusters sémantiques sans vous appuyer sur des modèles sémantiques. Ces modèles étant souvent à la fois complexes et coûteux, il est important de chercher d’autres moyens d’identifier les mots-clés qui partagent des propriétés sémantiques.
En traitant ensemble les mots-clés sémantiquement liés, vous pouvez mieux couvrir un sujet, mieux relier les articles de votre site les uns aux autres et augmenter le positionnement de votre site Web pour un sujet donné.
