Les règles JavaScript permettent de construire des applications modernes, interactives et qui se chargent sans difficulté. Dans de nombreuses situations, c’est un véritable avantage pour les utilisateurs. Cependant, d’un point de vue SEO, le JS peut être perçu comme un cauchemar car beaucoup de personnes ont rencontré quelques péripéties après l’avoir implémenté. Le JavaScript est notre nouvelle réalité. Nous ne devons pas le traiter comme un monstre mais plutôt apprendre à coexister avec lui.
Le JS apporte de la complexité et nous devons l’accepter
Le JS ajoute une complexité additionnelle à un site web standard. Dans de nombreux cas, il est plus difficile d’auditer et de débuguer des sites alimentés par JS. Même s’il existe des crawlers capables d’exécuter des données JS et fiables, il est nécessaire de se s préparer à résoudre des problèmes uniques et jamais rencontrés auparavant. Le SEO a donc gagné une nouvelle branche : le SEO JS. En réalité, le SEO JS est un SEO technique standard amélioré (chaque site web doit toujours suivre des bonnes pratiques d’optimisation on-page) qui vérifie comment Google interagit avec des sites web alimentés par JS.
Oui, le JavaScript peut vous compliquer la vie. Et puisque nous, les experts SEO, n’allons pas pouvoir arrêter la montée en flèche des cadres de développement JS, nous ferions mieux de nous y préparer.
Passer à un environnement JavaScript
Imaginez la situation suivante : le CTO et les développeurs prévoient d’implémenter d’importants changements dans la plateforme sur laquelle vous travaillez. Ils vont probablement opter pour l’un des frameworks JS, car comme le montrent les données de Stack Overflow Trends, l’intérêt pour les plus grands frameworks est en croissance continue
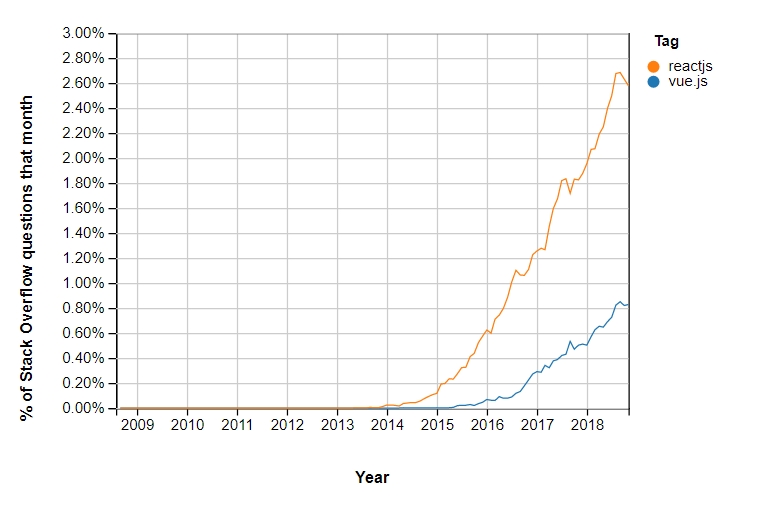
Si vous êtes confrontés à un tel scénario, n’abandonnez pas ! Prévoyez l’intégralité de la procédure d’implémentation et de maintien du cadre JS. Je pense que le JS en SEO est amené à devenir un élément naturel du SEO technique, car de plus en plus de sites web vont devenir dépendants du javascript.
Cet article a pour objectif de vous aider à assurer le changement vers un nouveau cadre sans ruiner votre business.
Pré-rendre ou ne pas pré-rendre ?
Pour clarifier les choses, j’utilise le terme “pré-rendre” dans cet article pour décrire le concept de rendre des pages dynamiques avec une infrastructure librement choisie puis de les renvoyer lorsqu’un User-Agent en fait la requête.
Avant une migration, vous devrez décider si vous souhaitez pré-rendre (ou rendre du côté serveur) les pages. La réponse est : ça dépend :) Mais dans la plupart des cas, oui vous devriez.
Vous trouverez ci-dessous les options envisageables en fonction du poid de votre site en JS:
- Laissez-le tel quel et fiez-vous au rendu côté client
Note : Google peut traiter le JS (gardez en tête que c’est toujours loin de l’idéal) mais d’autres moteurs de recherche n’ont pas cette capacité. Donc si vous cherchez à développer votre visibilité sur Bing ou Yahoo, ne comptez pas sur le rendu côté client.
- Implémentez un rendu côté serveur : de nombreuses options vous permettent de faire cela. Tout dépend de votre cadre, taille de site web et type de contenu.
La différence est représentée dans ce schéma :
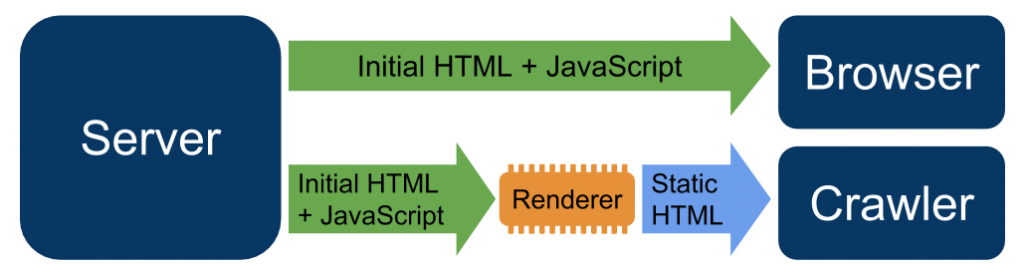
Si vous choisissez le rendu côté serveur, vous avez deux approches au choix :
- Le rendu dynamique : dans ce cas, vous devez construire une infrastructure additionnelle qui va détecter les User-Agents qui font une requête auprès de votre site. S’il s’agit d’un crawler de moteur de recherche, l’infrastructure servira la version pré-rendue de la page. Le rendu dynamique est un concept qui a été introduit pendant le Google I/O 2018 et qui est bien décrit dans la documentation de Google. Concrètement, cela signifie que vous pouvez détecter le User Agent et envoyer une version de rendu côté client à vos utilisateurs normaux et une version de rendu côté serveur aux crawlers.
- Le rendu hybride : dans ce cas, les utilisateurs et les crawlers reçoivent la version du rendu côté serveur de la page lors de la requête initiale. Toutes les interactions des utilisateurs subséquents sont servies avec JS. Rappelez-vous que lorsque le Googlebot crawle votre site, il n’interagit pas avec celui-ci. Il extrait les liens depuis le code source et envoie des requêtes au serveur donc il reçoit toujours le rendu côté serveur.
Comment choisir la meilleure option ? En fait, cela dépend des caractéristiques du site web. Si vous avez une grosse structure avec du contenu dynamique qui est très régulièrement rafraîchi, vous devriez probablement implémenter le rendu dynamique de l’approche hybride. Pourquoi ? À cause de la règle des deux vagues d’indexation que Google applique aux sites JS lourds.
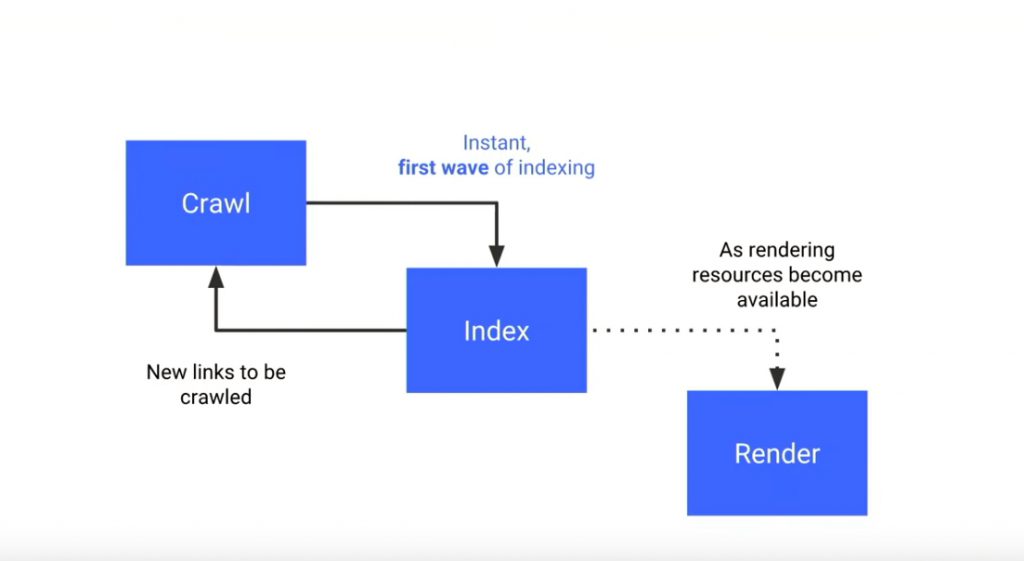
Dans la première étape, les moteurs de recherche indexent la page sans exécuter le JavaScript. Le contenu et la navigation dépendant de JS ne seront donc pas découverts. S’ils ont les ressources nécessaires, ils exécutent le JavaScript sur votre site web et Google peut enfin voir le contenu et l’indexer correctement. L’intégralité de la procédure peut prendre un peu plus de temps.
Si vous avez un portail d’actualités ou que vous publiez des offres limitées dans le temps, il se peut que Google ne découvre pas le contenu à temps et que vos concurrents prennent l’avantage. Pour éviter ce problème, vous devrez rendre les pages pour Google et les envoyer directement au crawler. Mais, si vous avez un petit site web et que vous ne changez pas souvent le contenu, vous pouvez essayez le rendu côté client.
Hi @JohnMu, what are your current thoughts on GB rendering of SPA’s? …. ???? or ???? or ???? – I’m not sure if JS rendering is working « well » for me yet.
— Kim Dewe (@kimdewe) July 16, 2018
Google peut exécuter et rendre les sites web alimentés par JS mais vous devez vérifier s’il le fait correctement et efficacement.
Version validée servie au GoogleBot
Que vous ayez choisi le cas du rendu côté serveur ou côté client, vous devez vérifier ce que vous servez au Googlebot. J’ai rassemblé quelques éléments critiques à inclure dans votre procédure de débogage pour vous assurez que Google voit le contenu correctement et peut efficacement indexer le site.
Comment Google rend ma page ?
La Google Search Console peut vérifier si Google est capable de rendre la page correctement. Tout ce que vous avez besoin de faire est d’utiliser l’outil de Fetch and Render en tant que User-Agent Desktop et Mobile. Si vous voyez que la page est rendue correctement, c’est super. Cependant, je recommande de tempérer vos attentes lorsque vous attendez le téléchargement des ressources. L’outil de Fetch and Render peut être plus patient que l’Indexer. Il se pourrait que Google n’indexe pas le contenu même s’il peut techniquement rendre la page à cause d’une temporisation des ressources dédiées au JS, CSS ou fichiers images. Ce problème peut apparaître lorsque l’infrastructure du serveur n’est pas suffisamment efficace pour servir les ressources. Si elles ne sont pas délivrées à temps, la procédure de rendu sera écrasée. Par conséquent, vos pages pourraient être rendues partiellement ou Google pourrait recevoir une page blanche.
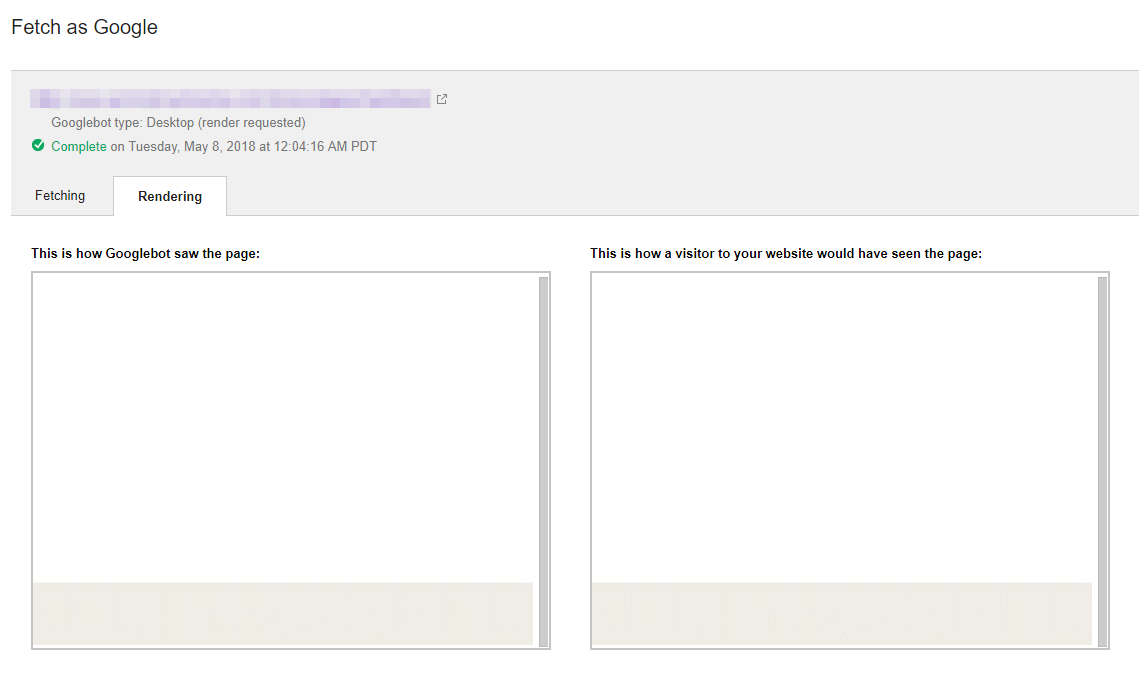
Dans un tel cas, Google pourrait ne pas indexer votre page du tout ou ne pas voir le contenu que vous voulez indexer. Si vous envoyez des pages blanches à grande échelle, Google pourrait les marquer en dupliquées.
Il existe différentes techniques pour identifier ce problème :
- Une vérification manuelle du contenu indexé (site: command)
- Vérifier les pages avec un faible nombre de mots dans les données de crawl. Cette méthode est applicable si vous savez que ces pages doivent avoir de meilleures métriques.
Est-ce que Google peut exécuter du javascript sur mon site ?
Vous devez vérifier cela si vous n’utilisez pas le rendu côté serveur.
Google pourrait rencontrer des problèmes avec le JS sur votre site qui pourraient l’empêcher de le rendre correctement.
Il existait auparavant deux options à vérifier :
- Télécharger Chrome 41 (navigateur de 3 ans, utilisé par Google pour rendre les pages) et vérifier la console.
- Vérifier les erreurs dans le testeur Mobile Friendly
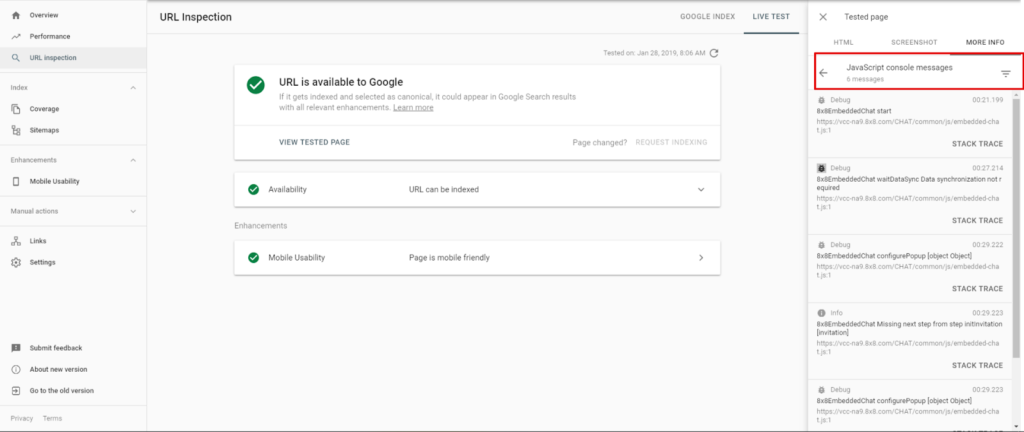
Maintenant, Google propose une nouvelle fonctionnalité dans la GSC qui permet de vérifier les erreurs JS sur les versions mobiles et desktop de votre site web. Vous devez utilisez l’outil Inspect URL et voir quels types de problèmes Google a rencontrés.
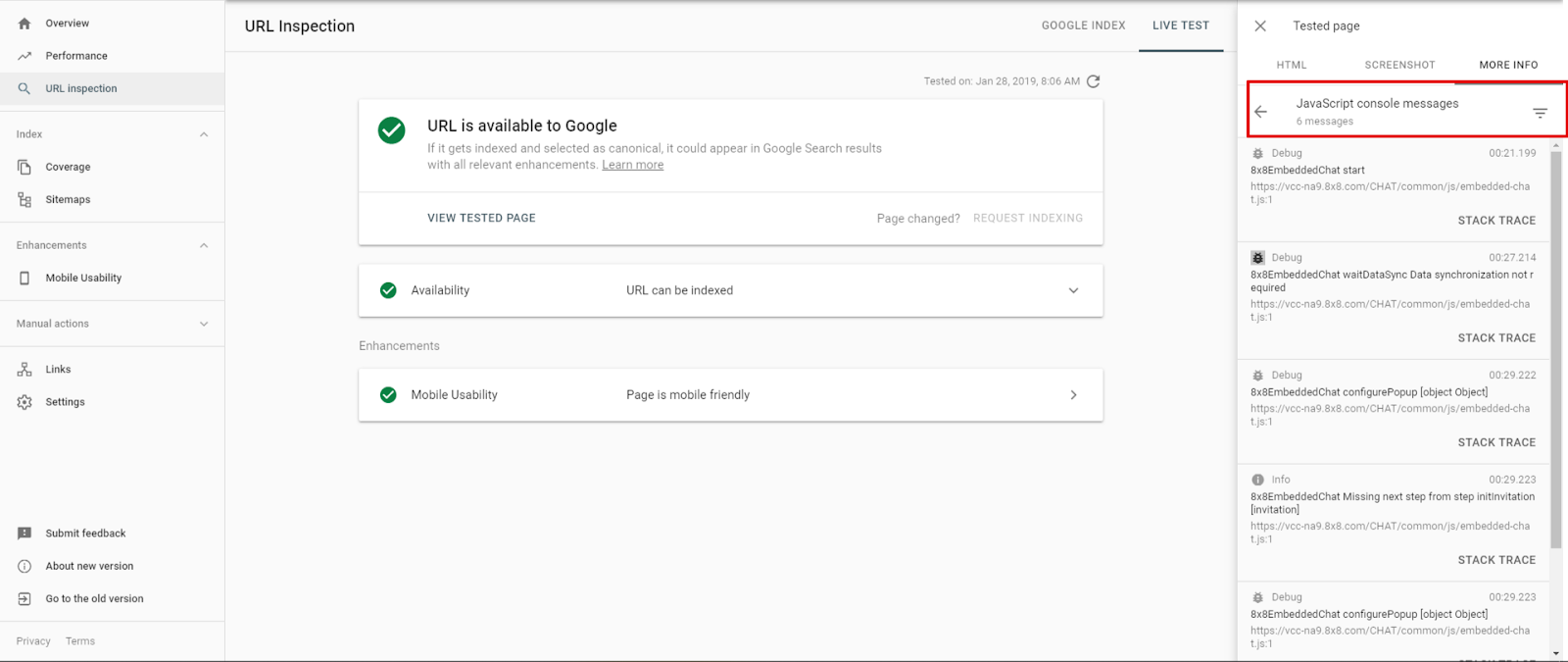
Pour l’instant, les erreurs JS que nous pouvons voir dans Inspect Element montrent seulement les données pour la version desktop. Si vous voulez vérifier les erreurs pour le site mobile et desktop, vous devez utiliser le test Mobile-Friendly et Inspect Element dans la Google Search Console.
Paramètres de cache
Si vous créez des aperçus pré-rendus, vous devez faire attention aux paramètres de cache pour ces fichiers. Il s’agit d’un problème plutôt commun où le rendu n’est pas synchronisé au moment de télécharger de nouvelles offres ou de changer le contenu. Par conséquent, les versions servies aux utilisateurs et aux crawlers sont légèrement différentes. Dans certaines niches comme l’immobilier, même les courts délais dans le rafraîchissement des offres peuvent avoir des résultats dramatiques dans les recherches organiques. De nombreuses fois, la même offre est publiée sur différent portails. Quiconque l’indexe en premier gagne le privilège de devenir la source.
Retirer le javascript de la version pré-rendue
JavaScript peut manipuler les éléments d’un site web. Cela pourrait conduire à des résultats pénalisant s’il interfère avec les métadonnées ou du contenu crucial de votre site. Google exécute le JS donc il remarquera également ces changements. Si vous décidez de servir la version du rendu côté client à Google, assurez-vous que le JS ne provoque pas de changements dans :
- La description et les méta titres
- Les instructions des méta robots
- Les hreflangs
- Le contenu
@JohnMu does Googlebot fully understand Angular.js ng-if robots meta tags? e.g. <meta ng-if= »pageHasNoResult » name= »robots » content= »noindex,follow »/>
<meta ng-if= »!pageHasNoResult » name= »robots » content= »noarchive,index,follow »/>— Lloyd Cooke (@lloydcooke) February 23, 2018
Même si vous décidez de servir des pages pré-rendues à Google, cela ne signifie pas que vous êtes débarrassé de ce problème. Il peut arriver que le Googlebot reçoive une version statique, pré-rendue qui possède toujours du JS qui change des éléments sur la page. Le pire scénario : que cela change les directives des méta robots, que Google l’exécute et écrase la configuration initiale.
Malheureusement, vous ne pouvez pas vous appuyez sur les données de l’outil Fetch and Render car il ne montre que le HTML brut. Pour diagnostiquer ce problème, vous devez vérifiez le DOM (le code après avoir exécuté tout le JS) dans le test Mobile-Friendly et vous assurez que les éléments importants n’ont pas changé.
Nettoyer les cookies en rendant le contenu
Ce problème peut affecter de nombreux sites web qui utilisent un navigateur sans tête pour rendre les pages pour les crawlers de moteurs de recherche. Les cookies sont petits mais sont aussi des petits bouts d’information très puissants stockés dans le navigateur. Certains sites web les utilisent pour stocker les préférences des utilisateurs comme les paramètres de langue, la devise ou l’appareil. Ils sont puissants car ils peuvent déclencher des redirections ou mettre à jour le contenu d’une page.
En crawlant et rendant la page, Google ne peut pas stocker les cookies donc il ne remarquera pas si vous avez changé quelque chose dans les informations qui y sont stockées. Si vous décidez d’utiliser le rendu dynamique pour rendre les pages pour les crawlers, vous devez veillez à ce que les cookies soient stockées dans l’outil de rendu. Si c’est bien le cas, vous devez les nettoyer après un rendu de page. Rappelez-vous que derrière Puppeteer ou Rendertron se trouve un navigateur sans tête qui exécute des scripts, rend la page et crée une version statique de la page. En résumé, il se comporte comme un navigateur standard.
Un navigateur sans tête a aussi la capacité de stocker des cookies et il peut arriver que les aperçus contiennent les changements qu’ils ont déclenchés.
J’ai déjà accompagné un client dans l’implémentation du rendu dynamique. Si un cookie stocké dans le navigateur ne correspond pas au langage d’une page donnée, les cookies déclenchent une redirection vers la page d’accueil. D’un point de vue SEO international, c’est une très mauvaise idée, mais en plus, ce phénomène a des conséquences extrêmement négatives sur l’indexation. Puppeteer qui était installé sur le serveur pour rendre les pages, stockait les cookies et recevait une redirection tout comme les utilisateurs normaux. Ainsi, au lieu de contenir le véritable contenu des pages, une grande partie des URLs renvoyait vers la page d’accueil.
Surveiller la performance
La vitesse du site impacte non seulement la vitesse de crawl mais aussi l’expérience utilisateur. Les sites alimentés par javascript peuvent être très lourds et si vous ne suivez pas les meilleures pratiques pour expédier avec ressources avec la performance en tête, vos utilisateurs vont être confrontés à une application désagréable.
Lighthouse et Webpagetest font partie des meilleurs outils gratuits pour tester la performance dans un environnement de test. Ils peuvent révéler des embouteillages et donner des indications sur les potentielles améliorations. Ces outils vous aident à capturer les métriques dans des conditions données. Cependant, ils ne fournissent pas d’informations sur la manière dont les véritables utilisateurs perçoivent la performance de votre site.
Des insights inestimables sont donnés par le rapport de Chrome User Experience à ce sujet. Ci-dessous, vous pouvez voir ce qui pourrait arriver après le passage au cadre JS. Jusqu’à novembre, il s’agissait d’un site classique, statique. Puis, il est passé sur un cadre JS et les données du rapport CRUX ont montré l’impact suivant sur les utilisateurs.
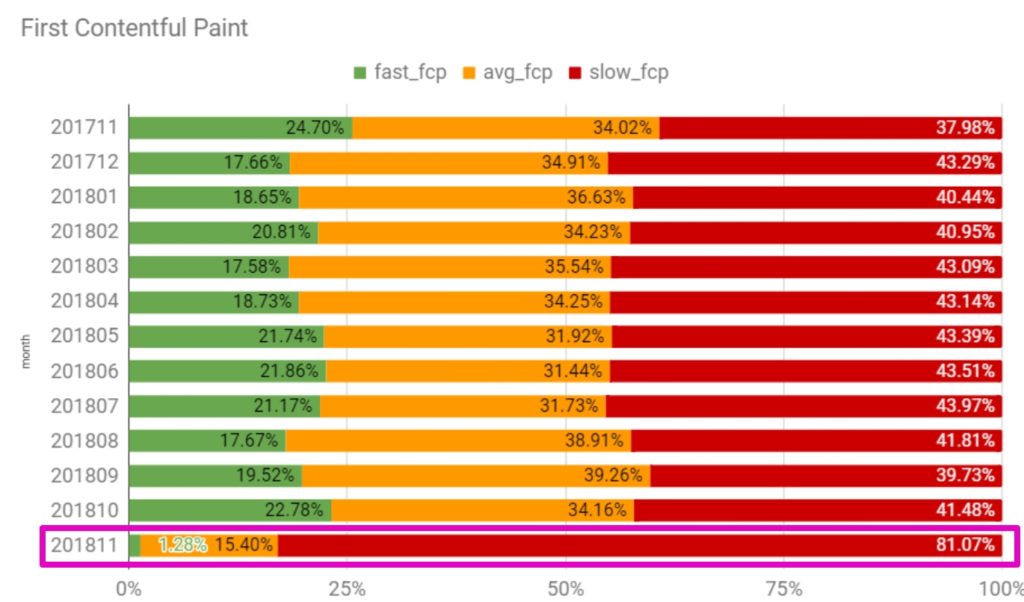
81 % des utilisateurs perçoivent le FCP comme lent. Ce nombre a doublé par rapport aux mois précédents. Les utilisateurs n’ont pas apprécié le changement et les propriétaires du site web ont été confrontés à une longue route avant l’amélioration de leurs performances.
Expliquer des problèmes complexes avec des mots simples et par la pratique
Ce n’est pas un conseil uniquement lié au SEO. L’analyse et le débugage des sites alimentés par javascript nous amènent à un différent niveau d’analyse technique. Les experts SEO doivent comprendre ce qu’il se passe sur le serveur et comment les pages sont rendues.
The web has moved from plain HTML – as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
— ???? John ???? (@JohnMu) August 8, 2017
Les sites web JS partagent tous le fait d’avoir des problèmes extrêmement spécifiques et souvent ils ne sont pas faciles à comprendre et à expliquer. Les SEOs doivent apprendre comment communiquer et se coordonner avec les développeurs. Expliquer des problèmes complexes et délicats avec des mots très précis est encore plus important aujourd’hui qu’auparavant.
Je pense que le plus grand challenge avec l’implémentation du SEO est le manque de communication entre les équipes SEO et développement. Or, dans notre nouveau monde, il y a peu de place pour l’incompréhension.
Conclusions
Le JavaScript n’est pas un cauchemar (mais il peut l’être). Il y a de nombreux sites alimentés par JS qui s’améliorent dans les recherches organiques. Dans cet article, je présente quelques éléments clés qui doivent être vérifiés dans le cas de sites alimentés par JS (il ne s’agit pas d’une liste exhaustive) basés sur les découvertes récentes de l’équipe d’Elephate. Bonnes analyses !
