
Fixer des objectifs et évaluer les réalisations dans le temps est un exercice très intéressant pour comprendre ce que nous sommes capables de réaliser et si la stratégie que nous utilisons est efficace ou non. Cependant, il n’est généralement pas si facile de fixer ces objectifs car nous devons d’abord établir une prévision.
Faire une prédiction n’est pas chose facile, mais grâce à certaines procédures de prévision disponibles, à notre unité centrale et à certaines compétences en matière de programmation, nous pouvons réduire considérablement sa complexité. Dans cet article, je vais vous montrer comment nous pouvons faire des prévisions précises et comment vous pouvez appliquer cela au SEO en utilisant Python et la bibliothèque Prophet (et sans avoir à disposer de super pouvoirs de voyance!).
Si vous n’avez jamais entendu parler de Prophet, vous vous demandez peut-être ce que c’est. En bref, Prophet est une procédure de prévision publiée par l’équipe Core Data Science de Facebook, disponible en Python et en R et qui traite très bien les valeurs aberrantes et les effets saisonniers pour fournir des prévisions précises et rapides.
Lorsque nous parlons de prévisions, nous devons prendre en considération deux choses :
- Plus nous disposons de données historiques, plus notre modèle et donc nos prévisions seront précis.
- Le modèle de prévision ne sera valable que si les facteurs internes restent les mêmes et qu’aucun facteur externe ne l’affecte. Cela signifie que si, par exemple, nous avons publié un article par semaine et que nous commençons à en publier deux par semaine, ce modèle pourrait ne pas être valable pour prédire le résultat de ce changement de stratégie. D’autre part, s’il y a une mise à jour de l’algorithme, le modèle pourrait ne pas être valide non plus. N’oubliez pas que le modèle est construit sur la base de données historiques.
Pour l’appliquer au SEO, nous allons prévoir les sessions SEO pour le mois à venir, après les prochaines étapes :
- Obtenir des données de Google Analytics sur les sessions organiques pour une période spécifique.
- Formation de notre modèle.
- Prévision du trafic SEO pour le mois à venir.
- Évaluer la qualité de notre modèle avec l’erreur moyenne absolue.
Vous voulez en savoir plus sur le fonctionnement de cette procédure de prévision ? Alors, commençons !
Obtenir les données de Google Analytics
Nous pouvons aborder l’extraction des données de Google Analytics de deux manières : en exportant un fichier Excel à partir de l’interface normale ou en utilisant l’API pour récupérer ces données.
Importation des données d’un fichier Excel
La façon la plus simple d’obtenir ces données de Google Analytics est d’aller dans la section Canaux de la barre latérale, de cliquer sur Organique et d’exporter les données avec le bouton qui se trouve en haut de la page. Assurez-vous que vous sélectionnez dans le menu déroulant en haut du graphique la variable que vous souhaitez analyser, dans ce cas-ci Sessions.
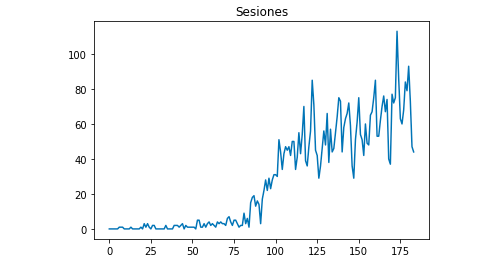
Après avoir exporté les données sous forme de fichier Excel, nous pouvons les importer dans notre carnet avec Pandas. Notez que le fichier Excel contenant ces données contiendra différents onglets, de sorte que l’onglet avec le trafic mensuel doit être spécifié comme un argument dans le morceau de code qui se trouve ci-dessous. Nous effaçons également la dernière ligne car elle contient le nombre total de sessions, ce qui fausserait notre modèle.
import pandas as pd
df = pd.read_excel ('.xlsx', nom_de_la_feuille="")
df = df.drop(len(df) - 1)Nous pouvons dessiner avec Matplotlib à quoi ressemblent les données :
from matplotlib import pyplot df["Sesiones"].plot(title = "Sesiones") pyplot.show()
Utilisation de l’API Google Analytics
Tout d’abord, afin d’utiliser l’API Google Analytics, nous devons créer un projet sur la console de développement de Google, activer le service Google Analytics Reporting et obtenir les informations d’identification. Jean-Christophe Chouinard explique très bien dans cet article comment le mettre en place.
Une fois les informations d’identification obtenues, nous devons nous authentifier avant de faire notre demande. L’authentification doit être faite avec le fichier d’identification qui a été obtenu initialement à partir de la console de développement de Google. Nous devrons également noter dans notre code l’identifiant GA View de la propriété que nous souhaitons utiliser.
from apiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
VIEW_ID = ''
credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', credentials=credentials)Après l’authentification, il suffit de faire la demande. Celle que nous devons utiliser pour obtenir les données sur les séances de bio pour chaque jour est :
response = analytics.reports().batchGet(body={
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'metrics': [
{"expression": "ga:sessions"}
], "dimensions": [
{"name": "ga:date"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "true"
}]}).execute()Notez que nous sélectionnons la plage de temps dans les DateRanges. Dans mon cas, je vais récupérer les données du 1er septembre au 31 janvier :
[{"startDate" : "2020-09-01", "endDate" : "2021-01-31"}]Il suffit ensuite d’aller chercher le fichier de réponse pour ajouter à une liste les jours avec leurs sessions organiques :
list_values = []
for x in response["reports"][0]["data"]["rows"]:
list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])Comme vous pouvez le voir, l’utilisation de l’API Google Analytics est assez simple et peut être utilisée pour de nombreux objectifs. Dans cet article, j’ai expliqué comment vous pouvez utiliser l’API Google Analytics pour créer des alertes afin de détecter les pages peu performantes.
Adaptation des listes aux Dataframes
Pour utiliser Prophet, nous devons entrer une Dataframe avec deux colonnes qui doivent être nommées : « ds » et « y ». Si vous avez importé les données d’un fichier Excel, nous l’avons déjà en tant que Dataframe, vous n’aurez donc qu’à nommer les colonnes « ds » et « y » :
df.columns = ['ds', 'y']
Si vous avez utilisé l’API pour récupérer les données, nous devons alors transformer la liste en un cadre de données et nommer les colonnes selon les besoins :
from pandas import DataFrame df_sessions = DataFrame(list_values,columns=['ds', 'y'])
Formation du modèle
Une fois que nous disposons de la Dataframe au format requis, nous pouvons déterminer et entraîner notre modèle très facilement avec :
import fbprophet de fbprophet import Prophet model = Prophet() model.fit(df_sessions)
Faire des prévisions
Enfin, après avoir formé notre modèle, nous pouvons commencer à faire des prévisions ! Afin de procéder aux prévisions, nous devons d’abord créer une liste avec la plage de temps que nous souhaitons prévoir et ajuster le format date-heure :
from pandas import to_datetime
forecast_days = []
for x in range(1, 28):
date = "2021-02-" + str(x)
forecast_days.append([date])
forecast_days = DataFrame(forecast_days)
forecast_days.columns = ['ds']
forecast_days['ds']= to_datetime(forecast_days['ds'])Dans cet exemple, j’utilise une boucle qui va créer une trame de données qui contiendra tous les jours de février. Il s’agit maintenant d’utiliser le modèle qui a été formé précédemment :
forecast = model.predict(forecast_days)
Nous pouvons dessiner une intrigue mettant en évidence la période de temps prévue :
from matplotlib import pyplot model.plot(forecast) pyplot.show()
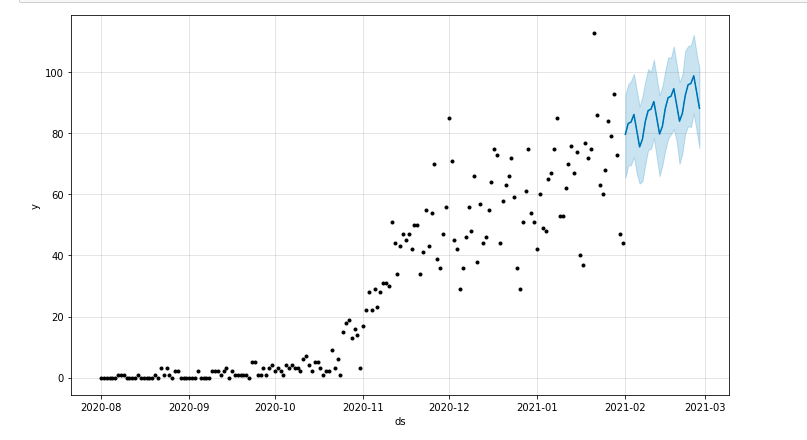
Évaluation du modèle
Enfin, nous pouvons évaluer la précision de notre modèle en éliminant certains jours des données utilisées pour former le modèle, en prévoyant les sessions pour ces jours et en calculant l’erreur moyenne absolue.
Par exemple, je vais éliminer de la base de données originale les 12 derniers jours de janvier, en prévoyant les sessions pour chaque jour et en comparant le trafic réel avec le trafic prévu.
Nous commençons par éliminer de la base de données initiale les 12 derniers jours avec pop et nous créons une nouvelle base de données qui n’inclut que les 12 jours qui seront utilisés pour la prévision :
train = df_sessions.drop(df_sessions.index[-12 :]) future = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]]
Maintenant, nous entraînons le modèle, nous faisons la prévision et nous calculons l’erreur moyenne absolue. À la fin, nous pouvons tracer un graphique qui montrera la différence entre les valeurs prévues et les valeurs réelles. C’est ce que j’ai appris dans cet article écrit par Jason Brownlee.
from sklearn.metrics import mean_absolute_error
import numpy as np
from numpy import array
#Nous formons le modèle
model = Prophet()
model.fit(train)
#Adapter le cadre de données utilisé pour les jours de prévision au format requis par Prophet.
future = list(future)
future = DataFrame(future)
future = future.rename(columns={0 : 'ds'})
# Nous faisons la prévision
forecast = model.predict(future)
# Nous calculons l'EAM entre les valeurs réelles et les valeurs prédites
y_true = df_sessions['y'][-12 :].values
y_pred = forecast['yhat'].values
mae = erreur_absolue_moyenne(y_true, y_pred)
# Nous traçons le résultat final pour une compréhension visuelle
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label="Actual")
pyplot.plot(y_pred, label='Predicted')
pyplot.legend()
pyplot.show()
print(mae)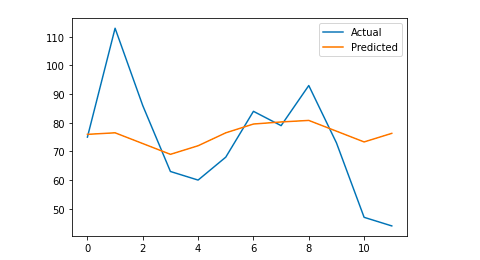
Mon erreur absolue moyenne est de 13, ce qui signifie que mon modèle prévisionnel attribue à chaque jour 13 sessions de plus que les sessions réelles, ce qui semble être une erreur acceptable.
C’est tout ! J’espère que vous avez trouvé cet article intéressant et que vous pouvez commencer à faire vos prévisions SEO afin de fixer des objectifs.
