
Qu’est-ce que la prévision SEO ?
La prévision SEO, ou l’estimation du trafic organique, est le processus d’utilisation des données de votre propre site, ou des données tierces, afin d’estimer le futur trafic organique de votre site, les revenus SEO et le ROI SEO. Cette estimation peut être calculée à l’aide de plusieurs méthodes différentes basées sur nos données.
Dans ce tutoriel, nous souhaitons prédire nos revenus organiques hors marque et notre trafic organique hors marque en fonction des positions de nos URLs et de leurs revenus actuels. Cela peut nous aider, en tant que SEO, à obtenir plus de soutien de la part des autres parties prenantes, qu’il s’agisse d’une augmentation du budget mensuel, trimestriel ou annuel ou d’une plus grande nombre d’heures de travail de la part des équipes produit et de développement.
Sachez que ce tutoriel n’est pas uniquement applicable au trafic organique hors marque ; en apportant quelques modifications et en connaissant Python, vous pouvez l’utiliser pour estimer le trafic de vos pages cibles.
En conséquence, nous pouvons produire une Google Sheet comme l’image ci-dessous:
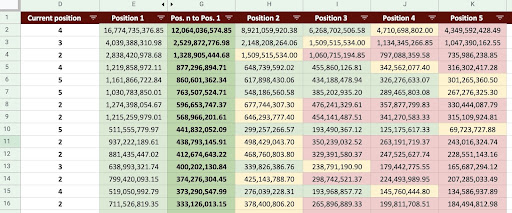
Image de Google Sheets
Prévision du trafic SEO hors marque
La première question que vous êtes susceptible de vous poser après avoir lu l’introduction est la suivante : « Pourquoi calculer le trafic organique hors marque ? »
Prenons l’exemple d’une entreprise comme Amazon. Lorsque vous voulez acheter un livre ou un masque, vous chercherez simplement « acheter masque amazon. »
Les marques viennent plus souvent en tête lorsque vous voulez acheter quelque chose, et vous avez tendance à privilégier vos achats auprès de ces entreprises. Dans chaque secteur, il existe des entreprises de marque qui ont une influence sur le comportement des utilisateurs dans les recherches Google.
Si nous regardons les données de Google Search Console (GSC) d’Amazon, nous découvrirons probablement que beaucoup de trafic provient de requêtes de marque et que, la plupart du temps, le premier résultat des requêtes de marque est le site de la marque elle-même.
En tant que SEO, peut-être que, comme moi, vous avez entendu à plusieurs reprises que « Seule notre marque aide notre SEO ! ». Comment pouvons-nous dire, « Non, ce n’est pas le cas, » et démontrer le trafic et les revenus des requêtes sans marque ?
Il est encore plus compliqué de le prouver, car nous savons que les algorithmes de Google sont très complexes et qu’il est difficile de séparer de manière distincte les recherches liées à une marque de celles qui ne le sont pas. Mais c’est ce qui rend notre travail en tant que SEO d’autant plus important.
Dans ce tutoriel, je vous montrerai comment faire la distinction entre les deux – avec et hors marque – et aussi je vous montrerai à quel point le SEO peut être puissant.
Même si votre entreprise n’est pas liée à une grande marque, vous pouvez tout de même bénéficier de cet article : vous apprendrez à estimer les données organiques de votre site.
ROI du SEO basé sur l’estimation du trafic
Où que vous soyez et quoi que vous fassiez, les ressources sont limitées, qu’il s’agisse de votre budget ou simplement du nombre d’heures dans une journée de travail. Savoir comment allouer au mieux vos ressources joue un rôle majeur dans le retour sur investissement (ROI) global et celui du SEO.
Un CMO, un VP marketing ou un spécialiste du marketing opérationnel ont tous des indicateurs clés de performance différents et ont besoin de ressources différentes pour atteindre leurs objectifs. La meilleure façon de s’assurer que vous obtenez ce dont vous avez besoin est de prouver sa nécessité en montrant les retours que cela apportera à l’entreprise. Le ROI du SEO n’est pas différent. Lorsque le moment de l’allocation budgétaire arrive et que votre équipe souhaite demander un budget plus important, l’estimation de votre ROI SEO peut vous permettre de prendre le dessus dans la négociation. Une fois que vous avez calculé l’estimation du trafic hors marque, vous pouvez mieux évaluer le budget nécessaire pour obtenir les résultats souhaités.
L’effet de la prédiction SEO sur la stratégie de SEO
Tous les 3 ou 6 mois, nous devons revoir notre stratégie de SEO afin de l’ajuster pour obtenir les meilleurs résultats possibles. Mais que se passe-t-il lorsque vous ne savez pas où se trouvent les plus grands bénéfices pour votre entreprise ? Vous pouvez prendre des décisions, mais elles ne seront pas aussi efficaces que celles prises lorsque vous aurez une vue plus complète du trafic du site.
L’estimation des revenus du trafic organique hors marque pourra être utilisée en combinaison avec vos landing pages et la segmentation des requêtes afin d’obtenir une vue d’ensemble qui vous aidera à développer de meilleures stratégies en tant que responsable SEO ou stratège SEO.
Les différentes manières de prévoir le trafic organique
Il existe un grand nombre de méthodes et de scripts publics disponibles dans la communauté SEO permettant de prédire le trafic organique futur.
Certaines de ces méthodes comprennent :
- Prévision du trafic organique sur l’ensemble du site
- Prévision du trafic organique sur des pages spécifiques (blog, produits, catégories, etc.) ou sur une seule page.
- Prévision de trafic organique sur des requêtes spécifiques (requêtes contenant « acheter », « comment faire », etc.) ou une requête.
- Prévision de trafic organique pour des périodes spécifiques (notamment pour les événements saisonniers)
Ma méthode concerne des pages spécifiques et une période d’un mois.
[Étude de cas] Stimuler la croissance sur de nouveaux marchés grâce au SEO on-page

Comment calculer les bénéfices du trafic organique
La méthode la plus précise consiste à se baser sur les données de Google Analytics (GA). Si votre site est tout nouveau, vous devrez utiliser des outils tiers. (Je préfère éviter d’utiliser de tels outils lorsque vous disposez de vos propres données).
Attention, vous devrez tester les données de tiers que vous utilisez en les comparant à certaines de vos données de pages réelles afin de détecter toute erreur éventuelle.
Comment calculer les revenus du trafic SEO hors marque avec Python
Jusqu’à présent, nous avons abordé plusieurs concepts théoriques avec lesquels nous devrions être familiers afin de mieux comprendre les différents aspects de nos prévisions de trafic et de revenus organiques. Maintenant, nous allons nous plonger dans la partie pratique de cet article.
Tout d’abord, nous allons commencer par calculer notre courbe CTR. Dans mon article sur la courbe CTR sur Oncrawl, j’explique deux méthodes différentes et aussi d’autres méthodes que vous pouvez utiliser en modifiant un peu mon code. Je vous recommande de lire d’abord l’article sur la courbe de clics ; il vous donnera un meilleur éclairage sur celui-ci.
Dans cet article, je modifie certaines parties de mon code pour obtenir les résultats spécifiques que nous cherchons dans l’estimation du trafic. Ensuite, nous obtiendrons nos données de GA et utiliserons la dimension de revenu de GA pour estimer notre revenu.
Prévision des revenus du trafic organique hors marque avec Python
Vous pouvez lancer ce code par vous-même, sans connaître Python. Cependant, je préfère que vous soyez familiarisé avec la syntaxe Python et que vous ayez des connaissances de base sur les bibliothèques Python que je vais utiliser dans ce code de prévision. Cela vous aidera à mieux comprendre mon code et à le personnaliser en fonction de vos besoins.
Pour exécuter ce code, je vais utiliser Visual Studio Code avec l’extension Python de Microsoft, qui comprend l’extension « Jupyter.” Mais, vous pouvez utiliser le notebook Jupyter directement.
Pour l’ensemble du processus, nous devons utiliser ces bibliothèques Python :
- Numpy
- Pandas
- Plotly
Nous allons également importer certaines bibliothèques standard Python :
- JSON
- pprint
# Importing the libraries we need for our process import json from pprint import pprint import numpy as np import pandas as pd import plotly.express as px
Étape 1 : Calcul de la courbe du CTR relatif (courbe du clic relatif)
Durant cette première étape, nous voulons calculer notre courbe de CTR relatif. Mais, qu’est-ce que la courbe de CTR relatif ?
Quelle est la courbe du CTR relatif ?
Pour commencer, parlons de la “courbe de CTR absolu. » Lorsque nous calculons la courbe de CTR absolu, nous disons que le CTR médian (ou CTR moyen) de la première position est de 36% et celui de la deuxième position est de 20%, et ainsi de suite.
Dans la courbe de CTR relatif, instantanée en pourcentage, nous divisons la médiane de chaque position par le CTR de la première position. Par exemple, la courbe de CTR relatif de la première position sera 0,36 / 0,36 = 1, la deuxième sera 0,20 / 0,36 = 0,55, et ainsi de suite.
Peut-être vous demandez-vous pourquoi il est utile de le calculer ? Prenons l’exemple d’une page classée en position 1, qui a un CTR de 44 %. Si cette page passe en deuxième position, la courbe du CTR ne descend pas à 20%, il est plus probable que son CTR descende à 44% * 0,55 = 24,2%.
1. Obtenir des données sur le trafic organique de marque et hors marque auprès de GSC.
Afin de réaliser les calculs, nous devons obtenir nos données du GSC. La première fois, toutes les données seront basées sur des requêtes de marque et la fois suivante, toutes les données seront basées sur des requêtes hors marque.
Vous pouvez utiliser différentes méthodes pour obtenir ces données : par le biais de scripts Python ou en utilisant le module complémentaire « Search Analytics for Sheets » de Google Sheets. Je vais utiliser l’explorer API de GSC.
Ces données produisent deux fichiers JSON qui montrent les performances de chaque page. Un fichier qui montre les performances des landing pages basées sur les requêtes de la marque et l’autre qui montre les performances des landing pages basées sur les requêtes hors marque.
Pour récupérer des données depuis l’explorer API de la GSC, il faut suivre les étapes ci-dessous :
- Allez sur le site : https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximisez l’explorer d’API qui se trouve dans le coin en haut à droite de la page.
- Dans le champ “
siteUrl” insérez votre nom de domaine. Par exemple : “https://www.example.com” ou “http://your-domain.com”. - Dans le corps de la requête, nous devons d’abord définir les paramètres “
startDate” et “endDate”. Ma préférence se porte sur les 30 derniers jours. - Puis, nous ajoutons “
dimensions” et sélectionnons “page” pour cette liste. - Maintenant nous ajoutons “
dimensionFilterGroups” afin de filtrer nos requêtes. Une fois pour les requêtes de marque et une deuxième pour les requêtes hors marque. - A la fin, nous fixons notre “
rowLimit” à 25 000. Si les pages de votre site qui reçoivent du trafic organique chaque mois sont supérieures à 25 000, vous devez modifier le corps de votre requête. - Après avoir effectué chaque requête, sauvegardez la réponse JSON. Pour les performances de la marque, enregistrez le fichier JSON sous le nom de “
branded_data.json” et pour les performances hors marque, enregistrez le fichier JSON sous le nom de “non_branded_data.json”.
Une fois que nous avons compris les paramètres de notre corps de requête, la seule chose que vous devez faire est de copier et coller les corps de la requête ci-dessous. Pensez à remplacer vos noms de marque par des “brand variation names”.
Vous devez séparer les noms de marque par un pipeline ou “|”. Par exemple “amazon|amazon.com|amazn”.
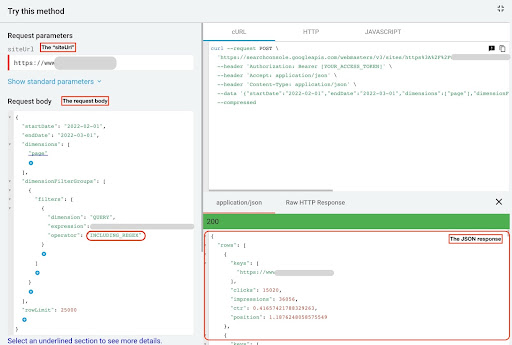
Explorateur API de la GSC
Corps de la demande de marque :
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"dimensions": [
"page"
],
"dimensionFilterGroups": [
{
"filters": [
{
"dimension": "QUERY",
"expression": "brand variation names",
"operator": "INCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Corps de la demande hors marque :
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"dimensions": [
"page"
],
"dimensionFilterGroups": [
{
"filters": [
{
"dimension": "QUERY",
"expression": "brand variation names",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
2. Importation des données dans notre notebook Jupyter et extraction des répertoires de sites
Maintenant, nous avons besoin de charger nos données dans notre carnet Jupyter pour pouvoir les modifier et en extraire ce qui nous intéresse. Reprenons là où nous nous sommes arrêtés plus tôt.
Afin de charger les données de marque, vous devez exécuter ce bloc de code :
# Creating a DataFrame for the website URLs performance on the brand, and branded queries
with open("./branded_data.json") as json_file:
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame(branded_data)
# Renaming 'keys' column to 'landing page' column, and converting 'landing page' list to an URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["landing page"] = branded_df["landing page"].apply(lambda x: x[0])
Pour les landing pages hors marque, vous devez exécuter ce bloc de code :
# Creating a DataFrame for the website URLs performance on the non-branded queries
with open("./non_branded_data.json") as json_file:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
# Renaming 'keys' column to 'landing page' column, and converting 'landing page' list to an URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["landing page"] = non_branded_df["landing page"].apply(lambda x: x[0])
Après avoir téléchargé nos données, nous devons définir le nom de notre site pour extraire les répertoires.
# Defining your site name between quotes. For example, 'https://www.example.com/' or 'http://mydomain.com/' SITE_NAME = "https://www.your_domain.com/"
Nous avons uniquement besoin d’extraire les répertoires de la performance hors marque.
# Getting each landing page (URL) directory
non_branded_df["directory"] = non_branded_df["landing page"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Ensuite, nous imprimons les répertoires afin de sélectionner ceux qui sont les plus utiles pour ce processus. Il se peut que vous souhaitiez sélectionner tous les répertoires pour avoir un meilleur aperçu de votre site.
# For getting all directories in the output, we need to manipulate Pandas options
pd.set_option("display.max_rows", None)
# Website directories
non_branded_df["directory"].value_counts()
Ici, vous pouvez insérer les répertoires qui sont pertinents pour vous.
""" Choose which directories are important for getting their CTR curve.
Insert the directories into the 'important_directories' variable.
For example, 'product,tag,product-category,mag'. Separate directory values with comma.
"""
IMPORTANT_DIRECTORIES = "your_important_directories"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Étiquetage des pages en fonction de leur position et calcul de la courbe relative au CTR
Nous devons maintenant étiqueter nos landing pages en fonction de leur position. Nous faisons cela parce que nous devons calculer la courbe du CTR relatif pour chaque répertoire en fonction de la position de sa landing page.
# Labeling non-branded positions
for i in range(1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= i) & (non_branded_df["position"] < i + 1),
"position label",
] = i
Ensuite, nous regroupons les landing pages en fonction de leur répertoire.
# Grouping landing pages based on their 'directory' value non_brand_grouped_df = non_branded_df.groupby(["directory"])
Définissons la fonction permettant de calculer la courbe relative du CTR ;
def each_dir_relative_ctr_curve(dir_df, key):
"""The function calculates each IMPORTANT_DIRECTORIES relative CTR curve.
"""
# Grouping "non_brand_grouped_df" based on their 'position label' value
dir_grouped_df = dir_df.groupby(["position label"])
# A list for saving each position median CTR
median_ctr_list = []
# Storing each directory as a key, and it's "median_ctr_list" as value
directories_median_ctr = {}
# Loop over each "dir_grouped_df" group
for i in range(1, 11):
# A try-except for handling those situations that a directory for example hasn't any data for position 4
try:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
except:
median_ctr_list.append(0)
# Calculating relative CTR curve
directories_median_ctr[key] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
return directories_median_ctr
Après en avoir défini la fonction, nous pouvons l’exécuter.
# Looping over directories and executing the 'each_dir_relative_ctr_curve' function
directories_median_ctr_dict = dict()
for key, item in non_brand_grouped_df:
if key in IMPORTANT_DIRECTORIES:
directories_median_ctr_dict.update(each_dir_relative_ctr_curve(item, key))
pprint(directories_median_ctr_dict)
Maintenant, nous allons charger nos landing pages, avec et hors marque, et calculer la courbe du CTR relatif pour nos données hors marque. Pourquoi faisons-nous cela pour les données hors marque uniquement ? Parce que nous voulons prédire le trafic organique hors marque et ses revenus.
Étape 2 : Prévision des revenus tirés du trafic organique hors marque
Dans cette deuxième étape, nous allons voir comment récupérer nos données de revenus et les prédire.
1. Fusionner les données organiques hors marque et celles de marque
Nous allons maintenant fusionner nos données de marque et hors marque. Cela nous permettra de calculer le pourcentage de trafic organique hors marque sur chaque landing page par rapport à l’ensemble du trafic.
# 'main_df' is a combination of 'whole site data' and 'non-brand data' DataFrames.
# Using this DataFrame, you can find out where most of our clicks and impressions
# come from Queries that aren't branded.
main_df = non_branded_df.merge(
branded_df, on="landing page", suffixes=("_non_brand", "_branded")
)
Ensuite, il faut modifier les colonnes pour supprimer celles qui sont inutiles.
# Modifying 'main_df' columns to those we need
main_df = main_df[
[
"landing page",
"clicks_non_brand",
"ctr_non_brand",
"directory",
"position label",
"clicks_branded",
]
]
Maintenant, calculons le pourcentage de clics hors marque par rapport au total des clics d’une landing page.
# Calculating the non-branded queries clicks percentage based on landing pages to the whole landing page clicks
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
axis=1,
)
[Ebook] Automatisation du SEO avec Oncrawl
Découvrez comment résoudre plus facilement les problèmes de SEO en automatisant les alertes lorsque les crawls sont terminés.

2. Chargement des revenus du trafic organique
Tout comme pour les données GSC, nous avons plusieurs façons d’obtenir les données GA : nous pouvons utiliser le module complémentaire Google Analytics Sheets ou l’API GA. Ici, je vais utiliser Google Data Studio (GDS) parce qu’il est très simple d’utilisation.
Afin d’obtenir les données GA du GDS, il faut :
- Dans GDS, créez un nouveau rapport ou un nouvel explorateur et un tableau.
- Pour la dimension, ajoutez « landing page » et pour la métrique, nous devons ajouter « Revenue ».
- Ensuite, vous devrez créer un segment customisé dans GA basé sur la source et le support. Filtrez le trafic « Google/organic ». Après la création du segment, ajoutez-le dans la section du segment dans le GDS.
- Finalement, exportez le tableau et sauvegardez-le sous le nom de “
landing_pages_revenue.csv”.
Exportation csv des revenus des landing pages
Chargeons nos données.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Maintenant, nous devons ajouter le nom de notre site aux URLs des landing pages de GA.
Lorsque nous exportons nos données depuis GA, les landing pages sont sous une forme relative, mais nos données GSC sont sous une forme absolue.
N’oubliez pas de vérifier les données de vos landing pages GA. L’ensemble des données avec lesquelles j’ai travaillé ont révélé que les données GA nécessitent à chaque fois une petite mise au point.
# Concating GA landing pages URLs with the SITE_NAME.
# Also, renaming the columns
organic_revenue_df.loc[:, "Landing Page"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Landing Page": "landing page", "Revenue": "revenue"}, inplace=True)
Maintenant, nous allons fusionner nos données GSC avec les données GA.
# In this step, I merge 'main_df' with 'dk_organic_revenue_df' DataFrame that contains the percentage of non-brand queries data main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
Pour finir, nous faisons un peu de tri dans les colonnes de notre DataFrame.
# A little cleaning up the 'main_df' DataFrame
main_df = main_df[
[
"landing page",
"clicks_non_brand",
"ctr_non_brand",
"directory",
"position label",
"clicks_non_brand_percentage",
"revenue",
]
]
3. Calculation des revenus hors marque
À cette étape, nous traiterons les données pour en extraire les éléments dont nous avons besoin.
Mais d’abord, il faut filtrer les landing pages en fonction des critères suivants “IMPORTANT_DIRECTORIES”:
# Removing other directories landing pages, not included in "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["directory"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=["revenue"])
.reset_index(drop=True)
)
Maintenant, voyons comment calculer le revenu du trafic organique hors marque.
J’ai défini une métrique que nous ne pouvons pas calculer facilement et c’est plus l’intuition que d’autres choses qui nous amène à lui attribuer un chiffre.
La métrique « brand_influence » montre la puissance de votre marque. Si vous pensez que les recherches non liées à la marque génèrent moins de chiffre d’affaires pour votre entreprise, réduisez ce chiffre, en le mettant à 0,8, par exemple.
# If your brand is so strong that querying without your brand can sell as much as querying with your brand, then 1 is good for you.
# Think about looking for a book without a brand name included in your query. When you see Amazon, do you buy from other marketplaces or stores?
brand_influence = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["revenue"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Faisons un camembert pour mieux comprendre les revenus hors marque basés sur les répertoires importants.
# In this cell I want to get all of non-brand landing pages revenue based on their directory
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="directory",
values=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
values="non_brand_revenue",
names=non_branded_directory_dist_revenue_df.index,
title="Non-branded revenue based on website directories",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
pie_fig.show()
Ce graphique montre la distribution des requêtes hors marque sur votre site IMPORTANT_DIRECTORIES.
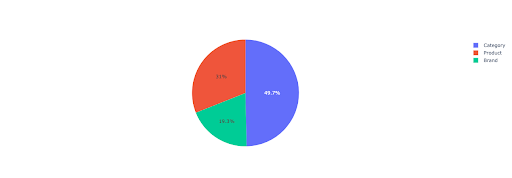
Distribution de requêtes hors marque
En me basant sur les données de ma courbe de CTR, je constate que je ne peux pas me fier au CTR pour les positions supérieures à 5. Pour cette raison, je filtre mes données en fonction de la position.
Vous pouvez modifier le bloc de code ci-dessous en fonction de vos données.
# Because of CTR accuracy in our CTR curve, I think we can skip landings with position more than 5. Because of this, I filtered other landing pages main_df = main_df[main_df["position label"] < 6].reset_index(drop=True)
4. Calcul du « revenu par clic » (RPC)
Ici, j’ai créé une mesure personnalisée que j’ai nommée « Revenu par clic » ou RPC. Cela nous montre le revenu que chaque clic hors marque a généré.
Vous pouvez utiliser cette mesure de différentes manières. J’ai trouvé une page avec un RPC élevé, mais peu de clics. En vérifiant la page, j’ai découvert qu’elle avait été indexée il y a moins d’une semaine. Nous pouvons donc utiliser des méthodes différentes pour optimiser la page.
# Calculating the revenue generated with each click (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. Prédire les revenus !
Nous arrivons à la fin, nous avons attendu jusqu’à maintenant pour prédire nos revenus organiques hors marque.
Passons aux derniers blocs de code.
# The main function to calculate revenue based on different positions
for index, row_values in main_df.iterrows():
# Switch between directories CTR list
ctr_curve = directories_median_ctr_dict[row_values["directory"]]
# Loop over position 1 to 5 and calculate the revenue based on increase or decrease of CTR
for i in range(1, 6):
if i == row_values["position label"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
else:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["position label"] - 1)]
)
# Calculating the "N to 1" metric. This shows the increase in revenue when your rank get from "N" to "1"
main_df.loc[index, "N to 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["position label"]]
En regardant le résultat final, nous avons de nouvelles colonnes. Les dénominations de ces colonnes sont « 1 », « 2 », « 3 », « 4 », « 5 ».
Que signifient ces dénominations ? Par exemple, nous avons une page en position 3 et nous souhaitons prédire ses revenus si elle améliore sa position, ou bien nous voulons savoir combien nous perdrons si nous baissons en positionnement.
Les colonnes « 1 » et « 2 » indiquent les revenus de la page lorsque le positionnement moyen de cette page s’améliore et les colonnes « 4 » et « 5 » indiquent les revenus de cette page lorsque nous chutons dans le positionnement.
Dans cet exemple, la colonne « 3 » indique le revenu actuel de la page.
J’ai également créé une métrique appelée « N to 1 ». Cela vous montre si la position moyenne de cette page passe de « 3 » (ou N) à « 1 » et dans quelle mesure ce changement peut affecter les revenus.
Conclusion
J’ai abordé beaucoup de choses dans cet article et c’est maintenant à votre tour de mettre les mains à la pâte et de prévoir les revenus de votre trafic organique hors marque.
C’est la façon la plus simple d’utiliser cette prédiction. Nous pourrions rendre cet algorithme plus complexe et le combiner avec certains modèles ML, mais cela rendrait l’article encore plus compliqué.
Je préfère sauvegarder ces données dans un CSV et les télécharger dans un Google Sheets. Ou, si j’ai l’intention de les partager avec les autres membres de mon équipe ou de l’organisation, je les ouvre avec Excel et je mets en forme les colonnes en utilisant des couleurs pour faciliter la lecture.
Sur la base de ces données, vous pouvez prédire le ROI de votre trafic organique hors marque et l’utiliser dans votre démarche de négociation.
