
Notre fonctionnalité de Crawl over Crawl vous permet de comparer deux crawls différents et de souligner des évolutions.
Lors de sa sortie en 2016, cette mise à jour faisait suite aux Trends qui vous permettaient de détecter des tendances globales entre vos crawls. Vous pouvez désormais accéder à une vue complète de vos améliorations SEO et mettre en avant des différences entre crawls sur un thème donné. La mise à jour Crawl over Crawl a intégré de nouveaux types de graphiques pour lire ces données.
En 2019, la fonctionnalité Crawl over Crawl a évolué ! Vous pouvez désormais comparer :
- Deux versions d’un site web qui comprennent le même ensemble de pages, comme des versions en production vs. pré-production ou des versions mobile vs desktop.
- Un seul site web à deux moments dans le temps, par exemple avant et après une évolution du site web.
Comparer deux versions d’un site web
Pour comparer deux sites web, Oncrawl examine les Start URLs que vous avez indiquées pour les deux crawls afin d’établir les différences entre les adresses des deux sites. Oncrawl part de l’idée que les deux versions contiennent la même contenu (ou presque). Par conséquent, la plupart des slugs des URLs doivent correspondre dans les deux domaines, dossiers ou sous-domaines que vous souhaitez comparer.
Voici quelques exemples de sites qui sont pris en charge par le comparaison automatique :
| Cas d’usage | Crawl 1 – Start URL | Crawl 2 – Start URL |
|---|---|---|
| Production vs Pré-Prods | https://www.exemple.fr | http://staging.exemple.fr/site/ |
| Desktop vs Mobile | https://www.exemple.fr | https://m.exemple.fr |
| Versions régionaux | https://www.exemple.com/fr-fr/ | https://www.exemple.com/fr-ca/ |
| Versions régionaux | https://www.exemple.fr | https://www.exemple.ca |
D’autres différences complexes entre les Start URLs sont également possibles, même lorsqu’elles ne sont pas prises en compte automatiquement. Dans ce cas, vous êtes alerté par un message lors de la mise en place du Crawl over Crawl. N’hésitez pas à nous contacter par le chat de l’interface pour que nous puissions intervenir manuellement dans votre cas spécifique.
Comparer un site web à deux moments dans le temps
Pour comparer un seul site web à deux moments différents, par exemple avant et après une amélioration ou une évolution majeure, vous aurez besoin de fournir :
- Des Start URLs identiques
- Un étendu de crawl identique (règles d’exploration de sous-domaines…)
Comment mettre en place un Crawl over Crawl ?
Vous pouvez mettre en place un Crawl over Crawl entre deux crawls existants, ou bien demander une comparaison avec un crawl précédent lors de la création d’un nouveau crawl. Pour plus d’informations sur la création d’un Crawl over Crawl, consultez la base de connaissances d’Oncrawl.
Comment lire un sunburst ?
Un sunburst se lie comme un diagramme circulaire habituel. Ces graphs sont très utiles pour suivre l’évolution d’un site web, crawl après crawl ou pour vérifier les différences entre deux versions d’un site (entre une prod et une dev par exemple).
Ce graph à plusieurs niveaux vous permet de comparer deux crawls sur un thème précis :
- Le premier niveau et le cercle le plus à l’intérieur : montre les pages appartenant au premier crawl (et au plus ancien) ;
- Le deuxième niveau et cercle à l’extérieur : montre les pages du second crawl (le plus récent) en fonction de chaque segment du premier cercle.
Vous pouvez ainsi par exemple facilement trouver des pages indexables dans le premier crawl qui ne sont plus dans le second et vise versa.

Dans ce graph, le cercle interne montre la répartition des pages du point de vue du premier crawl. Vous pouvez voir qu’il y a des pages indexables, non indexables et des pages qui n’étaient pas dans le premier crawl mais qui sont apparues dans le second (la section grise).
Ensuite, pour chaque section du cercle, vous pouvez voir la répartition des pages d’une section donnée dans le second crawl. La section grise interne signifie que ces pages n’existaient pas dans le premier crawl mais sont arrivées dans le second (les sections vertes et rouges extérieures appartenant à la section grise interne).
Les sections grises signifient que les pages sont soit nouvelles ou inexistante dans la structure en fonction de leur position sur le graph.
En cliquant sur la légende, vous pouvez décider quelle données vous souhaitez afficher. Le crawl 2 offre une vue plus globale.
Jetons un oeil au cercle le plus à l’intérieur.
La distribution de pages dans le premier crawl en fonction de leur indexabilité

Le premier crawl contient 10 854 pages indexables et 177 pages non indexables. 1661 pages ont seulement été trouvé dans le second crawl.
Regardons maintenant le cercle externe. Pour chaque segment du premier cercle, nous avons la distribution de ces pages dans le second crawl.

Au sein des 10 854 pages indexables du premier crawl, seulement 10 104 le sont toujours dans le second, 560 sont maintenant non indexables dans le second crawl et 190 n’existent plus dans le crawl 2.
Concentrons nous sur une petite section : les pages non indexables du premier crawl
En cliquant sur les éléments de la légende, il est possible de cacher les pages indexables et les pages du premier crawl ainsi que les pages qui n’était pas présents dans la structure du site web en ce moment-là.

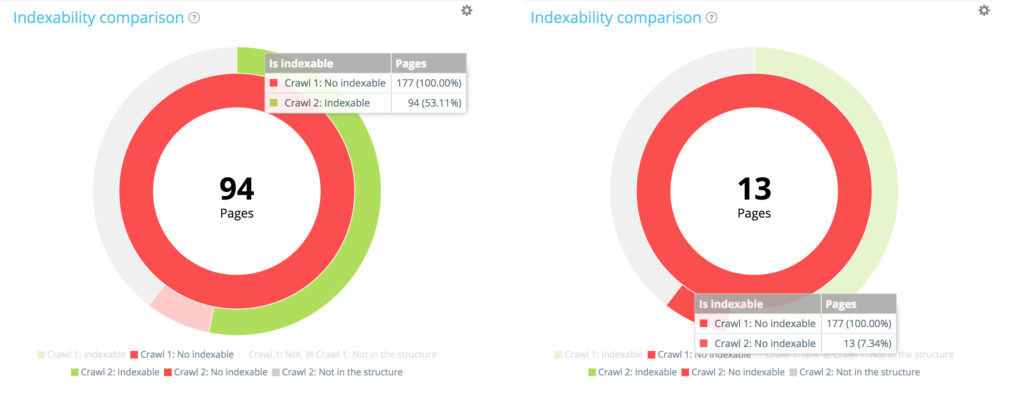
Au sein des 177 pages non indexables du premier crawl, 94 sont maintenant indexables et 13 restent indexables dans le deuxième crawl.

Au sein des 177 pages non indexables du premier crawl, 70 ne se trouvent plus dans le second crawl. 94 + 13 + 70 = 177. Nous retrouvons comme attendu la répartition des 177 pages non indexables trouvées dans le premier crawl.
Focus sur les nouvelles pages : les pages seulement trouvées dans le second crawl
Ensuite, utilisez la légende pour cacher les pages indexables et non-indexables du premier crawl. Ainsi, sont visibles uniquement les pages qui ne faisaient pas partie du site web au moment du crawl 1. Cela vous permet de voir le statut de nouvelles pages en terme d’indexation.

Toutes les nouvelles pages : 1 661 pages.
Au sein des 1 661 pages nouvellement créées, 709 ne sont pas indexables.
Au sein des 1661 pages nouvellement créées, 952 sont indexables.
Résumé : toutes les pages du second crawl

10 104 pages étaient indexables dans le premier crawl. 11 150 sont maintenant indexables dans le deuxième. 177 pages n’étaient pas indexables dans le premier crawl mais 1282 le sont maintenant dans le second.
1661 pages ont été créé. 260 pages ont été supprimées de la structure.
Les données Crawl over Crawl disponibles
Cette nouvelle fonctionnalité est divisée par expertise métier et entre les onglets suivants :
- Structure
- Internal linking
- Content
- Status Codes
- Performance
Par exemple, dans la section ‘Content’, vous pouvez accéder à une vue centrée sur l’évolution des duplications entre crawls :

Vous pouvez également analyser comment la profondeur des pages a évolué entre deux crawls. Dans le graphique ci-dessous, vous pouvez voir des mouvements de profondeur :

Par exemple, si nous regardons la profondeur 5, nous pouvons voir des pages qui sont parties vers des profondeur plus ou moins éloignées ou des pages venant de profondeur plus ou moins éloignées entre le crawl 1 et 2. Ici, 264 pages étaient dans le crawl 1 et à la profondeur 5 et sont parties vers des profondeurs moindres (4, 3 ou 2).
Cela vous donne une première idée de ce qui est disponible. Notre Data Explorer vos permet de découvrir plus de 700 métriques pour la comparaison.

Je viens de voir cette mise à jour chez un client c’est vraiment bien un grand bravo à toute l’équipe
Merci pour ce retour Fabien !
[…] vous n’avez pas encore lu notre guide sur comment lire un sunburst, il n’est pas trop tard […]