
Optimiser son budget de crawl et empêcher les robots d’indexer certaines pages sont des concepts familiers pour de nombreux SEOs. Mais le diable est dans les détails ! Surtout que les bonnes pratiques ont significativement changé au cours des dernières années.
Un petit changement dans un fichier robots.txt ou sur des balises de robots peut avoir un impact dramatique sur votre site web. Pour s’assurer que cet impact sera toujours positif, nous allons aujourd’hui nous intéresser à ces différents facteurs :
Optimiser le budget de crawl
Qu’est-ce qu’un fichier robots.txt ?
Qu’est-ce que les balises meta robots ?
Qu’est-ce que les balises X-robots ?
Directives des robots & SEO
Checklist des meilleures pratiques pour les robots
Optimiser le budget de crawl
Le robot d’un moteur de recherche dispose d’une “allocation” pour un certain nombre de pages qu’il peut et veut crawler sur votre site. Cela s’appelle le “budget de crawl”.
[Ebook] Crawlability

Vous pouvez trouver votre budget de crawl dans le rapport “Crawl Stats” de la Google Search Console (GSC). Cependant, la Google Search Console est un agrégat de 12 robots qui ne sont pas tous dédiés au SEO. L’outil compte aussi les robots AdWords ou AdSense qui sont des robots SEA. Donc, la GSC vous donne une idée de votre budget de crawl global mais pas sa répartition exacte.
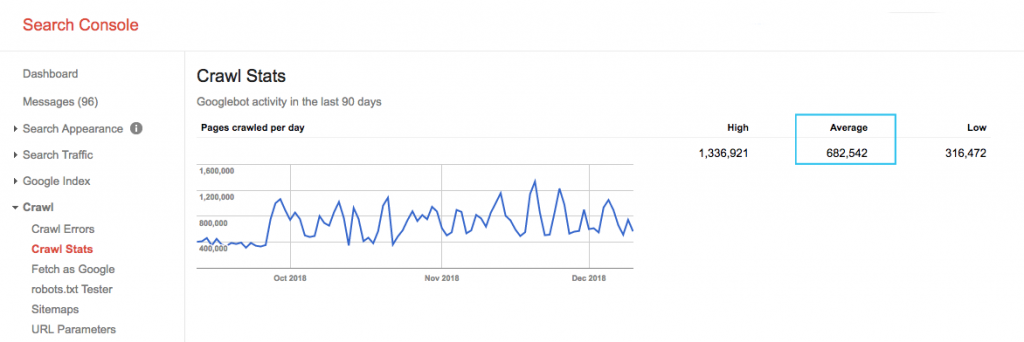
Pour rendre les chiffres plus actionnables, divisez le nombre moyen de pages crawlées par jour par le total des pages crawlables de votre site. Vous pouvez demander ce chiffre à vos développeurs ou lancer un crawl de votre site. Cela vous donnera le ratio de crawl attendu pour commencer vos optimisations.
Vous souhaitez aller plus loin ? Obtenez la répartition précise de l’activité du Googlebot, les pages exactes visitées ainsi que les statistiques des autres crawlers en analysant vos fichiers de log.
Il existe de nombreuses techniques pour optimiser votre budget de crawl, mais il est plus simple de commencer par vérifier le rapport “Coverage” dans la GSC pour comprendre le comportement de crawl et d’indexation de Google.
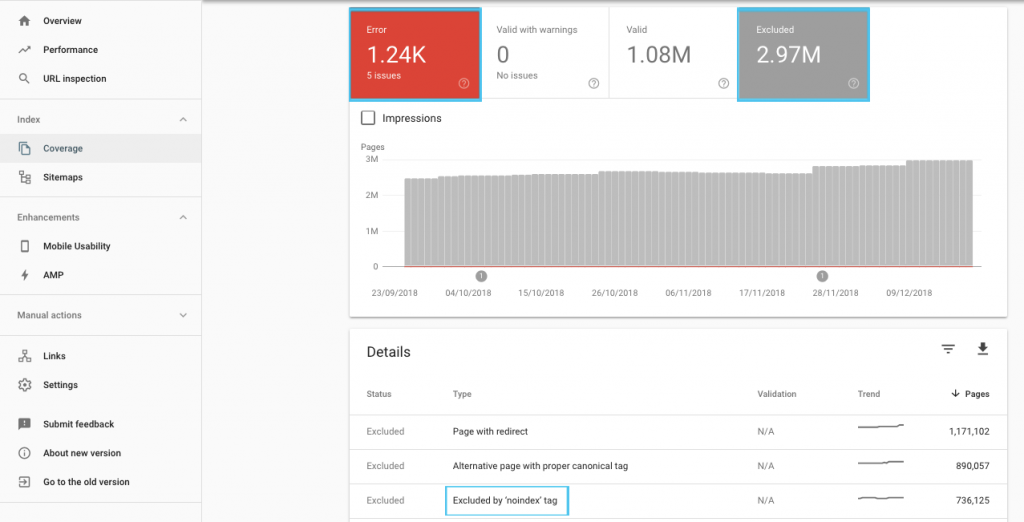
Si vous voyez des erreurs comme “l’URL soumise est marquée en ‘noindex’” ou “l’URL soumise est bloquée par le robots.txt”, sollicitez vos développeurs pour les corriger. Pour toutes les exclusions de robots, menez votre enquête pour vérifier qu’elles sont bien stratégiques d’un point de vu SEO.
En général, les spécialistes SEO cherchent à minimiser les restrictions de crawl dans les robots. La meilleure stratégie reste d’améliorer votre architecture de site pour rendre les URLs utiles et accessibles aux moteurs de recherche.
Crawler SEO Oncrawl

Google a souligné qu’une “architecture d’information solide est probablement un usage bien plus productif des ressources que la priorisation du crawl”.
Ceci étant dit, il est bénéfique de comprendre ce qui peut être fait avec les fichiers robots.txt et les balises robots pour guider le crawl, l’indexation et la circulation de l’équité de lien. Et plus important encore, quand et comment mieux les utiliser pour le SEO moderne.
Qu’est-ce qu’un fichier Robots.txt ?
Avant de crawler une page, le robot d’un moteur de recherche va d’abord vérifier le robots.txt. Ce fichier montre aux robots quels chemins d’URLs ils ont l’autorisation de visiter. Mais ces données sont seulement directives, pas obligatoires.
Les robots.txt ne peuvent pas empêcher le crawl de manière fiable, comme un pare-feu ou une protection par mot de passe. C’est juste l’équivalent digital d’une pancarte “n’entrez pas s’il vous plaît” posée sur une porte non verrouillée.
Les crawlers polis, comme la plupart des moteurs de recherche, vont généralement obéir à ces instructions. Les crawlers hostiles, comme des scrapers d’email, des spambots, virus et robots qui scannent les vulnérabilités des sites n’y prêtent souvent pas attention.
De plus c’est un fichier publiquement disponible. Tout le monde peut voir vos directives.
N’utilisez pas votre fichier robots.txt pour :
- Cacher des informations sensibles. Utilisez une protection par mot de passe.
- Bloquer l’accès à votre version dev et/ou en pré-prod . Utilisez l’authentification côté serveur.
- Bloquer explicitement les crawlers hostiles. Utilisez des IP ou des user-agents bloquants (empêchez l’accès à un crawler spécifique avec une règle dans votre fichier .htaccess ou un outil comme CloudFlare).
Chaque site web devrait avoir un fichier robots.txt valide avec au moins un groupe de directives. Sans cela, tous les robots auraient accès libre par défaut, donc chaque page serait crawlable. Même si c’est ce que vous souhaitez, il est préférable de clarifier cela pour tous les acteurs avec un fichier robots.txt. De plus, sans fichier robots.txt, vos logs seraient criblés de fausses requêtes.
Structure d’un fichier robots.txt
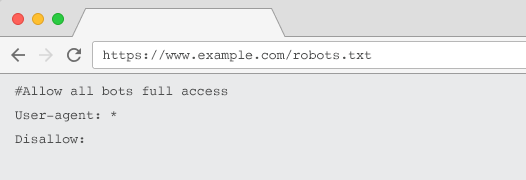
Pour être connu des crawlers, votre robots.txt doit :
- Être un fichier texte nommé “robots.txt”. Le nom de fichier est sensible. “Robots.TXT” ou d’autres variantes ne fonctionneront pas.
- Être localisé sur le répertoire principal de votre domaine canonique et, si cela est pertinent, des sous-domaines. Par exemple, pour crawler toutes les URLs sous https://www.exemple.com, le fichier robots.txt doit être localisé à https://www.exemple.com/robots.txt et pour sousdomaine.exemple.com à sousdomaine.exemple.com/robots.txt.
- Retourner un status HTTP 200 correct.
- Utiliser une syntaxe robots.txt – Utiliser l’outil de test robots.txt de la Google Search Console.
Un fichier robots.txt est composé de groupes de directives. Ceux-ci comportent généralement :
- Les user-agents : les adresses des différents crawlers. Vous pouvez avoir un groupe pour tous les robots ou utiliser des groupes pour nommer des moteurs de recherche spécifiques.
- Des disallow : des fichiers ou répertoires spécifiques à exclure du crawl des user agents ci-dessus. Vous pouvez avoir une ou plusieurs de ces lignes par bloc.
Pour consulter la liste complète des user-agents et plus d’exemples d’instructions, vous pouvez lire le guide sur les robots.txt de Yoast.
En plus des instructions “User-agent” et “Disallow”, il existe des directives non-standards :
- Allow : des exceptions spécifiques à une directive disallow pour un répertoire relatif.
- Crawl-delay : accélérer des crawlers lourds en disant aux robots combien de secondes attendre avant de visiter une page. Si vous avez quelques sessions organiques, le crawl-delay peut économiser la bande passante du serveur. Mais je conseille de mettre cela en place seulement si les crawlers causent activement des problèmes de chargement de serveurs. Google ne reconnaît pas cette demande mais offre la possibilité de limiter le taux de crawl dans la Google Search Console.
- Clean-param : empêcher le re-crawl du contenu dupliqué généré par des paramètres dynamiques.
- No-index : pensé pour contrôler l’indexation sans utiliser du budget de crawl. Ce n’est plus officiellement pris en charge par Google. Bien qu’il est évident que le no-index pourrait avoir un impact, ce n’est pas fiable ou recommandé par des experts comme John Mueller.
@maxxeight @google @DeepCrawl I’d really avoid using the noindex there.
— ???? John ???? (@JohnMu) 1 septembre 2015
- Sitemap : la meilleure manière pour soumettre votre sitemap XML est via la Google Search Console et les autres outils Webmaster des moteurs de recherche. Cependant, ajouter une directive de sitemap à la base de votre fichier robots.txt aide les autres crawlers qui n’offrent pas forcément d’option de soumission.


Limitations d’un robots.txt pour le SEO
Les robots.txt peuvent empêcher le crawl de tous les robots. De même, interdire aux crawlers l’accès à une page ne l’empêchera pas d’être indexée dans les pages de résultats des moteurs de recherches (SERPs).
Si une page bloquée dispose de facteurs forts de classement, Google pourrait juger pertinent de la montrer dans les SERPs. Même sans avoir crawlé la page.
Comme Google ne connaît pas le contenu de cette URL, le résultat de recherche pourrait ressembler à ça :

Pour empêcher définitivement une page d’être indexée, vous devez utiliser un robot meta tag “noindex” ou un header X-Robots-Tag HTTP.
Dans ce cas, ne bloquez pas l’accès à la page dans le robots.txt, car la page doit être crawlée afin que la balise “noindex” soit détectée et respectée. Si l’URL est bloquée, toutes les balises robots sont inutiles.
De plus, si une page a accumulé beaucoup de liens entrants, mais que Google ne peut pas crawler ces pages à cause du robots.txt, l’équité de lien sera perdue même si Google connaît les liens.
Qu’est-ce que les balises meta robots ?
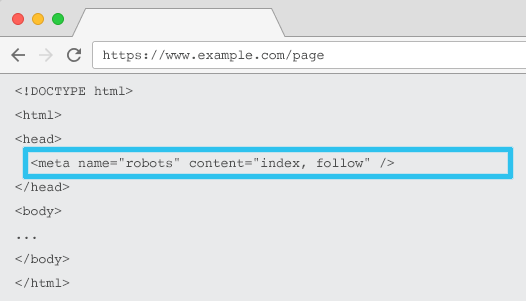
Placée dans le HTML de chaque URL, la meta name=”robots” dit aux crawlers si et comment ils doivent indexer le contenu et s’il doivent suivre (= crawler) tous les liens de la page et donc transmettre l’équité de lien.
Lorsque vous utilisez la meta générale name=”robots”, la directive s’applique à tous les crawlers. Vous pouvez aussi utiliser un user agent spécifique. Par exemple, la meta name=”googlebot”. Mais il est rare d’avoir besoin d’utiliser plusieurs balises meta robots pour configurer des instructions pour des robots spécifiques.
Il y a deux importantes considérations lorsque vous utilisez des balises meta robots :
- Similaires aux robots.txt, les balises meta sont directives mais pas obligatoires donc peuvent être ignorées par certains robots.
- Les directives des robots nofollow s’appliquent seulement aux liens sur cette page. Il est possible qu’un crawler suive le lien d’une autre page ou d’un site sans un nofollow. Donc le robot peut toujours réussir à trouver et indexer votre page non désirée.
Voici la liste de toutes les directives des balises meta robots :
- index : dit aux moteurs de recherche de montrer cette page dans les résultats de recherche. Il s’agit de l’état par défaut si aucune directive n’a été spécifiée.
- noindex : dit aux moteurs de recherche de ne pas montrer cette page dans les résultats de recherche.
- follow : dit aux moteurs de recherche de suivre tous les liens sur cette page et de passer l’équité, même si la page n’est pas indexée. Il s’agit de l’état par défaut si aucune directive n’a été spécifiée.
- nofollow : dit aux moteurs de recherche de ne suivre aucun lien sur cette page et de ne pas passer l’équité.
- all : équivalent de “index, follow”.
- none : équivalent de “noindex, nofollow”.
- noimageindex : dit aux moteurs de recherche de n’indexer aucune image sur cette page.
- noarchive : dit aux moteurs de recherche de ne pas montrer les liens cachés de cette page dans les résultats de recherche.
- nocache : équivalent de noarchive mais seulement utilisé par Internet Explorer et Firefox.
- nosnippet : dit aux moteurs de recherche de ne pas montrer la meta description ou l’aperçu d’une vidéo de cette page dans les pages de résultats.
- notranslate : dit aux moteurs de recherche de ne pas proposer de traduction de cette page dans les résultats de recherche.
- unavailable_after : dit aux moteurs de recherche de ne plus indexer cette page après une date spécifique.
- noodp : maintenant obsolète, cela permettait auparavant d’empêcher les moteurs de recherche d’utiliser la description de la page de DMOZ dans les SERPs.
- noydir : maintenant obsolète, cela permettait d’empêcher Yahoo d’utiliser la description de la page dans le répertoire Yahoo dans les résultats de recherche.
- noyaca : empêche Yandex d’utiliser la description de la page dans le répertoire Yandex dans les résultats de recherche.
Comme indiqué dans la documentation de Yoast, les moteurs de recherche ne prennent pas pas tous toutes les balises meta robots en charge. Certains ne sont même pas clairs sur ce qu’ils intègrent ou non.

* La plupart des moteurs de recherche n’ont pas de documentation spécifique, mais nous supposons que s’ils prennent en charge les paramètres excluant (ex : nofollow), ils le font également pour leur équivalent positif (ex : follow).
** Même si les les attributs noodp et nodyir sont toujours valides, les répertoires n’existent plus, donc il est très probable que ces valeurs n’aient aucun impact.
Communément, les balises robots seront configurées en “index, follow”. Certains SEOs pensent qu’il est redondant d’ajouter cette balise dans le HTML car elles sont déjà paramétrées par défaut. Le contre argument soutient qu’une spécification claire des directives peut aider à empêcher une confusion humaine.
Note : les URLs avec une balise “noindex” seront crawlées moins fréquemment et, si elles sont présentes depuis un long moment, vont éventuellement conduire Google à classer les liens de la page en nofollow.
Il est rare de trouver un cas d’usage où tous les liens d’une page sont placés en “nofollow” avec une balise meta robots. Il est plus commun de voir un “nofollow” ajouté sur les liens individuels en utilisant un attribut de lien rel=”nofollow”. Par exemple, vous devriez penser à ajouter un attribut rel=”nofollow” aux commentaires générés par les utilisateurs ou aux liens payants.
Il est encore plus rare d’avoir un cas SEO où les directives des balises robots n’adressent pas d’indexation basique de comportement de suivi, comme le cache, l’indexation des images, la gestion des snippets…
Le défi avec les balises meta robots est qu’elles ne peuvent pas être utilisées pour des fichiers non-HTML comme les images, vidéos ou documents PDF. C’est là que vous pouvez passer aux X-Robots-Tags.
Qu’est-ce que les balises X-Robots ?
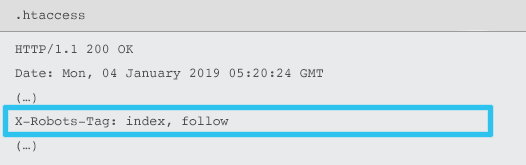
Les X-Robots-Tag sont envoyés par le serveur comme un élément de header de réponse HTTP pour une URL donnée utilisant des fichiers .htaccess et httpd.conf.
N’importe quelle directive de balise meta peut aussi être spécifiée comme un X-Robots-Tag. Cependant, un X-Robots-Tag offre une flexibilité additionnelle et des fonctionnalités avancées.
Vous devriez utiliser un X-Robots-Tag plutôt que des balises meta robots si vous voulez :
- Contrôler le comportement des robots pour des fichiers non-HTML, plutôt que les fichiers HTML seuls.
- Contrôler l’indexation d’un élément spécifique d’une page, plutôt que la page dans son intégralité.
- Ajouter des règles pour qu’une page soit indexée ou non. Par exemple, si un auteur a plus de 5 articles publiés, indexer sa page auteur.
- Appliquer des directives index & follow à une grande partie du site plutôt qu’à des pages spécifiques.
- Utiliser des expressions régulières.
Évitez d’utiliser des meta robots et des x-robots-tag sur la même page, cela pourrait être redondant.
Pour voir les X-Robots-Tags, vous pouvez utiliser la fonctionnalité “Fetch as Google” de la Google Search Console.
Directives de robots & SEO

Vous connaissez désormais les différences entre ces trois directives de robots.
robots.txt se concentre sur l’économie du budget de crawl mais n’empêchera pas une page d’être montrée dans les résultats de recherche. Il agit comme le premier gardien de votre site web et demande aux robots de ne pas accéder aux pages sans permission.
Tous les types de balises robots cherchent à contrôler l’indexation et le passage d’équité de lien. Les balises meta robots sont efficaces seulement après que la page ait été chargée, bien que les headers X-Robots-Tag offrent un contrôle plus granulaire. Ils sont efficaces après que le serveur ait répondu à une requête de page.
Grâce à ces outils, les SEOs peuvent faire évoluer la manière dont ils utilisent les directives de robots pour relever les challenges de crawl et d’indexation.
Bloquer les robots pour économiser la bande passante du serveur
Problème : en analysant vos fichiers de log, vous verrez que de nombreux user-agents utilisent de la bande passante sans apporter de réelle valeur :
- Les crawlers SEO, comme le MJ12bot (de Majestic) ou le Ahrefsbot (de Ahrefs).
- Les outils qui sauvegardent le contenu digital hors ligne, comme Webcopier ou Teleport.
- Les moteurs de recherche qui ne sont pas pertinents pour votre marché, comme Baiduspider ou Yandex.
Solution peu optimale : bloquer ces robots avec un robots.txt car il n’est pas garantit que celui-ci soit respecté. De plus, il s’agit d’une déclaration publique donc cela pourrait donner des insights compétitifs à des acteurs tierces intéressés.
Meilleure approche : utilisez la directive la plus subtile pour bloquer le user-agent. Cela peut être accompli de différentes manières mais est généralement fait en éditant votre fichier .htaccess pour rediriger toutes les requêtes de robots non requises vers une 403 : Forbidden page.
Les pages de recherche interne utilisent du budget de crawl
Problème : sur de nombreux sites, les pages de résultats de recherche interne sont générées de manière dynamique depuis des URLs statiques, qui consomment du budget de crawl et peuvent générer du contenu faible ou dupliqué si elles sont indexées.
Solution peu optimale : interdire les répertoires avec le robots.txt. Bien que cela évite les pièges à crawler, votre capacité à vous classer pour des recherches de clients clés et à transmettre l’équité de lien sera limitée.
Meilleure approche : cartographiez de manière pertinente, visez de grands volumes de recherche pour des URLs existantes et adaptées aux moteurs de recherche. Par exemple, pour la recherche “samsung phone”, plutôt que de créer une page /search/samsung-phone, redirigez vers la page /phones/samsung.
Si ce n’est pas possible, créez un paramètre basé sur l’URL. Vous pouvez alors facilement spécifier si vous souhaitez que le paramètre soit crawlé ou non dans la Google Search Console.
Si vous n’autorisez pas le crawl, analysez si de telles pages ont une qualité suffisante pour être classées. Si ce n’est pas le cas, ajoutez une directive “noindex, follow” en guise de solution à court terme, le temps d’améliorer la qualité du résultat pour répondre aux exigences du SEO et des utilisateurs.
Bloquer les paramètres avec des robots
Problème : les requêtes attachées à des paramètres, comme celles générées par la navigation à facette ou le tracking. Celles-ci sont connues pour consommer du budget de crawl, créer des URLs de contenu dupliqué et séparer les facteurs de classement.
Solution peu optimale : empêcher le crawl des paramètres avec le robots.txt ou avec une balise meta robots “noindex”. Les deux vont empêcher le flux d’équité de lien (le premier immédiatement, le second après une période plus longue).
Meilleure approche : assurez-vous que chaque paramètre a une raison claire d’exister et implémentez les règles de commande, qui utilisent les clefs qu’une seule fois et empêchent les valeurs vides. Ajoutez un attribut de lien rel=canonical aux pages de paramètres adaptées pour combiner les capacités de classement. Puis, configurez tous les paramètres dans la Google Search Console, où il y a plus d’options granulaires pour communiquer vos préférences de crawl. Pour plus de détails, consultez le guide de traitement des paramètres de Search Engine Journal.
Bloquer les domaines administratifs ou comptables
Problème : empêcher les moteurs de recherche de crawler et d’indexer du contenu privé.
Solution peu optimale : utiliser un robots.txt pour bloquer le répertoire car il n’est pas garanti que ces pages soit gardées privées en dehors des SERPs.
Meilleure approche : utilisez une protection par mot de passe pour empêcher les crawlers d’accéder aux pages et une directive “noindex” dans le header HTTP.
Bloquer les landing pages marketing et les pages de remerciement
Problème : vous avez souvent besoin d’exclure les URLs qui ne sont pas destinées aux recherches organiques, comme les email dédiés ou les campagnes au coût par clic comprenant des landing pages. De même, vous ne voulez pas que les utilisateurs qui n’ont pas converti visitent vos pages de remerciement via les SERPs.
Solution peu optimale : bloquer les fichiers avec des robots.txt car cela n’empêchera pas les liens d’apparaître dans les résultats de recherche.
Meilleure approche : utilisez une balise meta “noindex”.
Gérer le contenu dupliqué on-site
Problème : certains sites ont besoin d’une copie du contenu spécifique pour l’expérience utilisateur, comme par exemple une version imprimable de la page. Cependant, ils veulent aussi s’assurer que la page canonique, et non pas la page dupliquée, soit reconnue par les moteurs de recherche. Sur d’autres sites, le contenu dupliqué est dû à de faibles pratiques de développement, comme vendre le même item sur de multiples catégories d’URLs.
Solution peu optimale : bloquer les URLs avec un robots.txt empêchera la page dupliquée de transmettre un signal de classement. Le noindex destiné aux robots va éventuellement conduire Google à traiter également ces liens comme “nofollow” et empêcher les pages dupliquées de transmettre de l’équité de lien.
Meilleure approche : si le contenu dupliqué n’a pas de raison d’exister, retirez la source et redirigez vers l’URL adaptée aux moteurs de recherche. S’il a une raison d’exister, ajoutez un attribut de lien rel=canonical pour consolider les signaux de classement.
L’accessibilité du contenu mince des pages relatives au compte
Problème : les pages liées au compte comme le login, l’inscription, le panier, le checkout ou les formulaires de contact sont souvent légères en termes de contenu et offrent très peu de valeur aux moteurs de recherche mais sont nécessaires pour les utilisateurs.
Solution peu optimale : bloquer les fichiers avec un robots.txt car cela n’empêchera pas le lien d’être indexé dans les résultats de recherche.
Meilleure pratique : pour la plupart des sites, ces pages sont très peu nombreuses et vous ne devriez pas constater d’impact sur les KPIs en implémentant une gestion par robot. Si vous en ressentez le besoin, il est préférable d’utiliser une directive “noindex”, à moins qu’il y ait des recherches pour de telles pages.
Les balises de page qui utilisent du budget de crawl
Problème : des balises non contrôlées consomment du budget de crawl et génèrent souvent des problèmes de contenu pauvre.
Solution peu optimale : bloquer l’accès avec des robots.txt ou ajouter une balise “noindex”. Les deux vont empêcher les balises SEO pertinentes de se classer et (immédiatement ou éventuellement) stopper la transmission d’équité de lien.
Meilleure approche : évaluez la valeur de chacune de vos balises actuelles. Si les données montrent que la page apporte de la valeur aux moteurs de recherche ou aux utilisateurs, vous pouvez installer une redirection 301. Pour les autres pages, faites en sorte d’améliorer les éléments on-page afin qu’elles deviennent utiles pour les utilisateurs et les robots.
Le crawl de JavaScript et du CSS
Problème : auparavant, les robots ne pouvaient pas crawler le JavaScript et d’autres contenus média riches. Cela a changé et il est maintenant fortement recommandé de laisser les moteurs de recherche accéder aux fichiers JS et CSS afin de rendre les pages.
Solution peu optimale : bloquer les fichiers JavaScript et CSS avec un robots.txt pour économiser du budget de crawl. Cela peut générer une indexation pauvre et impacter négativement les classements. Par exemple, empêcher les moteurs de recherche d’accéder au JavaScript qui a été utilisé pour une publicité interstitielle ou pour rediriger des utilisateurs peut apparaître comme de la dissimulation.
Meilleure pratique : vérifiez tous les problèmes de rendu avec l’outil “Fetch as Google” ou repérez quelles ressources sont bloquées avec le rapport “Blocked Ressources”, tous les deux disponibles dans la Google Search Console. Si des ressources bloquées pourraient empêcher les moteurs de recherche de rendre correctement la page, retirez l’interdiction du robots.txt.
Checklist des meilleurs pratiques pour les robots
Il est effroyablement commun pour un site web d’avoir été accidentellement retiré de Google à cause d’une erreur de contrôle d’un robot.
Cependant, la gestion des robots peut être un outil puissant dans votre arsenal SEO lorsque vous savez comment l’utiliser. Il faut juste procéder judicieusement et avec attention.
Pour vous aider, voici une checklist rapide :
- Sécuriser les informations en utilisant une protection par mot de passe.
- Bloquer les accès aux sites en développement en utilisant l’authentification côté serveur.
- Restreindre les crawlers qui consomment de la bande passante mais offrent une faible valeur ajoutée avec un user-agent bloquant.
- S’assurer que le domaine principal et tous les sous-domaines ont un fichier texte appelé “robots.txt” situé tout en haut du répertoire et qui renvoie un code 200.
- S’assurer que le fichier robots.txt comporte au moins une interdiction avec une ligne de user-agent et une ligne de disallow.
- S’assurer que le fichier robots.txt a au moins une ligne de sitemap, entrée en dernière.
- Valider le fichier robots.txt dans le testeur de robots.txt de la Google Search Console.
- S’assurer que chaque page indexable spécifie ses directives de balise robots.
- S’assurer qu’il n’y a pas de contradictions ou de directives redondantes entre les robots.txt, les balises robots meta, les X-Robots-Tags, les fichiers .htaccess et les paramètres de la GSC.
- Réparer toutes les erreurs “Submitted URL marked ‘noindex’” ou “Submitted URL blocked by robots.txt” dans le rapport de la Google Search Console.
- Comprendre pourquoi les robots sont exclus du rapport coverage dans la GSC.
- S’assurer que seulement les pages pertinentes sont montrées dans le rapport “Blocked Ressources” de la GSC.
À vous de jouer et de vérifier la gestion de vos robots en vous assurant que vous faites les choses bien !
