
Qu’est-ce que le contenu dupliqué ?
Le contenu est dit dupliqué lorsque celui-ci apparaît dans plus d’une URL sur le web. Il y a deux types de doublons : le contenu dupliqué interne qui se trouve sur votre propre site et le contenu dupliqué externe qui représente le contenu très similaire entre plusieurs sites. Nous parlerons seulement des doublons internes puisque selon le fonctionnement des moteurs de recherche, à part si vous copiez collez une grande partie du contenu d’un site tierce, le contenu dupliqué externe n’aura pas d’impact négatif sur votre SEO.
Comment les moteurs de recherche localisent ils les doublons ?
Il existe beaucoup de méthodes scientifiques qui aident les robots à identifier le contenu dupliqué mais parmi toutes ces solutions, la méthode Simhash est la manière la plus flexible et efficace de les interpréter (ah oui et publiée par des Googleurs). C’est pour cela que nous utilisons cette méthode Simhash pour Oncrawl.
En quelque mots, la méthode Simhash a pour but de calculer une empreinte digitale pour chaque page, en se basant sur un ensemble de caractéristiques extrait d’une page web. Ces caractéristiques peuvent-être des mots-clés (N-grams) ou dans certains cas des balises HTML. Ensuite, toutes ces empreintes digitales (toutes ces pages web) sont comparées entre elles pour évaluer la “distance Hamming”, autrement dit, les différences entre les pages. Si deux empreintes digitales sont similaires, alors le contenu sur ces deux pages l’est aussi. De cette manière, les moteurs de recherche peuvent grouper les pages selon la similarité du contenu. C’est ce que nous appelons “clusters de pages dupliquées”.
Pour un moteur de recherche comme Google, le problème est de savoir quelle page, à l’intérieur de ce cluster, doit être indexée et ajoutée dans ses SERPs. Il existe plusieurs cas de figures:
- Google peut décider de ne pas indexer les pages à l’intérieur du cluster ;
- Google peut décider de n’indexer qu’une seule page à l’intérieur du cluster ;
- Google peut décider de toutes les indexer mais baissera leurs scores de qualité afin qu’elles ne se classent pas.
Lorsque vous devez implémenter ce genre de méthode sur l’ensemble du World Wide Web, cela peut revenir très cher, Google choisit donc souvent de ne pas indexer ces pages.
Est-ce que le contenu dupliqué interne représente un problème pour mon site ?
Google est assez intelligent pour interpréter les autres facteurs de l’analyse sémantique afin de décider quelle page devrait être indexée, vous pourriez juste le laisser faire son boulot. Mais c’est très mauvais signe: votre site va perdre des points en tant que source de confiance et cela va impacter son score de qualité. Ainsi, avoir des doublons va baisser les classements de votre site et la fréquence de crawl de Google.
L’essentiel à retenir ici est que Google déteste gaspiller ses ressources de crawl sur des pages identifiées comme ayant une faible valeur. Si vous avez des doublons, Google ira chercher moins de pages sur votre site ou ne le crawlera probablement pas du tout.
Comment détecter mon contenu similaire ?
Pour des raisons évidentes, je pense qu’Oncrawl est un bon moyen d’effectuer cette opération. Nous sommes les premiers dans le monde à sortir un détecteur de contenu similaire.
Il est très important pour vous de prendre des mesures en ce qui concerne votre contenu dupliqué. Avoir accès à une vue globale de vos clusters de contenus similaires peut vous aider à valider votre stratégie. Voici vos options :
- Supprimez vos pages avec du contenu dupliqué et ajoutez des redirections 301 pointant vers votre contenu unique ;
- Mettez un no-index sur les pages dupliquées ;
- Installez une balise canonique sur les pages dupliquées pointant vers votre contenu original. Mais faites attention à ce que vous faites car si vous ne l’installez pas correctement, cela n’aura pas l’effet attendu.
En effet, les réglementations canoniques que vous mettez en place influencent fortement le comportement des robots de Google. La meilleure solution est d’installer une canonique unique pour chaque groupe de pages dupliquées. Sinon c’est la catastrophe.
Voici un petit exemple de ce que vous pouvez trouver au sein de notre analyse croisée (comparaison des données de crawl et de logs):
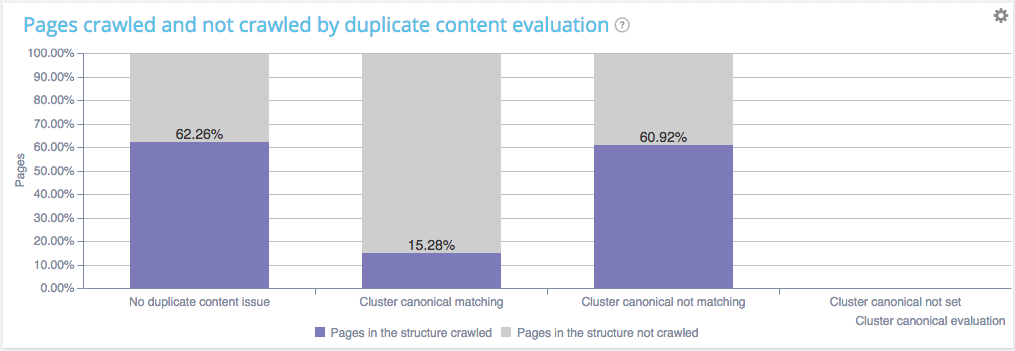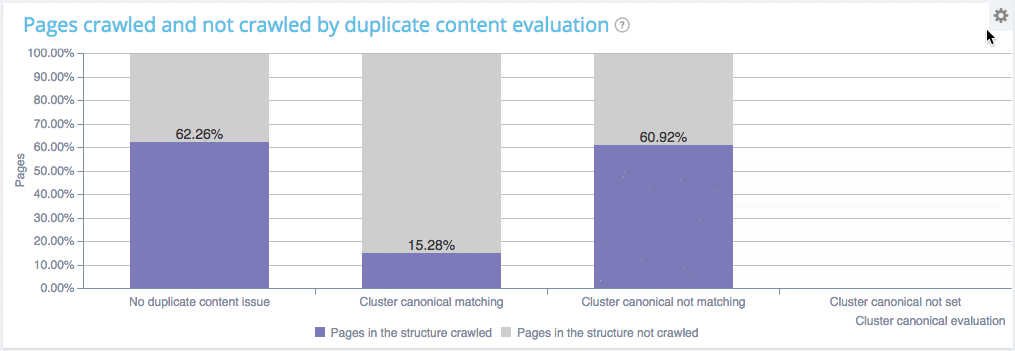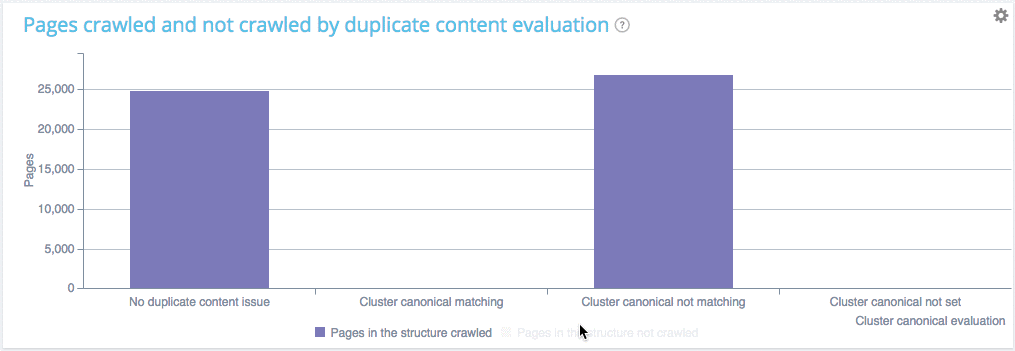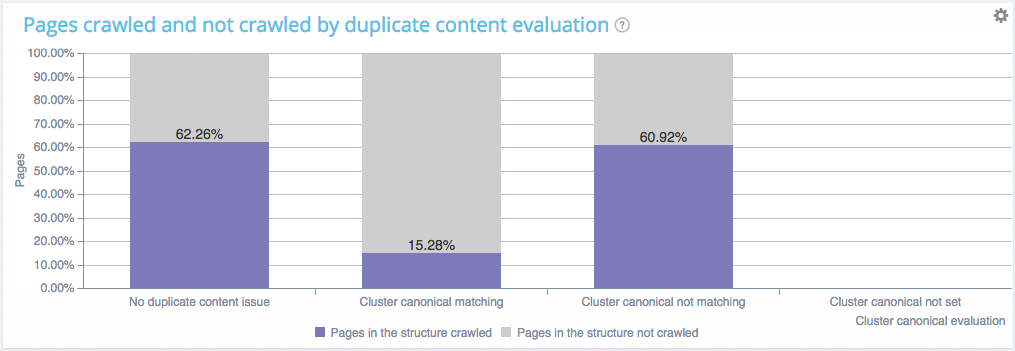
Vous pouvez voir que sur ce site :
- Les pages sans contenu dupliqué sont crawlées à un ratio de 62.26% ;
- Les pages à l’intérieur des clusters de pages dupliquées avec canonique sont crawlées pratiquement au même rythme (60.92%). Ce qui implique que Google va chercher ces pages comme d’habitude afin de vérifier si vous avez changé quelque chose et gaspille ainsi ses ressources. Votre fréquence de crawl est sur le point de baisser ;
- Les pages à l’intérieur des clusters de pages dupliquées avec canonique ne sont pas crawlées du tout. Bravo, vous ne faites pas perdre de temps à Google.
Conclusion
La résolution de vos problèmes de contenu dupliqué peut prendre du temps. Tout dépend de ce qui a engendré cette apparition. Cependant, prendre le problème au sérieux et prendre des mesures dès aujourd’hui peut vous permettre d’atteindre un ROI impressionnant. Évitez le contenu dupliqué peut vous permettre :
- d’obtenir de meilleurs classements dans les semaines qui suivent grâce à un meilleur score de qualité de votre site ;
- d’avoir plus de pages classées dans les SERPs grâce à l’attribution des ressources de Google à d’autres parties de votre site.
