
L’impact du COVID-19 sur le secteur du voyage
Compte tenu de l’impact que le Covid-19 a eu jusqu’à présent sur le secteur du voyage, il est probable que de nombreux hôtels, hébergements et agences de voyage doivent faire face à de très graves problèmes opérationnels dans des circonstances assez exceptionnelles.
Il est probable que nombre d’entre eux sont également contraints d’adopter une vision à long terme pour une grande partie de leurs investissements dans le marketing, s’ils sont capables de survivre pendant cette période.
Il ne sert pas à grand-chose d’essayer d’attirer des clients lorsque les gens ne peuvent littéralement pas voyager et que la plupart des pays du monde sont dans une sorte d’isolement ou dans une situation de verrouillage imposé.
Je ne crois pas que *en ce moment* un investissement massif dans le référencement d’un hôtel soit un coût nécessaire. Je vois que d’autres dans l’industrie disent tout le contraire, mais je pense que c’est plutôt une décision opérationnelle qui doit être prise par l’entreprise.
Avec le temps, l’impact s’estompera bien sûr et très lentement, la vie reprendra une certaine forme de « normalité » (bien que des changements durables soient nécessaires) et les gens continueront à voyager et auront besoin d’un endroit où séjourner. Les vacances seront peut-être plus nécessaires que jamais, même si la confiance des consommateurs sera certainement ébranlée après ce qui s’est passé.
D’ici là, il est clair que les hôtels, les d’hébergement et les agences de voyage devront adopter une vision à long terme pour rester compétitifs. Pour moi, cela implique une certaine forme de SEO.
Ainsi, pour certaines entreprises, l’investissement dans l’optimisation des moteurs de recherche peut encore être la solution la plus rentable à leurs problèmes. Mais malheureusement, le référencement n’est peut-être pas la solution miracle que certaines entreprises un peu douteuses peuvent vous faire croire.
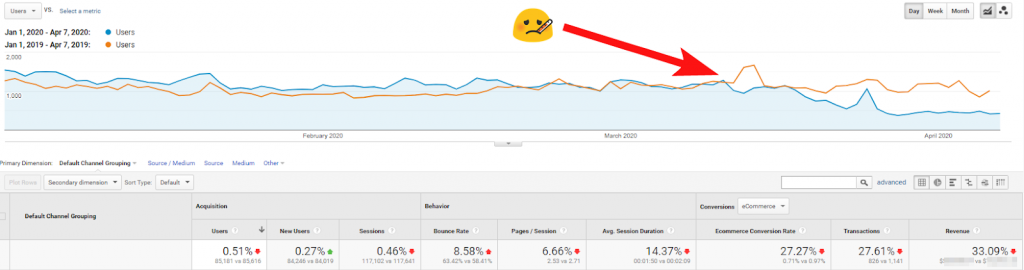
Capture d’écran montrant l’examen par YoY d’un hôtel de 300 chambres aux États-Unis – le trafic, les taux de conversion sont tous en forte baisse, montrant le dur impact de Covid-19 sur leur activité.
Règles SEO pour le secteur hôtelier
J’ai eu la chance de travailler jusqu’à présent au sein de quelques agences de voyage, réalisant des services SEO et de PPC pour de nombreux types d’hôtels dans le monde entier. D’après mon expérience, c’est un secteur assez différent dans lequel il faut travailler (mais là encore, tout le monde dit probablement la même chose de son propre secteur, ils semblent tous avoir leurs propres spécificités !)
Les hôtels ont normalement quelques exigences cohérentes de la part des canaux de recherche organique et payante : la génération de réservations dans leur hôtel étant la principale. D’autres objectifs supplémentaires peuvent inclure la location des salles de réunion ou de mariage.
Le principal point de friction d’un hôtel est lié aux agences de voyage en ligne (OTA), qui font un si bon travail en remplissant toutes les chambres d’un hôtel, qu’elles laissent souvent l’hôtel avec peu de chambres disponibles. Des sites comme Booking.com et Hotels.com prennent les disponibilités (chambres) d’un hôtel et les vendent directement au consommateur via leur propre site web et d’autres canaux, en prenant une bonne partie de la vente sous forme de commission.
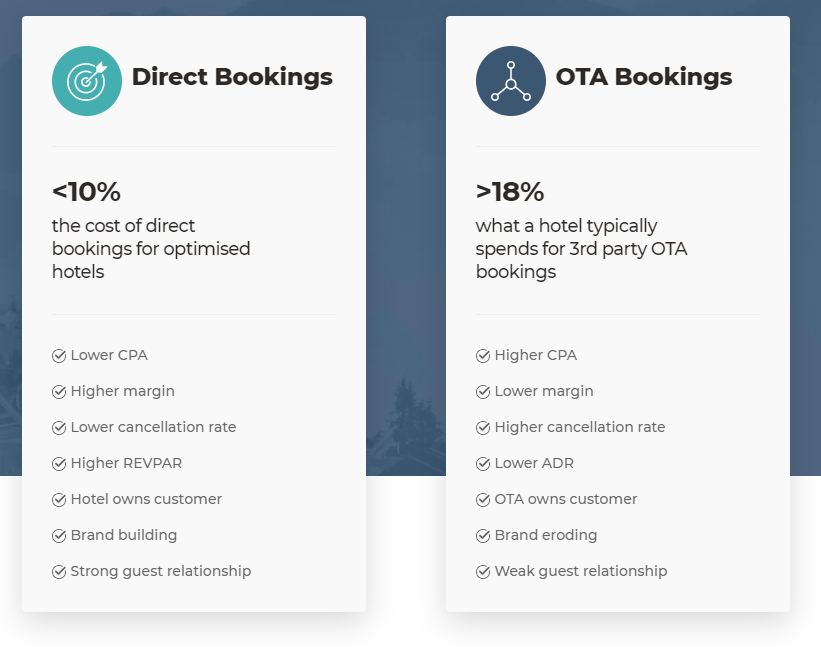
Un graphique du principal fournisseur de moteurs de réservation Bookassist, montrant la valeur de la chasse aux réservations directes par rapport à la vente par l’intermédiaire d’un OTA comme Booking.com.
Pour les hôtels, il est souvent bien plus avantageux de pouvoir vendre leurs chambres directement sur leur propre site web, où ils paient une commission bien moindre* (ou 0%) lorsqu’ils peuvent le faire, que de payer plus de 30% lorsqu’une chambre est vendue par l’intermédiaire d’un OTA.
Les hôtels veulent donc que les gens réservent directement auprès d’eux**, et pour ce faire, ils doivent amener davantage de personnes sur leur site web.
*Remarque : une petite commission peut être versée même lorsque la réservation est directe, car le fournisseur du moteur de réservation fait souvent payer aux hôtels un petit pourcentage qui sert à couvrir leurs propres frais de fonctionnement.
**Certains hôtels sont naturellement réticents à adopter cet état d’esprit – ils craignent qu’en se détournant des OTA, leurs revenus diminuent fortement. Ils craignent également de ne pas pouvoir commercialiser leur établissement suffisamment bien pour vendre les chambres requises chez eux – les OTA sont une option facile et sûre.
Si l’optimisation pour les moteurs de recherche ne représente pas souvent la plus grosse part du budget marketing des hôtels, surtout depuis les modifications apportées par Google aux SERPs qui renforcent la nécessité d’investir dans plusieurs produits Google Ads, cela ne signifie pas pour autant que le référencement doit être complètement négligé.
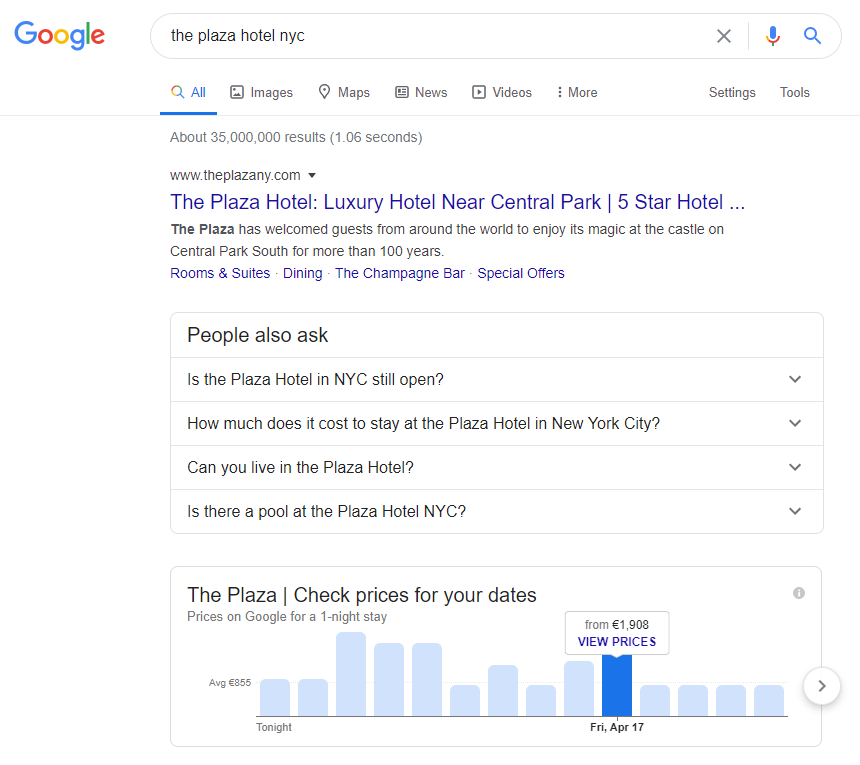
Affichage du vérificateur de tarifs généré par Google – encourageant les utilisateurs à entrer leurs dates ou à choisir le jour où les prix sont les plus bas pour cette propriété particulière (en cliquant sur un jour, vous accédez à une page Google Hotel Ads).
Facteurs clés SEO pour un site d’hôtel
Dans la plupart des hôtels avec lesquels j’ai travaillé, la recherche organique représente toujours la majeure partie du trafic et des revenus, représentant souvent environ 70 % de l’ensemble des réservations directes sur internet.
En ce moment, à cause du Covid-19, de nombreux hôtels se retirent entièrement de toute activité PPC, ce qui me semble logique. Pour ceux qui ont les moyens de maintenir une présence SEO ou qui peuvent la gérer en interne grâce aux ressources dont ils disposent, cet article pourrait les orienter dans la bonne direction.
En d’autres termes, en fonction de l’actualité mondiale, c’est peut-être l’occasion de faire le point et de réévaluer les performances de votre hôtel sur des moteurs comme Google, et d’essayer de prédire ce à quoi les prochains mois ressembleront.
À ce stade, vous pourriez commencer à vous poser les questions suivantes : « À quoi ressemble exactement une recherche de marque pour mon hôtel » (élément que je vais traiter par la suite) et « quels termes de recherche sans marque ont généré le plus de trafic et de réservations au cours des 12 derniers mois ? Et puis, comment pouvez-vous améliorer les résultats de la recherche de marque, et doubler les termes sans marque qui vous conviennent le mieux ?
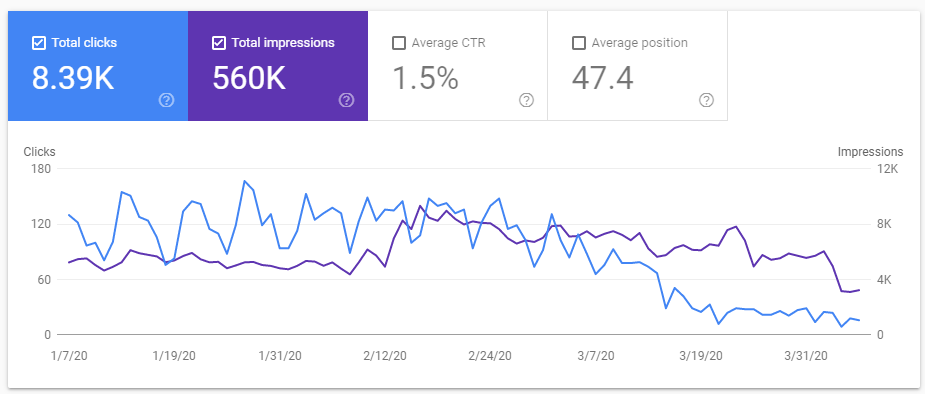
Triste mais pratiquement inévitable – la chute du trafic organique vers le site web d’un hôtel, d’après l’impact de Covid-19 sur le comportement de recherche des voyageurs.
SERPs de marque
L’évaluation de l’affichage des résultats de recherche (SERP) pour une requête d’hôtel de marque est une tâche simple que vous pouvez effectuer pour repérer tout problème sérieux (le plus important étant : le site web de mon hôtel est-il classé 1er ou non ?) et vérifier l’aspect de vos annonces de recherche PPC quand elles sont actives, car elles ne sont probablement pas visibles en ce moment à cause du Covid-19.
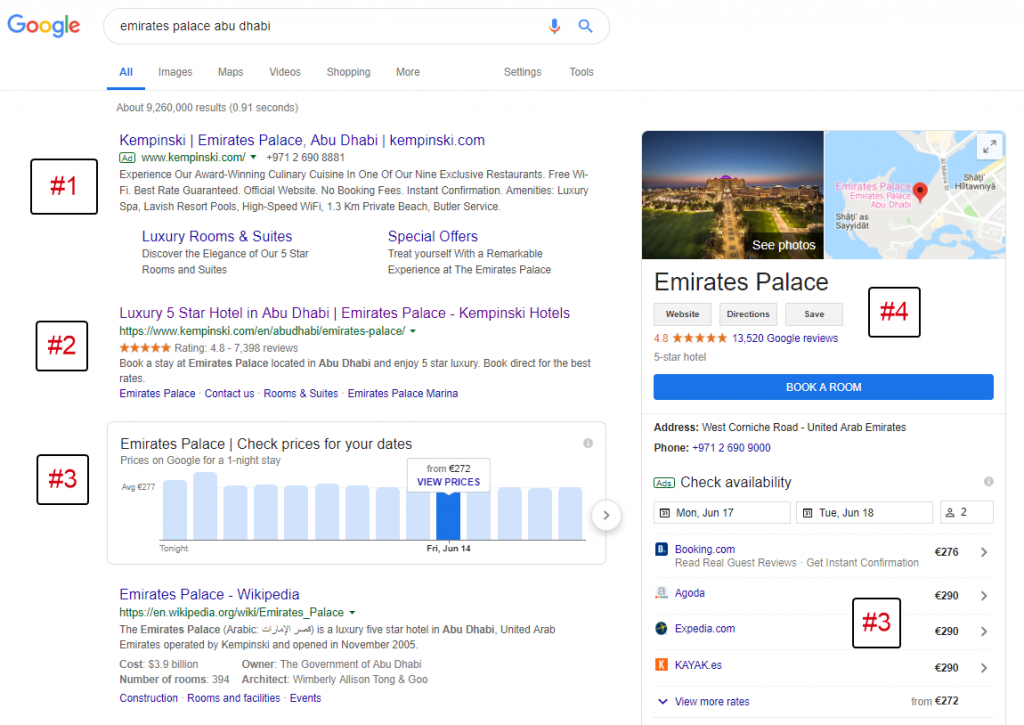
#1 : Annonces de recherche de marque diffusées par l’hôtel (Google Ads)
#2 : Liste de recherche organique appartenant à l’hôtel
#3 : Aperçu des tarifs et tarifs journaliers fournis – les tarifs de l’hôtel officiels ne sont pas affichés ici (Google Hotel Ads)
#4 : Informations sur les hôtels (Google My Business et autres sources)
Vous devez garder à l’esprit que le SERP de votre site web aura un aspect différent en fonction de nombreux facteurs, notamment :
- Localisation: des informations différentes peuvent être affichées en fonction de l’endroit où se trouve l’utilisateur.
- Support : les SERPs de marque sur mobile, tablette et ordinateur de bureau peuvent tous être très différents.
- Moteur de recherche : surtout si votre hôtel reçoit beaucoup de visites d’une région où Google n’a pas une part de marché aussi élevée, vous devriez vérifier à quoi ressemble votre SERP de marque dans les autres moteurs de recherche.
Crawlabilité de votre site
Les bots, que les moteurs de recherche utilisent pour trouver vos pages, découvrent tout le contenu disponible sur votre site en crawlant de page en page et en découvrant le contenu de toutes les URLs qu’ils peuvent trouver.
Vous devez vous assurer que votre site offre les bonnes informations aux bots pour constituer une excellente liste de SERP, des titres de page à la réparation de tout lien brisé. Vous devez également vous assurer que vos pages clés peuvent toutes être découvertes lors d’un crawl : si Google ne les trouve pas, vos clients non plus.
Utilisation des images et du contenu vidéo
L’image et la vidéo ont vraiment besoin d’une section à part entière ici, car elles sont essentielles pour les hôtels. Elles font une bonne impression sur tous les visiteurs de votre site, car le voyage est avant tout une expérience émotive ! Les images/vidéos sont bien sûr très visuelles !
Si vous ne voulez pas forcer tous vos visiteurs à regarder une longue vidéo d’introduction lorsqu’ils arrivent sur votre page d’accueil (surtout si le son est désactivé), vous pouvez néanmoins utiliser le contenu vidéo pour donner à votre site un véritable effet de surprise, ce qui est nécessaire si vous voulez que les gens se souviennent de votre hôtel.
N’oubliez pas de veiller à ce que votre site soit accessible à tous les utilisateurs, qu’ils utilisent de vieux navigateurs, des connexions lentes ou des aides visuelles comme des lecteurs d’écran.
Les données de la search console sur votre hôtel
Le rapport de performance de la console de recherche peut vous fournir une liste de mots-clés pour lesquels votre site est classé. Il s’agit des recherches Google que vos clients ont effectuées et qui ont abouties à l’affichage de votre site web en tant que résultat. Il s’agit d’informations essentielles que vous devez connaître et c’est le genre d’informations que votre agence/consultant en SEO doit partager et revoir régulièrement.
Identifiez les termes de recherche qui vous donnent une forte impression mais un faible nombre de clics, probablement en raison d’un classement moyen peu élevé.
Ce rapport vous permettra également de connaître l’état général de la notoriété de votre hôtel.
Filtrez par le nom de votre hôtel pour savoir combien de personnes recherchent votre nom de manière organique et découvrez ensuite comment cela se passe tout au long de l’année, ce qui servira à l’avenir de référence.
Vous pouvez même segmenter ces données par pays pour découvrir comment elles varient, ce qui peut être important pour le référencement international.
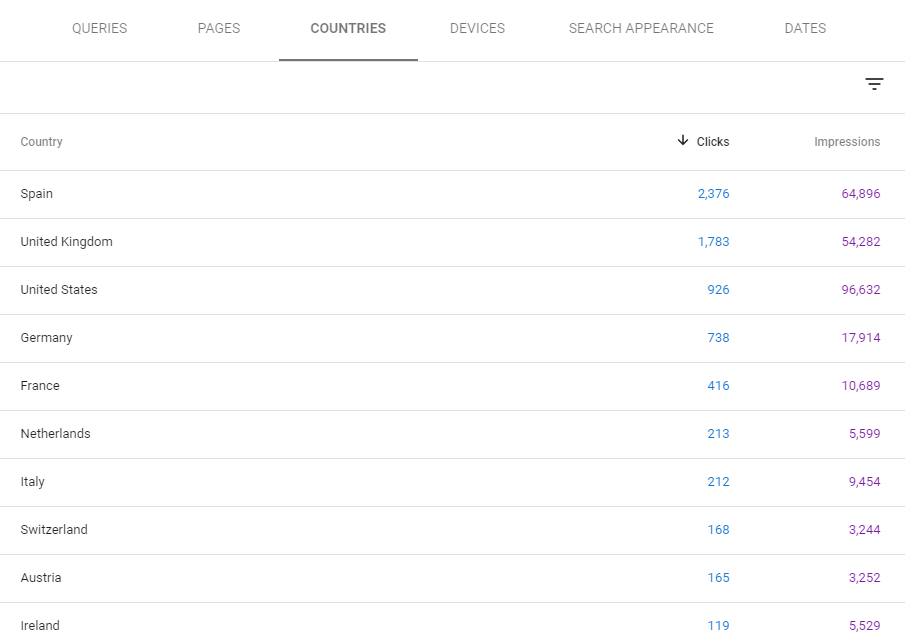
Trafic organique par pays dans la console de recherche Google pour un hôtel situé en Espagne.
Reporting de vos données
Google Analytics ou une autre solution de reporting vous donnera également un aperçu important de ce qui se passe sur votre site web.
Outre la possibilité d’analyser le comportement des utilisateurs sur votre site, cela peut également vous aider à détecter des problèmes potentiels, tels que des pages qui devraient être plus visitées mais qui ne le sont pas, des pages qui ne semblent pas se charger assez rapidement ou même des sites qui sont touchés par le spam, ce qui gonfle les chiffres et consomme de précieuses ressources du serveur.
Votre profil Google My Business
L’optimisation du profil Google Business de votre hôtel est devenue un élément crucial d’une stratégie de marketing de recherche réussie. Il est désormais essentiel de s’assurer qu’il est complet et bien optimisé, avec une stratégie claire pour recueillir systématiquement les avis des clients après leur séjour.
Présentation de l’interface Google My Business pour un hôtel/restaurant basé en Suisse.
Mobile friendly
Depuis le passage de Google à la première indexation mobile l’année dernière, il est devenu essentiel de s’assurer que le site de votre hôtel fonctionne bien sur tous les types d’appareils.
Vitesse du site et temps de chargement des pages
Pour que les choses restent simples, vous voulez vous assurer que votre site est aussi rapide, ou plus rapide, que n’importe quel concurrent de votre hôtel. Vous devez connaître ces sites suffisamment bien, et avoir une liste d’environ 5 hôtels concurrents est un atout majeur pour le SEO car cela peut vous aider à comparer les progrès organiques par rapport à eux ainsi qu’à obtenir des conseils pratiques sur les contenus que vous avez peut-être manqués.
Utilisation des données structurées
Les données structurées, également connues sous le nom de balisage schéma, permettent aux moteurs de recherche et autres outils d’être en mesure de comprendre plus de données au sein d’une page web.
Alors que les crawlers lisent et comprennent traditionnellement le contenu d’une page, les données structurées sont un langage de balisage spécifique qui vous permet de donner explicitement plus d’informations sur votre entreprise, votre hôtel en l’occurrence.
Les données structurées qu’un hôtel peut utiliser comprennent le schéma de l’hôtel, qui existe dans le schéma de l’entreprise locale, où vous pouvez fournir des détails tels que le nom de l’hôtel, des informations sur les équipements, si l’hôtel est adapté aux animaux de compagnie (c’est une nouveauté), et bien d’autres.
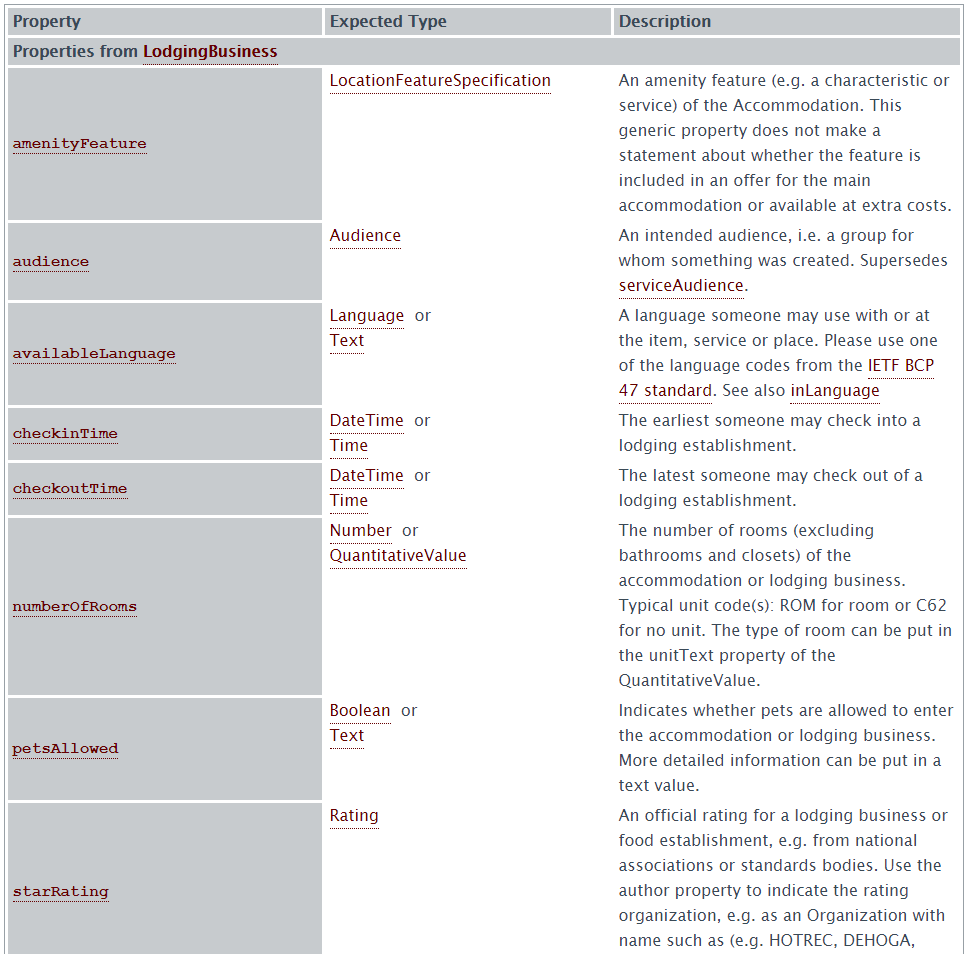
Exemple de balisage schéma de l’hôtel, montrant certaines des informations que vous pouvez utiliser dans vos données structurées.
Pour donner un autre exemple plus tangible des avantages du balisage schéma, vous pouvez voir un SERP pour le schéma ci-dessous dans Google. Bien qu’il ne s’agisse pas d’un exemple pour un hôtel, nous espérons qu’il montre la puissance des données structurées utilisées par TripAdvisor pour une requête de recherche de marque.
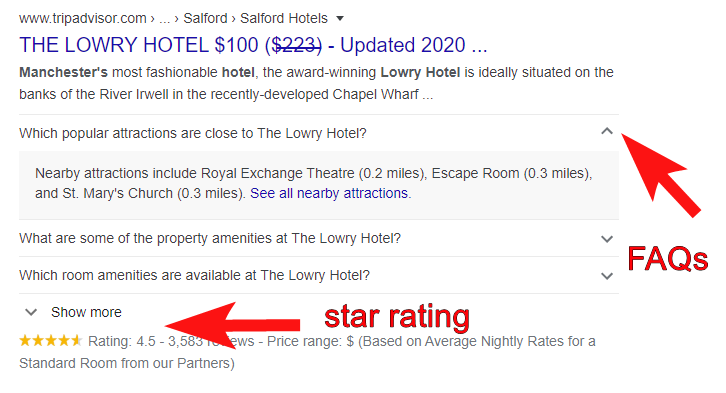
Exemple de données structurées montrant l’utilisation du balisage pour les FAQ, plus l’extrait de la note d’évaluation.
Vous devez faire attention à la façon dont vous choisissez de baliser les snippets pour un hôtel.
J’ai reçu une fois une « pénalité pour données structurées » automatisée par Google pour l’avoir utilisée d’une manière qu’ils n’approuvaient pas.
J’avais annoté des avis qui avaient été recueillis sur le profil commercial des hôtels sur Google, et non des avis qu’ils avaient recueillis de manière indépendante.
Donc, malheureusement, certains des avantages des riches snippets de données ne sont pas disponibles pour les hôtels indépendants.
Je ne peux pas non plus parler de données structurées sans mentionner les « Featured Snippets » – où vous avez la possibilité de saisir ce que l’on appelle la « position 0 » au sein du SERP.
C’est le résultat que Google fait apparaître pour les questions auxquelles il pense pouvoir répondre directement dans ses résultats.
Il existe une relation d’amour-haine entre les snippets er la communauté SEO – certains les adorent, car c’est une excellente occasion d’obtenir une bonne couverture pour votre site. D’autres les détestent et les considèrent comme un « vol » de clics par Google sur votre site.
Quelle que soit votre opinion sur les snippets, si vous pouvez maintenir la position 0, vous verrez beaucoup plus d’impressions et de clics sur votre site.
Pour un hôtel, je pense que vous êtes limité dans vos possibilités alors si vous pouvez répondre à des questions spécifiques sur votre hôtel (« y a-t-il un parking à l’hôtel xyz à Londres ? »), vous ne pouvez pas être présenté pour beaucoup d’autres choses.
Cela ne veut pas dire que si vous avez un blog, et que vous faites du bon travail avec votre stratégie de contenu pour créer des choses que les clients potentiels peuvent rechercher, alors vous pouvez toujours en tirer profit.
Votre profil de backlinks
En guise de mise en garde, je ne suis pas sûr que le fait d’avoir un énorme profil de backlinks en tant qu’hôtel soit aussi important pour votre classement organique que dans d’autres secteurs.
Je pense que les citations du NAP (lorsque votre hôtel est mentionné ailleurs sur le web sans lien) peuvent compter pour être tout aussi bénéfiques.
Si vous pensez du point de vue de Google, pourquoi devrait-il classer les hôtels de manière organique en fonction du nombre de liens qu’ils ont sur le web ?
Il est de loin préférable pour lui de montrer aux hôtels qu’il est sûr qu’ils correspondent à l’intention de recherche indiquée par l’utilisateur.
Je réalise que les liens feront toujours partie de l’algorithme de Google lorsqu’il s’agira de classer les hôtels de manière organique (Google choisit probablement de crawler plus souvent les sites qui ont un nombre de liens plus élevé que les autres) mais je ne pense pas qu’il soit absolument nécessaire d’avoir un profil de liens exceptionnel pour être bien classé.
C’est pourquoi, si j’étais un hôtel, j’investirais des efforts ailleurs et je ne courrais pas après les liens.
Je pense qu’en tant qu’hôtel, il vaut mieux passer son temps à s’assurer d’être extrêmement visible tout au long des phases de recherche et de réservation.
Prochaines étapes : audit et évaluation
Une fois que vous avez compris ce cadre d’éléments qui peuvent vous aider à rester en tête de ce paysage de recherche concurrentiel, l’étape suivante consiste à auditer le site web de votre hôtel.
Restez à l’écoute – je vous donnerai plus d’informations sur la manière d’évaluer chacun de ces points et un modèle de liste de contrôle Google Sheets pour le référencement des hôtels dans un prochain article.
