
Je voudrais commencer cet article par une équation très simple : si vos pages ne sont pas crawlées, elles ne seront jamais indexées et, par conséquent, vos performances SEO en souffriront toujours (et pueront).
Par conséquent, les SEOs doivent s’efforcer de trouver le meilleur moyen de rendre leurs sites Web accessibles aux robots et de fournir à Google leurs pages les plus importantes afin qu’elles soient indexées et qu’ils commencent à acquérir du trafic par leur intermédiaire.
Heureusement, nous disposons de nombreuses ressources qui peuvent nous aider à améliorer la facilité de crawl de nos sites Web, comme Screaming Frog, Oncrawl ou Python. Je vais vous montrer comment Python peut vous aider à analyser et améliorer vos indicateurs de crawlabilité et d’indexation. La plupart du temps, ce genre d’améliorations conduit également à un meilleur positionnement, à une plus grande visibilité dans les SERPs et, finalement, à l’arrivée de plus d’utilisateurs sur votre site Web.
1.- Demander l’indexation avec Python
1.1 Pour Google
Demander l’indexation pour Google peut se faire de plusieurs manières, bien que malheureusement je ne sois pas vraiment convaincu par aucune d’entre elles. Je vais vous guider à travers trois options différentes avec leurs avantages et inconvénients :
- Selenium et Google Search Console : de mon point de vue et après l’avoir testé ainsi que le reste des options, c’est la solution la plus efficace. Cependant, après un certain nombre de tentatives, il est possible qu’il y ait une pop-up captcha qui la casse.
- Pinging d’un sitemap : il est certainement utile de faire ramper les sitemaps comme demandé, mais pas des URLs spécifiques, par exemple dans le cas où de nouvelles pages ont été ajoutées au site Web.
- API d’indexation de Google : elle n’est pas très fiable, sauf pour les diffuseurs et les sites de plateformes d’emploi. Elle permet d’augmenter les taux de crawling mais pas d’indexer des URL spécifiques.
Après ce bref aperçu de chaque méthode, examinons-les une par une.
1.1.1 – Selenium et Google Search Console
Essentiellement, ce que nous allons faire dans cette première solution est d’accéder à Google Search Console depuis un navigateur avec Selenium et de reproduire le même processus que nous suivrons manuellement pour soumettre de nombreuses URLs à l’indexation avec Google Search Console, mais de manière automatisée.
Remarque : n’abusez pas de cette méthode et ne soumettez une page à l’indexation que si son contenu a été mis à jour ou si la page est entièrement nouvelle.
L’astuce pour pouvoir se connecter à Google Search Console avec Selenium est d’accéder d’abord au OUATH Playground comme je l’ai expliqué dans cet article sur la façon d’automatiser le téléchargement des rapports de statistiques de crawl de GSC.
#Nous importons ces modules
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
#Nous installons notre Selenium Driver
driver = webdriver.Chrome(ChromeDriverManager().install())
#Nous accédons au compte OUATH playground pour nous connecter aux services Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent.com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Nous attendons un peu pour nous assurer que le rendu est complet avant de sélectionner des éléments avec Xpath et d'introduire notre adresse email.
time.sleep(10)
form1=driver.find_element_by_xpath('//*[@id="identifierId"]')
form1.send_keys("<your email address>")
form1.send_keys(Keys.ENTER)
#Même chose ici, nous attendons un peu et ensuite nous introduisons notre mot de passe.
time.sleep(10)
form2=driver.find_element_by_xpath('//*[@id="password"]/div[1]/div/div[1]/input')
form2.send_keys("<your password>")
form2.send_keys(Keys.ENTER)
Après cela, nous pouvons accéder à notre URL Google Search Console :
driver.get('https://search.google.com/search-console?resource_id=your_domain”')
time.sleep(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div/div[1]/input[2]')
box.send_keys("your_URL")
box.send_keys(Keys.ENTER)
time.sleep(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div/div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
time.sleep(120)
Malheureusement, comme expliqué dans l’introduction, il semble qu’après un certain nombre de demandes, il commence à exiger un captcha de type puzzle pour procéder à la demande d’indexation. Comme la méthode automatisée ne peut pas résoudre le captcha, c’est un élément qui handicape cette solution.
1.1.2 – Pinging d’un sitemap
Les URLs de sitemap peuvent être soumises à Google par la ping méthode. En principe, il suffit d’envoyer une requête au point de terminaison suivant en introduisant l’URL de votre sitemap comme paramètre :
http://www.google.com/ping?sitemap=URL/of/file
Ceci peut être automatisé très facilement avec Python et des requêtes comme je l’ai expliqué dans cet article.
import urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" response = urllib.request.urlopen(url)
1.1.3 – API d’indexation Google
L’API d’indexation de Google peut être une bonne solution pour améliorer vos taux de crawl, mais ce n’est généralement pas une méthode très efficace pour indexer votre contenu. En effet, elle n’est censée être utilisée que si votre site Web contient un JobPosting ou un BroadcastEvent intégré à un VideoObject. Toutefois, si vous souhaitez essayer et tester vous-même cette méthode, vous pouvez suivre les étapes suivantes.
Tout d’abord, pour commencer à utiliser cette API, vous devez vous rendre sur Google Cloud Console, créer un projet et un compte de service. Ensuite, vous devez activer l’API d’indexation à partir de la bibliothèque et ajouter le compte de messagerie fourni avec les informations d’identification du compte de service en tant que propriétaire dans Google Search Console. Vous devrez peut-être utiliser l’ancienne version de Google Search Console pour pouvoir ajouter cette adresse électronique en tant que propriétaire.
Une fois que vous aurez suivi les étapes précédentes, vous pourrez commencer à demander l’indexation et la désindexation avec cette API en utilisant le code suivant :
from oauth2client.service_account import ServiceAccountCredentials
import httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
credentials = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
if credentials is None or credentials.invalid:
credentials = tools.run_flow(flow, storage)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
for iteration in range (len(list_urls)):
content = '''{
'url': "'''+str(list_urls[iteration])+'''",
'type': "URL_UPDATED"
}'''
response, content = http.request(ENDPOINT, method="POST", body=content)
print(response)
print(content)
Si vous souhaitez demander la désindexation, vous devez changer le type de demande de « URL_UPDATED » en « URL_DELETED ». Le morceau de code précédent imprimera les réponses de l’API avec les heures de notification et leurs statuts. Si l’état est 200, la demande a été effectuée avec succès.
1.2.- Pour Bing
Très souvent, lorsque nous parlons de SEO, nous ne pensons qu’à Google, mais nous ne pouvons pas oublier que sur certains marchés, il existe d’autres moteurs de recherche prédominants et/ou d’autres moteurs de recherche qui ont une part de marché respectable comme Bing.
Il est important de mentionner dès le départ que Bing dispose déjà d’une fonction très pratique dans les Bing Webmaster Tools qui vous permet de demander la soumission de jusqu’à 10 000 URLs par jour dans la plupart des cas. Parfois, votre quota quotidien peut être inférieur à 10 000 URLs, mais vous avez la possibilité de demander une augmentation du quota si vous pensez avoir besoin d’un quota plus important pour répondre à vos besoins. Vous pouvez en savoir plus à ce sujet sur cette page.
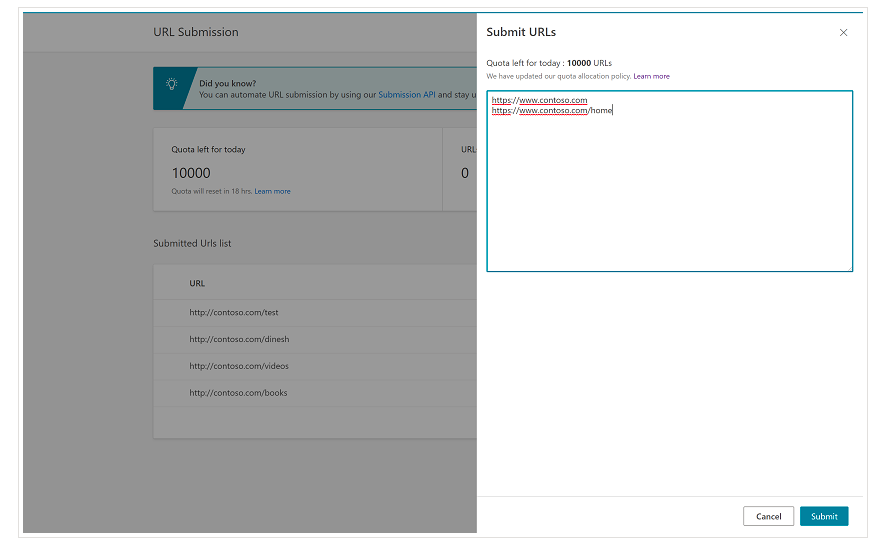
Cette fonctionnalité est en effet très pratique pour les soumissions d’URLs en masse, car il vous suffira d’introduire vos URLs sur différentes lignes dans l’outil de soumission d’URL à partir de l’interface normale des Bing Webmaster Tools.
1.2.1.- Bing Indexing API
Bing Indexing API peut être utilisé avec une clé API qui doit être introduite en tant que paramètre. Cette clé API peut être obtenue sur Bing Webmaster Tools, en allant à la section API access et ensuite, en générant la clé API.
Une fois la clé API obtenue, nous pouvons jouer avec l’API à l’aide du code suivant (il vous suffit d’ajouter votre clé API et l’URL de votre site) :
import requests
list_urls = ["https://www.example.com", "https://www.example/test2/"]
for y in list_urls :
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl" : "https://www.example.com", "urlList" :["'+ str(y) +""]}''
headers = {'Content-type' : 'application/json ; charset=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
print(str(y) + " : " + str(x))
Cette méthode permet d’imprimer l’URL et son code de réponse à chaque itération. Contrairement à l’API d’indexation de Google, cette API peut être utilisée pour tout type de site web.
[Étude de cas] Améliorer la visibilité via une crawabilité optimisée pour Googlebot

2.- Sitemaps
Comme nous le savons tous, les sitemaps sont des éléments très utiles pour fournir aux robots des moteurs de recherche les URLs que nous souhaitons qu’ils crawlent. Afin que les robots des moteurs de recherche sachent où se trouvent nos sitemaps, ils doivent être téléchargés sur Google Search Console et Bing Webmaster Tools et inclus dans le fichier robots.txt pour le reste des robots.
Avec Python, nous pouvons travailler sur trois aspects différents liés aux sitemaps : leur analyse, leur création, leur téléchargement et leur suppression dans Google Search Console.
2.1.- Importation et analyse des sitemaps avec Python
Advertools est une excellente bibliothèque créée par Elias Dabbas qui peut être utilisée pour l’importation de sitemaps ainsi que pour de nombreuses autres tâches de SEO. Vous serez en mesure d’importer des sitemaps dans des Dataframes en utilisant simplement :
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Cette bibliothèque prend en charge les sitemaps XML ordinaires, les sitemaps d’actualité et les sitemaps vidéo.
Par ailleurs, si vous souhaitez uniquement importer les URLs du plan du site, vous pouvez également utiliser les bibliothèques requests et BeautifulSoup.
import requests
de bs4 import BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.text
soup = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] for x in urls]
Une fois le sitemap importé, vous pouvez jouer avec les URLs extraites et effectuer une analyse de contenu comme l’explique Koray Tuğberk dans cet article.
2.2.- Création de sitemaps avec Python
Vous pouvez également utiliser Python pour créer des sitemaps.xml à partir d’une liste d’URLs comme l’explique JC Chouinard dans cet article. Cela peut être particulièrement utile pour les sites web très dynamiques dont les URLs changent rapidement et, avec la méthode ping expliquée ci-dessus, cela peut être une excellente solution pour fournir à Google les nouvelles URLs et les faire crawler et indexer rapidement.
Récemment, Greg Bernhardt a également créé une APP avec Streamlit et Python pour générer des sitemaps.
2.3.- Téléchargement et suppression de sitemaps à partir de Google Search Console
Google Search Console dispose d’une API qui peut être utilisée principalement de deux manières différentes : pour extraire des données sur les performances du web et pour gérer les sitemaps. Dans ce billet, nous allons nous concentrer sur l’option de téléchargement et de suppression des sitemaps.
Tout d’abord, il est important de créer ou d’utiliser un projet existant de Google Cloud Console pour obtenir un identifiant OUATH et activer le service Google Search Console. JC Chouinard explique très bien les étapes à suivre pour accéder à l’API Google Search Console avec Python et comment effectuer votre première requête dans cet article. En fait, nous pouvons tout à fait utiliser son code, mais seulement en introduisant un changement : dans les scopes, nous ajouterons « https://www.googleapis.com/auth/webmasters » au lieu de « https://www.googleapis.com/auth/webmasters.readonly », car nous utiliserons l’API non seulement pour lire, mais aussi pour télécharger et supprimer des sitemaps.
Une fois que nous nous sommes connectés à l’API, nous pouvons commencer à jouer avec elle et lister tous les sitemaps de nos propriétés Google Search Console avec le morceau de code suivant :
for site_url in verified_sites_urls :
print (site_url)
# Récupérer la liste des sitemaps soumis
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
if 'sitemap' in sitemaps :
sitemap_urls = [s['path'] for s in sitemaps['sitemap']]
print (" " + "\n ".join(sitemap_urls))
Lorsqu’il s’agit de sitemaps spécifiques, nous pouvons effectuer trois tâches que nous détaillerons dans les sections suivantes : télécharger, supprimer et demander des informations.
2.3.1.- Téléchargement d’un sitemap
Pour télécharger un sitemap avec Python, il suffit de spécifier l’URL du site et le chemin du sitemap et d’exécuter ce bout de code :
WEBSITE = 'yourGSCproperty' (votre propriété CGS) SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2.- Suppression d’un sitemap
Le revers de la médaille est le cas où l’on souhaite supprimer un sitemap. Nous pouvons également supprimer les sitemaps de Google Search Console avec Python en utilisant la méthode « delete » au lieu de « submit ».
WEBSITE = 'yourGSCproperty' (votre propriété GSC) SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3.- Demander des informations à partir des sitemaps
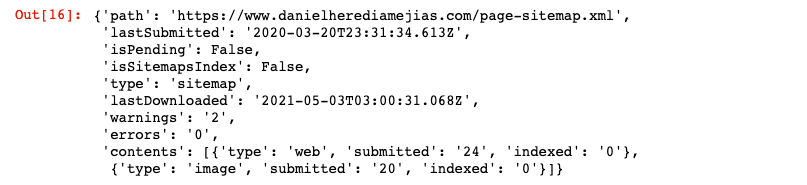
Enfin, nous pouvons également demander des informations à partir du sitemap en utilisant la méthode « get ».
WEBSITE = 'yourGSCproperty' (votre propriété CGS) SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
Ceci renverra une réponse au format JSON comme :
3.- Les liens internes
Une bonne structure de liens internes est très utile pour faciliter le crawl de votre site par les robots des moteurs de recherche. Voici quelques-uns des principaux problèmes que j’ai rencontrés en auditant un certain nombre de sites Web dotés de configurations techniques très sophistiquées :
- Liens introduits avec des événements on-click : en bref, Googlebot ne clique pas sur les boutons, donc si vos liens sont insérés avec un événement on-click, Googlebot ne sera pas en mesure de les suivre.
- Liens rendus côté client : bien que Googlebot et d’autres moteurs de recherche soient de plus en plus performants dans l’exécution de JavaScript, cela reste un défi pour eux. Il est donc préférable de rendre ces liens côté serveur et de les servir dans le HTML brut aux robots des moteurs de recherche plutôt que d’attendre d’eux qu’ils exécutent des scripts JavaScript.
- Pop-ups de connexion et/ou de barrière d’âge : les pop-ups de connexion et les barrières d’âge peuvent empêcher les robots des moteurs de recherche de crawler le contenu qui se trouve derrière ces « obstacles ».
- Utilisation excessive d’attributs nofollow : l’utilisation de nombreux attributs nofollow pointant vers des pages internes précieuses empêchera les robots des moteurs de recherche de les crawler.
- Noindex et follow : techniquement, la combinaison des directives noindex et follow devrait permettre aux robots des moteurs de recherche de crawler les liens qui se trouvent sur cette page. Cependant, il semble que Googlebot cesse de crawler les pages contenant des directives noindex après un certain temps.
Avec Python, nous pouvons analyser notre structure de liens internes et trouver de nouvelles opportunités de liens internes en mode groupé.
3.1.- Analyse des liens internes avec Python
Il y a quelques mois, j’ai écrit un article sur la manière d’utiliser Python et la bibliothèque Networkx pour créer des graphiques permettant d’afficher la structure de liens internes de manière très visuelle :
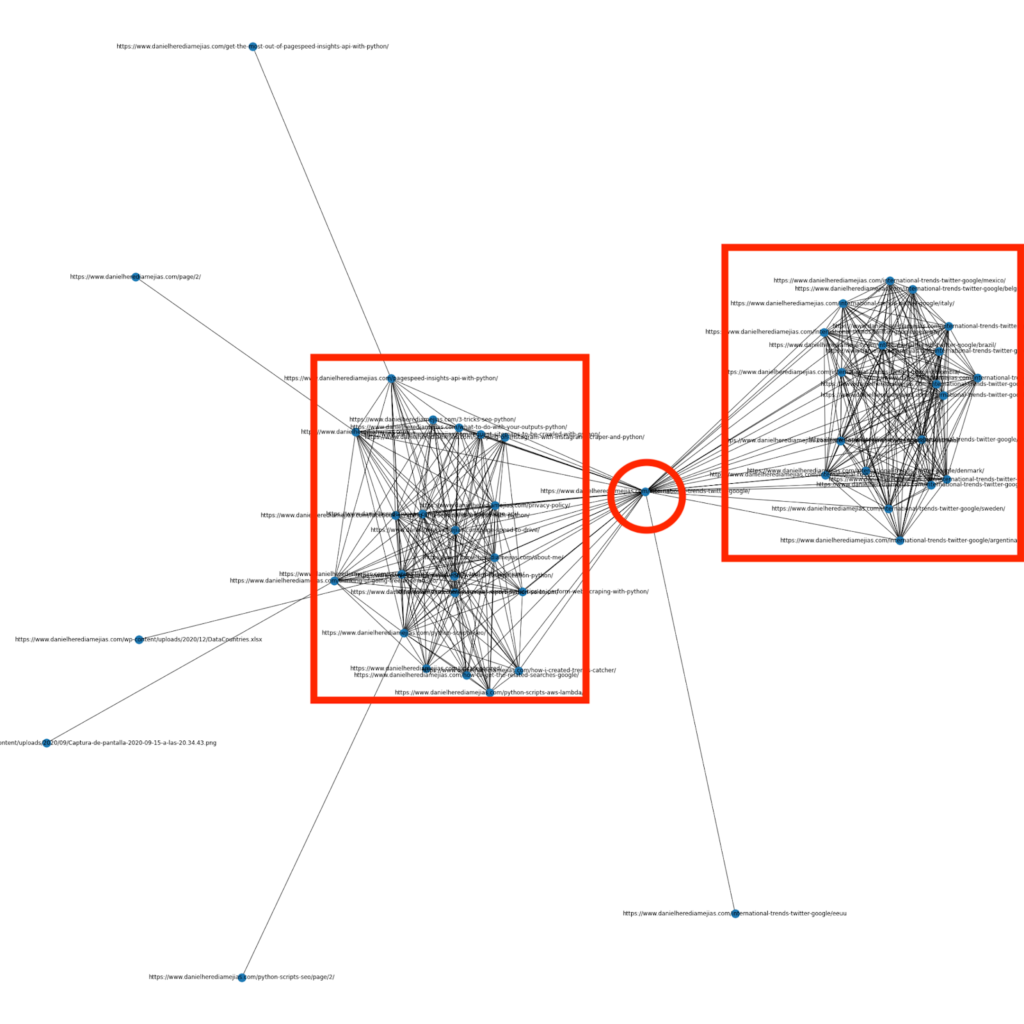
C’est quelque chose de très similaire à ce que vous pouvez obtenir de Screaming Frog, mais l’avantage d’utiliser Python pour ce type d’analyses est que vous pouvez choisir les données que vous souhaitez inclure dans ces graphiques et contrôler la plupart des éléments du graphique tels que les couleurs, la taille des nœuds ou même les pages que vous souhaitez ajouter.
3.2.- Trouver de nouvelles opportunités de liens internes avec Python
Outre l’analyse des structures de sites, vous pouvez également utiliser Python pour trouver de nouvelles opportunités de liens internes en fournissant un certain nombre de mots-clés et d’URL et en itérant sur ces URLs à la recherche des termes fournis dans leur contenu.
Cette méthode peut très bien fonctionner avec les exportations de Semrush ou Ahrefs afin de trouver des liens internes contextuels puissants à partir de certaines pages qui sont déjà classées pour des mots-clés et qui ont donc déjà une certaine autorité.
Vous pouvez en savoir plus sur cette méthode ici.
4.- Vitesse du site web, pages d’erreur 5xx et soft
Comme indiqué par Google sur cette page sur ce que le budget de crawl signifie pour Google, rendre votre site plus rapide améliore l’expérience utilisateur et augmente le taux de crawl. D’autre part, d’autres facteurs peuvent affecter le budget de crawl, tels que les pages d’erreurs, le contenu de faible qualité et le contenu dupliqué sur le site.
4.1.- Vitesse de la page et Python
4.2.1- Analyser la vitesse de votre site web avec Python
L’API Page Speed Insights est très utile pour analyser les performances de votre site Web en termes de vitesse des pages et pour obtenir de nombreuses données sur de nombreux paramètres de vitesse des pages (près de 50), ainsi que les Core Web Vitals.
Travailler avec Page Speed Insights avec Python est très simple, il suffit d’une clé API et de requêtes pour l’utiliser. Par exemple :
import urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Notez que vous pouvez insérer votre URL avec le paramètre URL et vous pouvez également modifier le paramètre device si vous souhaitez obtenir les données pour le desktop. response = urllib.request.urlopen(url) data = json.loads(response.read())
En outre, vous pouvez également prévoir, à l’aide de Python et du calculateur Lighthouse Scoring, dans quelle mesure votre score de performance global s’améliorera si vous apportez les modifications demandées pour améliorer la vitesse de vos pages, comme expliqué dans cet article.
4.2.2- Optimisation et redimensionnement des images avec Python
En lien avec la vitesse du site web, Python peut également être utilisé pour optimiser, compresser et redimensionner les images comme l’expliquent ces articles écrits par Koray Tuğberk et Greg Bernhardt :
- Automatiser la compression d’images avec Python par FTP.
- Redimensionner des images en masse avec Python.
- Optimiser les images via Python pour le SEO et l’UX.
4.2.- Extraction des erreurs de code de réponse 5xx et autres avec Python
Les erreurs de code de réponse 5xx peuvent indiquer que votre serveur n’est pas assez rapide pour faire face à toutes les demandes qu’il reçoit. Cela peut avoir un impact très négatif sur votre taux de crawl et peut également nuire à l’expérience de l’utilisateur.
Afin de vous assurer que votre site Web fonctionne comme prévu, vous pouvez automatiser le téléchargement du rapport de statistiques de crawl avec Python et Selenium et vous pouvez surveiller de près vos fichiers de logs.
4.3.- Extraction de pages d’erreur soft avec Python
Récemment, Jose Luis Hernando a publié un article en l’honneur de Hamlet Batista sur la façon dont vous pouvez automatiser l’extraction des rapports de couverture avec Node.js. Cela peut être une solution étonnante pour extraire les pages d’erreur soft et même les erreurs de réponse 5xx qui pourraient avoir un impact négatif sur votre taux de crawl.
Nous pouvons également reproduire ce même processus avec Python afin de compiler dans un seul onglet Excel toutes les URLs qui sont fournies par Google Search Console comme erronées, valides avec avertissements, valides et exclues.
Tout d’abord, nous devons nous connecter à Google Search Console comme expliqué précédemment dans cet article avec Python avec Selenium. Après cela, nous sélectionnerons toutes les cases d’état des URLs, nous ajouterons jusqu’à 100 lignes par page et nous commencerons à itérer sur tous les types d’URL signalés par la GSC et télécharger chaque fichier Excel.
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent.com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@id="identifierId"]')
searchBox.send_keys("")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@id="password"]/div[1]/div/div[1]/input')
searchBox.send_keys("")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
yourdomain = str(input("Insert here your http property or domain. If it is a domain include: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_id=' + yourdomain)
elem3 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[4]/div[1]/span/span/div/div[1]/span[2]")
elem3.click()
elem6 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[3]/div[1]/span/span/div/div[1]/span[2]")
elem6.click()
elem7 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[2]/div[1]/span/span/div/div[1]/span[2]")
elem7.click()
elem4 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[1]/div[1]/div[2]/span")
elem4.click()
time.sleep(2)
elem5 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[2]/div[5]/span")
elem5.click()
time.sleep(5)
problems = driver.find_elements_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[1]/div[2]/table/tbody/*/td[2]/span/span")
list_problems = []
for x in problems:
list_problems.append(x.text)
counter = 1
for x in list_problems:
print("Extracting the report for " + x)
elem2 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[1]/div[2]/table/tbody/tr[" + str(counter) + "]/td[2]/span/span")
elem2.click()
time.sleep(5)
downloading1 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz[2]/c-wiz/div/div[1]/div[1]/div[2]/div")
downloading1.click()
time.sleep(2)
downloading2 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz[2]/div/div/div/span[2]")
downloading2.click()
time.sleep(5)
if counter != len(list_problems):
driver.get('https://search.google.com/search-console/index?resource_id=' + yourdomain)
time.sleep(3)
elem3 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[4]/div[1]/span/span/div/div[1]/span[2]")
elem3.click()
elem6 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[3]/div[1]/span/span/div/div[1]/span[2]")
elem6.click()
elem7 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[2]/div[1]/span/span/div/div[1]/span[2]")
elem7.click()
elem4 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[1]/div[1]/div[2]/span")
elem4.click()
time.sleep(2)
elem5 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[2]/div[5]/span")
elem5.click()
time.sleep(2)
counter = counter + 1
else:
driver.close()
Vous pouvez regarder cette vidéo explicative:
Une fois que nous avons téléchargé tous les fichiers Excel, nous pouvons les assembler avec Pandas :
import pandas as pd
from datetime import datetime
today = str(datetime.date(datetime.now()))
for x in range(len(list_problems)):
print(x)
if x == 0:
df1 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + today + ".xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Type'] = listvalues
list_results = df1.values.tolist()
else:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + today + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Type'] = listvalues
list_results = list_results + df2.values.tolist()
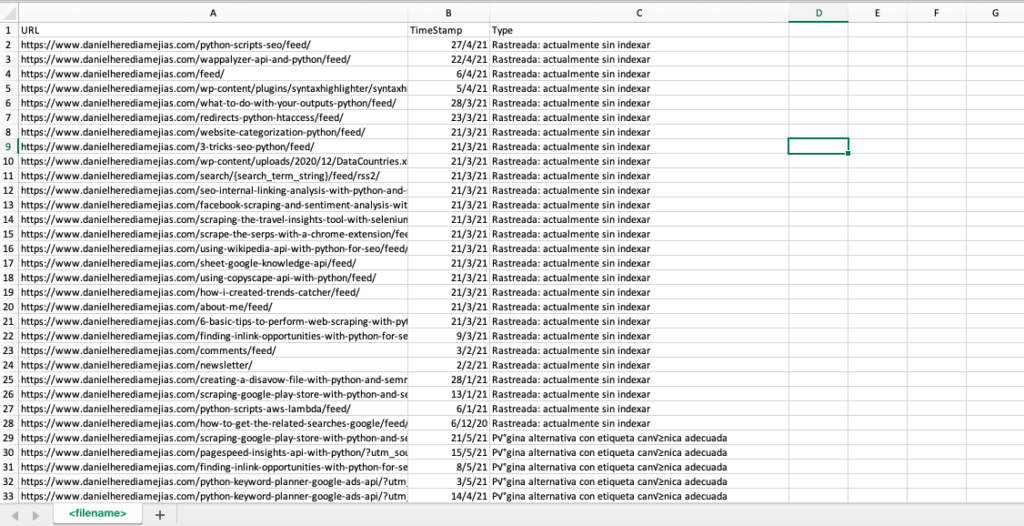
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('.csv', header=True, index=False, encoding = "utf-8")
Le résultat final ressemble à ceci :
4.4.- Analyse des fichiers de logs avec Python
En plus des données disponibles dans le rapport de statistiques de crawl de Google Search Console, vous pouvez également analyser vos propres fichiers en utilisant Python pour obtenir beaucoup plus d’informations sur la façon dont les robots des moteurs de recherche explorent votre site Web. Si vous n’utilisez pas encore un analyseur de logs pour le SEO, vous pouvez lire cet article de SEO Garden qui explique l’analyse des logs avec Python.
[Ebook] Analyse de logs : 4 cas d’usage
5.- Conclusions
Nous avons vu que Python peut être un atout important pour analyser et améliorer le crawling et l’indexation de nos sites Web de différentes manières. Nous avons également vu comment rendre la vie beaucoup plus facile en automatisant la plupart des tâches fastidieuses et manuelles qui nécessiteraient des milliers d’heures de votre temps.
Je dois dire que je ne suis malheureusement pas totalement convaincu par les solutions proposées actuellement par Google pour demander l’indexation d’un grand nombre d’URLs, même si je peux comprendre dans une certaine mesure sa crainte de proposer une meilleure solution : de nombreux référenceurs pourraient avoir tendance à en abuser.
À l’opposé, il y a Bing, qui offre des solutions exceptionnelles et pratiques pour demander des indexations d’URLs via l’API et même via l’interface normale des Bing Webmaster Tools.
Étant donné que l’API d’indexation de Google peut encore être améliorée, d’autres éléments tels que la mise en place d’un plan de site accessible et mis à jour, vos liens internes, la vitesse de vos pages, vos pages d’erreurs mineures et votre contenu dupliqué et de faible qualité deviennent encore plus importants pour garantir que votre site Web est correctement exploré et que vos pages les plus importantes sont indexées.
