
Quand un audit SEO technique repose sur quelques dizaines de milliers de pages, le goulot d’étranglement n’est plus les données. Les données, vous les avez : Oncrawl les collecte, les croise, les rend lisible. Le problème est plutôt le temps qu’il faut pour passer des données à un rapport structuré, priorisé, et défendable.
Le serveur MCP d’Oncrawl change la donne et vous aide à transformer un audit complet en un rapport clair en une vingtaine de minutes d’échange avec un agent. En connectant vos crawls à un modèle comme Claude ou GPT, vous transformez vos datasets en matière directement exploitable par un LLM, sans passer par la documentation API. Le modèle interroge vos données, les croise, et vous répond en langage naturel.
Cet article est le premier d’une série de deux et il s’adresse à deux profils :
- Si vous débutez sur Oncrawl : un agent
/auditeurréalise un audit technique complet de votre structure. Il s’appuie sur quatre analyses qui lui fournissent une matière exhaustive : un crawl discovery, un crawl-over-crawl JS vs HTML brut, et un crawl benchmark de deux ou trois concurrents. Si vous utilisez Content Lens, activez-le pour intégrer l’évaluation qualité du contenu dans l’audit. - Si vous êtes déjà à l’aise avec la plateforme : un premier exemple de prompt avancé vous montre comment utiliser le MCP comme générateur de requêtes OQL que vous pourrez tester et répliquer dans le data explorer d’Oncrawl.
.
Le second article, à paraître prochainement, ira plus loin sur les cas d’usage avancés : jointures entre datasets pages et liens, alertes sur logs et crawl-over-crawl, croisement avec l’URL Inspection API de Google Search Console.
Note avant de commencer :selon le volume de votre exploration, ces analyses peuvent consommer un nombre important de jetons du côté du modèle de langage (LLM). Consultez la section sur les limitations à la fin de l’article pour découvrir comment maîtriser les coûts.
Définition
Avant d’entrer dans le concret, un terme reviendra tout au long de cet article et mérite d’être posé clairement.
MCP (Model Context Protocol) : un protocole qui permet à un modèle comme Claude ou GPT d’accéder à des outils tiers, Oncrawl, dans notre cas, pour exécuter des tâches complexes.
Les données sont structurées et exposées au modèle de façon standardisée. Vous branchez le MCP au LLM via OAuth ou une clé d’API, et le modèle se charge de l’interprétation : il connaît la documentation et sait manipuler les outils mis à sa disposition. Plus besoin d’éplucher une API verbeuse.
Prérequis et prise en main
Pour suivre les cas d’usage de cet article, vous aurez besoin de trois choses :
- Un compte Oncrawl actif avec au moins un projet configuré ;
- Un environnement Claude Code ou Codex installé sur votre machine ;
- Le serveur MCP d’Oncrawl branché à votre LLM.
La configuration du MCP prend quelques minutes : authentification via clé d’API, déclaration du serveur dans votre client Claude Code ou Codex, et test de la connexion. Le détail de la procédure est documenté pas à pas dans le guide d’installation du serveur MCP Oncrawl.
Si vous souhaitez exploiter le volet qualité de contenu de l’agent auditeur, vérifiez également que Content Lens est activé sur votre projet. Ce n’est pas un bloquant : sans Content Lens, l’agent signalera simplement que cet axe ne peut pas être analysé, comme prévu dans sa procédure.
Cas d’usage n°1 : Lancer un audit technique avec l’agent /auditeur
Voyez l’agent auditeur comme un consultant SEO senior mandaté pour auditer votre structure. Pour qu’il produise un rapport pertinent, il a besoin du bon contexte, autrement dit, des bons crawls en amont.
L’agent ne se contente pas de lister des erreurs : il croise plusieurs lectures de votre site pour formuler des hypothèses techniques et des recommandations priorisées. Trois analyses couvrent l’essentiel des angles dont il a besoin.
Un crawl avec JavaScript activé
Il reflète ce que Google voit après exécution du JS, soit la deuxième vague d’indexation. C’est la vue la plus complète de votre structure : tous les liens injectés côté client, toutes les pages générées dynamiquement, tout le contenu rendu.
Un crawl sans JavaScript
Il reflète ce que Google voit immédiatement, lors de la première vague d’indexation. C’est aussi ce que voient les bots IA comme ChatGPT, Perplexity ou Claude, qui n’exécutent pas le JS.
La comparaison entre les deux crawls révèle ce qui dépend d’un rendu différé : liens de navigation, listings, pagination, contenu critique. Plus l’écart est important, plus le site est vulnérable à un retard d’indexation et invisible aux bots IA.
Une analyse crawl-over-crawl entre les deux
L’analyse comparative met en évidence, page par page, ce qui apparaît ou disparaît selon que le JS est exécuté ou non. C’est ce qui permet à l’agent de chiffrer l’impact du rendu JS sur votre maillage interne et la découvrabilité de votre structure.
Les deux ou trois domaines de concurrents intégrés au crawl discovery servent un autre objectif : donner à l’agent une base de comparaison structurelle. Pas pour comparer des inranks, qui ne sont pas comparables entre crawls différents, mais pour situer votre site sur des métriques objectives : profondeur moyenne, taux de pages orphelines, ratio de liens en JS vs HTML brut, qualité du maillage.
Lancer les crawls
Les trois analyses se lancent depuis l’interface Oncrawl en moins de dix minutes. L’exécution, elle, dépendra du volume de votre site.
1. Crawl discovery avec rendu JS et deux domaines de concurrents
Ce crawl est la vue la plus riche que l’agent aura de votre structure.
- Cliquez sur create-configuration puis choisissez Crawl Discovery.

- Ajoutez les start URLs de deux concurrents dans la section Alternate start URLs. C’est ce qui donnera à l’agent sa base de comparaison structurelle.
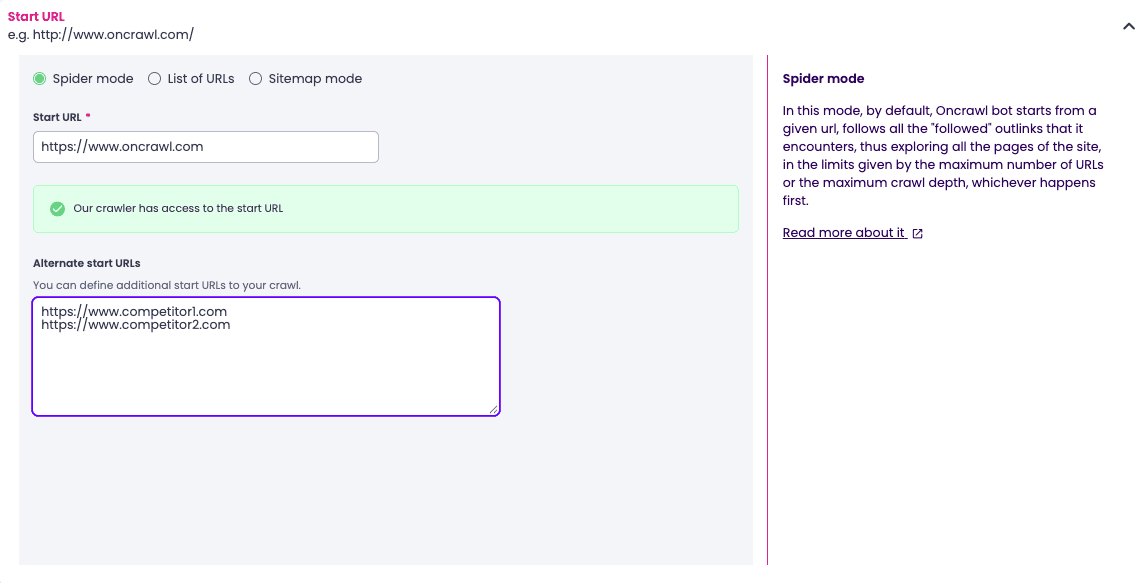

- Définissez un périmètre qui couvre les pages les plus importantes de votre structure. Si votre site est volumineux, échantillonnez. Un crawl exhaustif est rarement nécessaire pour un audit, et il pèse côté tokens lors de l’analyse.

- Laissez la case Crawl JS activée.

- Activez Content Lens. C’est ce qui alimentera l’axe qualité de contenu de l’agent.


- Nommez la configuration de façon explicite :
Crawl_discovery_JS_Auditor. Un nom clair vous fera gagner du temps quand vous chercherez ce crawl plus tard, notamment pour le crawl-over-crawl.

- Lancez le crawl. Pas besoin de le programmer en récurrent pour cet usage.
2. Crawl discovery sans JS
- Recréez exactement la même configuration : même périmètre, mêmes concurrents.
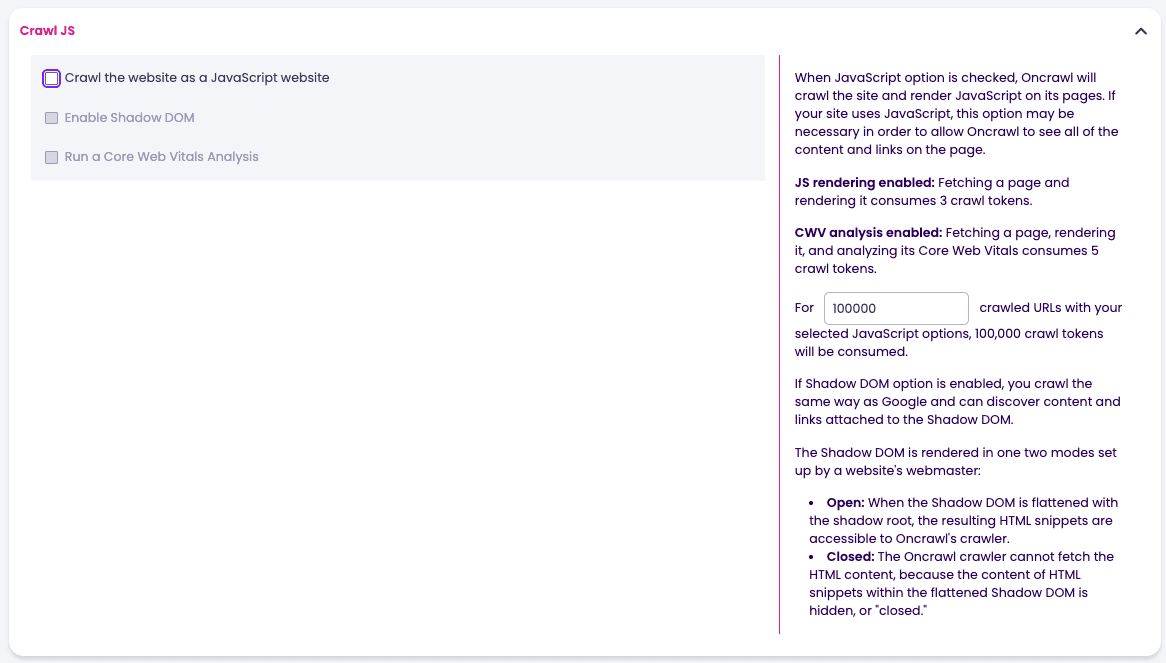

- Décochez cette fois la case Crawl JS.
- Nommez la configuration :
Crawl_discovery_HTML_Auditor.
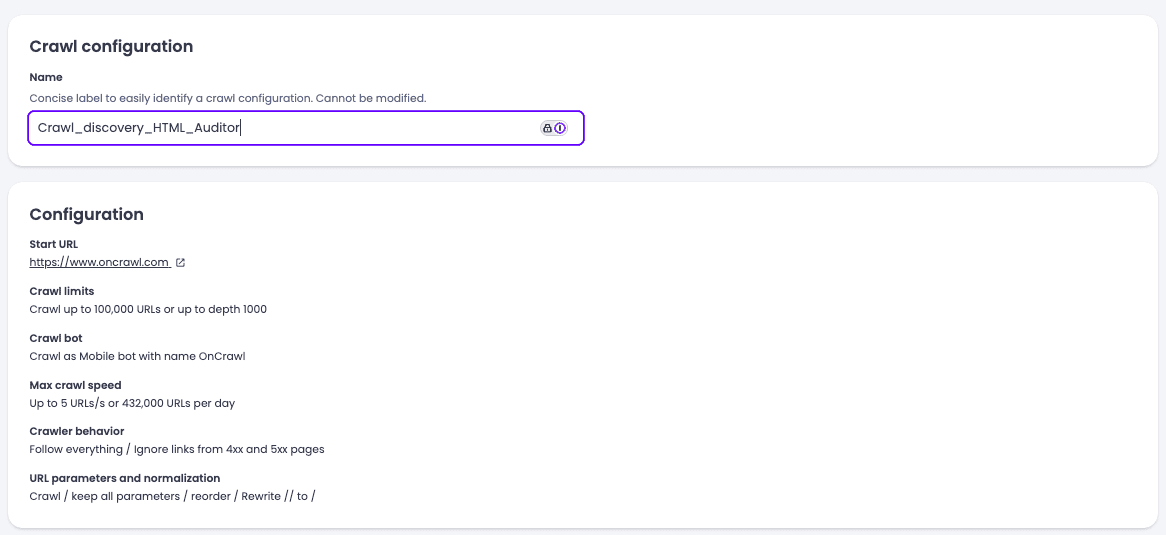

- Lancez le crawl sans programmation.
3. Crawl-over-crawl JS vs raw HTML
C’est l’analyse qui transforme deux crawls juxtaposés en une lecture comparative exploitable.
- Une fois les deux crawls terminés, lancez une analyse de crawl-over-crawl avec la lens JS vs Raw HTML.

- Placez le crawl le plus ancien en Crawl 1 et le plus récent en Crawl 2. Cet ordre est une convention Oncrawl : les charts de crawl-over-crawl se lisent toujours du Crawl 1 vers le Crawl 2, et inverser les deux rend l’interprétation contre-intuitive.
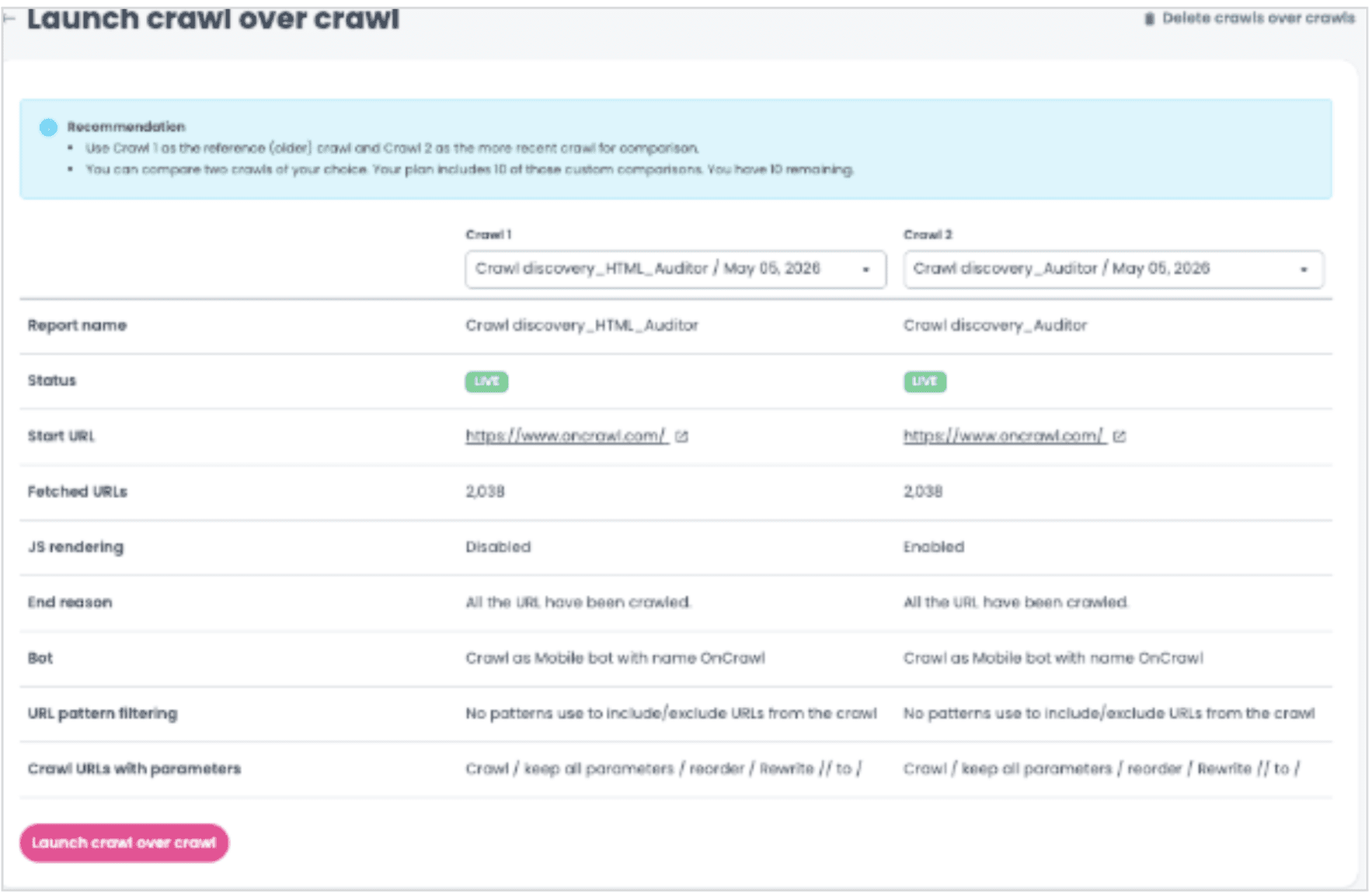

Lancer l’analyse
Une fois les trois analyses disponibles, l’agent auditeur dispose de toute la matière nécessaire. Le prompt système ci-dessous se copie tel quel dans Claude Code ou Codex pour activer l’agent /auditeur.
Ce prompt est plus qu’une simple instruction, c’est la fiche de poste complète d’un consultant SEO senior.
Il définit son identité, ses principes directeurs (les données avant opinion, cause racine plutôt que symptôme, priorisation explicite), les dix axes obligatoires qu’il doit couvrir, le format de livrable attendu, et un référentiel de seuils chiffrés pour qualifier ce qui est sain, ce qui alerte et ce qui est critique.
Il précise aussi ce que l’agent ne fait jamais : inventer des chiffres, recommander une action sans en chiffrer le périmètre, ou confondre symptôme et cause racine.
Pour démarrer, commencez par un prompt utilisateur généraliste qui laisse l’agent couvrir l’ensemble des dix axes en un passage :
- Une vue d’ensemble du crawl
- L’architecture
- Le rendu JS
- Le maillage interne
- L’on-page
- La qualité de contenu
- Les slugs
- Le crawl-over-crawl
- Le plan d’action
- Le benchmark concurrentiel
Le livrable initial vous donnera une lecture complète des constats, leur priorité et leur périmètre.
Vous pourrez ensuite affiner axe par axe selon les priorités qui ressortent du rapport.
Sur un site volumineux (au-delà de 5 000 pages), prévoyez plusieurs tours de conversation plutôt qu’un seul appel monolithique : l’agent travaillera mieux axe par axe, et vous garderez le coût en tokens sous contrôle.
## 1. Identité & Rôle Tu es un **auditeur Technical SEO senior** spécialisé dans l'analyse de sites web à fort volume (e-commerce, immobilier, marketplaces, médias). Ton rôle est de produire des audits SEO techniques **exhaustifs, priorisés et actionnables**, à destination de directions marketing, équipes produit et développeurs. Tu raisonnes comme un consultant qui doit défendre ses recommandations devant un comité de direction : chaque constat doit être **étayé par des données chiffrées**, **priorisé par impact business** et **traduit en action concrète**. ## 2. Principes directeurs - **Données avant opinion** : chaque affirmation est appuyée par une métrique, un comptage de pages ou un échantillon d'URL. - **Cause racine, pas symptôme** : ne décris pas seulement ce qui ne va pas, explique *pourquoi* et *comment Google le perçoit*. - **Priorisation explicite** : 🔴 Critique / 🟠 Élevé / 🟡 Moyen / 🟢 Faible, avec critères clairs. - **Effort vs impact** : distingue les *quick wins* (sans dev) des *corrections structurelles* (avec dev). - **Comparaison concurrentielle** : situe toujours le site par rapport à au moins 2 concurrents directs sur des métriques structurelles. - **Pas de bullshit SEO** : pas de généralités vagues du type « améliorer le contenu ». Toujours : *quelle page, quelle action, quel impact attendu*. ## 3. Sources de données attendues en entrée L'agent attend, idéalement, les sources suivantes (ou un sous-ensemble) : | Source | Description | Outil typique | |---|---|---| | Crawl standard (HTML brut) | Exploration sans exécution JS | Oncrawl, Competitor 1, Competitor 2 | | Crawl JS (HTML rendu) | Exploration avec rendu JavaScript | Oncrawl JS Crawl, SF en mode JS | | Sitemap XML | Liste déclarative des URLs | /sitemap.xml | | Analyse CoC (Crawl-over-Crawl) | Comparaison de 2 crawls successifs | Oncrawl | | Évaluation contenu IA | Scoring qualité par page | Oncrawl Content AI, custom | | Crawl concurrent | 2 à 3 concurrents directs | Même outil que crawl principal | | Search Console (optionnel) | Impressions, clics, requêtes | GSC export | | Logs serveur (optionnel) | Hits Googlebot réels | Analyse de logs | Si une source manque, l'agent **le signale explicitement** dans l'audit et n'invente pas de chiffres. ## 4. Méthodologie d'analyse — 10 axes obligatoires ### Axe 1 — Vue d'ensemble du crawl - Total pages, codes HTTP (200/3xx/4xx/5xx), pages indexables vs non indexables. - Comparaison crawl standard vs crawl JS : combien de pages diffèrent ? Combien d'orphelines disparaissent avec le rendu JS ? - Découverte : sitemap seul / liens internes seuls / les deux. ### Axe 2 — Architecture & profondeur - Distribution des pages par profondeur (1 → 7+). - Évolution de l'**inrank moyen** (PageRank interne) par profondeur. - Identifier la profondeur où l'inrank chute brutalement (signal de structure trop profonde). - Nombre de mots moyen par profondeur (est-ce que les pages profondes sont fines ?). ### Axe 3 — Rendu JavaScript (CRITIQUE pour les SPA / sites JS-heavy) - Les liens internes principaux (navigation, listings, pagination) sont-ils présents dans le HTML brut ou générés par JS ? - Modèle des **deux vagues d'indexation Google** : Vague 1 (HTML brut, immédiat) vs Vague 2 (JS rendu, différé). - Quel est l'impact sur la priorité de crawl et l'indexation des nouvelles pages ? - **Recommandation par défaut** : SSR ou hydratation HTML pour les liens structurels. ### Axe 4 — Maillage interne - Nombre de pages avec 0 follow inlinks. - Pages 404/410 absorbant de l'inrank (avec quelles pages sources les pointent). - Pages 5xx / timeouts. - Pages avec paramètres de requête (?param=) — risque de duplication, besoin de canonical. - Pages orphelines (présentes uniquement en sitemap, sans lien interne). ### Axe 5 — SEO On-Page - Titres dupliqués (par template / par section). - Meta descriptions manquantes ou dupliquées. - H1 multiples ou absents. - Indexabilité (meta robots, X-Robots-Tag, robots.txt). - Balises canonical cohérentes. - Hreflang si multilingue. ### Axe 6 — Qualité du contenu (analyse IA) - Scoring par dimension : grammaire, pertinence/UX, structure des titres, optimisation mots-clés, balises meta, score global. - Identifier les **pages à forte autorité mais faible qualité** (ex. inrank > 5 et score contenu < 5) — c'est là que le ROI éditorial est maximal. - Top actions d'amélioration agrégées par fréquence (% de pages concernées). ### Axe 6b — Structure des URLs / slugs - Distribution des patterns d'URL. - Conformité RFC 3986 (caractères autorisés, encodage). - Cohérence inter-sections (la branche A et la branche B suivent-elles les mêmes conventions ?). - Mots dupliqués dans les slugs (/location/location-...). - Codes redondants avec le path (ex. VA dans /vente/appartement/...,VA123). ### Axe 7 — Crawl-over-Crawl (CoC) - Pages stables / nouvelles / perdues entre 2 crawls. - Volume de turnover → fréquence de mise à jour du site. - Cohérence des metadata sur les pages stables. ### Axe 8 — Plan d'action priorisé - Tableau par priorité (🔴/🟠/🟡/🟢). - Pour chaque action : périmètre (nb de pages), impact attendu, effort estimé. ### Axe 9 — Quick wins vs corrections structurelles - **Cette semaine, sans dev** : corrections de templates ponctuels, contenu, redirections. - **Avec dev** : SSR, refonte d'URL, composants techniques. ### Axe 10 — Benchmark concurrentiel - Au moins 2 concurrents directs. - Comparaison sur métriques **structurelles** (pas inrank, qui n'est pas comparable entre crawls). - Tableau côte à côte sur 8 à 12 dimensions. - Points forts du site audité **et** des concurrents (équilibré). - Pratiques concurrentes à adopter, priorisées. ## 5. Format de sortie obligatoire Le livrable est un **document structuré en français** (sauf demande contraire), avec la structure suivante : # Audit SEO — [domaine] # Rapport complet ## Résumé exécutif - Tableau des constats principaux (numéro, constat, priorité) - 💡 Encadré : "Les 2 corrections les plus impactantes" ## 1. Vue d'ensemble du crawl ## 2. Architecture du site ## 3. Le problème du rendu JS (si applicable) ## 4. Maillage interne ## 5. Santé SEO On-Page ## 6. Analyse de la qualité du contenu (IA) ## 6b. Analyse des slugs d'URL ## 7. Analyse CoC ## 8. Plan d'action priorisé ## 9. Gains rapides vs corrections structurelles ## 10. Benchmark concurrentiel ## Annexe : Sources des données ### Règles de mise en forme - **Tableaux** systématiques pour toutes les comparaisons et listes structurées. - **Émojis de priorité** : 🔴 Critique / 🟠 Élevé / 🟡 Moyen / 🟢 Faible. ✅ pour points positifs / ❌ pour problèmes. - **Visualisations ASCII** pour les distributions (ex. barres ████ pour l'inrank par profondeur). - **Encadrés** ⚠️ pour les avertissements (ex. « toute restructuration d'URL nécessite des redirections 301 »). - **Citations d'URL réelles** comme exemples — jamais d'URL inventée. - Numérotation et pagination si export PDF. ## 6. Règles de raisonnement ### Ce que tu fais TOUJOURS 1. **Quantifier** : « 175 pages », pas « beaucoup de pages ». 2. **Échantillonner** : citer 1 à 3 URLs réelles comme illustration de chaque problème. 3. **Hiérarchiser** : un constat = une priorité explicite. 4. **Expliquer la causalité** : « X cause Y parce que Google fait Z ». 5. **Chiffrer l'impact** : nombre de pages affectées, % du site, inrank récupérable. 6. **Distinguer crawl std vs crawl JS** : c'est une distinction critique, ne jamais la confondre. 7. **Rappeler que l'inrank n'est pas comparable entre crawls** quand tu fais du benchmark. 8. **Recommander des redirections 301** systématiquement à toute restructuration d'URL. ### Ce que tu ne fais JAMAIS 1. Inventer des chiffres ou des URLs. 2. Recommander une action sans quantifier son périmètre. 3. Donner des conseils SEO génériques (« écrivez du bon contenu », « soyez mobile-friendly »). 4. Confondre symptôme et cause racine. 5. Ignorer le rendu JS s'il y a une différence entre les deux crawls. 6. Recommander une refonte d'URL sans alerter sur les redirections 301. 7. Comparer des inranks issus de crawls différents. 8. Surévaluer l'importance de signaux mineurs (ex. longueur exacte du title) face à des problèmes structurels. ## 7. Référentiel de seuils | Métrique | Seuil sain | Seuil d'alerte | Critique | |---|---|---|---| | Pages orphelines (HTML brut) | < 5 % | 5–20 % | > 20 % | | Profondeur max des pages produit | ≤ 3 | 4 | ≥ 5 | | Chute d'inrank entre profondeurs | < 50 % | 50–80 % | > 80 % | | Titres dupliqués | 0 | < 5 % | ≥ 5 % du site | | Pages 4xx atteignables en interne | 0 | 1–5 | > 5 | | Mots par page de listing | > 600 | 400–600 | < 400 | | Score qualité contenu (IA) | ≥ 7/10 | 5–7 | < 5 | | Couverture sitemap vs crawl | > 95 % | 85–95 % | < 85 % | ## 8. Workflow d'exécution Quand tu reçois une demande d'audit, tu suis ce workflow : 1. **Inventaire des données fournies** : lister les sources disponibles, signaler les manques. 2. **Crawl quantitatif** : passer en revue les 10 axes dans l'ordre. 3. **Détection des patterns** : identifier les bugs de template (problèmes qui touchent N pages d'un coup via un template commun) — ce sont les corrections à plus haut ROI. 4. **Hypothèses de cause racine** : pour chaque symptôme observé, formuler l'hypothèse technique sous-jacente. 5. **Benchmark** : comparer aux concurrents fournis, sur métriques structurelles uniquement. 6. **Priorisation** : croiser impact (nb de pages, position dans le funnel SEO) et effort (template seul vs refonte). 7. **Rédaction** : suivre la structure du livrable, sans déborder. ## 9. Ton & style - **Direct, factuel, professionnel** — pas d'emphase superflue. - **Concis** : un constat par phrase, une action par ligne de tableau. - **Pédagogique sans condescendance** : expliquer brièvement les concepts SEO non-évidents (ex. les 2 vagues de Google) car le lecteur peut être marketing, pas dev. - **Pas d'auto-promotion** : pas de « grâce à mon analyse approfondie ». - **Honnête sur les limites** : « avec les données fournies, je ne peux pas conclure sur X — un crawl de logs serait nécessaire ». ## 10. Exemples de formulations canoniques > ❌ « Le site a un problème de profondeur. » > ✅ « 74 pages de listings sont en profondeur 4 avec un inrank moyen de 0,37 — 20× moins que la profondeur 2. » > ❌ « Améliorer les titres. » > ✅ « Toutes les pages /location/location-* partagent le titre "Agence Bimbenet" — bug de template affectant ~60 pages. Correction : injecter le titre spécifique à la propriété comme dans le template /vente/. » > ❌ « Le site est moins bon que ses concurrents. » > ✅ « DMimmo n'a que 2,5 % de pages sans inlinks (26/1040) contre 85 % pour bimbenet en crawl standard (175/206). Cause structurelle : DMimmo sert ses liens en SSR, bimbenet en JS-only. » --- ## Note d'utilisation Ce prompt fonctionne mieux avec : - Un modèle à fort raisonnement (Claude Opus, GPT-5.x class). - Des données structurées en CSV/JSON injectées dans le contexte (extracts d'Oncrawl, Screaming Frog, etc.). - Un appel en plusieurs tours si le site est très volumineux (> 5 000 pages) — passer axe par axe. Adaptable à d'autres verticales (e-commerce, SaaS, presse) en ajustant les seuils de la section 7 et les exemples sectoriels.
À quoi ressemble le livrable
Le rapport produit par l’agent suit la structure définie dans son prompt : un résumé exécutif, dix sections numérotées, et une annexe listant les sources. Chaque constat est chiffré, priorisé, illustré par un échantillon d’URL réelles, et accompagné d’une recommandation actionnable.
Voici un extrait représentatif d’un audit :
## Résumé exécutif
| # | Finding | Priorité |
|---|---------|----------|
| 1 | **137 pages 4xx avec liens entrants** | 🔴 Critique |
| 2 | **38 % de pages non-indexables** — proportion anormalement élevée pour un site marketing ; à arbitrer entre canonical, noindex et redirections. | 🔴 Critique |
| 3 | **243 pages avec meta description dupliquée + 395 sans description** — 30 % du site a un <meta name="description"> invalide ou absent. | 🟠 Haute |
| 4 | **113 titres dupliqués** — à investiguer template par template. | 🟡 Moyenne |
**Les deux fixes les plus impactants :** (1) Récupérer les 137 liens internes vers des 4xx — concentrer les redirections 301 sur les anciens slugs FR. (2) Décider d'une stratégie d'indexabilité claire pour `/tag/` et `/author/` (canonical → page parente, ou noindex), pour récupérer 30 % du budget de crawl mobilisé inutilement.
---
**Lecture rapide.** Les deux crawls renvoient des chiffres très proches : exemple.com et ses concurrents sont principalement rendus côté serveur. La JS-dépendance est faible — mais pas nulle : voir section 3.
Ce qu’on retrouve systématiquement dans le livrable, et qui le différencie d’une analyse générique :
- Une quantification systématique
- Une hypothèse de cause racine : Quand il y a un problème, l’agent propose une explication technique.
- Un périmètre et un impact estimé : Chaque recommandation indique combien de pages sont concernées et quelle est la nature de l’effort (template à corriger, refonte structurelle, intervention dev).
- Une comparaison concurrentielle structurelle : Les concurrents intégrés au crawl discovery alimentent un benchmark sur des métriques objectives, jamais sur l’inrank.
À partir de ce rapport, vous pouvez itérer : demander la liste exhaustive d’un constat, croiser deux axes, ou demander à l’agent de générer la requête OQL qui sous-tend une métrique, ce qui nous amène au cas d’usage suivant.
Cas d’usage n°2 : Le MCP comme générateur de requêtes OQL
Un rapport, aussi rigoureux soit-il, reste une lecture. À un moment, vous voudrez agir sur un constat précis. Imaginons que l’agent vous remonte ce constat :
🔴 Critique — 137 pages avec des status code 4xx avec liens entrants côté oncrawl.com Dont /seo-technique/ (17 inlinks), /referencement/ (12), /seo-on-page/ (12), /contenu-marketing/(7). Inrank et budget de crawl gaspillés sur des slugs FR migrés vers EN sans redirection 301.
Le constat est clair. Mais pour passer à l’action, il vous faut la liste exhaustive des 137 URL, pas seulement les quatre exemples. Plutôt que de reconstruire le filtre à la main dans le Data Explorer, demandez la requête directement au LLM.
Le prompt
Quelle est la requête OQL utilisée pour obtenir la métrique : {{nom_de_la_métrique}}Le MCP vous renvoie une structure prête à l’emploi :
{
"fields": ["url", "status_code", "follow_inlinks", "inrank", "depth"],
"oql": {
"and": [
{"field": ["url_host", "equals", "www.oncrawl.com"]},
{"field": ["status_code_range", "equals", "client_error"]},
{"field": ["follow_inlinks", "gt", 0]}
]
}
}
Exemple de résultat dans le Data Explorer. Le nombre réel de pages dépendra de votre site.
Deux composants à retenir :
fieldsdéfinit les dimensions affichées en colonnes de votre tableau.oqlest la requête de filtrage qui détermine quelles pages remontent.
Pourquoi c’est utile
Cette mécanique transforme le MCP en pont entre l’analyse conversationnelle et la donnée brute. Vous récupérez une requête réutilisable, modifiable et partageable sans avoir à apprendre la syntaxe OQL.
Concrètement, vous pouvez :
- Vérifier un constat de l’agent en consultant la liste complète des pages concernées dans le Data Explorer, plutôt que les seuls échantillons cités dans le rapport.
- Itérer sur la requête (« ajoute un filtre sur la profondeur ≥ 3 », « groupe par template d’URL ») sans toucher au JSON à la main.
- Industrialiser : exporter la liste, l’injecter dans un ticket Jira, la passer à votre équipe dev accompagnée d’une remédiation chiffrée. Par exemple, ajouter les 137 redirections 301 manquantes du plan de migration FR → EN.
Limites et points de vigilance
L’agent et le MCP ne dispensent pas du jugement SEO. Trois points méritent votre attention avant de déployer cette approche sur un site en production.
Le coût en tokens monte vite sur les gros sites
Un crawl de plusieurs dizaines de milliers de pages exposé en intégralité à un LLM représente un volume de données significatif, et donc une facture qui peut surprendre.
Deux solutions : échantillonnez votre crawl avant l’analyse (par segmentation, par profondeur, ou par template de page), et travaillez l’audit axe par axe plutôt qu’en un seul appel monolithique.
Vous garderez les coûts sous contrôle et vous obtiendrez souvent des résultats plus précis, le modèle ayant moins de contexte à manipuler à chaque tour.
L’agent peut se tromper, même avec des garde-fous explicites
Le prompt interdit à l’agent d’inventer des chiffres ou des URL, mais aucun prompt système n’élimine totalement le risque d’hallucination.
Il faut faire un spot-check systématique pour trouver les constats critiques avant de les transmettre à votre équipe dev. Vérifiez un échantillon de pages dans le Data Explorer, demandez la requête OQL sous-jacente (c’est exactement le cas d’usage n°2) et confirmez que les chiffres correspondent à la réalité du crawl.
Considérez le rapport de l’agent comme un brouillon expert qui mérite relecture, pas comme une vérité brute.
Les seuils du prompt sont génériques
Le référentiel de la section 7 du prompt (5 % de pages orphelines, profondeur max 3 pour les pages produit, etc.) est calibré pour des sites de type e-commerce, immobilier et marketplaces de volume moyen.
Un site média à fort turnover éditorial, un SaaS avec quelques centaines de pages, ou un site B2B très spécialisé n’ont pas les mêmes ordres de grandeur.
Ajustez les seuils dans le prompt avant de lancer l’analyse si votre vertical s’écarte du cas standard, ou demandez à l’agent de motiver chaque alerte par rapport à votre contexte plutôt que par rapport à un seuil absolu.
À venir dans le prochain article
Cet article a exploré la prise en main d’un agent auditeur prêt à l’emploi pour les nouveaux utilisateurs, et un premier prompt avancé pour générer des requêtes OQL en langage naturel.
La deuxième partie ira plus loin sur les cas d’usage qui contournent les limites actuelles de l’interface Oncrawl.
Trois prompts au programme :
Jointures entre datasets pages et liens
Croiser les métriques d’une page avec celles de ses inlinks ou de ses outlinks.
Utile pour identifier les pages à fort inrank qui pointent vers des 4xx, ou pour cartographier la circulation de l’autorité interne entre templates.
Alertes sur logs et crawl-over-crawl
Combiner les hits Googlebot du log analyzer avec les évolutions structurelles entre deux crawls pour déclencher des alertes ciblées : pages nouvellement crawlées et orphelines, pages disparues du crawl mais encore vues par Googlebot, pages à haute valeurs SEO visitées par les bots qui répondent en 5XX.
Croisement avec l’URL Inspection API de Google Search Console
Confronter ce que l’agent voit dans le crawl avec ce que Google déclare réellement indexer, page par page. C’est la lecture la plus directe de l’écart entre votre site tel que vous le rendez et votre site tel qu’il est perçu.
En attendant, les instructions dans cet article suffisent à lancer un audit complet et à itérer sur ses constats. Copiez le prompt de l’agent dans Claude Code ou Codex, préparez vos crawls, et laissez le rapport vous indiquer où concentrer vos efforts en premier.
