Dans cet article, j’examinerai ce que sont exactement les données structurées Schema.org, pourquoi elles sont essentielles à la construction de l’E-A-T, et comment nous pouvons tirer parti de leurs attributs pour communiquer des données précises aux SERP.
Qu’est-ce que l’E-A-T ?
L’expertise, l’autorité et la confiance, ou E-A-T (pour Expertise, Authority and Trust), est l’un des principaux critères utilisés par les moteurs de recherche pour décider quel est le meilleur site à afficher pour une requête donnée. L’utilisation de données structurées leur permettra de savoir très précisément qui vous êtes et ce que vous faites, ce qui accroît leur confiance dans votre site. L’inclusion de données supplémentaires qui montrent l’expertise et l’autorité augmentera également la confiance et améliorera le classement de votre site.
Il existe un autre niveau appelé « YMYL », ou Your Money, Your Life, qui comprend tous les sites traitant spécifiquement de la finance et de la santé. Pour cette catégorie, Google est très strict et vous devez vraiment vous assurer d’inclure toute information qui démontre que vous êtes qualifié et compétent pour parler de ces sujets.
Qu’est-ce que les données structurées ?
Les données structurées sont des informations présentées dans un format standardisé qui peut être compris par des machines.
internet a besoin de données structurées pour exister. Pour que toutes les machines qui le composent puissent communiquer entre elles, tous les protocoles et langages (HTTP, TCP, TLS/SSL, PHP, Javascript, etc.) ont une structure rigoureuse et convenue.
Les informations que vous mettez en avant sur les pages de votre site web constituent une énorme exception à cette règle. Il n’existe aucune règle régissant la présentation de vos données. Lorsque les moteurs de recherche examinent ce contenu, ils analysent les morceaux de texte à la recherche d’éléments qu’ils peuvent identifier comme des types particuliers de données. Mais c’est toujours avec un certain degré d’incertitude. Par exemple, prenez une adresse standard telle que :
Amazing Stuff Inc, 39 Main Street, 34000 Newtown, France
On peut voir instantanément qu’il s’agit d’une adresse. Mais imaginez que vous soyez une personne venant d’une autre partie du monde qui utilise un format d’adresse différent, pourriez-vous interpréter les différentes parties de l’adresse ? On peut aisément dire que c’est la même chose pour les machines.
L’intelligence artificielle des SERP s’est développée au point de pouvoir reconnaître que cela ressemble probablement à une adresse et d’en extraire les différents éléments, mais elle n’est toujours pas sur à 100 % et a besoin d’être corroborée par de nombreuses autres sources pour être fiable. Les données structurées, cependant, sont constituées par paire avec un nom standardisé, tel que « streetAddress » ainsi que la valeur qui lui est attribuée (dans ce cas « 39, Main Street »). Les moteurs de recherche scannent alors le code html à la recherche de ce type de données.
Le problème est que même si une information affichée sur un site web semble structurée pour un être humain, ce n’est pas forcément le cas pour une machine. Elles doivent deviner !
Concrètement, que pouvons-nous faire face à ça?
Schema.org fait partie d’une initiative lancée en 2011 par Google, Bing et Yahoo pour fournir un système de schémas universels permettant de marquer les données structurées sur les sites web. Lorsque les moteurs de recherche voient la ligne « @contexte » : « http://schema.org/« , ils commencent à chercher des paires de données Schema.org qu’ils peuvent reconnaître.
Nous pouvons insérer des données structurées dans la section <head> de notre html :
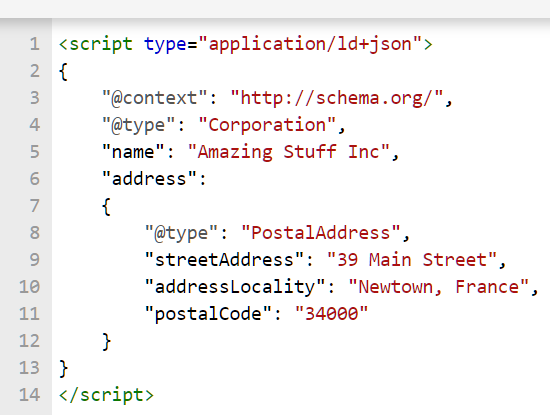
Fig 1. Données structurées au format JSON-LD
Et c’est comme ça que les moteurs de recherche le voient lorsqu’ils analysent la page :
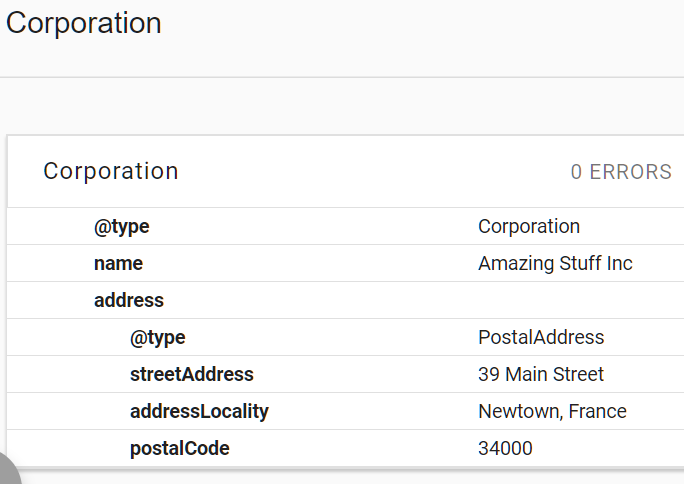
Fig 5 Données structurées dans l’outil de test de Google
Les algorithmes des SERP sont maintenant sûrs à 100 % de l’identité et du rôle de chaque bit de données structurées. Cela leur facilite la tâche et augmente la confiance qu’ils ont en vous, en ce que vous êtes et en ce que vous faites.

Le balisage du schéma pour une entreprise
Je vais commencer par le schéma le plus simple, puis j’aborderai quelques optimisations supplémentaires.
Tout d’abord, vous devrez définir votre type d’entreprise. Comme le système Schema.org est une hiérarchie d’élements (que vous pouvez voir ici) appelées types, vous pouvez commencer par le type le plus général et approfondir la hiérarchie jusqu’à ce que vous trouviez votre catégorie. Le type le plus général est « Thing » (chose), qui contient un certain nombre de sous-types généraux, dont l’un est « Organization » (organisation). Comme vous pouvez le voir dans la figure 3, “Organization” contient d’autres types comme Corporation, LocalBusiness, Écoles, etc…

Fig 3 Une partie de la hiérarchie des catégories
Vous pouvez voir que LocalBusiness a un grand nombre de sous-types, donc vous pouvez continuer à approfondir mais si vous n’êtes pas une entreprise locale, alors vous êtes probablement une société, donc vous pouvez regarder dans ce sens. Cliquez ici pour voir la page consacrée aux sociétés.
Votre bloc Schéma ressemble maintenant à ceci :
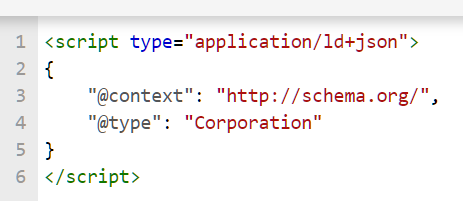
Fig 4 Le type de société
Aucune erreur dans l’outil de test ! En revanche, nous n’avons rien concernant l’entreprise et il est nécessaire de rajouter quelques attributs ou données pour la décrire.
Sur la page Société, vous verrez qu’il y a un certain nombre d’attributs acceptés. Il est important d’orthographier correctement les noms des attributs car une fois que le moteur de recherche a vu le type, il recherche les attributs spécifiques acceptés pour ce même type. Les noms d’attributs commencent par une lettre minuscule et les noms de types par une lettre majuscule.
Certains types ont un ou plusieurs attributs obligatoires : si vous choisissez un type de LocalBusiness (ou un sous-type de LocalBusiness), vous pouvez voir des erreurs affichées dans l’outil de test car il nécessite au moins un nom et une url d’image.
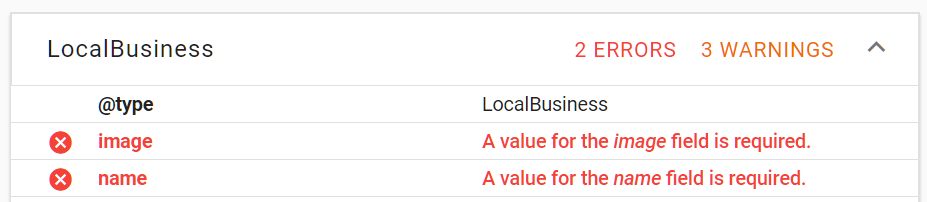
Fig 5 Erreurs pour les données manquantes
Si cela se produit, assurez-vous de fournir au moins les données requises comme dans la figure 6 ci-dessous, afin d’éviter un mauvais balisage et ajouter des données supplémentaires :
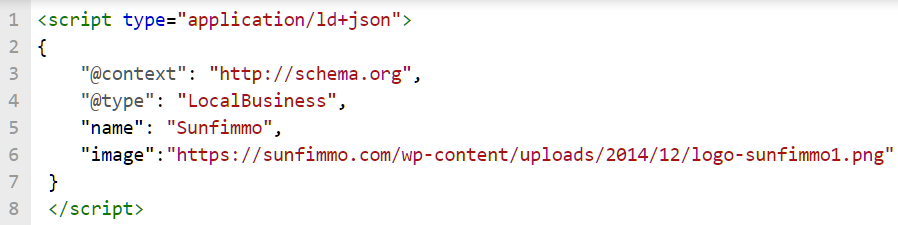
Fig 6 Les erreurs sont corrigées

Pour la suite de cet article, je prendrai l’exemple de sunfimmo.com, une entreprise que j’ai déjà balisé dans le passé. Il s’agit d’une société française mais souvenez-vous, les noms des attributs sont toujours dans la forme anglaise standardisée pour être reconnaissables par les SERP.
La société est une agence immobilière mais elle ne dispose pas d’une agence physique, ce qui signifie qu’elle n’est pas classé dans le type “ LocalBusiness”. Au lieu d’utiliser RealEstateAgent, la catégorie doit être Corporation. La balise de base est le suivant :
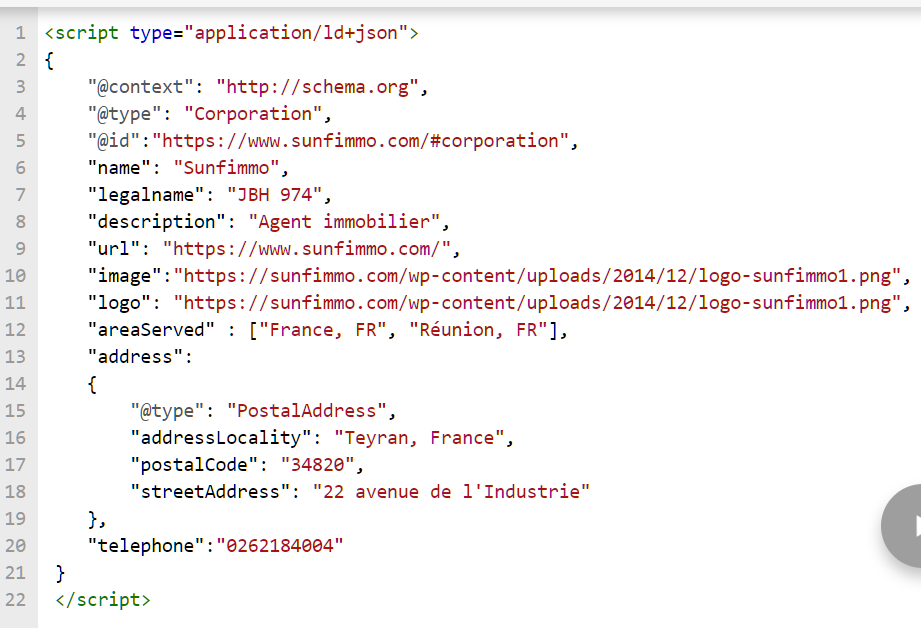
Fig 7 Schéma de base.org pour une société
Nous disposons maintenant de quelques données de base sur l’entreprise. Notez que le nom légal n’est pas le même que le nom utilisé pour le commerce. C’est un élément important car nous ajouterons plus tard des liens vers les listes officielles d’enregistrement des sociétés et les données doivent être les mêmes. Il en va de même pour l’adresse et le numéro de téléphone, ils doivent être les mêmes partout !
[Étude de cas] Optimiser les liens pour favoriser les pages les plus ROIstes

Point de contact
Si une entreprise a plusieurs points de contact (dans différentes villes, régions ou pays), ils peuvent également être marqués. Cette société a deux bureaux mais ils partagent le même numéro de téléphone, ce qui les regroupe :

Fig 8 Schema.org pour un Point de contact
Notez que lorsqu’un type (ici ContactPoint) est utilisé comme valeur pour un attribut, il est marqué comme un bloc entre parenthèses, il s’agit de données structurées ! Lorsqu’un attribut a plusieurs valeurs, nous pouvons les mettre entre crochets, séparées par des virgules.
Marquage supplémentaire pour une entreprise
Type supplémentaire
Vous avez vu précédemment dans l’article que nous ne pouvons pas marquer la société comme RealEstateAgent parce qu’il ne s’agit pas d’une entreprise locale. En revanche, nous POUVONS quand même montrer qu’elle a le type spécifique d’agent immobilier dans un format de données structuré en utilisant le système de Productontologie. Je n’entrerai pas dans les détails maintenant (les instructions sont ici) mais cela nous permet de le faire :
![]()
![]()
Fig 9 Productontologie
Et on peut aussi mettre un lien vers Wikipédia dans un bloc sameAs :

Fig 10 Utilisation de sameAs
Lien vers des pages officielles pour améliorer la crédibilité
Nous avons maintenant un marquage avec des détails de base sur l’entreprise ainsi qu’un type plus spécifique. N’oubliez pas que nous voulons également accroître la confiance et la crédibilité afin de montrer que l’entreprise est réelle. Pour ce faire, nous pouvons créer des liens vers des pages officielles contenant des données que nous ne pouvons pas modifier nous-mêmes, ce qui les rend beaucoup plus crédibles ! Par exemple, les comptes des réseaux sociaux où tout le monde peut prétendre être ce qu’il veut !
En France, toutes les entreprises ont un numéro d’enregistrement officiel (« SIRET ») et un code pour le secteur dans lequel elles travaillent (« CODE NAF »). Nous pouvons donc écrire un bloc personnalisé qui dit : « Ceci est un identifiant officiel, voici comment il s’appelle, voici sa valeur, voici une page wikipedia qui le décrit et voici la page d’administration officielle avec le listing » :
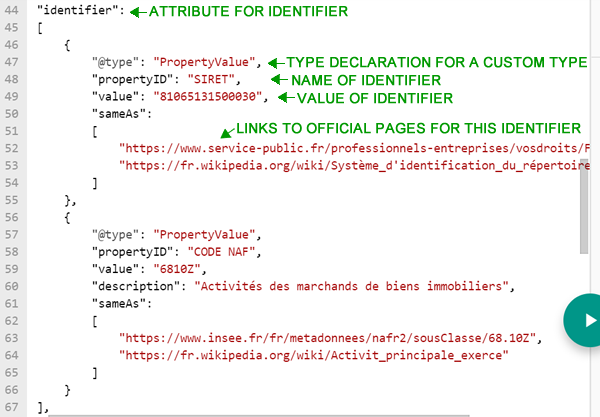
Fig 11 Utilisation de l’identifiant Schema.org
Pour corroborer avec d’autres informations « officielles », nous pouvons fournir des liens vers des pages de listes d’informations sur les entreprises avec tous les comptes sociaux actifs pertinents, dans le même bloc sameAs :

Fig 12 D’autres liens sameAs
Ajout de données de schéma pour une personne afin d’accroître l’expertise et l’autorité
Nous avons créé notre principal bloc de balisage Schema pour la société et ajouté une foule de données pour renforcer sa crédibilité ainsi que sa fiabilité. Un bon moyen d’accroître l’autorité (rappelez-vous que tout cela concerne l’E-A-T) et d’inclure une ou plusieurs personnes afin de connaître leurs qualifications. Pour ce faire, nous pouvons inclure un bloc « Personne » :
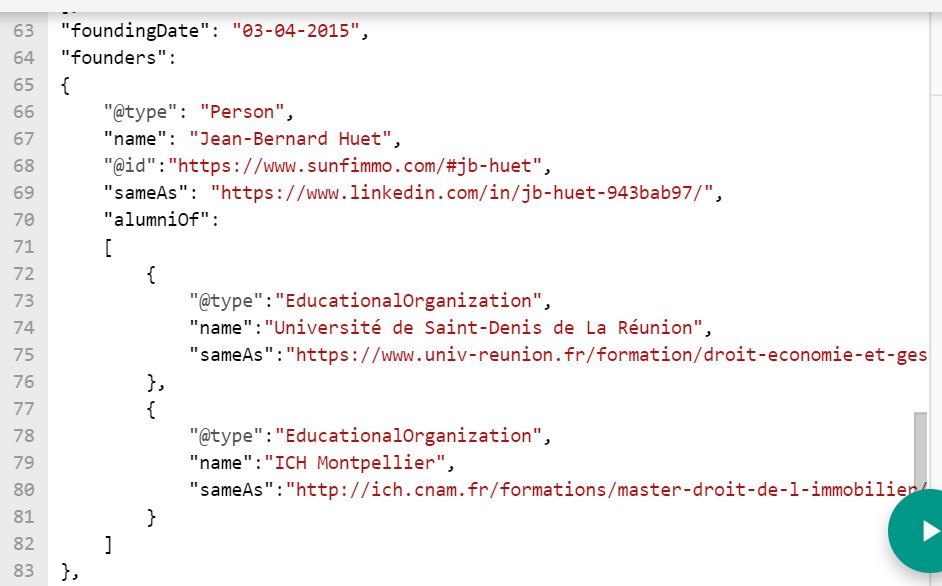
Fig 13 Schema.org pour une personne
Ici, nous disons que le fondateur est une personne appelée Jean-Bernard Huet, puis nous fournissons son compte LinkedIn et précisons qu’il est un ancien élève de 2 écoles avec un lien vers les pages des diplômes spécifiques obtenus, l’un en économie & commerce et l’autre en droit immobilier. Pour renforcer sa crédibilité professionnelle, nous pouvons inclure un bloc d’identification, comme pour l’entreprise, mais cette fois en définissant son numéro de licence d’agent immobilier et en établissant un lien vers les pages officielles qui décrivent ce qu’il est, ainsi que la page officielle de la Chambre de commerce :
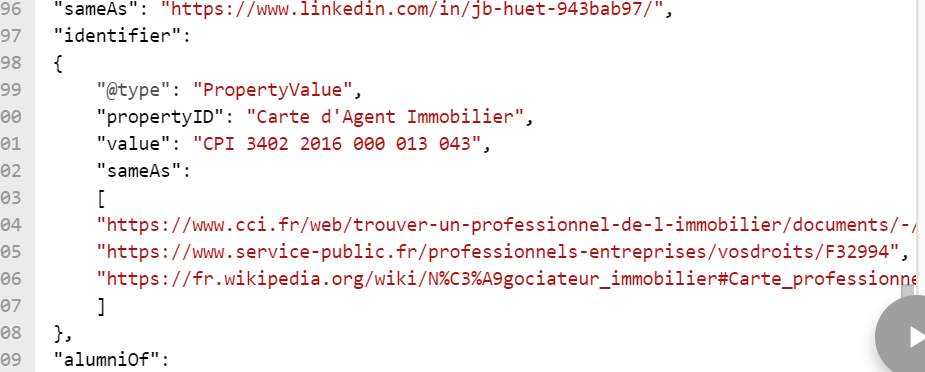
Fig 14 Identifiant Schema.org pour une personne
Ainsi, nous avons maintenant fourni une quantité massive de données très précises à Google dans un format spécialement conçu pour être facilement compris par les machines !
Le seul problème est que notre bloc est maintenant énorme et contient des entités dans des entités qui ne sont pas toutes nécessaires. Prenons l’exemple du bloc de balisage Schema pour l’attribut Fondateurs où nous voulons inclure la Personne et toutes les informations la concernant, mais nous ne voulons pas avoir à inclure le bloc Personne en entier à chaque fois. C’est là que @id prend tout son sens : une fois que nous avons défini le bloc Personne avec un @id, nous pouvons inclure cet @id dans le bloc Fondateurs…

Fig 15 Schema.org @id pour les éléments
… et Google reliera les éléments via @id comme vous pouvez le voir dans l’Outil de données structurées :
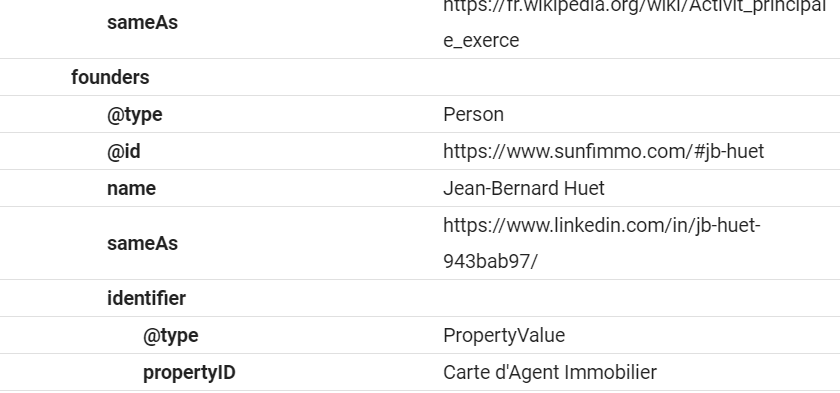
Fig 16 Comment Google verra le blog
Comment pouvons-nous inclure plusieurs blocs différents dans la même page ?
Pour rendre la gestion des blocs plus systématique, vous pouvez les placer sous forme de blocs séparés dans un conteneur comme @graph et les relier entre eux à l’aide de @id, comme ceci :

Fig 17 Utilisation de @graph pour plusieurs blocs
Ici nous avons donc : des blocs de données structurés claires, reliés entre eux par l’attribut @id, qui indiquent à Google et aux autres SERP qui vous êtes exactement, ce que vous faites et pourquoi vous avez l’autorité requise pour que vos pages soient bien classées dans les résultats de recherche. Tout ce que vous pouvez faire pour aider les moteurs de recherche à comprendre votre site et réduire leur charge de travail vous sera bénéfique.
Pour finir
C’est un vaste sujet et n’avons même pas analysé le balisage des produits/services ou des articles de blog, sans parler de la façon dont nous pouvons baliser les critiques ou les notes.. Ces questions seront traitées dans de futurs articles.
Amusez-vous avec vos données structurées et assurez-vous d’utiliser l’outil de test prévu à cet effet !
