
Le crawl fait partie des outils essentiels dans la boîte à outils SEO. La plupart des sites ont besoin d’être crawlés (par Google) pour être indexés, classés et cliqués. Il est donc indispensable de crawler votre site (avec un crawler SEO) et de s’assurer que les résultats sont corrects pour construire une stratégie SEO. C’est aussi la meilleure manière d’assurer le monitoring de votre site, suivre l’activité, analyser son état actuel ou pour mesurer les améliorations.
Qu’est-ce qu’un crawl (et comment il fonctionne) ?
Un crawl consiste en l’analyse d’un groupe de pages par un robot. Il peut s’agir d’une liste limitée de pages mais généralement, un crawl débute sur une page ou des pages spécifiques et utilise le robot pour lire la page et découvrir tous les liens sur ces pages. Le robot visite ensuite toutes les pages liées qui n’ont pas été déjà visitées et découvrent à nouveau des liens sur ces pages. Cette procédure se répète encore et encore jusqu’à ce que le robot ne trouve plus de liens qu’il ne connaît pas déjà.
Pendant ce voyage, le robot enregistre et rapporte les informations qu’il trouve comme le statut de la page rapporté par le serveur lorsqu’il demande une page spécifique, le temps nécessaire pour que le robot récupère toutes les informations d’une page…
Les robots peuvent aussi tirer des informations provenant des pages elles-mêmes : titres de page, méta informations, nombre de mots, données structurées…
Cela signifie que les robots ont besoin d’être capable d’accéder à une page et de la lire pour identifier les liens. La plupart des limitations de crawls proviennent d’éléments ou de conditions qui empêchent l’une de ces étapes de se produire.
Quelles sont les limitations d’un crawl ?
Les règles que vous programmez pour les crawlers SEO
À l’inverse du googlebot, vous pouvez paramétrer beaucoup des paramètres du comportement d’un robot SEO. Cela va déterminer la manière dont le crawl se déroule et quelles pages le robot peut découvrir.
Un exemple très évident est la limite de crawl via un nombre maximum d’URLs. Si ce paramètre est configuré et que le nombre est trop faible pour votre site, le robot ne pourra pas crawler toutes vos pages, mais pas pour une raison technique !
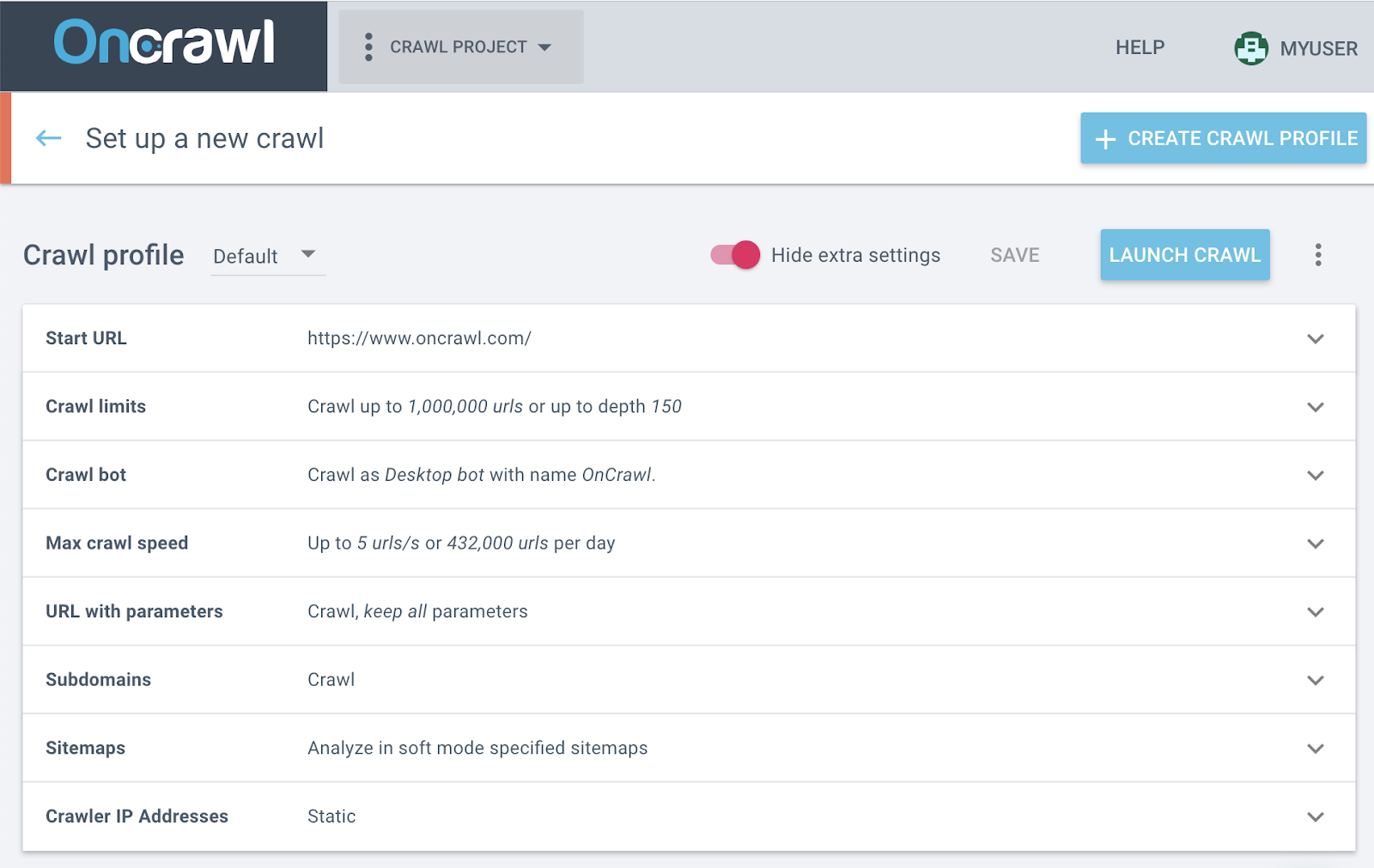
Comment réparer cette erreur : modifiez vos paramètres de crawl !
Préjudice anti-robot
Les sites qui ne jouent pas le jeu avec les robots ont souvent des problèmes avec les crawls.
Cela inclut les sites qui refusent l’accès aux robots. Ces sites peuvent avoir des raisons légitimes pour exclure les robots :
- Le propriétaire du site ne veut pas que le site soit indexé.
- Le site requiert un login, un cookie ou une autre méthode de vérification que les robots standards ne peuvent pas fournir.
- Le site a mis en place des autorisations restrictives suite à une mauvaise expérience avec un robot, comme le scraping, le monitoring par des concurrents ou une attaque qui visait à faire tomber le serveur.
- Le site utilise un service de protection tierce qui bloque tous les robots inconnus ou enregistre les robots blacklistés, que le site ait eu ou non une mauvaise expérience.
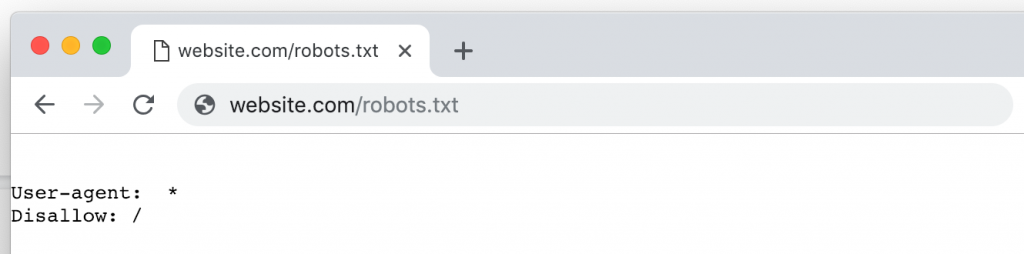
Mais le problème avec les exclusions générales de robots c’est que vous ne pouvez pas crawler votre site à la main. La nature des audits requiert que le site soit accessible par les robots.
Même si un site n’a pas décidé que tous les robots sont des mauvais robots, il peut toujours leur mettre des bâtons dans les roues. Il peut par exemple traiter certains robots différemment par rapport à d’autres ou aux visiteurs humains. Cela peut inclure les comportements suivants :
- Cacher du contenu aux robots ou utilisateurs (cloaking)
- Fournir différentes restrictions à certains robots en utilisant les fichiers htaccess, robots.txt ou les instructions meta robots.
Lorsque le robot de crawl est traité différemment que le googlebot, les résultats de crawl montrent l’analyse d’un site qui n’est pas celui que Google voit. Ainsi, les réels problèmes rencontrés par les googlebots peuvent restés non détectés.
De même, lorsque les robots ne sont pas traités comme les utilisateurs, le site qui est analysé n’est pas le même que celui que les utilisateurs voient. Il ne peut donc pas être utilisé pour révéler des problèmes d’expérience utilisateur.
Comment réparer cette erreur : assurez-vous que vous comprenez pourquoi vous crawlez votre site. Est-ce que vous voulez comprendre comment les utilisateurs perçoivent le site ? Comment Google le voit ? Obtenir une liste de pages et leurs caractéristiques, indépendamment des visiteurs ? Cela va déterminer le type d’autorisations dont le robot de crawl aura besoin.
Puis, échangez avec l’équipe de développement web ou avec votre fournisseur de service web pour établir le bon compromis entre les paramètres de robot disponibles dans votre crawler et les autorisations possibles sur votre site et ses pages.
Lorsque vous utilisez Oncrawl pour crawler votre site, vous pouvez prendre des mesures parmi les suivantes :
- Demandez les adresses IP statiques du robot Oncrawl et mettez-les sur liste blanche.
- Utilisez un fichier robots.txt virtuel pour outrepasser les instructions du site web concernant les robots (… mais seulement pour le robot Oncrawl).
- Modifiez le nom du robot pour que le robot Oncrawl suive les instructions dédiées à d’autres robots.
- Fournissez les informations de login, cookie ou header HTTP pour rendre correctement le site.
Relations robots / JavaScript
L’historique des relations entre robots et JavaScript est pour le moins tendu, à cause des problèmes liés au fait de produire du contenu sur une page pour le visiteur qui le demande, ou en d’autres termes rendre une page. Jusqu’à présent, seulement quelques robots étaient capables de rendre les pages qui utilisaient le JavaScript. Bien que ce ne soit plus le cas, tous les crawlers ne peuvent pas rendre tous les types de JavaScript, et les crawls JavaScript sont toujours plus “chers” (comprenez : ils requièrent des technologies plus complexes et sont plus lents) que les crawls standards.
Comme le JavaScript est utilisé pour insérer et étendre toutes sortes de contenu, dont les informations du header (comme les canoniques et hreflang), les liens et contenus textuels, les robots doivent avoir accès aux versions finales des pages. Lorsque ce n’est pas le cas, les informations de chaque page ou de l’intégralité du site web dans un crawl seront incomplètes si JavaScript a été utilisé pour insérer des liens.
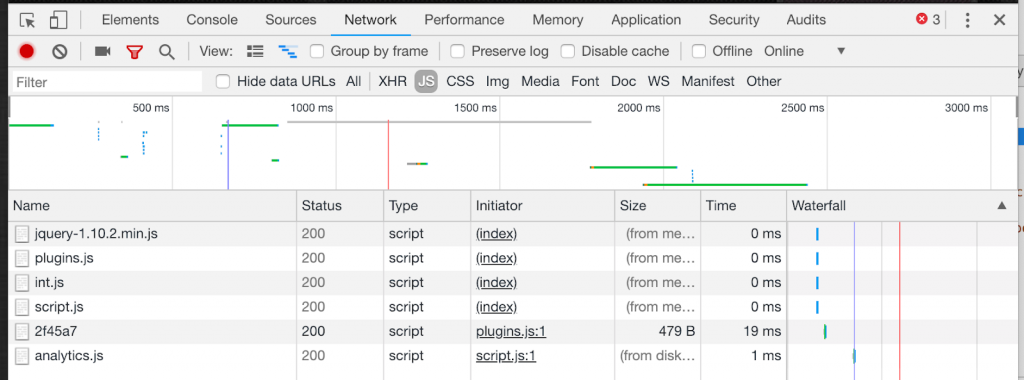
Comment réparer cette erreur : comprenez comment le JavaScript est utilisé sur votre site web et déterminez si les robots ont besoin ou non de comprendre le site. Si avez besoin de crawler en JavaScript, déterminez si votre site peut être pré-rendu ou si le crawler doit faire tout le rendu lui-même. (Le robot Oncrawl en est capable ! N’oubliez pas d’autoriser cette option dans les paramètres de crawl). Si vous êtes à la recherche d’un bon crawler, assurez-vous d’en choisir un avec un robot qui supporte les crawls de sites avec des specs techniques comme les vôtres.
Le grand inconnu derrière vos délimitations de crawl
Un crawl fournit simplement des informations à propos des pages qu’il crawle. Il n’a aucune connaissance des pages en dehors du champ du crawl. Cela peut paraître évident mais engendre également des conséquences qu’il est facile d’oublier :
- Un crawl n’a aucune connaissance des pages en dehors de ses limites si vous avez restreint le nombre de pages, la profondeur d’exploration, les sous-domaines à crawler…
- Un crawl n’a aucune idée de ce qui pourrait ou ne pourrait pas exister au-delà des frontières de votre site. Cela inclut les standards du secteur, les sites concurrents, d’autres sites classés, des traductions de votre site sur différents ccTLDs, l’influence des réseau de blogs privé, etc…
- Un crawl ne voit pas les backlinks : il ne peut pas prendre en compte l’influence des backlinks car il ne voit pas les pages qui renvoient vers votre site.
- Un crawl ne peut pas voir les pages qui ne sont pas liées dans la structure de votre site (pages orphelines).
- Un crawl ne rapporte que les mesures internes du site, sans prendre en compte les facteurs off-site, comme le linking, le paid search, la promotion sur les réseaux sociaux…
Lorsque les éléments clés de votre analyse ou de votre stratégie SEO tombent en dehors des frontières du crawl, cela peut fausser les résultats. Par exemple des pages orphelines très performantes, des backlinks, hreflang ou canoniques pointant vers d’autres (sous) domaines, des campagnes off-site ou payantes, ou la qualité relative de votre site par rapport à d’autres sites similaires peuvent être oubliés.
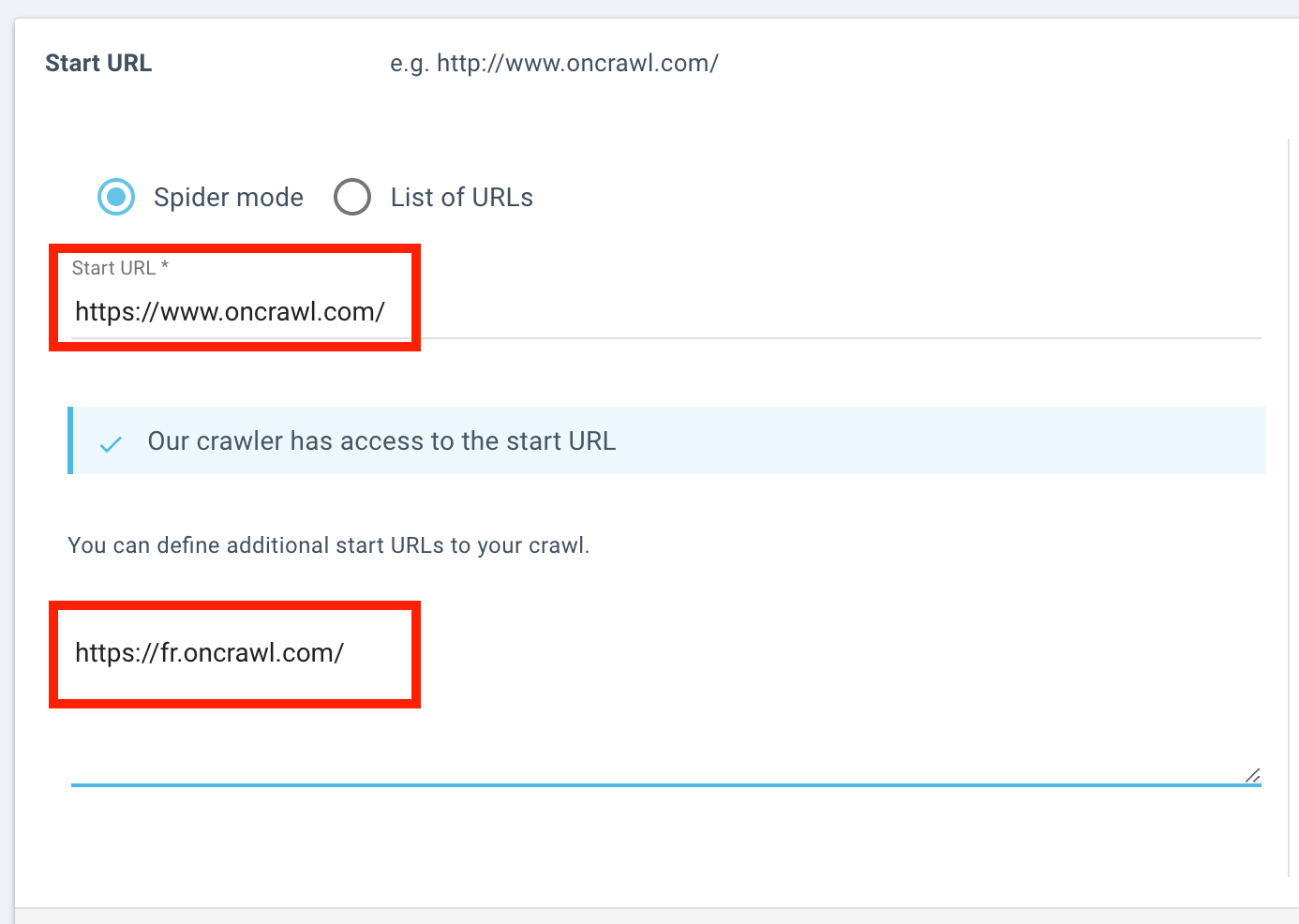
Étendre les frontières de crawl pour inclure un sous-domaine.
Comment réparer cette erreur : beaucoup des problèmes liés à la part d’inconnu au-delà de vos frontières de crawl peuvent être résolus. Rappelez-vous qu’un élément qui n’est pas présent dans vos résultats de crawl peut tout de même exister. Cela signifierait juste qu’il n’a pas été crawlé. Lorsque vous êtes conscients du type de pages que vous pourriez avoir exclu de votre crawl, vous pourrez mieux juger si cela avait ou non de l’influence sur vos résultats.
Plus concrètement, Oncrawl fournit des options pour vous aider à étendre les frontières de votre crawl. Par exemple, vous pouvez crawler les sous-domaines ou utiliser différentes start URLs sur différents domaines. Vous pouvez aussi utiliser des données tierces pour inclure des informations à propos des pages au-delà du périmètre de crawl. Pour en citer quelques-uns :
- Vous pouvez inclure les données de Majestic pour analyser vos backlinks et leur influence sur les pages de votre site.
- Vous pouvez utiliser les données de différentes sources (Google Analytics et des outils analytics similaires, la Google Search Console, les données de serveur de logs…) pour trouver des pages orphelines.
- Le crawl et les analyses ultérieures sont construits pour des sites de n’importe quelle taille, donc vous pouvez configurer des limites de crawl selon la profondeur et le nombre de pages sur votre site, au lieu des maximums arbitraires.
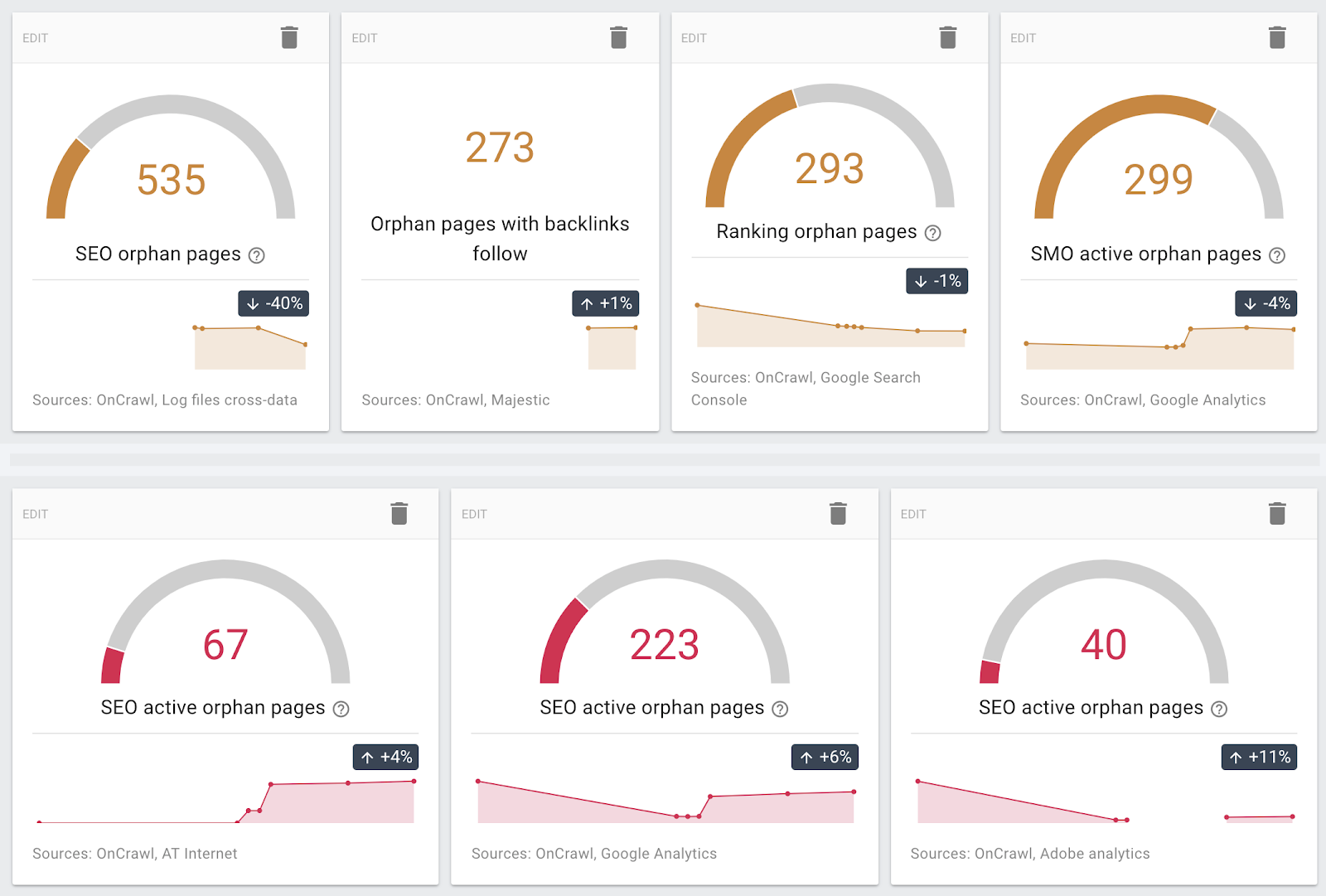
Pages orphelines découvertes en utilisant différentes sources
Attentes du crawl vs. réalité
Un crawl décrit votre site et comment un robot ou un utilisateur vont voir ses pages, en commençant par le point d’entrée que vous avez défini comme votre start URL. Cependant, un crawler SEO ne dispose pas de l’intention de recherche, des résultats de recherche ou des structures de prise de décision dont le visiteur humain dispose. À l’inverse, l’utilisateur n’a pas pleine conscience de la planification de crawl, des facteurs de classement, du machine learning et des connaissances sur le fonctionnement d’internet, que les moteurs de recherche ont.
Un crawl ne peut pas fournir des informations sur comment et quand les robots des moteurs de recherche ou utilisateurs consomment votre site. Ce type d’informations, qui sont indispensables pour comprendre comment un site performe, prennent en compte :
- Comment les éléments mesurés affectent ou sont affectés par le comportement des utilisateurs ou des robots Quand, comment et dans quel ordre vos pages seront crawlées par Google
- Quelles pages obtiennent le plus de visites
- Comment les pages se classent
- Où concentrer vos efforts SEO pour le meilleur ROI
Le résultat mène souvent à une analyse inutile. Un crawl fournit des informations complètes sur votre site, mais aucun moyen de lier cette information à comment votre site vit et respire selon vos clients, les SERPs et le reste d’internet.
Comment réparer cette erreur : utilisez plus de données !
Les données basiques du crawl pour chaque URL connue d’un site web peuvent être associées avec n’importe quel type de données ou l’ensemble de ces données pour faire du crawl un outil extrêmement puissant pour comprendre et gérer la performance web :
- Les données analytics pour le comportement utilisateur
- Les données de classement tirées de la Google Search Console
- Le nombre et la fréquence des robots et utilisateurs inscrits dans les serveurs de logs
- Les indicateurs business du CRM
- Des jeux de données personnalisés provenant d’autres sources
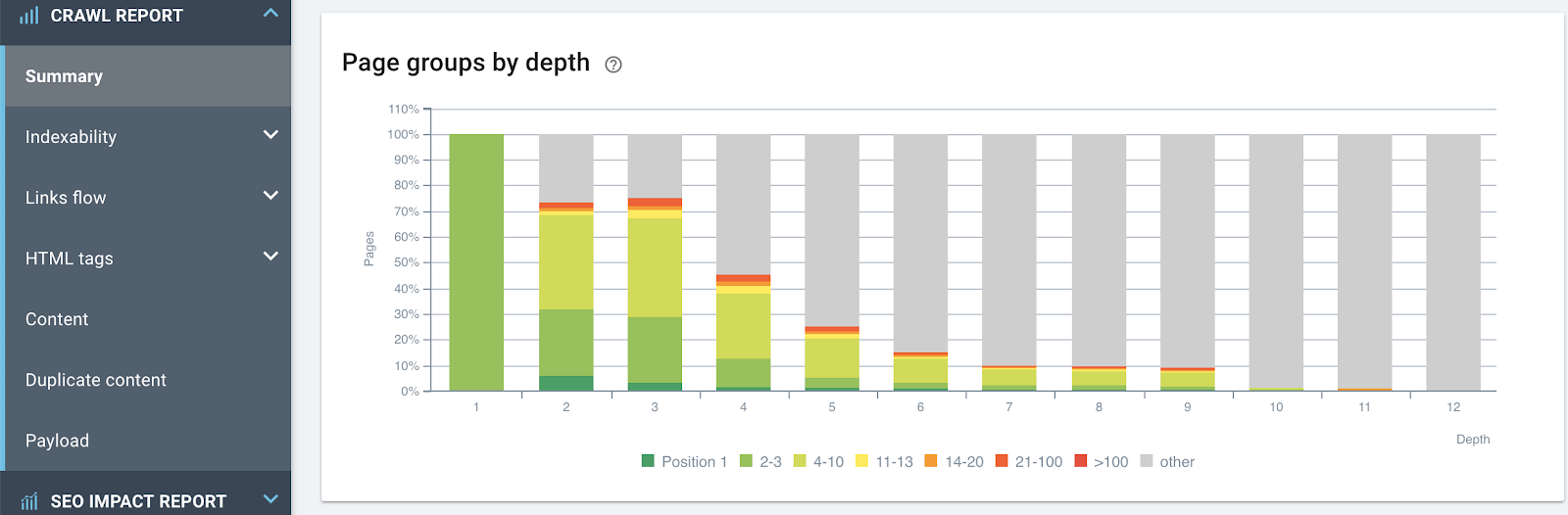
Effet de la profondeur (distance depuis la page d’accueil en nombre de clics) sur les classements : plus une page est proche de la page d’accueil, plus elle a de chances de se classer.
Pour résumer : comment surmonter les problèmes liés au crawl ?
Le crawl est un outil essentiel dans la boîte à outils SEO mais lorsqu’il est pris tout seul, ce n’est pas non plus la panacée SEO ! Comme vu précédemment, beaucoup des lacunes d’un crawl peuvent être éliminées ou nuancées grâce à deux stratégies majeures :
- Évaluer les limitations du robot. Les limitations imposées aux robots peuvent être liées à la technologie derrière le crawler, aux règles configurées par le site web ou aux options choisies par la personne qui a configuré le crawl. En travaillant avec l’équipe de développement du site web et en utilisant le bon crawler avec des paramètres de crawl appropriés, vous pourrez vous débarrassez de nombreux obstacles qui bloquent le crawl de vos pages et obtenir des analyses utiles.
- Fournir un accès aux données additionnelles. Par nature, la vue de votre site depuis un crawl ne peut pas inclure de données de performance ou business, des indicateurs clés pour les prises de décision marketing. Ces données ne sont pas rapportées car elles ne sont pas présentes sur la page web en elle-même. L’analyse croisée entre les données de crawl et comportementales, les classements ou même les données business peuvent faire d’une analyse de crawl un outil précis de prise de décision.
Une fois que vous aurez surpassé les limitations qui empêchent vos résultats de crawl d’être complètement fiables, vous trouverez de nombreuses informations pour conduire votre stratégie SEO.
