L’analyse des logs est le moyen le plus complet d’analyser la façon dont les moteurs de recherche lisent nos sites. Chaque jour, les SEOs, les spécialistes du marketing digital et les analystes web utilisent des outils qui présentent des diagrammes sur le trafic, les comportements des utilisateurs et les conversions. Les SEOs essaient généralement de comprendre comment Google parcourt leur site via Google Search Console.
Alors, pourquoi un SEO devrait-il utiliser un logiciel d’analyse des fichiers logs pour vérifier si un moteur de recherche lit correctement le site ? Commençons par les bases.
Qu’est ce que sont les fichiers de logs ?
Un fichier de log est un fichier dans lequel le serveur web écrit une ligne pour chaque ressource du site web qui est demandée par des robots ou des utilisateurs. Chaque ligne contient des données sur la demande, qui peuvent inclure :
l’adresse IP de l’appelant, la date, la ressource requise (page, .css, .js, …), l’agent utilisateur, le temps de réponse, …
Une ligne ressemble à ceci :
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)" "www.***.it" "-"
Crawlabilité et capacité de mise à jour
Chaque page a trois statuts SEO de base:
- crawlable
- indexable
- classable
Du point de vue de l’analyse des logs, nous savons que pour indexer une page, elle doit être lue par un robot. De même, le contenu déjà indexé par un moteur de recherche doit être re-crawlé pour être mis à jour dans les index du moteur de recherche.
Malheureusement, dans Google Search Console, nous ne disposons pas de ce niveau de détail : nous pouvons vérifier combien de fois Googlebot a lu une page du site au cours des trois derniers mois et à quelle vitesse le serveur web a répondu.
Comment pouvons-nous vérifier si un robot a lu une page ? Bien sûr, en utilisant les fichiers de logs et un analyseur de logs.
Comment analyser les logs et pourquoi le faire ?
L‘analyse de logs permet aux SEO (et aux administrateurs système également) de comprendre :
- Ce qu’un bot lit exactement
- A quelle fréquence le robot le lit
- le coût des crawls, en termes de temps passé (ms).
Un logiciel d’analyse de logs permet d’analyser les lignes de ces fichiers en regroupant les informations par « chemin », par type de fichier ou par temps de réponse. Un excellent outil d’auditer des logs nous permet également de joindre les informations obtenues à partir d’autres sources de données comme Google Search Console (clics, impressions, positions moyennes) ou toutes les alternatives Google Analytics.
[Étude de cas] Optimiser le trafic organique en utilisant l’analyse de fichiers de log

Comprendre les logs : que faut-il rechercher dans les fichiers de logs ?
L’un des principaux éléments importants d’information dans les fichiers de logs est ce qui n’y figure pas. Vraiment, je ne plaisante pas. La première étape pour comprendre pourquoi une page n’est pas indexée ou n’est pas mise à jour dans sa dernière version est de vérifier si le robot (par exemple Googlebot) l’a lue.
Ensuite, si la page est fréquemment mise à jour, il peut être important de vérifier à quelle fréquence un robot lit la page ou la section du site.
L’étape suivante consiste à vérifier quelles sont les pages les plus lues par les robots. En les suivant, vous pouvez vérifier si ces pages :
- méritent d’être lues aussi souvent
- ou sont lues si régulièrement parce que quelque chose sur la page provoque des changements constants et incontrôlables.
Par exemple, il y a quelques mois, un site sur lequel je travaillais présentait une fréquence très élevée de lecture par des robots sur une URL étrange. Le bot a révélé que cette page provenait d’une URL créée par un script JS, et que cette page était empreinte de certaines valeurs de débogage qui changeaient à chaque fois que la page était chargée… Suite à cette révélation, un spécialiste en SEO peut sûrement trouver la bonne solution pour réparer ce trou dans le budget de crawl.
Logs seo et budget de crawl
Le budget de crawl ? Qu’est-ce que c’est ? Chaque site a son budget métaphorique lié aux moteurs de recherche et à leur robot. Oui : Google fixe une sorte de budget pour votre site. Celui-ci n’est enregistré nulle part, mais vous pouvez le « calculer » de deux manières :
- en vérifiant le rapport de statistiques de Google Search Console Crawl
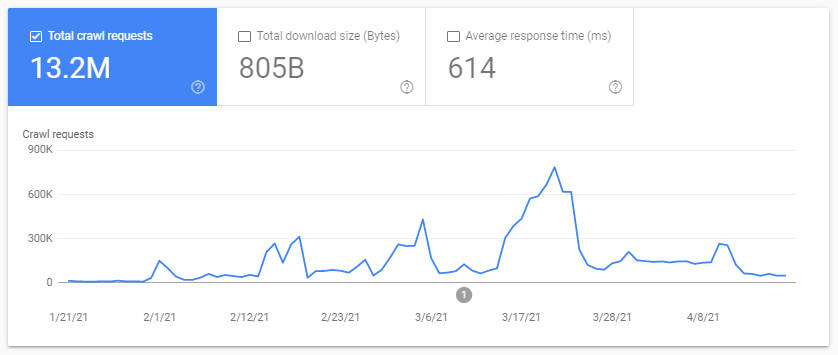

- en vérifiant les fichiers de logs, en les parcourant (en les filtrant) en fonction de l’agent utilisateur contenant « Googlebot » (vous obtiendrez de meilleurs résultats si vous vous assurez que ces agents utilisateurs correspondent aux bonnes adresses IP de Google…).
Le budget de crawl augmente lorsque le site est mis à jour avec un contenu intéressant, ou lorsqu’il est régulièrement mis à jour, ou lorsque le site reçoit de bons backlinks.
La façon dont le budget de crawl est dépensé sur votre site peut être gérée par :
- les liens internes (follow / nofollow aussi !)
- noindex / canonical
- robots.txt (attention : cela « bloque » l’agent utilisateur)
Pages zombies découvertes dans les fichiers de logs
Pour moi, les « pages zombies » sont toutes les pages qui n’ont pas eu de trafic organique ou de visites de robots pendant une période de temps considérable, mais qui ont des liens internes pointant vers elles.
Ce type de page peut utiliser trop de budget de crawl et peut recevoir inutilement un Page Rank à cause des liens internes. Cette situation peut être résolue :
- Si ces pages sont utiles pour les utilisateurs qui viennent sur le site, on peut les mettre en noindex et mettre les liens internes vers elles en nofollow (ou utiliser disallow robots.txt, mais attention à cela…)
- Si ces pages ne sont pas utiles pour les utilisateurs qui viennent sur le site, nous pouvons les supprimer (et renvoyer un code de statut 410 ou 404) et supprimer tous les liens internes.
Avec Oncrawl nous pouvons créer un « rapport zombie » basé sur les :
- Impressions GSC
- Clics CGC
- Sessions GA
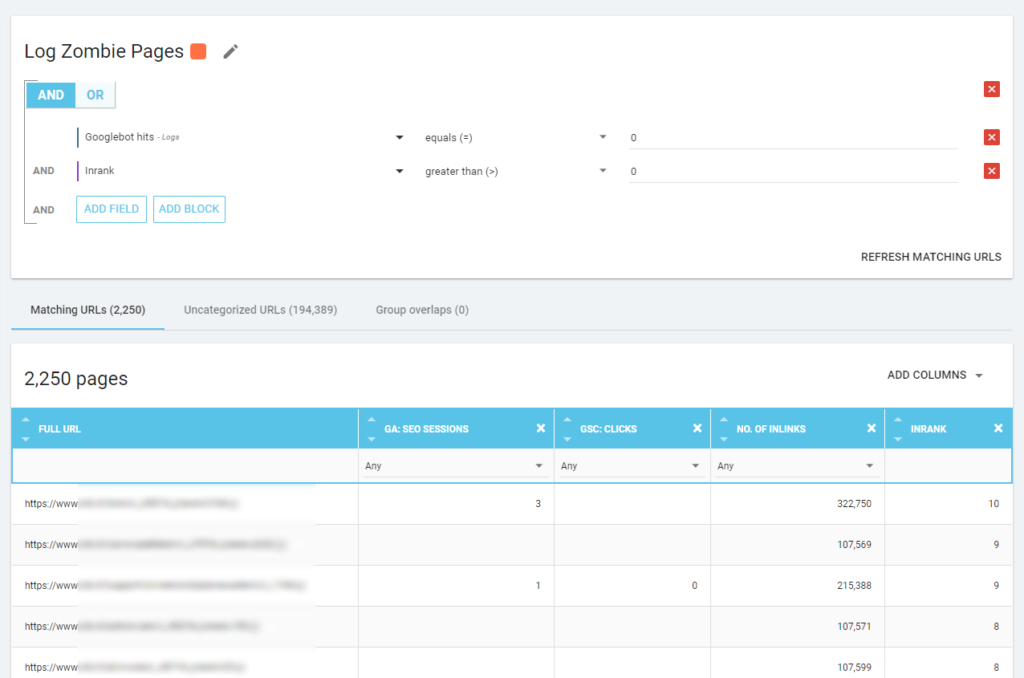
Nous pouvons également utiliser les événements des logs pour découvrir les pages zombies : en définissant un filtre d’événements 0, par exemple. L’une des façons les plus simples de le faire est de créer une segmentation. Dans l’exemple ci-dessous, je filtre toutes les pages avec les critères suivants : pas de visites de Googlebot mais avec un Inrank (cela signifie que ces pages ont des liens internes qui pointent vers elles).
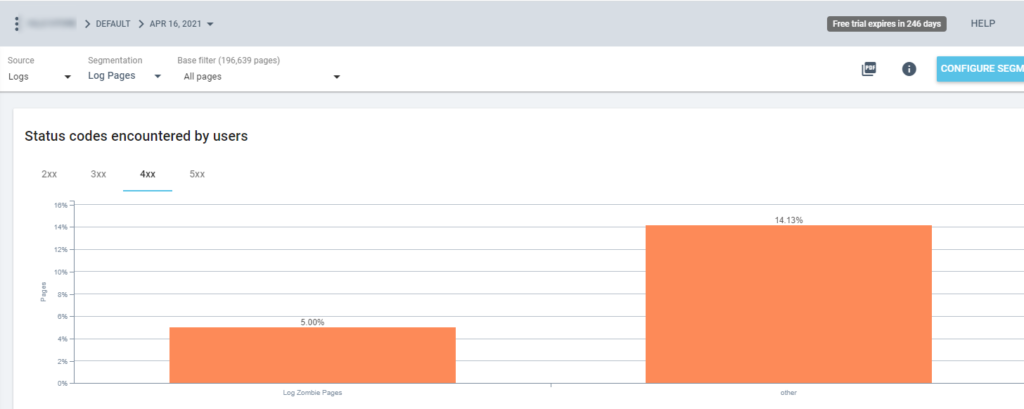
Nous pouvons maintenant utiliser cette segmentation dans tous les rapports Oncrawl. Cela nous permet d’obtenir des informations à partir de n’importe quel graphique, par exemple : combien de « pages zombies » renvoient un code d’état 200 ?
Pages orphelines
Pour moi, les « pages orphelines » qui méritent d’être examinées attentivement sont toutes les pages qui ont une valeur élevée sur des mesures importantes (GA Session, GSC Impression, Log hits, …) qui n’ont pas de liens internes pointant vers elles pour partager le pagerank et indiquer l’importance de la page.
Comme pour les « pages zombies », pour créer un rapport basé sur les logs, la meilleure façon est de créer une nouvelle segmentation.
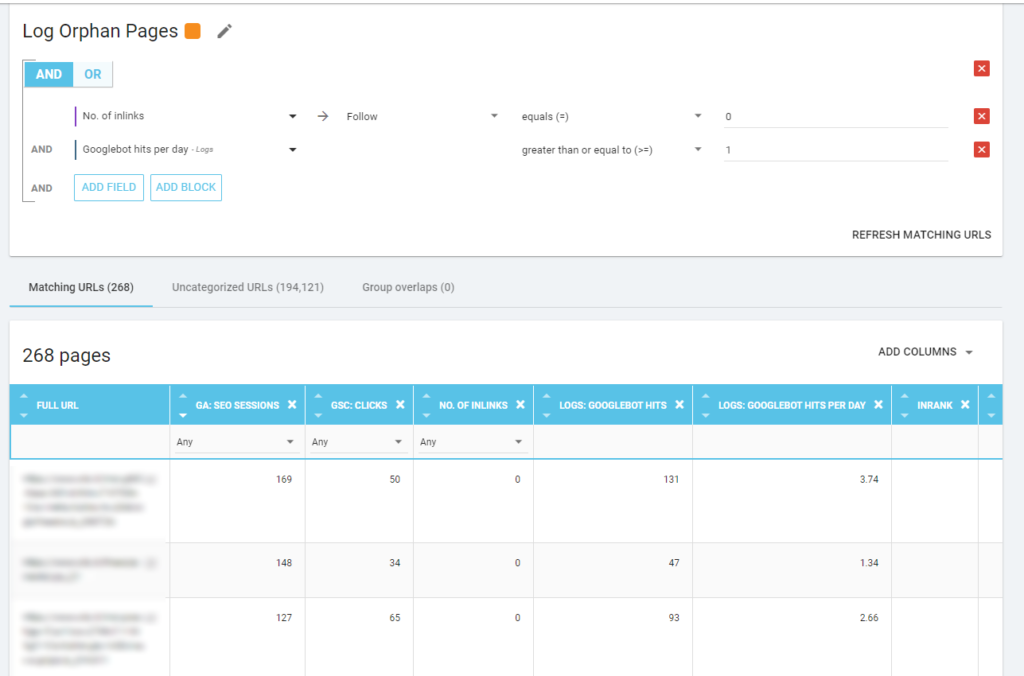
WOW, quel nombre de pages avec des sessions et des hits et sans inlinks !
Lorsque vous vérifiez un rapport basé sur « Zero Follow Inlinks », faites attention à l’état du crawling : Oncrawl a-t-il pu crawler tout le site, ou seulement quelques pages ? Vous pouvez le voir sur la page principale du projet :
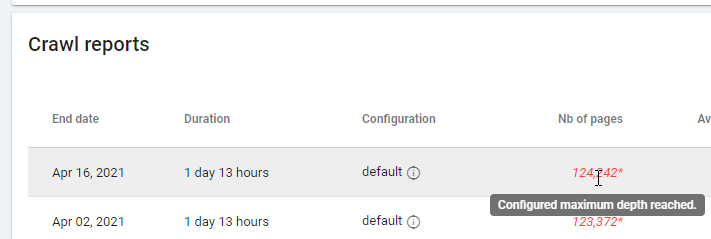
Si la profondeur maximale a été atteinte :
- Vérifiez la configuration de votre crawl
- Vérifiez la structure de votre site
Les fichiers de logs seo et Oncrawl
Que propose Oncrawl dans ses tableaux de bord par défaut ?
Live log
Ce tableau de bord est utile pour vérifier les informations clés sur la façon dont les bots lisent vos sites, dès que les bots visitent le site et avant que les informations des fichiers de logs soient complètement traitées. Pour en tirer le meilleur parti, je vous recommande de télécharger fréquemment les fichiers de logs : vous pouvez le faire par FTP, via des connecteurs tels que celui pour Amazon S3, ou vous pouvez le faire manuellement via l’interface web.
Le premier graphique montre à quelle fréquence votre site est lu, et par quel bot. Dans l’exemple que vous pouvez voir ci-dessous, nous pouvons vérifier les accès desktop par rapport aux accès mobiles. Dans ce cas, nous avons envoyé à Oncrawl les fichiers de logs filtrés uniquement pour Googlebot :
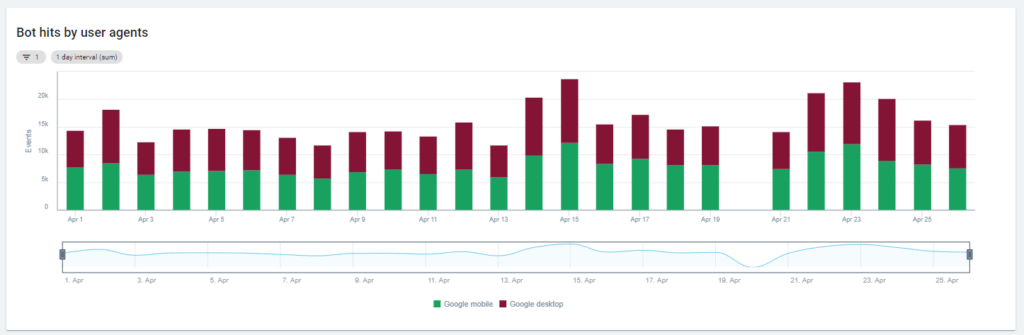
Il est intéressant de voir comment la quantité de lectures mobiles est encore très élevée : est-ce normal ? Cela dépend… Le site que nous analysons est toujours dans « l’index mobile-first » mais ce n’est pas un site entièrement responsive : c’est un site à dynamic serving (comme Google l’appelle) et Google vérifie toujours les deux versions !
Un autre diagramme intéressant est « Bot hits by page group ». Par défaut, Oncrawl crée des groupes basés sur les chemins URL. Mais nous pouvons définir des groupes manuellement afin de regrouper les URLs qui ont le plus de sens à analyser ensemble.
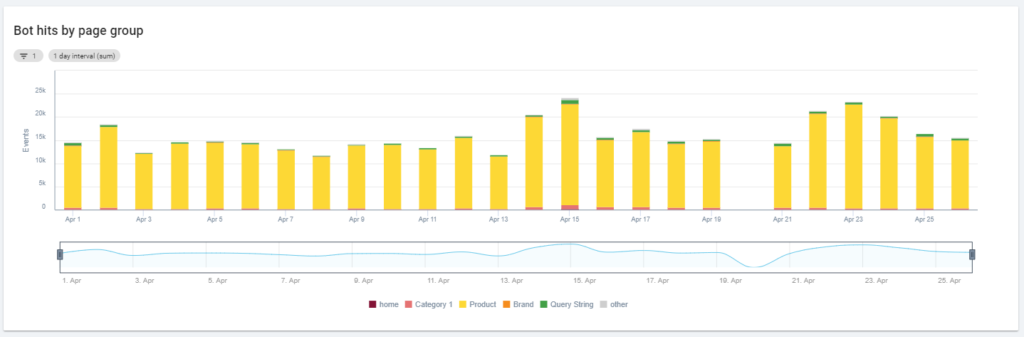
Comme vous pouvez le voir, le jaune l’emporte ! Il représente les URLs avec un chemin de produit, il est donc normal qu’il ait un impact aussi élevé, d’autant plus que nous avons des campagnes Google paid Shopping.
Et… oui, nous venons de confirmer que Google utilise le Googlebot standard pour vérifier le statut des produits liés au flux marchand !
Crawl behavior
Ce tableau de bord présente des informations similaires à celles du « Live log » mais ces informations ont été entièrement traitées et sont agrégées par jour, semaine ou mois. Ici, vous pouvez définir une période de date (début/fin), qui peut remonter dans le temps aussi loin que vous le souhaitez. Il y a deux nouveaux diagrammes pour approfondir l’analyse des logs :
- Comportement de crawl : pour vérifier le ratio entre les pages crawlées et les pages nouvellement crawlées.
- Fréquence de crawl par jour
La meilleure façon de lire ces diagrammes est de relier les résultats aux actions du site :
- Avez-vous déplacé des pages ?
- Avez-vous mis à jour certaines sections ?
- Avez-vous publié du nouveau contenu ?
SEO Impact
Pour le SEO, il est important de surveiller si les pages optimisées sont lues par les robots ou non. Comme nous l’avons écrit à propos des « pages orphelines », il est important de s’assurer que les pages les plus importantes/mises à jour sont lues par les robots afin que les moteurs de recherche disposent des informations les plus récentes pour être classables.
Oncrawl utilise le concept de « pages actives » pour indiquer les pages qui reçoivent du trafic organique des moteurs de recherche. À partir de ce concept, il affiche quelques chiffres de base, tels que :
- Visites SEO
- Pages actives SEO
- SEO active ratio (la proportion de pages actives parmi toutes les pages crawlées)
- Fresh Rank (le temps moyen qui s’écoule entre le moment où le robot lit la page pour la première fois et la première visite organique)
- Pages actives non explorées
- Pages nouvellement actives
- Fréquence de crawl par jour des pages actives
Comme le veut la philosophie d’Oncrawl, d’un simple clic, on peut aller au fond du lac d’informations, filtré par la métrique sur laquelle on a cliqué ! Par exemple : quelles sont les pages actives non crawlées ? Un seul clic…
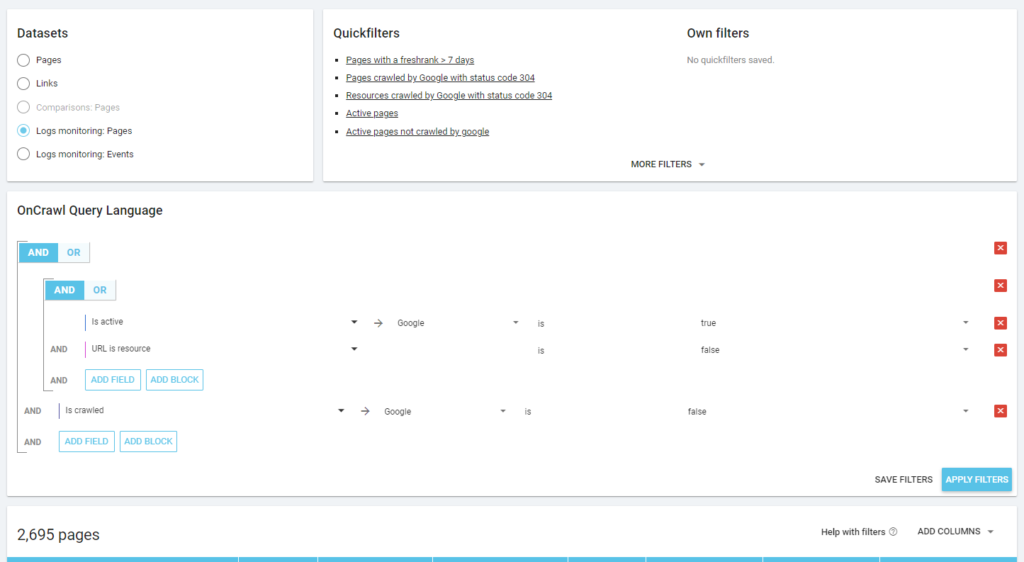
Exploration sanity
Ce dernier tableau de bord nous permet de vérifier la qualité du crawling du BO, ou plus exactement, la façon dont le site se présente aux moteurs de recherche :
- Analyse du code de statut
- Analyse du code d’état par jour
- Analyse du code d’état par groupe de pages
- Analyse du temps de réponse
Pour un bon travail de SEO, il est obligatoire de :
- réduire le nombre de réponses 301 des liens internes
- supprimer les réponses 404/410 des liens internes
- optimiser le temps de réponse, car la qualité du crawl de Googlebot est directement liée au temps de réponse : essayez de réduire de moitié le temps de réponse de votre site et vous verrez (en quelques jours) que la quantité de pages crawlées doublera.
La science de l’analyse de logs SEO et le Data Explorer d’Oncrawl
Jusqu’à présent, nous avons vu les rapports standards d’Oncrawl et comment les utiliser pour obtenir des informations personnalisées via des segmentations et des groupes de pages.
Mais le cœur de l’analyse des logs est de comprendre comment trouver quelque chose d’anormal. En général, le point de départ de l’analyse est de vérifier les pics et de les comparer au trafic et à vos objectifs :
- les pages les plus explorées
- les pages les moins explorées
- ressources les plus explorées (pas les pages)
- fréquences de crawling par type de fichier
- impact des codes de statut 3xx / 4xx
- impact des codes d’état 5xx
- pages les moins explorées
- …
Vous voulez aller plus loin ? Bien… vous devez ajouter des données. Et Oncrawl offre un outil vraiment puissant, le Data Explorer.
Comme vous pouvez le voir dans la capture d’écran précédente (pages actives non explorées), vous pouvez créer tous les rapports que vous voulez en fonction de votre cadre d’analyse.
Par exemple:
- les pires pages de trafic organique avec beaucoup de crawl par les bots
- les meilleures pages de trafic organique avec trop de crawl par les bots
- pages plus lentes avec beaucoup d’impressions SERP
- …
Ci-dessous vous pouvez voir comment j’ai vérifié quelles sont les pages les plus crawlées par rapport à leur nombre de sessions SEO :
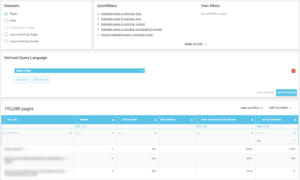
Points à retenir
L’analyse des logs n’est pas strictement technique : pour la réaliser de la meilleure façon possible, nous devons combiner des compétences techniques, en SEO et en marketing.
Trop souvent, l’analyse est exclue d’une « liste de contrôle SEO » parce que notre client n’a pas accès aux fichiers de logs ou parce qu’il s’agit d’une analyse coûteuse.
En réalité, les logs sont les seules sources permettant de vérifier réellement où vont les bots sur nos sites, et de savoir comment nos serveurs y répondent.
Un outil comme Oncrawl peut réduire considérablement les exigences techniques : il suffit de télécharger les fichiers de logs et de commencer à les analyser !
