
Comment tirer profit des fonctionnalités avancées d’Oncrawl pour gagner en efficacité dans le pilotage de votre activité de SEO.
Oncrawl est un outil SEO puissant qui vous permet de piloter et d’optimiser la stratégie de visibilité sur les moteurs de recherche de sites e-commerce, média, blog ou applications. Il est construit autour d’un principe simple : aider les trafic managers à gagner du temps dans les phases d’analyses et dans la gestion de projets SEO au quotidien.
En plus d’être un outil d’audit onsite, basé sur une plateforme SaaS conçue autour d’une API qui combine toutes les data de sites, il est aussi un analyseur de logs qui simplifie l’extraction et l’analyse de données issues des fichiers de log web.
Les possibilités d’Oncrawl sont très larges mais nécessitent d’être maîtrisées. Nous allons dans cet article, vous présenter 5 astuces pour gagner du temps au quotidien dans votre utilisation du Crawler & Log analyzer Oncrawl.
1# La création d’une catégorisation d’urls HTTP/HTTPS
Le sujet de la migration HTTPS est un sujet brûlant dans le monde du SEO. Pour une gestion parfaite de cette étape clé de la vie d’un site web, il est important de pouvoir suivre précisément le comportement des bots sur les deux protocoles.
L’expérience a démontré que les bots prennent plus ou moins de temps pour faire le passage complet des appels HTTP vers HTTPS. En moyenne, cette transition prend de quelques semaines à plusieurs mois ; tout dépend de facteurs externes et internes fortement liés à la qualité du site et de la migration.
Pour suivre précisément cette phase de transition, où les budgets de crawl sont fortement impactés, il est préférable de suivre les hits des bots. Il est donc nécessaire d’ analyser les logs serveurs. Le bot – comme un utilisateur lambda – laisse une trace sur chaque page, ressource et requête qu’il fait. Vos logs contiennent le port qui a servi ces appels. Vous êtes donc en mesure de valider la qualité de votre migration vers HTTPS.
Méthode pour configurer un Set de Groupe de Page dédié http vs https
Sur la home d’un projet Advanced, vous trouverez en haut à droite le bouton “settings”, sélectionnez ensuite le menu “Configure Page Group”.
Une fois sur l’écran de configuration des groupes, créez un nouveau Set “Create Group Set” et nommez le “HTTP vs HTTPS”.
Afin d’avoir l’accès aux logs il est important de sélectionner l’option “I want to use this set on log monitoring and cross analysis dashboards”
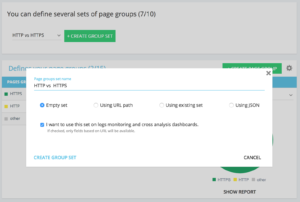
Les “Groups” se construisent de la façon suivante :
- HTTPS : “Full url” / “start with” / https
- HTTP : “Full url” / “not start with” / https
Une fois sauvegardé, vous obtiendrez cette vue de votre migration HTTPS à condition d’avoir bien ajouté le port de la requête dans les lignes de log (voir notre guide sur l’ajout des logs).
2# L’utilisation des QuickFilters et la gestion des OwnFilters
Les QuickFilters se trouvent dans le “Data Explorer”. Ils ont été créé pour vous faciliter l’accès à certaines mesures SEO importantes comme par exemple les liens pointant vers des 404, 500 ou 301/302, les pages trop lentes ou trop pauvres en contenu, etc.
Voici la liste complete :
- 404 errors
- 5xx errors
- Active pages
- Active pages not crawled by Google
- Active pages with status code encountered by Google different than 200
- Canonical not matching
- Canonical not set
- Indexable pages
- No indexable pages
- Orphan active pages
- Orphan pages
- Pages crawled by Google
- Pages crawled by Google and Oncrawl
- Pages in the structure not crawled by Google
- Pages pointing to 3xx errors
- Pages pointing to 4xx errors
- Pages pointing to 5xx errors
- Pages with bad h1
- Pages with bad h2
- Pages with bad metadescription
- Pages with bad title
- Pages with HTML duplication issues
- Pages with less than 10 inlinks
- Redirect 3xx
- Too Heavy Pages
- Too Slow Pages
Mais il arrive que ces QuickFilters, pensés de manière générique, ne soient pas assez précis pour être pertinents sur votre projet.
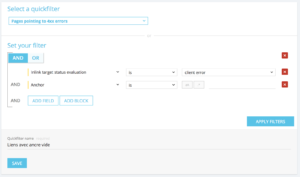
Dans ce cas, vous pouvez partir de l’un d’entre eux et créer votre propre Filter “Own Filter” en ajoutant des conditions dans le filtre et en le sauvegardant ensuite pour le récupérer rapidement lors de votre prochaine visite.
Par exemple, en partant des liens pointant vers une 4xx, vous pouvez choisir de filtrer sur les liens comportant une ancre vide : “Anchor“ / “is” / “” et sauvegarder ce filtre grâce au bloc suivant “Quickfilter name” puis “Save” comme sur la capture ci-dessous.
Une fois enregistré, il peut être modifié à volonté puis re-enregistré sous le même nom si besoin.
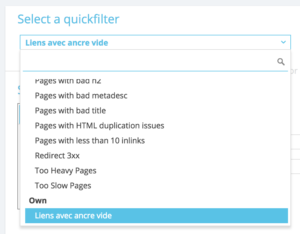
Vous avez maintenant accès à ce “Quickfilter” particulier directement dans la liste “Select a Quickfilter” tout en bas dans la partie “Own” comme sur la capture ci-dessous.
3# La configuration de Customs Fields liés à un DataLayer
Vous utilisez sûrement une catégorisation de vos types de pages liées, par exemple à la définition des tags de votre outil d’analytics. Ce code particulier est très intéressant pour votre segmentation ou pour croiser les données d’Oncrawl avec vos data externes.
Pour vous permettre de créer des “colonnes pivot” pour vos analyses, nous pouvons extraire ces bouts de codes lors des phases de crawls et les rapporter comme type de donnée de votre projet.
L’option “Custom Fields” permet de “scraper” (ou récupérer) n’importe quel élément du code source des pages grâce à une expression régulière “regex” (pour regular expression) ou une requête XPath. Ces langages ont leur définition et leur règles que nous n’aborderons pas ici. Vous pouvez trouver des information sur le Xpath ici et ici pour les “regex”.
Use case 1 : extraire les données du datalayer du code source des pages
Code à analyser :

Solution : Utiliser une “regex” : s.prop2=”([^ »]+)” / Extract : Mono-value / Field Format : Value

Pour résumer la “Rule” dit :
- Trouve la chaine de caractère s.prop2=”
- Scrape tous les caractères qui ne sont pas des “ (le premier caractère à la suite de la donnée à extraire)
- La chaîne à extraire se trouve avant le “ de fermeture
A la suite du crawl, dans le data explorer vous retrouverez dans les colonnes sProp2, sProp3 ou votre field Name, la donnée issue de cette extraction :

Use case 2 : faire du relevé de prix chez le concurrent
Utiliser un XPATH
Code à analyser :
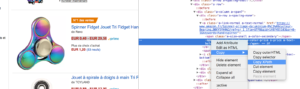
Il suffit de copier/coller le Xpath de l’élément à scraper directement depuis l’analyseur de code de Chrome. Attention toutefois, si le code est affiché en JavaScript il faudra configurer un projet de Scrape sur mesure.
Le langage Xpath est très puissant et peut être complexe à manipuler, si vous avez besoin d’aide n’hésitez pas à faire appel à nos experts.
Use case 3: tester la présence d’un tag analytics en phase de recette
Utiliser une regex
Code à analyser :

Solution : Utiliser une “regex” : ’_setAccount’, ‘UA-364863-11’ / Extract : Check if exist
Vous obtiendrez dans le data explorer “true” si la chaîne est trouvée, False dans le cas contraire.
4# La visualisation de la fréquence de Crawl Google sur chaque partie de son site
Le budget de crawl est au centre des préoccupations de tous les SEOs depuis quelques temps. Il est en fait intimement lié au concept de “Page importance” et de planification des crawls de Google ou “crawl Scheduling”. Nous savons que ces principes – exposés dans les brevet de Google depuis 2012 – permettent à la société de Mountain View d’optimiser les ressources allouées au crawl du web.
Google ne dépense pas la même “énergie” sur toutes les rubriques de votre site. Sa fréquence de visite sur chaque partie du site vous donne l’indication précise de “L’importance” de vos pages aux yeux de Google.
Les pages “importantes” sont plus crawlées par les robots de Google car le budget de crawl est intimement lié à la capacité d’une page à se positionner.
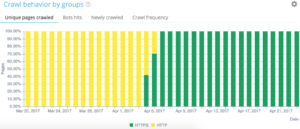
Nativement, les projets Oncrawl Advanced permettent de voir le budget de crawl dans le “Log monitoring” / “Crawl Behavior” / “Crawl Behavior By Group”.
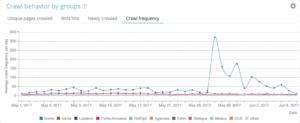
Vous constaterez que le groupe “Home Page” est le groupe avec la plus grande fréquence de Crawl. C’est normal car Google cherche en continu les nouveaux articles et c’est en général sur la home page qu’ils sont remontés. La notion de “Page Importance” est étroitement liée à la notion de “Freshness” pour Google. Votre home page est la page la plus importante de votre site pour prioriser le budget de crawl de Google, puis l’optimisation se déploie à toutes les pages en fonction de la profondeur et de la popularité transmise.
Cela ne permet pas de bien voir les différences de fréquence, donc à vous de cliquer sur les groupes à retirer (en cliquant sur leur légende) et au fur et à mesure voir les données apparaître.
5# Le test de codes retours d’une liste d’urls suite à une migration
Lorsque l’on veut tester rapidement les status codes d’un ensemble d’urls, il est possible de tordre les settings d’un nouveau crawl :
- Ajouter toutes les urls en start urls (bouton “add start url”)
- Définir la profondeur max à 1
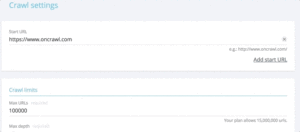
Ce crawl sur mesure vous retournera des données qualitatives précisément sur cet ensemble d’url.
Vous pourrez vous assurer que les redirections sont bien en place ou suivre l’évolution des status codes en fonction du temps. Pensez à l’avantage que vous pouvez tirer de ce crawl si vous le lancez périodiquement, vous pourrez suivre l’évolution des anciennes urls de manière automatisée.
Pourquoi ne pas créer un dashboard automatisé via notre API et réaliser du suivi de tests automatisé sur ces aspects ?
Nous espérons que grâce à ces hacks vous pourrez gagner en rapidité avec Oncrawl. Nous avons encore de nombreuses techniques avancées à vous présenter. Un webinar dédié sur le sujet est accessible en vidéo :
N’hésitez pas à nous partager vos #hack #Oncrawl sur Twitter par exemple, nous sommes heureux que nos utilisateurs puissent s’amuser autant que nous à explorer l’outil.