
Le 11 mai dernier, nous tenions un webinar consacré au budget crawl de Google. Pour son 2ème webinar avec Oncrawl, Erlé Alberton, ancien responsable SEO d’Orange & Sosh et désormais nouveau Customer Success Manager chez Oncrawl, présente le concept de budget de crawl, les bonnes pratiques pour l’optimiser, les erreurs à éviter, etc. Des exemples pratiques viendront illustrer ce concept récemment affirmé par Google.
Ce que dit Google sur le « Crawl Budget »
À la mi-janvier Google a posté un article sur leur blog en déclarant ceci sur le crawl budget : “nous ne disposons pas d’un terme unique pour décrire tout ce que ce terme semble signifier en externe”. En d’autres mots ce que nous, les SEOs, nous considérons comme le crawl budget.
Le géant du web indique aussi que si vos nouvelles pages sont généralement explorées le jour même de leur publication, alors vous n’avez pas vraiment à vous préoccuper du budget de crawl. Il affirme également que si un site dispose de moins de quelques milliers d’URLs, il sera crawlé correctement et qu’habituellement le crawl budget est réservé aux sites à fort volume… Ceci s’avère à la fois vrai et faux, car tous les sites dans la Google Search Console ont forcément du budget de crawl. On peut d’ailleurs facilement le constater dans les suivis des métriques de Google.
On apprend pareillement dans cet article que Google cherche à atteindre une limite de volume de crawl qu’il peut faire sur votre site. On peut constater que, par exemple lorsqu’un temps de chargement est trop long, Google coupe son budget quasiment en 2. Cela dit, il y a donc des facteurs qui peuvent impacter le budget de crawl comme une mauvaise architecture (système, status codes, maillage), des contenus faibles et/ou dupliqués, des spider traps, etc.
Rappel du fonctionnement du Crawl Budget de Google
Le crawl de Google est un ensemble d’étapes simples qu’il opère de manière récursive pour chaque site. Voici un graphique provenant de Google où l’on voit que le crawl débute avec un hit sur un robot txt et qu’ensuite c’est un dépilage d’un ensemble d’URLS qui sont compilées dans une liste que Google va tenter de fetcher en comparant avec les URLS qu’il connaît déjà en plus des maîtrises qu’il a déjà en base.

Son objectif est de remplir son index de façon exhaustive et le plus précisément possible. On constate que même si le site est en JavaScript, Google va envoyer des crawlers de 3e niveau. Il faut tout de même faire attention avec les sites en JavaScript, car ils consomment énormément de ressource machine et sont envoyés en moyenne seulement 1 fois par trimestre. Il faut repenser à sa méthode pour que Google ait accès aux pages en dehors d’une navigation JavaScript.
Google va ensuite vérifier l’état de la mise à jour de la page (comparaison avec le contenu indexé précédemment) pour évaluer si la page est importante ou peu importante. En effet, Google doit optimiser ses ressources de crawl, car il ne peut crawler toutes les pages de tous les sites du web. C’est ce qu’on appelle le “page importance”… c’est un score très important à suivre et que l’on verra en détails plus bas !
Constat : si Google optimise c’est qu’il y a un sujet
Le budget de crawl dépend :
- De la capacité de votre site à répondre rapidement ;
- De la santé du site – 4xx, 5xx, 3xx (quand un site commence à avoir des 404 ou des 500, le budget de crawl est affecté, car il passera son temps à surveiller si les corrections ont été apportées) ;
- De la richesse des contenus – sémantique et exhaustivité ;
- De la diversité des ancres (une page est importante quand elle reçoit beaucoup de liens. Grâce au InRank d’Oncrawl vous pouvez analyser le tout) ;
- De la popularité de vos pages – externe/interne ;
- De facteurs purement « optimisants » – simplifier le crawl (réduction du poid des images, capacité d’avoir des css, js, gif, fonts, etc.)


Les composantes importantes pour le Google Page Importance
La notion de “Page Importance” n’est pas pareille que celle du Page Rank :
- Localisation de la page dans le site – profondeur sur le taux de crawl ;
- Page Rank : TF/CF de la page – Majestic ;
- Le Page Rank interne – InRank Oncrawl ;
- Type de document : PDF, HTML, TXT (le PDF est souvent un fichier final et considéré comme qualitatif donc très crawlé) ;
- L’inclusion dans le sitemap.xml ;
- Le nombre de liens internes ;
- La qualité/l’importance des ancres ;
- Contenu de qualité : nombre de mots, peu de near duplicate (Google va hitter les contenus similaires si les pages sont trop proches en contenu) ;
- L’importance de la page mère.
Comment planifier les URLS importantes à crawler
“URL scheduling” : Quelles pages Google a-t-il envie de visiter et à quelle fréquence ?
Dans l’exemple ci-dessus, (observation de la fréquence de crawl d’un même site) Google ne crawle pas à la même fréquence sur les différents groupes. On constate que quand Google crawle une partie du site, l’impact sur le ranking se voit rapidement.
Plus d’informations sur le budget de crawl de Google
- 100% des sites déclarés dans la Google Search Console ont des données d’exploration ;
- On peut suivre son « Crawl Behavior » grâce à l’analyse de ses logs qui permet de détecter rapidement une anomalie dans le comportement du bot ;
- Un mauvais maillage interne (pagination, facette, pages orphelines, spider trap) peut empêcher Google de crawler les bonnes pages ;
- Le budget de crawl est directement en relation avec le ranking.


Page Speed First
Le facteur le plus important est le temps de chargement d’une page qui joue un rôle décisif sur le budget de crawl. En effet, nous sommes aujourd’hui dans un monde mobile. Votre meilleur atout est donc le temps de chargement des pages pour optimiser votre budget de crawl et votre SEO. À l’heure des révolutions mobiles, le temps de chargement est un facteur essentiel à l’évaluation de la qualité d’un site. Sa capacité à répondre rapidement – surtout pour les mobiles et l’index mobile first.
Pour l’optimiser, on peut utiliser des solutions CDN (Content Delivery Network) comme Cloudflare. Ces solutions permettent aux robots de Google d’être le plus proche possible des ressources et de charger les pages le plus rapidement possible.
Google teste en permanence la capacité d’un site à répondre rapidement. La qualité de l’architecture et du code ont un fort impact sur le crédit accordé par Google.

Le temps de chargement
C’est le premier facteur d’attribution de budget de crawl !
Au niveau du serveur, il faut :
- Éviter les redirections ;
- Autoriser la compression ;
- Améliorer les temps de réponse.

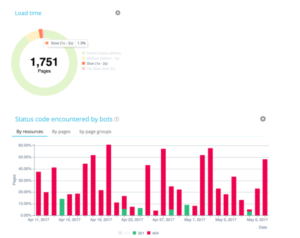
Ci-dessus, un exemple avec le site de la plateforme Manageo qui avait un budget de crawl linéaire et où l’on peut apercevoir une augmentation linéaire. En mai, il y a un décroché du nombre de pages explorées par jour et donc en conséquence un changement dans la vitesse de réponse du site. Google voit que le site répond moins vite alors il coupe en deux son budget de crawl. Pour corriger tout cela, il faut, côté serveur, optimiser vos codes, réduire les redirections, utiliser la compression, etc.

Au niveau du front, il faut :
- Exploiter la mise en cache navigateur ;
- Réduire la taille des ressources (optimiser les images, utiliser des CDN / afficher en priorité les contenus visibles (lazy loading) / supprimer les JS qui bloquent l’affichage ;
- Utiliser les scripts asynchrones.
Perte de qualité = perte d’amour = perte de budget
Aussi simple que cela ! Il faut ainsi vérifier les status code renvoyés aux robots Google afin de s’assurer que le SI est propre. C’est le seul moyen pour Google de valider que la qualité de votre code et votre architecture est propre.
Le fait de suivre leur évolution dans le temps permet de s’assurer que les mises à jour du code sont SEO friendly. Google dépense énormément sur les ressources (css, img, js) donc il faut s’assurer qu’elles soient impeccables.
Un contenu unique et riche

Plus une page est importante, plus elle a un texte riche. On le voit ci-dessus, le nombre de pages crawlées et non crawlées par Google est lié au nombre de mots qui sont présents dans la page. Vos pages doivent donc être “nourries” et mises à jour le plus régulièrement possible.
Attention aux canoniques et au contenu dupliqué
Google dépensera deux fois plus de budget lorsque deux pages similaires ne pointent pas vers la même URL canonique. Ainsi, la gestion des canoniques peut devenir critique pour les sites avec des facettes, ou des liens externes avec queryString.
La gestion du contenu en near duplicate et les canoniques deviennent des aspects importants de l’optimisation du budget de crawl.
Maillage interne et répartition du InRank

Les pages qui génèrent des visites SEO sont considérées comme actives. Ce sont celles qui se trouvent en haut de l’architecture du site. Par contre, on voit ici qu’à la page 15 il y a un groupe de pages qui émerge. Peut-être que ces pages sont beaucoup plus recherchées par vos utilisateurs que vous le pensiez et nécessiteraient d’être remontées dans l’architecture pour favoriser leur ranking.

Comme nous le savons, plus les pages sont profondes, moins Google les visite !
Mes pages importantes sont elles bien placées ?

Astuce : si vous voulez optimiser la profondeur de certains groupe de pages, n’hésitez pas à créer des plans de sites html (pages hubs), c’est-à-dire des pages déterminantes pour la gestion de votre profondeur.
Google hit toutes les pages qu’il connaît

Google comparera les pages de votre structure vs crawlées vs actives. Ceci dit, il serait à votre avantage de résoudre le problème des pages orphelines pour lesquelles Google dépense du budget inutilement et corriger l’architecture du site pour renvoyer des liens vers des pages actives, mais hors structure.
Parfois certaines pages ne reçoivent plus de liens ;c’est ce qu’on appelle les pages orphelines. Par contre Google, lui, ne les a pas oubliées.Il va continuer à les visiter. Elles ne reçoivent plus de liens donc elles perdent en importance, mais pourtant dans le graphique de droite, certaines pages orphelines continuent de recevoir des visites SEO. Il faut savoir les identifier rapidement et corriger les problèmes de linking qui sont dans l’architecture. Ceci est un très bon moyen d’optimiser son budget de crawl.
Les erreurs à ne pas commettre
- Robots.txt en 404 ;
- Sitemap.xml & sitemap.html out of date ;
- Erreurs 50x / 40x / soft 404 ;
- Avoir des chaînes de redirections ;
- Canonicals errors ;
- Contenu dupliqué (footer) / near duplicate / HTTP vs HTTPS ;
- Temps de réponse trop long ;
- Poids des pages trop important ;
- Erreurs AMP/. Ce protocole est largement adopté par Google surtout pour les sites e-commerce (pas seulement les sites médias) ;
- Mauvais maillage interne + Rel=nofollow ;
- Utiliser le JS sans solution alternative.
Conclusions
Pour optimiser son budget de crawl il faut :
- Connaître ses pages importantes, connaître les réactions de Google ;
- Améliorer ses temps de chargement ;
- Optimiser son maillage interne : remonter les pages importantes dans l’architecture ;
- Corriger les pages orphelines ;
- Augmenter le volume de texte des pages importantes ;
- Mettre à jour au maximum les pages importantes – freshness ;
- Réduire les contenus faibles et dupliqués ;
- Optimiser les canonicals, les images, le poids des ressources ;
- Éviter les chaînes de redirection ;
- Suivre ses logs et réagir en fonction des anomalies (voir le use case de Manageo lors du SEOcamp Lyon sur le sujet).
Pour optimiser son budget de crawl il faut suivre précisément le crawl de Google

Certains moments du parcours de Google sur votre site sont plus importants que d’autres donc il faut savoir les optimiser.
Pour optimiser son budget de crawl il faut bien gérer sa migration HTTPS (HTTP2)

Il faut pouvoir le suivre et le monitorer. Challengez vos équipes IT à faire le passage au HTTP2 avec HTTPS.
Retrouvez l’intégralité du webinar
Oncrawl permet de suivre jour après jour le budget de crawl de Google et de cibler rapidement les rectifications et les évolutions structurelles à entreprendre dès aujourd’hui pour améliorer vos performances SEO.