
Quelle est la chose la plus importante que vous pouvez faire pour que votre site apparaisse dans les résultats de recherche ?
Un site web adapté aux robots permet aux moteurs de recherche de découvrir facilement son contenu et de le rendre disponible à tous les utilisateurs.
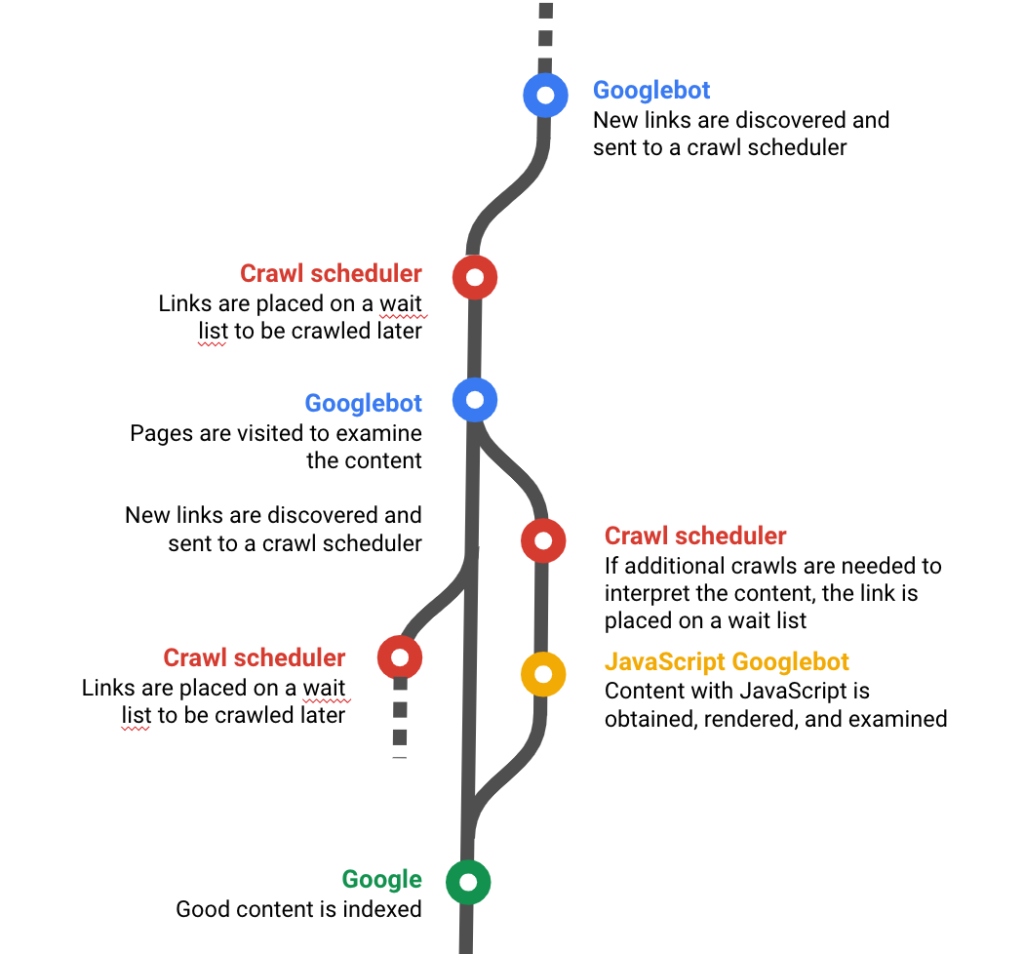
Le crawl, ou la visite d’un robot pour collecter des informations, est la première étape de la (longue) procédure qui se termine lorsque votre site est classé premier dans la page des résultats de recherche. Cette étape est tellement importante que l’un des porte-parole de Google, Gary Illyes, pense qu’il faut l’affirmer en majuscules :
Nous [Google] n’insistons visiblement pas suffisamment pour que les webmasters se concentrent sur les choses les plus importantes. Comme CONSTRUIRE UN SITE CRAWLABLE.
Gary Illyes (Chief of Sunshine and Happiness & Trends Analyst chez Google) / 8 février 2019 Reddit AMA sur r/TechSEO
Un site crawlable permet aux robots des moteurs de recherche de réaliser des tâches basiques :
- Découvrir qu’une page existe à travers des liens pointant vers elle
- Atteindre une page depuis plusieurs points d’entrée sur le site, comme la page d’accueil
- Examiner les contenus d’une page
- Trouver les liens d’autres pages
Les étapes que vous pouvez réaliser pour rendre votre site crawlable doivent couvrir tous ces aspects.
Donner les bonnes instructions aux robots
Les Googlebots suivent les instructions des sites web. Ces instructions peuvent apparaître dans différentes localisations :
- Les propriétés robots des balises meta d’une page
- Les balises x-robots dans le header d’une page, particulièrement pour les URLs qui ne sont pas des pages HTML
- Les fichiers robots.txt du site
- Les paramètres du serveur du domaine dans le fichier htaccess
Les pages où les sections de site interdites aux robots ne sont pas crawlables car non accessibles par Google.
Lorsque vous fournissez des instructions aux robots, gardez en tête que Google crawle régulièrement avec les robots suivants :

Vous pouvez voir comment le fichier robots.txt de votre site cible ces robots en utilisant un crawler SEO qui respecte les directives des robots et en lançant un crawl avec “Googlebot” dans le nom du user agent du robot.
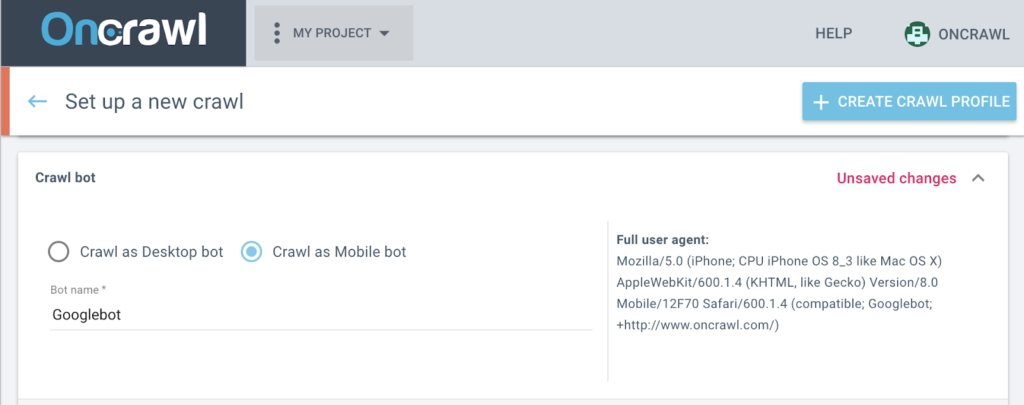
Auditer toutes les pages de votre site pour vérifier les instructions données aux robots est aussi très simple : toutes les pages apparaissant dans Google doivent autoriser les googlebots à les crawler.
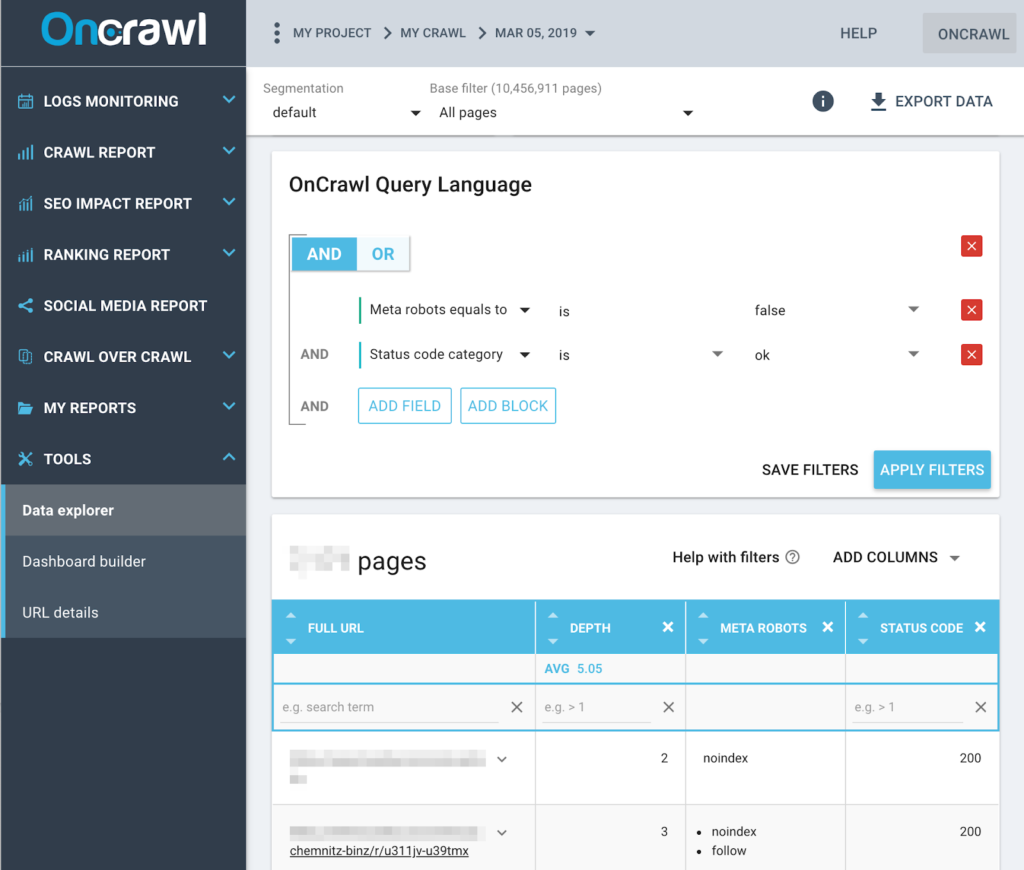
Suivre la performance du serveur
Les sites avec des pages contenant des erreurs de serveur sont inaccessibles pour les robots (et les utilisateurs !) tant que l’erreur est présente. Des erreurs récurrentes ou systématiques peuvent aussi avoir un effet négatif sur le SEO en général.
Vous pouvez suivre les erreurs de votre site grâce à des crawls réguliers et en corrigeant les pages avec un statut HTTP 400 ou 500.
Penser l’architecture du site avec précaution
L’architecture d’un site désigne la manière dont un visiteur, que ce soit un utilisateur ou un robot, passe d’une page à une autre en utilisant les liens d’un site. Cela inclut non seulement les liens du menu navigationnel, mais aussi les liens dans le contenu d’une page et tous les liens du footer.
Un bon design d’architecture de site inclut les standards suivants :
- Créer plus de liens pour les pages les plus importantes
- S’assurer que toutes les pages qui existent ont au moins un lien vers elles
- Réduire le nombre de clics nécessaires pour aller de la page d’accueil vers d’autres pages
Ces trois standards sont basés sur la manière dont les crawlers des moteurs de recherche se comportent :
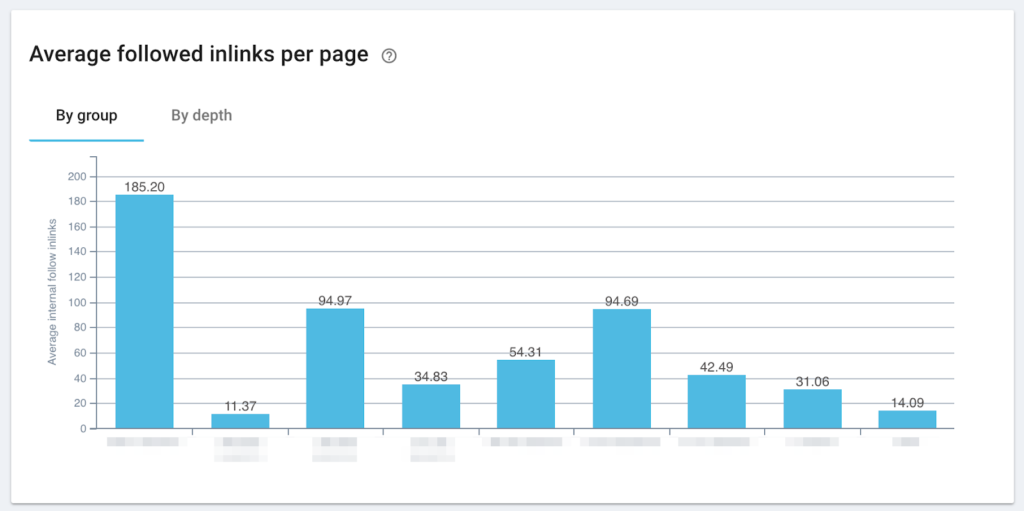
Des liens d’autres pages sur le même site peuvent aider les moteurs de recherche à établir l’importance relative d’une page sur le site. Cela aide les robots à déterminer si un contenu est de qualité. En résumé, une page avec beaucoup de liens pointant vers elle est souvent plus importante qu’une page recevant peu de liens.
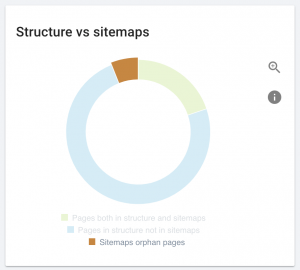
En terme de négligence, les pages orphelines, des pages avec aucun lien pointant vers elles, sont problématiques. À moins qu’il y ait des liens externes vers les pages orphelines, ces pages sont invisibles aux moteurs de recherche. La clef pour les rendre crawlables est d’ajouter des liens vers elles depuis une page qui fait déjà partie de l’architecture de votre site.
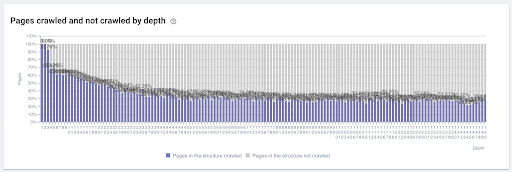
À cause du délai entre le moment où une page est découverte, où elle est crawlée et lorsque les liens qu’elle comporte sont crawlés, les pages qui sont situées loin des points clés du site (comme la page d’accueil) peuvent mettre un moment avant d’être crawlées par les moteurs de recherche. La distance depuis la page d’accueil, appelée la profondeur de page, peut être réduite en ajoutant des liens vers les pages profondes sur les pages catégorie et les autres pages qui sont plus proches de la page d’accueil.
Utiliser une technologie web accessible aux moteurs de recherche
Il existe un écart entre ce que font les navigateurs modernes et ce que fait Google actuellement.
Martin Splitt (Webmaster Trends Analyst chez Google) / Oct. 30 2018 Google Webmaster hangout
La technologie utilisée par les crawlers web pour accéder au contenu d’une page est actuellement basée sur Chrome 41 (M41). Si vous utilisez une version à jour de Chrome en mars 2019, vous êtes probablement sur une version de Chrome 72 ou Chrome 73. Bien qu’il s’agisse d’un grand écart, Google affirme qu’ils travaillent à le réduire.
Les principales différences concernent l’accompagnement pour les rich media et les technologies additionnelles. Google fournit des détails dans la documentation de Chrome et sur la page de documentation pour le service de rendu web.
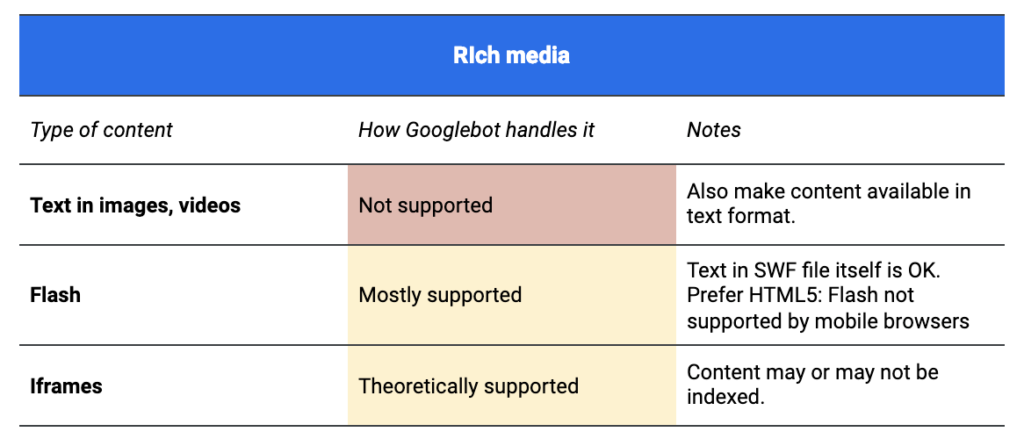
Cela ne signifie pas que vous ne pouvez pas inclure du contenu média riche comme Flash, Silverlight ou des vidéos sur votre site. Cela signifie simplement que n’importe quel contenu que vous intégrez dans ces fichiers devra toujours être disponible en format texte ou il ne pourra pas être accessible du tout aux moteurs de recherche.
— Google Webmaster Support
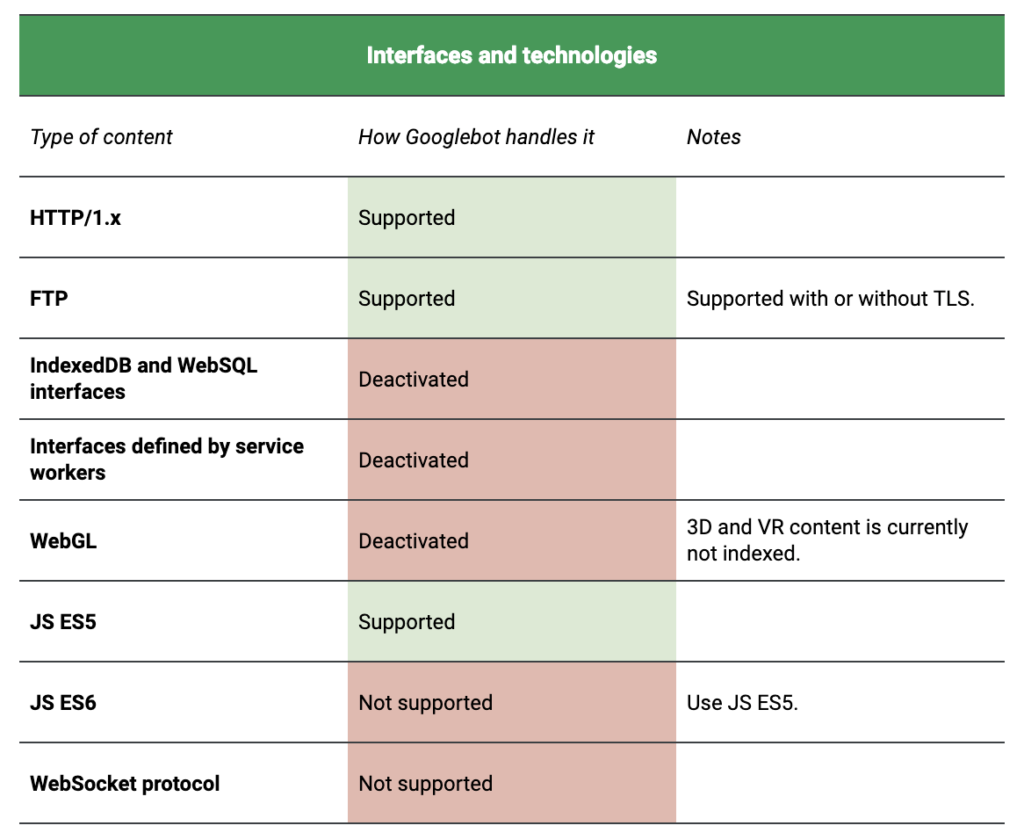
Si vous êtes particulièrement préoccupés par le JavaScript, vous devriez regarder la série de vidéos de Google ou lire les suggestions de Maria Cieslak pour apprendre à travailler avec JavaScript sans que cela ne soit un cauchemar.
[Étude de cas] Gérer le crawl du robot de Google

S’assurer que les informations clés sont rendues ___ et __
Les mots-clés manquant dans le titre sont “en premières” et “par le serveur”.
Google a récemment publié un article recommandant le rendu dynamique. Cette procédure permet au contenu JavaScript d’être crawlé plus rapidement en fournissant aux crawlers le contenu préalablement préparé par le serveur (rendu côté serveur ou SSR). Cela s’applique même si vous fournissez aux utilisateurs un HTML ou un JavaScript brut qui seront ensuite interprétés par le navigateur (rendu côté client, ou CSR).
Le rendu dynamique requiert que votre serveur web puisse détecter les crawlers (par exemple, en utilisant le user agent). Les requêtes des crawlers sont acheminées vers un moteur de rendu, les requêtes des utilisateurs sont servies normalement. Si nécessaire, le rendu dynamique sert une version du contenu appropriée pour le crawler. Par exemple, il peut servir une version statique du HTML. Vous pouvez choisir d’autoriser le rendu dynamique pour toutes les pages ou page par page.
— Google Developers’ Guide / Dernière modification le 4 février 2019
Il y a eu quelques débats pour déterminer si cette pratique n’était pas du cloaking, qui est sujet à des pénalités. C’est une manière de fournir du contenu non identique au utilisateurs et aux robots.
L’objectif est de s’assurer que votre contenu peut être vu et interprété par tous les visiteurs, qu’il s’agisse d’utilisateurs ou de robots. Quelques experts SEO comme Jan-Willem Bobink, soutiennent le rendu côté serveur à des fins SEO.
Si vous fournissez du contenu non rendu, assurez-vous que votre contenu principal est disponible dans le HTML basique de la page. Le rendu peut être retardé si des éléments bloquent le contenu en étant absents, en erreur, ou incomplets, comme le CSS ou JavaScript.
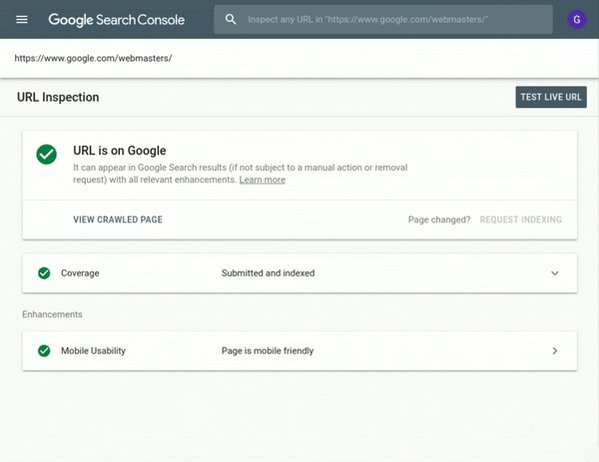
Vous pouvez vérifier comment Google voit votre page en utilisant l’outil Inspect URL, disponible depuis janvier 2019 dans la nouvelle Google Search Console :
Influencer les moteurs de recherche avec un site adapté aux robots
Si votre site web est facilement crawlable, vous avez gagné la première bataille du SEO. Les sites crawlables peuvent être indexés et les sites indexés peuvent être classés. Et les sites classés ramènent des leads.
Un site crawlable prend en considération la nature des robots et leurs limitations dans son design et son monitoring. Pour cela, vous devez vous intéresser aux questions suivantes :
- Comment les robots passent d’une page à une autre
- Comment les moteurs de recherche programment les crawls
- Comment les robots accèdent au contenu d’une page web
- Comment les sites communiquent avec les robots
- Comment les serveurs fournissent du contenu aux visiteurs robots
Si vous souhaitez attirer des visiteurs, c’est-à-dire gagner des leads grâce au marketing digital ou promouvoir des produits et services en ligne, un site crawlable est une première étape vers le succès.
Demandez votre démo personnalisée

