
Cet article de Bill Hunt, président et fondateur de Back Azimuth, montre comment une gestion centralisée de l’index peut permettre de découvrir et de résoudre des problèmes dont vous ne soupçonniez peut-être pas l’existence.
La couverture de l’index est une question clé pour les sites web internationaux. Les pages de sites web qui ne sont jamais indexées par les moteurs de recherche ne peuvent pas apparaître dans les résultats de recherche. Cela a des effets néfastes évidents sur la visibilité et le business en raison de l’impact négatif sur les éléments du hreflang.
Les produits qui n’apparaissent pas dans les résultats de recherche ne se vendent pas aussi bien. En ce qui concerne les sites internationaux, si aucune langue locale ou page de pays n’est indexée, la page internationale ou la page d’un autre pays peut apparaître à la place, ce qui est source de confusion et de frustration pour les consommateurs. Imaginez l’utilisateur australien qui clique sur votre annonce dans Google et qui arrive sur une page avec le prix en livres sterling… ou pire encore, un prix avec le signe du dollar, mais il s’agit en fait de dollars américains et non australiens.
Google a démontré l’importance de la couverture de l’index en mettant à disposition plusieurs ensembles d’informations dans sa console de recherche. Ces rapports montrent ce qu’ils ont indexé, ce qu’ils ont exclu et les multiples types d’erreurs. Il s’agit d’une liste exhaustive des choses à faire dans le cadre du nettoyage d’un site. C’est pourquoi l’une des premières choses à faire sur toute liste de contrôle SEO technique est de vérifier le rapport de couverture et le taux d’indexation d’un site web. (Google a quitté le rapport sur le ciblage international pour que vous puissiez réparer les pages. Ils ne peuvent pas vous trouver d’alternatives hreflang pour vous, car elles ne sont pas indexées).
Malheureusement, pour de nombreuses marques internationales, cela n’arrive jamais.
Malgré les problèmes que peuvent poser les questions de couverture des indices et leur impact direct sur le chiffre d’affaires, de nombreuses entreprises ayant des marques et des sites mondiaux ne disposent pas d’un protocole solide pour gérer et surveiller cette fonction essentielle. Voici deux exemples de problèmes pour lesquels une solution gérée de manière centralisée était nécessaire pour garantir le bon fonctionnement du site.
Cas n° 1 – Produits manquants sur les marchés e-commerce internationaux
Profil du site web
- L’industrie : e-commerce international
- Nombre de versions par pays/langue : 44
- Nombre de SKU (produits) par pays : 3000
Le problème : des produits manquants et des sitemaps générés par le CMS peu fiables
Nous avons importé tous les sitemaps XML dans HREFLang Builder. Nous nous attendions à 3 000 URLs dans le XML de chaque site, pour un total d’environ 132 000 URLs.
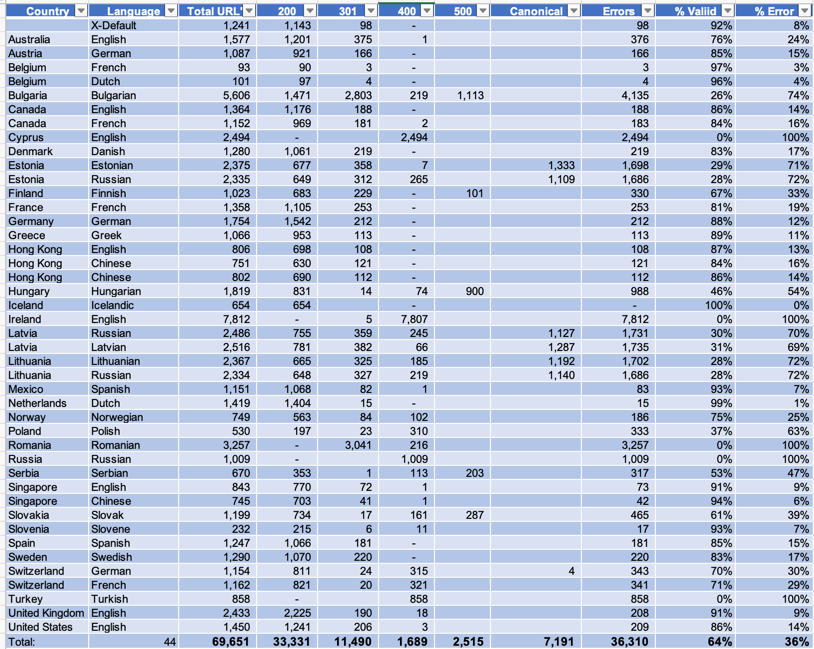
Cependant, aucun des marchés n’avait 3000 URLs. En moyenne, les sites n’ont eu que 1500, soit environ la moitié de ce qui était prévu. Pour compliquer encore les choses, parmi les URL répertoriées, 36% avaient une sorte de code d’état non indexable.
Sur l’ensemble des 44 marchés, 25 % seulement des URLs en moyenne ont été soumises via des sitemaps. Nous avons dû conclure que ces sitemaps générés par le CMS n’étaient pas fiables et nous avons dû trouver une solution pour augmenter les sitemaps XML comme source d’URL. La meilleure option était d’utiliser les URLs valides d’un outil de diagnostic SEO comme Oncrawl. Cela nous a permis de capturer et de fusionner les URLs crawlables avec celles du CMS afin d’obtenir le plus grand nombre d’URLs valides.
Cas n° 2 – Les mauvaises pages de marché apparaissant dans les résultats de recherche
Profil du site web
- L’industrie : Marque de consommation multinationale
- Nombre de versions par pays/langue : 165
Problème observé : mauvaises pages de marché dans les résultats de recherche
Le deuxième projet a débuté sous la forme d’une marque de consommation multinationale qui voulait résoudre un problème de mauvaises pages de marché apparaissant dans les résultats de recherche. Par exemple, en Thaïlande, c’est le site global qui s’affichait au lieu du site de la marque thaïlandaise. Au Maroc, douze sites de pays différents ont été représentés pour leur assortiment de mots-clés et une seule page marocaine est apparue dans les résultats. Cette situation était source de confusion et de frustration pour les consommateurs et les responsables des marques sur les différents marchés.
Le problème : Des URLs manquantes, infrastructure ancienne et mise en œuvre difficile des hreflangs
La mise en place des balises hreflang s’est avérée plus difficile que l’équipe SEO ne l’avait prévu. La majorité des sites se trouvaient sur des systèmes CMS distincts. Les conventions d’appellation varient considérablement d’un site à l’autre, ce qui rend impossible l’utilisation de noms de pages correspondant exactement à ceux du site. Il a finalement été jugé impossible d’utiliser les balises hreflang sur les pages elles-mêmes.
Cela en faisait un candidat parfait pour le projet HREFLang Builder.
En raison de la diversité des structures des domaines et des sites, Back Azimuth a dû élaborer une matrice d’admission de la langue du pays qui répertorie le site web, le pays, la langue et la source URL.
La première chose que nous avons constatée est que près de 70 % des sites n’avaient pas de sitemaps XML. Près d’un tiers d’entre eux étaient alimentés par d’anciens systèmes CMS qui ne pouvaient pas les développer.
Les autres sites ont connu des problèmes de qualité comme la première étude de cas, ou n’ont répertorié qu’une petite partie des URLs.
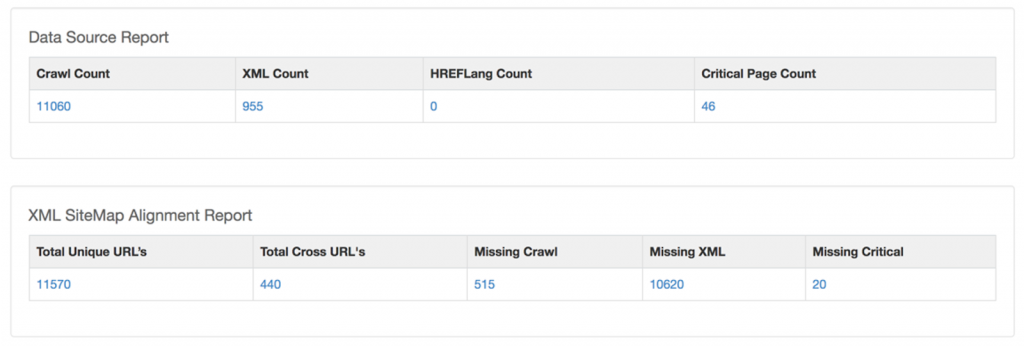
Dans la capture d’écran ci-dessous de notre « Outil d’alignement des pages », la différence de nombre de pages d’une source à l’autre est évidente :
- Le crawler SEO a trouvé un peu plus de 11 000 URLs indexables avec un code d’état de 200.
- Le CMS n’en a signalé que 944.
- Le client suivait 46 URLs en tant que « pages d’atterrissage préférées » pour des mots-clés essentiels dans son outil de vérification de classement.
Après avoir fusionné les listes d’URLs des différentes sources (sitemaps, données de crawl et CMS), seules 440 URLs ont été signalées par les trois sources. Près de 10 000 URLs, dont plus de la moitié de la liste des URLs critiques du client, étaient absentes des sitemaps XML générés par le CMS.
Collaborer avec les équipes internationales de DevOps pour trouver des solutions
Dans le cadre de ces deux projets, l’équipe de DevOps a réalisé qu’elle devait trouver un moyen de gérer de manière centralisée ses sitemaps XML et HREFLang afin de faire en sorte que le plus grand nombre possible de pages soient soumises et indexées par Google.
Ils ont demandé de l’aide et, en collaboration avec les équipes de Back Azimuth, ils ont décomposé la solution en une série de défis :
- Défi 1 – Obtenir une liste maîtresse de toutes les URLs pour chaque site
- Défi 2 – Création des sitemaps XML HREFLang
- Défi 3 – Soumettre à Google
- Défi 4 – Maintenir les sitemaps XML
- Défi 5 – Suivi des résultats
HREFLang Builder et Oncrawl comme solution pour l’alignement des marchés
Mise en place : relever les défis de la centralisation et de l’automatisation
En raison de la nature décentralisée de l’hébergement du site et de l’assistance informatique sur les différents marchés, l’idée que nous puissions faire télécharger des fichiers sur des serveurs locaux a été rapidement rejetée.
Il était plutôt prévu de créer un hôte central pour les fichiers XML. Cela a permis de résoudre une grande partie du deuxième objectif d’automatisation. En utilisant un domaine en dehors du site principal, HREFLang Builder pourrait automatiquement télécharger des mises à jour.
Pour des raisons de sécurité, il a été décidé d’utiliser un domaine dédié pour héberger les sitemaps XML par domaine et tirer parti de la vérification interdomaines. Pour permettre la vérification interdomaine, nous avons dû créer des comptes Google Search Console pour tous les sites web dans un compte GSC maître. Là encore, la nature des sites web rendait impossible le téléchargement d’un fichier html ou le balisage des pages.
À l’exception de quelques domaines, tous ont été gérés et enregistrés de manière centralisée par l’équipe mondiale de DevOps. En moins d’une journée, ils ont pu soumettre et enregistrer les validations, ce qui a permis de réduire de plusieurs mois le temps estimé pour obtenir les validations de façon traditionnelles.
Défi 1 – Obtenir une liste maîtresse de toutes les URLs pour chaque site
L’un des plus grands défis a été de créer une liste maîtresse d’URLs indexables pour chaque site.
Nous utiliserons les sitemaps XML existants, la liste des URLs prioritaires et les résultats des diagnostics de crawl.
La bonne nouvelle est que les équipes SEO en internes des deux entreprises utilisent Oncrawl comme outil de diagnostic. Nous avons paramétré les deux sites dans Oncrawl et avons exploité leur API pour permettre à HREFLang Builder d’importer leur rapport « 200 Indexable » d’URLs valides de manière transparente dans HREFLang Builder.
Défi 2 – Création des sitemaps XML HREFLang
Tous les sites étant configurés dans Oncrawl, nous nous sommes connectés à l’API et avons ensuite ajouté la liste principale des sitemaps XML et des fichiers d’index dans le gestionnaire d’importation d’URL AutoUpdate de HREFLang Builder.
Nous avons importé les URLs de toutes les sources dans HREFLang Builder, les avons fusionnées puis déduites. Enfin, nous avons procédé à une deuxième vérification des URLs qui n’étaient pas dans l’importation de l’API d’Oncrawl pour nous assurer qu’elles étaient valides.
Une fois que nous avons eu notre première importation d’URLs, le système a pu commencer à les faire correspondre et à créer des sitemaps XML.
Dans HREFLang Builder, vous avez la possibilité de choisir de n’exporter que les URLs correspondantes ou d’exporter toutes les URLs. Nous avons choisi l’option « All URL » afin de pouvoir utiliser la sortie pour les URLs qui n’avaient pas d’équivalent dans chaque marché.
Défi 3 – Soumettre à Google
En moins d’une heure, nous avions des sitemaps XML pour chaque pays et chaque version linguistique. Nous les avons téléchargées sur le serveur central et elles ont envoyé un message automatique à Google pour informer le moteur de recherche qu’elles étaient prêtes à être indexées.
Défi 4 – Maintenir les sitemaps XML
La solution que nous avons proposée devait permettre de cartographier les nouvelles URLs dans tous les pays et toutes les langues afin de maintenir les sitemaps à jour. Pour cela, nous avons développé un tableau de correspondance entre les différentes versions.
Certaines des connexions étaient plus simples que d’autres. Comme nous l’avons mentionné, certains sites utilisaient déjà la même structure et la même adresse URL. Et dans le cas du site de e-commerce, nous avons pu faire correspondre des pages basées sur le SKU globale même s’il y avait peu de ressemblance entre les URLs.
Cependant, dans le cas du site de la marque, nous avons dû élaborer un tableau de correspondance manuel. Le premier objectif que nous avons atteint était de cartographier les pages critiques identifiées par le client où la version incorrecte était classée.
Défi 5 – Suivi des résultats
Grâce aux rapports de classement et aux rapports de couverture de la console de recherche Google, les équipes internes sont en mesure de suivre les projets.
Leçons apprises
Les problèmes de couverture de l’indice peuvent nécessiter de la créativité pour les résoudre, en particulier lorsqu’ils impliquent une infrastructure de site web distribuée et des équipes de marché individuelles. Mais, étonnamment, les plus grands défis techniques sur les sites ayant de nombreuses versions et de langues sont d’obtenir une liste maîtresse des URLs des sites, et de faire correspondre ces URLs d’une version de site à une autre.
En déployant la stratégie centralisée que nous avons expliquée ici, et en utilisant les puissants outils de diagnostic d’Oncrawl et les fonctionnalités d’agrégation et de gestion de HREFlang Builder, nous avons pu résoudre de manière collaborative un problème majeur pour ces clients et contribuer à récupérer d’importantes pertes de revenus.
Dans ces deux cas, les taux d’indexation ont augmenté et ils ont constaté une réduction des erreurs canoniques et une meilleure mise en page alternative. Le trafic et les ventes des filiales locales ont donc augmenté de manière exponentielle, car la bonne page s’affichait dans les résultats de recherche et permettait aux visiteurs d’acheter facilement.
Il aurait été impossible de résoudre ces problèmes dans le cadre des systèmes CMS disponibles ou sur les marchés locaux.
C’est un exemple de résolution de problèmes que nous sommes capables de faire à Back Azimuth en utilisant HREFLang Builder et nos partenariats techniques.
