
L’une de mes conférences favorites au cours des 10 dernières années a été donnée par Mark Johnstone en 2014, alors qu’il était encore chez Distilled. La présentation s’intitulait “How to produce better content ideas”. Je m’en suis servi comme d’une bible pendant quelques années alors que je construisais des équipes chargées de promouvoir du contenu.
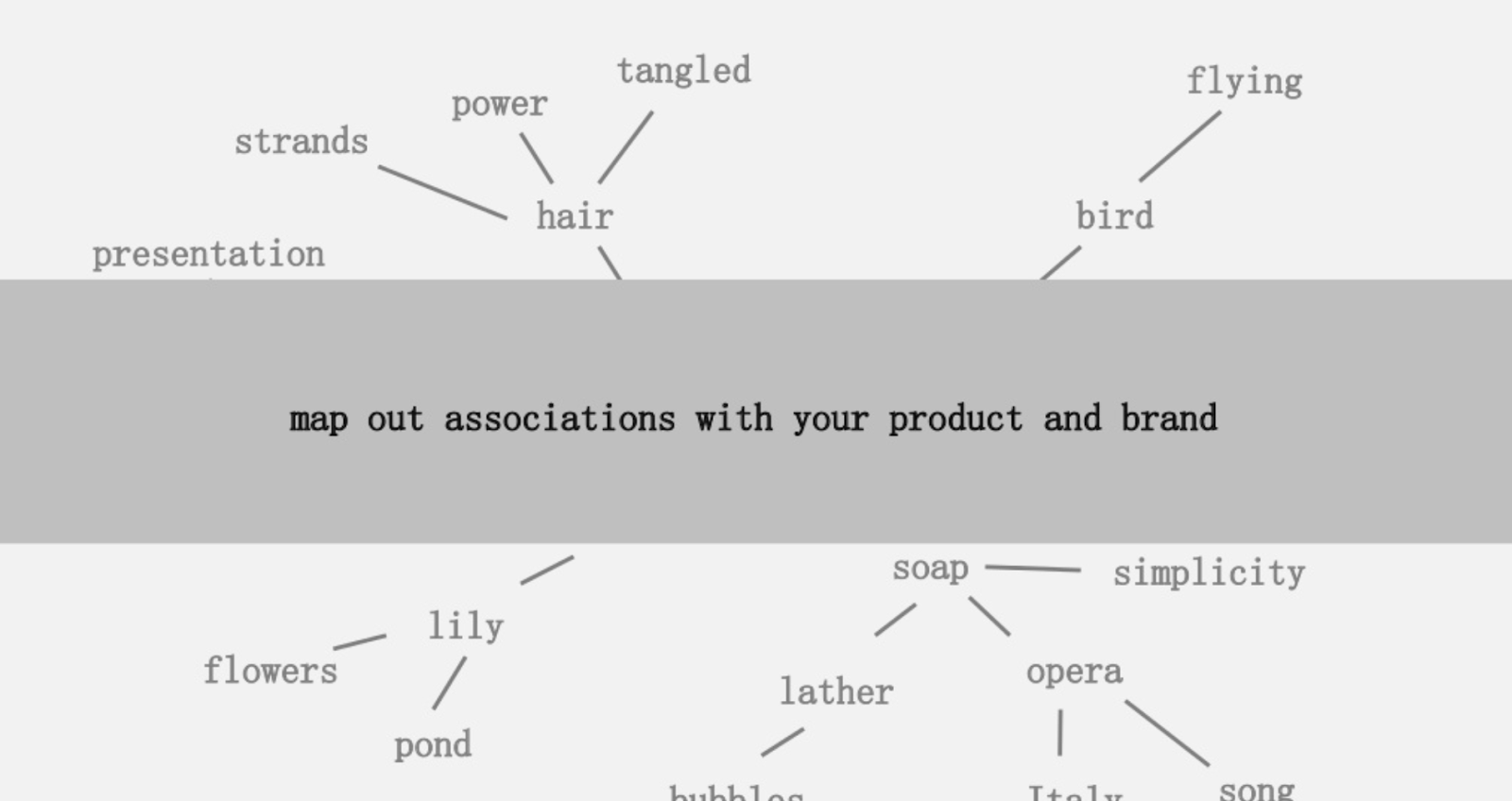
L’une des idées proposées était de créer un mapping visuel des connexités de mots associées avec votre produit ou marque. L’objectif est de pouvoir prendre le recul nécessaire pour trouver des moyens de combiner les associations et d’en faire quelque chose d’intéressant. Le but ultime étant la production d’idées, ce qu’il définit comme “une combinaison novatrice d’éléments auparavant non connectés afin d’apporter de la valeur.”
Dans cet article, nous prenons une approche orientée “cerveau gauche” en utilisant Python, l’API de Google Language et Wikipedia pour explorer les associations d’entités qui gravitent autour d’un sujet. L’objectif est d’acquérir une vue globale des relations entre les entités du topic graph. Cet article n’est pas destiné aux lecteurs moyens. Pour que l’article soit instructif, vous devez être familiers avec Python et avoir au moins un niveau basique en développement.
L’idée
Suite à l’idée de mapping de Mark Johnstone, j’ai pensé qu’il pouvait être intéressant de laisser Google et Wikipedia définir une structure de sujet en partant d’une page web ou d’un thème de départ. Le but est de construire le mapping des relations autour du sujet principal de manière visuelle dans une arborescence qui peut être analysée pour trouver des connections et possiblement générer des idées de contenu. L’image suivante représente l’idée de design initiale.
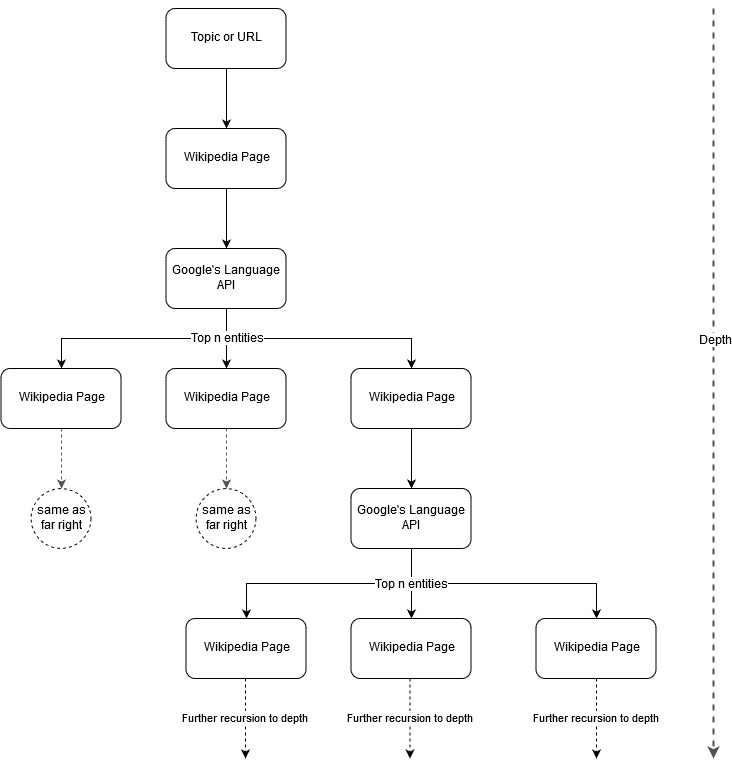
Nous donnons à l’outil un sujet ou une URL et laissons l’API de Google Language sélectionner le top X d’entités (3 dans nos exemples – elles incluent les URLs Wikipedia) pour chaque entité de page. Puis, nous construisons de manière récurrente un réseau de graphiques pour chaque entité trouvée jusqu’à une profondeur maximale.
Contexte des outils utilisés
Oncrawl API

L’API Google Language
L’API Google Language vous permet de passer soit en texte brut ou en HTML et renvoie miraculeusement toutes les entités diverses associées au contenu. L’API fait plus que ça encore, mais pour cette analyse, nous allons nous en tenir à cette portion. Voici une liste des types d’entités qu’elle retourne :

L’identification d’entité a été une partie fondamentale du Natural Language Processing (NLP) pendant longtemps et la terminologie correcte pour ces tâches est Named Entity Recognition (NER). NER est une tâche difficile car beaucoup de mots disposent de différentes signification basées sur le contexte utilisé. Donc, les outils NLP ou APIs doivent comprendre l’intégralité du contexte autour des termes afin de pouvoir les identifier en tant qu’entité particulière.
J’ai proposé un aperçu plutôt détaillé de cette API et des entités en particulier dans un article sur opensource.com si vous voulez en savoir plus sur le contexte avant de finir cet article.
Une fonctionnalité intéressante de l’API Google Language, en plus de la détection d’entités pertinente, est qu’elle montre les relations entre les entités et le document global (saillance). Pour certaines d’entre elles, elle fournit un article Wikipedia lié (knowledge graph) représentant l’entité.
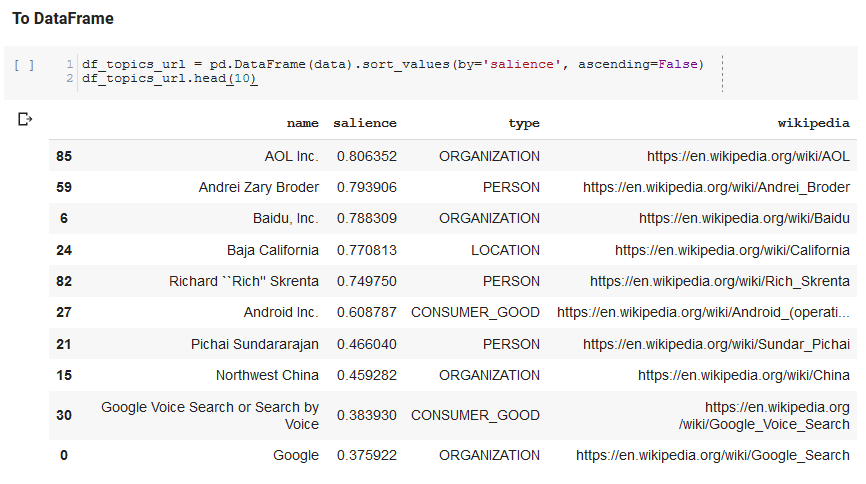
Voici un échantillon des éléments renvoyés par l’API (classés par saillance) :
Python
Python est un langage informatique devenu plutôt populaire dans le domaine du data science grâce à ses librairies importantes et grandissantes qui simplifient l’ingestion, le nettoyage, la manipulation et l’analyse d’importants jeux de données. Il bénéficie également d’un environnement collaboratif appelé les Jupyter notebooks qui permettent aux utilisateurs de facilement tester et annoter leur code sans efforts.
Pour cette analyse, nous allons utiliser quelques librairies clés qui vont nous permettre de réaliser des actions intéressantes avec les données NLP de Google. (lien)
- Pandas : imaginez pouvoir scripter Microsoft Excel pour lire, enregistrer, passer ou arranger des feuilles de calcul et vous aurez une idée de ce que fait Pandas. Pandas est incroyable.
- Networkx : Networkx est un outil permettant de construire des graphiques de noeuds et de sections qui définissent les relations entre les noeuds. Il dispose aussi d’un support intégré pour tracer les graphiques afin qu’ils soient faciles à visualiser. (lien)
- Pywikibot : Pywikibot est une librairie qui vous permet d’interagir avec Wikipédia pour rechercher, éditer et trouver des relations avec tous les contenus pour chaque site Wikipedia. (lien)
Le processus
Nous partageons un carnet Google Colab ici qui peut être utilisé pour suivre le processus. (Remerciements spéciaux à Tyler Reardon pour la relecture de cet article et du carnet.)
Configuration
Les premiers éléments du carnet expliquent l’installation de librairies, rendent ces librairies disponibles pour Python et fournissent des crédits et fichiers de configuration pour l’API de Google Language et Pywikibot, respectivement. Voici toutes les librairies que nous devons installer pour nous assurer que l’outil puisse fonctionner :
- pandas
- requests
- httplib2
- google-cloud-language
- pywikibot
- networkx
- validators
- Bs4
Note : La partie la plus difficile pour exécuter ce carnet est d’obtenir les crédits de Google pour accéder à leurs APIs. Pour les lecteurs qui n’ont jamais été confrontés à cela avant, il vous faudra peut-être une heure ou deux avant de trouver la solution. Nous avons inséré un lien vers les instructions pour obtenir les crédits tout en haut du carnet pour vous aider. Ci-dessous, vous trouverez un exemple montrant comment nous avons inclus les nôtres.
Fonctionnalités pour le gain
Dans la cellule indiquée par “Define some functions for Google NLP”, nous avons développez 8 fonctions qui gèrent des choses comme l’interrogation de l’API Language, l’interaction avec Wikipedia, l’extraction de textes de pages web et la construction de graphiques tracés. Les fonctionnalités sont principalement de petites unités de code qui assimilent des configurations de données, travaillent et produisent quelque chose. Tous les fonctionnalités sont programmées pour dirent quelles variables elles prennent et ce qu’elles produisent.
Tester l’API
Les deux cellules suivantes prennent une URL, retirent le texte de L’URL et les entités de l’API Google Language. L’une retire seulement les entités qui ont des URLs Wikipedia et l’autre toutes les entités de la page.
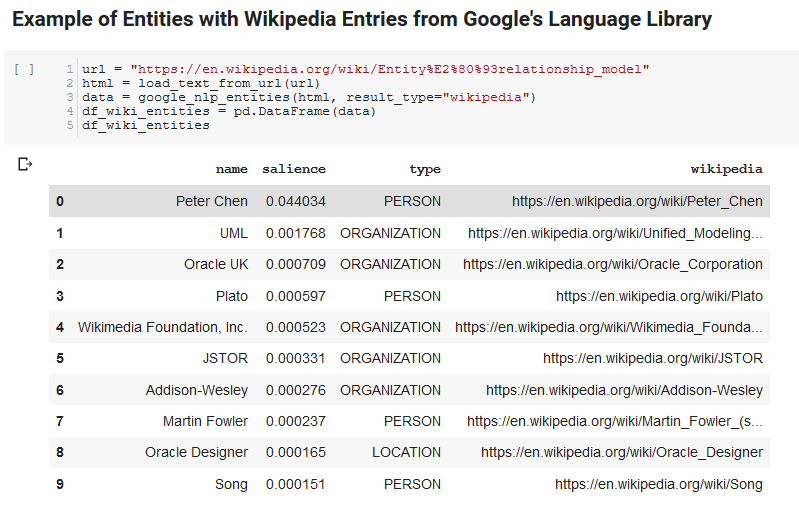
Il s’agit d’une première étape importante pour comprendre l’extraction de contenu correctement et comprendre comment fonctionne l’API Language et renvoie les données.
Networkx
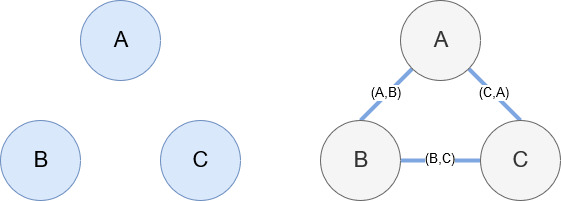
Networkx, comme mentionné précédemment, est une excellente librairie, plutôt intuitive. Vous devez lui mentionner quels sont vos noeuds et comment ils sont connectés entre eux. Par exemple, sur l’image ci-dessous, nous avons donné 3 noeuds à Networkx (A, B, C). Nous lui avons ensuite dit qu’ils étaient connectés par des sections (A, B), (B, C), (C, A), définissant les relations entre les noeuds. Pour notre utilisation, les entités avec les URLs Wikipedia seront les noeuds et les sections sont définies par de nouvelles entités trouvées sur une page d’entité actuelle. Donc, si vous examinez la page Wikipedia pour l’entité A et que l’entité B est découverte, alors il s’agit d’une section entre l’entité A et l’entité B.
L’assemblage
La prochaine section du carnet est appelée “Wikipedia Topic Branching by URL”. C’est là que la magie se produit ! Nous avons défini une fonction spéciale (recurse_entities) plus tôt qui parcourt les pages sur Wikipedia suivant les nouvelles entités définies par l’API Google Language. Nous avons aussi ajouté une fonction vraiment difficile à comprendre (hierarchy_pos) que nous avons relevé dans Stack Overflow qui fait un excellent travail pour présenter une arborescence avec de nombreux noeuds. Dans la cellule ci-dessous, nous avons défini le input par “Search Engine Optimization” et spécifié une profondeur de 3 (cela correspond au nombre de pages suivies) et une limite de 3 (combien d’entités relevées par page).
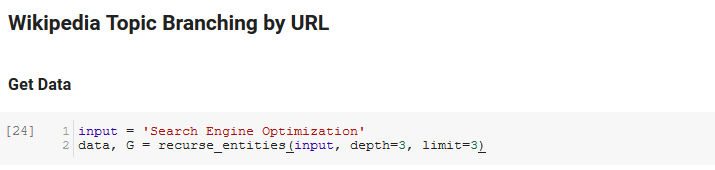
En lançant la fonction pour le terme “Search Engine Optimization”, nous pouvons voir le chemin que l’outil a emprunté, en commençant par la page Search Engine Optimization de Wikipedia (niveau 0) et en suivant automatiquement les pages jusqu’à une profondeur spécifiée (3).

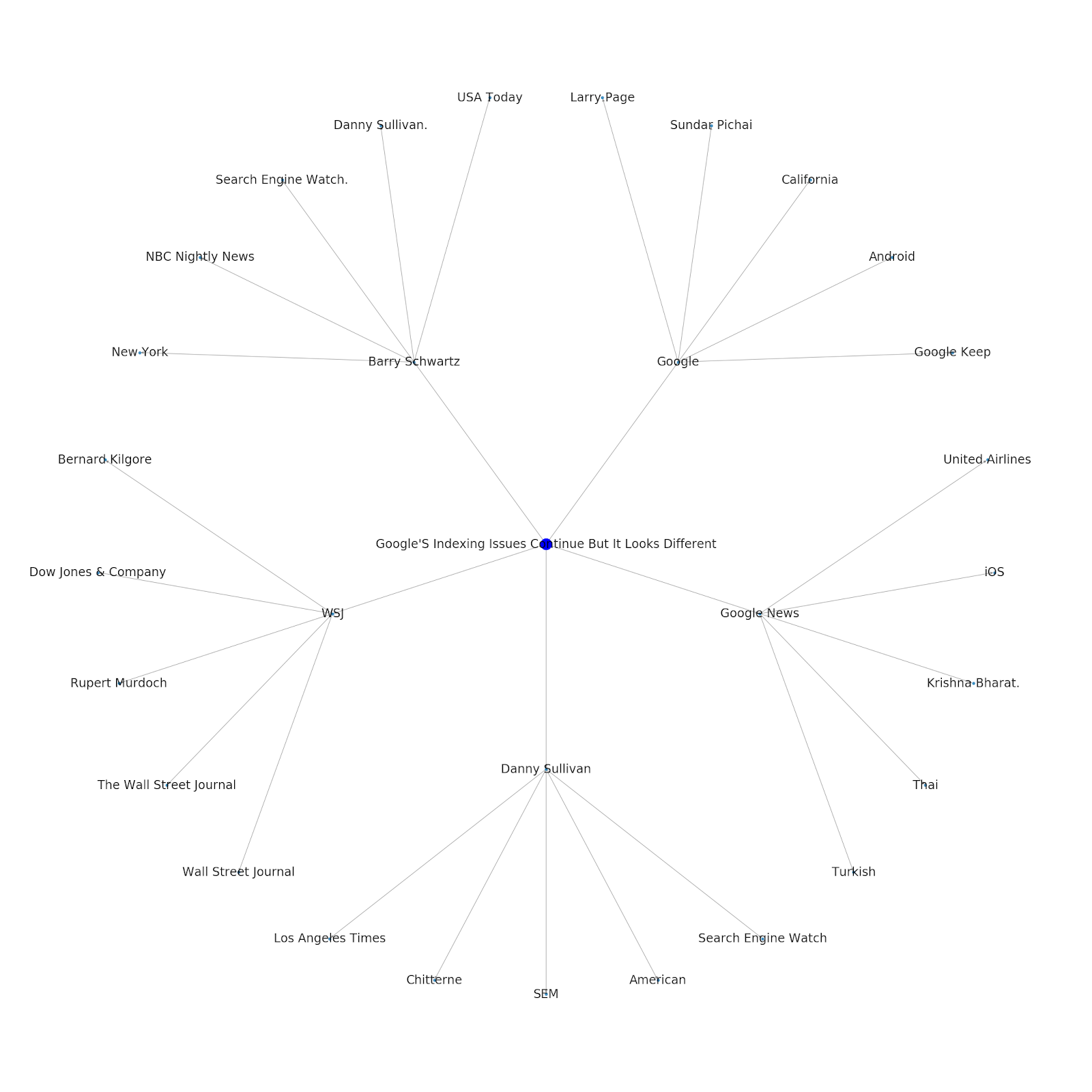
Puis, nous prenons toutes les entités trouvées et les ajoutons à un DataFrame Pandas, ce qui nous permet de les sauvegarder en CSV. Nous trions ces données par saillance (qui correspond à l’importance de l’entité pour la page sur laquelle elle a été trouvée). Mais ce score est un peu trompeur dans ce contexte parce qu’il ne vous dit pas dans quelle mesure l’entité est liée à votre terme de départ (“Search Engine Optimization”). Nous laissons cette piste à creuser aux lecteurs.
Enfin, nous avons tracé le graphique construit par l’outil pour montrer les connectivité entre les entités. Dans la cellule ci-dessous, les paramètres que vous pouvez analyser avec la fonction sont : (G : le graphique construit avant par la fonction recurse_entities, w : la largeur du tracé, h : la hauteur du tracé, c : le pourcentage circulaire du tracé, et filename : le fichier PNG qui est sauvegardé dans le dossier images.)

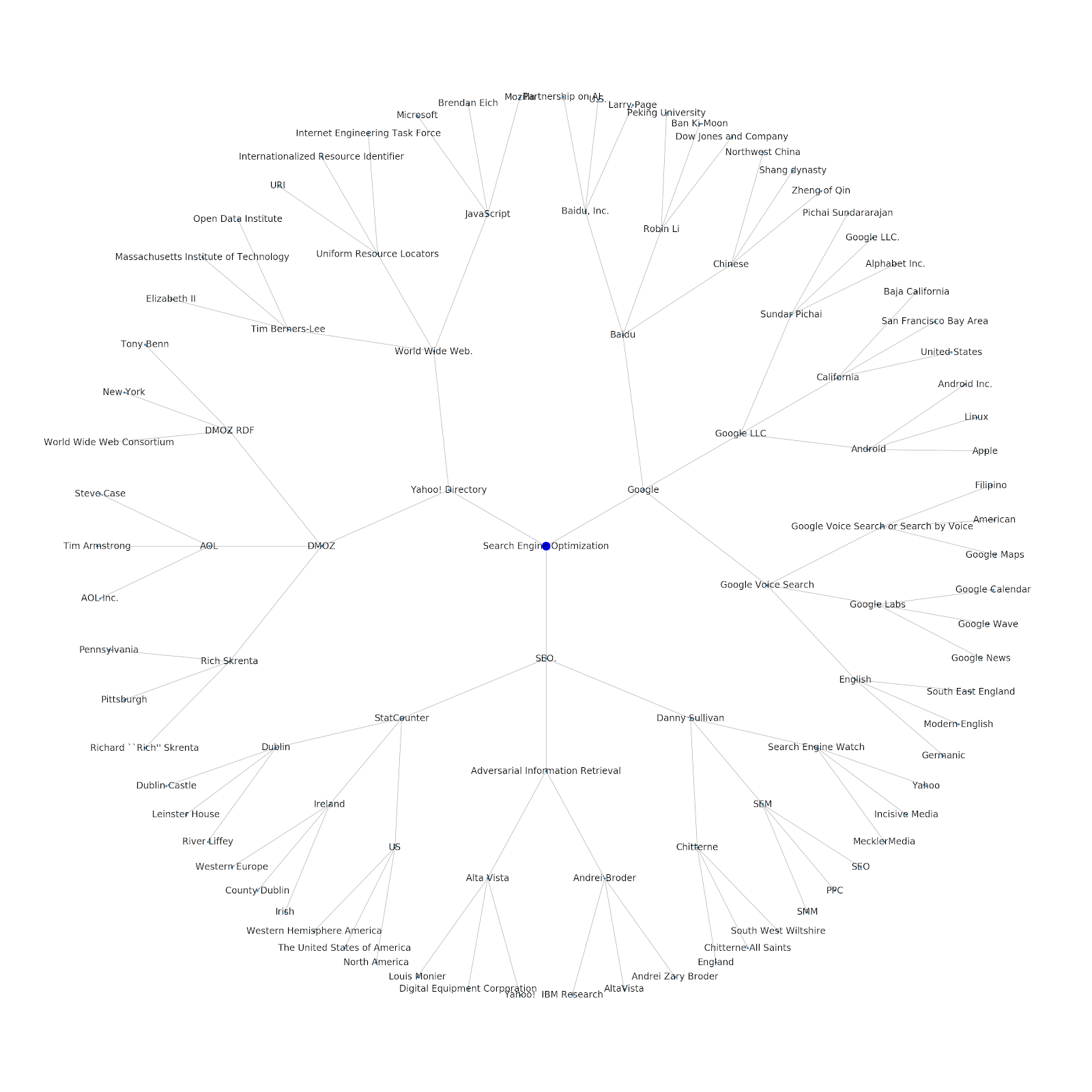
Nous avons ajouté la possibilité de donner soit un sujet de départ ou bien une URL. Dans ce cas, nous allons observer les entités associées à l’article Google’s Indexing Issues Continue But This One Is Different.
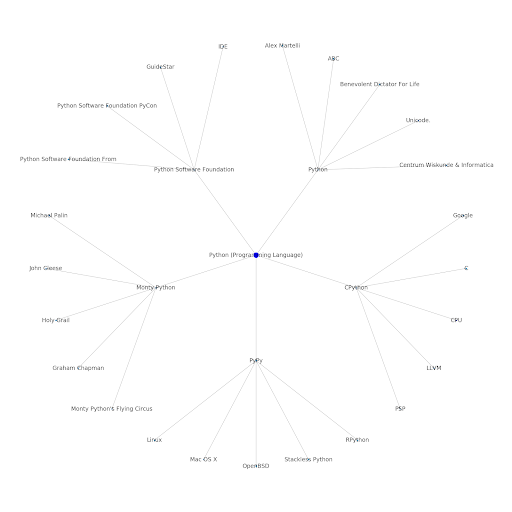
Voici le graphique d’entité Google/Wikipedia pour Python.
Ce que cela signifie
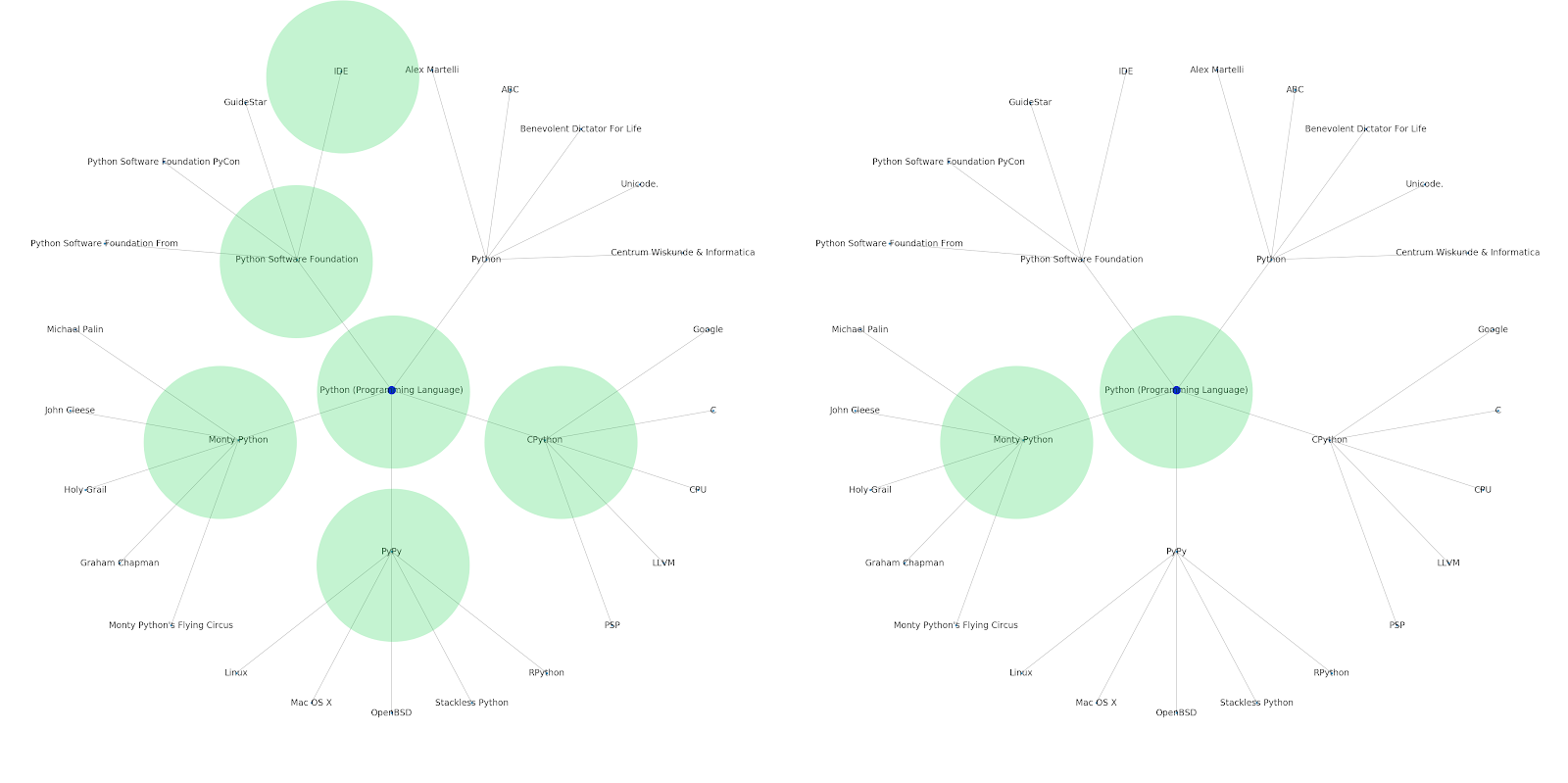
Comprendre les strates de sujets disponibles sur internet est intéressant d’un point de vu SEO car cela vous force à penser en termes de connections et pas seulement en requêtes individuelles. Depuis que Google utilise ces strates pour lier les affinités d’un utilisateur individuel à des sujets, comme mentionné dans leur réintroduction à Google Discover, ces workflows pourraient devenir plus importants pour les SEOs. Dans le graphique “Python” ci-dessus, nous pouvons déduire que la familiarité d’un utilisateur avec les sujets liés à une thématique de départ dépend de leur niveau d’expertise avec ce dernier. L’exemple ci-dessous montre deux utilisateurs, le vert reflétant leur historique d’intérêts ou affinités avec les sujets liés. L’utilisateur sur la gauche, comprend ce que sont un IDE, PyPy et CPython, et semble être un utilisateur de Python plus avancé que l’autre qui n’a pas de connaissances avancées sur le sujet. Cela rend bien simple de transformer ces données en score pour chaque sujet et utilisateur.
Conclusion
Mon objectif aujourd’hui était de partager un processus standard que j’utilise pour tester et étudier l’efficacité de différents outils ou APIs en utilisant Jupyter Notebooks. Explorer le topic graph est incroyablement intéressant et nous espérons que vous trouverez les ressources nécessaires dans cet article pour commencer à explorer le topic graph par vous-même. Avec ces outils, vous êtes désormais capables de construire des topic graphs qui analysent de nombreux niveaux de relations, seulement limitées par le quota de l’API de Google Language (qui est e 800 000 par jour). Si vous souhaitez améliorer le carnet ou trouvez des cas intéressants, n’hésitez pas à me le faire savoir. Vous pouvez me trouver sur Twitter à @jroakes.
