
Pourquoi le budget de crawl est important ?
Les moteurs de recherche doivent crawler et indexer les sites correctement afin de construire efficacement les SERPs. C’est là que le budget de crawl devient important : ce terme renvoie au nombre de pages que Google examine sur votre site pendant chaque crawl.
Si vous avez un petit site, vous n’avez probablement pas besoin de vous soucier du budget de crawl. Cependant, si vous avez un site ecommerce ou un très grand site avec plus de 1000 pages uniques, vous feriez mieux de commencer à optimiser votre budget.
Le cas de great content
Chez great content, nous fournissons des services de production de contenu multilingues dans plus de 30 languages. Nos 1000+ clients et les membres de notre communauté d’auteurs free lance sont basés dans différents pays et possèdent différentes langues maternelles. Cela signifie que notre site doit être disponible et visible dans plusieurs pays (ou au moins dans ceux qui génèrent le plus de valeur). Nous devons gérer le crawl et l’indexation des moteurs de recherche pour les différentes versions et les multiples pages.
[Étude de cas] Augmenter le budget de crawl sur les pages stratégiques

Actuellement, nous sommes dans un processus de transition. Nous avons récemment sorti une nouvelle version de notre site qui est seulement disponible en 3 langues et nous sommes en train de créer du contenu multilingue pour les pays que nous ciblons. Cela inclut d’avoir un grand nombre de pages (au moins une version du site par langage) qui doivent être indexées par Google. C’est là que le budget de crawl devient crucial. Donc, que devons-nous faire pour s’assurer que ce dernier est dépensé efficacement ?
Comment détecter les problèmes de crawl en utilisant Oncrawl ?
La première chose à faire est de rassembler autant d’informations que possible.
1. Ajouter des sources de données
L’un des avantages d’Oncrawl est que la plateforme permet d’intégrer diverses sources de données afin d’obtenir une vue globale de la situation de votre site.
Vous pouvez ensuite connecter toutes les informations provenant de différentes sources comme Google Analytics et la Google Search Console. Et surtout, vous pouvez intégrer les données tierces d’outils comme SEMrush (via fichiers CSV) et accéder à vos données de log afin d’analyser le comportement de Google et de vos utilisateurs sur votre site.
Vous voulez en savoir plus sur comment connecter vos sources de données externes ? Vous pouvez regarder cette vidéo :
2. Log monitoring
L’analyse de logs est l’une des fonctionnalités Oncrawl générant le plus de valeur.
Vous pouvez facilement ajouter des informations depuis votre serveur de log. Oncrawl vous fournit un compte FTP qui vous permet d’importer vos fichiers de log depuis votre serveur dans votre projet Oncrawl.
Vous pouvez voir comment cette information est croisée dans cette vidéo :
Avec Oncrawl, vous avez deux options lorsque vous importez vos logs :
- Les télécharger manuellement (vous devrez le faire pour chaque date pour lesquelles vous voulez les données)
- Inclure le script dans le serveur source pour que les logs soient envoyés automatiquement
Dans notre cas, nous avions besoin de savoir si Google se rendait sur les pages les moins pertinentes (la plupart sont des pages portfolio). La Search Console nous a montré que c’était le cas et a rassemblé les informations pour nous aider à comprendre pourquoi.
3. Données tierces
Comme nous l’avons déjà dit, Oncrawl vous permet de croiser des données provenant de tous les outils imaginables. Pour cela, vous pouvez simplement utiliser un fichier CSV (dans le format indiqué) ce qui vous permet de traiter les données de vos outils. Par exemple, vous pouvez télécharger les tableaux de visibilité SEMrush qui montrent les mots-clés pour lesquels vous vous positionnez, les positions que vous occupez, les volumes de recherche mensuels… En bref, à peu près tout.
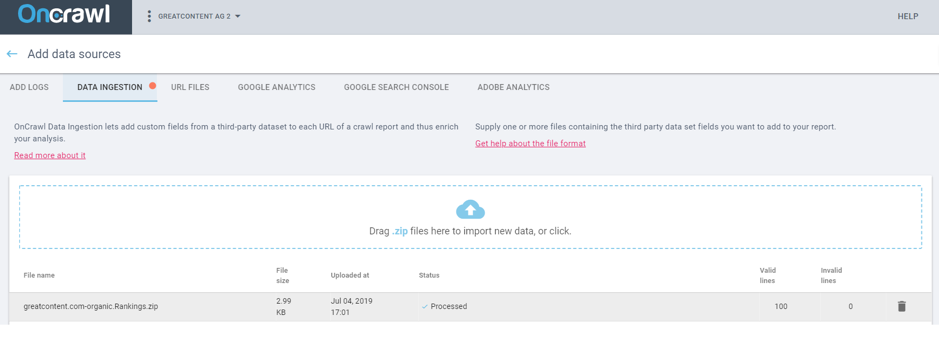
4. Rapport de crawl
Après avoir ajouté les sources de données pour collecter autant d’informations que possible, nous pouvons lancer le crawl et analyser les résultats dans la partie “Crawl Report” qui évoque le Crawler SEO.
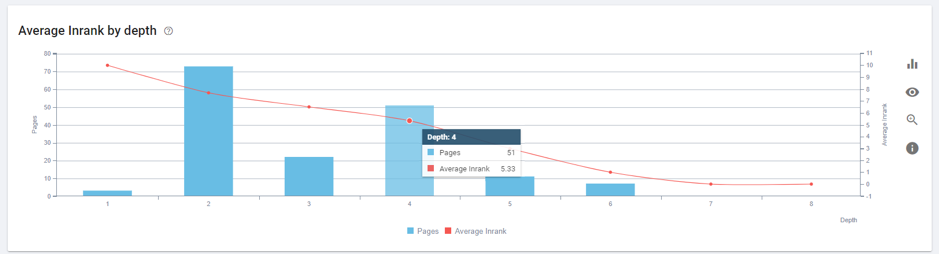
L’une des fonctionnalités les plus intéressantes est celle qui permet de voir la valeur de classements des liens entrants (Page Rank) par niveau de profondeur.
Curieusement, nous avons de nombreuses pages avec des valeurs d’Inrank moyennes élevées à un niveau de profondeur de 4 (trop profond). La plupart sont des pages portfolio, qui ne sont pas les plus pertinentes.
Un autre point fondamental du rapport de crawl est l’onglet Status Codes. Celui-ci vous montre les réponses du serveur trouvées par le robot.
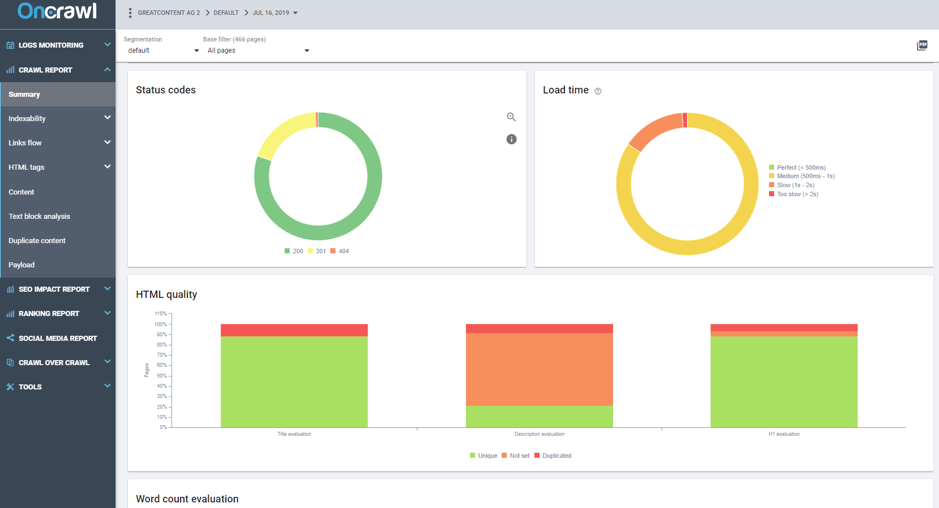
Sur notre site, presque 20 % des pages crawlées ont un code 301. Cela signifie que nous gaspillions 20 % du budget des bots de Google. Nous avions aussi beaucoup de liens internes qui devaient être remplacés.
5. Rapport SEO Impact
Enfin, vous devez analyser l’indicateur le plus important lorsqu’il s’agit de budget de crawl : le rapport SEO Impact. Cela nous donne un rapport global détaillé et complet qui nous permet de voir toutes les informations pertinentes au même endroit.
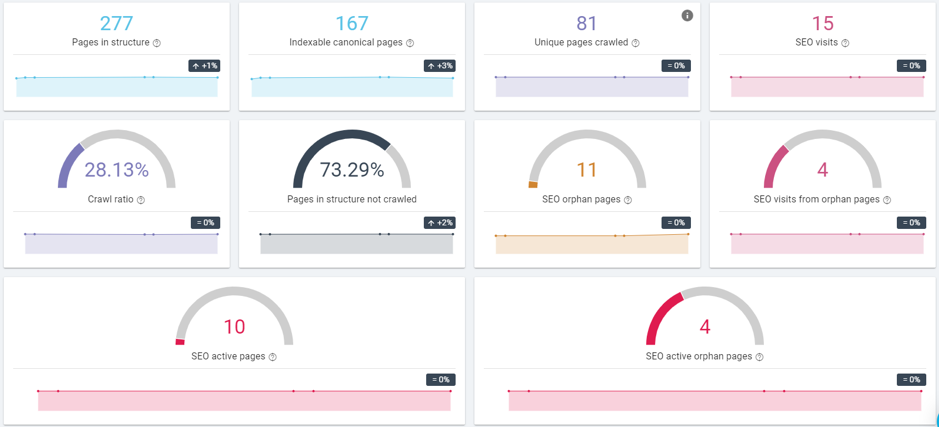
Nous pouvons voir ici tous les insights pertinents issus des données basées sur les informations dans les fichiers de log.
- Seulement 81 des 167 pages indexables ont été crawlées par Google, moins de la moitié.
- Moins de 30 % des pages connues par Oncrawl ont été crawlées par Google.
- Google a crawlé des pages inactives quotidiennement, presque 2 fois par crawl en moyenne.
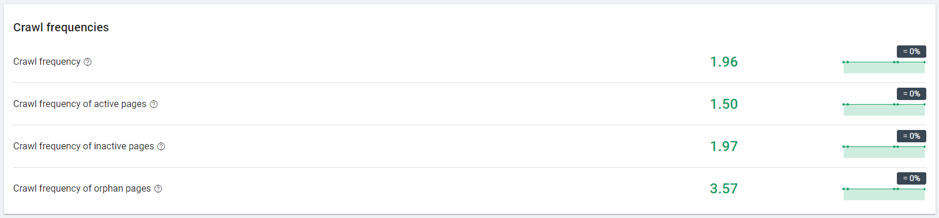
Conclusions
Selon la Search Console, certaines des pages qui sont apparues récemment dans les moteurs de recherche Google étaient moins pertinentes à nos yeux.
En fait, il s’agissait de pages qui, dans les anciennes versions du site, étaient utilisées (et liées) fréquemment mais qui n’étaient plus du tout pertinentes. Par exemple, les pages portfolio (exemples de textes pour chaque langue et secteur).
Le point fort de la plateforme SEO d’Oncrawl c’est les informations détaillées fournies pour chaque URL. Non seulement les améliorations SEO de la page et les valeurs d’indexation (que la Search Console vous fournit également) mais aussi des informations sur l’architecture (popularité de cette URL dans la page, liens que vous recevez, redirections…)
Grâce à Oncrawl, nous avons remarqué plusieurs problèmes liés au crawl de la page par les moteurs de recherche :
- Les pages les plus importantes du site ne gagnent pas d’autorité. Cela est dû au fait que nous avons un grand nombre de liens internes pointant vers des pages non pertinentes au lieu des plus importantes.
- Beaucoup de liens ne sont pas des liens directs mais des liens qui pointent vers une redirection. Vous savez peut-être que lorsque Google arrive sur une page et reçoit un code 301, cela ajoute cette URL à une liste de crawls futurs. Ainsi, les URLs ne sont pas trackées directement et nous manquons l’opportunité que Google crawle le page au cours de sa session. Cela résulte en du gaspillage de budget de crawl.
- Les boucles de redirections. Nous avions un lien qui devait renvoyer vers une catégorie générale mais en réalité, il dirigeait vers une URL qui n’existait pas encore et renvoyait elle-même vers la page de départ. Ce qui crée une boucle de redirections infinie !
- Nous avons aussi découvert d’autres pages où les liens internes pointaient continuellement vers un contenu avec une redirection.
Les outils seo d’Oncrawl nous ont fourni des informations utiles pour nous aider à améliorer la nouvelle version de notre site et éviter de répliquer les mêmes erreurs dans des versions futures.
Si ces outils sont pratiques pour n’importe quel site grand ou petit, je vous laisse imaginer à quel point ils sont indispensables pour un site ecommerce où le nombre de pages est immense et où le budget de crawl peut rapidement devenir significatif.
