
Diagnostiquer les problèmes SEO de l’implémentation JavaScript d’un site n’est pas toujours évident. Lorsque l’on opte pour un rendu côté serveur (Server Side Rendering) ou un rendu hybride pour les bots (Pre-rendering), la tâche peut se complexifier davantage.
Il faut s’assurer que la version servie aux bots Google est bien complète, que tous les éléments javascript ont bien exécutés côté serveur et sont présents dans le html crawlés par le bot.
Dans cet article, nous allons voir comment tester rapidement et simplement votre rendu JS pour l’ensemble de vos pages avec Oncrawl.
SEO et JS
Avant de commencer avec la pratique, revenons rapidement sur l’intérêt en SEO du Server Side Rendering (SSR) et du Pre-rendering des éléments javascript d’un site.
JS et Google : les bonnes pratiques
Par défaut, le rendu HTML du javascript est effectué par le client, c’est-à-dire votre navigateur internet. Lorsque vous demandez une page contenant des éléments en JS, c’est votre navigateur qui exécute ce code javascript pour afficher la page complète. On parle ici de Client Side Rendering (CSR).
Pour Google c’est un problème car cela nécessite beaucoup du temps et surtout des ressources. Cela l’oblige à parcourir deux fois votre page, une première fois pour récupérer le code, puis une deuxième fois après avoir fait le rendu HTML du JS.
Conséquence directe du CSR pour votre SEO, le contenu complet de vos pages ne sera pas visible immédiatement par Google et donc cela peut retarder l’indexation de celles-ci. De plus, le crawl budget qui est accordé à votre site est également affecté car vos pages nécessitent d’être crawlées deux fois.
Le SSR (server side rendering)
Dans le cas du SSR, le rendu HTML du javascript est effectué côté serveur pour l’ensemble des visiteurs du site, humains et bots. Conséquence, Google n’a pas besoin de gérer le contenu en JS car il obtient directement le html complet au moment du crawl. Cela corrige le défaut du javascript en SEO.
Par contre, le coût des ressources pour réaliser ce rendu côté serveur peut-être important. C’est là qu’intervient la troisième option, le pré-rendering.
Le pre-rending (dynamic rendering)
Dans cette configuration hybride, l’exécution du JS est faite côté client pour l’ensemble des visiteurs (CSR) sauf pour les bots des moteurs de recherche. Un contenu HTML pré-rendu est servi aux bots Google de manière à conserver les avantages SEO du SSR mais aussi les avantages économiques du CSR.
Cette pratique qui à priori pourrait être considérée comme du cloaking (le fait de proposer des versions différentes aux bots et aux visiteurs d’une page internet) est en fait une idée de Google qui est fortement recommandée. On devine aisément pourquoi.
Comment tester le rendu Javascript avec Oncrawl ?
Il existe de nombreuses façons de diagnostiquer les erreurs SEO d’implémentation du JS. En utilisant Oncrawl vous allez pouvoir tester l’ensemble de vos pages et de manière automatique sans avoir à faire des comparaisons manuellement.
Oncrawl est capable de crawler un site en exécutant le javascript côté client. L’idée est donc de lancer deux crawls et de générer une comparaison entre :
- Un crawl avec le rendu JS activé
- Un crawl avec le rendu JS désactivé
Puis de mesurer à travers plusieurs métriques les différences entre ces deux crawls, signes qu’une partie du javascript n’est pas exécutée côté serveur.
A noter, dans le cas du pre-rendering le second crawl devra être fait avec un user-agent Google de manière à crawler la version pré-rendue du site.
Ce test peut se réaliser en trois étapes :
- Créer les profils de crawl
- Crawler le site avec chaque profil et générer un crawl over crawl
- Analyser les résultats
Créer les profils de crawl
Le profil avec JS
Depuis la page de votre projet, cliquez sur « + Set up new crawl ».
Cela vous amènera à la page des paramètres du crawl. Vos paramètres de crawl par défaut sont affichés. Vous pouvez soit les modifier, soit créer une nouvelle configuration de crawl.
Un profil de crawl est un ensemble de paramètres qui a été enregistré sous un nom à utiliser ultérieurement.
Pour créer un nouveau profil de crawl, cliquez sur le bouton bleu « + Create Crawl Profile » en haut à droite.
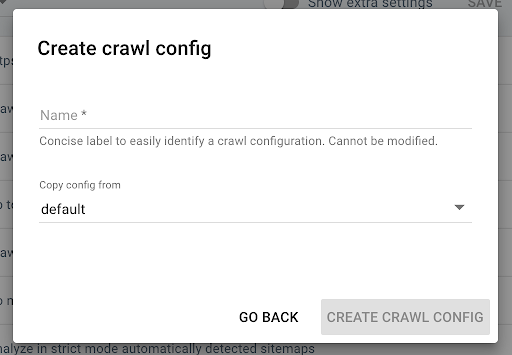
Nommez le “Crawl avec JS” et copiez votre profil de crawl habituel (le Default par exemple).
Pour activer le JS sur ce nouveau profil, il faut afficher les paramètres supplémentaires qui sont masqués par défaut. Pour y accéder, cliquez sur le bouton « Show extra settings » en haut de la page.
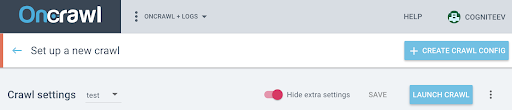
Rendez-vous ensuite au niveau des Extra settings puis cliquez sur “Enable” au niveau de l’option Crawl JS.
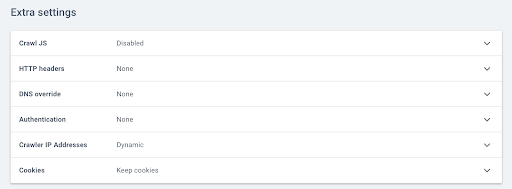
Remarque : Pensez à adapter votre vitesse de crawl par rapport à la capacité des serveurs de votre site sachant qu’Oncrawl va faire beaucoup plus d’appels par URL afin d’exécuter les éléments en Javascript. La vitesse idéale est celle que votre serveur et l’architecture de votre site peuvent le mieux supporter. Si la vitesse d’exploration d’Oncrawl est trop élevée, votre serveur risque de ne pas pouvoir suivre.
Le profil sans JS
Pour ce deuxième profil de crawl, suivez les mêmes étapes et décochez la case JS enable.
Note : il est important d’avoir deux profils avec un scope identique pour que la comparaison ait un sens.
Si votre site est en Serveur Side Rendering, passez à l’étape suivante.
Si votre site est en pre-rendering basé pour les bots Google, il faudrait nous faire une demande pour vous modifier le User Agent du crawl. Une fois le profil créé, envoyez-nous un message via Intercom directement dans l’application pour que l’on vous remplace le User Agent Oncrawl par un User Agent Google bot.
Demandez votre démo personnalisée

Lancez vos crawls et générez un Crawl over Crawl
Une fois les deux profils créés, vous n’avez plus qu’à crawler votre site avec ces deux profils tour à tour. Pour vous faciliter la tâche, vous pouvez utiliser la fonction de programmation de crawl.
Programmer un crawl
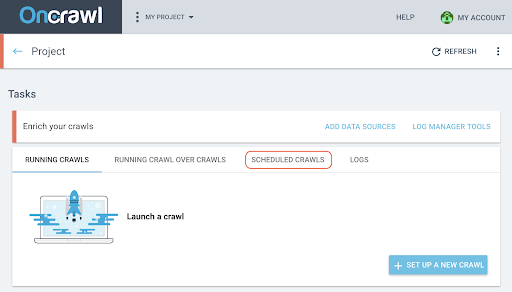
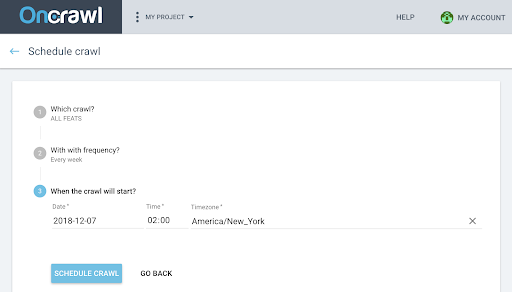
- Sur la page du projet, cliquez sur l’onglet « Scheduled crawls » en haut de la boîte de suivi du crawl.
- Cliquez sur « + Schedule crawl » pour planifier un nouveau crawl.
- Vous devrez ensuite choisir :
- Le profil de crawl que vous souhaitez utiliser pour le futur crawl
- La fréquence pour répéter le crawl, choisissez « Just once ».
- La date, l’heure (en format 24 heures) et le fuseau horaire (par ville) du moment où vous souhaitez que le crawl se lance.
- Cliquez sur « schedule crawl ».
Une fois que les deux analyses de vos crawls seront disponibles vous devez générer un crawl over crawl.
Générer un Crawl over Crawl
- Depuis la page d’accueil du projet, lancez un crawl over crawl :
- Sous « Tasks », cliquez sur l’onglet « Running Crawl over Crawls ».
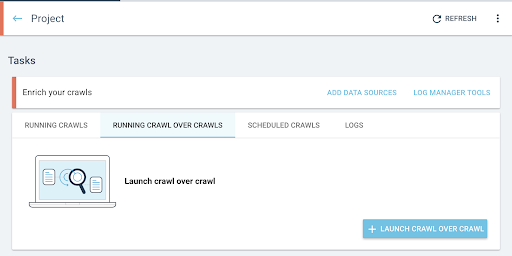
- Cliquez sur « + Start crawl over crawl ».
- Sélectionnez les deux crawls que vous souhaitez comparer.
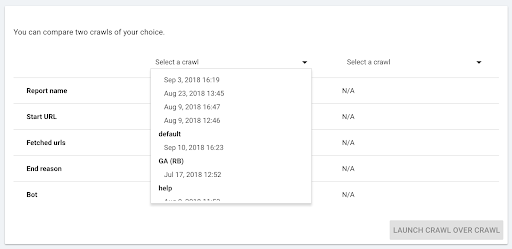
Lorsque vous cliquez sur « + Run crawl over crawl », Oncrawl analyse les différences entre les deux crawls existants et ajoute le rapport Crawl over Crawl aux résultats d’analyse des deux crawls.
Vous pouvez suivre la progression de ce crawl over crawl dans l’onglet « Lancer le crawl over crawl » sur la page d’accueil du projet. Comme le crawl est déjà terminé, le crawl over crawl sautera l’état « Crawling » et commencera directement par « Analyse ».
Analyser les résultats
Rendez-vous sur le rapport de crawl over crawl sur les trois vues suivantes :
- Structure
- Content
- Internal linking
Vous pouvez également télécharger notre custom dashboard prévu à cet effet.
Quelles métriques regarder ?
Page crawled, Average word count per page et Average text to code ratio
Premier indicateur Page crawled vous montre immédiatement si les deux profils on crawlé le même nombre de pages.
Si la différence n’est pas significative, vous pouvez vérifier deux indicateurs on page:
- Average word count per page
- Average text to code ratio
Ces deux métriques vont mettre en évidence une différence du contenu html avec ou sans exécution du javascript côté client.
S’il y a moins de mots par pages en moyenne, c’est qu’une partie du contenu de la page n’est pas disponible sans rendu du JS.
De même, si le text to ratio est plus faible, c’est qu’une partie du contenu de la page n’est pas disponible sans rendu du JS.
Le text to code ratio mesure la part du contenu d’une page qui est visible (texte) et la part d’encodage du contenu (code). Plus le pourcentage rapporté est élevé, plus la page contient de texte par rapport à la quantité de code.
Depth, Inrank et Inlinks
Vous pouvez ensuite regarder les métriques liées à votre maillage interne qui sont plus sensibles. Qu’une petite partie du contenu de la page ne soit pas disponible sans rendu JS n’est à priori pas forcément problématique pour votre SEO, par contre si cela impact votre maillage interne, les conséquences sur la crawlabilité de votre site et le crawl budget sont plus importantes.
Comparez la profondeur moyenne, l’Inrank moyen, le nombre moyen d’Inlinks et outlinks interne.
Une profondeur moyenne en hausse, un inrank moyen en baisse et un nombre moyen d’Inlinks et outlinks en baisse, sont des indicateurs de l’existence de blocs de maillage gérés en JS non pré-rendu côté serveur. Résultat, une partie des liens n’est pas immédiatement disponibles pour le bot google.
Cela peut avoir des conséquences sur tout ou une partie de votre site. Il convient ensuite d’étudier ces modifications par groupe de pages pour identifier si certains types de pages sont défavorisées par ce maillage en javascript.
Le data explorer vous permettra de jouer avec les filtres pour faire ressortir ces éléments.
Aller plus loin avec le Data explorer et le URL details
Dans le Data explorer
Lorsque vous consultez les données de Crawl over Crawl dans l’explorateur de données (Data explorer), vous verrez deux colonnes d’URL : une pour les URL de Crawl 1 et une pour les URL de Crawl 2.
Vous pouvez ensuite ajouter chacune des métriques citées plus haut (crawled pages, wordcount, text to code ration, depth, inrank, inlinks) deux fois chacune pour afficher la valeur du crawl 1 et du crawl 2 côte à côte.
En utilisant les filtres vous allez pouvoir identifier les URLs avec les plus grands écarts.
URL details
Si vous avez identifié des différences entre la version SSR et/ou Prérendue et la version avec le rendu côté client, il va falloir ensuite rentrer dans les détails pour comprendre quels sont les éléments JS qui ne sont pas optimisés pour le SEO.
En cliquant sur une page dans le Data explorer, vous basculez dans l’URL details et vous pouvez ensuite consulter le code source telle que vue par Oncraw en cliquant sur l’onglet “ “view source”.
Vous pouvez ainsi récupérer le code HTML en cliquant sur Copy HTML source.
En haut à gauche, vous pouvez basculer d’un crawl à un autre pour récupérer l’autre version du code.
En utilisant un outil de comparaison de code html, vous pourrez comparer les deux versions d’une page, avec JS et sans JS exécuté côté client. Pour le reste, c’est à vous de jouer !
