
Contexte
À la R&D d’Oncrawl, nous cherchons de plus en plus à valoriser le contenu sémantique de vos pages Web. En effet, à l’aide de modèles de Machine Learning pour le traitement du langage naturel (Natural Language Processing aka NLP en anglais), il est possible d’effectuer des tâches avec une réelle valeur ajoutée en SEO.
Parmi ces tâches, nous retrouvons des activités comme les suivantes :
- Comparer finement le contenu de vos pages
- Réaliser des résumés automatiques
- Compléter ou corriger les tags de vos articles
- Optimiser le contenu en fonction de vos données Google Search Console
- Etc.
La première étape de cette aventure commence par extraire le contenu texte des pages Web que ces modèles de Machine Learning vont utiliser. Et qui dit page Web, dit HTML, JavaScript, menus, médias, header, footer, … L’extraction de contenu automatique de qualité n’est pas chose aisée. À travers cet article, je propose de vous exposer la problématique ainsi que quelques outils et préconisations afin de réaliser cette tâche.
Problématique
Extraire le contenu texte d’une page Web pourrait paraître simple. Avec quelques lignes de Python par exemple, deux-trois expressions rationnelles (aka regexp), une bibliothèque de parsing comme BeautifulSoup4 et le tour est joué.
Si on oublie quelques minutes le fait que de plus en plus de sites utilisent des moteurs de rendu en JavaScript comme Vue.js ou React, parser du HTML n’est pas bien compliqué. Si par ailleurs vous voulez profiter du Crawler JS dans vos crawls, je vous invite à lire “Comment crawler un site en JavaScript ?”.
Néanmoins, nous voulons extraire le texte qui ait du sens, qui soit le plus informatif possible. Quand vous lisez un article sur le dernier album posthume de John Coltrane par exemple, vous ignorez les menus, le footer, … et vous ne voyez évidemment pas l’ensemble du contenu HTML. Ces éléments HTML qui apparaissent sur quasiment toutes vos pages, nous appelons cela du boilerplate. Et c’est ce boilerplate dont on veut se débarrasser pour ne garder qu’une partie : le texte qui porte une information pertinente.
C’est ensuite ce texte qui sera traité par des modèles de Machine Learning. Il est donc indispensable qu’il soit le plus qualitatif possible.
Solutions
Globalement, on voudrait se débarrasser de tout ce qui traine “autour” du texte principal : les menus et autres sidebars, les éléments de contact, les liens du footer, etc. Il existe plusieurs méthodes qui permettent de le faire. On s’est surtout intéressés à des projets Open Source en Python ou en JavaScript.
jusText
jusText est une proposition d’implémentation en Python issue d’une thèse de doctorat : “Removing Boilerplate and Duplicate Content from Web Corpora”. La méthode permet de catégoriser des blocs de texte issus du HTML comme étant “bons”, “mauvais”, “trop courts” suivant différentes heuristiques. Ces heuristiques sont la plupart du temps basées sur le nombre de mots, le ratio text/code, la présence ou non de liens, etc. Vous pouvez avoir plus de précisions sur l’algorithme dans la documentation.
trafilatura
trafilatura fait aussi en Python propose aussi des heuristiques à la fois sur le type d’élément HTML et sur le contenu, e.g. longueur du texte, position/profondeur de l’élément dans le HTML, nombre de mots. trafilatura utilise d’ailleurs jusText pour réaliser certains traitements.
readability
Avez-vous déjà vu le bouton dans la barre d’URL de Firefox ? C’est la Reader View : elle permet d’enlever justement le boilerplate de pages HTML pour ne garder que le contenu du texte principal. Assez pratique à utiliser pour les sites d’information. Le code derrière cette fonctionnalité est fait en JavaScript et s’appelle readability par Mozilla. Il est basé sur les travaux initiés par le laboratoire Arc90.
Voici un exemple de rendu de cette fonctionnalité pour un article issu du site de France Musique.
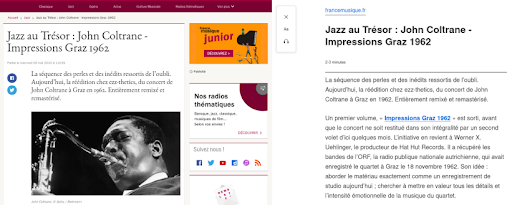
À gauche un extrait de l’article original. À droite le rendu de la fonctionnalité Reader View de Firefox.
Autres
Nos recherches sur les outils d’extraction de contenu HTML nous ont aussi amené à envisager d’autres outils tels que :
- newspaper : extraction de contenu plutôt dédié aux sites d’information (Python). Cette bibliothèque a été utilisée pour extraire du contenu du corpus OpenWebText2
- boilerpy3 est un portage Python de la bibliothèque boilerpipe
- dragnet bibliothèque Python aussi inspirée de boilerpipe
Évaluation et préconisation
Avant d’évaluer et comparer les différents outils, nous voulions savoir si la communauté NLP utilise certains des ces outils pour préparer leur corpus (large ensemble de documents). À titre d’exemple, le dataset appelé The Pile utilisé pour entrainé GPT-Neo dispose de +800 GB de texte en anglais venant de Wikipedia, Openwebtext2, Github, CommonCrawl, etc. À l’instar de BERT, GPT-Neo est un language model de type transformers. Il propose une implémentation Open Source proche de l’architecture de GPT-3.
L’article “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” mentionne l’utilisation de jusText pour une grosse partie de leur corpus venant de CommonCrawl. Ce groupe de chercheur·euse·s avait d’ailleurs envisagé de faire un benchmark des différents outils d’extraction. Malheureusement, ils ne l’ont pas fait par manque de ressource. Dans leurs conclusions, il est à noter que :
- jusText supprimait parfois un peu trop de contenu mais restait de bonne qualité. Au vue de la quantité de données qu’ils avaient, c’est un choix qui ne leur a pas posé de problème
- trafilatura arrivait à mieux conserver la structure de la page HTML mais gardait trop souvent de boilerplate
Pour notre méthode d’évaluation, nous avons pris une trentaine de pages Web. Nous avons extrait le contenu principal “à la main”. Nous avons ensuite comparé l’extraction de texte des différents outils avec ce contenu dit “de référence”. C’est le score ROUGE, utilisé essentiellement pour évaluer des résumés de texte automatiques, que nous avons utilisé en tant que métrique.
Nous avons aussi comparé ces outils avec un outil “fait maison”, basé sur des règles de parsing HTML. Il s’avère que trafilatura, jusText et notre outil maison s’en sortent mieux que la plupart des autres outils pour cette métrique.
Tableau des moyennes et écart-types du score ROUGE :
| Tools | Mean | Std |
|---|---|---|
| trafilatura | 0.783 | 0.28 |
| Oncrawl | 0.779 | 0.28 |
| jusText | 0.735 | 0.33 |
| boilerpy3 | 0.698 | 0.36 |
| readability | 0.681 | 0.34 |
| dragnet | 0.672 | 0.37 |
Au vu des valeurs des écarts-types, il est à noter que l’extraction peut être de qualité très variable. La façon dont est fait le HTML, la cohérence des balises, la bonne utilisation du langage peuvent faire beaucoup varier les résultats des outils d’extraction.
Nous avons dans les trois meilleurs outils trafilatura, notre outil maison nommé “oncrawl” pour l’occasion et jusText. Comme jusText est utilisé en tant que fallback par trafilatura, nous avons décidé d’utiliser en première intention trafilatura. Néanmoins, quand ce dernier échoue et extrait zéro mot, nous utilisons nos propres règles.
À savoir que le code de trafilatura propose aussi un benchmark sur plusieurs centaines de pages. Il calcule les scores de précisions, f1-score, accuracy sur la présence ou non de certains éléments dans le contenu extrait. Deux outils ressortent principalement : trafilatura et goose3. Lire aussi :
- Bien choisir son outil d’extraction de contenu à partir du Web (2020)
- le dépôt Github : article extraction benchmark: open-source libraries and commercial services
Conclusions
La qualité du code HTML et l’hétérogénéité du type de page rendent difficile l’extraction de contenu de qualité. Comme l’ont constaté les chercheur·euse·s d’EleutherAI – The Pile et GPT-Neo – il n’y a pas d’outils parfaits. Il faut donc faire certains compromis entre un contenu parfois tronqué et le bruit résiduel dans le texte quand tout le boilerplate n’a pas été retiré.
L’avantage de ces outils est d’être context-free. C’est-à-dire qu’ils n’ont pas besoin d’autres données que le HTML d’une page pour extraire le contenu. À partir de résultats d’Oncrawl, on pourrait imaginer une méthode hybride en utilisant les fréquences d’occurrence de certains blocs HTML dans toutes les pages du site pour les considérer en tant que boilerplate.
À propos des datasets utilisés dans les benchmarks que nous avons croisés sur la Toile, ce sont souvent le même type de page : articles de news ou articles de blog. Ce n’est pas nécessairement des sites d’assurance, d’agence de voyage, d’e-commerce etc. où le contenu texte est parfois plus compliqué à extraire.
À propos de notre benchmark et par manque de ressource, nous avons conscience qu’une trentaine de pages est peu suffisante pour avoir une vision plus fine des scores. Dans l’idéal, nous souhaiterions avoir plus de pages Web différentes pour affiner les valeurs de notre benchmark. Et nous pouvons aussi essayer d’autres outils tels que goose3, html_text ou inscriptis.
