Un réseau sémantique est lié au concept d’une base de connaissances qui peut représenter les informations du monde réel pour les choses qui ont des connexions relationnelles. Une base de connaissances peut avoir des milliers de types de relations avec des milliards d’entités et des trillions de faits. Un réseau sémantique peut être créé à partir de n’importe quelle existence du monde réel avec des caractéristiques mutuelles telles que le poids, la taille, le type, l’odeur ou la couleur. La relation entre les réseaux sémantiques et le Web sémantique est créée par les moteurs de recherche et l’optimisation sémantique.
Les réseaux sémantiques sont utilisés dans l’analyse syntaxique sémantique, la désambiguïsation du sens des mots, la création de WordNet, la théorie des graphes, le traitement du langage naturel, la compréhension et la génération. La perspective d’un réseau sémantique peut être utilisée dans le cadre du SEO sémantique en fournissant un réseau de contenu sémantique.
Dans cette étude de cas SEO, deux sites web différents avec deux méthodes différentes avec la même perspective seront expliqués sur la base des modèles de requête, de document, d’intention et des paires entité-attribut derrière eux.
En utilisant une compréhension de la façon dont les moteurs de recherche représentent la connaissance et comment ils étendent leur représentation de la connaissance, je suis capable de m’en servir pour obtenir des résultats de positionnement incroyables. Une fois que vous aurez compris les concepts de base, je vous expliquerai comment je les ai appliqués à deux sites Web différents, puis je détaillerai les méthodes que j’ai utilisées.
Comment les réseaux sémantiques peuvent-ils aider le positionnement de votre site Web ?
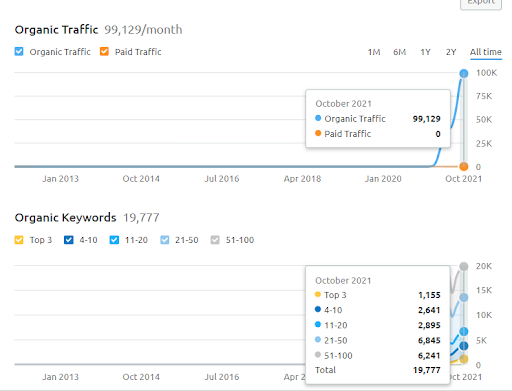
Ci-dessous, vous trouverez les résultats bruts globaux pour le Projet I.
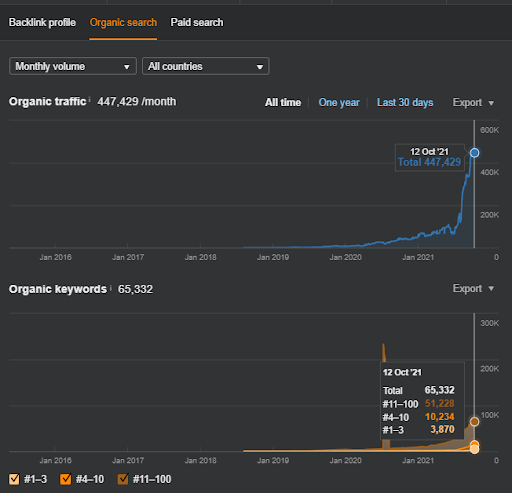
Résultats pour le Projet 1 qui est IstanbulBogaziciEnstitu.com. Pour prouver que les « réseaux sémantiques » peuvent être utilisés pour le SEO avec des modèles de requêtes et de documents, je vais démontrer deux réseaux de contenu différents du projet 1. Le Projet 1 aura de bien meilleurs résultats dans un avenir proche grâce au Réseau de contenu sémantique 2. Le client sera responsable du déploiement de ce deuxième réseau, mais je lui expliquerai également sa logique.
17 jours plus tard, voici l’état d’avancement du projet I :
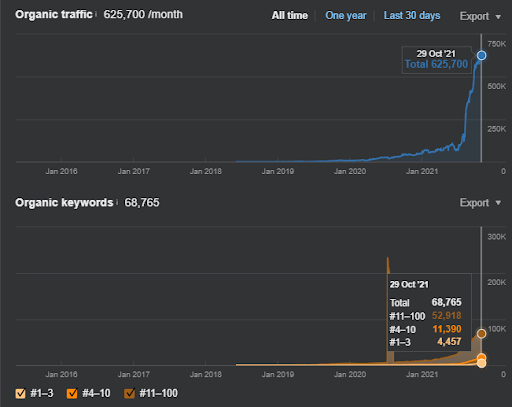
17 jours plus tard, le processus de repositionnement du Réseau de Contenu Sémantique est plus clair.
Les concepts du Réseau de contenu sémantique nous aident à comprendre la valeur de la requête, de l’intention de recherche, du comportement et des modèles de documents pour les entités du même type. Dans cette étude de cas SEO axée sur le réseau sémantique, l’étude de cas précédente sur l’autorité thématique et le SEO sémantique sera approfondie via les deux nouveaux sites Web qui utilisent des réseaux de contenu créés sémantiquement autour des mêmes types d’entités.
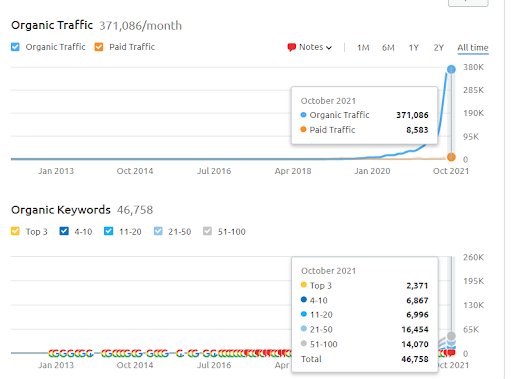
Voici le graphique SEMRush du premier projet. Je dois également mentionner que ce site web a perdu la mise à jour de l’algorithme Broad Core de juin, s’il ne perdait pas sa « Rankabilité », les résultats seraient meilleurs. Pour la prochaine mise à jour de l’algorithme Broad Core, avec une meilleure autorité thématique, une meilleure couverture et des données historiques, il peut facilement retrouver sa « Rankabilité ».
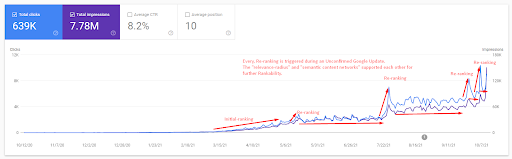
Le nom du deuxième projet est Vizem.net. Contrairement au projet 1, vous pouvez voir que Vizem.net a une augmentation plus lente mais régulière. C’est parce qu’ils utilisent les réseaux de contenu sémantique avec des perspectives légèrement différentes. Ci-dessous, vous pouvez voir les résultats Ahrefs du deuxième projet.
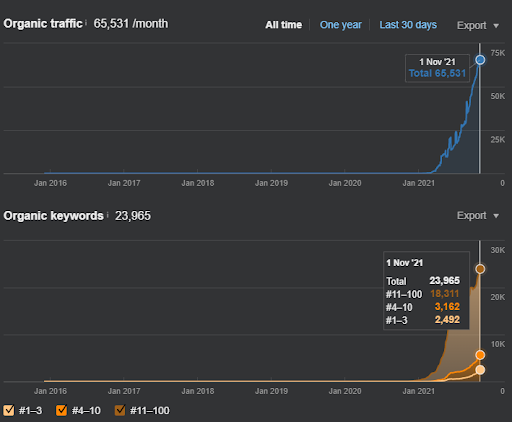
Les résultats du deuxième projet représentent un « processus lent de repositionnement » par l’amélioration progressive de la couverture thématique et de l’autorité. Les termes « Re-ranking » et « Initial Ranking » seront expliqués après les concepts liés aux réseaux de contenu sémantique. Si vous vous rendez compte de la « stabilité » dans les graphiques, c’est parce que j’ai arrêté de publier du nouveau contenu dans la source. Et, cela affecte le processus de repositionnement comme vous pouvez le constater à partir du nombre de requêtes dans les 3 premiers rangs. Les relations « Momentum » et « Re-ranking » se trouvent après les explications des concepts fondamentaux.
Ci-dessous, vous trouverez les résultats SEMRush de Vizem.net.
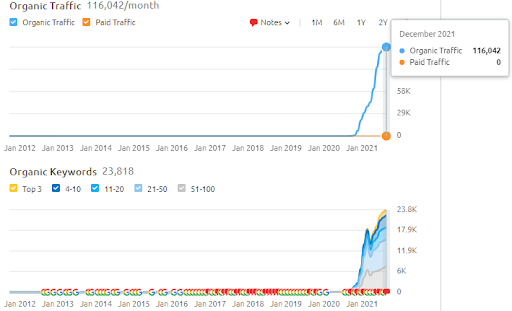
Le trafic réel de ce site est 3x plus important que le nombre indiqué dans SEMRush. Vous pouvez réaliser les mêmes concepts de « stabilité » et « momentum » dans ces graphiques.
Lors de la rédaction de l’étude de cas sur le SEO Topical Authority, j’ai remercié Bill Slawski pour le partage de ses connaissances. C’est également le cas pour cette étude de cas. Pour comprendre les concepts de « Re-rank » et « Initial-rank », il faut lire “Ways Search Engines May Rerank Search Results”.
Le 18 mars 2021, Oncrawl, RankSense et Holistic SEO & Digital ont publié un webinaire Python SEO and Data Science. Dans ce webinaire, la SERP a été enregistrée pour animer les différences de résultats. On peut voir que le moteur de recherche change les positionnements de certaines sources avec d’autres avec une fréquence similaire.
Avant de poursuivre, je sais que cet article est long. Mais, en réalité, il s’agit d’une brève explication d’une méthodologie SEO très complexe. Les réseaux de contenu sémantique demandent trop de réflexion lors de leur conception, et des mois d’apprentissage pour les clients, les auteurs, et tout au long de l’onboarding. Ainsi, dans cet article, je veux me concentrer sur les définitions des concepts avec les meilleures suggestions brèves exécutables possibles et les brevets importants de Google et d’autres moteurs de recherche, les documents de recherche ainsi que leurs propres concepts. Dans la version longue (en fait, un livre), je me suis concentré sur le « positionnement initial » et le « repositionnement » des réseaux de contenu sémantique.
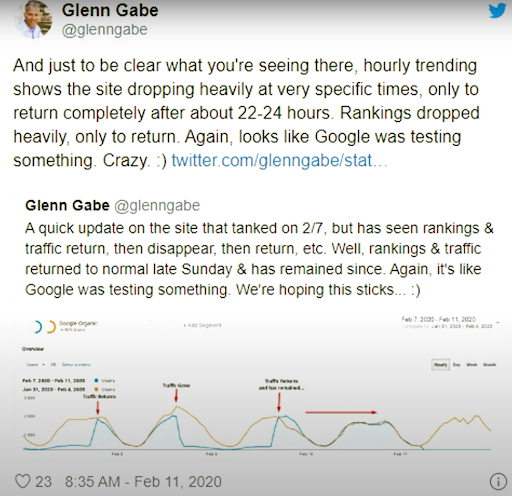
Le 11 février 2020, Glenn Gabe a donné un bon exemple de méthodologie de repositionnement et de test des moteurs de recherche visuellement.
Si vous voulez en savoir plus, lisez “Importance of Initial Ranking and Re-ranking for SEO”.
Pour plonger dans les données du monde réel de l’étude de cas SEO, les concepts pour comprendre le réseau de contenu sémantique doivent être traités dans une perspective de compréhension et communication des moteurs de recherche.
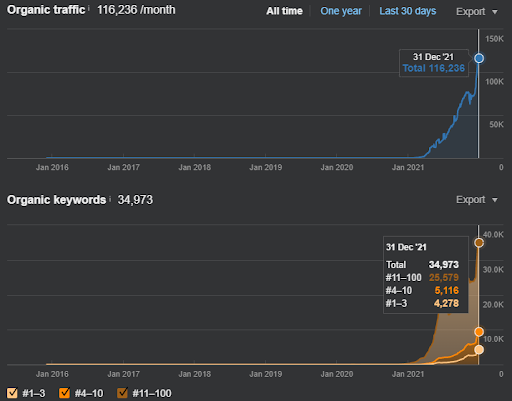
Un exemple de repositionnement de Vizem.net, la situation actualisée peut être vue ci-dessus. Dans les prochaines sections de l’étude de cas SEO, il y aura plus d’explications sur les algorithmes de repositionnement de Google pour le SEO.
Qu’est-ce qu’un réseau sémantique ?
Un réseau sémantique peut être utilisé pour connecter et analyser l’internet des objets. Il peut être bénéfique pour reconnaître les acheteurs potentiels sur le marché de la technologie, ou simplement pour l’analyse des co-mots pour la création de réseaux de mots-clés et le regroupement. Un réseau sémantique peut être utilisé pour soutenir la navigation et révéler la structure des relations, ou l’importance relative d’une chose par rapport à une autre. Le réseau sémantique a les composantes suivantes :
- Sémantique lexicale : Comprendre quels mots et concepts sont liés à quels autres, avec quelles différences.
- Composante structurelle : Comprendre quel nœud est connecté à quel bord avec quelle information.
- Composante sémantique : Définition des faits.
- Composante procédurale : Aide à créer d’autres connexions entre les composantes.
Les réseaux sémantiques étant polyvalents, les algorithmes NLP peuvent également être utilisés à des fins très diverses, par exemple pour aider à identifier des problèmes de santé complexes. La même structure de réseau sémantique peut être mise en œuvre dans plusieurs autres domaines, pour autant que ces autres domaines aient une relation sémantique entre eux.
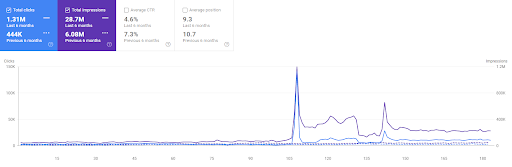
Comparaison des 6 derniers mois du premier projet.
Qu’est-ce qu’une base de connaissances ?
Une base de connaissances est une bibliothèque d’informations contenant une classification sous une forme lisible par une machine. Une base de connaissances peut être utilisée comme une encyclopédie qui peut être réduite et approfondie en fonction de la requête. Une base de connaissances peut être formée à partir de propositions, de l’extraction de faits et de l’extraction d’informations. La relation entre un réseau sémantique et une base de connaissances est que tout ce qui est dans le réseau sémantique sera placé dans la base de connaissances tout en extrayant les faits.
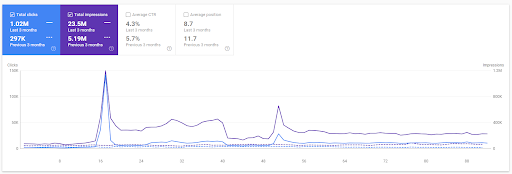
Comparaison des trois derniers mois du premier projet
Qu’est-ce qu’un réseau de contenu sémantique ?
Le réseau de contenu sémantique représente un réseau de contenu qui a été préparé sur la base des composants et de la compréhension du réseau sémantique. Un réseau de contenu sémantique peut inclure plusieurs attributs d’une entité ou d’entités du même groupe afin de fournir une base de connaissances plus détaillée.
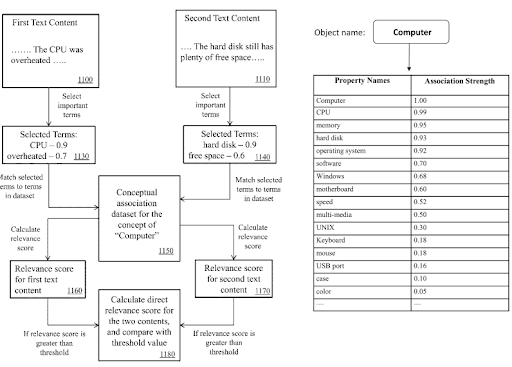
Dans un réseau de contenu sémantique, les termes du domaine de connaissances peuvent être utilisés pour signaler l’objectif principal d’un document et les éventuels éléments de contenu voisins.
Un moteur de recherche peut comparer sa propre base de connaissances à la base de connaissances qui peut être générée à partir du contenu d’un site web. Si le site Web présente un niveau élevé de précision et d’exhaustivité pour les différentes couches contextuelles, le moteur de recherche peut améliorer sa propre base de connaissances à partir du contenu du site Web. Si un moteur de recherche améliore et développe sa propre base de connaissances à partir d’une autre source sur le web ouvert, c’est le signal d’un haut niveau de confiance basé sur la connaissance.
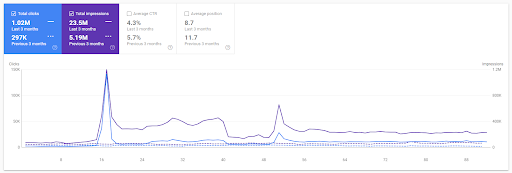
Comparaison d’une année sur l’autre pour les 3 derniers mois sur la base du premier projet.
Qu’est-ce que la connaissance basée sur la confiance ?
La connaissance basée sur la confiance se concentre sur le web ouvert sur la « précision de l’information », et non sur le « PageRank ». Il s’agit d’un algorithme similaire à celui de RankMerge. La confiance basée sur la connaissance implique des triplets, l’extraction de faits, la vérification de l’exactitude et la compréhension du texte en supprimant l’ambiguïté du texte. La confiance basée sur la connaissance peut être acquise en fournissant des réseaux de contenu sémantique qui ont les composants fortement connectés dans l’article, basés sur des couches contextuelles différentes mais pertinentes.
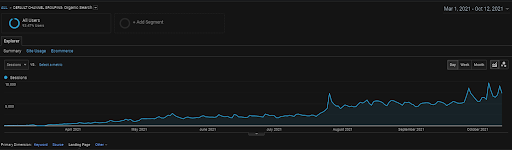
La session organique du Vizem.net de GA pour les 6 derniers mois.
Ci-dessous, vous verrez un exemple de présentation de la confiance basée sur la connaissance de Luna Dong. Elle montre comment un moteur de recherche peut se concentrer sur les « facteurs de positionnement internes » plutôt que sur les facteurs de positionnement exogènes. Il explique qu’un PageRank élevé ne peut pas représenter à lui seul une qualité et une précision élevées du contenu. Il est donc important d’avoir un KBT (Knowledge-based Trust).
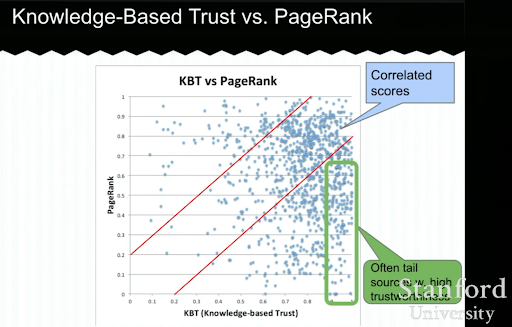
Un grand merci à Arnout Hellemans qui a partagé cette conférence éducative avec moi lors d’un chat privé sur le SEO. Si vous voulez en savoir plus sur la confiance basée sur la connaissance : Stanford Seminar – Knowledge Vault and Knowlege-Based Trust
Qu’est-ce que la couverture contextuelle ?
La couverture contextuelle et la couverture thématique ne sont pas les mêmes, tout comme le domaine de connaissances et le domaine contextuel ne sont pas les mêmes. Une couverture contextuelle représente les angles de traitement d’un concept. Un concept peut être traité en fonction de ses points communs avec d’autres choses. Par exemple, si l’entité est un pays, sa position sur la crise environnementale peut être traitée. Si d’autres pays sont traités sous le même angle, cela signifie que nous couvrons un domaine contextuel.

Le moteur de recherche Google construit ses documents de recherche et ses brevets au fil du temps. La citation de droite de la section ci-dessus est un attribut des « vecteurs contextuels » tandis que la section de gauche est un attribut de la « taxonomie des phrases ». Ce qui est intéressant, c’est que même l’exemple est le même, à savoir « appareil photo numérique ».
Les détails approfondis et les sous-parties de ces combinaisons représentent les couches contextuelles dans un domaine contextuel. Chaque entité, qu’elle soit nommée ou non, possède de nombreux domaines contextuels. Ainsi, Google extrait plus de domaines contextuels et les utilisateurs effectuent des recherches plus longues chaque année. Lorsque le traitement et la compréhension du langage naturel sont développés, les requêtes et les documents se développent ensemble en termes de détails et de contexte.
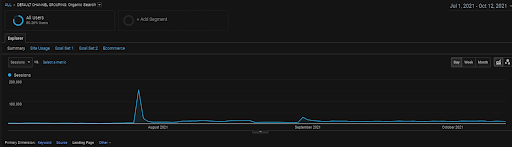
Le graphique des sessions organiques de GA pour les 4 derniers mois du projet BoğaziciEnstitu. En raison de la « phase d’acquisition de données historiques » du projet, l’augmentation des détails n’est pas claire et ne peut être considérée comme linéaire.
Une couverture contextuelle peut être comprise par les « qualificatifs de contexte ». Un qualificatif de contexte peut être un adjectif, un adverbe ou toute autre préposition telle que les phrases commençant par « for, in, at, during, while ». Les questions liées aux entités ci-dessous ne sont pas les mêmes en termes de domaine contextuel :
- Quels sont les fruits les plus utiles pour les enfants insomniaques ?
- Quels sont les fruits les plus utiles pour les enfants souffrant d’anxiété ?
Les questions liées à l’entité ci-dessous ne sont pas les mêmes en termes de couche contextuelle :
- Quels sont les fruits les plus utiles pour les enfants de plus de 6 ans souffrant d’insomnie sévère ?
- Quels sont les fruits les plus utiles pour les enfants de moins de 6 ans souffrant d’une faible anxiété ?
Les questions liées aux entités ci-dessous ne sont pas les mêmes en termes de domaines de connaissances :
- Quels sont les livres les plus utiles pour les enfants de plus de 6 ans souffrant d’insomnie sévère ?
- Quels sont les jeux les plus utiles pour les enfants de moins de 6 ans souffrant d’anxiété légère ?
Mais toutes ces questions peuvent se trouver dans le même réseau de contenu sémantique parce qu’elles concernent toutes le même « concept » et le même « domaine d’intérêt », avec une activité de recherche similaire et une activité dans le monde réel liée à la recherche.
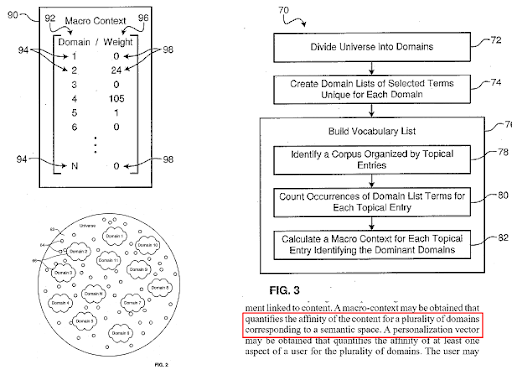
Un moteur de recherche divise le web en différents domaines de connaissances et calcule les scores de macro et micro contexte pour une source, une page web et une section de page web en même temps.
Je sais que j’ai beaucoup de nouveaux concepts pour vous, et puisque c’est la version brève de cet article, je ne serai pas en mesure de parler de tout ici, mais dans un futur cours de SEO sémantique, je traiterai ces choses telles que la différence entre « activité de recherche », et « activité du monde réel liée à la recherche ».
Continuons un peu vers les choses plus concrètes.
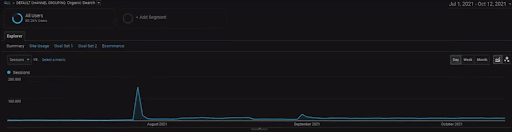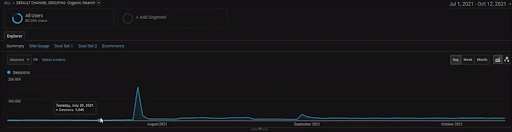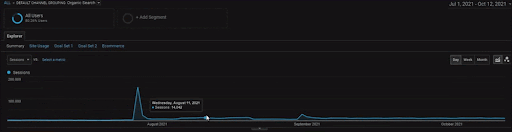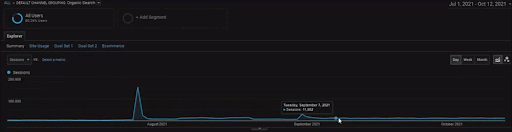
Pour montrer les détails du projet BogaziciEnstitu, vous pouvez consulter la version interactive en images. Le processus de test et de repositionnement des moteurs de recherche est plus clair sur ce projet après l’événement de la source de données historiques.
Comment MuM est-il lié aux réseaux de contenu sémantique ?
L’apprentissage multitâche avec un transformateur unifié ou le modèle multitâche unifié forme des modèles de langage pour évaluer des entrées visuelles, ainsi que du texte. Il est capable de générer du texte tout en le comprenant. En outre, MuM est agnostique par rapport au langage, en d’autres termes, le SEO sémantique dépend des compétences linguistiques, mais il n’est pas limité à une langue. Puisque les entités n’ont pas de langue et que le sens est universel, MuM exploite les informations provenant de plusieurs langues et de plusieurs contextes en une seule base de connaissances.
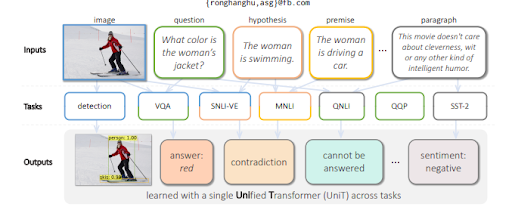
Pour répondre aux questions d’un visuel, MuM génère des questions basées sur les objets détectés dans une image. Dans un futur proche, des questions liées à l’audio et à la vidéo pourront également être générées.
MuM utilise différents domaines pour la détection d’objets et la compréhension du langage naturel avec une structure d’encodeur-décodeur transformateur. Chaque entrée provient d’un domaine différent du web ouvert, tandis que toutes les entrées sont évaluées à partir d’un seul décodeur partagé. Ci-dessous, vous pourrez voir un autre exemple tiré du document de recherche.
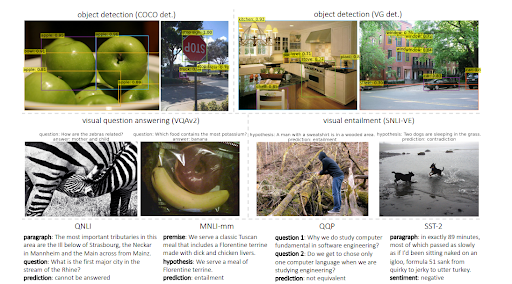
A noter que MuM peut être 1000 fois plus fort que BERT, mais BERT est toujours utilisé dans l’encodeur de texte de MuM. Le principal avantage de MuM est qu’il peut être utilisé pour les images et l’audio directement, c’est pourquoi il peut être appelé un modèle « multitâche ». Le deuxième avantage est qu’il élimine directement toutes les barrières linguistiques. Le troisième avantage est qu’il est capable de connecter tout à autre chose sans avoir besoin d’intermédiaires supplémentaires. Le quatrième avantage est que MuM peut également générer du texte, contrairement à BERT.
Le lien entre MuM, la base de connaissances, les réseaux sémantiques et la couverture contextuelle est que le moteur de recherche est capable de trouver beaucoup plus de domaines contextuels via les qualificatifs contextuels et leurs combinaisons avec les domaines de connaissances possibles. Ainsi, un réseau de contenu sémantique bien structuré, façonné avec une carte thématique et un contexte de source appropriés, peut améliorer la confiance dans la base de connaissances, ainsi que l’autorité thématique.
Qu’est-ce que le contexte de la source ?
Le contexte de la source représente deux choses. L’internet de recherche central de la source, et l’activité de recherche centrale qui peut être effectuée avec l’activité de recherche associée. Pour un site de e-commerce, le contexte de la source est l’achat d’un produit spécifique ou d’un type de produit spécifique. S’il s’agit d’un site Web de voyage, le contexte de la source est de se rendre dans un autre endroit pour différents types d’aliments, de paysages, ou simplement d’affaires. En fonction du contexte de la source, la conception du Réseau de contenu sémantique et la carte thématique devront être configurées davantage. Cela nécessite de choisir les sections centrales et les sections supplémentaires de la carte thématique.
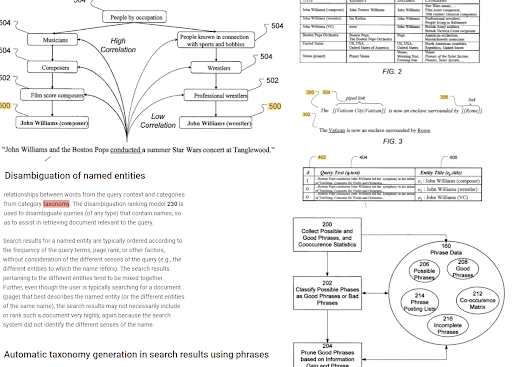
L’indexation basée sur les phrases et la compréhension de la recherche orientée vers les entités sont connectées les unes aux autres sur la base de la sémantique. Ci-dessus, la « désambiguïsation des entités nommées » et la « génération automatique de taxonomie dans les résultats de recherche à l’aide de phrases » peuvent être vues ensemble pour déterminer le « contexte ». Les bonnes phrases et les informations uniques mais corrélées à un sujet permettront d’améliorer le positionnement initial et le repositionnement.
Encore une fois, certains de ces concepts, la « configuration de la carte thématique », la « conception du réseau de contenu sémantique » n’ont pas encore été définis, et ce n’est pas le bon endroit pour le faire. Mais l’activité de recherche connexe a été expliquée ainsi que l’intention de recherche canonique et les phrases représentatives de ces intentions de recherche canonique.
Contexte de l’étude de cas SEO centrée sur le Réseau Sémantique
Sur la base des concepts ci-dessus, j’ai utilisé les Réseaux Sémantiques pour créer une étude de cas SEO. Nous allons nous pencher sur les deux projets de sites Web que j’ai mentionnés au début de cet article et examiner les résultats, ainsi que la façon dont j’ai mis en œuvre les Réseaux Sémantiques pour les produire.
Pour vous donner une idée de la puissance de ces réseaux, les résultats liés au SEO pour l’étude de cas SEO axée sur les Réseaux Sémantiques sont énumérés ci-dessous.
- La compréhension des Réseaux Sémantiques est une nécessité pour créer une Carte Thématique appropriée.
- Pour les deux projets, le SEO technique n’est pas utilisé afin d’isoler les effets du SEO sémantique.
- L’optimisation de la vitesse des pages n’est pas utilisée, pour la même raison.
- L’optimisation du design et du WUX (Website User Experience) n’est pas utilisée.
- Les backlinks (références externes et flux de PageRank) ne sont pas utilisés.
- Les deux marques ne disposent pas de données historiques. Vizem.net est complètement nouveau, BoğaziçiEnstitusu a un historique plus ancien mais il était inférieur à celui de la société actuelle.
- Le SEO on-page ou d’autres verticaux du SEO ne sont pas utilisés.
- Les deux marques ont un meilleur serveur que l’exemple précédent de l’étude de cas sur l’autorité thématique.
Cette étude de cas SEO centrée sur le réseau sémantique aidera les personnes qui veulent améliorer leur perspective SEO sémantique avec deux méthodologies et concepts différents qui se concentrent sur deux sites web différents.
Deuxième projet : Vizem.net se concentre sur le processus de demande de visa. Avant d’écrire, de publier ou même de lancer ces projets, j’ai montré ces deux sites Web à plusieurs reprises à mes autres clients ou partenaires. Et, Vizem.net a commencé son voyage sur l' »Autorité thématique » récemment.
L’étude de cas SEO based on Semantic Networks a été rédigée en deux versions différentes. Si vous voulez lire tous les brevets, les documents de recherche, les examens détaillés et les interprétations du point de vue des moteurs de recherche, tout en comprenant mieux les arbres de décision des moteurs de recherche, vous pouvez lire l’article « Importance du positionnement initial et du repositionnement » de l’étude de cas SEO, qui compte plus de 30 000 mots. Si vous n’avez pas suffisamment de connaissances théoriques sur le SEO et le contexte historique, vous pouvez continuer à lire le résumé.
Ci-dessous, vous pouvez voir le graphique du deuxième projet (Vizem.net) de SEMRush.
Le graphique SEMRush du Second Site. Vizem.net est une source entièrement nouvelle qui cible les industries avec un niveau élevé de concurrents enracinés comme « Demande de visa ». En particulier, en raison des derniers événements en Turquie, le niveau de concurrence de l’industrie augmente. Ainsi, l’utilisation de la perspective du réseau sémantique pour créer un réseau de contenu est utile.
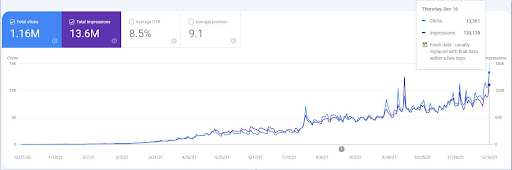
Premier projet : İstanbul Boğaziçi Enstitüsü : Augmentation de 600% des clics organiques en 3 mois – Exploitation des données historiques et positionnements initiaux.
İstanbulBoğaziçi Enstitusu est l’une des études de cas SEO les plus difficiles que j’ai réalisées, non pas à cause des moteurs de recherche, mais à cause des personnes et de mes problèmes de santé. Ainsi, j’ai quitté le projet et je n’ai pas publié le troisième réseau de contenu sémantique qui est conçu pour compléter les relations sémantiques basées sur le contexte de la source. Même si les termes du domaine de connaissance et les phrases contextuelles ne sont pas correctement implémentés, il est configuré avec suffisamment de niveaux de connexions sémantiques et de précision pour permettre une performance globale de recherche organique de plus de trois millions de sessions par mois si le troisième réseau de contenu est publié à l’avenir, en tenant compte de l’effet croissant du deuxième réseau de contenu sémantique.
Ci-dessous, vous pouvez voir l’évolution des graphiques de l’İstanbulBoğaziçi Enstitusu sur GSC au cours des 12 derniers mois. Le projet a été lancé en mai 2021 de manière appropriée et s’est terminé en septembre 2021 par la publication de deux réseaux de contenu sémantique.
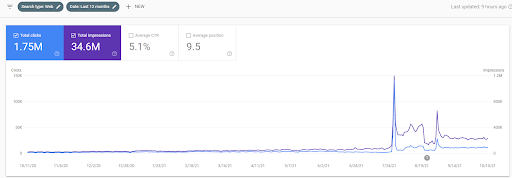
Ci-dessous vous pouvez voir la version plus détaillée. De 1400 clics quotidiens à 140000 clics, puis à plus de 10.000 clics par jour, on peut voir la performance de la recherche organique.
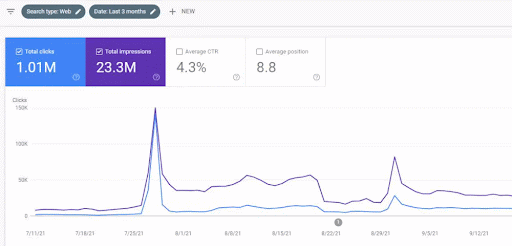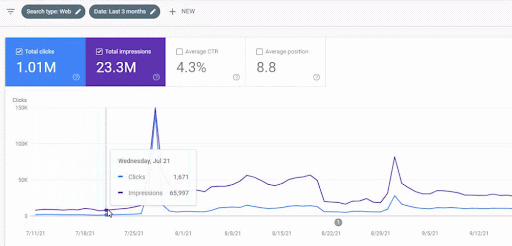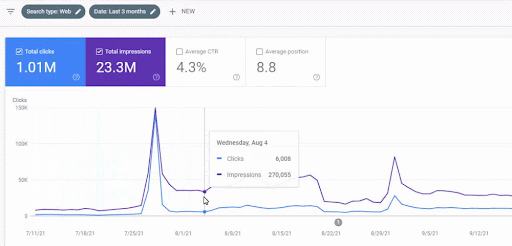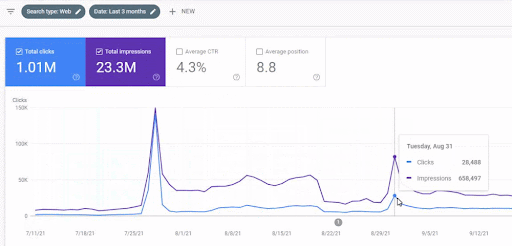
L’augmentation du trafic du premier réseau de contenu après son lancement est visible ci-dessous.
Cette capture d’écran montre le 4ème mois du premier réseau de contenu sémantique.
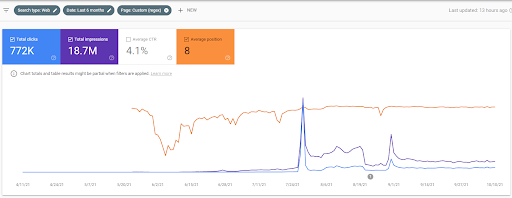
Comme vous pouvez le voir sur le graphique, le trafic global du site a été dominé et affecté par le premier réseau de contenu sémantique qui se concentre sur les « branches éducatives ». Le deuxième réseau de contenu que j’ai lancé avec ce site Web est visible ci-dessous dans la Google Search Console. La capture d’écran ci-dessous date du 16e jour du deuxième réseau de contenu sémantique.
Le positionnement initial et le repositionnement ont été utilisés dans l’article parce qu’ils définissent les phases des algorithmes de positionnement ainsi que leurs types et leurs objectifs avant de tester une source, et une page web de la source dans les SERPs pour les requêtes plus importantes qui ont une popularité.
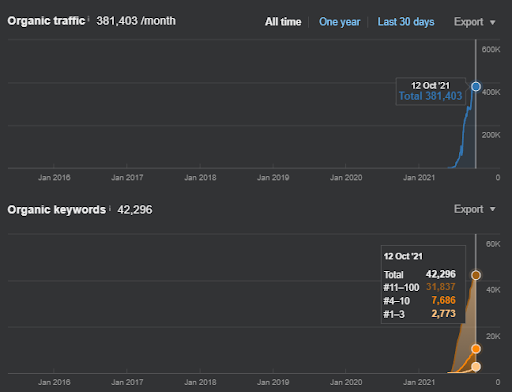
Sur quoi se concentre le premier réseau de contenu sémantique du premier projet ?
Le « Réseau de contenu sémantique » utilise un réseau sémantique à partir d’une base de connaissances pour expliquer les relations principales, secondaires et tertiaires entre les éléments de la base de connaissances. Ainsi, la création d’un réseau de contenu sémantique nécessite de concevoir le réseau de contenu sémantique suivant en fonction du contexte de la source qui est la fonction principale du site web. Dans ce contexte, le premier réseau de contenu sémantique s’est concentré sur « les départements universitaires, les branches éducatives et les nécessités d’une éducation universitaire dans une organisation et une branche spécifiques. »
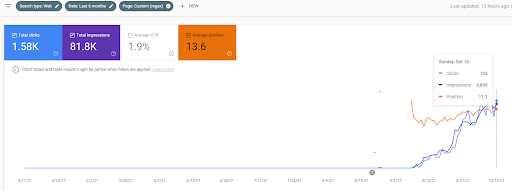
Ci-dessous, vous trouverez le graphique Ahrefs du premier réseau de contenu sémantique.
C’est cinq jours plus tard par rapport à la capture d’écran précédente.
« Root : istanbulbogazicienstitu.com/bolum », après la première phase de positionnement initial, le processus de repositionnement est plus efficace et productif.
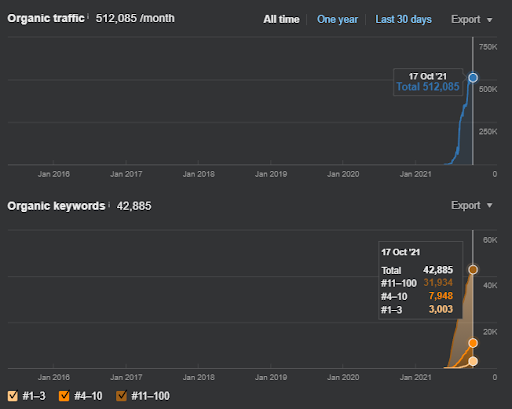
Vous pouvez voir la version quatre jours plus tard comme ci-dessous pour soutenir la nature du « repositionnement ».
Sur quoi se concentre le deuxième réseau de contenu sémantique du premier projet ?
Le deuxième réseau de contenu sémantique se concentre sur les professions, les emplois, les compétences et l’éducation nécessaire pour acquérir ces compétences, ou la routine. Sur la base du premier réseau de contenu sémantique, le deuxième réseau de contenu sémantique a été soutenu. Et, selon les « modèles de requête – modèles d’intention », deux autres réseaux de sous-contenu sémantique différents sont créés et placés avec les « connexions relationnelles » tout en étant connectés aux niveaux hiérarchiques supérieurs similaires.
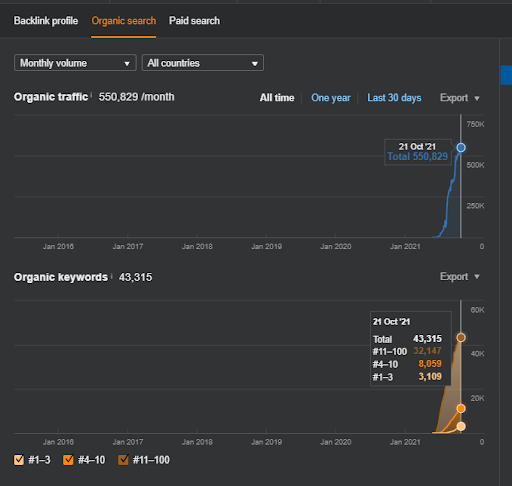
Je sais que ces sections sont compliquées pour vous parce que vous n’avez pas encore vu de définition pour les choses ci-dessous.
- Réseau de contenu sémantique
- Contexte de la source
- Réseau de sous-contenu sémantique
- Base de connaissances
- Connexions relationnelles
- Positionnement initial
- Re-positionnements
- Couverture contextuelle
- Positionnements comparatifs
- Extraction de faits
Après avoir expliqué le deuxième site Web, il sera plus facile de comprendre ces concepts et ces phrases.
Vizem.net : De 0 à plus de 9 000 clics par jour en 6 mois – Positionnements comparatifs avec couverture contextuelle.
Vous pouvez voir le graphique de Vizem.net pour les 12 derniers mois. Pour ce projet, en raison de la Covid-19, nous avons connu beaucoup de problèmes économiques car l’investisseur est issu de l’industrie de la gym. Ainsi, je peux dire que les problèmes économiques ont ralenti le projet, et ont causé une certaine latence pour les « processus de repositionnement ».
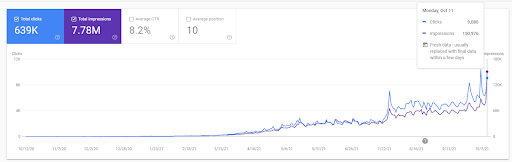
Pour comprendre le positionnement initial, et le re-positionnement un peu plus loin, vous pouvez utiliser le graphique ci-dessous.
Vous trouverez ci-dessous certaines des définitions liées au positionnement initial et au repositionnement du graphique ci-dessus.
- Les grands positionnements ont eu lieu pendant les mises à jour non confirmées de Google. Certains tests ont donné des Featured Snippets et des People Also asked Questions.
- Certains tests de Google ont supprimé les gains FS et PAA.
- À chaque fois, le délai entre deux processus de positionnement était plus court.
- Les processus de repositionnement ont amélioré le positionnement de la source à chaque fois.
- La source a toujours amélioré son rayon de pertinence tout en élargissant les groupes de requêtes.
En guise de remarque, je peux laisser une phrase ci-dessous.
Si un moteur de recherche indexe votre page Web, cela ne signifie pas qu’il a compris la page Web. L’indexation se fait plus rapidement que la compréhension, et la plupart du temps, un moteur de recherche positionne une page web avec des prédictions, « initialement ». Après la compréhension, le « repositionnement » se produit.
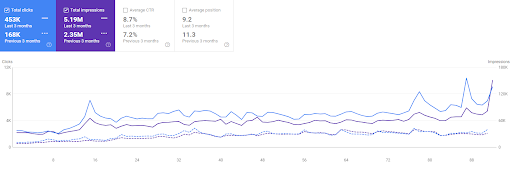
Comparaison des 3 derniers mois de Vizem.net
Comment est le réseau de contenu sémantique de Vizem.net ?
Je me souviens que pour beaucoup de mes clients, amis, ou groupes secrets de SEO, pendant les réunions, j’ai fait la démonstration de ces deux sites en disant « ils vont exploser ». Et, en écrivant cet article, je vous le dis :
Regardez le réseau de contenu sémantique « istanbulbogazicienstitu.com/meslek », car il va exploser. Et, vous pouvez trouver une vidéo que j’ai publiée avant d’écrire cet article en démontrant les « données historiques » d’un événement saisonnier et son effet sur les processus de positionnement initial et de repositionnement. Vous pouvez la voir ci-dessous.
Sur cette base, le réseau de contenu sémantique de Vizem.net n’est pas similaire au İstanbulBogazici Enstitusu, donc, je n’ai pas utilisé un « niveau intense de couverture thématique et d’augmentation des données historiques », j’ai dû créer l’autorité liée à certains types d’entités, leurs attributs, et les actions possibles derrière les requêtes pour ces paires entité-attribut. Vizem.net ne contient pas seulement des « branches d’universités » ou des « professions et cours en ligne ». Il contient également des « pays pour les demandes de visa ». Ainsi, pour créer un niveau suffisant d’autorité thématique, il faut une cohérence dans le temps avec au moins 190 réseaux de contenu sémantique différents.
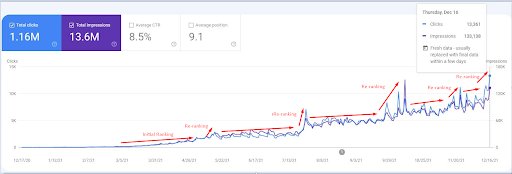
Une capture d’écran du 18 décembre 2021. Vous pouvez voir le repositionnement continu et l’augmentation des impressions et des clics, 4 semaines plus tard par rapport à la capture d’écran précédente.
Pour voir les événements de repositionnement, vous pouvez comparer la version nue du graphique de performance de recherche organique qui démontre l’effet du SEO sémantique.
Ces 190 réseaux de contenu sémantique différents sont formés sur la base du « pays » lui-même, et les pays sont placés au centre de la carte thématique avec toutes les couches contextuelles possibles pour améliorer la couverture de l’activité de recherche.
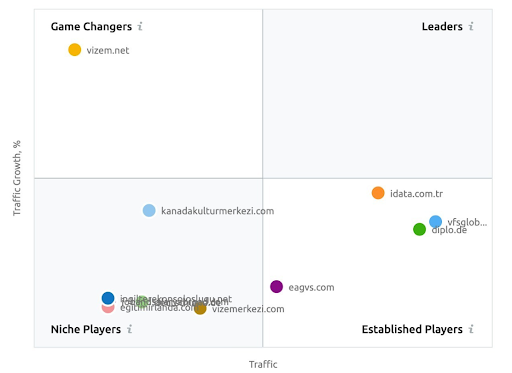
Une capture d’écran de SEMRush montrant leur perception de Vizem.net contrairement aux autres acteurs du secteur.
J’ai également publié une autre vidéo, juste pour Vizem.net. Dans cette vidéo, la dernière situation du site n’existe pas, donc, je crois, elle fournit également une bonne comparaison entre aujourd’hui et ce jour-là.
Enfin, la publication de choses non pertinentes dans un article, un segment de site Web ou une source non pertinente peut diminuer la pertinence globale de l’entité Web par rapport au domaine de connaissances spécifique. Vizem.net montrera sa vraie valeur, et la Rankabilité dans le futur sera bien meilleure.
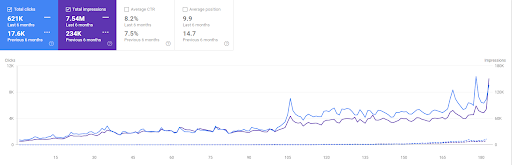
La comparaison des 6 derniers mois de Vizem.net.
Avant de continuer, je sais que c’est un long article. Mais, en fait, il s’agit d’une brève explication d’une méthodologie SEO très complexe. Les réseaux de contenu sémantique nécessitent trop de réflexion lors de leur conception, et des mois d’éducation pour les clients, les auteurs, et tout au long de l’onboarding. Ainsi, dans cet article, je veux me concentrer sur les définitions des concepts avec les meilleures suggestions brèves exécutables possibles et les brevets importants de Google et d’autres moteurs de recherche, les documents de recherche ainsi que leurs propres concepts. Dans la version longue (en fait, un livre), je me suis concentré sur le « positionnement initial » et le « repositionnement » des réseaux de contenu sémantique.
Si vous voulez en savoir plus, lisez “Importance of Initial Ranking and Re-ranking for SEO”.
Jusqu’à présent, nous avons traité les éléments ci-dessous.
- Réseau sémantique
- Base de connaissances
- Réseau de contenu sémantique
- Connaissance basée sur la confiance
- Couverture contextuelle
- Domaine et couches contextuelles
- Pertinence de MuM pour les réseaux de contenu sémantique
- Contexte de la source
Ces concepts permettent de comprendre comment fonctionnent les réseaux de contenu sémantique et comment ils peuvent être utilisés avec une carte thématique. Les prochaines sections porteront sur la façon dont un moteur de recherche positionne les Réseaux de Contenu Sémantique Initialement et plus tard, en les modifiant. Dans ce contexte, les éléments ci-dessous seront traités.
- Positionnement initial
- Re-positionnements
- Modèle de requête
- Modèle de document
- Modèle d’intention de recherche
- Ce que vous devez faire pour tirer parti des réseaux de contenu sémantique
Qu’est-ce que le positionnement initial pour le SEO ?
Il s’agit d’un nouveau terme et concept pour le SEO, mais d’un vieux terme pour les moteurs de recherche. La version longue de l' »Étude de cas SEO axée sur les réseaux sémantiques » se concentre sur les algorithmes de positionnement basés sur des algorithmes dépendant de la requête, du document et de la source, et sur de multiples brevets. Les algorithmes de recherche d’information prédictive ou de positionnement prédictif tentent de réduire le coût des calculs. En effet, même si l’indexation se fait en un jour, la compréhension d’un document peut prendre des mois, voire des années. Le calcul d’un positionnement initial est donc un moyen d’améliorer la qualité des SERPs tout en réduisant le coût. Certaines tâches liées aux moteurs de recherche sont plus prioritaires que d’autres pour maintenir l’index en vie, récent et de qualité suffisante.

Le terme « positionnement initial » apparaît dans des dizaines de milliers de brevets Google et de documents de recherche, car il s’agit d’un point de vue classique parmi les constructeurs de moteurs de recherche. Ainsi, ci-dessus, vous pouvez voir différents documents de brevets avec la continuation des mêmes paragraphes, et des termes avec des changements mineurs autour du terme initial-ranking.
Le positionnement initial représente le rang d’un document sur les SERPs immédiatement après son indexation. Le positionnement initial d’un document représente l’autorité globale et la pertinence de la source par rapport au sujet spécifique, au modèle de requête et à l’intention de recherche. Le même contenu peut être classé différemment en termes de positionnement initial entre différentes sources. Le positionnement initial est important lors de l’utilisation des réseaux de contenu sémantique pour voir la qualité globale et l’augmentation de l’autorité de la source. Chaque nouveau document augmente son positionnement initial tout en réduisant le délai d’indexation si la conception du réseau de contenu sémantique est correctement structurée.
Le positionnement initial soutient le processus de re-positionnement et son efficacité pour la source. Et, la « Rankabilité d’une source » devrait être traitée avec ces deux termes, positionnement initial et re-positionnement.
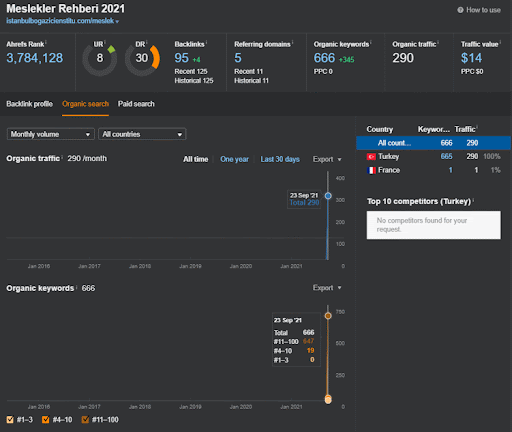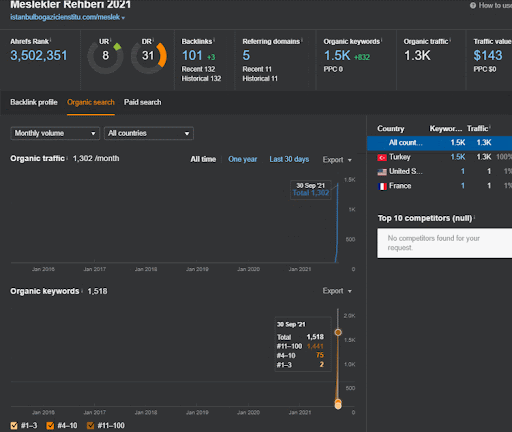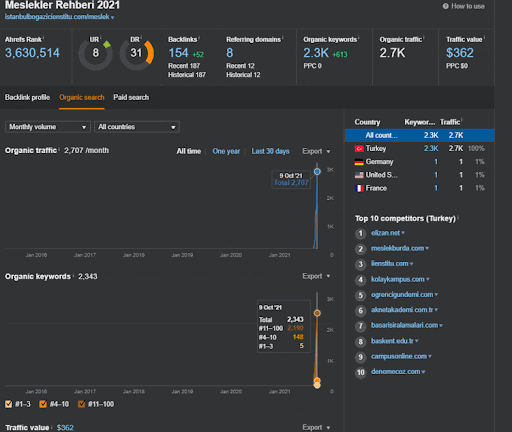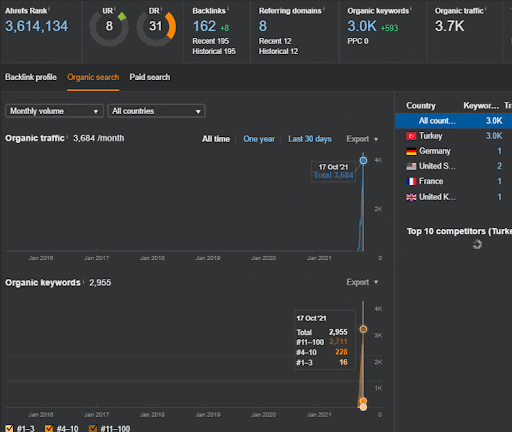
Vous pouvez observer les 20 premiers jours du changement de performance organique du Second Content Network par rapport au Projet I.
Dans ce contexte, chaque fois que Vizem.net publie un nouveau document, ou que l’İstanbulBogazici Enstitu publie un nouveau réseau de contenu sémantique, le positionnement initial est meilleur qu’auparavant tandis que le contenu est indexé plus rapidement.
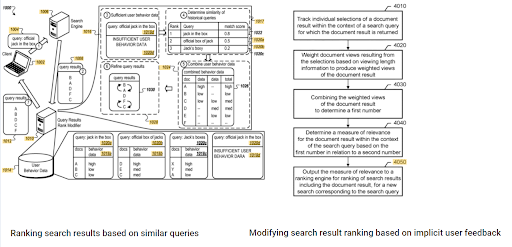
La proéminence du positionnement initial et des données historiques peut être observée entre ces deux brevets complémentaires de Google. L’un concerne le positionnement initial et le repositionnement des documents sur la base des commentaires implicites des utilisateurs. L’autre permet de faire de même en l’absence d’un niveau suffisant de données utilisateur, sur la base de requêtes similaires. Les requêtes similaires sont également le point qui relie la sémantique. La création d’un réseau de contenu sémantique réduira l’énergie nécessaire pour lire l’esprit du propriétaire du site Web du point de vue du moteur de recherche.
Qu’est-ce que le repositionnement pour le SEO ?
Le re-positionnement est le processus qui consiste à modifier le positionnement d’un document sur les SERPs en fonction des commentaires des utilisateurs, de la pertinence et des algorithmes d’évaluation de la qualité. La fréquence de repositionnement peut signaler une mise à jour de l’algorithme, ou une mise à jour du document, ou une mise à jour de l’ensemble du site pour une source. Le repositionnement est affecté par les données historiques qui sont expliquées dans l’étude de cas SEO précédente qui se concentre sur l’autorité thématique. L’examen des processus de repositionnement et le retour d’information des moteurs de recherche aident à la configuration de la conception du réseau de contenu sémantique. Les délais de repositionnement peuvent être raccourcis grâce au trafic réel et aux données historiques si la couverture contextuelle et thématique est améliorée.
Les processus de re-positionnement sont affectés par le positionnement initial et la qualité du contenu du voisinage. Le contenu du voisinage affectera le positionnement de tout composant fortement connecté. Les processus de repositionnement peuvent signaler les points faibles et la capacité du moteur de recherche à comprendre certaines sections du réseau de contenu sémantique. Si la conception est correctement réalisée, le réseau de contenu sémantique continuera à s’élever en termes de performances de recherche organique au fil du temps, et toute mise à jour de Google confirmera ces processus.
Ci-dessous, vous pouvez voir la comparaison du réseau de contenu sémantique 1 et du réseau de contenu sémantique 2 de l’İstanbulBoğaziçi Enstitu en termes de positionnement initial et de repositionnement.
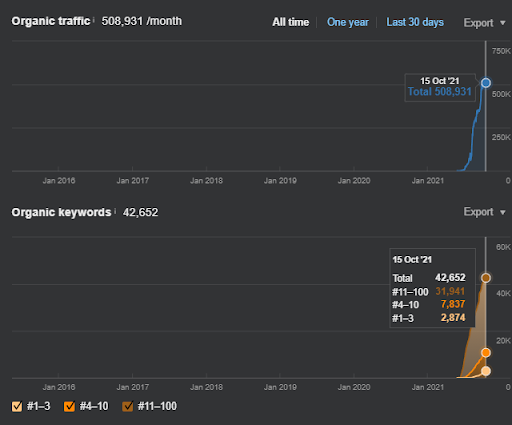
15 octobre 2021, performance du premier réseau de contenu sémantique de l’İstanbulBoğaziçiEnstitusu qui est le 124e jour du lancement.
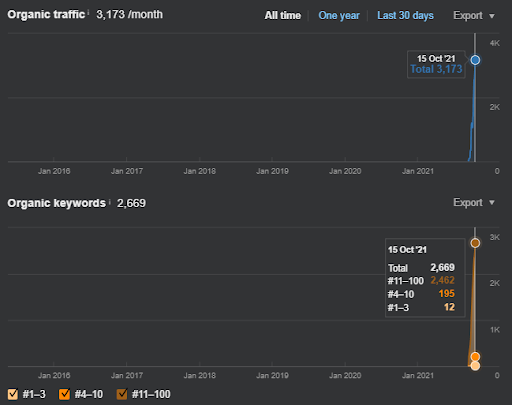
15 octobre 2021, performance du deuxième réseau de contenu sémantique de l’İstanbulBogazici Enstitu qui est le 19e jour du lancement.
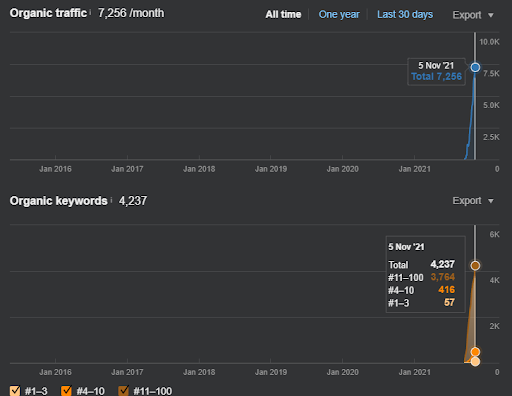
Comme vous le voyez, le deuxième réseau de contenu augmente le nombre de requêtes organiques et les positionnements beaucoup plus rapidement que le premier. Le réseau de contenu sémantique 1 bénéficie du « SEO saisonnier » qui fournit un niveau suffisant de données historiques de manière positive. S’il y a un événement SEO saisonnier, le moteur de recherche repositionnera les pages et attribuera aux documents et aux sources les nouveaux scores de rayon de pertinence et de couverture de l’activité de recherche. J’ai donc choisi d’utiliser d’abord un « lancement soudain » pour les « branches universitaires ». C’était la première étape de la construction de l’autorité thématique qui est égale aux « données historiques * couverture thématique ».
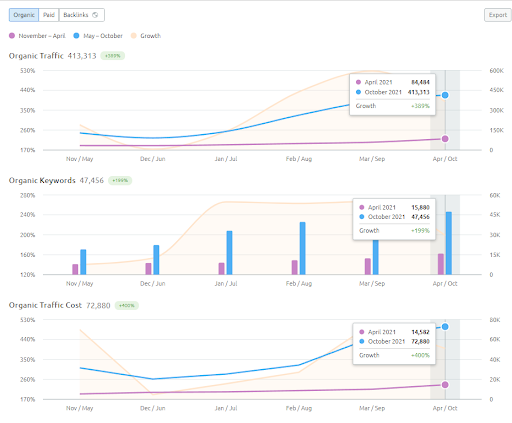
La comparaison des 6 mois de croissance de l’İstanbulBogazici Enstitu sur SEMRush.
Note : Pour compenser les faiblesses de l’exécution, j’ai conçu un Réseau de contenu sémantique 3 pour unir les deux premiers en utilisant des connexions conceptuelles en fournissant le contexte de la source. Si je le lançais, vous verriez que la source acquerrait plus de 1,2M de trafic organique sur la base du graphique Ahrefs, en réalité, cela peut être plus de 2M. Vous pouvez voir la validité de ma prédiction à partir des performances du Second Content Network. Chaque fois que vous le vérifiez, vous verrez qu’il a des milliers de nouvelles requêtes avec des positionnements plus élevés.
Dans le premier Réseau de Contenu Sémantique, les 3 premières requêtes de positionnements sont apparues après 2 mois’ pour le second, elles sont apparues le 15ème jour. Vous pouvez imaginer l’augmentation de l’autorité. Puisque la base de connaissances du site Web est laissée partiellement incomplète, une fois que la source perd son élan pour l’achèvement du réseau sémantique, le moteur de recherche peut donner la priorité à d’autres sources, et il peut diminuer la positivité du repositionnement ainsi que le rayon de pertinence et la capacité de positionnement.
La mise en œuvre des réseaux sémantiques sur ces sites fait appel à quelques concepts et « modèles » utilisés par les moteurs de recherche. Avant de vous parler de la méthode de mise en place d’un Réseau Sémantique, vous devez également comprendre ce que sont ces modèles et comment ils fonctionnent. Cela vous aidera à comprendre comment les modèles de recherche et la structure des documents influencent le positionnement, et donc pourquoi la méthode que j’ai utilisée dans cette étude de cas est si efficace.
Le positionnement initial et le re-positionnement sont deux types d’algorithmes de positionnement différents pour un moteur de recherche, basés sur le moment. Les moteurs de recherche ont d’autres types d’algorithmes de positionnement, comme ceux qui dépendent de la requête, ceux qui sont indépendants de la requête, ceux qui sont basés sur le contenu, ceux qui sont basés sur les liens et ceux qui sont basés sur l’utilisation. Pour pouvoir comprendre les systèmes de positionnement et la technologie d’association des clusters des moteurs de recherche, il faut comprendre les modèles de requête-document-intention et leur relation mutuelle.
Qu’est-ce qu’un modèle de requête ?
Un modèle de requête représente un modèle de recherche avec des phrases ordonnées qui couvrent une entité pour la recherche d’informations factuelles. Un modèle de requête peut avoir un format de question, un format de proposition ou un ordre de types de mots, comme un adjectif et un nom. Un modèle de requête est utile pour générer des requêtes d’amorçage et synthétiques du point de vue d’un moteur de recherche. Une requête d’amorçage peut aider un moteur de recherche à choisir des centroïdes pour les groupes de requêtes tout en aidant à regrouper les documents de pages Web, leurs types et les activités de recherche possibles pour ceux-ci.
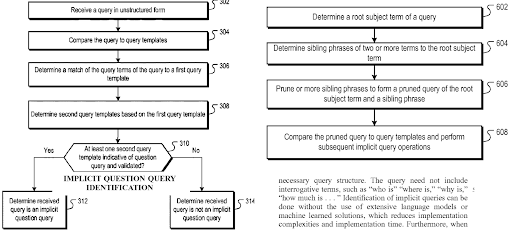
Un autre brevet de Google concerne l' »Implicit Question Query Identification » que Nitin Gupta a inventé avec Steven Baker. L' »Implicit Question Query Identification » est également liée à la génération de questions qui est connectée au « K2Q System ».
Dans ce contexte, un modèle de requête peut être utilisé pour alimenter les données historiques des moteurs de recherche afin de créer la confiance. Même si un moteur de recherche ne comprend pas tous les aspects d’une requête, ou d’un document correspondant, certaines sources peuvent être positionnées plus tôt et mieux que d’autres grâce aux modèles de documents. Si une source répond à des requêtes à partir d’un modèle, le moteur de recherche positionnera mieux la source spécifique pour ces types de requêtes à partir du même modèle initialement et pendant les processus de repositionnement. Ainsi, sur le web, nous avons des sources qui ne se concentrent que sur une seule verticale avec un seul modèle de requête, comme Wikihow, ou GiftIdeas.

« Query Suggestion Templates » est l’un des documents qui explique comment un moteur de recherche peut générer des modèles de requêtes à partir des logs de requêtes. Comme Nitin Gupta est l’un des inventeurs de ce brevet, il a plus de valeur pour moi.
Un modèle de requête peut être utilisé pour créer un réseau de contenu sémantique efficace, mais dans des domaines contextuels de page, et les connexions doivent être configurées correctement pour connecter plusieurs réseaux de contenu sémantique pour plusieurs modèles de requête.
Remarque : Les thèmes des modèles de requête, des modèles d’intention et des modèles de document sont étroitement liés et une autre étude de cas SEO sera publiée pour fournir de plus amples détails à ce sujet.

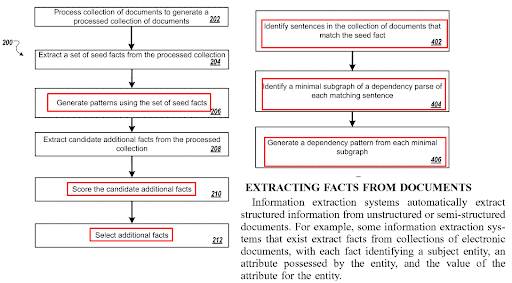
Une section de l’apprentissage de la représentation pour l’extraction d’information
à partir de documents de type formulaire de Google pour l’extraction d’informations à partir de contenus de type modèle.
Qu’est-ce qu’un modèle de document ?
Un modèle de document peut signaler l’objectif d’une page Web en se basant sur les éléments de conception, ou même sur la taille, le nombre et les types de requêtes. Si une page Web contient trop de JS, il peut s’agir d’un site Web dépendant de JS, ou les besoins en interactivité peuvent être plus élevés que d’autres. Cela peut être confirmé facilement en vérifiant simplement les récepteurs d’événements sur la page Web, ou les types d’entrée et les points de terminaison API. Lorsqu’il s’agit de penser comme un moteur de recherche, n’oubliez pas que le web est un endroit chaotique. Et, tout ce qui est possible pour comprendre les utilisateurs, surtout si les utilisateurs sont markoviens, c’est-à-dire qu’ils sont plus influencés par la page actuelle que par leur historique de navigation.

Une section qui explique comment un moteur de recherche peut utiliser les modèles de documents pour voir le centre d’intérêt d’un utilisateur.
Saviez-vous que Prabhakar Raghavan, le vice-président de la recherche chez Google, a également effectué une recherche qui pose la même question ? “Are Web Users Markovian?”.

Une section de l’article de recherche « Are Web Users Markovian ? »
Oui, ils le sont. Le positionnement probabiliste et le positionnement par pertinence dégradée sont les principales colonnes d’un moteur de recherche sémantique pour comprendre les utilisateurs et créer la SERP de la meilleure qualité possible, préparée pour les états des possibilités.
Auparavant, pour faire de « la conception, l’apparence ou la tonalité du site Web » un argument en faveur de l’apprentissage de la représentation pour les sites Web, Bill Slawski a écrit “Website Representation Vectors”.
Qu’est-ce qu’un modèle d’intention de recherche ?
Un modèle d’intention de recherche peut être représenté par le besoin qui se cache derrière le modèle de requête. Un modèle de document de requête peut être unifié sur la base d’un modèle d’intention. Le fait de disposer d’un modèle d’intention de recherche avec une compréhension possible du « positionnement de pertinence dégradé » et du « positionnement probabiliste » aidera à créer la meilleure activité de recherche possible et à couvrir l’intention de recherche dans le bon ordre. Lors de la création d’un réseau de contenu sémantique, la chose la plus importante est d’ajuster le modèle document-requête-intention en fonction du contexte de la source pour compléter un réseau sémantique basé sur un domaine de connaissances en améliorant la couverture contextuelle pour améliorer la confiance basée sur les connaissances et l’autorité thématique.
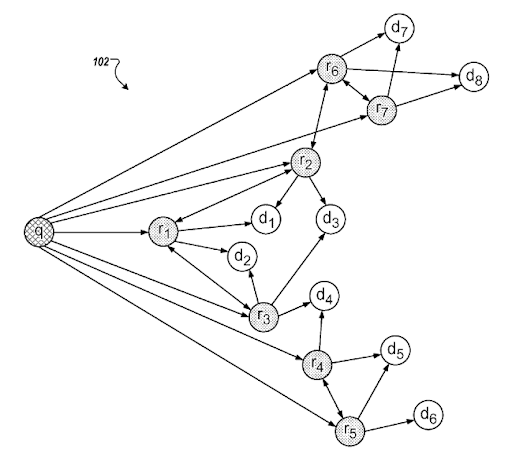
Une section du « Query Refinements based on Inferred Intent » de Google. Il fonctionne par le biais de groupes de requêtes et de modèles d’intention avec des connexions sémantiques. Vous pouvez en faire l’expérience sur différents niveaux de taxonomie des phrases.
Avant de passer à des exemples concrets et à des suggestions pour vous aider à créer un meilleur réseau de contenu sémantique, je dois vous dire que même la version simple de cette étude de cas SEO nécessite un haut niveau de compréhension des moteurs de recherche et des compétences en communication. Ainsi, même si j’ai le sentiment de donner des informations de haut niveau, je sais que le cours de SEO sémantique que je vais créer vous montrera des exemples concrets plus nombreux et de meilleure qualité.
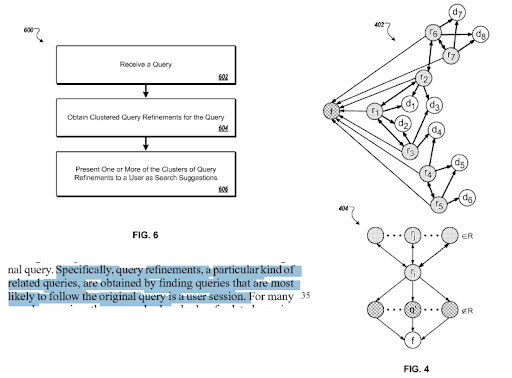
Le même brevet explique les liens appropriés entre les différents « chemins de requête » et les « changements de contexte ».
Que devez-vous savoir sur l’exploitation des réseaux de contenu sémantique ?
Pour créer un réseau de contenu sémantique, il faut parfois une heure, même pour une simple présentation et conception de contenu sémantique, si l’on y ajoute tous les détails pertinents basés sur la sémantique lexicale, ou les types de relations entre les entités et les phrases. L’utilisation simultanée de plusieurs angles d’approche, tels que l’indexation basée sur les phrases, les vecteurs de mots ou les vecteurs de contexte pour calculer la pertinence contextuelle d’un contenu global par rapport à un domaine contextuel, ou sa pertinence en fonction des différents types de sous-contenus, nécessite un haut niveau de compréhension des moteurs de recherche sémantique.
Ainsi, l’utilisation d’une méthodologie générative rendra tout plus facile avec les concepts que je vous ai expliqués ci-dessus, car même si vous préparez parfaitement chaque partie du réseau de contenu sémantique, les auteurs et rédacteurs ne seront pas capables de l’écrire, ou les gestionnaires de contenu ne seront pas capables de suivre votre vision. Ainsi, cela pourrait vous fatiguer pour rien, et vous faire quitter un projet comme je l’ai fait pour certains de ces projets d’études de cas SEO après avoir prouvé le concept d’une manière suffisante, vivante et vérifiable.
Les suggestions ci-dessous ne concernent que des mesures brèves et faciles à exécuter qui vous aideront.
1. Ne pas utiliser de liens latéraux fixes de chaque réseau de contenu sémantique
Chaque lien doit avoir une description de connexion entre deux documents hypertextes comme chaque mot dans une page web. L’utilisation du HTML sémantique peut aider à préciser la position et la fonction d’un document sur une page Web tout en aidant les moteurs de recherche à pondérer les sections différemment en fonction du contexte.
Dans l’exemple de Vizem.net, je n’ai pas utilisé le même design de barre latérale. La barre latérale ne montrait pas les derniers messages, ni les plus critiques. Les barres latérales ne montrent que les attributs des entités centrales, et elles ne sont pas fixes, elles sont dynamiques. En d’autres termes, sur la base de la hiérarchie de la carte thématique, les réseaux de contenu sémantique changent même s’ils se trouvent dans la barre latérale.
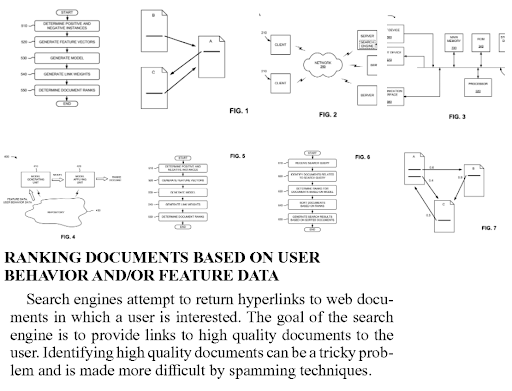
La réflexion sur les modèles du surfeur raisonnable et du surfeur prudent peut aider un SEO à créer une meilleure pertinence entre différents documents hypertextes.
En outre, les flux de liens en termes de proéminence, et la popularité devrait suivre le contexte de la source à partir des meilleures connexions possibles. Ci-dessous, vous pouvez voir les sections de la barre latérale avec les codes HTML sémantiques ajustés.

Selon la hiérarchie de l’article qui est actif sur la session de l’utilisateur, les onglets, l’ordre des onglets, les liens à l’intérieur des onglets vont changer. L’exemple ci-dessus est tiré de la hiérarchie du fil d’Ariane ci-dessous.
![]()
![]()
2. Soutenir les réseaux de contenu sémantique avec PageRank
Même si le PageRank externe n’est pas indispensable, si vous êtes en mesure de l’utiliser, vous vous rendrez compte que le positionnement initial et le repositionnement seront meilleurs. Pour ces deux projets, je ne les ai pas utilisés, mais cette fois, ce n’était pas le but. Pour Vizem.net, il y avait des problèmes économiques, et je ne voulais pas dépenser le budget sur les relations publiques numériques et la sensibilisation. Pour İstanbul BoğaziçiEnstitusu, j’ai prévu un couple de « sources interconnectées localement » pour soutenir l’authenticité de la source pour le sujet spécifique, mais encore une fois, la société n’a pas été en mesure de le mettre en œuvre en raison de problèmes de budget et de discipline organisationnelle.
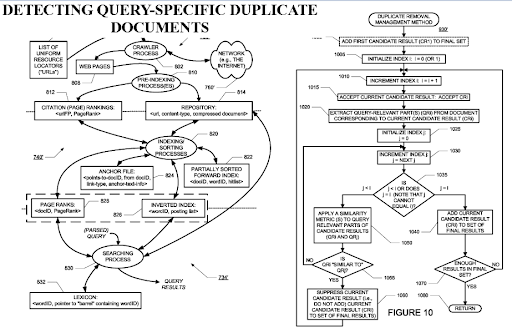
La détection des documents dupliqués spécifiques à une requête est une perspective importante pour les moteurs de recherche, car le PageRank peut aider un document à être filtré comme précieux même s’il est dupliqué. Comme les réseaux de contenu sémantique hautement organisés peuvent être similaires les uns aux autres, le flux de PageRank et les données historiques sont utiles.
Lorsqu’il s’agit de choisir le point de flux PageRank externe pour ces types de réseaux de contenu sémantique, utilisez les sources avec des données historiques. Dans mon cas, j’avais organisé ces points d’arrivée PageRank plus tôt, avant de lancer et de publier le premier réseau de contenu sémantique. De cette façon, j’ai pu prendre des références externes de concurrents directs, mais lorsque j’ai publié le réseau de contenu sémantique, les concurrents ont renoncé à lier la source parce qu’ils ont vu l’augmentation massive de la source en tant que concurrent.
Cette situation nous amène à la troisième suggestion. Si nous pouvions utiliser le flux PageRank des références externes, le processus de repositionnement serait plus rapide et le positionnement initial serait plus élevé.
3. Utiliser des textes d’ancrage différents du pied de page, de l’en-tête et du contenu principal pour les parties saillantes du réseau de contenu sémantique
Les textes d’ancrage ou le « texte du lien », du point de vue du moteur de recherche, signalent la pertinence d’un document hypertexte par rapport à un autre. Selon le document original du PageRank, le nombre de liens est proportionnel au flux du PageRank. Mais, plus tard, Google a modifié ce principe pour éviter le « bourrage de liens » et a limité les liens qui peuvent effectivement transmettre le PageRank. C’est sur cette base que sont développés les modèles TrustRank, Surfeur prudent, Algorithme Hilltop ou Surfeur raisonnable.

Ce sont deux liens vers deux réseaux de contenu sémantique différents pour le BogaziciEnstitusu, mais comme je n’ai pas mis en œuvre de SEO technique, ou d’améliorations UX, vous pouvez vous rendre compte de la « bon marché » de la conception des boutons.
Selon Google, le même lien ne peut pas transmettre le PageRank une deuxième fois à une autre page Web, alors que le PageRank sera transmis uniquement à partir du premier lien. Et, dans la forme originale de l’algorithme PageRank, un document hypertexte peut se lier lui-même pour améliorer son PageRank, ou des redirections 301 peuvent être utilisées pour prendre le PageRank du document cible du lien. Ces deux situations ont donné naissance à d’anciennes techniques « Black Hat » telles que la redirection d’une page Web vers une autre temporairement pour simplement prendre son PageRank. Cela remonte à l’époque où les SEO étaient en mesure de voir le PageRank d’une page Web à partir de la Google Search Console ou des SERP. Plus tard, Google a commencé à atténuer le PageRank à chaque redirection, tandis que Danny Sullivan a expliqué que les redirections 301 transmettaient entièrement le PageRank. Outre tous ces changements, l’important ici est que même si le deuxième lien ne transmet pas le PageRank, il transmet quand même la pertinence du texte du lien.

Les sections importantes du Réseau de contenu sémantique ont été liées à partir de la page d’accueil sur la base des « raffinements intermédiaires de la requête » qui comprennent les « verbes, les prédicats » ou les « activités du chercheur ».
Ainsi, les sections les plus importantes du Réseau de contenu sémantique devraient être liées à partir du menu d’en-tête et de pied de page avec les sections de taxonomie supérieure, et les textes des liens devraient être différents les uns des autres. Dans ces exemples, j’ai utilisé les liens d’en-tête avec des textes de lien importants mais courts, tandis que j’ai gardé les exemples de pied de page plus longs.

Une section de « Anchor Tag indexation in a web crawler system », elle résume l’importance d’un texte d’ancre, et d’un texte d’annotation pour positionner une page web dans les clusters de requêtes, et les clusters de pages web.
Si la section Réseau de contenu sémantique est trop importante, pour passer le PageRank et la priorité de crawl correctement, j’ai lié les sections les plus importantes avec des textes de lien appropriés, et des paragraphes explicatifs qui incluent les attributs importants avec différentes variations de N-Grams pertinents.

C’est la deuxième zone liée de la page d’accueil de Vizem.net, elle se trouve derrière un accordéon, et elle se concentre sur les pays dans les requêtes, et elle relie la section centrale du réseau de contenu sémantique.
Remarque : autour des textes d’ancrage, un « texte d’annotation » prévu a toujours été utilisé pour améliorer la précision de l’objectif du lien.
4. Limiter la restriction du nombre de liens et faire correspondre les liens des ordinateurs de bureau et des téléphones portables avec le contenu principal
Les deux projets sont limités à moins de 150 liens internes par page Web. Avec l’aide du HTML sémantique, l’emplacement et la fonction des liens sont clairement indiqués aux robots d’exploration. Le site İstanbulBogazici Enstitusu comptait plus de 450 liens par page Web, dont certains étaient des auto-liens (un lien de la même page vers la même page). Le pire, c’est que la moitié de ces liens n’existaient pas dans la version mobile du contenu.

L’URL Keep Score, le Crawl Score et d’autres types de scores peuvent être utilisés pour déterminer la proéminence d’un lien dans la carte d’URL interne, et les balises d’identification des documents dans les différents niveaux peuvent être utilisées pour trier l’index sur la base de scores de pertinence indépendants de la requête.
Étant donné que Google utilise l’indexation uniquement pour les mobiles, si le contenu n’existe pas dans la version mobile, il sera ignoré et ne sera pas utilisé pour l’évaluation de la pertinence et les positionnements. Ainsi, les contenus mobile et de bureau ont été configurés pour être mis en correspondance. Même si Google tolère les disparités de contenu entre les versions mobile et de bureau, cela complique la compréhension et le positionnement d’une page Web pour les moteurs de recherche.
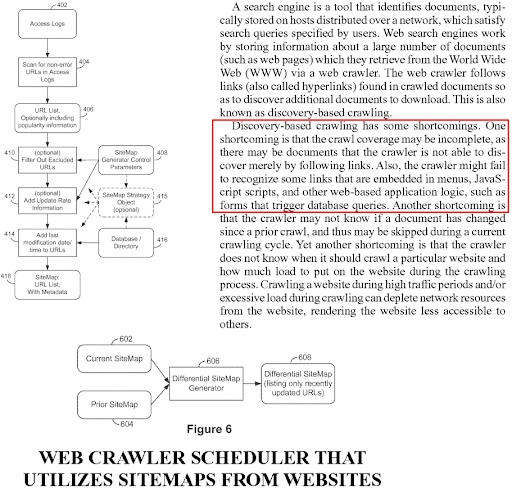
Un moteur de recherche peut générer un sitemap pour le site Web, et ce sitemap peut être généré à nouveau en boucle, si les liens et les métadonnées des URL ne correspondent pas entre les agents utilisateurs ou les lignes de temps. Il est donc important que le chemin d’exploration soit court, la file d’attente d’exploration brève et les liens internes cohérents.
En plus des liens entre les différentes pages Web, des liens pour les sous-sections des pages Web sont utilisés avec la « table des matières » et les « fragments d’URL ». Ces URL Fragments ciblent une sous-section spécifique de la page web tout en la nommant correctement, et la section spécifique a été placée dans une balise section avec un
h2. Avec l’aide des fragments d’URL et des « liens de navigation dans la page », il est plus facile pour un utilisateur de passer de la SERP à la section spécifique de la page Web, tandis que les sections inférieures du contenu ont été mises en évidence pour satisfaire le besoin à l’origine de la requête.
5. Avoir une discipline de niveau militaire pour vos projets de SEO
C’est un tout autre sujet et un autre article pourrait être écrit pour définir ce que signifie la discipline de niveau militaire, ou pourquoi elle est utile pour un projet SEO. Mais, je dois vous dire qu’au cours de ces 2 derniers mois, j’ai formé beaucoup de PDG, et de SEOs d’autres agences avec leurs équipes pour voir si la conception de mon cours fonctionnera bien ou pas.
Chaque fois que je vois le succès, et un haut niveau de compréhension pour les sessions d’éducation que je réalise, il y a une forte volonté et persévérance. Le problème principal est que le SEO sémantique est beaucoup plus difficile que les autres verticaux du SEO. Le SEO technique est universel, et il existe même des guides écrits pour chaque étape. Le SEO OnPage, ou le WUX et le Layout Design peuvent être suivis avec des mesures numériques. En ce qui concerne la sémantique, il s’agit d’unir le point de vue d’une machine qui fonctionne sur la base d’un système adaptatif complexe à celui d’homo-sapiens qui ne comprennent pas comment la machine fonctionne.
Cette distinction nécessite une base concrète qui doit être posée dès le premier jour du projet. La plupart du temps, j’utilise les règles ci-dessous.
- Les conceptions de contenu et le réseau de contenu sémantique ne doivent pas être logiques pour un auteur, ou un rédacteur.
- La tâche du gestionnaire de contenu est de vérifier la compatibilité du contenu avec la conception du contenu.
- La tâche de l’auteur est de rédiger le contenu avec les informations connexes qui comprennent un haut niveau de précision et de détail.
- Les liens, les définitions, les preuves, les comparaisons, les propositions et les références doivent être illustrés par des exemples concrets, et non par des mots inutiles.
- Chaque mot inutile est une dilution du contexte et du concept.
À la lecture, cela peut sembler facile à mettre en œuvre, mais ce n’est pas si facile. Ainsi, je peux dire que j’étais même sur le point de renvoyer certains de mes propres employés. Je suis heureux de ne pas l’avoir fait, du moins pour l’instant. Dans des conditions normales, il y aura beaucoup de questions qui vous seront posées, si le propriétaire de la question n’est pas un SEO ou un propriétaire de l’entreprise, ne répondez pas. Gardez votre énergie pour le stockage des données du moteur de recherche qui conservera vos commentaires positifs, et non les commentaires redondants et non pertinents pour les positionnements.
6. Élargir la source avec la pertinence contextuelle
Cette section est entièrement consacrée à la compréhension des besoins de Google pour la création de la carte thématique. Lorsque vous concevez une carte thématique, elle inclut de nombreux réseaux de contenu sémantique qui constituent une meilleure base de connaissances au niveau du site. Ainsi, lors de la publication de ces sous-sections, elles doivent pouvoir se connecter au contexte de la source, sinon cela peut changer la façon dont le moteur de recherche voit la source, et le thème du site peut basculer vers un autre domaine de connaissances. Par exemple, pour relier les choses autour de concepts et de domaines d’intérêt avec des actions possibles, il faut comprendre les connexions complexes des significations entre elles. Le processus de création d’un réseau de contenu sémantique consiste à rendre ces connexions claires pour un utilisateur, un rédacteur et une machine en même temps.

Pour ce faire, chaque nouvelle section du site Web doit pouvoir être connectée à la section centrale de la carte thématique. Ces ponts contextuels sont visibles dans la conception et l’explication de LaMDA par Google.
Je rencontre beaucoup de questions telles que « devrais-je écrire sur un autre sujet », « si j’ai deux niches différentes, cela va-t-il nuire ? ». Si vous connectez toutes ces sous-sections, segments de site Web en tant que composants fortement connectés, ces réseaux de contenu sémantique se soutiendront mutuellement pour obtenir de meilleurs positionnements au lieu de diviser l’identité de la marque et l’autorité thématique pour deux sujets différents et non pertinents.
7. Créer un trafic réel et un audit avec la segmentation personnalisée de Google Analytics
Le trafic réel est lié à RankMerge de la même manière que la confiance basée sur la connaissance est liée au PageRank. Bientôt, je pense écrire un autre article avec le titre « Quand le PageRank ment… » pour expliquer pourquoi le moteur de recherche essaie d’affecter le PageRank avec des signaux secondaires. En fait, le PageRank n’est pas un signal définitif qui montre l’autorité, l’expertise et la fiabilité d’une source. Il peut être un signal pour le positionnement, et un facteur, mais on ne peut pas lui faire confiance seul. RankMerge est le processus qui consiste à unir le trafic du site Web et le PageRank de manière à ce que le site Web ait un sens pour le moteur de recherche. Un PageRank élevé et un trafic faible peuvent signaler un « trafic impopulaire », ou une « manipulation du PageRank ».
Ainsi, pour améliorer les données historiques de la source, j’ai utilisé les événements SEO saisonniers, et j’ai augmenté les requêtes « marque + terme générique ». Le trafic direct et les pages Web marquées d’un signet sont augmentés par un trafic réel et authentique.
Ces types de données aident un moteur de recherche à lui faire confiance pour le positionner de plus en plus haut dans les SERPs.
Pour être en mesure d’auditer ce trafic réel qui provient du Réseau de contenu sémantique, un SEO peut créer un segment personnalisé de Google Analytics pour voir comment ils viennent en tant que trafic direct. Il est également possible de créer des objectifs personnalisés tels que la création d’un parcours de recherche possible du premier réseau de contenu sémantique au deuxième réseau de contenu. C’est la preuve de concept que le réseau sémantique est construit autour des intérêts, des concepts et des actions possibles liées à la recherche.
Ci-dessous, vous trouverez un seul exemple de l’une des pages web qui sont placées dans le premier réseau de contenu sémantique pour démontrer le trafic direct acquis via le trafic organique.
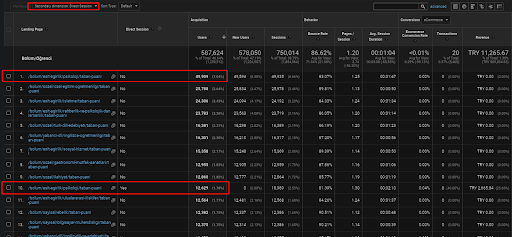
Au cours des trois derniers mois, une seule page web du premier réseau de contenu sémantique a été utilisée par 49 000 utilisateurs organiques. Et, 12 900 utilisateurs supplémentaires sont venus en tant que trafic direct qui a été acquis par la recherche organique pour la première fois. La métrique session/page et la durée moyenne de la session sont plus élevées pour ces segments d’utilisateurs.
Comme nous l’avons dit précédemment, un moteur de recherche peut regrouper des requêtes, des documents, des intentions, des concepts, des intérêts, des actions, mais il peut aussi regrouper des utilisateurs. Si un groupe d’utilisateurs laisse des commentaires positifs tout en créant une valeur de marque en ajoutant ces pages Web aux signets, en tapant directement dans la barre d’adresse et en recherchant les termes génériques avec le nom de la marque, cela montre que la source améliore son autorité et que le moteur de recherche est capable de tout reconnaître à partir des SERP, de Chrome et de ses propres adresses DNS.
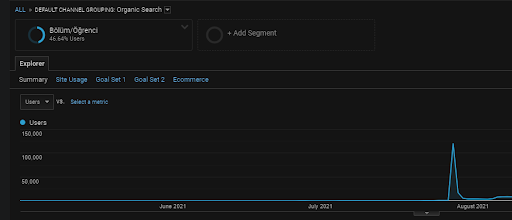
Ci-dessus, vous pouvez voir le segment utilisateur du First Content Network. Vous pouvez créer un segment d’utilisateurs pour chaque Réseau de Contenu Sémantique avec des objectifs personnalisés, et vous pouvez ajouter des segments de sous-utilisateurs pour les réseaux de sous-contenu Sémantique également.
8. Supporter les réseaux de contenu sémantique avec des sous-sections basées sur les activités de recherche
Cette section traite également de la résolution et de l’analyse des attributs des entités, qui est un autre sujet. Mais, en termes simples, certains attributs de ces entités basés sur des domaines contextuels devraient être placés dans une hiérarchie inférieure, et non dans la hiérarchie supérieure. Dans ce cas, « Vizem.net » peut donner un meilleur exemple, tandis que pour le Boğaziçi Enstitusu, il peut être démontré avec « Salaires des professions », et « Points d’examen des universités ». Ces deux attributs importants ont été placés dans les réseaux de sous-contenu sémantique en fonction des modèles de requête et de document.

L’identification d’unités sémantiques à partir d’une requête de recherche est un autre brevet de Google qui divise les phrases en différentes catégories sémantiques, et agrège la pertinence d’un document en fonction de sa proximité avec toutes les variations de la requête.
Dans une étude de cas SEO précédente, je n’ai pas suivi ce type de structure, j’ai créé un chemin de crawl basé sur la « chronologie » et les liens internes qui sont strictement limités. Dans ces articles, le nombre de liens internes placés dans le contenu principal est plus élevé que dans le précédent.
9. Utiliser des mots thématiques dans les URLs
Si Google rencontre deux URLs différentes avec le même contenu sans aucun signal de canonisation, il choisit la plus courte comme étant l’URL canonique. En effet, les URLs courtes sont plus faciles à analyser, à résoudre et à demander. Lorsque vous avez des billions de pages web que vous rafraîchissez des milliards de fois par jour, même les lettres des URLs peuvent montrer « l’équilibre coût/qualité » d’un site web. Comme je l’ai déjà dit, le « coût de récupération » doit être inférieur au « coût de non-récupération ». Si vous voulez être compris par un moteur de recherche, vous devez placer les « signaux contextuels ordonnés et complémentaires » à tous les niveaux, y compris dans les URLs.

Une section du positionnement « basé sur les preuves » via l’agrégation de preuves. Elle explique comment une réponse peut être mise en correspondance avec une question.
Dans ce contexte, la plupart du temps, j’utilise un seul mot dans l’URL. Celles-ci peuvent refléter la hiérarchie et la structure du réseau de contenu sémantique. Certains pensent encore que le « nombre de couches » dans l’URL affecte la fréquence de crawl, avant 2019, c’était vrai. Mais, tant que le contenu a du sens, et satisfait les utilisateurs d’un sujet populaire ou proéminent, il ne sera pas affecté par une telle situation.
Pour le démontrer, vous pouvez suivre l’exemple ci-dessous.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
Ces deux réseaux de contenu sémantique peuvent se lier entre eux à partir de la même hiérarchie, et ils peuvent également se lier entre eux sur la base de la pertinence. Il y a d’autres choses dont nous pouvons parler ici, comme le « Contenu du groupe d’entités – Contenu du type hub », mais c’est le sujet d’un autre jour.
Remarque : Le troisième réseau de contenu sémantique prévu peut également être traité comme un « réseau de contenu de groupeur conceptuel ». Et, s’il est publié, avec l’effet du deuxième réseau de contenu sémantique, le trafic organique global peut dépasser les 3 millions de sessions par mois.
10. Comprendre la différence entre l’imbrication et la connexion
En tant que différence méthodologique pratique, la connexion consiste à relier des éléments similaires les uns aux autres sur la base d’un domaine contextuel, tandis que l’imbrication consiste à regrouper les contenus similaires ayant le même objectif. Ce regroupement aidera le moteur de recherche à trouver plus rapidement les contenus similaires et à créer un score de qualité de la source pour ces groupes, ou ces contenus imbriqués, sur la base d’un réseau sémantique.
Imaginons qu’il y ait deux chemins de crawl différents comme ci-dessous.
- Chemin de crawl 1 : rencontre des URLs au hasard, sans modèle, sans similarité et sans pertinence contextuelle.
- Chemin de crawl 2 : rencontre des URLs qui ont un sens même à partir de l’URL elle-même, avec un modèle, un haut niveau de similarité et une pertinence basée sur le contexte.
Si, même à partir du chemin de crawl, le contenu a du sens, le « positionnement initial » et le « repositionnement » seront meilleurs grâce au « déclenchement du repositionnement basé sur la compréhension de la couverture du moteur de recherche ».
Remarque : l’utilisation correcte des liens internes avec la taxonomie de phrase est importante pour l’imbrication et la connexion.
Ceci nous amène aux deux derniers partages de méthodologie pratique, brièvement. Et cette section est à nouveau liée au haut niveau de discipline et à la suffisance organisationnelle.

Un brevet de Trystan Upstill et Steven D. Baker pour la reconnaissance des termes co-occurrents dans les listes HTML. L’intérêt de ce brevet est qu’il montre la valeur d’une seule liste HTML pour déterminer les listes de termes co-occurrents pour un sujet ou une partie de la taxonomie des phrases.
11. Comprendre quand publier un réseau de contenu sémantique avec une fréquence ajustée
Cela a déjà été expliqué, mais dans l’un de ces projets d’étude de cas SEO, j’ai publié près de 400 éléments de contenu en une journée. Dans l’autre, j’ai commencé à publier seulement 10-15 contenus soudainement, puis j’ai augmenté la vélocité au fil du temps avec une constance jusqu’à ce que les problèmes économiques liés à Covid commencent.
Si une nouvelle source crée un nouveau réseau de contenu sémantique, le publier le premier jour peut être un peu plus difficile que vous ne le pensez, vérifier tous les liens internes, les grammaires et les informations sur la page web n’est pas si facile. Mais, si tout le contenu ne provient que d’un seul sujet, et d’un modèle de requête, et si la source n’a pas d’historique sur ce sujet, la publication de la plus grande partie du réseau de contenu sémantique présente des avantages tels qu’une indexation, une compréhension et un positionnement plus rapides.
Dans ma situation, il y avait également un événement historique avec une saisonnalité. Mon objectif était donc d’avoir un niveau suffisant de position moyenne jusqu’à ce que je puisse être testé par le moteur de recherche pour les entités spécifiques et les activités de recherche par rapport aux sources plus anciennes. Ainsi, j’ai publié le premier Réseau de Contenu Sémantique avec un haut niveau de préparation avant les 45 jours de l’événement saisonnier.
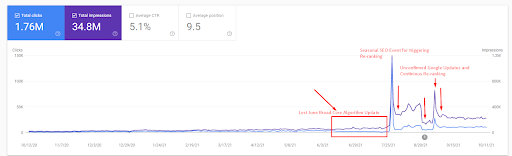
Ensuite, vous pouvez voir comment le moteur de recherche a testé la source à plusieurs reprises comme ci-dessous.
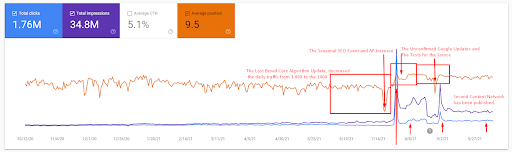
Une explication plus détaillée peut être trouvée ci-dessous.
Une vérification rapide des faits peut être trouvée ci-dessous pour l’explication de la capture d’écran ci-dessus.
- La mise à jour de l’algorithme Broad Core a réduit le trafic du site Web de plus de 200 %.
- Le site a également perdu plus de 15 000 requêtes.
- Cela a affecté l’indexation globale de la source pour le nouveau réseau de contenu sémantique, comme cela a été expliqué plus en détail dans l’article sur l’étude de cas SEO.
- Grâce à l’événement SEO saisonnier, le repositionnement a eu lieu plus tôt, et après l’événement SEO saisonnier, le moteur de recherche a normalisé le positionnement de la source sur la base du trafic réel pendant les mises à jour non confirmées.
- Les requêtes et les positionnements acquis grâce au premier réseau de contenu sémantique et à l’événement saisonnier ont été protégés et améliorés.
- Le premier réseau de contenu sémantique a également soutenu le nouveau et deuxième réseau de contenu sémantique.
La perte de requêtes et la perte moyenne de positionnements sont également visibles sur Ahrefs comme ci-dessous. Vous pouvez vérifier l’effet de la Google Broad Core Algorithm Update (GBCAU) de juin 2021 ainsi que l’effet de la mise à jour non confirmée.
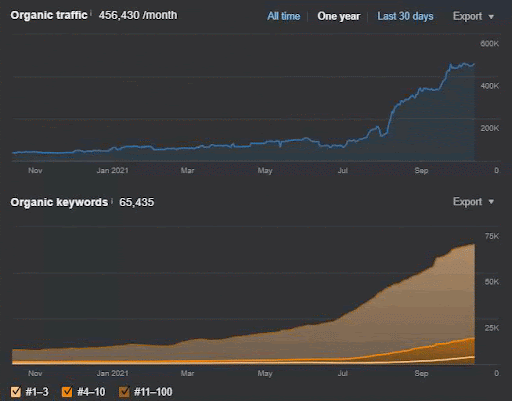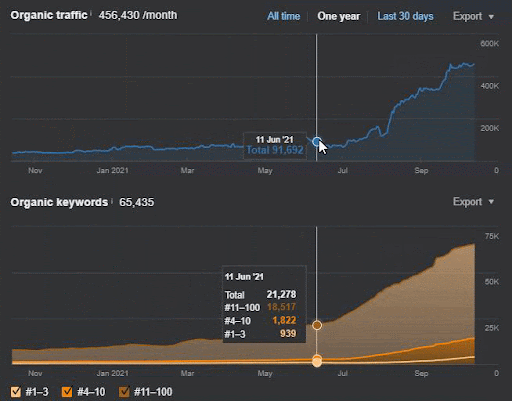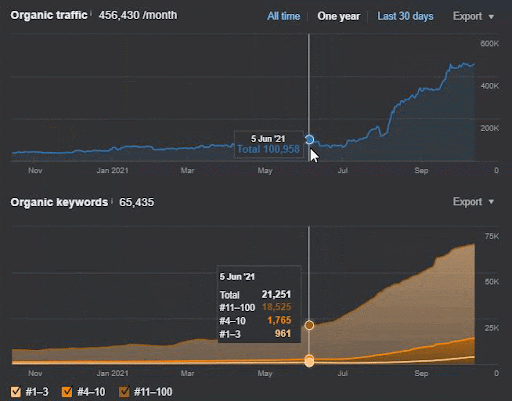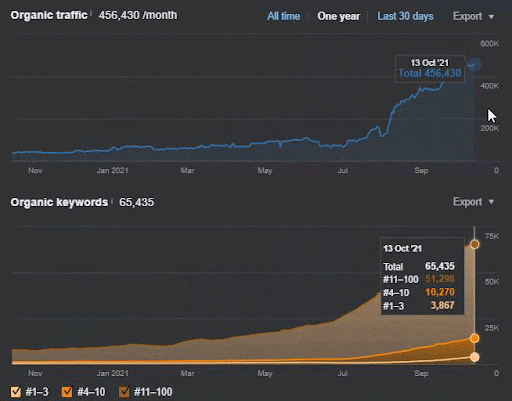
Ainsi, l’utilisation d’un réseau de contenu sémantique avec plusieurs stratégies possibles est une nécessité. Même si la mise à jour GBCAU est perdue, d’autres facteurs liés à la nature du moteur de recherche peuvent aider un SEO. Ainsi, vous pouvez imaginer pourquoi expliquer ces choses à un auteur, ou un client est plus difficile que le SEO technique. Le SEO sémantique n’utilise pas de valeurs numériques, il utilise des connaissances théoriques qui proviennent de la compréhension des moteurs de recherche via des brevets, des documents de recherche, l’expérience et des annonces historiques.
12. Utiliser l’optimisation des phrases en page pour une meilleure structure factuelle
Pour être honnête, même la 10ème liste est un sujet entièrement nouveau et peut nécessiter l’écriture de 20.000 mots. Mais je vais commencer par un exemple simple.
- X est Y.
- Y est X.
Pour les phrases d’exemple ci-dessus, vous pouvez comprendre les choses ci-dessous.
- Les phrases ci-dessus ne sont pas du contenu dupliqué.
- Les propositions ci-dessus sont dupliquées.
- Les explications relationnelles entre deux phrases sont les mêmes.
- Les étiquettes de rôle sémantique sont 100% différentes.
- Le résultat de la reconnaissance des entités nommées est 100% identique.
L’optimisation des phrases dans la page est liée aux algorithmes de génération de questions et aux technologies de couplage question-réponse. Un format de question requiert un certain type de phrase. Et à certains types de questions, il faut répondre par certains types de phrases. Le format du contenu, le NER et l’extraction de faits seront affectés par l’optimisation de la structure des phrases.
Les triplets (un objet, deux sujets) peuvent être extraits et vérifiés en termes de précision plus rapidement. Deux phrases similaires ne signifient pas qu’elles sont dupliquées, mais qu’elles sont proches l’une de l’autre en termes de structure de phrase. Tant que la proposition est différente, l’utilisation de phrases similaires entre des modèles de documents similaires pour des paires requête-intensité différentes est une nécessité pour la création de réseaux de contenu sémantique.

Des structures de phrases claires avec un modèle approprié sont utiles pour rendre les morceaux de texte plus pertinents les uns par rapport aux autres, tout en aidant un moteur de recherche à reconnaître les entités nommées, les sujets, les attributs et leurs valeurs les uns par rapport aux autres.
Cela permet également de voir quelle section d’un article peut être améliorée et, dans les réseaux thématiques, où votre contenu se positionne mieux pour quels types de paires de mots, vecteurs de mots et intentions. Parce que, si certains types de structures de phrases pour certains types de questions peuvent être observés sur plusieurs pages Web, cela aidera les tests A/B SEO avancés avec des quantités infinies d’échantillons de données et de tests. Vous pouvez créer plusieurs conceptions de phrases en page pour vérifier comment un moteur de recherche extrait les faits pour les comparer.

Lorsqu’il s’agit de donner les faits, il faut se souvenir du « Knowledge Vault » et de la Luna Dong.
13. Donner des informations du monde réel avec précision et cohérence, et non des opinions avec du superflu.
La précision signifie ici que les informations peuvent être comparées à des valeurs numériques ou à des relations conceptuelles concrètes. La cohérence signifie que vous protégez votre position pour la proposition spécifique. Par exemple, ne dites pas que « le produit X est le meilleur pour Y » pour chaque critique de produit liée à Y. Ne faites pas de propositions contradictoires sur l’ensemble du site. Et si le produit est le meilleur, quelle en est la preuve ? Le matériau, la taille, ou la couleur et l’odeur ? Le terme « fluff » dans le texte signifie que vous utilisez des mots ponts inutiles, ou que vous ne racontez pas des choses qu’il n’est pas possible de prouver, ou qui contredisent la vérité.
Dans le contexte de ces instructions non-définitives qui sont soutenues par certains des exemples, vous pouvez vérifier l’un des modèles linguistiques de Google qui est KeALM.
Il permet de générer du texte à partir d’une base de données à l’aide des modèles de conversion des données en texte, et de vérifier l’exactitude du contenu.

KELM est un exemple d’audit d’exactitude pour les propositions avec des méthodes de conversion de texte en données.
Il s’agit également d’un petit peu de la définition du « Triplet » et de l' »Open Information Extraction for Unknown Entities », mais comme vous le savez, c’est la version courte, et je pense que j’en ai assez dit. En gros, lorsque vous donnez des informations erronées sur votre site web, assurez-vous que Google est capable de les comprendre pour diminuer la confiance basée sur la connaissance de la source. Vous devez également savoir que, puisque vous êtes en mesure d’étendre la base de connaissances, un moteur de recherche peut modifier sa propre base de connaissances en fonction de vos informations, si vous avez une source corrélée avec PageRank, une base de connaissances de confiance avec une grande précision et des triplets uniques.
14. Comprendre l’arbre de dépendance sémantique pour les entités
L’arbre de dépendance sémantique signifie que les attributs qui signalent des relations avec d’autres entités ont une dépendance hiérarchique entre eux. L’arbre de dépendance sémantique peut être observé en vérifiant plusieurs profils d’entités et des angles tels qu’un pays peut être membre d’une organisation, et en tant qu’autre entité, cette organisation peut avoir d’autres attributs qui peuvent être attribués aux pays connectés avec des relations déduites.
Ci-dessous, vous pourrez voir un exemple simple provenant directement du moteur de recherche.

REALM est une méthode qui utilise les arbres de dépendance sémantique pour extraire des informations d’un texte ambigu.
Sur le web ouvert, l’extraction d’information ouverte peut reconnaître de nouvelles entités nommées, et extraire ces mêmes entités comme cooccurrentes avec d’autres entités. Ces cooccurrences et attributs mutuels dans l’article peuvent attribuer un contexte et un type de relation candidat entre les entités. Sur la base des connexions et du type de l’entité, l’arbre de dépendance sémantique peut être créé. La même logique s’applique à la sémantique lexicale. Le mot « garçon » a quelques significations possibles et d’autres exactes. Par exemple, un garçon est un homme, et probablement un adolescent qui n’est pas marié. Il peut également être utilisé à proximité de l’étudiant. Le mot « reine », quant à lui, a d’autres significations possibles et exactes, telles que « femme » et « être un gouverneur ». Ainsi, le fait d’avoir quelque chose à gouverner est une hiérarchie naturelle d’arbres de dépendance sémantique qui peut signaler certains types de modèles de requête tels que « Reine de… », ou « Pour Quen ». Ces couches contextuelles avec des qualificatifs de contexte devraient être unies naturellement avec des domaines contextuels et des domaines de connaissances pour améliorer la couverture thématique et contextuelle ensemble.
La génération de raffinements de requêtes à mi-chemin est un autre brevet de Google qui montre les connexions entre les réseaux sémantiques de contenu. Chaque raffinement de requête midtring fait partie du réseau de sous-sujets du sujet. Un réseau de contenu sémantique qui se concentre sur tous ces candidats au raffinement de la requête avec les annotations sémantiques correctes aura l’avantage d’un meilleur re-positionnement et d’un meilleur positionnement initial.
Dernières réflexions sur le réseau de contenu sémantique
Je sais que ce contenu était très technique en termes de SEO sémantique. Et, avant de publier mon cours de SEO sémantique, je veux encore augmenter les connaissances, afin que les premières leçons théoriques puissent être digérées par nos esprits plus rapidement que d’habitude. Les réseaux de contenu sémantique peuvent être définis comme la somme de la carte thématique, et des conceptions de contenu individuel qui comprennent tous les titres, les questions, les niveaux de titres, les textes d’ancrage, la hiérarchie du contenu, et les positions dans l’arbre du site, ou tout ce qui est lié à la pièce de contenu, y compris les images vedettes et les images détaillées dans la page.
Ici, outre les conceptions de structures de phrases dans la page, ou les formats de questions-réponses, ou les formats de phrases synonymes, nous pouvons également parler de vecteurs contextuels, de hiérarchies contextuelles, de phrases séquentielles avec des contextes reliés, ou de positionnements basés sur des preuves par agrégation de preuves. Toutes ces choses rendraient cette étude de cas et ce guide du SEO plus compliqués mais néanmoins détaillés. Ainsi, comme dans l’étude de cas et le guide SEO précédents, Importance de l’autorité thématique, expliquer les réseaux sémantiques rendrait cet article plus compliqué mais néanmoins détaillé.
Les futures études de cas SEO incluront de plus en plus de détails en soutenant les précédentes. Enfin, j’ai reçu beaucoup de captures d’écran et de messages de remerciement de vous tous qui montrent les résultats positifs que vous avez obtenus grâce à la compréhension de Topical Authority. J’espère que le positionnement initial et le repositionnement ainsi que la compréhension du Réseau de contenu sémantique vous aideront davantage.
Rendez-vous dans les prochaines études de cas SEO.
« L’acquisition de connaissances est toujours utile à l’intellect, parce qu’elle peut ainsi conduire à une meilleure compréhension de la réalité.
l’intellect, parce qu’elle peut ainsi chasser les choses inutiles
inutiles et conserver les bonnes choses. Car rien ne peut être
être aimé ou détesté si on ne le connaît pas d’abord. »
– Léonard de Vinci.
