
Dans le webinaire « Chaînes et boucles de redirection » du 20 novembre dernier, Erlé Alberton, Customer Success Manager chez Oncrawl, présentait les moyens d’utiliser Oncrawl pour gérer les redirections sur un site.
Retrouvez le replay sur YouTube, ou suivez ci-dessous les points clés du webinaire.
Qu’est-ce qu’une redirection ?
Les redirections sont des status codes HTTP qui indiquent que le contenu de la page se trouve sur une autre URL. Cela comprend les redirections spécifiques suivantes :
- 301 : redirection permanente
- 302 : redirection temporaire
- 307 : redirection temporaire qui force le navigateur à refaire la demande de la nouvelle URL à l’identique à la demande de l’ancienne URL
À noter : Oncrawl a pu constater grâce aux crawls de millions de sites web que la redirection 302 consomme du budget de crawl pendant que Google détermine si la temporalité est terminée. Préférez donc des 301 si vous souhaitez minimiser le budget crawl consommé.
Comment Google gère-t-il les redirections ?
Selon Google, les redirections font partie de la vie d’un site. Elles transmettent de PageRank à leur cible, et ne posent des problèmes que lorsqu’elles apparaissent en cascade.
IMO SEOs fuss too much about redirects. Use the right one for the job, it’s a technical thing, not a SEO thing; it’s not voodoo magic.
— ? John ? (@JohnMu) September 29, 2016
all redirects pass PageRank now
— Gary « 鯨理 » Illyes (@methode) September 28, 2016
“À mon avis, les SEOs font trop de bruit autour des redirections. Utilisez la bonne redirection pour son cas, c’est une manoeuvre technique, pas SEO. Ça n’a rien de mystérieux !
— John Mueller
« Le PageRank est désormais transmis par les toutes les redirections. »
— Gary Illyes
« Nous suivons jusqu’à 5 [redirections] dans une chaîne (merci de limiter autant que possible les chaînes de redirection), mais vous pouvez rediriger simultanément autant d’URLs de votre site que vous le souhaitez. »
— Explication donnée dans un webinaire de Google.
Néanmoins, les données Oncrawl permettent de constater que le nombre maximum de redirections suivies par Google se situe plutôt autour de 16.
Qu’est-ce qu’une chaîne et comment cela se produit ?
Une redirection devient une chaîne lorsqu’elle pointe vers une URL cible qui est elle-même une redirection vers une autre URL.
Une chaîne peut apparaître dans les cas suivants :
- Lors d’une correction de titre d’article, si les URLs sont basées sur les titres des articles
URL d’origine -> correction de titre -> renvoi vers la nouvelle URL 2 -> correction de titre -> renvoi vers la URL 3
Ce qui se passe : votre CMS crée souvent une redirection automatique à chaque fois que vous modifiez le titre. Ou, si vous paramétrez manuellement les modifications comme règles dans le fichier htaccess, il se peut que la version d’origine reste dans le fichier.
Un conseil : partez toujours de l’existant pour établir les nouvelles règles, puis modifiez les anciennes règles pour pointer directement vers l’URL 3.
- À la suite de multiples refontes de site.
URL d’origine -> refonte -> URL 2 -> refonte -> URL 3…
Ce qui se passe : lors d’une refonte, des règles de redirection sont inscrites dans le fichier htaccess. Quelques mois plus tard, une partie du site est à nouveau réaménagée. Les nouvelles règles s’ajoutent aux anciennes dans le fichier htaccess, créant des redirections en cascade.
- Migration HTTPS ou un changement de nom de domaine
URL http (sans www) -> URL http (avec www) -> URL https (sans www) -> URL https (avec www)
URL http (sans www) -> URL https (sans www) -> URL https (avec www)
URL http (avec ou sans www) -> URL http (ancien slug) -> URL http (nouveau slug) -> URL https (nouveau slug)
URL http (avec ou sans www) -> URL https (ancien slug) -> URL https (nouveau slug)- Ce qui se passe : les URLs sont redirigées selon vos règles vers la bonne URL. Souvent, cela comprend déjà une étape de redirection, automatique (dans le cas des sous-domaines en www) ou non (lorsque vous avez ajouté une règle pour corriger une URL), avant et/ou après la redirection HTTP en HTTPS.
Qu’est-ce qu’une boucle et comment se crée-t-elle ?
Une boucle de redirections est une chaîne qui se referme. L’un des maillons de la chaîne est redirigé vers une URL qui fait déjà partie de la chaîne. Après environ 20 redirections, ce qui arrive rapidement dans une boucle, l’utilisateur ne voit pas la page.
Quelles statistiques sont disponibles dans Oncrawl ?
Dans le Crawl report, Oncrawl présente 5 graphiques principaux sur l’état des redirections de votre site. Les graphiques se trouvent dans Indexability, puis Status codes.
![]()
![]()
1. Distribution des status codes HTTP pour tout le site
Ce graphique existe depuis longtemps chez Oncrawl et permet de suivre le pourcentage de pages redirigées (avec status codes de 3xx) sur le site.
2. Tableau résumé de toutes les redirections.
Pour chaque configuration de redirection, ce tableau résume le nombre de pages impliquées mais surtout le nombre de liens qui pointent vers les pages dans la boucle ou chaîne de redirection.

Il y a plusieurs types de redirection:
- Single redirects : des redirections simples d’URL A vers URL B, et aucune autre redirection n’a lieu. Les redirections simples ne posent pas de problème pour votre SEO. Elles peuvent servir pour conserver la PageRank reçue sur l’ancienne URL si vous avez un backlink qui y pointe. Faites attention aux liens internes qui pointent vers la « mauvaise » partie de la redirection : il suffit de les mettre à jour pour les faire pointer vers l’URL finale.
- Pages in 3xx chain : une série de 2 redirections ou plus. Elles sont évaluées de bout en bout. On donne le nombre de pages concernées et le nombre de liens qui pointent vers une partie de la chaîne. En cliquant sur les chiffres, vous découvrez les URLs concernées. Ensuite, c’est à vous de les corriger pour faire pointer les liens vers l’URL finale.
- Pages in 3xx chains with too many redirects : des chaînes avec trop d’itérations. Oncrawl s’arrête après 500 redirections !
- Pages inside a 3xx loop : des boucles, qui se crée lorsque l’une des pages de la chaîne est redirigée vers une autre page de la chaîne. Par conséquent, il n’y a pas de page finale dans la série de redirections.
- Pages that are 3xx final targets : pages vers lesquelles une redirection existe mais qui ne redirigent pas elles-mêmes vers une autre page. Si la page cible finale est interdite au crawl, elle n’est pas comptée dans ces statistiques : à vous de déterminer les raisons spécifiques.
3. Représentation de l’état final des redirections
Ce graphique permet de répondre à la question : une fois qu’Oncrawl a fini de crawler toutes les étapes de la boucle ou de la chaîne, quel est le statut de la page de destination finale ?
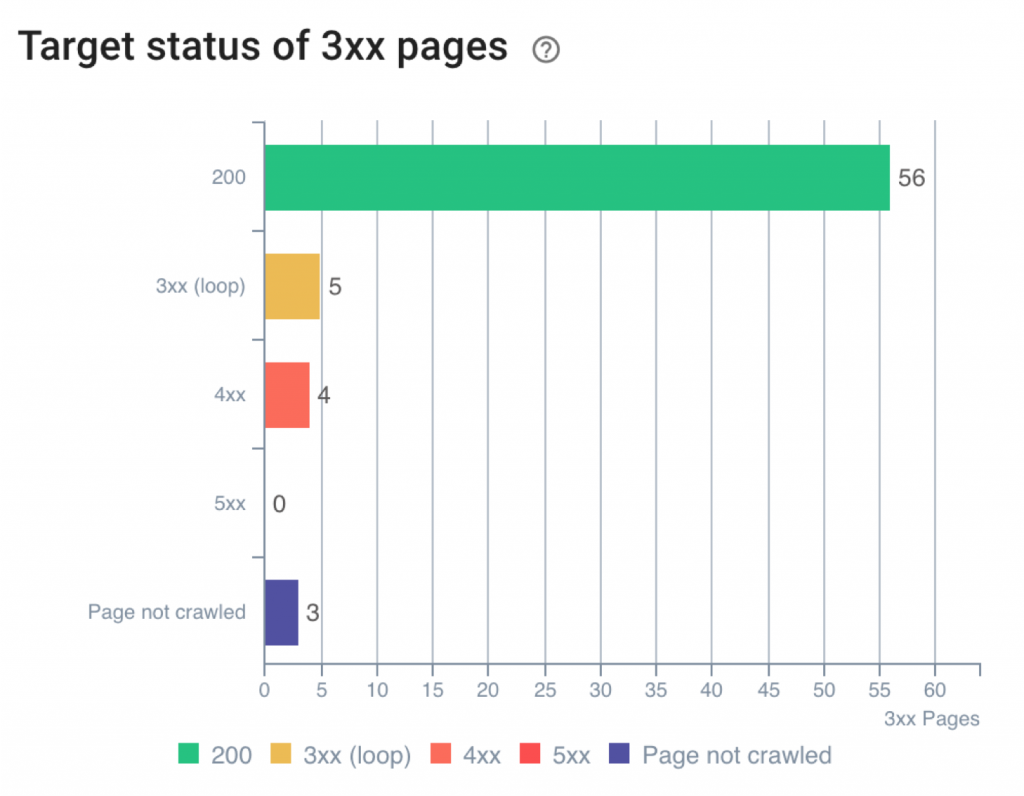
Le graphique présente les réponses possibles :
- 200 : la page finale fonctionne
- 3xx (externe) : la page finale se trouve sur un autre site, mais est elle-même redirigée
- 4xx : la page finale ne peut pas être trouvée
- 5xx : la page finale retourne une erreur du serveur
- Not crawled : le bot Oncrawl n’a pas pu trouver la page : elle se trouve peut-être dans un sous-domaine non crawlé ou est en robots denied dans le fichier robots.txt
Les pages en 3xx, 4xx et 5xx peuvent être vraiment intéressantes à corriger.
Commencez par les 4xx et 5xx (pages en erreur) avant de procéder aux pages en 3xx (ce sont les pages dans des chaînes ou boucles).
4. Répartition de status code par groupe de pages et par profondeur
Ce graphique se présente soit par groupes de pages, soit par profondeur. La version par groupes de pages donne la possibilité d’utiliser la segmentation d’Oncrawl, qui peut catégoriser les pages selon n’importe lesquelles des métriques Oncrawl.
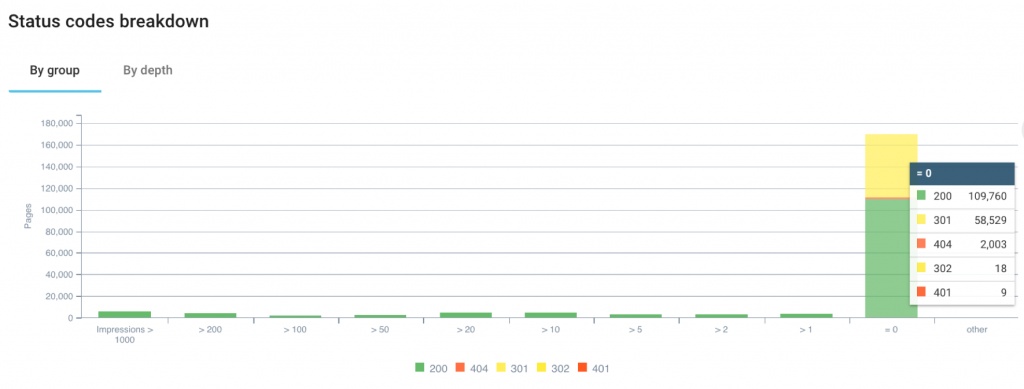
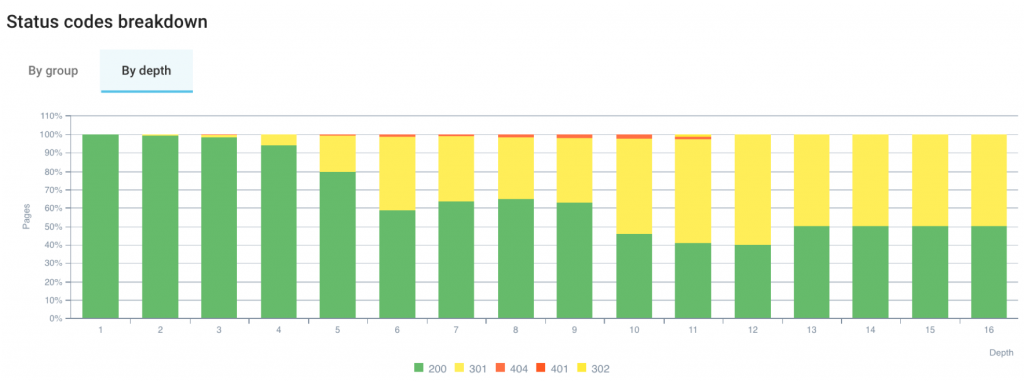
Quelques exemples :
- En utilisant une segmentation sur les pages qui rankent ou ne rankent pas :
Quelle est la proportion de status code 4xx ou 5xx dans mes pages que ne rankent pas ? - Avec une segmentation sur le nombre d’impressions dans GSC :
Est-ce qu’il y a des pages qui font zéro impression qui sont affectées par une chaîne dont la cible finale ne répond pas en 200 ?
Dans le deuxième onglet, on voit la distribution de status code en fonction de la profondeur du site. En général, si la profondeur augmente, le nombre de redirections augmente aussi.
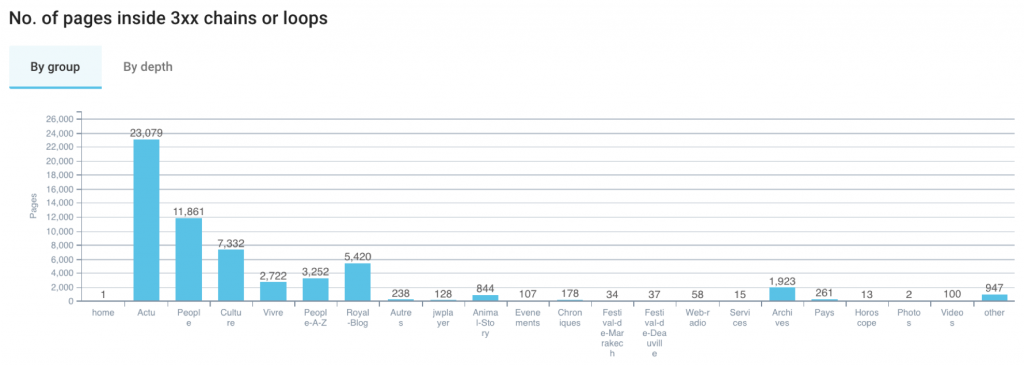
5. Répartition des pages inscrites dans les boucles ou les chaînes par groupe de pages et par profondeur
Ce graphique s’ajuste selon la segmentation que vous aurez choisie.
Ce graphique-ci est également visible par profondeur pour que vous puissiez voir où sont localisées les pages qui font partie des boucles et des chaînes de redirection.
Actions à entreprendre pour gérer ses redirections

- 1. Lister les pages concernées
Pages de destination finale d’une boucle ou dans une chaîne. Cela vous donnera une bonne notion des pages à corriger ou à interdire au crawl.
Priorité 1 : Pages dans une boucle. Les boucles sont les plus importantes à corriger.
Priorité 1 : Pages dans une chaîne avec trop de redirections. Comme les boucles, la correction des chaînes trop longues est une priorité absolue.

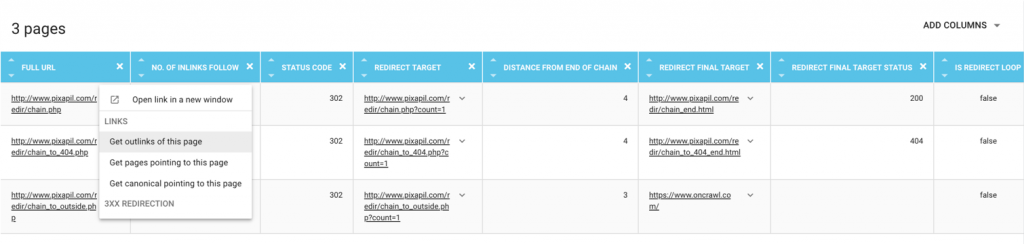
- 2. Changer les liens vers les pages impliquées
Les liens peuvent être mis à jour pour pointer vers la page finale de la chaîne, ou passés en « nofollow » pour interdire le crawl.
Priorité à définir selon votre cas : Liens vers pages de destination finale d’une chaîne. Cela vous donnera une bonne notion des pages à corriger ou à interdire au crawl.
Priorité 1 : Liens vers pages dans une boucle. Les boucles sont les plus importantes à corriger.
Priorité 1 : Liens vers pages dans une chaîne avec trop de redirections. Comme les boucles, la correction des chaînes trop longues est une priorité absolue.
Priorité 2 : Liens vers pages dans une chaîne.
Priorité 3 : Liens vers pages avec une seule redirection vers la page cible finale.
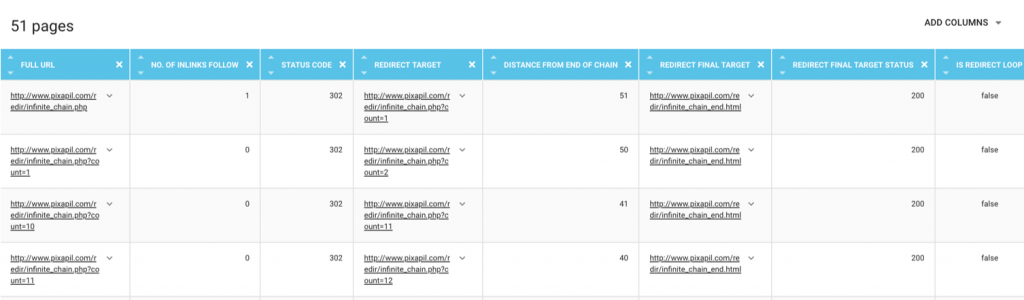
Comment lister les pages ou les liens impliqués dans une redirection ?
Lorsque vous cliquez sur un métrique dans Oncrawl, vous arrivez directement dans le Data Explorer avec un filtre pré-réglé pour donner le détail de l’information sur laquelle vous avez cliquée.
Par exemple, en cliquant sur le nombre de pages qui ne sont pas dans une boucle mais dans une chaîne avec trop de redirections, nous arrivons directement au rapport complet des URLs concernées. Vous pouvez moduler le filtre pour qu’il vous donne toutes les pages qui sont dans une boucle, par exemple.
De la même façon, vous êtes en mesure d’explorer tous les liens qui pointent vers une page : par exemple, pour toutes les pages redirigées, le QuickFilter « Pages pointing to 3xx errors » vous donne tous les liens qui pointent vers des pages redirigées.

Pour ceux qui utilisent l’API Oncrawl, vous avez également un moyen de lister tous les liens qui pointent vers toutes les pages par des requêtes croisées. Nous n’entrerons pas dans le détail ici mais vous pouvez tous les obtenir par type de redirection, avec les ancres et éventuellement mesurer le jus qui y passerait.
Comment tester la redirection sur votre site sans lancer un crawl ?
Vous pouvez obtenir un premier diagnostic avant même de lancer le crawl.
Il est conseillé de tester sa Start URL avant de crawler. Oncrawl valide automatiquement le statut de votre Start URL dès que vous la saisissez dans les paramètres du crawl. Si votre Start URL n’est pas validée, il peut s’agir de plusieurs cas de figure.

- Votre page Start URL est redirigée. Il s’agit d’un cas assez particulier. Pour Erlé, s’il doit crawler un site, il prend forcément l’URL du domaine. Même si Oncrawl dit que cette URL « semblerait être redirigée… » il forcerait l’utilisation de cette URL, car il reste très intéressant d’analyser le site dans ce cas de figure. L’alerte sur la redirection d’une Start URL n’est pas une erreur. Il s’agit simplement d’une information.
- Votre page Start URL renvoie une erreur. Par contre, il est possible de mettre une page qui renvoie une erreur comme Start URL. Dans ce cas, le crawler ne peut pas procéder.
- Votre start URL est dans une boucle. Dans ce cas, Oncrawl vous informe que le crawl ne sera pas possible. Oncrawl ne peut pas déterminer une page cible finale pour la première URL, car vous pointez déjà vers une boucle.
Pour aller plus loin
Analyser vos redirections avec la bonne segmentation
« Status codes breakdown » : repartition de status code final par groupe
Une optimisation SEO part toujours de la possibilité d’une page de faire plus d’impressions. En appliquant une segmentation des pages par tranche d’impressions GSC, on voit des pages qui font 0 impression GSC sur les 45 derniers jours. Cela nous permet de constater qu’une partie de ces pages sont en 3xx et 4xx.
Vous pouvez tout à fait utiliser une autre segmentation pour mieux voir d’autres caractéristiques de données.
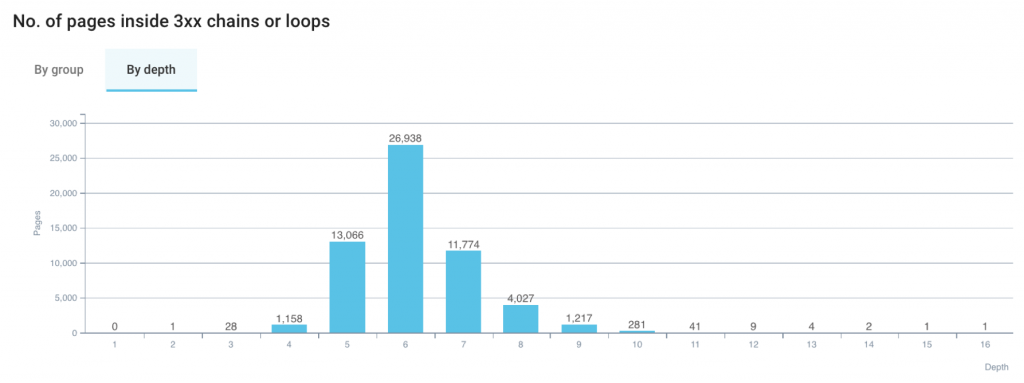
« No. of pages inside 3xx chains or loops » : répartition des pages inscrites dans les boucles ou les chaînes
Ce graphique fournit un résumé du nombre de pages qui sont impactées. Encore une fois, cela s’organise par groupe, ou encore par profondeur.
Par groupe, on peut estimer le type de groupe qui est le plus impacté par les boucles et les chaînes de redirections.
En changeant d’onglet, on est capable de voir à partir de quelle profondeur les pages apparaissent dans les boucles et dans les chaînes. Mais ce n’est pas pour autant qu’on perd l’intérêt de la segmentation.
Si vous avez la segmentation par URL qui est fournie par défaut dans Oncrawl, filtrez dans le deuxième filtre de segmentation pour cibler un groupe en particulier, puis descendez à ce graphique pour comprendre quelle est la répartition pour ce type de pages dans votre architecture.
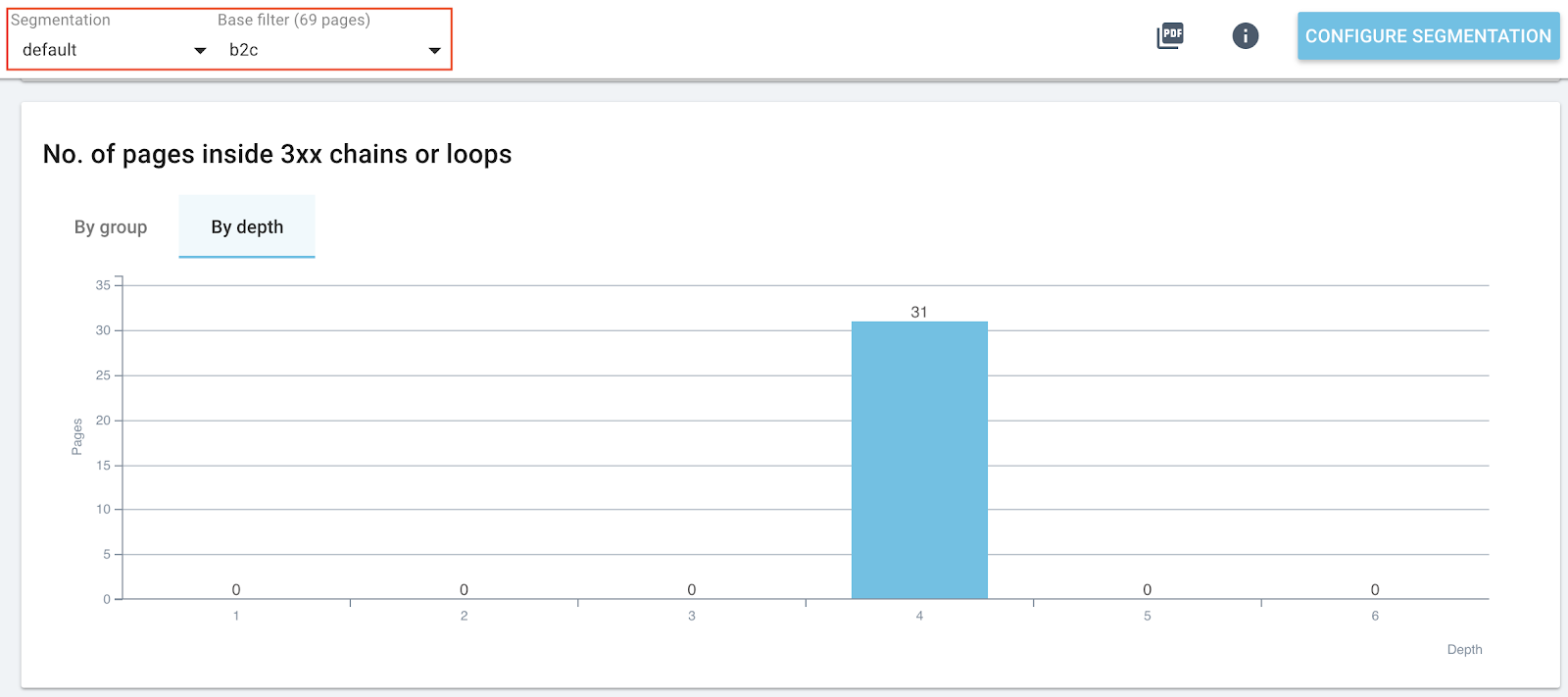
Souvenez-vous qu’une page qui est peu profonde a plus de possibilités d’être indexée qu’une page qui est plus profonde. Cette stratégie permet de porter un focus sur le groupe le plus important pour le site et sur les pages les plus hautes dans l’architecture, pour pouvoir prioriser les actions.
Adapter vos rapports et vos segmentations
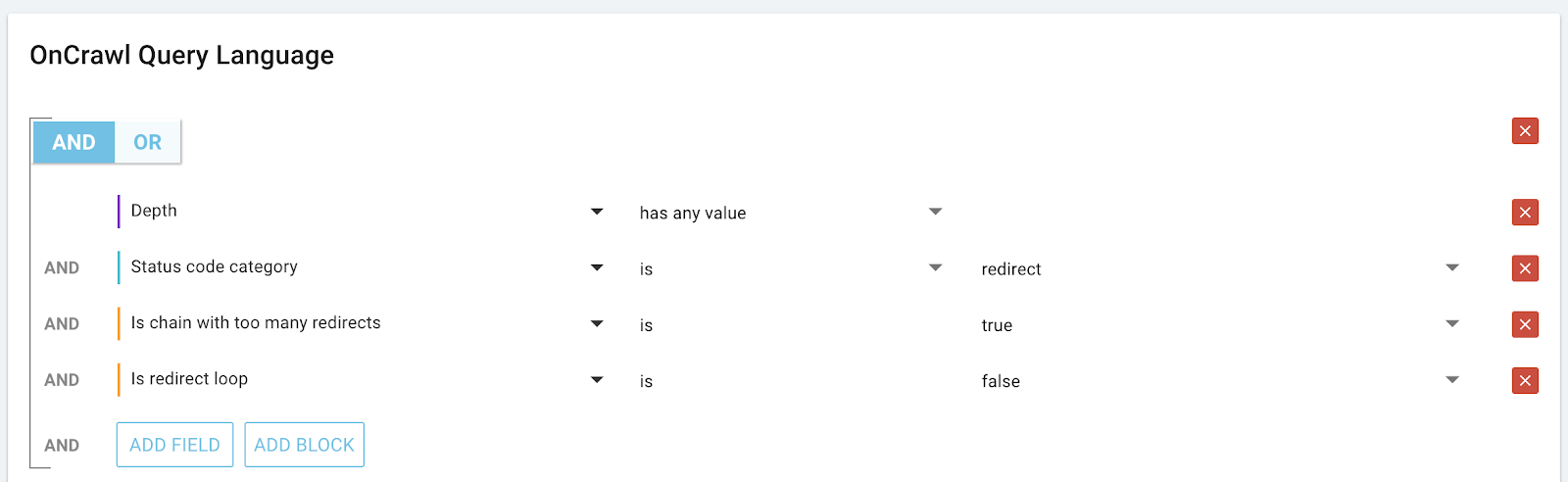
Oncrawl est basé sur des métriques. Comme toutes les métriques, les métriques issues de l’analyse sur les redirections sont disponibles dans le Data Explorer.
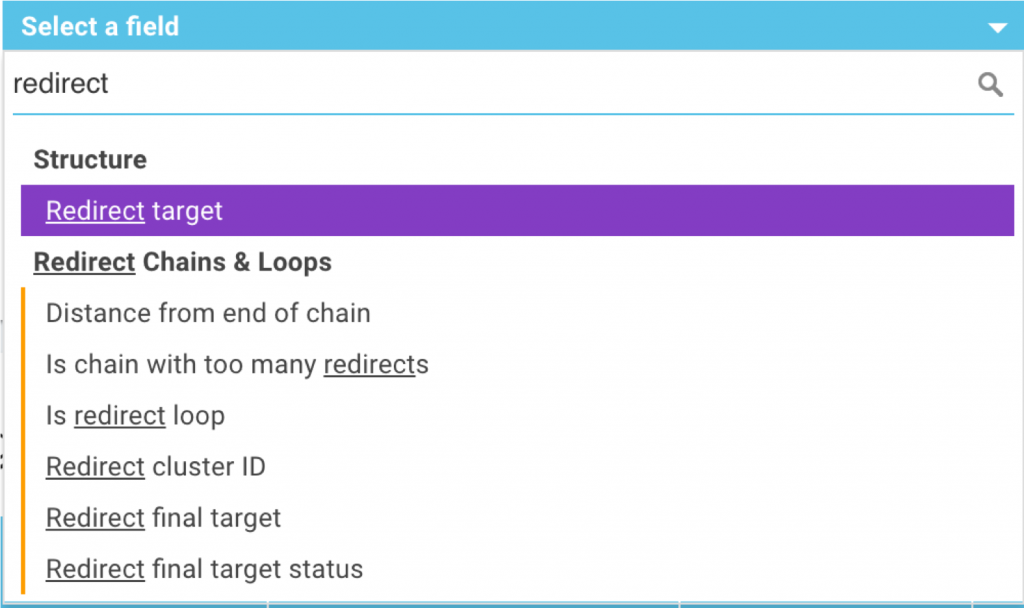
Vous pouvez ajouter à vos rapports :
– La page cible de la redirection
– La distance en nombre de redirections jusqu’à la fin de la chaîne
– Une indication si la page se trouve dans une chaîne avec trop de redirections
– Une indication si la page se trouve dans une boucle de redirections
– Le nombre d’identification du « cluster », ou d’un ensemble. Toutes les pages qui appartiennent au même cluster se trouvent dans la même chaîne ou boucle de redirections.
– La page cible finale dans une chaîne et son statut HTTP
Vous pouvez également utiliser ces métriques pour créer des segmentations Oncrawl. Par exemple, cela permettrait de catégoriser les pages avec redirections par le nombre de redirections dans la chaîne, ou encore de cibler les chaînes les plus grandes et les plus petites. On peut également voir les caractéristiques des pages selon leur distance par rapport à la fin de la chaîne : 1 redirection, 2-5 redirections, 6-10, 11-20, plus que 20…
Vérifier la représentation graphique des redirections dans « URL Details »
L’explorateur des détails par URL contient des informations sur la chaîne de redirection d’une page.
Depuis la Data Explorer, vous pouvez cliquer sur une URL pour retrouver plus de détails, y compris les infos des redirections.
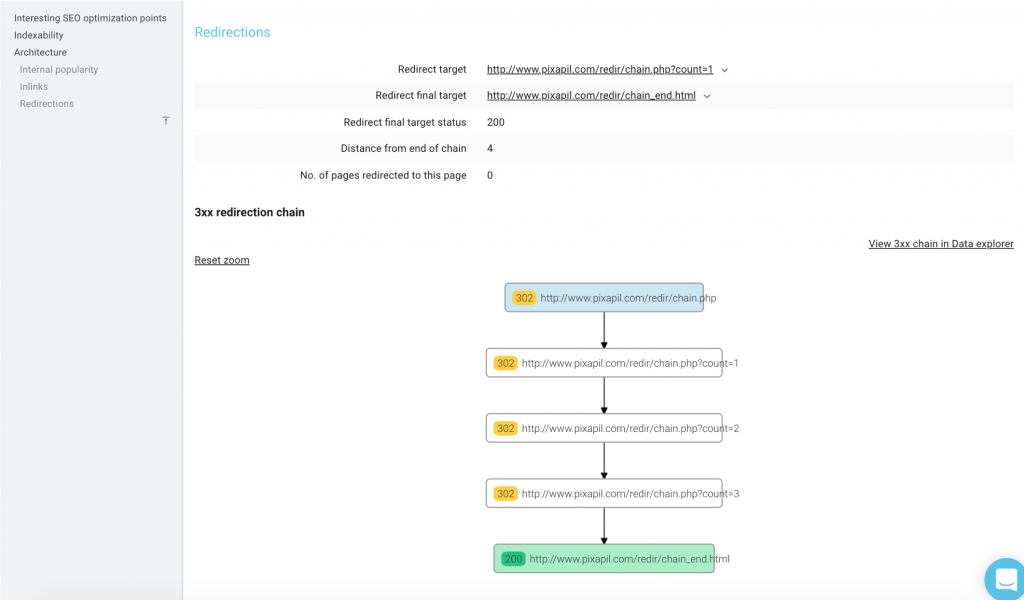
Sur la page URL Details, il y a de nombreuses informations sur les redirections concernant cette page. Il y a aussi une représentation visuelle de la chaîne de redirections qui représente :
– l’entrée de la chaîne
– le statut de chaque page de la chaîne
– la cible finale (en vert)
– l’URL actuelle
Ce visuel est également disponible pour les boucles. Les status codes et l’enchaînement sont représentés de la même manière que pour les chaînes.
Quelques bonnes pratiques
Pendant le webinaire, Erlé a partagé les astuces suivantes :
- Chaque maillon de la chaîne doit pointer vers l’URL ciblée !
- Chaque lien vers un maillon doit pointer vers l’URL ciblée !
- Corrigez d’abord les boucles, puis 4xx et 5xx
- Configurez votre crawl avec une Start URL la plus haute possible
- Lors des refontes / migrations, créez des configurations de crawl qui ont pour Start URLS les 100 règles de redirections présentes dans vos htaccess et lancez des crawls régulièrement (1 fois par semaine) pour vérifier que votre politique de redirection est toujours en place.
- Assurez-vous de réduire les redirections en cascade à 1 seule redirection (pensez aux backlinks!)
Des SEOs connus sont allés plus loin pendant la discussion sur Twitter en partageant leurs bonnes pratiques préférées :
However we should aim at redirecting to the final URL without additional chains.
— Maria Cieślak (@McCieslak) November 22, 2018
« On devrait tâcher de rediriger vers l’URL finale sans chaîne additionnelle. »
— Maria Cieslak
Yeah, aim for direct-to-target redirects. Redirects slow things down, especially on mobile, especially cross-host. We crawl 5 chained in one go, and take it from there the next time we crawl. Crawlers are great at spotting these issues for you!
— ? John ? (@JohnMu) November 22, 2018
« Oui, les redirections doivent pointer directement vers la cible. Les redirections ralentissent tout, surtout sur mobile, et plus particulièrement lorsqu’il y a plusieurs hôtes. On crawle 5 URLs en chaîne d’un coup, puis on reprend la prochaine fois qu’on vient crawler. Les crawlers sont idéaux pour vous aider à identifier ces problèmes. »
— John Mueller
It’s also key to look for the causes of chains 1) site launches 2) automated redirect tools (i.e. when a URL is altered) and 3) an active content team.
ID’ing and fixing is relatively easy when you’re looking, however it’s most cost effective to address as point of process
— Chris Green (@chrisgreen87) November 22, 2018
« C’est également important de chercher la cause des chaînes. 1) lancements de site 2) outils de redirection automatique (par ex. lorsqu’une URL est modifiée) et 3) une équipe de contenu active. Identifier et corriger les chaînes est plutôt facile,, mais c’est encore plus rentable si vous corrigez votre process. »
— Chris Green
– not blocking them in robots.txt unless they are to affiliates …
– test the crap out of any rules, as something will become a loop
– test them with cookies stuff full, as this can sometimes be an issue
– don’t worry about a few minor issues … but try and fix sitewide stuf— Gerry White ⁉️ SEO geek (@dergal) November 22, 2018
Ne pas bloquer les redirections dans robots.txt sauf si elles vont vers un partenaire…
Tester à fond toutes les règles
Tester les règles avec les cookies, cela peut parfois poser des problèmes
Ne pas se soucier des petites choses… mais essayez de corriger les problèmes concernant tout le site
— Gerry White
Make sure internal links point to final redirection targets. :D
— Señor Muñoz (@senormunoz) November 22, 2018
« Vérifiez que les liens internes pointent vers les cibles finales des redirections :D »
— Señor Muñoz
My answer is here: https://t.co/rsrXsZLsl6
Basically, I hate them ??
— Omi Sido (@OmiSido) November 22, 2018
« Voir mes conseils ici. En gros, je les déteste. »
— Omi Sido
Something people do not sometimes think about is redirecting images while working on their website redesign. ?
— Alice Roussel (@aaliceroussel) November 22, 2018
« Une chose que les gens ne prennent souvent pas en compte lors d’une une refonte : les redirections pour les images. »
— Alice Roussel
especially if the site has 1M+ urls, crawling can become tricky so we need to avoid redir chains asap by regularly monitoring site health via automated crawl analyses
— Murat Yatagan (@muratyatagan) November 22, 2018
« Surtout si le site possède +1M URLs, crawler peut devenir assez difficile. Il faut éliminer les chaînes de redirection dès que possible par le suivi régulier de la santé du site par analyse avec crawl automatisé »
— Murat Yatagan
Comment s’informer sur les redirections dans Oncrawl ?
Les slides du webinaire sont disponibles sur Slideshare.
Si vous êtes intéressé par cette fonctionnalité, elle est inclue de base dans les crawls Oncrawl. Il vous suffit d’avoir lancé un crawl après la sortie de la fonctionnalité.