
Le contenu est l’une des principales forces d’une stratégie de marketing, et l’optimisation des moteurs de recherche (SEO) fait partie intégrante du fonctionnement de cette stratégie. En général, cela couvre les bases du référencement on-page : structure de l’article, placement des mots clés, balises meta, balises titre, texte alt, titres, données structurées et utilisation du formatage pour créer des données structurées de manière informelle dans des listes et des tableaux.
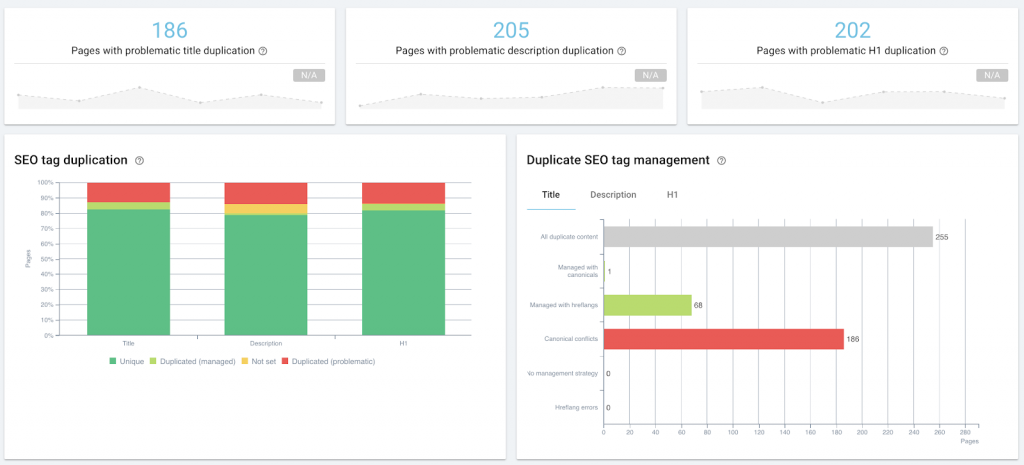
Audit du référencement des pages dans le cadre de la gestion du contenu, en utilisant Oncrawl.
Cela relève du SEO technique lorsque vous commencez à optimiser ou à surveiller, que ce soit par des audits de sites ou des crawls réguliers, par des méta descriptions en langage naturel générées par des machines, des balises de contrôle de snippet ou l’injection de données structurées.
Cependant, l’intersection du SEO technique et du marketing de contenu est encore plus importante en ce qui concerne les performances du contenu : nous examinons les mêmes données primaires, telles que le classement des pages sur les SERP, ou le nombre de clics, d’impressions et de sessions. Nous pouvons mettre en œuvre les mêmes types de solutions, ou utiliser les mêmes outils.
Qu’est-ce que la performance de contenu ?
La performance du contenu est le résultat mesurable de la façon dont le public interagit avec le contenu. Si le contenu est le moteur du trafic entrant, les mesures de ce trafic reflètent la qualité ou la faiblesse du contenu. Chaque stratégie de contenu devrait, sur la base d’objectifs concrets, définir ses propres KPI. La plupart comprendront les mesures suivantes :
- La visibilité du contenu dans la recherche (impressions dans les SERP)
- La pertinence du contenu selon les moteurs de recherche (classement sur les SERP)
- La pertinence de la liste de recherche du contenu selon les chercheurs (clics des SERP)
- Combien de personnes consultent le contenu (visites ou sessions dans une solution d’analyse)
- Combien de personnes interagissent avec le contenu d’une manière qui favorise les objectifs commerciaux (suivi de la conversion)
Jusqu’à présent, tout va bien.
La difficulté est de placer le curseur : quels chiffres signifient que vous avez une bonne performance de contenu ? Qu’est-ce qui est la norme ? Et comment savoir si quelque chose ne va pas bien ?
Ci-dessous, je vais partager mon expérience pour construire une « preuve de concept » d’un outil de faible technicité pour aider à répondre à ces questions.
Pourquoi exiger une norme pour la performance du contenu ?
Voici quelques-unes des questions auxquelles je voulais répondre dans le cadre de mon propre examen de la stratégie en matière de contenu :
- Existe-t-il une différence entre le contenu interne et les postes des contributeurs en termes de performance ?
- Y a-t-il des sujets sur lesquels nous insistons et qui ne donnent pas de bons résultats ?
- Comment puis-je identifier les messages « evergreen » sans attendre trois ans pour voir s’ils attirent toujours un trafic hebdomadaire ?
- Comment puis-je identifier les petits coups de pouce de la promotion par des tiers, par exemple lorsqu’un message est repris dans une newsletter qui n’était pas dans notre scope, afin d’adapter immédiatement notre propre stratégie de promotion et de tirer parti de la visibilité accrue ?
Pour répondre à ces questions, vous devez cependant savoir à quoi ressemble la performance « normale » du contenu du site sur lequel vous travaillez. Sans cette base de référence, il est impossible de dire quantitativement si un élément ou un type de contenu spécifique fonctionne bien (mieux que la base de référence) ou non.
La façon la plus simple de définir une base de référence est de regarder la moyenne des sessions par jour après la publication, par article, où le jour zéro est la date de publication.
Cela produira une courbe qui ressemblera à ceci, montrant un pic d’intérêt initial (et éventuellement les résultats de toute promotion que vous faites, si vous n’avez pas limité votre analyse aux sessions provenant des moteurs de recherche uniquement), suivi d’une longue traîne de moindre intérêt :
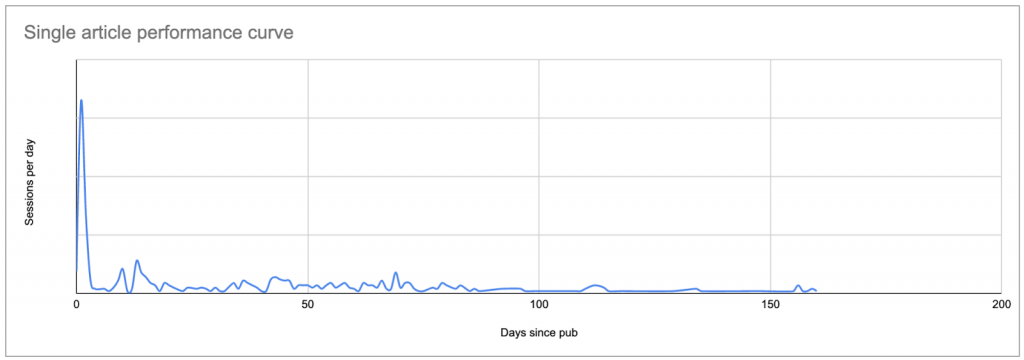
Données réelles pour un poste type : un pic à la date de publication ou peu après, suivi d’une longue traîne qui, dans de nombreux cas, finit par rapporter plus de sessions que le pic initial.
Une fois que vous savez à quoi ressemble la courbe de chaque poste, vous pouvez comparer chaque courbe aux autres et établir ce qui est « normal » et ce qui ne l’est pas.
Si vous n’avez pas d’outil pour le faire, c’est une vraie plaie.
Lorsque j’ai commencé ce projet, mon objectif était d’utiliser Google Sheets pour construire une preuve tangible avant de m’engager à apprendre suffisamment de Python pour changer ma façon d’examiner la performance des contenus.
Nous allons décomposer le processus en phases et en étapes :
- Trouver votre base de référence
– Indiquez le contenu que vous souhaitez étudier
– Découvrez combien de sessions a reçu chaque élément de contenu chaque jour
– Remplacer la date dans la liste des sessions par le nombre de jours depuis la publication
– Calculer la courbe « normale » à utiliser comme référence - Identifier les contenus qui ne ressemblent pas à la ligne de base
- Tenez-le à jour
Trouvez votre base de performance en matière de contenu
Indiquez le contenu que vous souhaitez étudier
Pour commencer, vous devez établir une liste des contenus que vous souhaitez examiner.
Pour chaque contenu, vous aurez besoin de l’URL et de la date de publication.
Vous pouvez obtenir cette liste comme vous le souhaitez, que vous la construisiez à la main ou que vous utilisiez une méthode automatisée.
J’ai utilisé un Apps Script pour extraire chaque URL de contenu et sa date de publication directement du CMS (dans ce cas précis, WordPress) en utilisant l’API, et j’ai imprimé les résultats sur une feuille Google. Si vous n’êtes pas à l’aise avec les scripts ou les API, cela reste relativement facile : vous pouvez trouver de nombreux exemples en ligne sur la manière de faire cela pour WordPress.
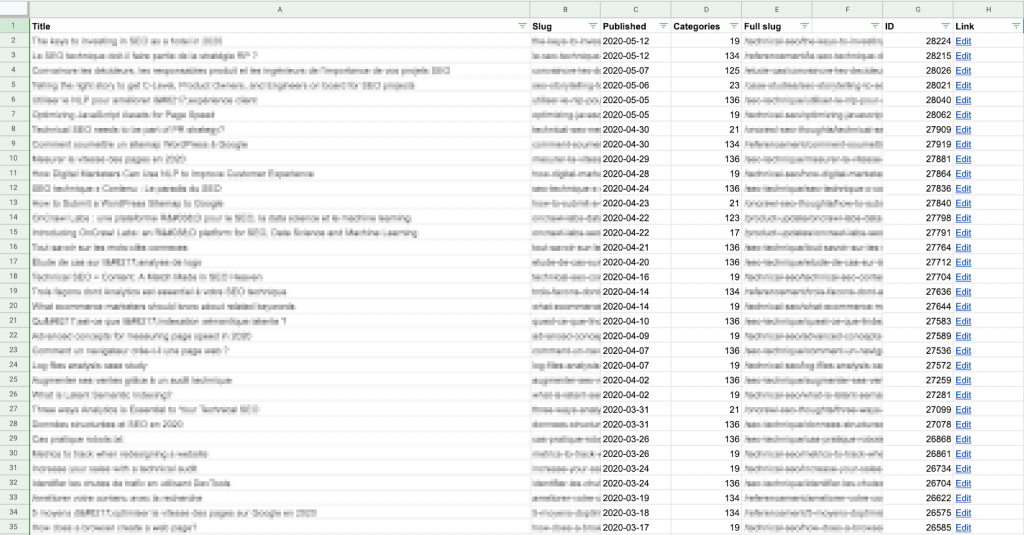
N’oubliez pas que vous devrez comparer ces données avec les données de session pour chaque article. Vous devrez donc vous assurer que le « slug » sur cette feuille correspond au format du chemin URL fourni par votre solution d’analyse.
Je trouve qu’il est plus facile de construire le slug complet (chemin URL) ici, dans la colonne E ci-dessus, plutôt que de modifier les données tirées de Google Analytics. C’est aussi moins lourd en termes de calcul : il y a moins de lignes dans cette liste !

Exemple de formule pour créer une URL complète pour ce site : recherchez le numéro de catégorie fourni par le CMS dans un tableau et retournez le nom de la catégorie, qui est placé avant le slug de l’article, correspondant au modèle d’URL pour ce site (https://site.com/categoryName/articleSlug/)
Si vous n’avez pas accès au backend, vous pouvez créer votre liste en collectant ces informations depuis votre site web lui-même, par exemple, lors d’un crawl. Vous pouvez ensuite exporter au format CSV les données que vous souhaitez, et les importer dans une feuille Google.
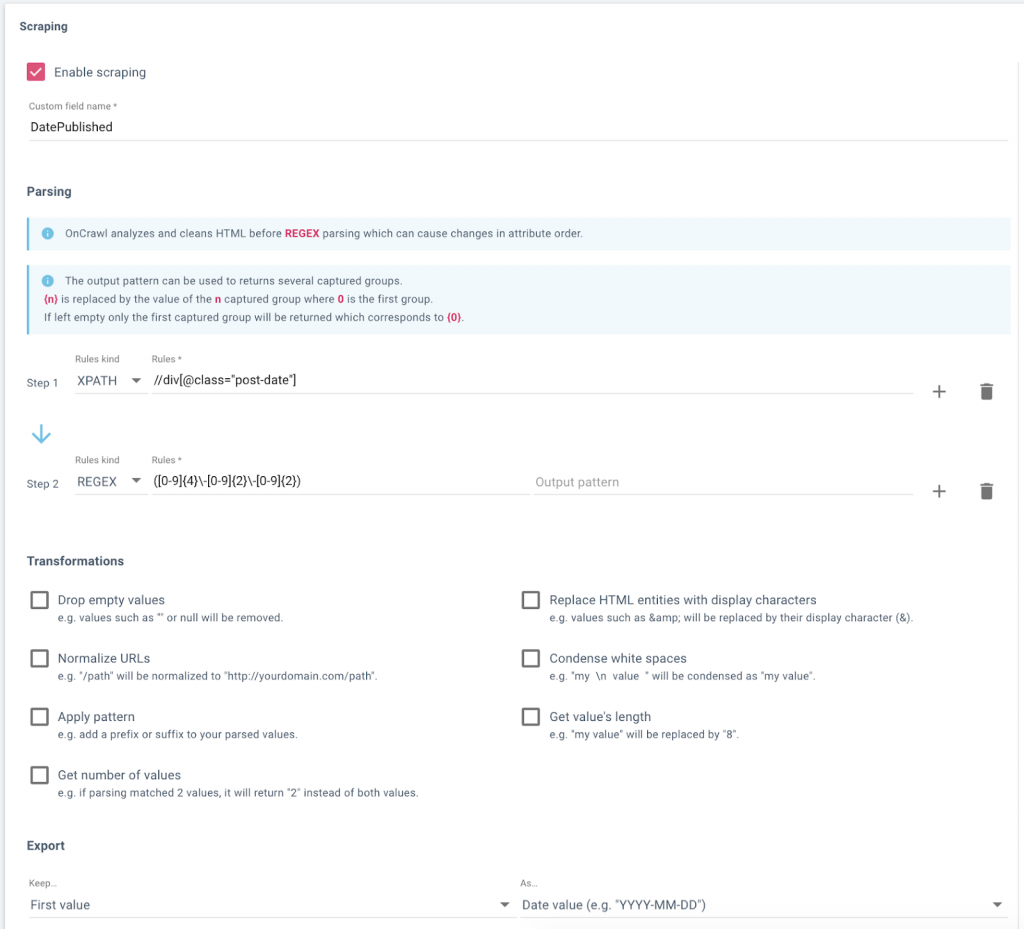
Mise en place d’un champ de données dans Oncrawl pour scrapper (collecter) les dates de publication du blog d’un site web.
Données, y compris l’URL et la date de publication scrappée, dans Data Explorer d’Oncrawl, prêtes pour l’export !
Découvrez combien de sessions par jour chaque élément de contenu a obtenu
Ensuite, vous avez besoin d’une liste des sessions par contenu et par jour. En d’autres termes, si un contenu date de 30 jours et a reçu des visites tous les jours pendant cette période, vous voulez avoir 30 lignes pour lui et ainsi de suite pour le reste de votre contenu.
Pour cela, vous aurez besoin d’une feuille séparée dans le même document.
Le module complémentaire Google Analytics de Google Sheets rend cela relativement facile.
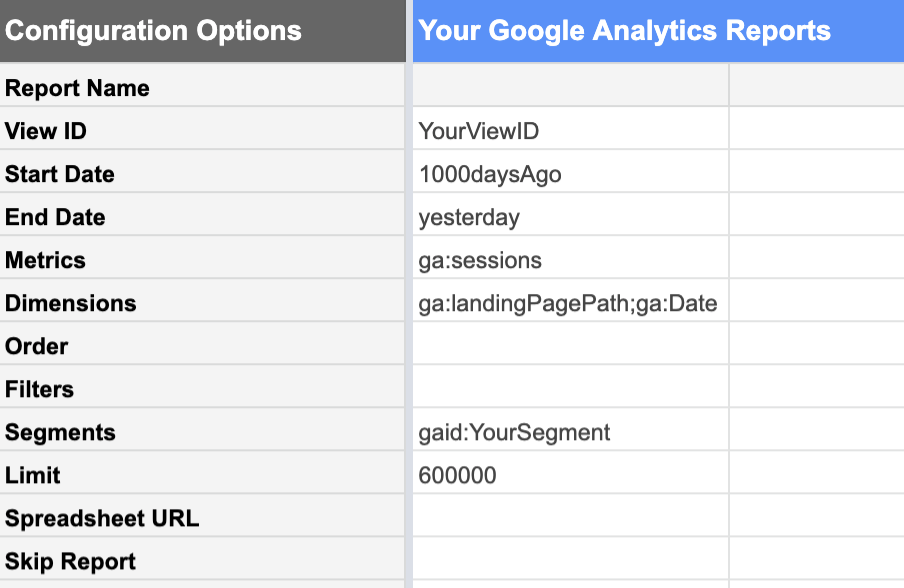
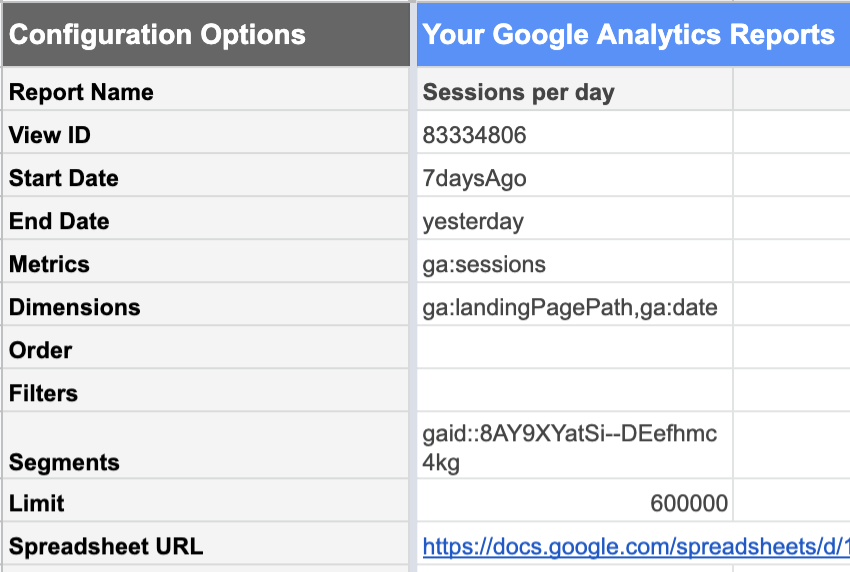
À partir de la vue Google Analytics avec les données que vous souhaitez, vous pouvez demander un rapport de :
| Dates | Métriques | Caractéristiques |
|---|---|---|
| Depuis 1000 jours Jusqu’à hier.Les données d’aujourd’hui ne sont pas encore complètes car la journée n’est pas encore terminée. Si vous l’incluez, elle ne ressemblera pas à une journée complète « normale » et fera baisser toutes vos statistiques. | Sessions Nous sommes intéressés par le nombre de sessions. | Landing Pages Cette liste énumère les sessions pour chaque landing page séparément.Date Cela permet de répertorier les sessions pour chaque date séparément, plutôt que de nous donner un total de 1000 jours… |
L’utilisation de segments de vos données Google Analytics est extrêmement utile à ce stade. Vous pouvez, par exemple, limiter votre rapport à un segment contenant uniquement les URLs de contenu que vous souhaitez analyser, plutôt que l’ensemble du site. Cela réduit considérablement le nombre de lignes dans le rapport qui en résulte et rend les données beaucoup plus simples à utiliser dans les Google Sheets.
De plus, si vous avez l’intention de ne considérer que les performances organiques à des fins strictement SEO, votre segment doit exclure les canaux d’acquisition qui ne peuvent être attribués au travail SEO : les références, l’email, le social…
N’oubliez pas de vous assurer que la limite est suffisamment élevée pour ne pas tronquer vos données par erreur.
Calculer le nombre de jours depuis la publication
Pour calculer le nombre de jours depuis la publication pour chaque point de données dans l’article, nous devons joindre les données du rapport des sessions aux données de votre liste de contenus.
Pour ce faire, utilisez l’URL ou le chemin d’accès à l’URL comme clé. Cela signifie que le chemin de l’URL doit être formaté de la même manière dans le tableau CMS et le rapport Google Analytics.
J’ai créé un tableau séparé afin de pouvoir supprimer tout paramètre de la page d’accueil dans mon rapport Analytics. Voici comment j’ai configuré mes colonnes :
- Page d’accueil
Paramètres du scrubs depuis l’URL du slug dans le rapport Analytics
Exemple de formule :

- Date
Date d’enregistrement des sessions, d’après le rapport Analytics
Exemple de formule :

- Sessions
Date d’enregistrement des sessions, d’après le rapport Analytics
Exemple de formule :

- Jours après la publication
Recherche la date de publication de cette URL dans la colonne du tableau CSM que nous venons de créer et la soustrait de la date d’enregistrement de ces sessions. Si l’URL ne peut pas être trouvée dans la table CSM, il faut imprimer une chaîne vide plutôt qu’une erreur.
Exemple de formule :
![]()
![]()
Notez que ma clé de recherche, le chemin complet de l’URL, n’est pas la colonne la plus à gauche dans mes données ; j’ai dû déplacer la colonne E avant la colonne C pour les besoins du VLOOKUP.
Si vous avez trop de lignes à remplir à la main, vous pouvez utiliser un script comme celui ci-dessous pour copier le contenu de la première ligne et remplir les 3450 suivantes environ :
function FillDown() {
var spreadsheet = SpreadsheetApp.getActive();
spreadsheet.getRange('F2').activate();
spreadsheet.getActiveRange().autoFill(spreadsheet.getRange('F2:F3450), SpreadsheetApp.AutoFillSeries.DEFAULT_SERIES);
};Calculer le nombre « normal » de sessions par jour après la publication
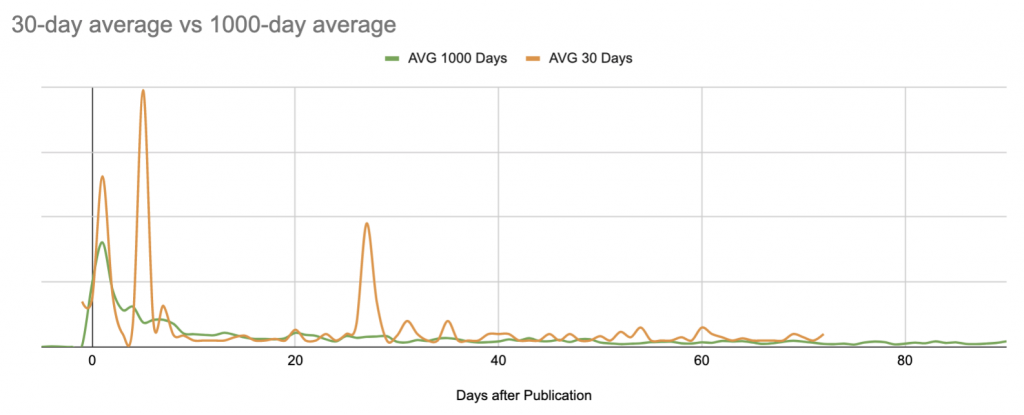
Pour calculer le nombre de sessions normales, j’ai utilisé un tableau croisé dynamique assez simple, associé à un graphique. Par souci de simplicité, j’ai commencé par examiner le nombre moyen de sessions par jour après la publication.
Voici la moyenne par rapport à la médiane des sessions sur les 1000 jours suivant la publication. Nous commençons ici à voir les limites de Google Sheets en tant que projet de visualisation de données :
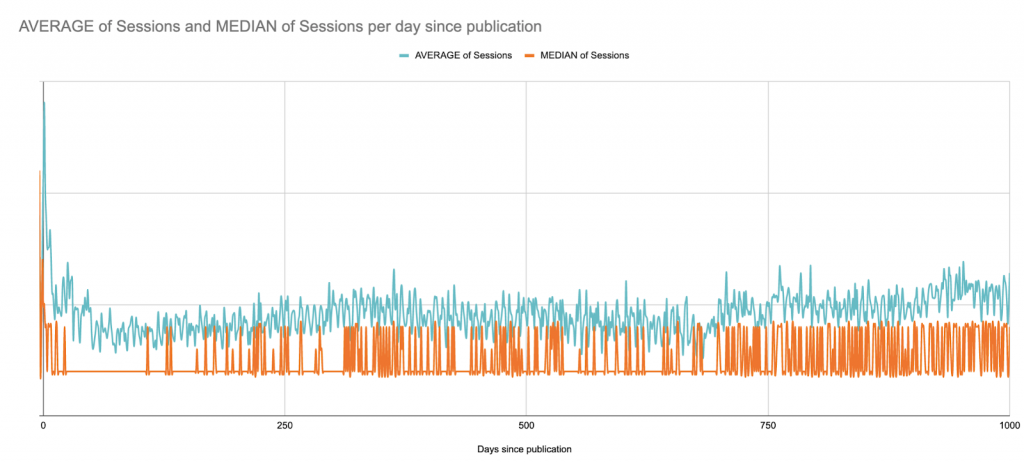
Il s’agit d’un site B2B avec des pics de session en semaine sur l’ensemble du site ; il publie des articles plusieurs fois par semaine, mais toujours les mêmes jours. Ici, les schémas hebdomadaires sont presque visibles.
Dans ce cas, à des fins de visualisation, il serait probablement préférable de regarder les moyennes mobiles sur 7 jours, mais voici une version rapide qui se contente de lisser les semaines depuis la publication :
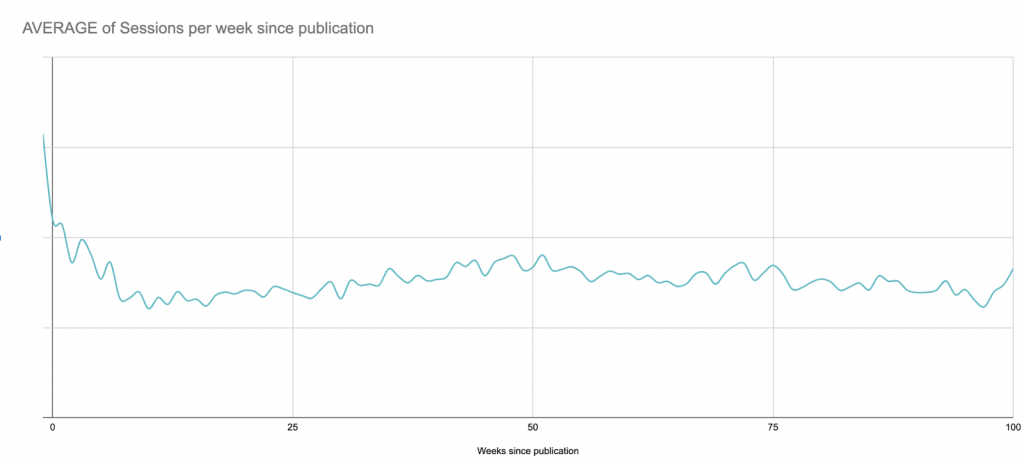
Malgré cette vision à long terme, pour les prochaines étapes, je limiterai le graphique à 90 jours après la publication afin de rester dans les limites de Google Sheets par la suite :
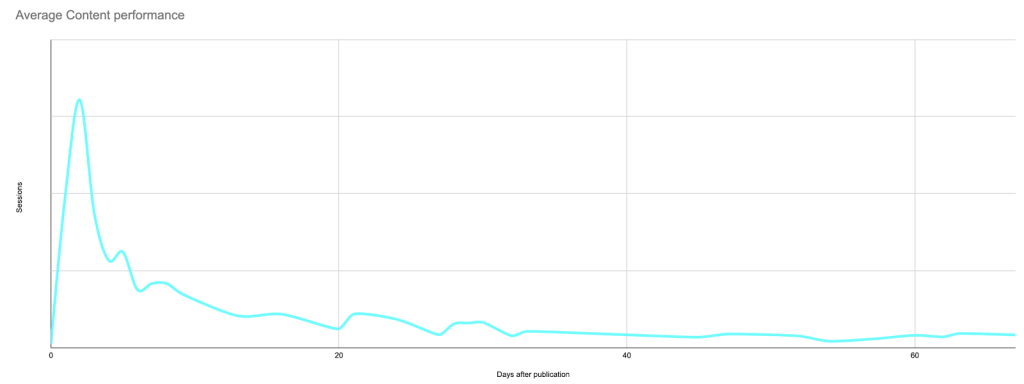
La recherche d’anomalies
Maintenant que nous savons à quoi ressemble le poste moyen un jour donné, nous pouvons comparer n’importe quel poste à la base de référence pour savoir s’il est sur- ou sous-performant.
Cela devient rapidement incontrôlable si vous le faites manuellement. Essayons au moins d’automatiser un peu tout cela.
Chaque article (datant de moins de 90 jours) doit être comparé à la base de référence que nous venons d’établir pour chaque jour dans notre créneau de 90 jours.
Pour cet élément, j’ai calculé la différence en pourcentage par rapport à la moyenne quotidienne.
Pour une analyse rigoureuse, il conviendrait d’examiner l’écart type des sessions par jour, et établir combien d’écarts types la performance de chaque élément de contenu se situe par rapport à la ligne de base. Un nombre de sessions qui correspond à trois écarts types par rapport à la performance moyenne est plus susceptible de constituer une anomalie qu’un écart de plus de X% par rapport à la moyenne de la journée.
J’ai utilisé un tableau croisé dynamique pour sélectionner chaque élément de contenu (avec les sessions des 90 derniers jours) qui a au moins un jour d’anomalies pendant cette période :
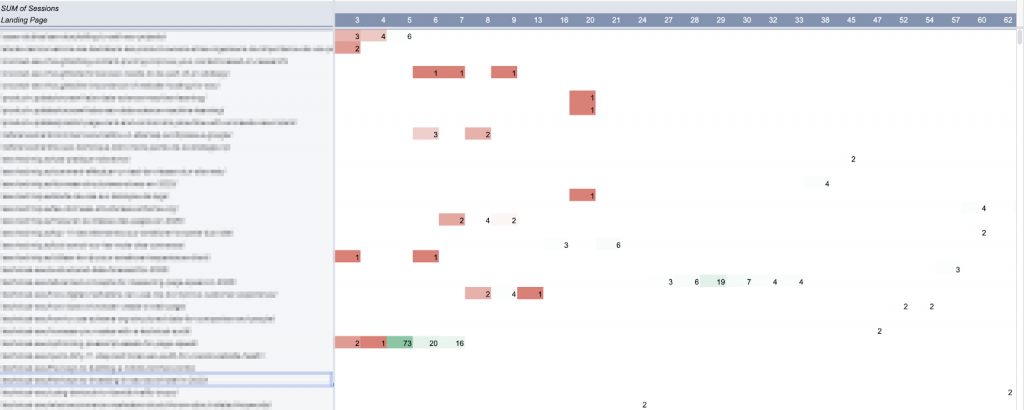
Dans Google Sheets, les tableaux croisés dynamiques ne sont pas autorisés à créer plus de 100 colonnes. D’où la limitation à 90 jours pour cette analyse.
J’ai fait un graphique de ce tableau. (Idéalement, je voudrais tracer la courbe complète de 90 jours pour chacun de ces articles, mais j’aimerais également que la feuille réponde si je clique sur une courbe).
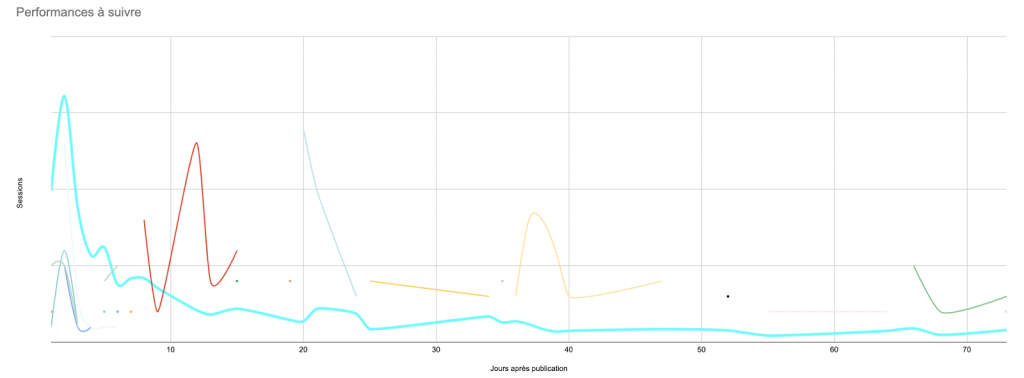
Tenir les choses à jour : automatiser les mises à jour
Il y a ici trois éléments majeurs :
- La ligne de base
- Les éléments de contenu que vous souhaitez suivre
- Les performances de ces contenus
Malheureusement, aucun d’entre eux n’est statique.
Théoriquement, les performances moyennes évolueront à mesure que vous vous améliorerez dans le ciblage et la promotion de votre contenu. Cela signifie que vous devrez recalculer la base de référence de temps en temps.
Si votre site web connaît des hauts et des bas saisonniers, il peut être intéressant d’examiner les moyennes sur des périodes plus courtes, ou sur la même période chaque année, au lieu de créer une fusion comme nous l’avons fait ici.
Au fur et à mesure que vous publierez du contenu, vous voudrez également suivre les nouveaux contenus.
Quand nous voudrons examiner la date de la session de la semaine prochaine, nous ne l’aurons pas.
En d’autres termes, ce modèle doit être mis à jour plus ou moins fréquemment. Il existe de multiples façons d’automatiser les mises à jour, plutôt que de reconstruire l’outil complet à partir de zéro chaque fois que vous souhaitez y jeter un coup d’œil.
Le plus simple à mettre en œuvre est probablement de programmer une mise à jour hebdomadaire des sessions d’analyse, et de rapporter les nouveaux postes (avec leurs dates de publication) en même temps.
Le rapport Google Analytics que nous avons utilisé peut facilement être programmé pour s’exécuter automatiquement à intervalles réguliers. L’inconvénient est qu’il écrase les rapports précédents. Si vous ne souhaitez pas exécuter et gérer le rapport complet, vous pouvez le limiter à une période plus courte.
En ce qui me concerne, j’ai constaté qu’une fenêtre de 7 jours me donne suffisamment d’informations pour travailler sans être trop dépassée.
Garder un œil sur les postes permanents en dehors de la période de 90 jours
En utilisant les données que nous avons générées précédemment, disons qu’il a été possible de déterminer que la plupart des postes ont une moyenne d’environ 50 sessions par semaine.
Il est donc logique de garder un œil sur tout poste dont les sessions hebdomadaires sont supérieures à 50, quelle que soit la date de publication :
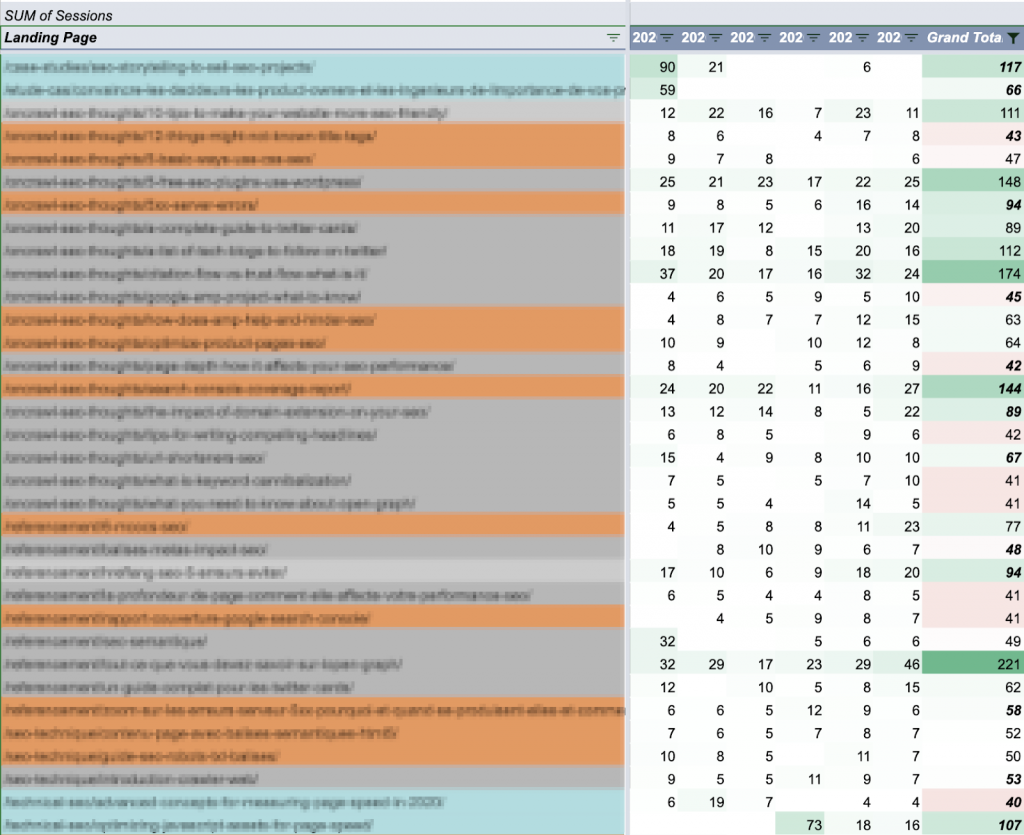
Les articles sont colorés par période de publication : 90 derniers jours (bleu), année écoulée (orange) et héritage (gris). Les totaux hebdomadaires sont codés par couleur en les comparant à l’objectif de 50 pour la session.
En décomposant le nombre total de sessions par jour dans la semaine, il est facile de faire rapidement la différence entre les postes permanents dont les performances sont assez constantes et les activités événementielles dont les performances sont inégales :
![]()
![]()
Contenu evergreen (performance constante de ±20/jour)
![]()
![]()
Promotion extérieure probable (performances généralement faibles en dehors d’un pic à court terme)
Ce que vous ferez de ces informations dépendra de votre stratégie en matière de contenu. Vous pouvez par exemple réfléchir à la manière dont ces articles convertissent les leads sur votre site web, ou les comparer à votre profil de backlink.
Limites des Google Sheets pour l’analyse de contenu
Google Sheets, comme vous l’avez probablement remarqué à ce stade, est un outil extrêmement puissant mais limité pour ce genre d’analyse. Ces limites expliquent pourquoi j’ai préféré ne pas partager un modèle avec vous : l’adapter à votre cas demanderait beaucoup de travail et les résultats que vous pourriez obtenir ne seraient encore que des approximations.
Voici quelques-uns des principaux points sur lesquels ce modèle ne donne pas de résultats :
- Il y a trop de formules.
Si vous avez beaucoup (disons des milliers) d’URLs de contenu actif, il peut être extrêmement lent. Dans mes scripts de mise à jour hebdomadaire, je remplace un grand nombre de formules par leurs valeurs une fois qu’elles sont calculées, de sorte que le fichier réagisse réellement lorsque je l’ouvre plus tard pour l’analyser.
- Ligne de base statique.
Au fur et à mesure que mes performances de contenu s’améliorent, je me retrouve avec plus de contenu « surperformant ». La ligne de base doit être recalculée tous les quelques mois pour tenir compte de l’évolution. Ce problème pourrait être facilement résolu en utilisant un modèle d’apprentissage automatique non supervisé pour calculer les moyennes (ou même pour sauter cette étape et identifier directement les anomalies par le machine learning).
- Une ligne de base « inexacte ».
La base de référence ne tient pas compte des changements saisonniers ou des incidents à l’échelle du site. Elle est également très sensible aux événements extrêmes, en particulier si vous limitez vos calculs à une période plus courte :
- Analyse statistique non fondée.
En particulier si vous n’avez pas beaucoup de sessions par jour par élément de contenu, prétendre qu’une différence de 10% par rapport à une moyenne constitue une performance inhabituelle est un peu sommaire.
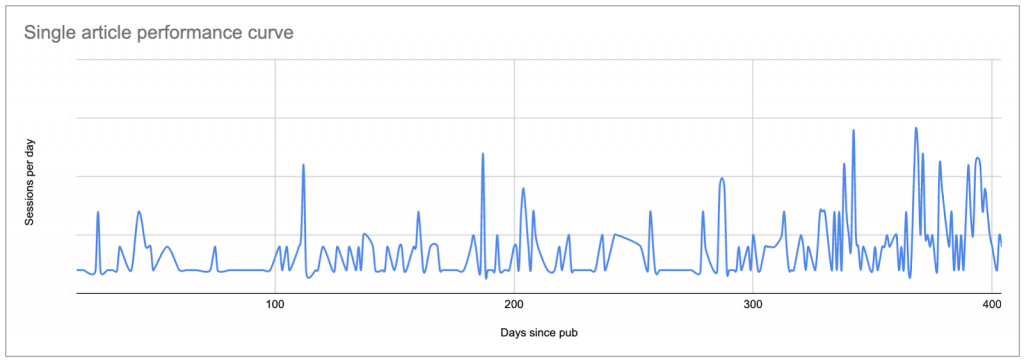
- Limite arbitraire à 90 jours d’analyse.
Toute limite arbitraire est un problème. Dans le cas présent, elle m’empêche de comprendre les performances des contenus permanents et me rend aveugle face à un pic de performances. Bien que je sache grâce à Google Analytics que de très vieux articles reçoivent parfois un pic soudain, ou que certains articles attirent régulièrement l’attention en prenant de l’âge, cela n’est pas visible dans l’outil, mais ça l’est si vous tracez leur courbe individuelle :
- Questions relatives à la longueur des feuilles.
Certaines de mes formules et certains de mes scripts nécessitent une série de cellules. Au fur et à mesure que le site et les lignes du rapport des sessions augmentent, ces fourchettes doivent être mises à jour. (Mais elles ne peuvent pas dépasser le nombre de lignes présentes sur la feuille, pour éviter que certaines d’entre elles ne produisent des erreurs).
- Incapacité de tracer des courbes complètes pour chaque élément de contenu.
“Allez, je veux tout voir !”
- Interactivité limitée avec les résultats graphiques.
Si vous avez déjà essayé de repérer un point (ou une courbe) sur un graphique avec plusieurs courbes dans Google Sheets… vous savez déjà de quoi je parle. C’est encore pire lorsque vous avez plus de vingt courbes sur le même graphique et que les couleurs commencent toutes à se ressembler.
- Possibilité de négliger les contenus peu performants sans sessions.
Avec la méthode que j’ai présentée ici, il est difficile d’identifier un contenu qui n’a systématiquement pas de sessions. Comme il n’apparaît jamais dans le rapport de Google Analytics, il n’est pas (encore) repris dans le reste du flux de travail. Un contenu qui n’est pas performant “en permanence” n’apporte que peu de valeur, donc à moins que vous ne cherchiez des pages à élaguer, un contenu non performant n’a sans doute pas sa place dans un rapport de performance.
- Incapacité à s’adapter à l’analyse en temps réel.
Bien qu’il ne soit pas particulièrement laborieux de relancer les scripts de rapport, de calcul de la moyenne et de mise à jour, il s’agit toujours d’actions manuelles en dehors de la mise à jour hebdomadaire programmée. Si la mise à jour hebdomadaire a lieu le mercredi et que vous me demandez un mardi comment ça va, je ne peux pas me contenter de consulter la fiche.
- Limites de l’extension.
Ajouter un axe d’analyse tel que le classement ou le suivi des mots-clés, ou même des options de filtrage par région géographique à ce rapport serait onéreux. Non seulement, cela exacerberait certains des problèmes existants, mais il serait aussi extrêmement difficile de mettre en place une visualisation lisible et exploitable.
La conclusion ?
Exécuter les mêmes types de calculs dans un environnement de machine learning ou de programmation permettrait de résoudre presque tous ces problèmes. Ce serait une bien meilleure façon d’effectuer des opérations semi-complexes sur un large ensemble de données. En outre, il existe d’excellentes bibliothèques qui utilisent le machine learning pour détecter de manière fiable les anomalies basées sur un ensemble de données, il existe également de meilleurs outils pour la visualisation !
Takeaways sur les performances du contenu
L’analyse des performances du contenu, même avec des méthodes primitives et imparfaites, renforce le suivi et la prise de décision basée sur les données dans la stratégie du contenu.
Concrètement, c’est la compréhension des performances du contenu qui permet :
- De comprendre la valeur des promotions initiales par rapport à l’activité de longue traîne
- De repérer rapidement les postes peu performants
- De capitaliser sur les activités de promotion extérieure pour accroître la portée
- De reconnaître facilement ce qui fait le succès de certains articles
- D’identifier certains auteurs ou certains sujets qui obtiennent systématiquement de meilleurs résultats que d’autres
- De déterminer le moment où le SEO commence à avoir un impact sur les sessions
Ces données permettent de prendre des décisions pour promouvoir le contenu, du quand et du comment, à guider les choix de sujets, le profilage du public, etc.
Enfin, des expériences comme celle-ci montrent que tout domaine pour lequel vous pouvez obtenir des données a une utilisation potentielle pour le codage, les scripts et les compétences de machine learning. Mais vous ne devez surtout pas renoncer à fabriquer vos propres outils si vous ne possédez pas toutes ces compétences !
