
Dans cette étude de cas, je vais m’intéresser au site Hangikredi.com qui est l’un des plus grands actifs financiers et numériques de la Turquie. Nous nous intéresserons à leur SEO technique via plusieurs graphiques.
Cette étude de cas est présentée en deux articles. Cet article traite de la mise à jour du 12 mars de l’algorithme de Google. Nous examinerons 13 problèmes et questions holistiques afin de définir ensemble les solutions techniques.
Problèmes et solutions : Correction des effets du Core update de Google
Jusqu’à la mise à jour de l’algorithme de base du 12 mars, tout se passait bien pour le web. En un jour, après la publication de la mise à jour des algorithmes de base, il y a eu une énorme chute des classements et une grande frustration au bureau. Personnellement, je n’ai pas vécu cette journée, ils m’ont engagé pour commencer un nouveau projet de référencement 14 jours plus tard.
Voici le rapport du site web de la société après le 12 mars et le core update :
- 36% de perte de sessions organiques
- 65% de chute des clics
- 30 % de perte du CTR
- 33 % de perte d’utilisateurs organiques
- 100 000 d’impressions perdues par jour.
- 9.72% de perte d’empreintes
- 8 000 mots-clés perdus

Maintenant, comme nous l’avons dit au début de l’article, une question se pose « Quand aura lieu la prochaine mise à jour importante de l’algorithme de Google ?« . Si elle a déjà eu lieu, il ne reste alors qu’une seule question : « Quels sont les différents critères que Google a pris en compte entre moi et mon concurrent ? »
Comme vous pouvez le voir dans le tableau ci-dessus et dans le rapport de dommages, nous avions perdu notre trafic principal et nos mots-clés.
1. Problème : Maillage interne
Lorsque j’ai vérifié pour la première fois le nombre de liens internes, j’ai remarqué que sur le texte d’ancrage et le flux de liens, mon concurrent était en avance sur moi.
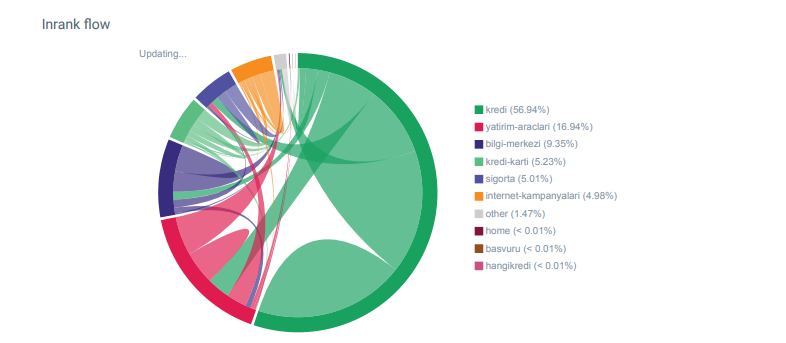
Rapport de flux de liens pour les catégories de Hangikredi.com à partir d’Oncrawl
Mon principal concurrent possède plus de 340 000 liens internes avec des milliers de textes d’ancrage. A l’époque, notre site web ne comptait que 70 000 liens internes sans textes d’ancrage de valeur. De plus, le manque de liens internes avait affecté le budget de crawl et la productivité du site web. Même si 80 % de notre trafic a été collecté sur seulement 20 pages de produits, 90 % de notre site était constitué de pages de guide avec des informations utiles pour les utilisateurs. La plupart de nos mots-clés et de notre score de pertinence pour les requêtes financières proviennent de ces pages. De plus, il y avait un nombre incalculable de pages orphelines.
En raison de la structure de liens interne manquante, lorsque j’ai fait l’analyse des logs avec Kibana, j’ai remarqué que les pages les plus explorées étaient celles qui recevaient le moins de trafic. Aussi, lorsque j’ai jumelé ceci avec le réseau de liens internes, j’ai découvert que les pages corporatives ayant le plus faible trafic (Confidentialité, Cookies, Sécurité, Pages à propos de nous) ont le nombre maximum de liens internes.
Comme nous verrons dans la prochaine section, cela a amené le Googlebot à supprimer le facteur de lien interne du Pagerank lorsqu’il a crawlé le site, réalisant que les liens internes n’étaient pas construits comme prévu.
2. Problème : architecture du site, pagerank interne, traffic et optimisation du crawl
Selon Google, les liens internes et les textes d’ancrage aident le Googlebot à comprendre l’importance et le contexte d’une page web. Le Pagerank ou Inrank interne est calculé sur la base de plusieurs facteurs. Selon Bill Slawski, les liens internes ou externes ne sont pas tous égaux. La valeur d’un lien pour le flux de Pagerank change selon sa position, son type, son style et sa police.

Si le Googlebot comprend quelles pages sont importantes pour votre site web, il les explorera davantage et les indexera plus rapidement. Les liens internes et une conception correcte de l’arborescence du site sont des facteurs importants. D’autres experts ont également commenté cette corrélation au fil des années :
» La plupart des liens fournissent peu d’informations supplémentaires grâce à leur texte d’ancrage. Du moins, ils devraient, n’est-ce pas ? » John Mueller, Google 2017
« Si vous avez des pages que vous pensez être importantes sur votre site ne les enterrez pas 15 liens plus loin dans votre site et je ne parle pas de la longueur du répertoire, je parle de cliquer à travers 15 liens pour trouver cette page alors qu’elle représente un taux de conversion important pour vous » Matt Cutts, Google 2011
« Si une page est liée à une autre avec le mot « contact » ou le mot « à propos », et que la page liée inclut une adresse, celle-ci peut être considérée comme pertinente pour la page faisant ce lien. » Les méthodes d’analyse des liens Google qui auraient pu changer – Bill Slawski
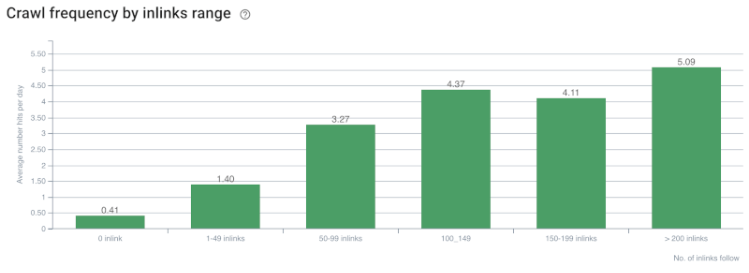
Taux de crawl / Demande et correlation avec les liens internes. Source : Oncrawl
À ce stade, nous pouvons faire les déductions suivantes :
- Google se soucie de la profondeur des clics. Si une page web est plus proche de la landing page, elle devrait être plus importante. Cela a également été confirmé par John Mueller le 1er juillet 2018.
- Si une page web a beaucoup de liens internes qui pointent vers elle, elle devrait être importante.
- Les textes d’ancrage peuvent donner un pouvoir contextuel à une page web.
- Un lien interne peut transmettre différents montants de Pagerank selon sa position, son type, sa police ou son style.
- Une arborescence pensée pour UX qui donne des messages clairs sur l’autorité de la page interne aux crawlers des moteurs de recherche est un meilleur choix pour la distribution de l’Inrank et l’efficacité du crawl.
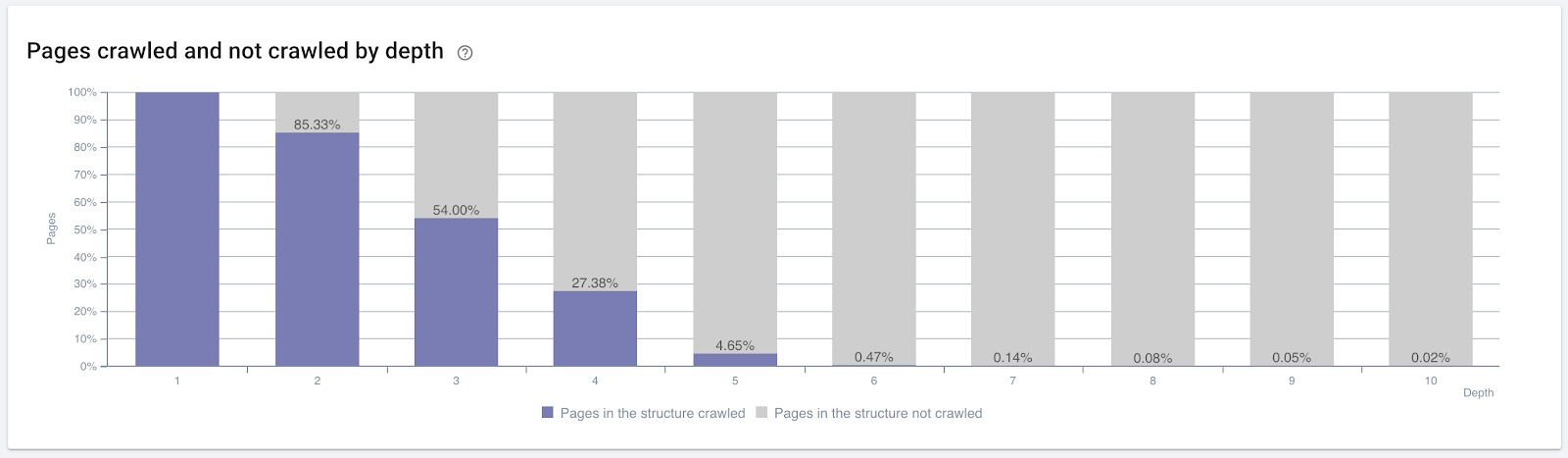
Pourcentage de pages crawlées par profondeur de clics. Source : Oncrawl.
Mais cela ne suffit pas pour comprendre la nature des liens internes et leurs effets sur l’efficacité du crawl.
Si vos pages les plus liées en interne ne créent pas de trafic ou ne génèrent pas de clics, cela donne les signaux que votre arborescence de site et votre structure de liens internes ne sont pas construites pour l’UX. De plus, Google essaie toujours de trouver les pages les plus pertinentes en fonction de l’intention de l’utilisateur ou des entités de recherche. Nous avons une autre citation de Bill Slawski qui rend ce sujet plus clair :
« Si une ressource est liée à un nombre disproportionné de liens par rapport au trafic reçu de ces mêmes liens, cette ressource peut être rétrogradée dans le processus de classement. » Did the groundhog update just take place at Google – Bill Slawski
« La sélection du score de qualité peut être plus élevé pour une sélection qui dispose d’un long dwell time (ex : plus grand que le seuil de période de temps) que pour une sélection avec un court dwell time. » Did the groundhog update just take place at Google – Bill Slawski
Nous avons donc deux autres facteurs :
- Le temps passé sur la page liée.
- Le trafic utilisateur engendré par le lien
Le nombre de liens internes et le style ne sont pas les seuls facteurs. Le nombre d’utilisateurs qui suivent ces liens et leurs comportement sont également importants. En outre, nous savons que les liens et les pages cliquées/visitées sont beaucoup plus explorés par Google que les liens et les pages non cliquées ou non visitées.
« Nous nous sommes de plus en plus orientés vers la compréhension des sections d’un site pour comprendre la qualité de ces mêmes sections. » John Mueller, le 2 mai 2017, le site anglais de Google Webmasters Hangout.
À la lumière de tous ces facteurs, je vais partager deux résultats différents du simulateur de Pagerank :
Ces calculs de Pagerank sont faits avec l’hypothèse que toutes les pages sont égales, y compris la page d’accueil. La différence réelle est déterminée par la hiérarchie des liens.
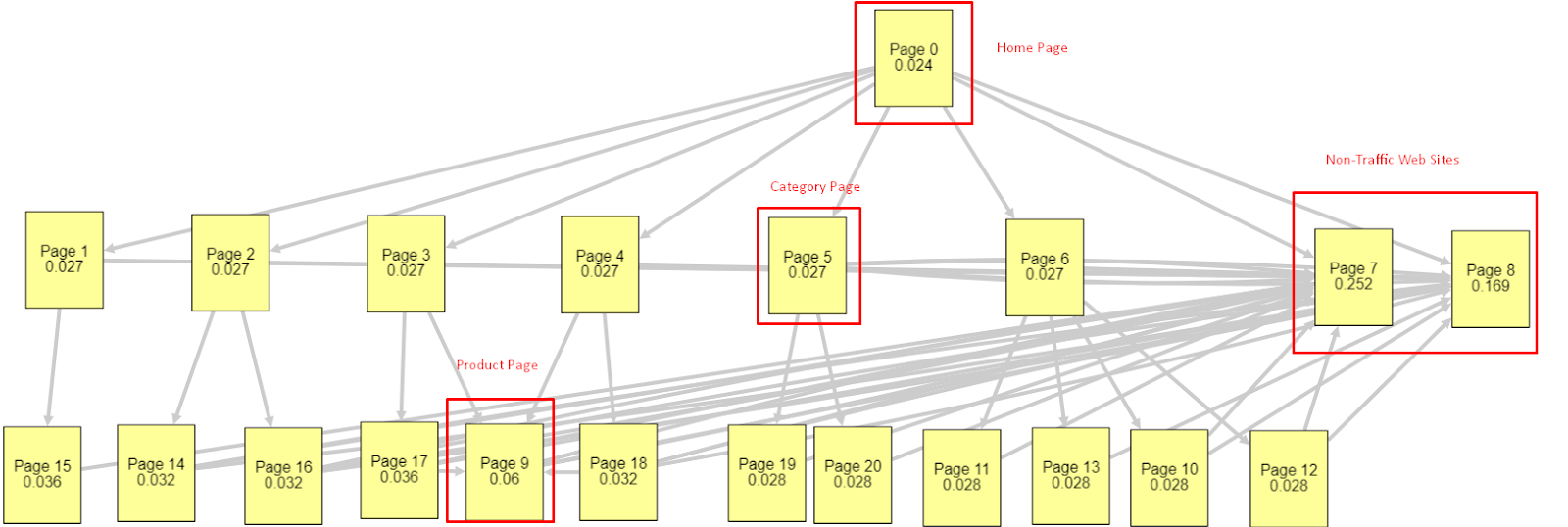
L’exemple présenté ici est plus proche de la structure de liaison interne avant le 12 mars. Homepage PR : 0.024, Category Page PR : 0.027, Product Page PR : 0.06, Non-traffic Web Pages PR : 0.252.
Comme vous pouvez le remarquer, le Googlebot ne peut pas faire confiance à cette structure de lien interne pour calculer le pagerank interne. Les pages sans trafic et sans produit ont 12 fois plus d’autorité que la page d’accueil.
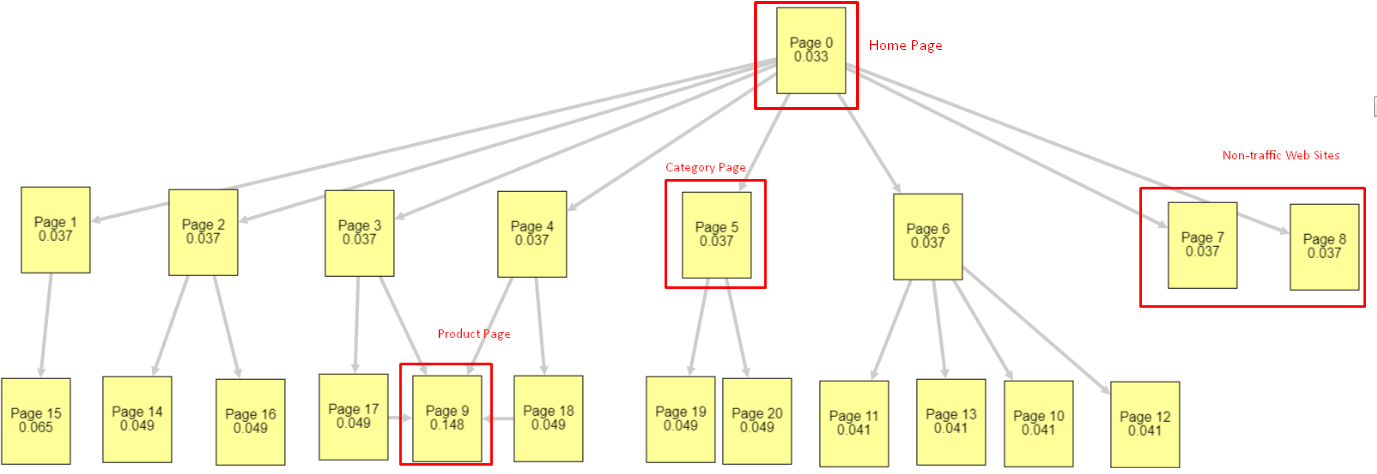
Cet exemple est plus proche de notre situation avant la mise à jour de l’algorithme de base du 5 juin. Page d’accueil PR : 0.033, Page de catégorie : 0,037, Page de produit : 0,148 et PR des pages sans trafic : 0,037.
Comme vous pouvez le remarquer, la structure interne des liens n’est toujours pas correcte mais au moins les pages sans traffic n’ont pas plus de PR que les Pages de Catégorie et les Pages Produits.
Quelle est la preuve que Google a pris le lien interne et la structure du site en fonction du flux d’utilisateurs et des requêtes ou intentions ? Bien sûr, le comportement du Googlebot et les corrélations du Pagerank et du classement Inlink :
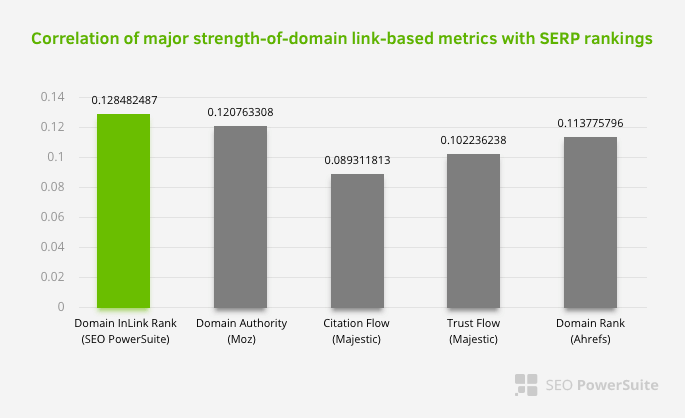
Cela ne signifie pas que le maillage interne est plus important que d’autres facteurs. La perspective d’optimisation des moteurs de recherche qui se concentre sur un seul point ne peut jamais réussir. Dans une comparaison entre des outils tierces, nous pouvons voir que la valeur interne du Pagerank progresse par rapport à d’autres critères.
Selon l’étude Inlink Rank and rank correlation de Aleh Barysevich, les pages avec le plus de liens internes ont un classement plus élevé que les autres pages du site. Lors de l’enquête menée du 4 au 6 mars 2019, 1 000 000 de pages ont été analysées selon la métrique interne Pagerank pour 33 500 mots-clés. Les résultats de cette recherche menée par SEO PowerSuite ont été comparés avec les différentes métriques de Moz, Majestic et Ahrefs et ont donné des résultats plus précis.
Voici quelques-uns des numéros de liens internes de notre site avant la mise à jour de l’algorithme de base du 12 mars :
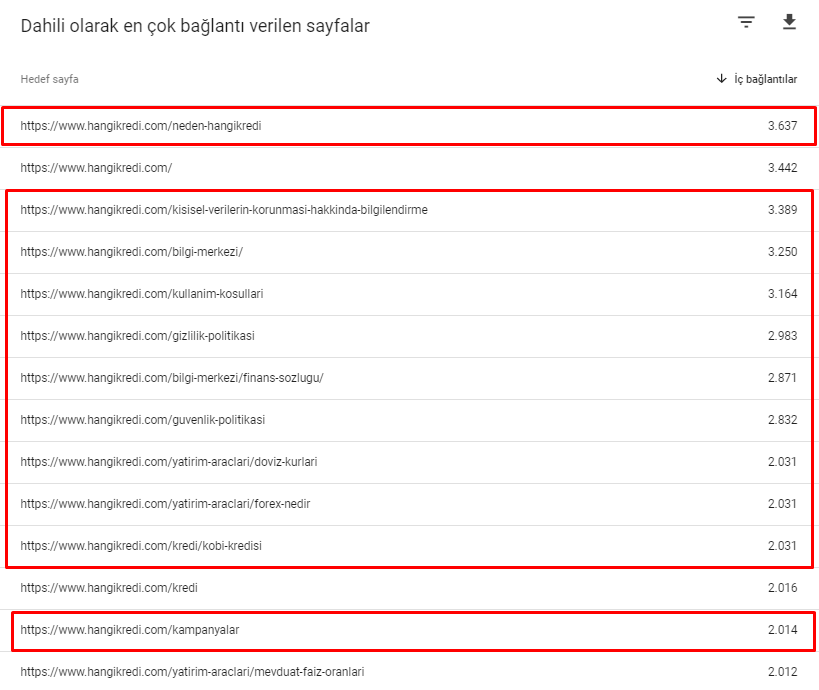
Comme vous pouvez le voir, notre schéma de connexion interne ne reflétait pas l’intention et le flux des utilisateurs. Les pages qui reçoivent le moins de trafic (pages de produits mineures) ou qui ne reçoivent jamais de trafic (en rouge) reçevaient des PR de la page d’accueil. Et certaines avaient encore plus de liens internes que la page d’accueil.
Au vu de tout cela, il ne reste que deux points à voir à ce sujet :
- Taux de crawl / demande pour les pages les plus liées du site
- Lien sculpté et Pagerank
Entre le 1er février et le 31 mars, voici les pages que Googlebot a le plus souvent crawlées :
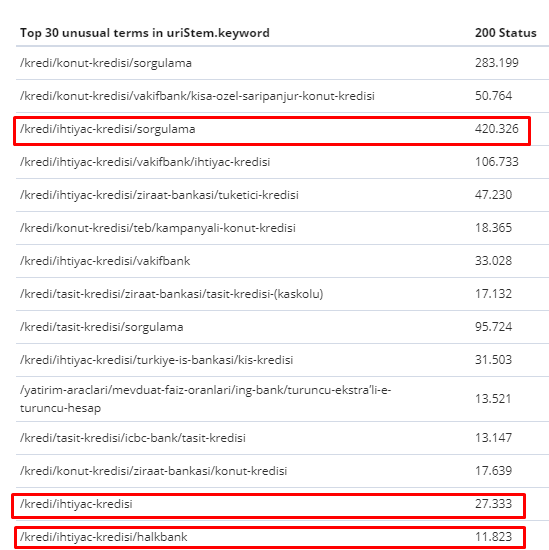
Comme vous pouvez le remarquer, les pages explorées et les pages qui ont le plus de liens internes sont complètement différentes les unes des autres. Les pages avec le plus de liens internes n’étaient pas pratiques pour l’UX ; elles n’ont pas de mots-clés organiques ni aucune sorte de valeur de référencement direct.
Les URLs dans les cases rouges sont nos catégories de pages de produits les plus visitées et les plus importantes. Les autres pages de cette liste sont les deuxième ou troisième catégories les plus visitées et les plus importantes.
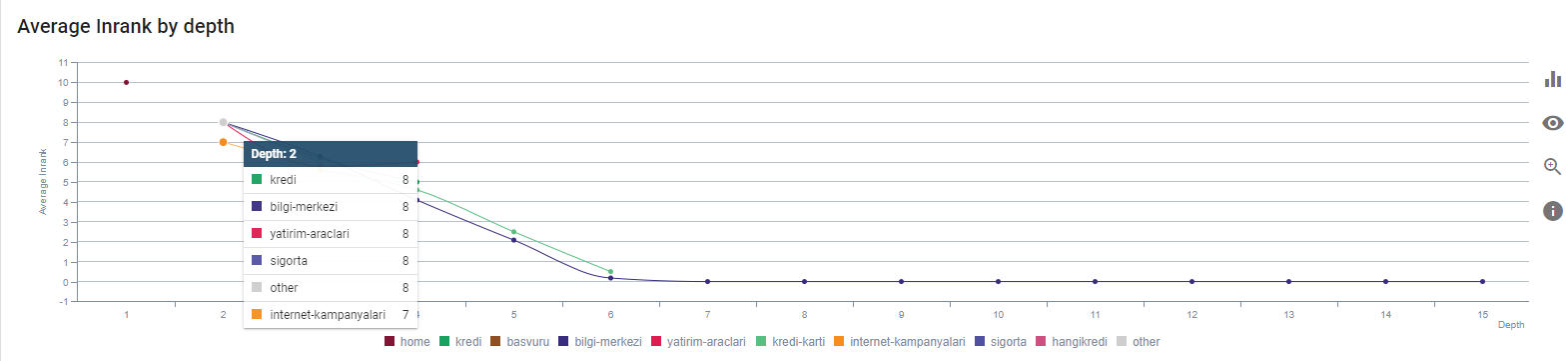
Notre Inrank actuel par profondeur de page. Source : Oncrawl.
Qu’est-ce que la sculpture de liens et que faire des liens internes non suivis ?
Contrairement à ce que la plupart des SEOs croient, les liens marqués avec un tag « nofollow » passent toujours la valeur du Pagerank interne. Pour moi, après toutes ces années, personne n’a mieux expliqué cela que Matt Cutts dans son article du 15 juin 2009 sur la sculpture de liens dans le Pagerank.
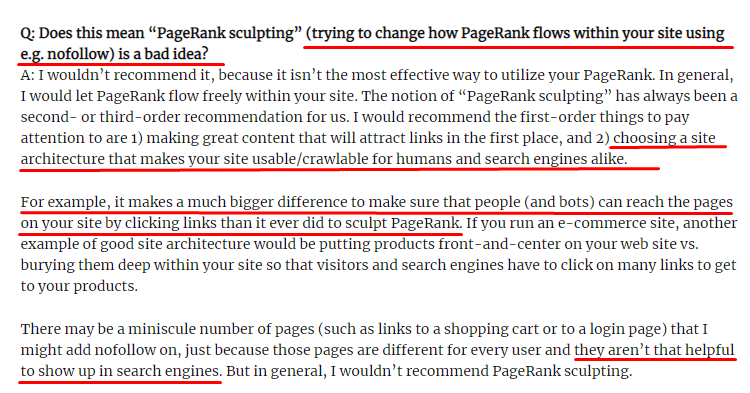
« Je recommande de ne pas utiliser le nofollow pour sculpter le PageRank d’un site web car il ne fait probablement pas ce que vous pensez qu’il fasse » John Mueller, Google 2017
Si vous avez des pages web sans valeur pour Google et les utilisateurs, vous ne devriez pas les marquer avec « nofollow ». Ça n’arrêtera pas le flux de Pagerank. Vous devriez les interdire dans le fichier robots.txt. De cette façon, le Googlebot ne les parcourra pas, mais il ne leur transmettra pas non plus le Pagerank interne. Cependant, je vous conseille d’utiliser cela que pour des pages vraiment sans valeur. Les pages qui font des redirections automatiques pour le marketing d’affiliation ou les pages qui n’ont presque pas de contenu sont quelques exemples pratiques ici.
Solution : Une meilleure structure du maillage interne
Notre concurrent était désavantagé. Leur site web avait plus de texte d’ancrage, plus de liens internes, mais leur structure n’était pas naturelle. Le même texte d’ancrage était utilisé avec la même phrase sur chaque page de leur site. Le paragraphe d’entrée de chaque page était couvert de ce même contenu. Chaque utilisateur et moteur de recherche peut facilement reconnaître qu’il ne s’agit pas d’une structure naturelle qui tient compte de l’intérêt de l’utilisateur.
J’ai donc décidé trois choses à faire afin de fixer la structure interne des liens :
- L’architecture d’information du site ou l’arbre du site devrait suivre un chemin différent des liens placés dans le contenu.
- Dans chaque élément de contenu, les mots-clés latéraux doivent être utilisés avec les mots-clés principaux de la page ciblée.
- Les textes d’ancrage doivent être naturels, adaptés au contenu et utilisés à un point différent de chaque page en tenant compte de la perception de l’utilisateur.
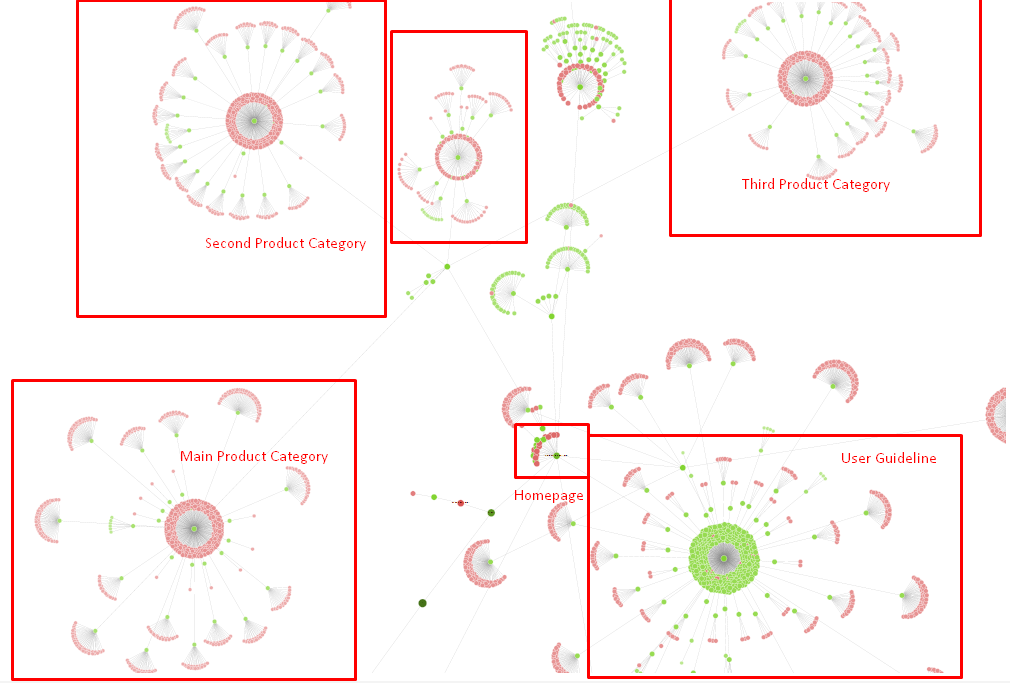
Notre site-tree et une partie de la structure de liens internes
Dans le diagramme ci-dessus, vous pouvez voir notre lien interne actuel et l’arborescence du site.
Certaines des choses que nous avons faites pour résoudre ce problème sont ci-dessous :
- Nous avons créé 30 000 liens internes supplémentaires avec des ancres utiles.
- Nous avons utilisé des spots naturels et des mots-clés pour l’utilisateur.
- Nous n’avons pas utilisé les phrases répétitives et les modèles pour les liens internes.
- Nous avons donné les bons signaux au Googlebot à propos de l’Inrank d’une page web.
- Nous avons examiné les effets d’une structure de liens internes correcte sur l’efficacité de crawl via l’analyse des logs et nous avons constaté que nos pages produits principales étaient davantage crawlées.
- Nous avons créé plus de 50 000 liens internes pour les pages orphelines.
- Nous avons utilisé des liens internes de la page d’accueil pour alimenter les sous-pages et créé plus de sources de liens internes sur la page d’accueil.
- Pour protéger l’alimentation du pagerank, nous avons également utilisé la balise nofollow pour certains liens externes inutiles. (Il ne s’agissait pas de liens internes mais l’objectif est le même).
3. Problème : Structure du contenu
Google dit que pour les sites web YMYL, la fiabilité et l’autorité sont beaucoup plus importantes que pour les autres types de sites.

Dans le passé, les mots-clés n’étaient que des mots-clés. Mais aujourd’hui, ce sont aussi des entités bien définies, singulières, significatives et distinctes. Dans notre contenu, il y avait quatre problèmes principaux :
- Notre contenu était court. (Normalement, la longueur du contenu n’est pas importante. Mais dans ce cas, ils ne contenaient pas assez d’informations sur les sujets).
- Les noms de nos auteurs n’étaient pas singuliers, significatifs ou distinguables en tant qu’entité.
- Notre contenu n’était pas agréable pour les yeux. En d’autres termes, ce n’était pas un contenu « fast-food ».
- Nous avons utilisé un langage marketing. En l’espace d’un paragraphe, nous pouvions identifier le nom de la marque et sa publicité pour l’utilisateur.
- Il y avait beaucoup de boutons qui envoyaient les utilisateurs vers les pages produits à partir des pages d’information.
- Dans le contenu de nos pages produits, il n’y avait pas assez d’informations ni de directives complètes.
- Nous utilisions essentiellement la même couleur pour la police et le fond. (C’est encore le cas la plupart du temps en raison de problèmes d’infrastructure).
- Les images et les vidéos n’étaient pas considérées comme faisant partie du contenu.
- L’intention de l’utilisateur et l’intention de recherche pour un mot clé spécifique n’avaient pas été considérées comme importantes auparavant.
- Il y avait beaucoup de contenu en double, inutile et répétitif pour le même sujet.
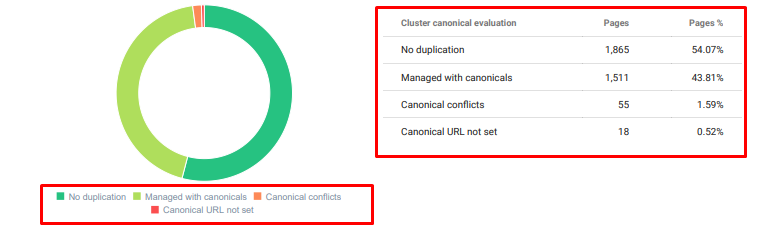
Audit de contenu dupliqué d’Oncrawl
Solution : Une meilleure structure de contenu pour la confiance des utilisateurs
Lors de la vérification d’un problème à l’échelle du site, l’utilisation d’un programme de vérification est une meilleure façon d’organiser le temps passé sur les projets de référencement. Comme dans la section des liens internes, j’ai utilisé Oncrawl avec d’autres outils.
Tout d’abord, la résolution de chaque problème dans la section de contenu aurait pris trop de temps. En ces jours de crise, le temps est un luxe. J’ai donc décidé de résoudre les problèmes à gain rapide tels que :
- Suppression du contenu en double
- Unifier les contenus courts
- Reproduction de contenu sans sous-titres et sans structure de repérage
- Fixer le ton du marketing intensif dans le contenu
- Suppression d’un grand nombre de call-to-action
- Une meilleure communication visuelle avec des images et des vidéos
- Rendre le contenu et les mots-clés cibles compatibles avec l’utilisateur et l’intention de recherche
- Utiliser et montrer les entités financières et éducatives dans le contenu pour renforcer la confiance
- Utiliser la communauté sociale pour créer une preuve d’approbation sociale
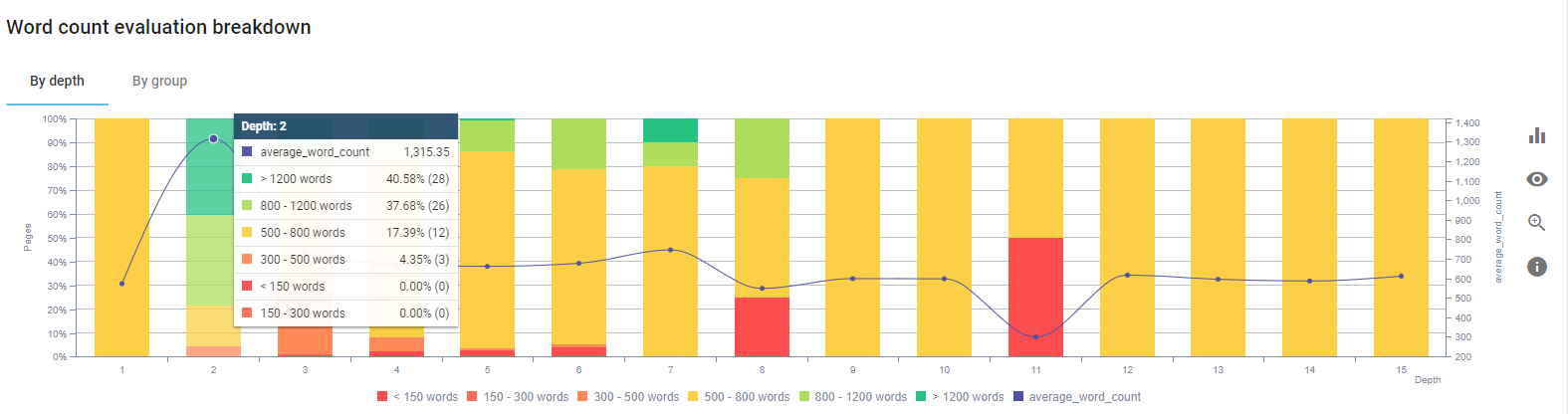
Nous nous sommes concentrés sur la réparation des contenus des pages produits et les pages guides à proximité.
Au début de ce process, la plupart de nos produits et des pages transactionnelles avaient moins de 500 mots sans informations complètes.
En 25 jours, les actions que nous avons menées sont les suivantes :
- Suppression de 228 pages avec un contenu en double, inutile et répétitif. (Les profils de backlink ont été vérifiés avant le processus de suppression. Et nous avons utilisé les status code 301 ou 410 pour une meilleure communication avec le Googlebot).
- Combinaison de plus de 123 pages qui manquaient d’informations.
- Utilisation de sous-titres en fonction de leur importance et de la demande des utilisateurs.
- Suppression des boutons de marque et des CTA avec un langage marketing.
- Inclusion de texte dans les images pour renforcer le sujet principal.
Voici une capture d’écran de la vision IA de Google. Google peut lire les textes dans les images et détecter les expressions et identités dans les entités.
- Activation de notre réseau social pour attirer plus d’utilisateurs.
- Analyse de l’écart de contenu entre les concurrents et création de plus de 80 nouveaux éléments de contenu.
- Utilisation de Google Analytics, de la Search Console et de Google Data Studio pour déterminer les pages les moins performantes avec un taux de rebond élevé et un faible trafic.
- Recherches sur les snippets et les mots-clés.
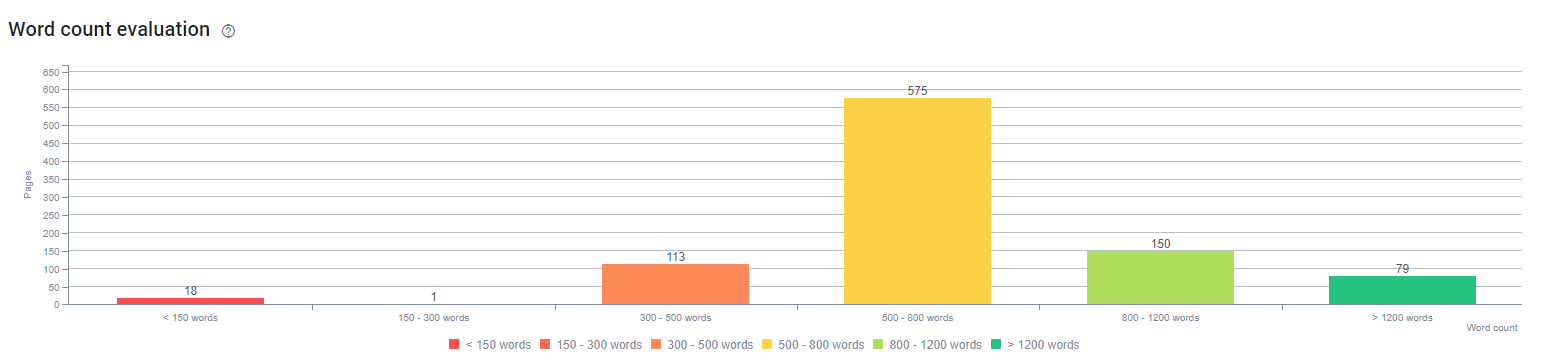
Au début du processus, nos contenus étaient composés de 150 à 300 mots. La longueur moyenne a augmenté de 350 mots pour l’intégralité du site.
4. Problème : pollution de l’index, inflation et balises canoniques
Google n’a jamais fait de déclaration sur la pollution de l’index et en fait je ne suis pas sûr que quelqu’un l’ait déjà utilisé comme terme de référencement ou non. Toutes les pages qui n’ont pas de sens pour Google devraient être supprimées des pages d’index. Les pages qui causent de la pollution d’index sont des pages qui n’ont pas produit de trafic depuis des mois. Elles ont zéro CTR et zéro mots-clés organiques.
Aussi, nous avions effectué des recherches concernant l’inflation de l’index et nous avons trouvé encore plus de pages indexées inutiles. Ces pages existent à cause d’une structure d’information du site erronée, ou à cause d’une mauvaise structure d’URL.
Une autre cause à ce problème était l’utilisation incorrecte des balises canoniques. Pendant plus de deux ans, les balises canoniques ont été traitées comme de simples indices pour le Googlebot. Si elles sont mal utilisées, Googlebot ne les calculera pas ou n’y prêtera pas attention lors de l’évaluation du site. Aussi, pour ce calcul, vous consommerez probablement votre budget de crawl de manière inefficace. À cause de l’utilisation incorrecte des balises canoniques, nous avons eu plus de 300 pages de commentaires avec du contenu en double qui ont été indexées.
L’objectif de ma théorie est de montrer à Google uniquement les pages de qualité ayant le potentiel de gagner des clics et de créer de la valeur pour les utilisateurs.
[Étude de cas] Améliorer les classements, visites organiques et ventes avec l’analyse des fichiers de log

Solution : remédier à la pollution et à l’inflation de l’index
D’abord, j’ai pris des conseils auprès de John Mueller de Google. Je lui ai demandé si j’utilisais la balise noindex pour ces pages mais que je laissais quand même le Googlebot les suivre, « est-ce que je perdrais l’équité des liens et l’efficacité du crawl ? »
Comme vous pouvez le deviner, il a dit oui au début mais ensuite il a suggéré que l’utilisation de liens internes pouvait surmonter cet obstacle.
J’ai aussi trouvé que l’utilisation des balises noindex en même temps que dofollow diminuait le taux d’indexation par le Googlebot sur ces pages. Ces stratégies m’ont permis de faire en sorte que le Googlebot crawle plus souvent mes pages produits importantes. J’ai également modifié ma structure de liens interne comme John Mueller me l’a conseillé.
En peu de temps :
- Des pages indexées inutiles ont été découvertes.
- Plus de 300 pages ont été supprimées de l’index.
- Aucune balise d’index n’a été implémentée.
- La structure interne des liens a été modifiée pour les pages qui recevaient des liens qui ont été supprimés de l’index.
- L’efficacité et la qualité de l’indexation ont été examinées au fil du temps.
5. Problème : status codes erronés
Au début, j’ai remarqué que le Googlebot visitait beaucoup de contenu supprimé. Même les pages datant de plus de huit ans étaient encore explorées. Cela était dû à l’utilisation de status codes incorrects, en particulier pour les contenus supprimés.
Il y a une énorme différence entre les fonctions 404 et 410. L’une d’entre elles concerne une page d’erreur où aucun contenu n’existe et l’autre concerne un contenu supprimé. De plus, les pages valides référencent souvent des URLs de sources et de contenus supprimés. Certaines images supprimées et des ressources CSS ou JS ont également été utilisées comme ressources sur les pages valides publiées. Enfin, il y avait beaucoup de pages soft 404, et de multiples chaînes de redirection.
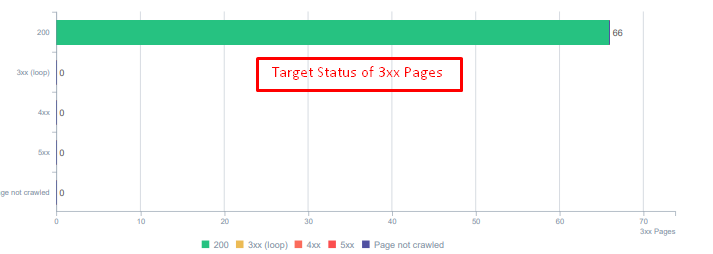
Status codes des éléments redirigés.
Solution : Correction des status codes erronés
- Chaque status code 404 a été converti en 410. (Plus de 30000)
- Chaque ressource avec le status code 404 a été remplacée par une nouvelle ressource valide. (Plus de 500)
- Chaque redirection 302-307 a été convertie en 301. (Plus de 1500)
- Les chaînes de réacheminement ont été retirées des actifs en cours d’utilisation.
- Chaque mois, nous avions reçu plus de 25 000 visites sur des pages et des ressources avec un code d’état 404 dans notre analyse de log. Maintenant, c’est moins de 50 status codes 404 par mois et 0 status 410…
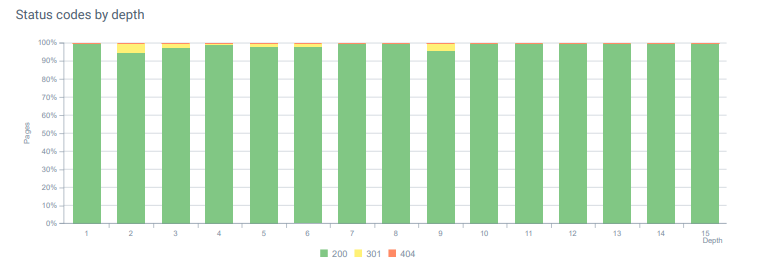
Status codes par profondeur de page.
6. Problème : HTML sémantique
Le HTML sémantique comprend des balises qui définissent les composants de la page dans une hiérarchie. Grâce à cette structure de code, vous pouvez indiquer à Google le but du contenu. En outre, dans le cas où le Googlebot ne peut pas explorer toutes les ressources nécessaires, vous pouvez au moins spécifier la mise en page de votre page web et les fonctions de vos contenus au Googlebot.
Sur Hangikredi.com, après la mise à jour de l’algorithme de Google du 12 mars, je savais qu’il n’y avait pas assez de budget de crawl à cause d’une structure de site web non optimisée. Donc, afin de faire comprendre au Googlebot le but, la fonction, le contenu et l’utilité de la page web plus facilement, j’ai décidé d’utiliser du HTML sémantique.
Solution : utilisation du HTML sémantique
Selon les directives de Google sur le classement par qualité, chaque chercheur a une intention et chaque page web a une fonction en lien avec cette intention. Pour prouver ces fonctions au Googlebot, nous avons apporté quelques améliorations à notre structure HTML pour certaines des pages qui sont moins crawlées par Google.
- Utilisation de la balise <main> pour afficher le contenu principal et la fonction de la page.
- Utilisation de <nav> pour la partie navigationnelle.
- Utilisation de <footer> pour le footer du site.
- Utilisation de <article> pour l’article.
- Utilisation de <section> pour chaque balise d’en-tête.
- Utilisation des balises <image>, <table>, <citation> pour les images, les tables et les citations dans le contenu.
- Utilisation de <aside> pour le contenu supplémentaire.
- Correction des problèmes de hiérarchie H1-H6 (Malgré la dernière déclaration de Google « utiliser deux H1 n’est pas un problème », utiliser la bonne structure, aide le Googlebot).
- Comme dans la section Structure du contenu, nous avons également utilisé le HTML sémantique pour les snippets.
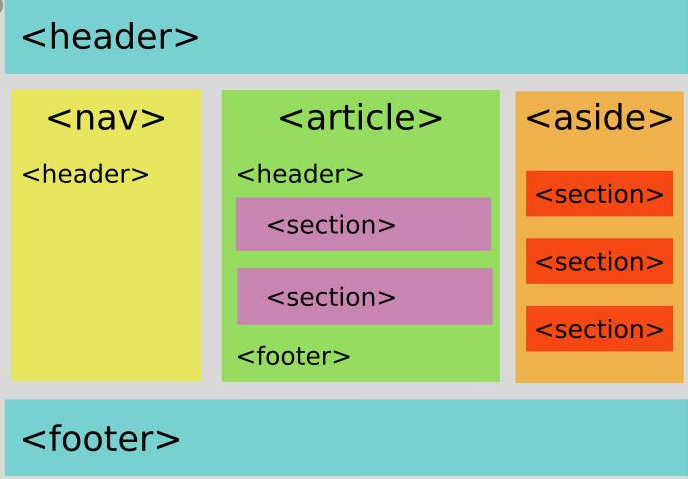
Pour nous, il ne s’agissait pas d’une implémentation réaliste pour tout le site. Pourtant, avec chaque mise à jour design, nous continuons à implémenter des balises HTML pour des pages web additionnelles.
7. Problème : utilisation des données structurées
Tout comme l’utilisation de HTML sémantique, les données structurées peuvent être utilisées pour montrer les fonctions des pages web au Googlebot. De plus, les données structurées sont obligatoires pour les résultats dit “riches”. Sur notre site web, les données structurées n’ont pas été utilisées, ou du moins, ont été utilisées incorrectement jusqu’à la fin du mois de mars.
Crawler SEO Oncrawl

Solution : utilisation correcte et testée des données structurées
- FAQ Données structurées pour les pages produits principales
- Données structurées de la page web
- Données structurées de l’organisation
- Données structurées par fil d’Ariane
8. Plan du site et optimisation Robots.txt
Sur Hangikredi.com, il n’y a pas de plan de site dynamique. Le plan du site existant à l’époque n’incluait pas toutes les pages nécessaires et comprenait également du contenu supprimé. De plus, dans le fichier Robots.txt, certaines des pages de référence des affiliés avec des milliers de liens externes n’étaient pas interdites. Cela incluait également certains fichiers JS tiers qui n’ont aucun rapport avec le contenu et d’autres ressources supplémentaires qui n’étaient pas nécessaires pour Googlebot.
Les étapes suivantes ont été appliquées :
- Création d’un sitemap_index.xml pour plusieurs sitemaps qui sont créés en fonction des catégories de sites pour un meilleur signal de crawling et un meilleur examen de la couverture.
- Certains des fichiers JS tiers et certains fichiers JS inutiles ont été interdits dans le fichier robots.txt.
- Les pages d’affiliation avec des liens externes et sans valeur de landing page ont été interdites, comme nous l’avons mentionné dans la section Pagerank ou Sculpture de lien interne.
- Correction de plus de 500 problèmes de couverture. (La plupart d’entre eux étaient des pages qui étaient indexées malgré le fait qu’elles étaient interdites par le fichier robots.txt).
Vous pouvez voir notre taux de crawl, la charge et l’augmentation de la demande dans le tableau ci-dessous :
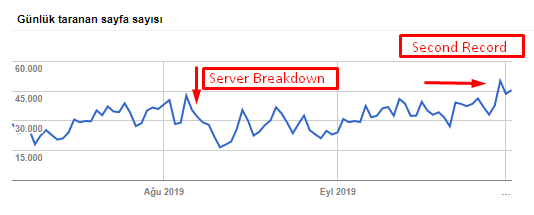
Crawl des pages par jour du Googlebot. Il y a eu une augmentation constante du nombre de pages par jour jusqu’au 1er août. Après qu’une attaque ait provoqué une panne de serveur début août, il a retrouvé sa stabilité.
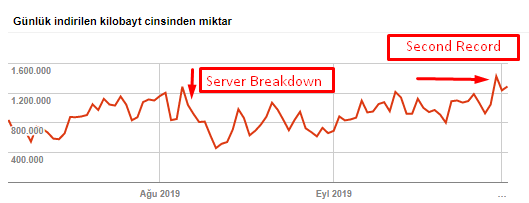
Crawled Load par jour par Googlebot. Celui-ci a évolué en parallèle avec le nombre de pages crawlées par jour.
9. Correction des problèmes AMP
Sur le site web de l’entreprise, chaque page de blog a une version AMP. A cause d’une mauvaise implémentation du code et de l’absence de canoniques AMP, toutes les pages AMP ont été supprimées de l’index à plusieurs reprises. Cela a créé un score d’index instable et un manque de confiance vis à vis du site. De plus, les pages AMP avaient des termes et des mots anglais par défaut sur le contenu turc.
- Les tags canoniques ont été corrigés pour plus de 400 pages AMP.
- Des implémentations de code incorrectes ont été trouvées et corrigées. (Cela était principalement dû à une implémentation incorrecte des balises AMP-Analytics et AMP-Canonical).
- Les termes anglais par défaut ont été traduits en turc.
- Une stabilité d’index et de classement a été créée pour le côté blog du site web de la société.
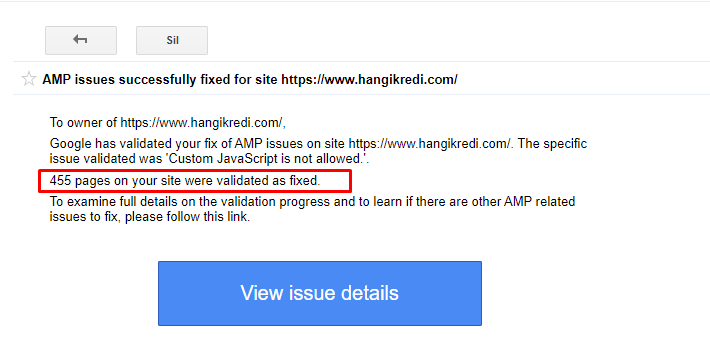
Un exemple de message dans la GSC à propos des améliorations AMP
10. Problèmes et solutions des metag tag
En raison des problèmes de budget de crawl, parfois, dans des requêtes de recherche critiques pour des pages produits importantes, Google n’a pas indexé ou affiché le contenu dans les balises méta. Au lieu du méta titre, le SERP n’affichait que le nom de l’entreprise construit à partir de deux mots. Aucun extrait de description n’était affiché… Cela diminuait notre CTR et nuisait à l’identité de notre marque. Nous avons résolu ce problème en déplaçant les méta-tags en haut de notre code source comme indiqué ci-dessous.
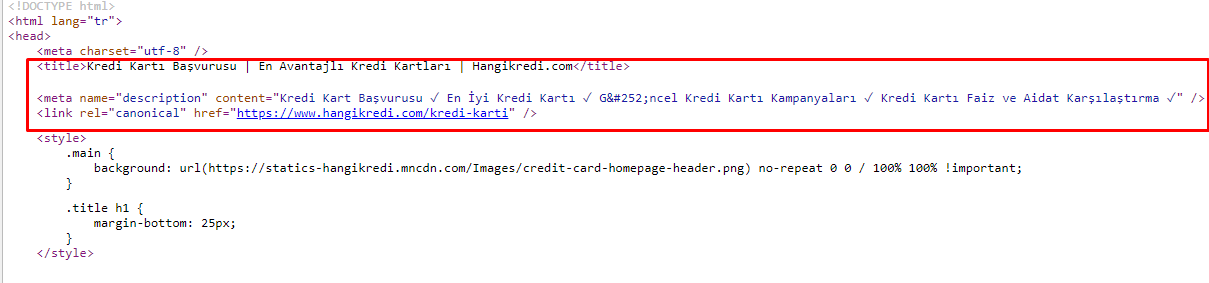
En plus du budget de crawl, nous avons également optimisé plus de 600 meta tags pour les pages transactionnelles et informatives :
- Longueur de caractères optimisée pour les appareils mobiles.
- Utilisation de plus de mots-clés dans les titres.
- Utilisation de différents styles de méta-tags et analyse des changements de CTR, d’écart de mots-clés et de classement.
- Grâce à ces processus d’optimisation, nous avons créé plus de pages avec une structure d’arborescence de site correcte pour mieux cibler les mots-clés secondaires.
- Sur notre site, nous avons encore différents méta titres, descriptions et rubriques pour tester l’algorithme de Google et le CTR de l’utilisateur de recherche.
11. Problèmes de performance de l’image et solutions
Les problèmes d’image peuvent être divisés en deux types. Pour la commodité du contenu et pour la vitesse de la page. Pour les deux, le site web de la société a encore beaucoup à faire.
En mars et avril, suite à la mise à jour négative de l’algorithme du 12 mars :
- Les images n’avaient pas de balises alt ou avaient de mauvaises balises alt.
- Elles n’avaient pas de titres.
- Elles n’avaient pas de structure d’URL correcte.
- Elles n’avaient pas d’extensions de la prochaine génération.
- Elles n’avaient pas été compressées.
- Elles n’avaient pas la bonne résolution pour chaque taille d’écran d’appareil.
- Elles n’avaient pas de légendes.
Pour préparer la prochaine mise à jour de l’algorithme Google :
- Les images ont été compressées.
- Leurs extensions ont été partiellement modifiées.
- Des balises alt ont été écrites pour la plupart d’entre elles.
- Les titres et les légendes ont été corrigés pour l’utilisateur.
- Les structures des URLs ont été partiellement corrigées pour l’utilisateur.
- Nous avons trouvé quelques images inutilisées qui sont toujours en cours de chargement par le navigateur, et nous les avons supprimées du système.
En raison de l’infrastructure du site, nous avons partiellement mis en œuvre des corrections de référencement des images.
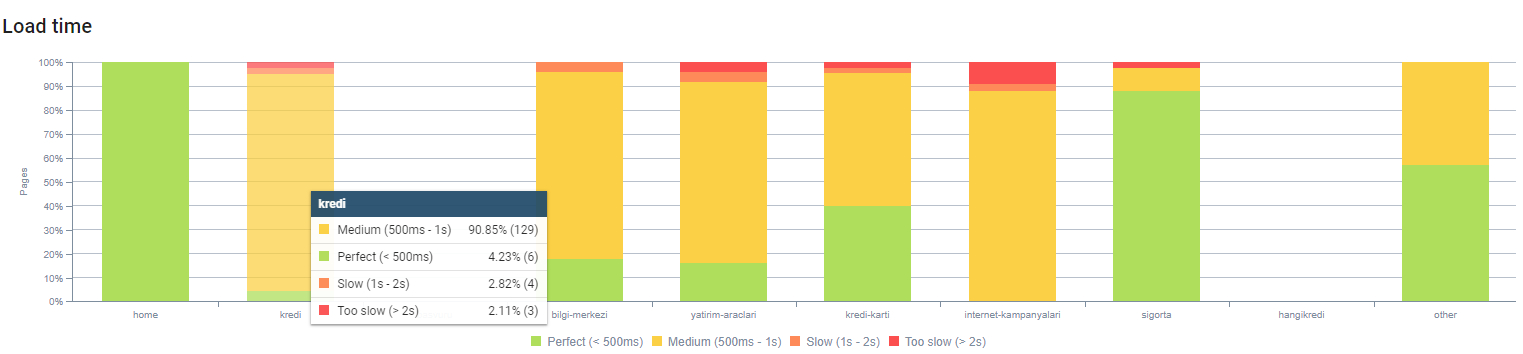
Vous pouvez observer notre temps de chargement pas profondeur de page ci-dessus. Comme vous pouvez le voir, la plupart des pages produits sont toujours lourdes.
12. Problèmes/solutions de cache et de préchargement
Avant le core update du 12 mars, il y avait un système de mémoire cache mal installé sur le site web de la société. Certaines parties du contenu étaient dans le cache, mais d’autres non. C’était surtout un problème pour les pages produits car elles étaient 2 fois plus lentes que celles de nos concurrents.
Pour préparer la prochaine mise à jour de l’algorithme de Google :
- Nous avons mis en cache certains composants pour chaque page web et les avons rendus statiques.
- Ces pages étaient des pages produits importantes.
- Nous n’utilisons toujours pas les E-Tags à cause de l’infrastructure du site.
- En particulier les images, les ressources statiques et certaines parties importantes du contenu sont maintenant entièrement mises en cache à l’échelle du site.
- Nous avons commencé à utiliser le code dns-prech pour certaines ressources externalisées oubliées.
- Nous n’utilisons toujours pas le code préchargé mais nous travaillons sur l’UX du site.
13. Optimisation et réduction de HTML, CSS et JS
En raison des problèmes d’infrastructure du site, il n’y avait pas tant de choses à faire au sujet de la vitesse. J’ai essayé de combler l’écart avec toutes les méthodes possibles, y compris la suppression de certains composants de page. Pour les pages produits, nous avons nettoyé la structure du code HTML, l’avons réduite et compressée.
Une capture d’écran du code source de l’une de nos pages produits saisonières. En utilisant les données structurées FAQ, le HTML, l’optimisation d’image, le rafraîchissement de contenu et le maillage interne, nous avons obtenu la première position dans les classements au bon moment (Le mot-clé était « Bayram Kredisi », en anglais « Holiday Credit ».)
Nous avons également implémenté le Factoring CSS, le Refactoring et la Compression JS. Lorsque les classements ont chuté, nous avons examiné l’écart de vitesse du site entre les pages de nos concurrents et les nôtres. Nous avions choisi quelques pages que nous pouvions rapidement accélérer. Nous avons aussi partiellement compressé les fichiers CSS critiques de ces pages. Nous avons lancé le processus de suppression de certains fichiers JS tiers utilisés par différents services de la société, mais ils n’ont pas encore été supprimés. Pour certaines pages produits, nous avons également pu modifier l’ordre de chargement des ressources.
Analyse concurrentielle
En plus de chaque amélioration technique de référencement, l’inspection des concurrents a été mon meilleur guide pour comprendre la nature et les objectifs d’une mise à jour d’algorithme. J’ai utilisé quelques programmes utiles pour suivre les changements de conception, de contenu, de rang et de technologies des concurrents.
- Pour les changements de classement par mot-clé, j’ai utilisé Wincher, Semrush et Ahrefs.
- Pour les mentions de marque, j’ai utilisé Google Alerts, BuzzSumo, Talkwalker.
- Pour les nouveaux liens et les nouveaux rapports de gain de mots-clés, j’ai utilisé Ahrefs Alert.
- Pour les changements de contenu et de design, j’ai utilisé Visualping.
- Pour les changements de technologie, j’ai utilisé SimilarTech.
- Pour les nouvelles et l’inspection de Google Update, j’ai principalement utilisé Semrush Sensor, Algoroo et CognitiveSEO Signals.
- Pour l’inspection de l’historique des URLs des concurrents, j’ai utilisé la Wayback Machine.
- Pour la vitesse du serveur des concurrents, j’ai utilisé Chrome DevTools et ByteCheck.
- Pour le budget de crawl et de rendu, j’ai utilisé « What Does My Site Cost ». (Depuis le mois dernier, j’ai commencé à utiliser les nouveaux outils JS de Onely comme WWJD ou TL:DR…)

Capture d’écran depuis SimilarTech visant mon concurrent principal.
Une capture d’écran de Visualping qui montre les changements de disposition pour mon concurrent secondaire.
Tester la valeur des changements
Une fois tous ces problèmes identifiés et les solutions mises en place, j’étais prêt à voir si le site web tiendrait le coup jusqu’au prochain core update de Google.
Dans le prochain article, j’examinerai les principales mises à jour des algorithmes de base au cours des prochains mois, ainsi que les performances du site.
