
Oncrawl est heureux d’annoncer que la migration progressive de tous ses utilisateurs vers son nouveau crawler a eu lieu pendant la période de février à mars 2019. Notre aspect favori de la nouvelle technologie de crawl Oncrawl ? La vitesse incomparable !
Nous avons aussi profité de cette mise à jour majeure pour inclure une constellation de nouveaux éléments, dont le monitoring en temps-réel des détails de crawl et l’extension des données pour l’analyse des liens et des pages non-indexables.
Nouveau crawler, fonctionnalités de crawl identiques
Cette amélioration majeure du crawler Oncrawl produit des résultats de crawl identiques. Tous les tableaux de bord, fonctionnalités et données disponibles sont complètement pris en charge par notre nouveau crawler.
Ainsi, vous pouvez comparer des crawls réalisés avec l’ancienne version du crawler avec les crawls plus récents sans crainte d’avoir de données faussées et sans devoir procéder à des ajustements.
Il n’y a aucune différence dans les tableaux de bord et graphiques Oncrawl. Leur aspect et les calculs utilisés pour les produire n’ont pas changé. La modification du crawler ne produit pas de chiffres différents dans les graphiques.
Vitesse astronomique : crawl plus rapide
Pour un décollage plus rapide
Vos crawls décollent désormais avec un compte à rebours plus court et une base de lancement plus puissante.
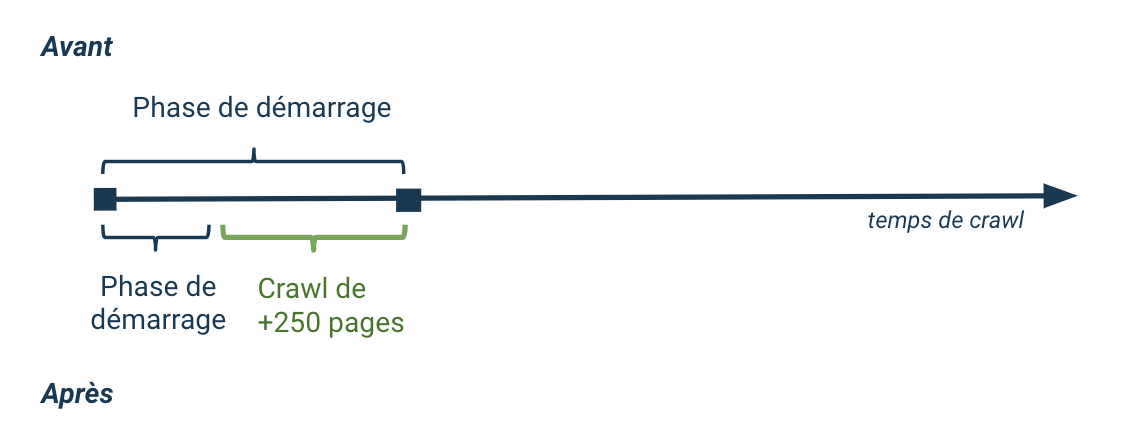

Non seulement la phase d’initialisation du crawl prend beaucoup moins de temps mais vous pouvez aussi utiliser la nouvelle version de la page de monitoring de crawl pour voir ce qu’il se passe pendant cette période, avant que les premières pages soient crawlées.
Sur la page de monitoring de crawl, vous pouvez suivre la progression des différentes tâches de pre-crawl et ensuite analyser des nombres précis, rafraîchir en temps réel, vous permettant de savoir exactement ce que le crawl fait et comment il le fait.
Une vitesse de crawl plus rapide
Vos crawls bénéficient également d’un coup de boost de leur vitesse. Les plus grands sites vont voir une réduction de temps conséquente lors de leur crawl. Même les sites avec moins de 1000 pages pourront voir une vitesse de crawl multipliée par 8.
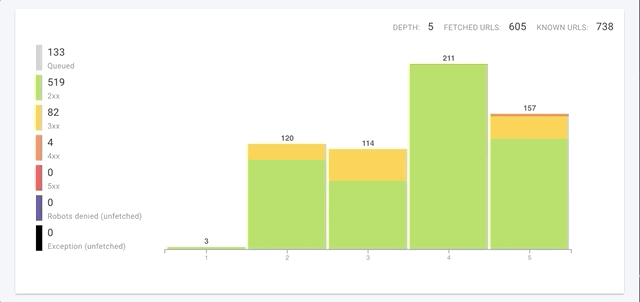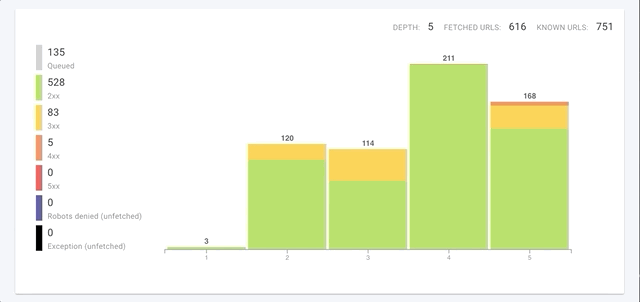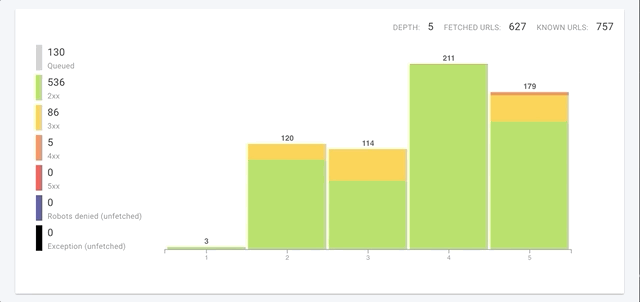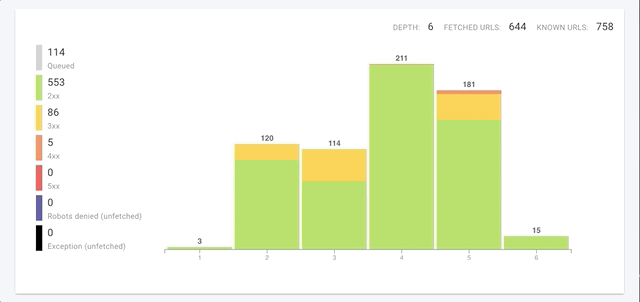
Nous crawlons non seulement chaque page plus rapidement mais nous avons aussi amélioré la vitesse de crawl globale dans 3 domaines clés :
- Nous avons parallélisé les tâches de crawl.
Comme plusieurs tâches peuvent être exécutées en même temps, la vitesse de crawl globale est bien plus rapide. - Nous avons retiré les pauses pendant la période de crawl.
Sans pauses, le crawler est maintenant capable de respecter la vitesse de crawl que vous avez demandé pour un temps de crawl plus court. (Cela signifie que vous pourriez avoir besoin de faire des ajustements si vous vous rendez compte que la vitesse la plus rapide demande trop d’efforts à votre serveur web.) - Nous avons ré-écris les algorithmes pour incrémenter la profondeur pendant un crawl.
Pour les grands sites web, par exemple, les crawls profonds pouvaient prendre plus d’une heure pour progresser d’une profondeur de 10 (ou N) à une profondeur de 11 (ou N+1). Avec le nouveau crawler, les changements de profondeur sont plus fluides, même aux niveaux les plus profonds des sites web gigantesques.
Temps de réaction plus rapides
Le délais nécessaire pour mettre en pause ou arrêter un crawl a été amélioré. À cause du stockage et du traitement des données précédents, mettre en pause un crawl pouvait prendre un moment, même après que vous ayez appuyé sur le bouton. Avec le nouveau crawler, c’est maintenant presque instantané.
Si vous avez besoin de mettre en pause ou d’arrêter un crawl, vous pouvez maintenant le faire en quelques secondes.
Monitoring de crawl amélioré
Le monitoring de crawl de l’interface d’Oncrawl a été repensé avant la sortie du nouveau crawler. Avec le nouveau crawler, cependant, il y a toute une galaxie de différences dans le monitoring de crawl.
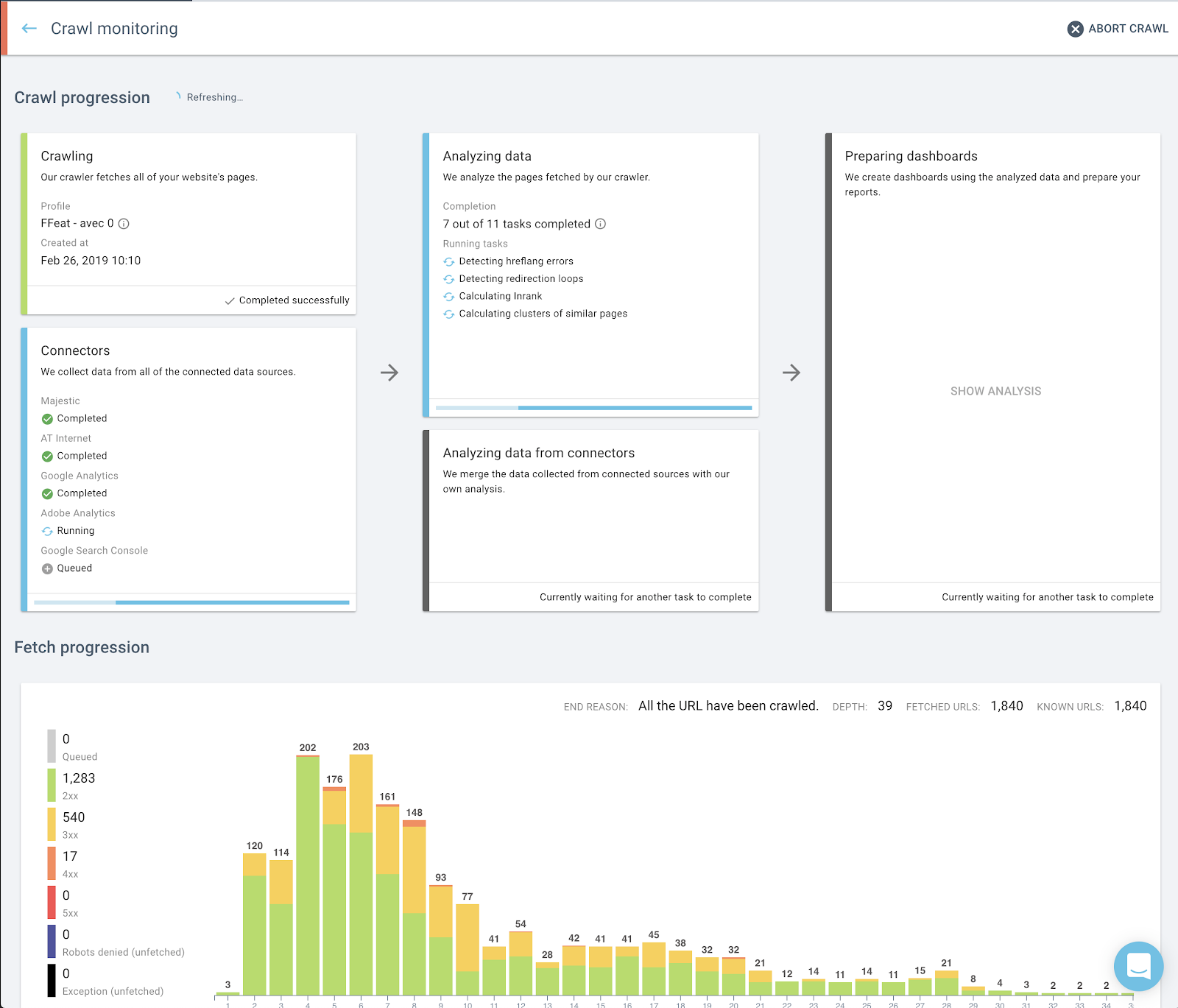

L’amélioration inclut :
- Plus d’informations lorsque que les comptes connectés mettent du temps à répondre ou lorsque les informations demandées ne peuvent pas être obtenues. Cela peut arriver, par exemple, lorsque vous n’avez pas assez de quota restant dans votre compte tierce connecté.
- Plus d’informations en temps réel sur les erreurs de crawl d’une page.
- La possibilité de voir la progression d’un crawl pendant la phase d’analyse.
Quelles sont les autres nouveautés ?
Plus d’informations pour plus d’URLs
Le nouveau crawler Oncrawl récupèrent des informations pour toutes les pages en format HTML, peu importe leur indexabilité et leur status code HTTP.
Auparavant, les données des pages n’étaient disponibles que pour les pages avec un status code 200 et pour les pages indexables. Les nouvelles informations sont disponibles dans le Data Explorer et l’outil URL Details, comme elles concernent généralement seulement les pages qui ne sont pas incluses dans les tableaux de bord et graphiques Oncrawl. Cela inclut le nombre de mots, le titre, la méta description, les titres (H1 – HN), les n-grams, l’Open Graph, les Twitter cards et bien plus encore.
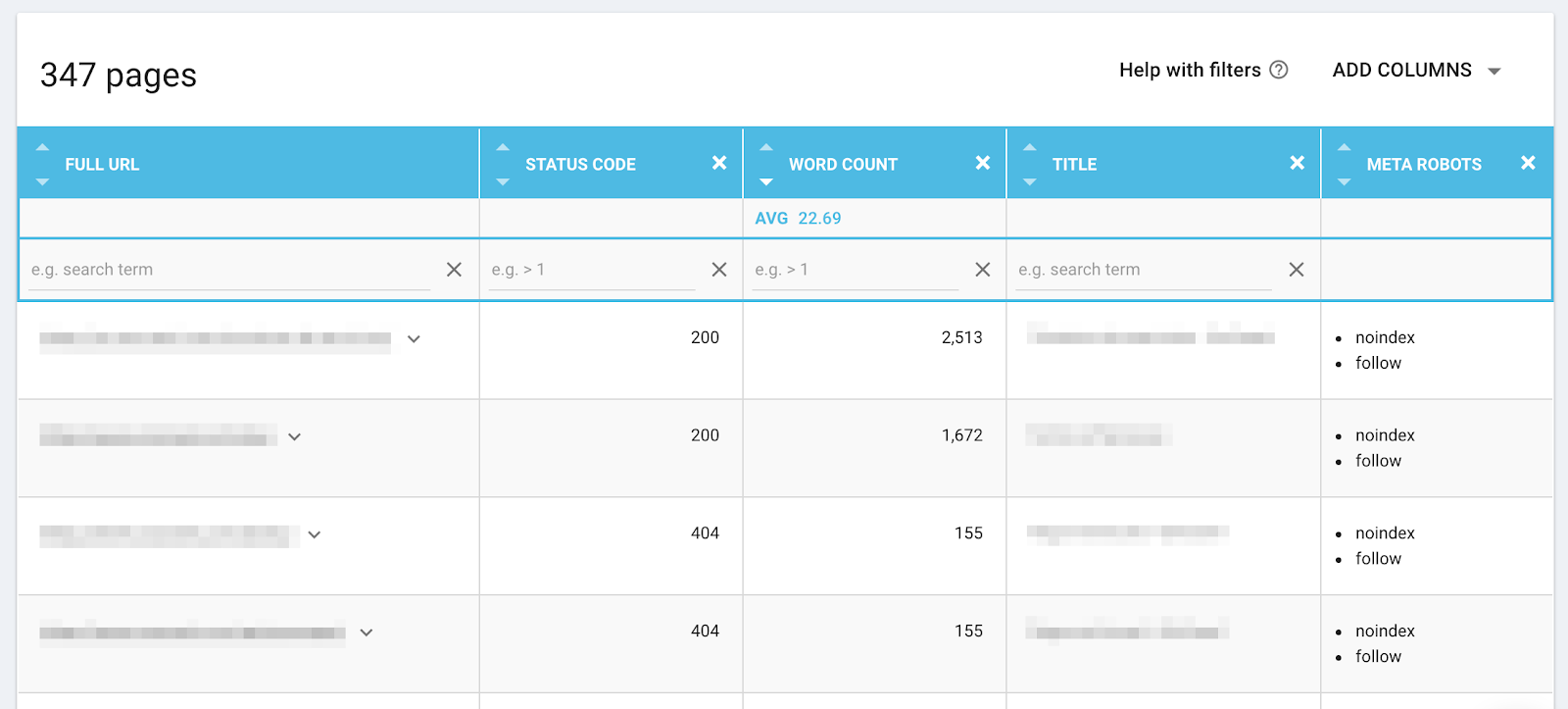
Dans l’URL Details, sous “View Source”, l’intégralité du code, dont les headers, sont disponibles pour toutes les pages.
Récupérer des données provenant de pages additionnelles aide aussi Oncrawl à trouver plus de liens et à améliorer la similarité entre notre crawler et le googlebot. Par exemple, Oncrawl ignorait précédemment le contenu des pages avec un status code 3xx, malgré l’évidence que Google puisse suivre des liens de ce type sur ces pages. Oncrawl peut maintenant, comme Google, crawler les liens sur les pages avec un status code autre que 200.
Le fait que des liens additionnels soient trouvés et que des pages additionnelles soient analysées signifie que le total du nombre de pages dans le Data Explorer peut être plus élevé que les nombres que vous trouviez auparavant pour le même site. Par exemple, sur une page redirigée, il est possible que nous découvrons de liens vers des nouvelles pages. Même si ces pages-là se trouvent à ne pas être indexables, elles seront comptées dans le nombre total de pages affiché dans le Data explorer.
Analyse de liens sortants étendue
Nous avons amélioré la capacité de notre crawler à identifier et suivre les liens qui conduisent vers une autre page. Le crawler d’Oncrawl prend maintenant en compte les liens suivants :


Nouveaux champs (et améliorations) dans le Data Explorer
Nous avons ajouté des champs liés au robot d’Oncrawl dans le Data Explorer :
- Sources : comment Oncrawl connait cette page ? Nous vous informons de la manière dont notre robot l’a trouvée, si elle est listée dans votre sitemap, et si les données connectées y font référence.
- Fetch date : la date et l’heure auxquelles notre robot a demandé l’URL.
- Fetch status : le résultat de la tentative de notre robot pour récupérer la page. La valeur ‘success” signifie que le robot d’Oncrawl a reçu une réponse du serveur web : même si la réponse du serveur indiquait une erreur de page ou de serveur, notre robot a réussi à obtenir cette information du serveur.
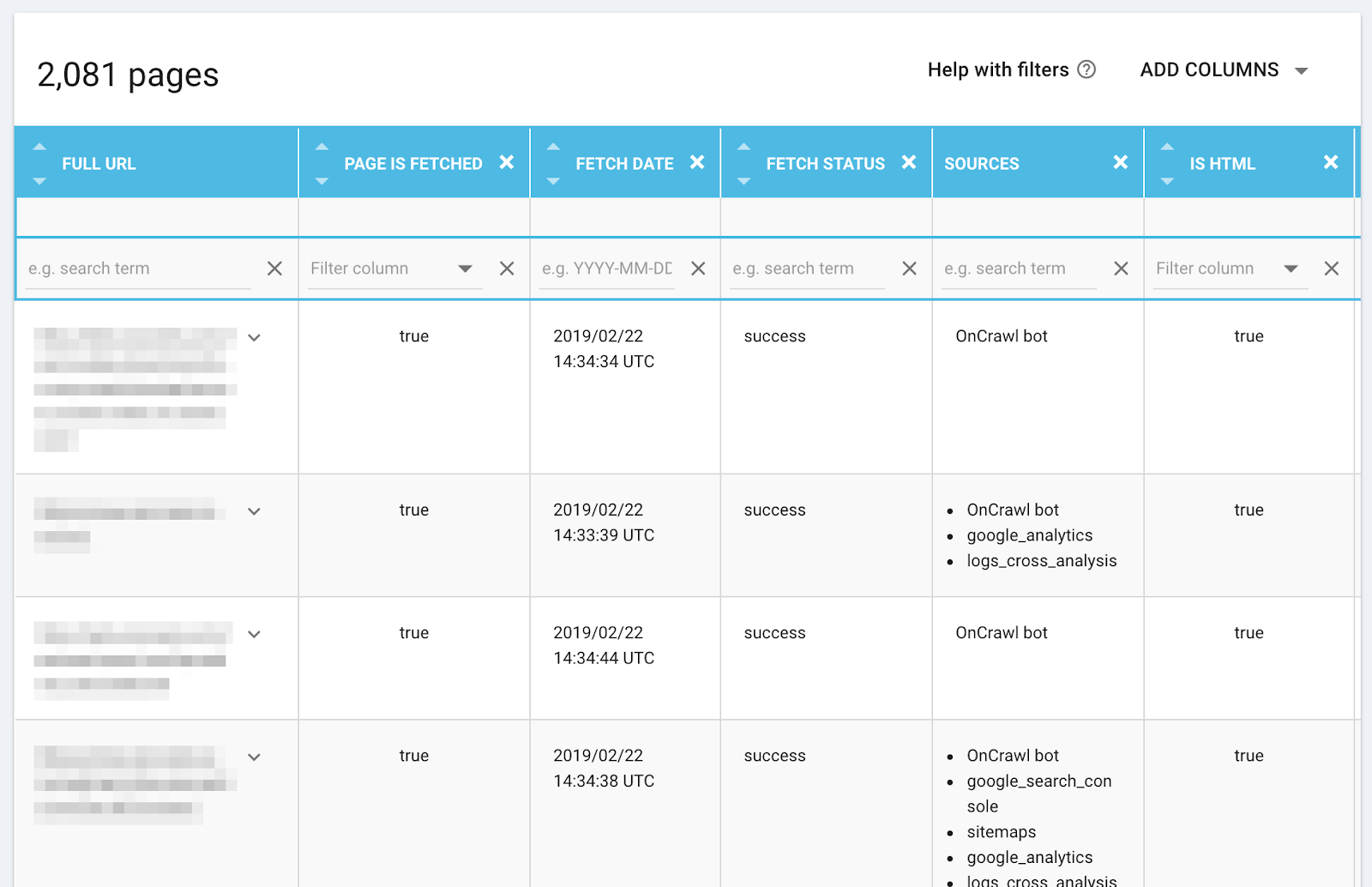
Nous avons aussi amélioré le rapport de certains champs qui affichaient auparavant des valeurs par défaut. Cela vous donne des informations plus précises pour toutes vos pages. Par exemple, le champ Metarobots dans le Data Explorer indiquait par défaut que les robots étaient autorisés lorsque aucune contre indication n’était présente. Maintenant, le champ Metarobots montre la valeur actuelle de la propriété “meta robots=” pour l’URL. Si la propriété est manquante, le champ est laissé blanc.
Comment obtenir ces nouvelles analyses supersoniques sur votre compte Oncrawl ?
Le nouveau schéma de crawl sera déployé progressivement pour tous nos utilisateurs, qu’ils soient nouveaux ou non, et sans aucune action demandée.
Cependant, si vous utilisez toujours l’ancienne version et que vous souhaitez obtenir dès maintenant la version mise à jour, n’hésitez pas à contacter votre responsable de compte ou à nous contacter directement via le bouton bleu Intercom en bas à droite de l’écran lorsque vous vous identifiez dans l’application.
