
Si vous travaillez dans le domaine du SEO, vous l’avez probablement entendu (et répété à vos interlocuteurs) un millier de fois : vous pouvez écrire le meilleur contenu du monde, si Google ne peut pas le trouver, il ne vaut pas grand-chose. Il en est de même pour les produits et les services : peu importe ce que votre site propose, les moteurs de recherche doivent être en mesure de le trouver et le reconnaître afin de le classer dans les résultats de recherche.
C’est pourquoi le SEO technique est la base d’un site web sain. Pour de nombreux sites, il n’est pas très difficile d’obtenir que les pages importantes soient explorées et indexées.
Vous ajoutez une nouvelle URL, elle apparaît dans votre sitemap, elle n’est pas bloquée dans le fichier robots.txt, vous pouvez peut-être lui proposer quelques liens internes, et voilà ! Elle est éligible pour les SERP. Mais pour les sites plus importants et plus complexes, ce n’est pas toujours aussi simple.
Les capacités de crawl des moteurs de recherche sont vastes, mais elles ont une limite. Google donne la priorité à l’exploration des pages qu’il considère comme utiles, et si vous n’envoyez pas les bons signaux concernant les pages que vous considérez comme importantes à crawler, elles risquent d’être négligées au profit d’autres.
Si ce problème ne se pose généralement pas pour sites plus petits et moins complexes, il existe quelques secteurs d’activité pour lesquels la gestion du budget de crawl doit faire partie d’une stratégie SEO technique.
Les grands sites e-commerce proposant un nombre important de produits, les éditeurs de presse qui ajoutent de nouvelles pages chaque jour et les sites comportant au moins un million d’URLs sont susceptibles d’avoir des préoccupations légitimes en matière de crawl. Voyons comment gérer ces problèmes en auditant l’efficacité de crawl de vos pages les plus importantes.
Identifiez les URLs de valeur
Vous pouvez considérer que chaque URL de votre site web est nécessaire, mais cela ne signifie pas que chaque page a de la valeur pour la recherche organique.
Par exemple, la page des conditions d’utilisation de votre site e-commerce peut exister par nécessité juridique, mais elle n’apporte aucune valeur monétaire directe ou indirecte à l’entreprise (et elle n’a probablement pas besoin d’être crawlée).
Étant donné que les moteurs de recherche consacrent leur budget de crawl aux pages qu’ils jugent utiles, vous devez définir la valeur des pages de votre site avant d’aligner les perceptions de Google aux vôtres.
Dans certains cas, la valeur des pages est évidente. Les pages de produits d’un site e-commerce sont généralement celles qui ont la valeur monétaire la plus directe, suivies de près par les pages de catégories.
Les articles les plus récents d’un grand site éditeur d’actualités sont ceux qui ont le plus de valeur, car c’est grâce à eux que le site reste toujours pertinent. Mais dans d’autres cas, vous devrez approfondir les mesures de conversion et d’engagement pour trouver des liens indirects entre la recherche organique et le résultat net.
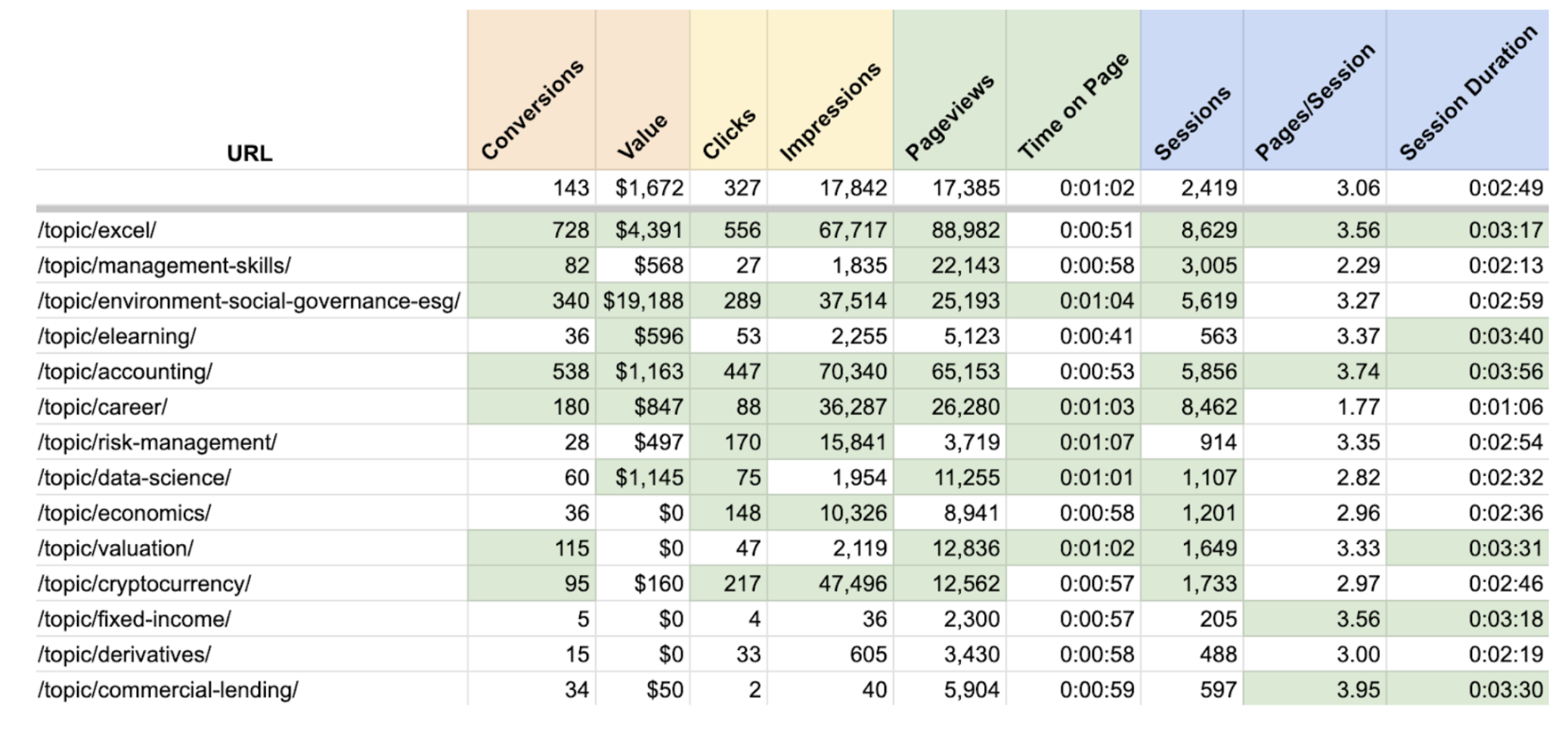
Les pages de conversion (qui présentent directement les produits) ont évidemment une grande valeur, mais certaines pages de ressources, comme celles présentées ci-dessus, peuvent également être liées à des montants réels.
En extrayant des données de Google Analytics, nous sommes en mesure de voir lesquelles de ces pages de ressources ont été visitées le plus fréquemment sur le chemin d’un client vers une conversion et quelle était la valeur monétaire de ces conversions.
Nous pouvons également utiliser les données de GA et de la Search Console pour évaluer la valeur de chaque page en termes d’engagement (clics organiques, temps passé sur la page, etc.).
Gardez en tête que parfois, les pages qui ne rapportent pas d’argent doivent tout de même être crawlées en priorité.
Dans le cas d’un site enterprise SaaS, les pages de solutions et de tarifs peuvent se trouver en bas du tunnel de ventes, mais les livres blancs, les webinaires et les autres ressources jouent un rôle essentiel en haut du tunnel en augmentant la notoriété de la marque et en attirant des chercheurs d’informations sur le site.
Si ces pages ne sont pas crawlées efficacement, le trafic du site dépendra entièrement des utilisateurs qui sont prêts à acheter, sans possibilité de guider les utilisateurs en amont dans le tunnel au fil du temps.
[Étude de cas] Augmenter le budget de crawl sur les pages stratégiques

La manière la plus simple de segmenter votre site et de surveiller le crawl des différents types de pages est d’organiser vos sitemaps en conséquence.
Sur un site e-commerce, si vous placez toutes les pages de produits dans un ensemble de sitemaps, toutes les pages de catégories dans un autre, et ainsi de suite, vous pouvez facilement identifier les modèles d’indexation et suivre les problèmes affectant chaque type de page.
Certains systèmes de gestion de contenu organisent automatiquement vos sitemaps de cette manière, à condition que vos modèles de page et vos structures d’URL soient correctement appliqués.
Repérez les inefficacités du crawl
Vous avez identifié les pages à surveiller de plus près et organisé ces pages de manière à faciliter le monitoring. Vous devez maintenant déterminer dans quelle mesure vos pages importantes sont crawlées et indexées, étudier les causes potentielles d’inefficacité et faire tout ce qui est en votre pouvoir pour encourager les moteurs de recherche à crawler votre site conformément à vos priorités.
Supposons que vous ayez identifié votre dossier de produits e-commerce comme étant votre priorité en matière de crawl. Vous pouvez commencer par effectuer une recherche de site pour ce répertoire, ce qui vous permettra de savoir si le nombre d’URL de produits existants est similaire au nombre d’URL indexées par Google.

Si ce nombre est nettement inférieur au nombre de produits présents sur votre site, vous saurez qu’il y a un problème de crawl et/ou d’indexation à résoudre.
Vous pouvez également utiliser un outil comme Oncrawl pour crawler l’ensemble de votre site ou un sous-dossier spécifique et renvoyer les codes d’état et l’indexabilité de chaque URL en question. Toute page de valeur qui ne renvoie pas un status code 200 et qui n’apparaît pas comme « indexable » doit faire l’objet d’un examen plus approfondi.

Source : Oncrawl
Si vous avez organisé vos sitemaps par type de page et les avez soumises à la Search Console, vous pouvez également étudier les problèmes affectant chaque type de page en consultant le rapport d’indexation de chaque sitemap.

Source : Search Console
Dans ce cas, l’indexation des pages de produits a fluctué dans le temps, mais il est clair que des problèmes affectent la majorité de ces pages. Les raisons sont énumérées ci-dessous, ainsi qu’un échantillon de pages spécifiques affectées par chaque problème.

Source : Search Console
La Google Search Console propose également des statistiques sur le crawl de l’ensemble du site dans le menu Settings, sous Crawling > Crawl stats.
Vous y trouverez le nombre total de requêtes de crawl que votre site a récemment reçues (que ces requêtes aient abouti ou non), ainsi que le temps moyen nécessaire pour que votre site réponde à une requête de crawl.
Bien que vous ne puissiez pas segmenter ces données par sous-dossier, vous pouvez les utiliser pour évaluer la fréquence des requêtes de crawl de Google par rapport au nombre d’URL de valeur sur votre site et déterminer si la qualité des pages et l’utilisation des directives d’exploration influent sur l’exhaustivité du crawl de votre site.

Source : Search Console
Dans l’exemple ci-dessus, les robots de Google ont visité en moyenne 18 500 pages par jour. Sur un site comptant plus de 600 000 URLs, il s’agit d’un déficit de crawl évident. Et nous pouvons identifier les coupables potentiels.
Tout d’abord, le temps de réponse moyen de l’exploration du site est assez élevé – près de 3000 ms, alors qu’un temps supérieur à 300 ms devrait être considéré comme inquiétant. Cela peut s’expliquer soit par le fait que Google est censé crawler trop de contenu à faible valeur, soit parce qu’il y en a trop, soit parce que le site ne dispose pas de contrôles de crawl suffisants.
Ensuite, nous pouvons descendre un peu plus bas et constater que seulement 7 % des requêtes de crawl de ce site ont été effectuées dans le but de découvrir de nouvelles pages.

Source : Search Console
Cela signifie que la très grande majorité des 600 000 URLs du site ne sont pas découvertes et crawlées du tout, ou du moins qu’elles le sont très, très lentement.
La source ultime de vérité sur la manière dont Google explore votre site se trouve dans vos fichiers de logs. L’utilisation d’un analyseur de logs avec des filtres réglés pour n’afficher que les occurrences des robots d’indexation de Google vous permettra de savoir exactement quelles URLs sont crawlées par le moteur de recherche, à quelle fréquence, et quel est le degré de réussite et d’efficacité de ces crawls.

Source : Oncrawl
L’échantillonnage de ces données sur une longue période et leur segmentation par type de page peuvent vous aider à identifier des schémas problématiques à traiter par des améliorations du site ou de meilleurs contrôles du crawl et de l’indexation.
Auditez les URLs inefficacement crawlés
Une fois que vous savez quelles pages souffrent d’un crawl inefficace, l’étape suivante consiste à en déterminer les raisons. La réalisation d’un audit de site est un moyen efficace de trouver des réponses. Lancer un crawl dans Oncrawl vous permet de collecter différents types de données à analyser et à croiser. Les différents rapports disponibles sont les suivants :
- Rapport sur les médias sociaux
- Logs monitoring
- Crawl report
- SEO impact report
- Ranking report
- Social media report
En général, il y a deux raisons principales pour lesquelles une page peut ne pas être crawlée efficacement : une mauvaise utilisation des contrôles techniques et une mauvaise qualité de la page.
Considérations SEO technique
Pour qu’une page soit découverte et crawlée, il faut qu’elle soit liée quelque part. Plus une page est placée en évidence dans l’architecture du site, plus les moteurs de recherche auront l’impression que cette page est importante pour le crawl et l’indexation.
Par exemple, en plaçant un lien vers une page de catégorie dans votre navigation supérieure ou dans un pied de page persistant, vous donnez l’impression que la page a une grande valeur et qu’elle doit être traitée comme telle.
Il est conseillé de créer une carte visuelle de toutes les pages importantes de votre site et de veiller à ce qu’elles soient reliées entre elles de manière efficace, sans qu’aucune URL de grande valeur ne se trouve à plus de trois clics de la page d’accueil.
Analyser votre distribution Inrank, une mesure de votre pagerank interne, vous aide à comprendre la popularité de vos pages sur la base de votre architecture de liens internes.

Source : Oncrawl
Évaluer vos groupes de pages en fonction de leur profondeur peut également vous aider à comprendre s’il existe des sections spécifiques – ou des pages à l’intérieur de chaque section – qui sont trop éloignées de la page d’accueil et qui devraient par conséquent être mieux positionnées dans l’architecture de votre site.

Source : Oncrawl
Mauvaise qualité des pages
La canonicalisation, la pagination et le paramétrage peuvent indiquer qu’une page est moins importante pour l’exploration – et si votre fichier robots.txt bloque l’exploration de certaines URLs paramétrées, elles n’apparaîtront évidemment pas dans l’index.
Pour les sites comportant des directives de paramétrage complexes, utilisez un outil de test robots.txt pour vérifier la navigabilité de certaines pages et ajustez vos directives ou déplacez les pages importantes en dehors de votre structure de filtrage si elles sont bloquées de manière involontaire.
Quelles que soient les suggestions que vous faites aux moteurs de recherche, ils peuvent toujours refuser d’explorer et d’indexer fréquemment les pages qu’ils jugent de faible qualité. Leur demander de prêter attention à un contenu dupliqué ailleurs sur le site, trop mince pour être utile à l’utilisateur ou obsolète, c’est détourner l’attention d’un contenu de meilleure qualité.
Déterminez comment vous souhaitez gérer votre contenu dupliqué ou superficiel et surveillez de près les stratégies que vous mettez en œuvre.

Source : Oncrawl
De plus, si Google découvre qu’un sitemap particulier contient trop de pages qui ne répondent pas aux normes de qualité, il peut traiter l’ensemble de ce sitemap comme étant de faible priorité.
Assurez-vous que toutes les pages inutiles et de faible valeur sont consolidées ou supprimées de votre site, et que seules les URLs avec un status code de niveau 200, indexables et de haute qualité sont présentes dans vos sitemaps.
Favorisez l’exploration et l’indexation des pages de valeur
L’un des moyens les plus efficaces de s’assurer que les moteurs de recherche explorent et indexent les pages qui vous intéressent le plus est d’éviter de les distraire avec des pages qui ne vous intéressent pas autant.
Vous pouvez y parvenir en interdisant les pages sans importance, telles que celles qui sont impliquées dans le processus de paiement, à l’aide des directives robots.txt.
De nombreux sites e-commerce choisissent également d’interdire les pages de filtrage au-delà d’un certain niveau de paramétrage.
Par exemple, ils peuvent autoriser l’exploration d’URL à paramètre unique, comme une page « robes rouges » avec l’URL /robes?couleur=rouge ou une page « robes de moins de 50 dollars » avec l’URL /robes?prix=moins-50, mais bloquer toute page à laquelle deux filtres ou plus sont appliqués, comme /robes?couleur=rouge&prix=moins-50. Cela permet de réduire le nombre de pages indexées en quasi-double exemplaire.
Une canonisation appropriée
La canonicalisation est souvent utilisée pour montrer aux moteurs de recherche la « meilleure » version d’une page.
Par conséquent, une page dupliquée, ou presque, devrait idéalement pointer vers la page du contenu original en tant qu’autorité canonique.
Pour les pages clés, l’autocanonicalisation n’est pas strictement nécessaire, mais elle est recommandée, en particulier lorsqu’il s’agit de pages qui présentent différentes variations de paramètres.
Il est également essentiel de comprendre que les pages marquées d’une balise canonique sont toujours sujettes à l’exploration et à l’indexation.
Cette balise est davantage une suggestion sur la manière dont Google et les autres moteurs de recherche doivent traiter la page qu’un ordre absolu. Par conséquent, la décision finale d’indexer ou non les pages canonisées appartient au moteur de recherche.
Dans la plupart des cas, l’utilisation d’une balise canonique transfère la valeur SEO d’une page à celle indiquée dans la balise (qu’il s’agisse de la même page ou d’une page différente), améliorant ainsi son potentiel de performance dans les résultats de recherche.
Cela dit, dans la mesure du possible, envisagez de consolider le contenu et de mettre en œuvre une redirection 301 au lieu d’une redirection canonique (par exemple, lorsque vous informez les moteurs de recherche de la version https d’un site par rapport à la version http).
Une pagination efficace
Une pagination inefficace peut également consommer le budget de crawl. Pour les sites comportant un grand nombre de pages paginées qui changent constamment, veillez à mettre en place des liens canoniques autoréférents sur chaque page paginée (ne les canonisez pas vers la première page de résultats). Pensez également à limiter le nombre de liens vers les pages de résultats suivantes – au lieu de cette option :

Prenons l’exemple suivant, qui montre mieux l’importance décroissante de chaque page paginée dans la liste, tout en donnant à l’utilisateur une idée de la taille de la liste :

Maximisez les entrées sitemap
Les éditeurs de presse et autres sites qui ajoutent fréquemment de nouvelles URLs et qui ont besoin d’une indexation rapide peuvent bénéficier de l’envoi de flux RSS au Google Publisher Center et de l’optimisation de leurs entrées sitemap afin d’offrir autant d’informations que possible sur chaque article :

Alternative maximisée :

Conclusion
En fin de compte, les moteurs de recherche gèreront toujours leurs propres budgets de crawl de la manière qui sert leurs propres intérêts. En vous rappelant que Google est une entreprise comme une autre, avec des ressources à conserver, vous devriez vous efforcer de fournir des chemins d’exploration clairs et efficaces sur l’ensemble de votre site web, sans aucune distraction en cours de route.
Examinez votre site comme le ferait un moteur de recherche, soyez aussi impitoyable qu’il le sera dans l’identification d’un contenu de valeur, et donnez-lui les indicateurs les plus forts et l’opportunité de placer ce contenu en tête et au centre de ses index.
