
Le webinaire « Nouvelles perspectives sur le contenu dupliqué » fait partie de la série SEO in Orbit, et a été diffusé le 24 juin 2019. Comment les facteurs de classement et l’évolution des technologies de search impactent la manière dont nous gérons le contenu dupliqué ? Que réserve l’avenir au contenu dupliqué ? Rejoignez Omi Sido, ambassadeur Oncrawl et Alexis Sanders pour explorer la question du contenu dupliqué.
SEO in Orbit est la première série à envoyer le SEO dans l’espace. Tout au long de la série, nous avons débattu sur le présent et le futur du SEO technique avec certains des experts les plus qualifiés et avons envoyé leurs meilleurs conseils dans l’espace le 27 juin 2019.
Présentation d’Alexis Sanders et d’Omi Sido
Alexis Sanders travaille comme Chargée de compte Technical SEO pour l’agence Merkle. L’équipe technical SEO s’assure de la précision, de la faisabilité et de la scalabilité des recommandations techniques de l’agence. Elle est contributrice pour le blog Moz et créatrice du challenge TechnicalSEO.expert ainsi que du podcast SEO in the Lab.
Omi est un intervenant international chevronné et est connu dans le secteur pour son humour et son habilité à délivrer des insights actionnables que son audience peut immédiatement utiliser. De consultant SEO pour quelques unes des plus grandes entreprises en télécommunication et voyage à SEO in-house pour HostelWorld et le Daily Mail, Omi adore plonger dans des données complexes et y trouver des points lumineux. Actuellement, Omi est Senior Technical SEO pour Canon Europe et ambassadeur Oncrawl.
Qu’est-ce que le contenu dupliqué ?
Omi donne la définition suivante :
Un contenu dupliqué est similaire (ou presque) à un autre contenu présent sur le même site web ou sur une autre URL.
Le mythe de la pénalité pour le contenu dupliqué
Il n’y a pas de pénalité en cas de contenu dupliqué.
Il s’agit d’une question de rendement. Notre objectif n’est pas qu’un bot regarde deux URL et pense que ce sont deux contenus différents et qu’ils peuvent être classés l’un à côté de l’autre.
Alexis compare la compréhension de votre site web par un bot à celle de Joey de la série “10 choses que je déteste chez vous” : il est impossible pour un bot de trouver une différence matérielle entre les deux versions.

Il faut surtout éviter d’avoir deux contenus identiques qui se font concurrence. Le plus important c’est d’avoir une expérience unique et sûr, qui peut être classée et performante dans les moteurs de recherche.
Différence entre ce que voient les utilisateurs versus ce que voient les bots
Quand un bot peut voir plusieurs versions d’une URL, un utilisateur n’en voit qu’une.
– Effet sur le budget de crawl pour les très gros sites
Pour les sites qui sont très gros, comme Zillow ou Walmart, le budget de crawl peut varier selon les pages.
Dans un article de 2018 basé sur une présentation de Frédéric Dubut à la SMX East, Alexis à mentionné que les budgets sont établis à différents niveaux – aux niveaux des sous-domaines et des serveurs. Les moteurs de recherche, qu’il s’agisse de Google ou de Bing, veulent être des crawlers “polis”. Ils ne veulent pas ralentir les performances des utilisateurs réels. Chaque fois qu’ils sentent un changement de performance, ils se retirent. Cela peut se produire à différents niveaux, pas seulement au niveau du site.
Si vous avez un site « important », donner la meilleure expérience possible à vos utilisateurs est une priorité.
Contenu dupliqué : une question de contenu ou une question technique ?
Malgré le mot « contenu » dans « contenu dupliqué », c’est en partie un problème technique.
– Sources de duplication
De nombreux facteurs peuvent être à l’origine de dédoublements :
- Pages répétitives
- Les sites de préproduction
- URL HTTP vs HTTPS
- Différents sous-domaines
- Différents cas
- Différentes extensions de fichiers
- Trailing slash
- Les pages d’index
- Les paramètres URL
- Les facettes
- Le tri
- La version imprimable
- La page d’accueil
- L’inventaire
- Le contenu syndiqué
- Les communiqués de presse
- La republication du contenu
- Le contenu plagié
- Le contenu localisé
- Le contenu pauvre
- Les images
- La recherche interne sur le site
- Le site mobile séparé
- Le contenu non unique
- …
– Distribution des problèmes entre le SEO technique et la gestion de contenu
Ces sources de contenu dupliqué peuvent être divisées en sources techniques ou bien en sources basées sur le contenu. À noter que certaines d’entre elles se trouvent à cheval entre les deux.
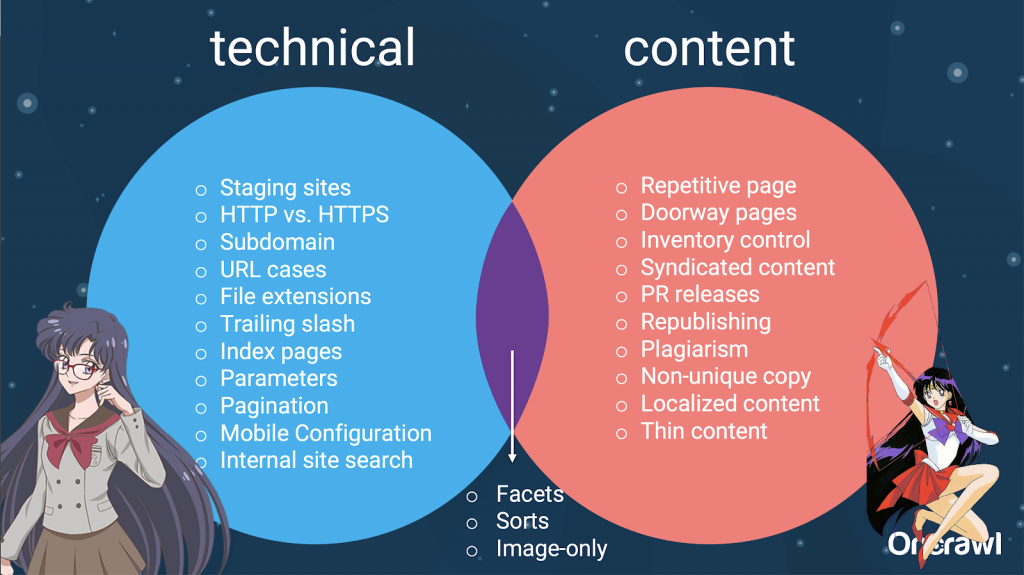
Le contenu dupliqué est alors vecteur de problèmes entres les équipes, d’où la densité du sujet.
Comment trouver le contenu dupliqué ?
La plupart des contenus en double sont le plus souvent involontaires. Pour Omi, cela indique qu’il y a une responsabilité partagée entre l’équipe « content » et l’équipe technique.
– L’outil préféré d’Omi : Grammarly
Grammarly est l’outil préféré d’Omi pour traquer le contenu dupliqué. Pourtant, ce n’est même pas un outil SEO. Il utilise l’outil de plagiat et s’informe auprès de l’éditeur si un nouveau contenu a déjà été publié ailleurs.
– Volume de contenu dupliqué créé par erreur
Le problème des duplications involontaires de contenu est un problème que les ingénieurs connaissent bien. Dans un livre intitulé “Introduction to Information Retrieval (2008)”, qui est légèrement dépassé aujourd’hui, ils ont estimé qu’environ 40 % du web à l’époque était dupliqué.

– Priorisation des stratégies pour gérer le contenu dupliqué
Pour traiter le contenu en double, il faut :
- Commencer par connaître votre parcours utilisateur, cela vous aidera à comprendre où se situe chaque élément de contenu. Cette tâche peut-être extrêmement difficile à faire, surtout lorsque les sites web ont été créés il y a 20 ans, à une époque où nous ne savions pas comment le web allait évoluer. Savoir où se trouve votre utilisateur vous aidera à établir des priorités dans les prochaines étapes.
- Vous aurez besoin d’une hiérarchie fonctionnelle, afin de fournir une place pour chaque type de contenu. La compréhension de votre architecture est une priorité dans le traitement du contenu dupliqué.
- Donner la priorité au contenu en double qui a une incidence sur le rendement.
- S’occuper des duplications 100% identiques
- Mettre en place un signal de contenu dupliqué
- Effectuer des choix stratégiques sur la façon de gérer la duplication : consolider, créer, supprimer, optimiser
- Traiter les contenus volés

– Outils : utiliser la segmentation dans Oncrawl
Alexis apprécie la possibilité de segmenter son site web avec Oncrawl, ce qui permet de se focaliser sur les éléments les plus pertinents.
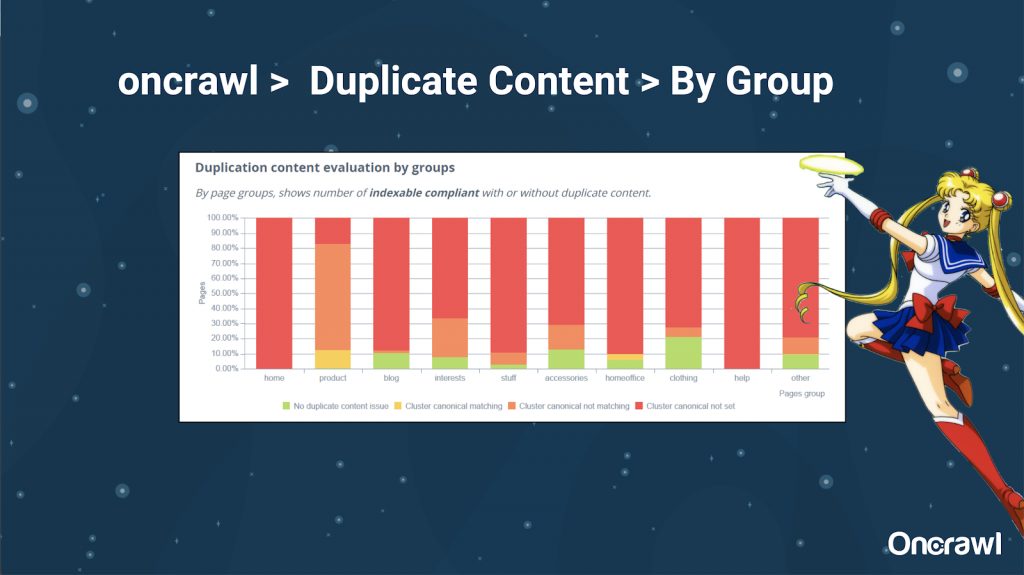
Plusieurs types de pages ont différents niveaux de duplication, ce qui permet d’avoir une vue d’ensemble des sections qui ont le plus de problèmes. Dans l’exemple, le site nécessite une attention particulière.
– Outils : recherches Google et GSC
Vous pouvez également vérifier le contenu en double à l’aide du moteur de recherche lui-même. Dans Google, vous pouvez :
- Utiliser des citations
- Utiliser le : recherche
- Utiliser des opérateurs supplémentaires comme inurl :, intitle :,, ou filetype :

Google Search Console permet maintenant d’effectuer un rapport de contenu dupliqué, donnant la possibilité de comprendre comment Google analyse les doublons.
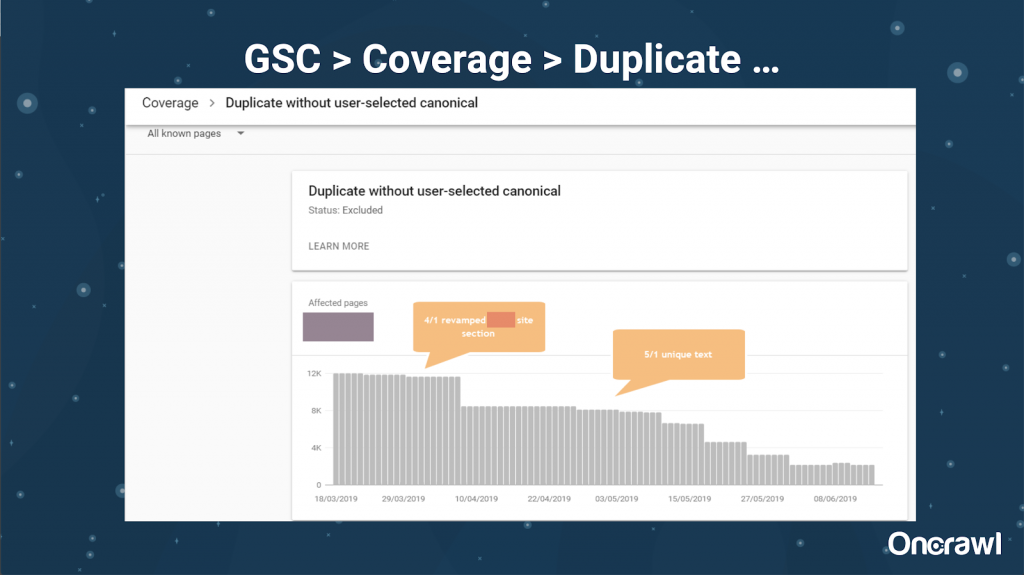
– Outils : outils de plagiat
Comme Omi, Alexis utilise aussi différents outils de plagiat :
- Quetext
- Noplag
- Évaluateur de papier
- Grammarly
- CopyScape
Vous devez vous assurer que votre contenu n’est pas seulement original, mais aussi du point de vue d’un bot, qu’il n’est pas perçu comme provenant d’une autre source.
Ces outils peuvent également vous aider à trouver des segments d’article similaires à d’autres contenus sur internet.
Nous disposons aujourd’hui d’outils qui nous permettent d’être « emphatiques face aux crawlers”. Quand les outils nous signalent que le contenu est trop similaire, même si nous savons qu’il y a une différence, il faut prendre connaissances des similarités.
– Outils : outils de densité de mots-clés
Deux exemples d’outils de densité de mots-clés qu’Alexis utilise sont :
- TagCrowd
- SEObook
Problèmes typiques selon le type de site
La résolution des contenus dupliqués dépend vraiment du type de contenu que vous publiez et du type de problème auquel vous êtes confronté. Les blogs ne sont pas confrontés aux mêmes problèmes que les sites e-commerce, par exemple.
Cas marquants
Alexis nous partage aujourd’hui les cas récents de clients où il a trouvé des problèmes liés aux doublons.
– Résultats sur un site massif après l’ajout de contenu unique
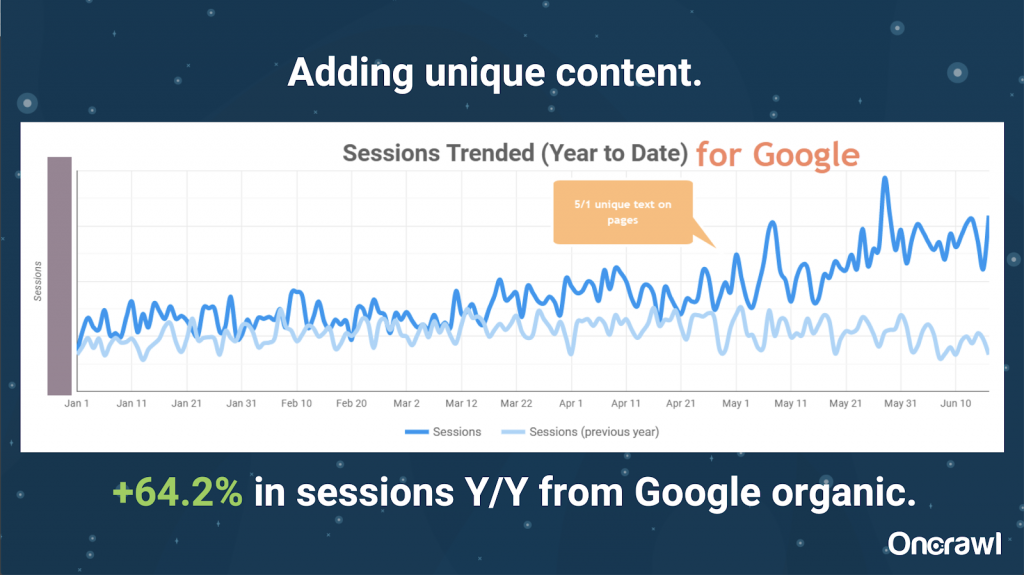
Ce site était excessivement important et a dû faire face à des problèmes de budget de crawl. Il compte 86 millions de pages qui n’ont pas encore été indexées, et seulement 1 % environ de ses pages l’ont été.
Il s’agit d’un site immobilier, une grande partie du contenu n’est pas particulièrement unique, et beaucoup de leurs pages sont très, très similaires. Alexis a fini par ajouter du contenu à la page ainsi que des informations spécifiques afin de les différencier. Il était surprenant de voir à quelle vitesse les résultats sont apparus dit-il. (Ce ne sont que des données organiques de Google.)
Pour Alexis, il s’agit d’une étude de cas assez générique. Bien que nous parlions aujourd’hui de l’EAT et d’autres choses similaires, cela démontre que dès que les moteurs de recherche considèrent le contenu comme unique et précieux, ce sera toujours récompensé.

Sur ce site, un problème canonique accidentel de tags a provoqué l’envoi d’environ 250 pages au mauvais protocole.
Les balises canoniques indiquaient la mauvaise page principale, poussant les pages HTTP à la place de la page HTTPS.
Évolutions au cours des derniers 18 mois
Alexis a écrit un article très complet, “Duplicate content and strategic resolution”, environ 18 mois avant ce webinaire. Le référencement évolue rapidement, et vous devez constamment renouveler et réévaluer vos connaissances.
Pour Alexis, la plupart de ce qui est mentionné dans l’article est toujours pertinent aujourd’hui, à l’exception de rel=next/prev, mais elle espère cela ne sera plus le cas d’ici 5 ans.
Problèmes techniques traités par les développeurs : gestion trop manuelle
Bon nombre des problèmes liés au contenu dupliqué qui sont traités par les développeurs sont beaucoup trop manuels. Alexis pense qu’ils devraient plutôt être gérés par les CMS et Adobe. Par exemple, vous ne devriez pas avoir à vérifier manuellement et à vous assurer que toutes les balises canoniques sont définies et cohérentes.
– Opportunités d’automatisation/notification
Il existe de nombreuses possibilités d’automatisation concernant les problèmes liés au contenu dupliqué. Pour donner un exemple : nous devrions être capables de détecter immédiatement si des liens vont vers HTTP quand ils devraient aller vers HTTPS, et de les corriger.
– Freins de l’âge du site et structure historique comme freins
Certains systèmes back-end sont beaucoup trop anciens pour supporter certains changements et automatisations. Il est extrêmement difficile de migrer un ancien CMS vers un nouveau.
Omi donne l’exemple de la migration des sites web de Canon vers un nouveau CMS personnalisé. Non seulement le coût était élevé, mais cela leur a pris plus de 12 mois.
Rel prev/next et la communication de Google
Parfois, la communication de Google est un peu confuse. Omi cite un exemple où, en appliquant rel=prev/next, son client a vu une augmentation significative des performances en 2018, malgré l’annonce de Google en 2019 que ces balises n’avaient pas été utilisées depuis des années.
– Pas de solution unique pour tous les cas spécifiques
La difficulté avec le référencement s’explique par le fait que chaque personne voit une version différente de ce même référencement, celui-ci n’est jamais à caractère unique.
Malheureusement, beaucoup des déclarations de Google sont erronées (comme le cas de rel=next/prev).
Attentes pour le futur de la gestion du contenu dupliqué
- Moins de contenu technique en double (à mesure que les CMS s’en aperçoivent).
- Plus d’automatisation (tests unitaires et tests externes). Par exemple, des outils comme Oncrawl peuvent régulièrement parcourir votre site et vous avertir dès qu’ils remarquent certaines erreurs.
- Détectez automatiquement les pages et les types de pages de haute similitude pour les rédacteurs et les gestionnaires de contenu. Cela pourrait automatiser certaines des vérifications qui sont actuellement effectuées manuellement dans des outils comme Grammarly : quand quelqu’un essaie de publier, le CMS devrait dire « c’est un peu pareil, êtes-vous sûr de vouloir publier ceci ?
- Que Google continuent d’améliorer leurs systèmes existants et la détection.
- Un système d’alerte pour indiquer une mauvaise compréhension des canoniques par Google.
Aujourd’hui, les websmasters ont besoin de plus d’outils et Google se doit d’implementer de nouveaux éléments.
Astuces techniques préférées d’Alexis
Alexis a plusieurs astuces techniques :
- Le remote EC2. C’est un excellent moyen d’accéder à un ordinateur pour les très gros crawls, ou tout ce qui nécessite beaucoup de puissance de calcul. C’est extrêmement rapide une fois que vous l’avez installé. En revanche, le service est payant donc assurez-vous de le fermer lorsque vous avez terminé.
- Vérifier mobile first, reconnu comme étant la représentation la plus précise aux yeux de Google. (DOM)
- Passer à Googlebot. Cela vous donnera une idée de ce que les Googlebots voient vraiment.
- Utiliser l’outil robots.txt de TechnicalSEO.com. C’est l’un des outils de Merkle, mais Alexis l’aime particulièrement parce que robots.txt peut parfois être très déroutant.
- Utiliser un log analyzer.
- Procéder avec le vérificateur htaccess de Made with Love
- Utiliser Google Data Studio pour rendre compte des changements (synchronisation des feuilles avec les mises à jour, filtrage de chaque page etc..).
Difficultés de SEO technique : robots.txt
Robots.txt peut être vraiment déroutant.
C’est un fichier archaïque qui semble pouvoir supporter RegEx, mais qui finalement, ne le supporte pas.
Différentes règles de préséance existent pour interdire et autoriser des règles, ce qui peut prêter à confusion.
Les bots peuvent ignorer des choses différentes, même s’ils ne sont pas censés le faire.
Ce que vous supposez juste, ne l’est pas toujours.

Q&A
– HSTS : un protocole séparé est-il obligatoire ?
Vous devez avoir tous les HTTPS pour le contenu dupliqué si vous avez le HSTS.
– Le contenu traduit est-il du contenu dupliqué ?
Souvent, lorsque vous utilisez hreflang, vous l’utilisez pour empêcher les ambiguïtés entre les versions localisées d’une même langue, comme par exemple, une page américaine et une page irlandaise en anglais. Alexis ne considère pas ce contenu comme dupliqué, mais elle recommande de s’assurer que les balises hreflang sont correctement configurées.
– Est-il possible d’utiliser de balises canoniques à la place des redirections 301 pour une migration HTTP/HTTPS ?
Il serait utile de vérifier ce qui se passe réellement dans les SERPs. Idéalement, s’il s’agit exactement de la même page, vous devriez utiliser un 301. Alexis a déjà fait face à des balises canoniques pour ce type de migration.
D’après l’expérience d’Omi, il suggère fortement d’utiliser des 301 pour éviter les problèmes : si vous migrez un site web, autant le migrer correctement pour éviter les erreurs.
– Effet des titres de page dupliquées
Supposons que vous ayez un titre similaire à différents endroits, mais que le contenu soit très différent. Bien qu’il ne s’agisse pas d’un contenu dupliqué pour Alexis, elle considère que les moteurs de recherche voient cela comme un titre » global « , et les titres peuvent être utilisés pour identifier les domaines.
C’est ici que vous pouvez utiliser une requête [site : + intitle : ].
Cependant, ce n’est pas parce que vous avez la même balise titre que cela va créer du contenu dupliqué.
Vous devriez toujours viser des titres et des méta descriptions uniques, même sur des pages paginées ou d’autres très similaires. Ceci n’est pas dû aux doublons, mais plutôt à la manière dont vous souhaitez optimiser la présentation de vos pages dans les SERPs.
Meilleure recommandation
« Le contenu dupliqué est à la fois un défi technique et un défi pour le content marketing. »
SEO in Orbit est parti dans l’espace
Si vous avez manqué notre voyage dans l’espace, découvrez quelles astuces nous avons envoyées le 27 juin dernier.
