
Lorsque l’on évoque la notion de budget de crawl, on touche une corde sensible dans l’écosystème du SEO. D’un côté, les sceptiques qui pensent que le budget crawl est une définition brillamment marketée, rien de plus, et de l’autre, les partisans d’une technique utilisée par Google pour prioriser l’exploration des pages d’un site. Du côté de Google, il est dit que le budget crawl est ainsi appelé par abus de langage par les professionnels du SEO et qu’il ne devrait pas y avoir lieu de s’en soucier pour les sites de moins d’un million de pages. On pourrait toutefois le dénommer ressources de crawl pour être un peu plus proche, à minima des termes évoqués dans les brevets.
En somme, le budget de crawl ou quel que soit son nom est un indicateur de plus dans les débats, âprement discuté mais jamais vraiment démontré.
Il y a toutefois deux indicateurs cités par Google dont on entend peu parler :
- Le crawl rate limit : qui permet à Google de définir la vitesse de crawl idéale sans menacer les performances globales du site.
- Le besoin d’exploration (crawl demand) : qui permet d’accroître le nombre de pages crawlées sde manière ponctuelle : refonte, jeu de redirections, etc.
Pourtant, il y a une chose qui met tout le monde d’accord : les lignes de logs ne mentent pas. “Log files are so underrated” pour citer John Mueller.
Qu’est-ce qu’une réserve de budget de crawl ?
On définit le budget de crawl comme une unité de temps à l’intérieur de laquelle Google définit, en fonction d’un score d’importance, les URLs à explorer. A fortiori, on admet souvent que le budget de crawl d’un site web donné mériterait d’être optimisé : faire en sorte que davantage de pages soit explorées par Google par rapport à un instant T.
C’est là qu’intervient la notion de réserve de budget de crawl. Il s’agit précisément d’identifier les explorations inutiles actuelles de Google sur certaines pages afin de transférer son exploration à d’autres pages.
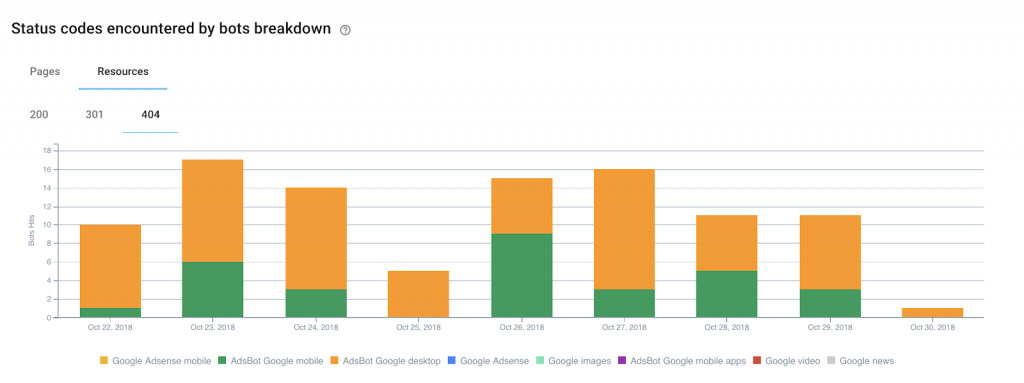
On pense naturellement aux erreurs « 4 double x » autant sur les pages que sur les ressources. On peut rapidement s’apercevoir que Google perd son temps sur des pages qui n’ont plus lieu d’être. C’est une première réserve à travailler : récupérer du hit pour favoriser l’exploration de Google sur des pages à réelle valeur ajoutée.

Et la même logique vaut pour les explorations effectuées via les User Agent hors SEO :
On peut aussi utiliser intelligemment les segmentations personnalisées créées via Oncrawl afin d’identifier les URLs qui ne méritent aucune attention de la part de Google. De très nombreuses raisons peuvent permettre d’identifier ces URLs : tags qui permettent de classer le contenu rédactionnel mais qui n’ont aucune valeur ajoutée en tant que page web, pages liées au tunnel de commande, etc.
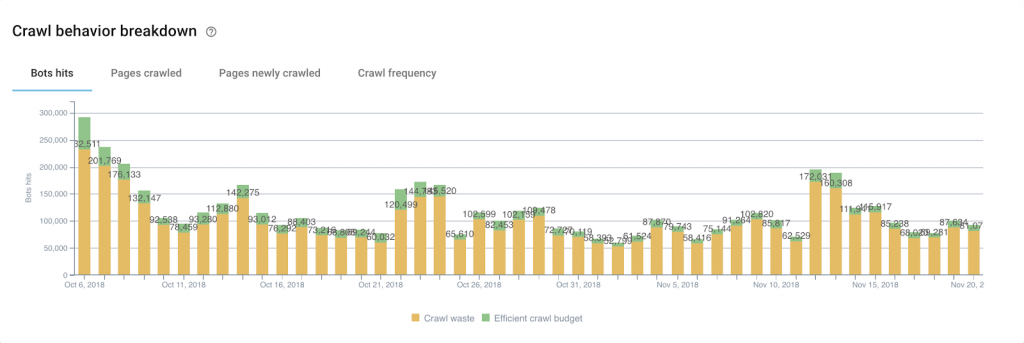
On sait également que lorsque le périmètre de crawl n’est pas atteint, Google peut être amené à crawler des URLs qui n’ont pas ou plus aucune valeur ajoutée, dès lors retirées de l’architecture du site : les pages orphelines.
Certaines peuvent continuer à recevoir des hits de Google. Lorsque le cas se présente et lorsque ces pages ne reçoivent plus de SEO visits, il convient également de les traiter en priorité afin de réaffecter la réserve de hits à d’autres pages.
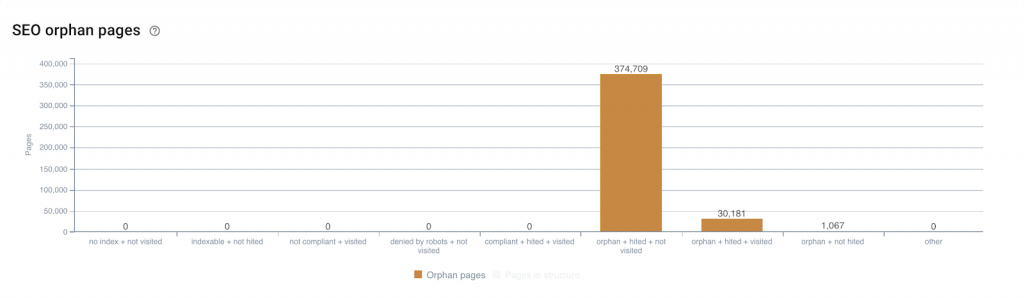
Comment mesurer les résultats ?
Notre discipline est tout sauf une science exacte. Une question se trouve en tête de liste lorsque nous évoquons l’exploitation des réserves de budget de crawl : “comment je peux dire si, une fois les optimisations apportées, Google s’intéresse à mes autres pages ?”.
On peut d’abord facilement s’apercevoir si oui ou non les optimisations que l’on apporte à un lot de pages données induisent le comportement attendu côté Google.
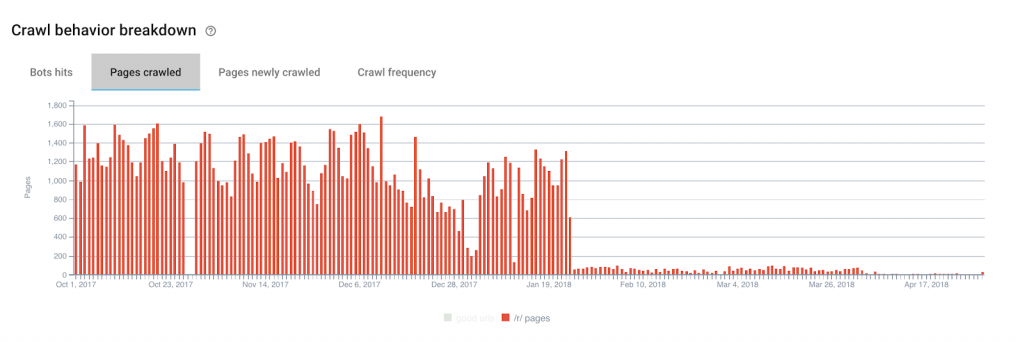
L’illustration est plutôt criante de vérité ici : malgré quelques rebuts après le 19 janvier 2018, on voit clairement que le crawl de Google sur nos pages inutiles est proche du néant.
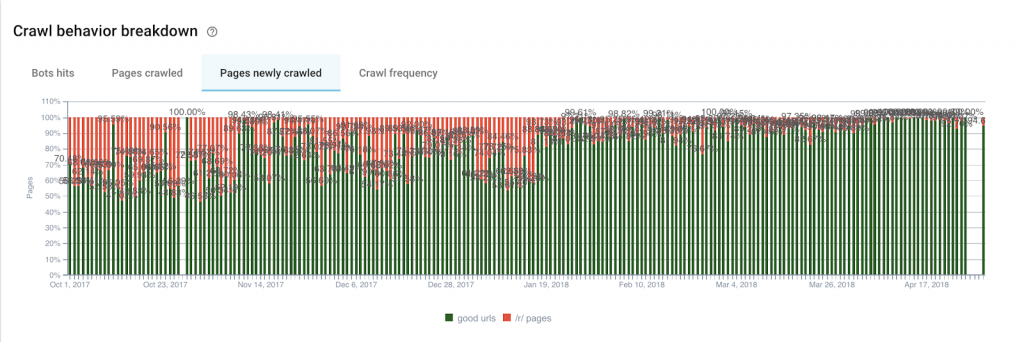
Si on s’intéresse maintenant aux pages nouvellements crawlées, on s’aperçoit que pour notre groupe “budget de crawl efficient”, on passe en moyenne de 58% de pages nouvellement crawlées par jour à 88%.
En appliquant le Base filter sur notre groupe de pages à abattre, on s’aperçoit également clairement du résultat :
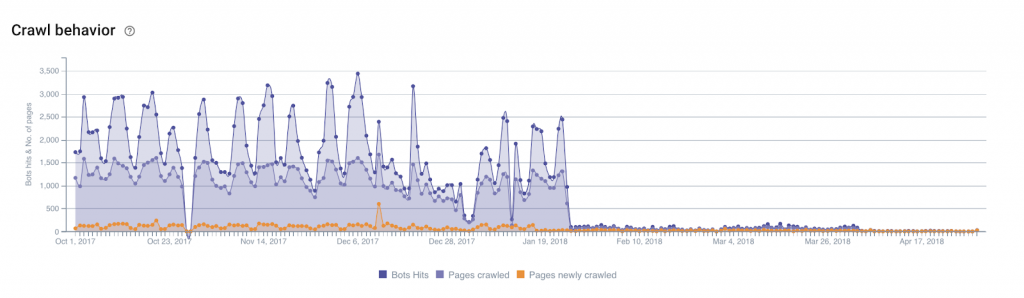
Il est aujourd’hui difficile voire impossible d’identifier précisément un schéma de crawl : soit définir un point d’entrée et suivre url par url le chemin de Google pour un groupe de pages en particulier. Certainement parce que Google ne se comporte pas ainsi et, pour aller plus loin, son comportement ne suit certainement aucune logique. L’identification des bénéfices suite à l’exploitation des réserves de budget de crawl demeure donc inexacte car nous ne pouvons mesurer précisément les tenants et aboutissants. Toutefois, à la lumière des illustrations et métriques énoncées plus haut, on note clairement une modification globale du comportement de Google entre nos pages à budget de crawl efficient et non efficient.
