
Note de la rédaction : cet article a été mis à jour afin de refléter les dernières évolutions de Google Search et les meilleures pratiques en matière de SEO.
L’indexation sémantique latente (LSI) fait depuis longtemps l’objet d’un débat parmi les spécialistes du search. Si vous recherchez sur Google le terme « facteur de positionnement de l’indexation sémantique latente », vous trouverez à la fois des partisans et des sceptiques.
Cependant, en 2025, un consensus plus clair se dégage : si la LSI est une technique réelle dans le traitement du langage naturel, Google a clairement indiqué qu’il ne l’avait jamais utilisée pour le positionnement des recherches.
Ce concept reste utile pour comprendre le fonctionnement du langage et du sens, mais il ne doit pas être confondu avec un élément actif de l’algorithme de Google. Si vous n’êtes pas familier avec ce concept, cet article résume l’histoire et le débat sur la LSI afin que vous puissiez comprendre ce qu’elle signifie pour votre stratégie de SEO.
Qu’est-ce que l’indexation sémantique latente ?
LSI est un processus que l’on retrouve dans le traitement du langage naturel (NLP). Le NLP est un sous-ensemble de la linguistique et de l’ingénierie de l’information, qui se concentre sur la façon dont les machines interprètent le langage humain. La sémantique distributionnelle est un élément clé de cette étude. Ce modèle nous aide à comprendre et à classer des mots ayant des significations contextuelles similaires au sein de grands ensembles de données.
Développé dans les années 1980, le LSI utilise une méthode mathématique qui rend la recherche d’informations plus précise. Cette méthode fonctionne en identifiant les relations contextuelles cachées entre les mots. Elle peut vous aider à la décomposer de cette manière :
- Latent → Caché
- Sémantique → Relations entre les mots
- Indexation → Recherche d’informations
[Étude de cas] Stimuler la croissance sur de nouveaux marchés grâce au SEO on-page

Comment fonctionne l’indexation sémantique latente ?
LSI fonctionne en utilisant l’application partielle de la Décomposition en valeurs singulières (DVS). La DVS est une opération mathématique qui réduit une matrice à ses parties constitutives pour des calculs simples et efficaces.
Lors de l’analyse d’une chaîne de mots, LSI supprime les conjonctions, les pronoms et les verbes courants, également appelés « stop words ». Cela permet d’isoler les mots qui constituent le « contenu » principal d’une phrase. Voici un exemple rapide de ce que cela peut donner :

Ces mots sont ensuite placés dans une Matrice de documents terminologiques (TDM en anglais). Une TDM est une grille 2D qui répertorie la fréquence à laquelle chaque mot (ou terme) spécifique apparaît dans les documents d’un ensemble de données. Des fonctions de “pesage” sont ensuite appliquées à la TDM. Un exemple simple consiste à classer tous les documents qui contiennent le mot avec une valeur de 1 et tous ceux qui ne le contiennent pas avec une valeur de 0. Lorsque des mots apparaissent avec la même fréquence générale dans ces documents, on parle de co-occurrence. Vous trouverez ci-dessous un exemple de base de TDM, et la façon dont il évalue la co-occurrence dans plusieurs phrases :
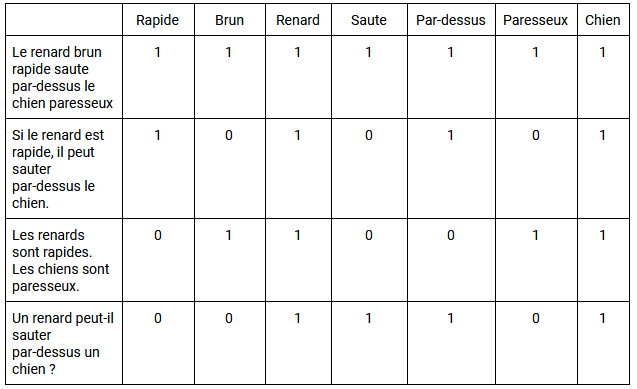
L’utilisation de l’SVD nous permet d’approcher les modèles d’utilisation des mots dans tous les documents. Les vecteurs SVD produits par LSI permettent de prédire le sens avec plus de précision que l’analyse des termes individuels. En fin de compte, LSI peut utiliser les relations entre les mots pour mieux comprendre leur sens, ou leur signification, dans un contexte spécifique.
Comment l’indexation sémantique latente s’est-elle retrouvée impliquée dans le SEO ?
Dans ses années de formation, Google a découvert que les moteurs de recherche pouvaient classer les sites web en fonction de la fréquence d’un mot-clé particulier. Cependant, cela ne garantit pas le résultat de recherche le plus pertinent. Google a donc commencé à classer des sites web qu’il considérait comme “de confiance” en matière d’information.
Au fil du temps, les algorithmes de Google ont permis de filtrer avec une plus grande précision les sites web de mauvaise qualité et non pertinents. Par conséquent, les spécialistes du marketing doivent comprendre le sens d’une recherche, au lieu de se fier aux mots exacts utilisés. C’est pourquoi Roger Montti a décrit LSI comme des « roues d’entraînement pour les moteurs de recherche ».
Au fil du temps, les algorithmes de Google ont filtré avec une plus grande précision les sites web de faible qualité et non pertinents. Les spécialistes du marketing ont donc compris qu’ils devaient comprendre le sens d’une recherche, plutôt que de se fier uniquement aux mots exacts utilisés. C’est pourquoi Roger Montti a un jour décrit le LSI comme « des roulettes pour les moteurs de recherche » dans un article sur les croyances obsolètes en matière de SEO, ajoutant que le LSI n’avait « que peu ou pas de pertinence pour la façon dont les moteurs de recherche positionnent les sites web aujourd’hui ».
Depuis lors, des représentants de Google tels que John Mueller et Gary Illyes ont clairement indiqué que Google n’utilisait pas le LSI.
La signification d’une requête de recherche est étroitement liée à l’intention qui la sous-tend. Google tient à jour un document intitulé « Search Quality Evaluator Guidelines » (Directives pour l’évaluation de la qualité de la recherche). Dans les versions précédentes, quatre catégories utiles ont été introduites pour définir l’intention de l’utilisateur :
- Know Query – Il s’agit de la recherche d’informations sur un sujet. Une variante de cette méthode est la requête « Know Simple », qui permet aux utilisateurs d’effectuer une recherche en ayant une réponse particulière à l’esprit.
- Do Query – Elle reflète le désir de s’engager dans une activité particulière, telle qu’un achat en ligne ou un téléchargement. Toutes ces requêtes peuvent être définies par un sens d’interaction
- Website Query – C’est lorsque les utilisateurs recherchent un site ou une page spécifique. Ces recherches indiquent une connaissance préalable d’un site web ou d’une marque particulière.
- Visit-in-Person Query – L’utilisateur recherche un lieu physique, tel qu’un magasin de briques et mortier ou un restaurant.
Ces catégories restent utiles, mais il est important de noter que Google a mis à jour ses directives à plusieurs reprises au fil des ans. Aujourd’hui, les évaluateurs examinent des formes plus nuancées d’intention et attribuent des notes en fonction des « besoins satisfaits ». Les spécialistes du marketing doivent toujours consulter la dernière version des directives pour obtenir des informations à jour.
Les principes fondamentaux de LSI, qui consiste à définir le sens contextuel d’un mot au sein d’une phrase, a donné à Google un avantage concurrentiel. Cependant, l’idée s’est rapidement répandue que les « mots-clés LSI » constituaient soudainement la clé du succès pour le SEO.
[Étude de cas] Améliorer les classements, visites organiques et ventes avec l’analyse des fichiers de log
Les « mots-clés LSI » existent-ils vraiment ?
De nombreuses publications continuent de préconiser l’utilisation des mots-clés LSI ; cependant, plusieurs sources, dont des représentants de Google, affirment régulièrement qu’il s’agit d’un mythe. Ces sources avancent plusieurs raisons :
- LSI a été développé avant le World Wide Web et n’était pas destiné à être appliqué à un ensemble de données aussi vaste et dynamique.
- Le brevet américain sur l’indexation sémantique latente, accordé à Bell Communications Research Inc. en 1989, a expiré en 2008. Selon feu Bill Slawski, l’utilisation de la LSI par Google s’apparenterait à « l’utilisation d’un télégraphe intelligent pour se connecter à l’Internet mobile ».
- Google a introduit des systèmes de la machine learning tels que RankBrain, qui transforment des volumes de texte en « vecteurs », des entités mathématiques qui aident les ordinateurs à comprendre le langage écrit. RankBrain a adapté le Web à un ensemble de données en constante expansion, ce que le LSI ne pouvait pas gérer. Aujourd’hui, RankBrain n’est plus considéré comme un système distinct, ayant été intégré à des modèles plus récents.
En fin de compte, le LSI démontre une vérité à laquelle les spécialistes du marketing devraient adhérer : explorer le contexte unique d’un mot nous aide à mieux comprendre l’intention de l’utilisateur que les mots-clés insérés dans le contenu. Cependant, cela ne confirme pas que Google positionne les résultats en fonction du LSI. Il est peut-être préférable de considérer le LSI comme une philosophie plutôt que comme une science exacte.
Pour revenir à la citation de Roger Montti qui qualifie le LSI de « roues d’entraînement pour les moteurs de recherche », nous pouvons désormais affirmer que Google a depuis longtemps retiré ces roues d’entraînement. En réalité, Google a développé des systèmes d’IA bien plus avancés.
En 2019, Pandu Nayak, vice-président de la recherche, a annoncé que Google avait commencé à utiliser un système d’IA appelé BERT (Bidirectional Encoder Representations from Transformers). Il s’agissait de l’une des plus importantes mises à jour algorithmiques de l’époque, touchant plus de 10 % de toutes les requêtes de recherche.
Lors de l’analyse d’une requête de recherche, BERT considère un seul mot par rapport à tous les mots de cette phrase. Cette analyse est bidirectionnelle, en ce sens qu’elle considère tous les mots précédant ou suivant un mot spécifique. La suppression d’un seul mot pourrait avoir un impact considérable sur la façon dont BERT comprend le contexte unique d’une phrase.
Cela contraste avec LSI, qui omet tout mot d’arrêt dans son analyse. L’exemple ci-dessous montre comment la suppression des mots d’arrêt peut modifier la façon dont nous comprenons une phrase :
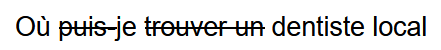
Bien qu’il s’agisse d’un mot d’arrêt, « trouver » est le point central de la recherche, que nous définirions comme une requête « visite en personne ».
[Étude de cas] Améliorer les classements, visites organiques et ventes avec l’analyse des fichiers de log
Depuis BERT, Google a encore progressé avec l’introduction de MUM (Multitask Unified Model) en 2021, qui aide la recherche à comprendre et à relier des informations dans différentes langues et différents formats, et AI Overviews en 2024, qui génère des résumés contextuels directement dans les résultats de recherche.
Ces mises à jour soulignent que Google ne se concentre plus uniquement sur les mots-clés, mais sur une compréhension sémantique et contextuelle plus approfondie des informations.
Que doivent donc faire les spécialistes du marketing ?
Au départ, on pensait que le LSI pouvait aider Google à associer le contenu aux requêtes pertinentes. Cependant, nous savons désormais que Google n’utilise pas le LSI et que le débat autour des « mots-clés LSI » repose sur un malentendu. Malgré cela, les spécialistes du marketing peuvent encore prendre de nombreuses mesures pour s’assurer que leur travail reste stratégiquement pertinent.
Les articles, les textes web et les campagnes doivent être optimisés afin d’inclure des synonymes et des variantes. Cela permet de tenir compte des différentes façons dont des personnes ayant des intentions similaires utilisent le langage.
Mais surtout, les spécialistes du marketing doivent continuer à rédiger avec autorité et clarté. C’est une condition sine qua non s’ils souhaitent que leur contenu résolve un problème spécifique. Ce problème peut être un manque d’informations ou le besoin d’un produit ou d’un service particulier. En agissant ainsi, les spécialistes du marketing démontrent qu’ils comprennent véritablement l’intention des utilisateurs.
Ils doivent également utiliser fréquemment les données structurées. Qu’il s’agisse d’un site web, d’une recette ou d’une FAQ, les données structurées fournissent à Google le contexte nécessaire pour donner un sens à ce qu’il crawl et sont de plus en plus importantes pour obtenir des résultats enrichis et pour les nouveaux aperçus IA.
Enfin, les stratégies de contenu doivent aujourd’hui tenir compte des consignes relatives au contenu utile de Google, qui soulignent l’importance d’un contenu axé sur l’humain, démontrant expertise, expérience, autorité et fiabilité.
En résumé, si le LSI reste un concept académique utile pour comprendre le langage, il ne fait pas partie des systèmes de positionnement de Google, mais cela n’a finalement pas beaucoup d’importance. Les spécialistes du marketing doivent se concentrer sur le SEO sémantique, le contenu axé sur l’intention et les développements modernes basés sur l’IA dans le domaine de la recherche.
