
En Avril 2018, nous avons participé à l’événement SEO britannique incontournable BrightonSEO. Cette conférence était une excellente opportunité pour réseauter mais aussi pour assister à des conférences de haut niveau tenues par les meilleurs speakers du secteur. Oncrawl participait à l’événement pour la seconde fois et a proposé une conférence sur Rankbrain et l’IA Google en SEO.
Cet article a pour objectif de résumer cette conférence et de mettre en avant les points stratégiques pour maximiser vos efforts SEO dans un environnement Rankbrain. Vous pouvez lire l’article en entier ou aller directement aux parties qui vous intéressent le plus.
Crawl, indexation, classements et principes IA
Indicateurs SEO clés qui favorisent le crawl de Google
Indexation et interprétation du contenu
Comment maximiser vos efforts pour Rankbrain ?
Crawl, indexation, classements et principes IA
Avant de creuser plus sur l’impact de Rankbrain et sur le SEO, il est essentiel de comprendre comment fonctionnent les moteurs de recherche et l’IA de Google.
En réalité, la vie d’une requête faite par un utilisateur débute bien avant votre capture, par l’exploration et l’indexation de milliards de documents à travers le web. Les IA Google sont des programmes informatiques pensés pour naviguer parmi des milliards de pages, pour trouver les bons indices et envoyer la meilleure réponse possible à votre question.
Ainsi, Google consomme annuellement autant d’énergie que la ville de San Francisco. Cette énergie est appelée budget de crawl et renvoie aux ressources que Google configure pour crawler votre site web.
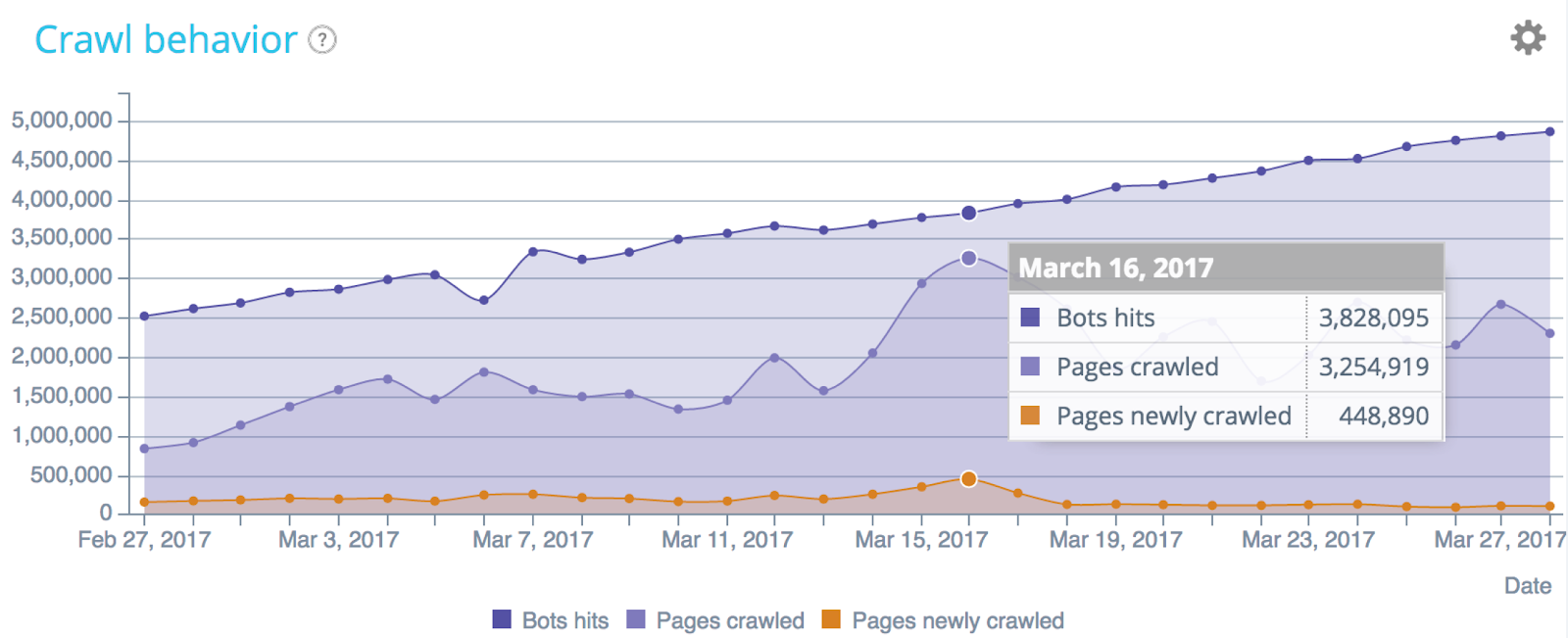
Comprendre le comportement de crawl avec l’analyse de fichiers de log (Données Oncrawl)
Comprendre et optimiser le budget de crawl
Il est donc important de comprendre comment Google voit votre site web et à quelle fréquence il le crawle.
Google dit que :
“[…] nous n’avons pas un terme unique pour décrire tout ce que cela semble signifier. Si vous constatez que les nouvelles pages sont généralement explorées le jour même de leur publication, alors vous n’avez pas vraiment à vous inquiéter du budget d’exploration.
[…] Si un site a moins de quelques milliers d’URLs, il sera parcouru correctement la plupart du temps”.
Le fait est que, nous savons tous que ce n’est pas complètement exact et que nous avons besoin de données plus précises sur la manière dont le budget de crawl est dépensé sur notre site web. En effet, 100 % des sites disposent de l’exploration de données dans leur compte Search Console :
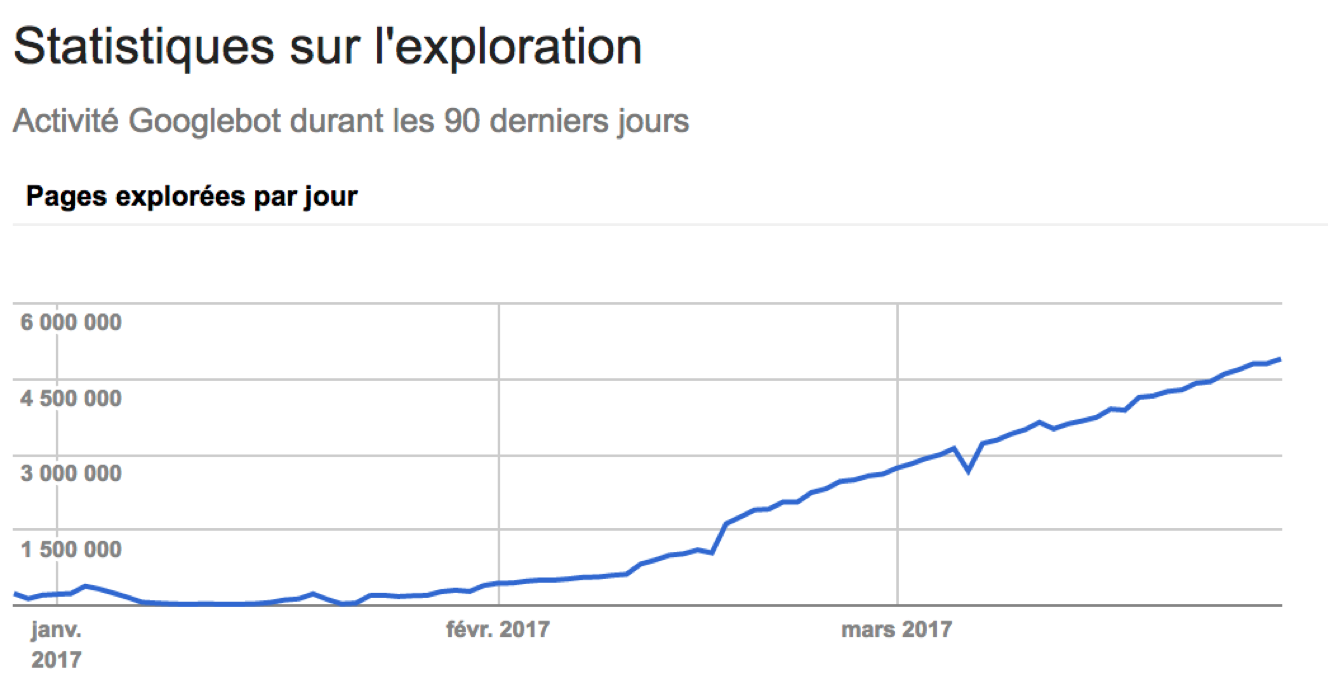
Alors que vous ne pouvez accéder qu’à un échantillon de résultats depuis GSC, l’analyse des fichiers de log permet de découvrir l’intégralité du comportement de crawl de votre site. Ainsi, vous pouvez détecter les anomalies dans le comportement du bot, les pics de crawl et n’importe quel autre problème.
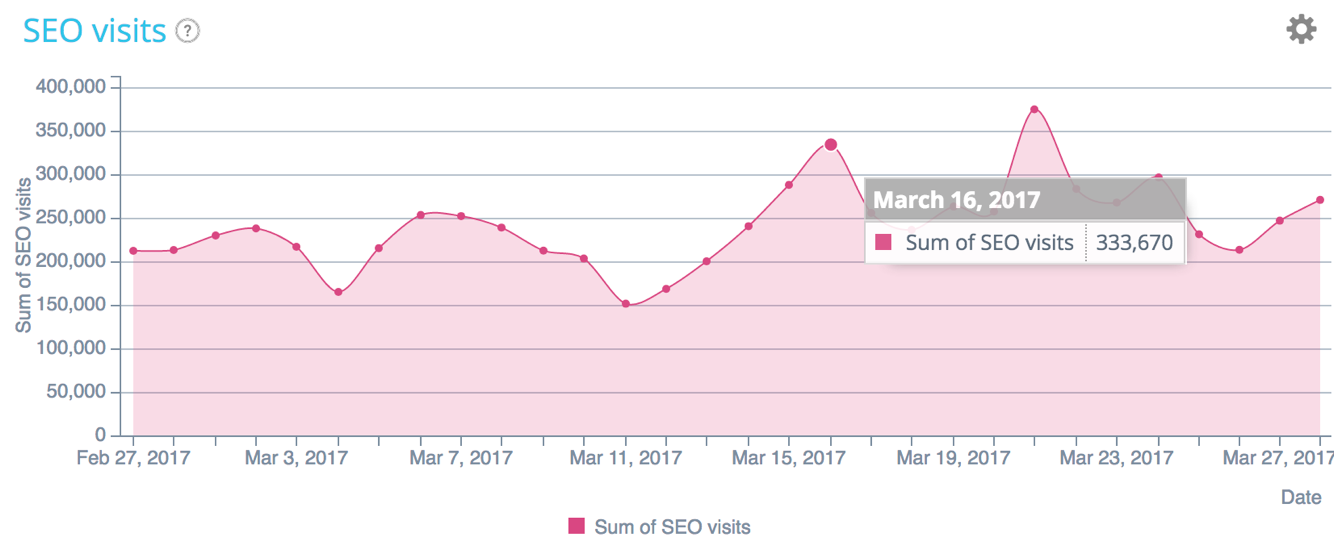
Répartition des visites SEO – Données Oncrawl
Est-ce que le budget de crawl est lié aux classements et visites ? Plus l’index est mis à jour, plus Google saura que la page est “la meilleure réponse à une requête”.
Organiser correctement le crawl
Afin de définir comment votre budget de crawl va être dépensé, vous devez :
- Prioriser les URLs à explorer selon les facteurs les plus importants ;
- Planifier les pages les plus importantes en priorité ;
- Adapter votre budget en fonction des besoins pour réduire les coûts ;
- Optimiser la qualité des données de votre site pour aider les algorithmes à faire les bons choix.
“Les robots de Google crawlent régulièrement le web pour reconstruire leur index. Les crawls sont basés sur différents facteurs comme le PageRank ou encore les liens vers une page et des contraintes de crawling comme les paramètres dans une URL. Un grand nombre de facteurs peut affecter la fréquence de crawl des sites individuels.
Notre procédure de crawl est algorithmique ; les programmes informatiques déterminent les sites à crawler, à quelle fréquence et combien de pages à rapporter de chaque site. Nous n’acceptons pas les paiements pour crawler un site plus fréquemment”.
Lignes directrices de Google Webmaster.
Surveiller la fréquence de crawl
Afin d’optimiser la fréquence de crawl, vous devez :
- Analyser vos fichiers de log pour recevoir un bilan de santé de votre SEO. Ils contiennent les seules données qui reflètent exactement la manière dont les moteurs de recherche parcourent votre site ;
- Créer une alerte quand la fréquence de crawl diminue ou augmente.
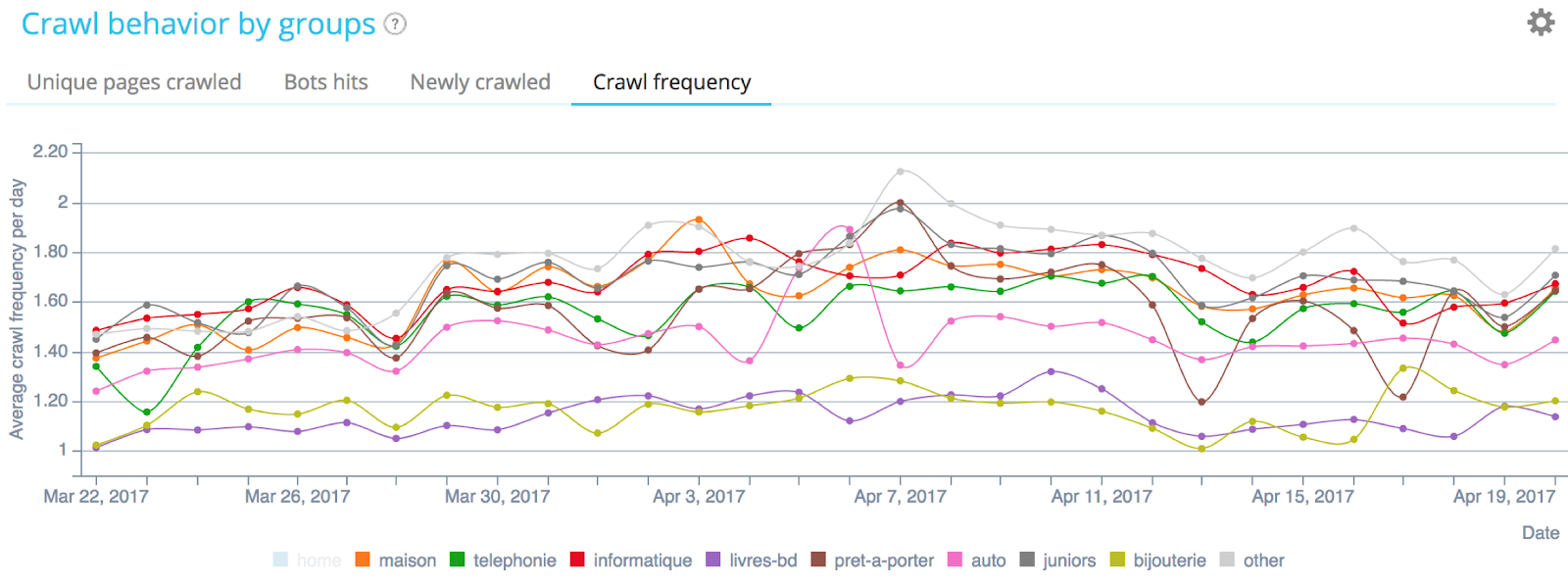
Fréquence de crawl en fonction des groupes stratégiques de pages – Données Oncrawl
Comprendre l’impact des variables sur l’indexation
Les IA Google ou IA de Bing utilisent des variables pour définir le montant de budget de crawl à dépenser sur votre site. Il est nécessaire de retourner les plus belles données pour aider les algorithmes à déclencher l’augmentation du budget de crawl.
Google utilise des métriques internes (contenu, détection d’entité, schema.org, payload, popularité, etc) et des métriques externes (Page Rank, Trust & Citation Flow, etc) pour choisir d’indexer une page ou non.
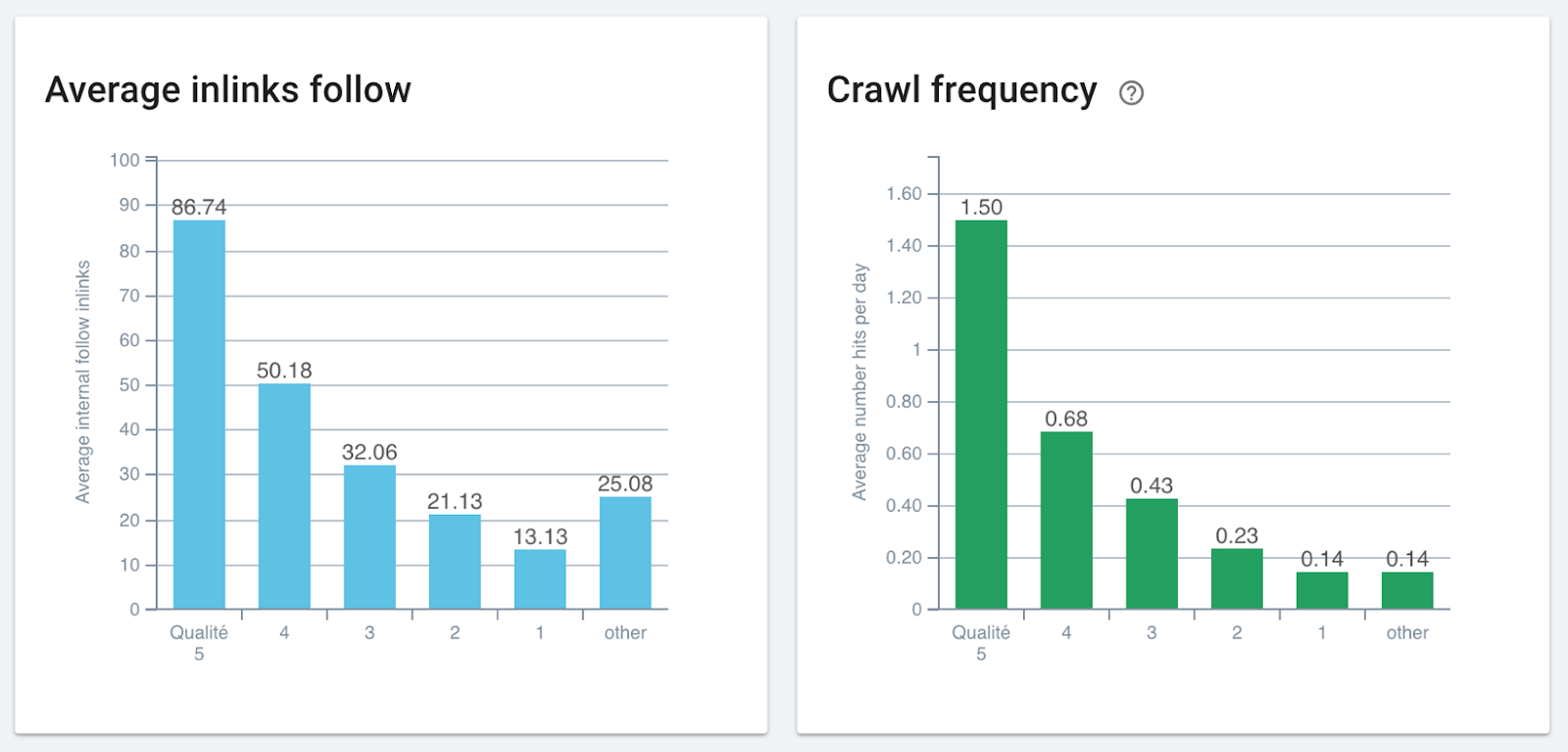
Corrélation entre le nombre de liens et la fréquence de crawl – Données Oncrawl
Les principes d’échelle du web s’appuient sur :
- L’utilisation massive de l’interprétation de données comme l’analyse du langage naturel ou l’incorporation de mot ;
- L’utilisation massive de données corrélées car le web est rempli d’entités ;
- L’ontologie qui inclue également toute la sémantique décrivant les relations entre les termes ou entre les entitées nommées.
Optimiser les classements
Une fois indexées, Google note chaque page de votre site et utilise différentes métriques calculées comme le Pagerank, les scores de qualité, la confiance du site, etc, puis agrège de nombreux attributs à chaque page (méta données, titre, schema.org, n-grams, payload, interprétation de contenu…)
Les principes d’échelle du web s’appuient également sur :
- L’utilisation massive d’agrégation de données : humaine / calculée ;
- L’utilisation massive d’interdépendance / qualification de données : humaine/calculée.
Comprendre l’intelligence artificielle
Crawling, indexation et classement ne sont pas délimités par l’intelligence artificielle. Les algorithmes, l’agrégation de données, la validation humaine/supervisée, l’utilisation massive de modèles de données, la connaissance et l’interdépendance des analyses renvoient à l’IA. Le Machine Learning peut aussi faire partie de la procédure en ajoutant de multiples cycles d’itération.
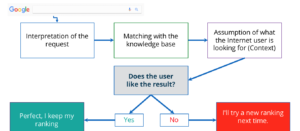
Google Rankbrain est une procédure de machine learning qui consiste à pré-classer des résultats. De l’interprétation de la requête à la supposition de ce que l’utilisateur recherche et l’adaptation des résultats, Rankbrain est en cours de test et d’apprentissage.
Pour garder vos classements et correspondre aux directives de Rankbrain, vous devez aider Google à maximiser les sessions d’exploration et diriger le bot et les utilisateurs dans la bonne direction :
- Réduire les erreurs ;
- Rectifier les problèmes techniques ;
- Renforcer le contenu ;
- Créer des raccourcis profonds ;
- Organiser le maillage par objectifs ;
- Accélérer le site web.
Comprendre la Page Importance
La Page Importance joue aussi un grand rôle dans la procédure de re-indexation. Un score indépendant de requête (aussi appelé un document de score) est calculé pour chaque URL par les rankers d’URL de page.
“[…] le score de page importance est calculé en considérant non seulement le nombre d’URLs qui référencent une URL donnée mais aussi avec le score de page importance de telles URLs référencées”.
Les données du score de page importance sont partagées aux managers d’URLs qui transmettent un score de page importance pour chaque robot d’URL et serveur de traitement de contenu.
Un exemple de score de page importance est le PageRank, qui permet au taux de crawl d’être dirigé par des données fixées par les SEOs.
Brevet US20110179178 de Page Importance
La page importance peut cependant être optimisée en jouant avec avec les bonnes métriques :
- Profondeur et localisation de page sur le site ;
- PageRank, Trust Flow, Citation Flow ;
- Inrank – PageRank interne d’Oncrawl ;
- Type de document : PDF, HTML, TXT ;
- Inclusion de sitemap.xml ;
- Qualité / répartition des ancres ;
- Nombre de mots, peu de contenu similaire ;
- Page Importance liée.
Indicateurs SEO clés qui favorisent le crawl de Google
Des expérimentations de l’équipe SEO d’Oncrawl et des insights partagés par la communauté ont montré que :
- Google n’aime pas creuser trop profond dans un site ;
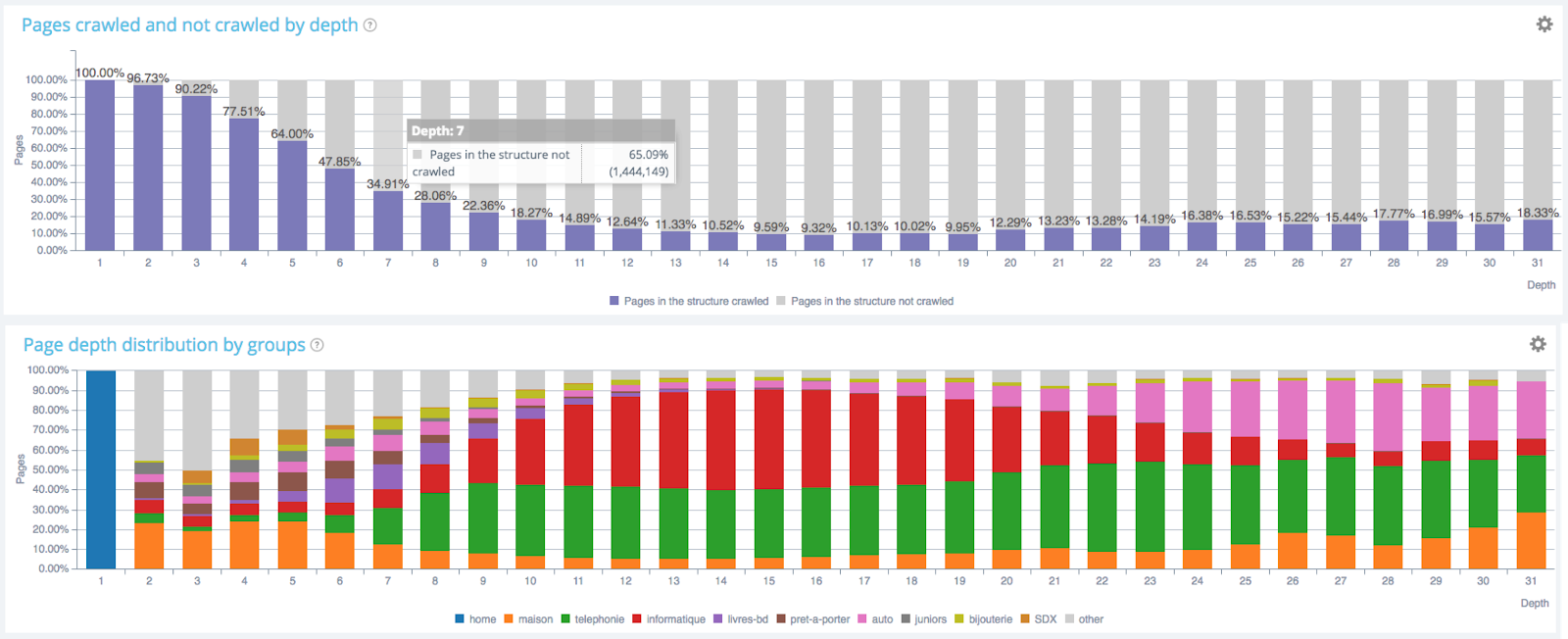
L’impact de la profondeur sur la fréquence de crawl – Données Oncrawl
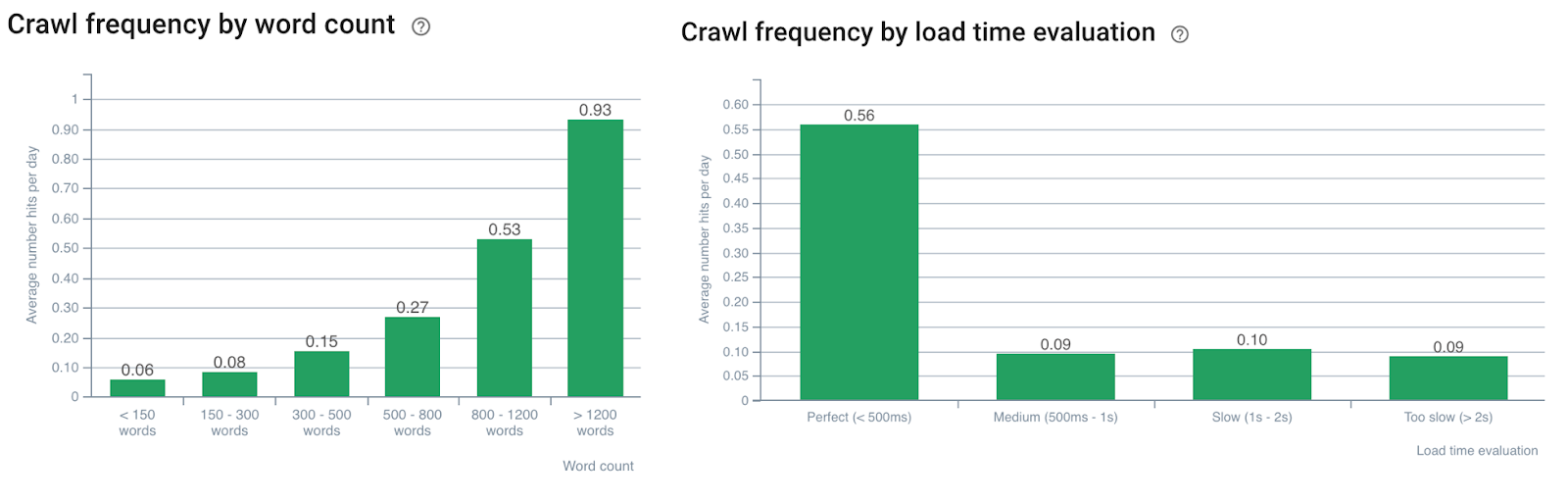
- Google est sensible au volume de contenu ;
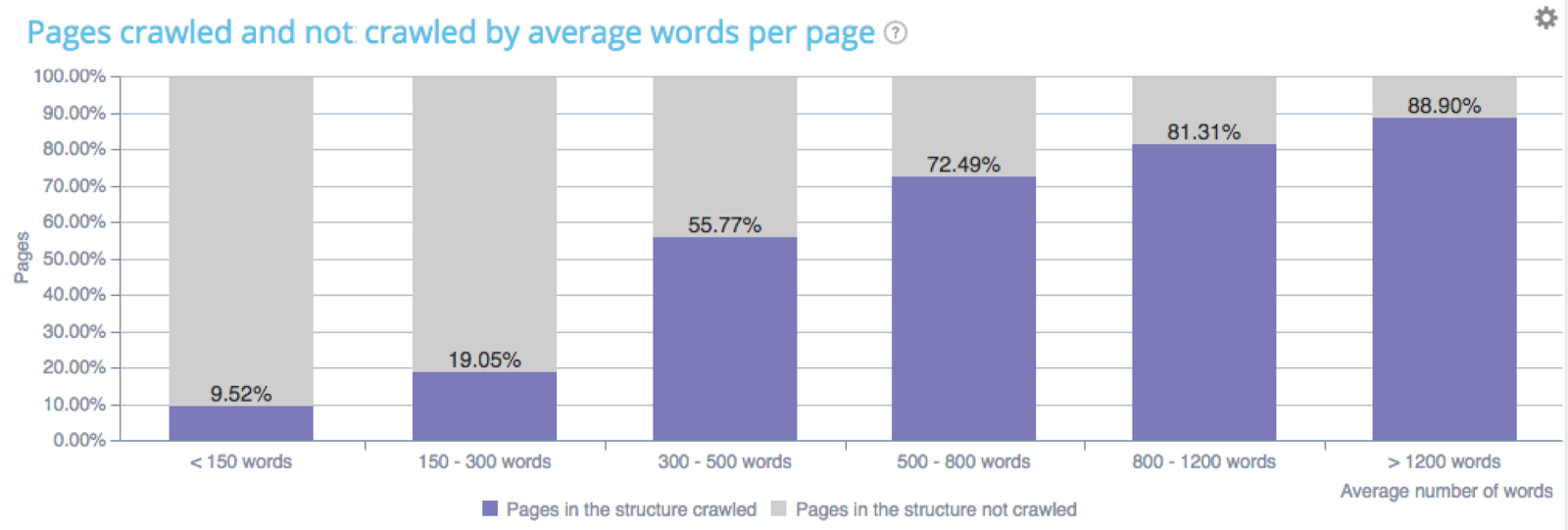
L’impact du nombre de mots sur la fréquence de crawl – Données Oncrawl
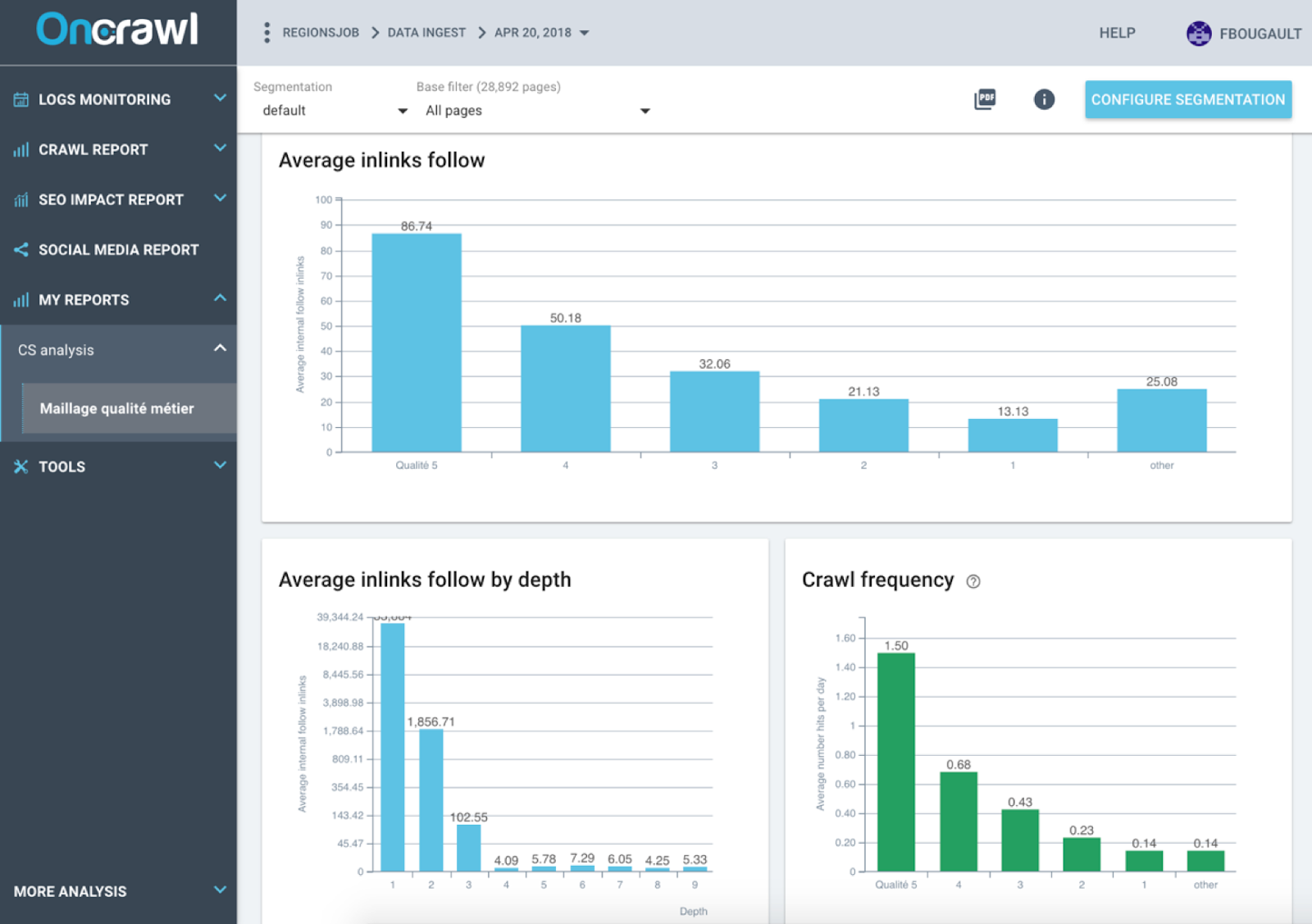
- Google est sensible à la popularité interne (Inrank Oncrawl) ;
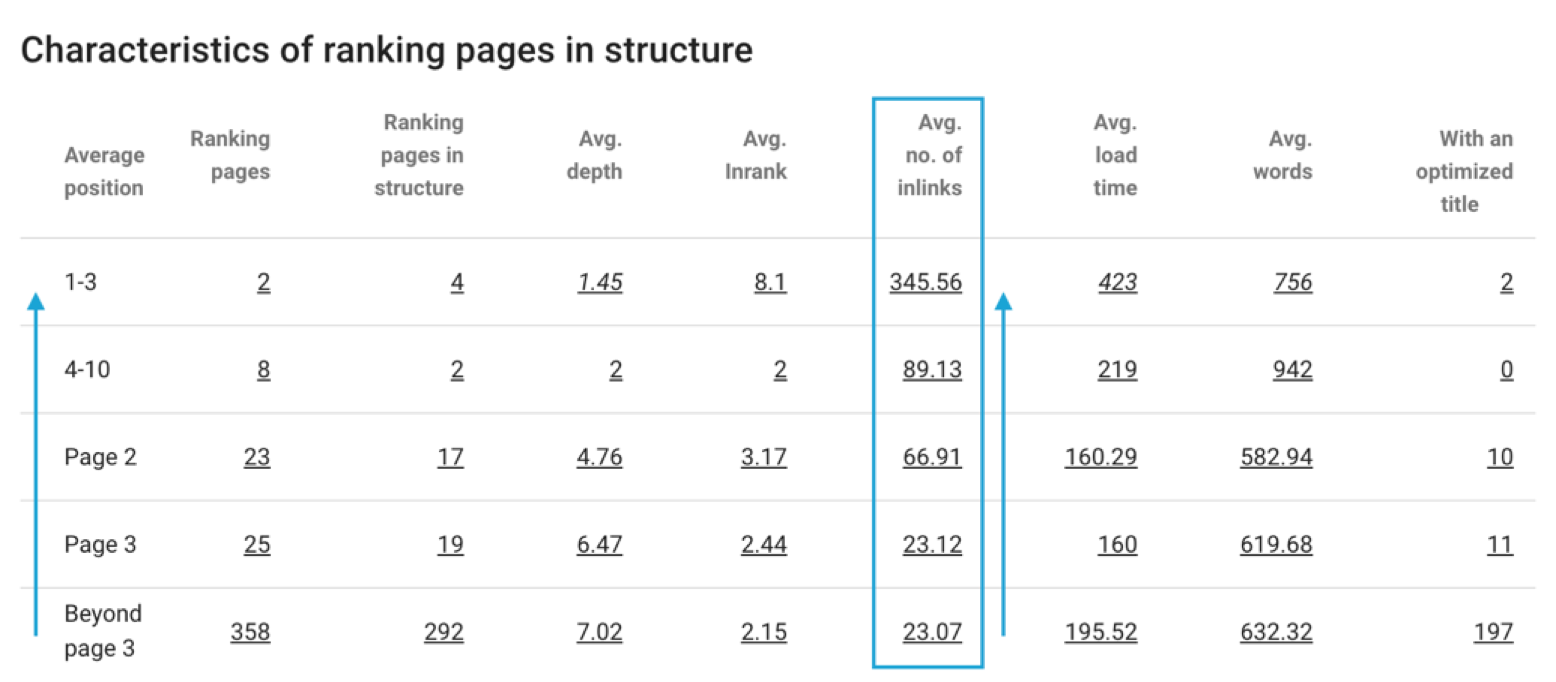
Impact du nombre de liens sur la position moyenne
- Google est sensible au CTR moyen et au taux de rebond ;
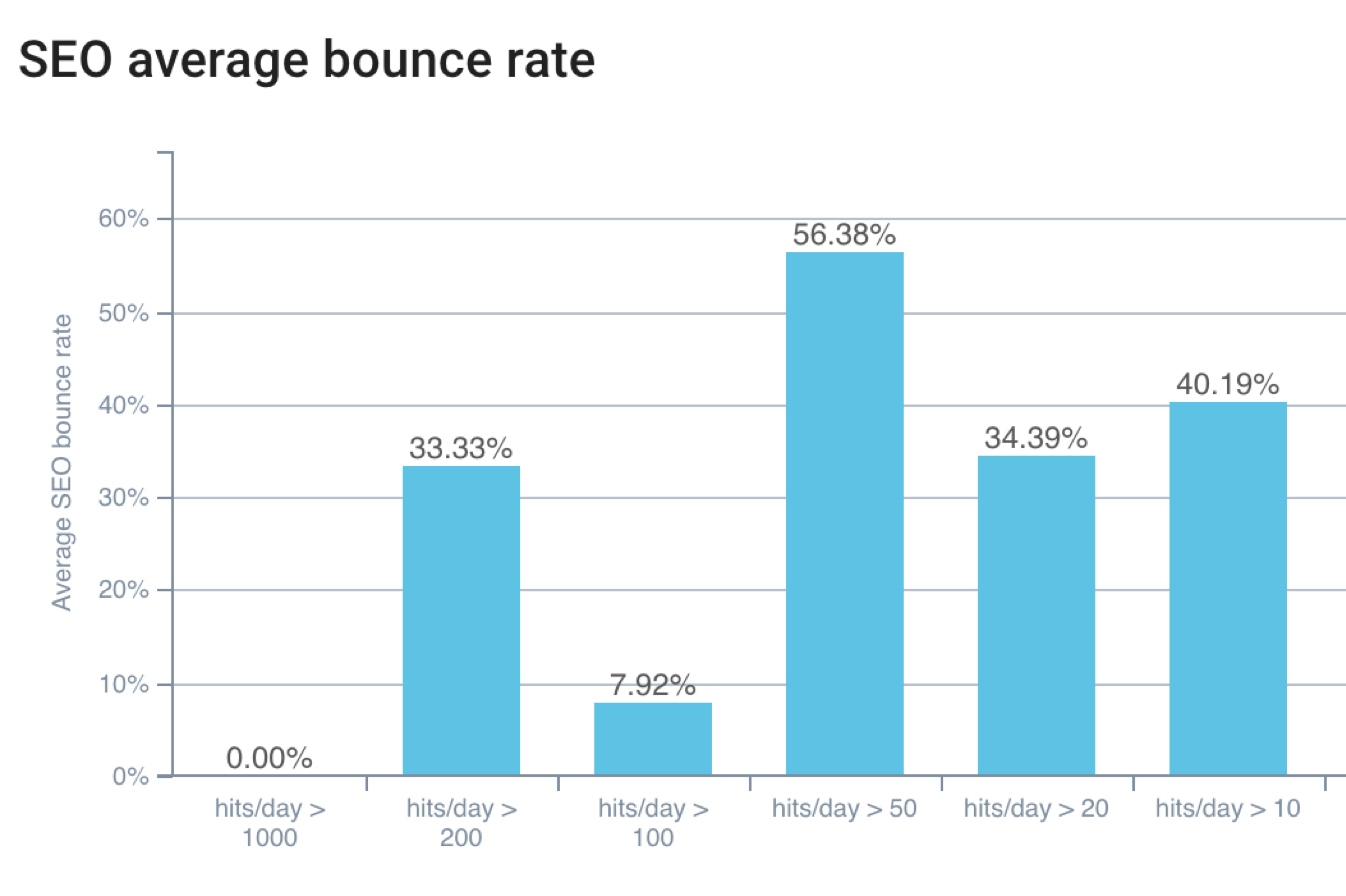
Taux de rebond faible = passages des bots plus élevé
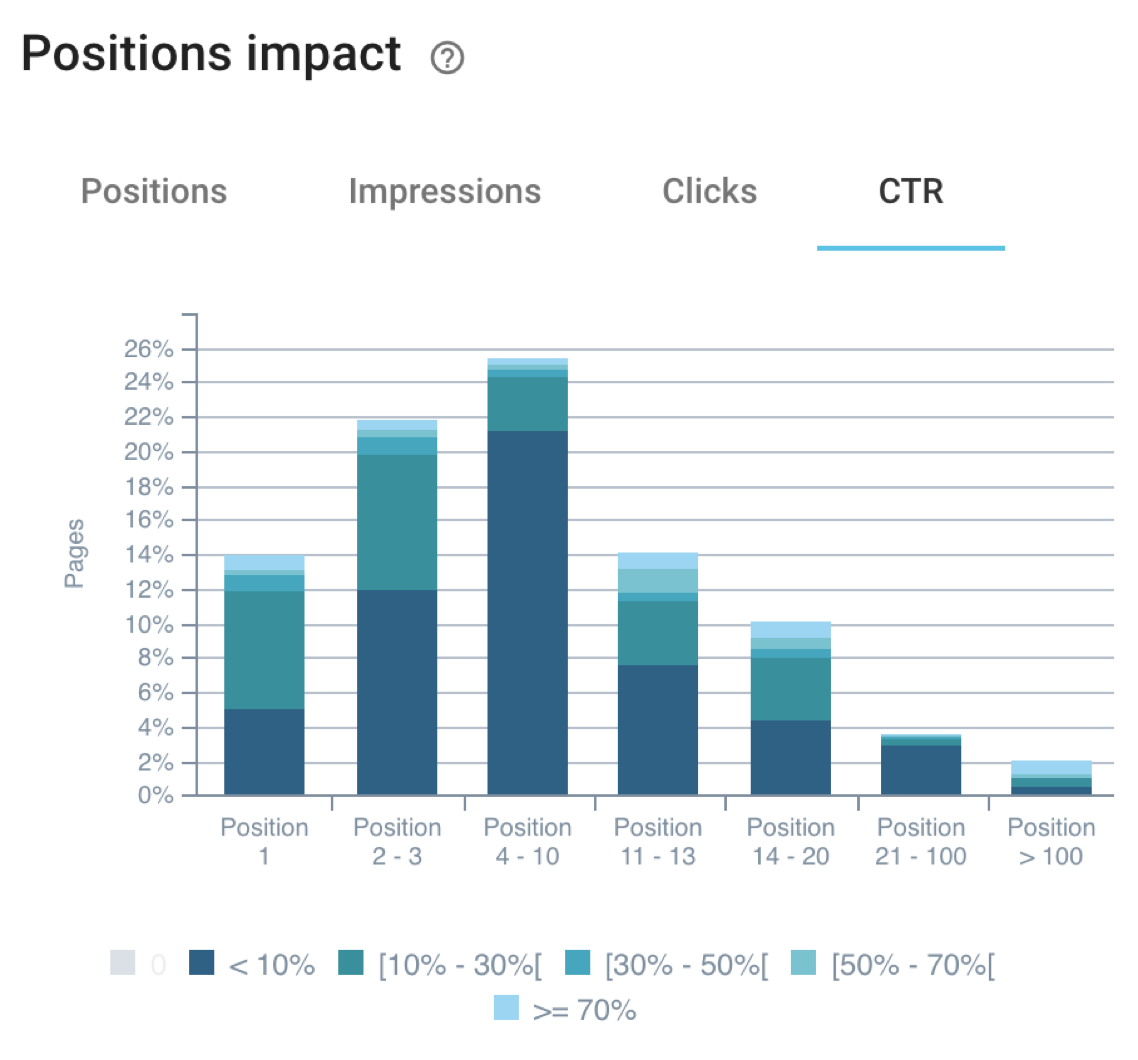
Meilleur CTR = Meilleures positions
- Les pages prioritaires devraient être liées depuis la page d’accueil, ou idéalement à 1 ou 2 niveaux depuis la page d’accueil ;
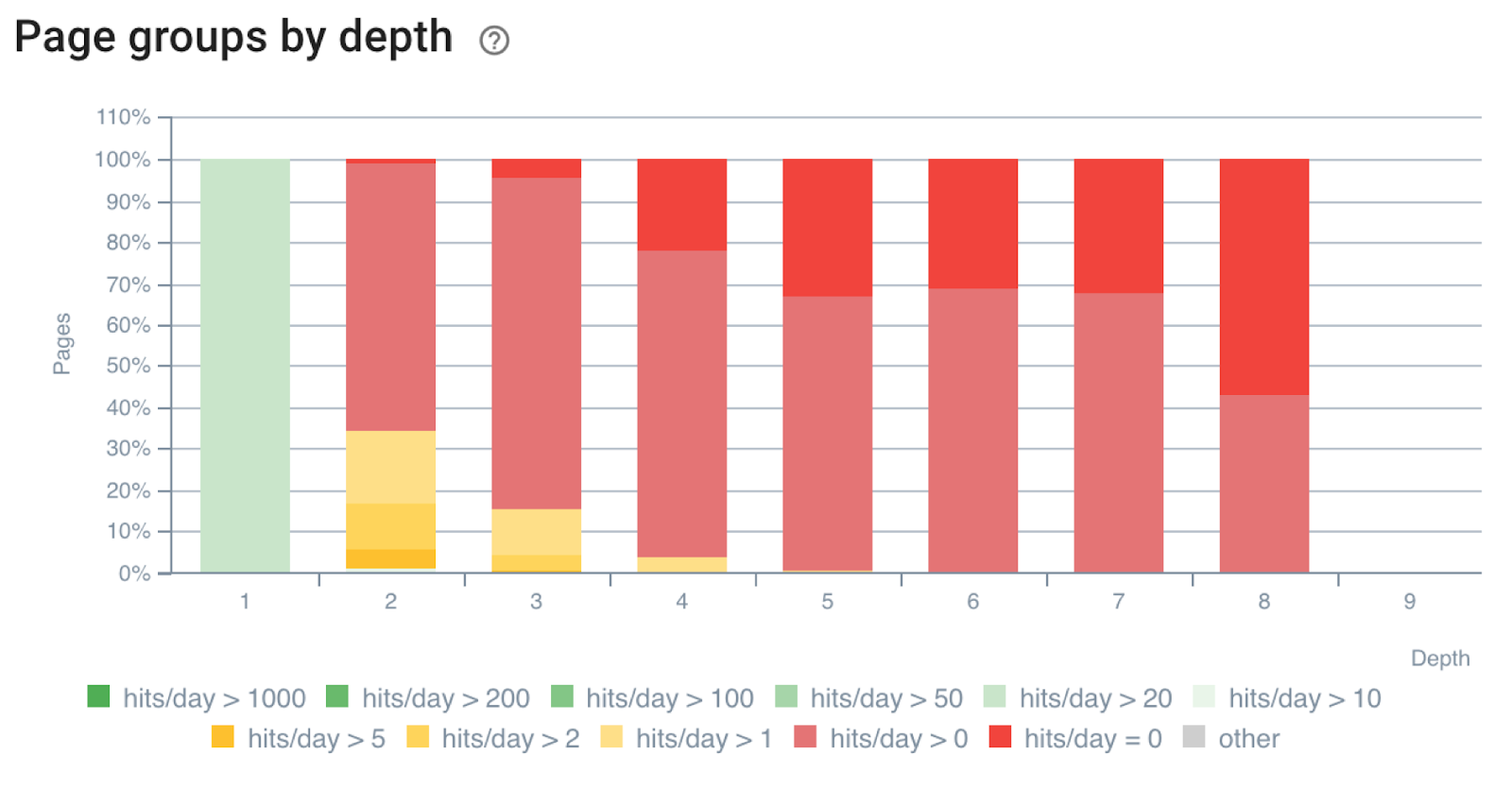
Nombre de passages de bots en fonction du niveau de profondeur – Données Oncrawl
- Pour être fréquemment crawlée, une page doit être rapide et avoir un très bon contenu.
Indexation et interprétation du contenu
Google classe trois types de requêtes :
- Transactionnelles ;
- Informationnelles ;
- Navigationnelles ;
En fonction du type de requête à classer, Google va plus ou moins crawler.
Google ne comprend pas le contenu, mais il semble comprendre les concepts en utilisant la détection des entitées nommées :
- Il crée des matrice de termes et de poids des mots ;
- Il déduit les thèmes des pages pour la procédure de classement ;
Comprendre les requêtes transactionnelles
Pour illustrer ce type de requête, nous avons utilisé la recherche suivante : “converse men’s chuck taylor”.
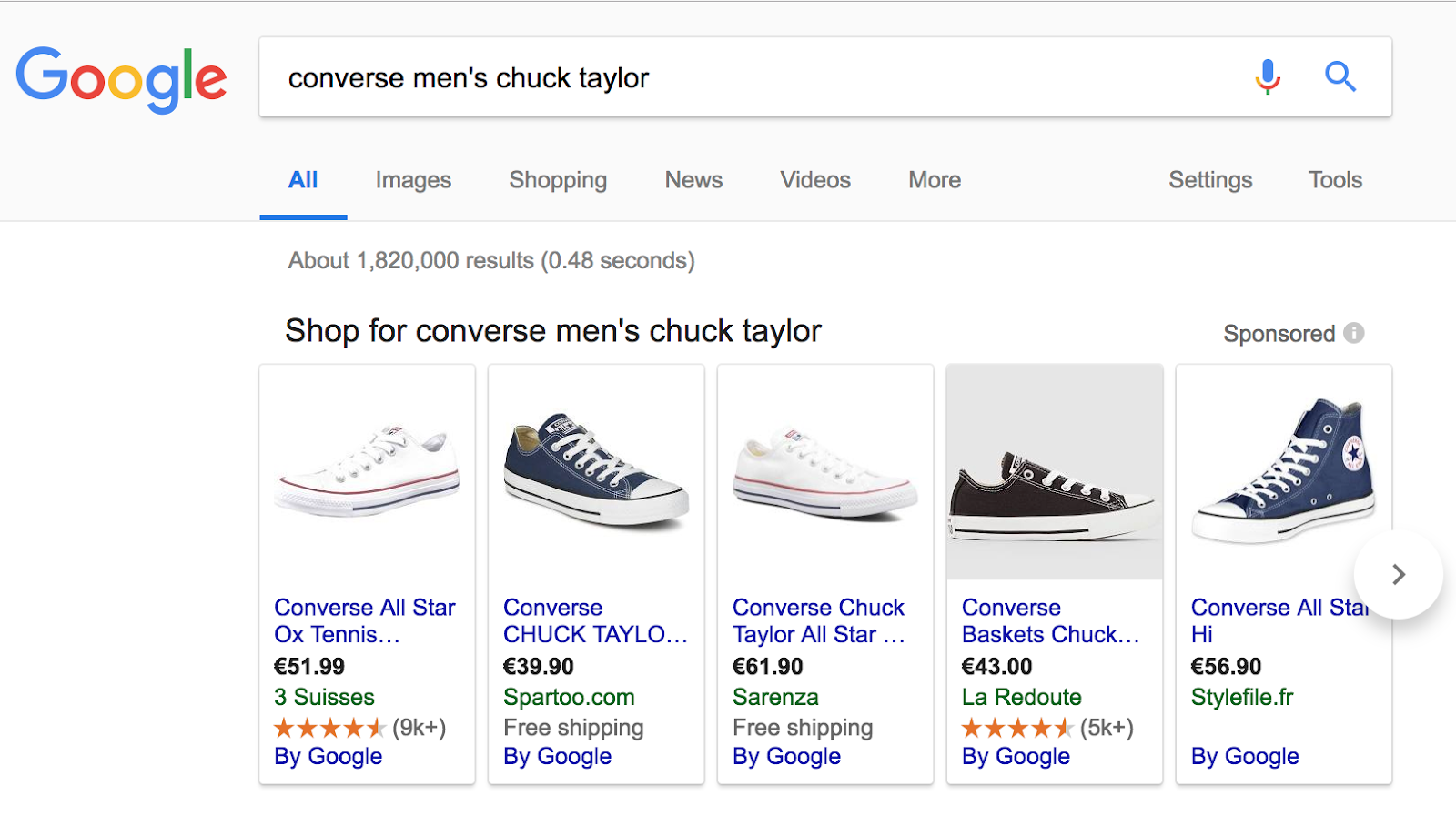
Ici, l’utilisateur souhaite accéder à un site web ou il y aura des interactions.
Les pages sur “converse men’s chuck taylor” renvoient à du contenu froid et à une requête transactionnelle et reçoivent une fréquence de crawl moyenne. Il est important de penser le maillage en termes de relation des entités marque/produit
Comprendre les requêtes informationnelles
Ce type de requête est réalisée lorsque l’utilisateur recherche une information spécifique. Par exemple “Clinton”.
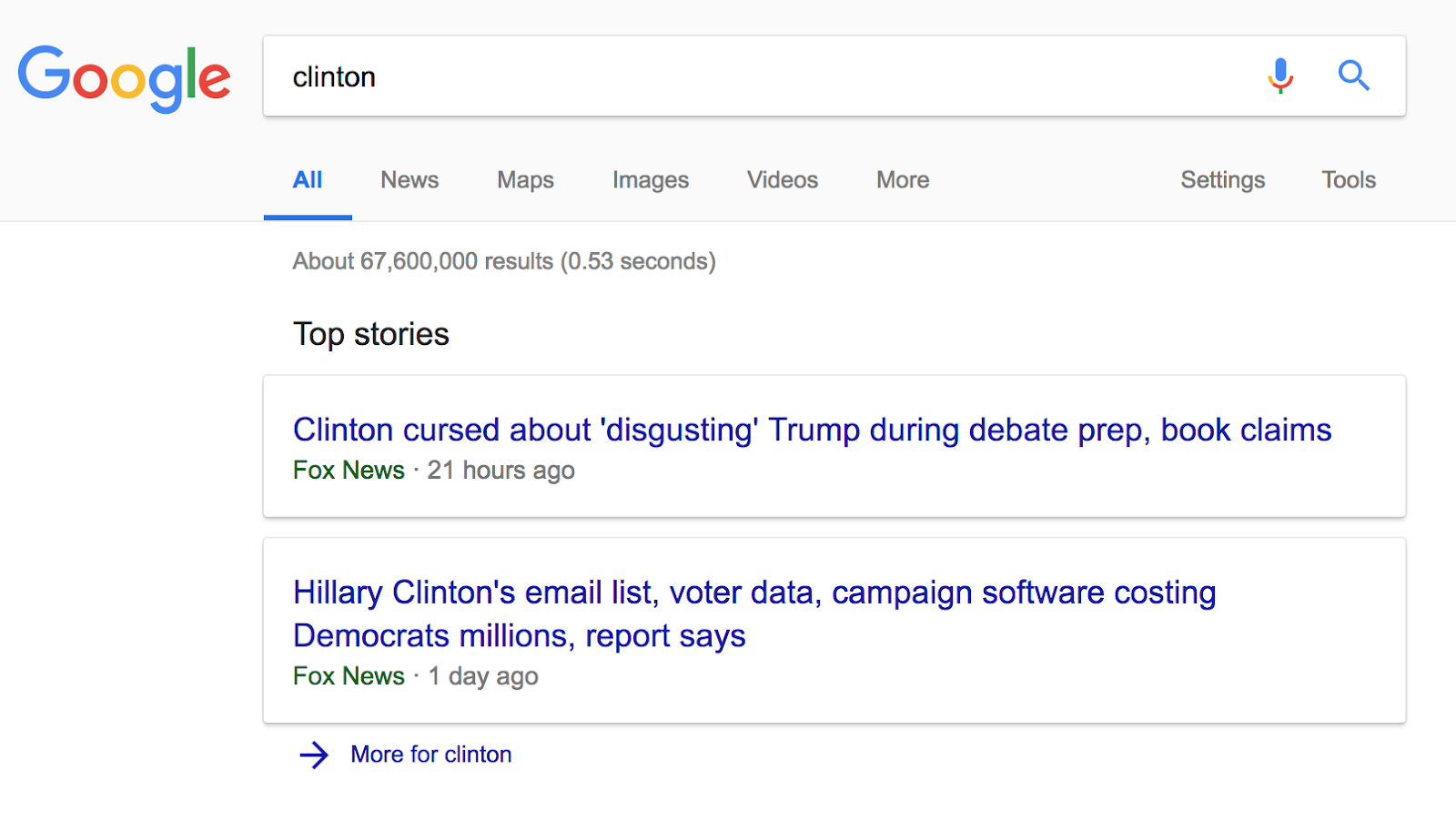
Les résultats montrent des pages à propos de “Clinton” ou “Trump” comme il s’agit d’un sujet “d’actualités chaudes”. Ces pages reçoivent donc une très haute fréquence de crawl. Le maillage doit être puissant et basé sur des entités nommées.
Comprendre les requêtes navigationnelles
Les requêtes navigationnelles sont utilisées par les utilisateurs qui cherchent à atteindre un site particulier.
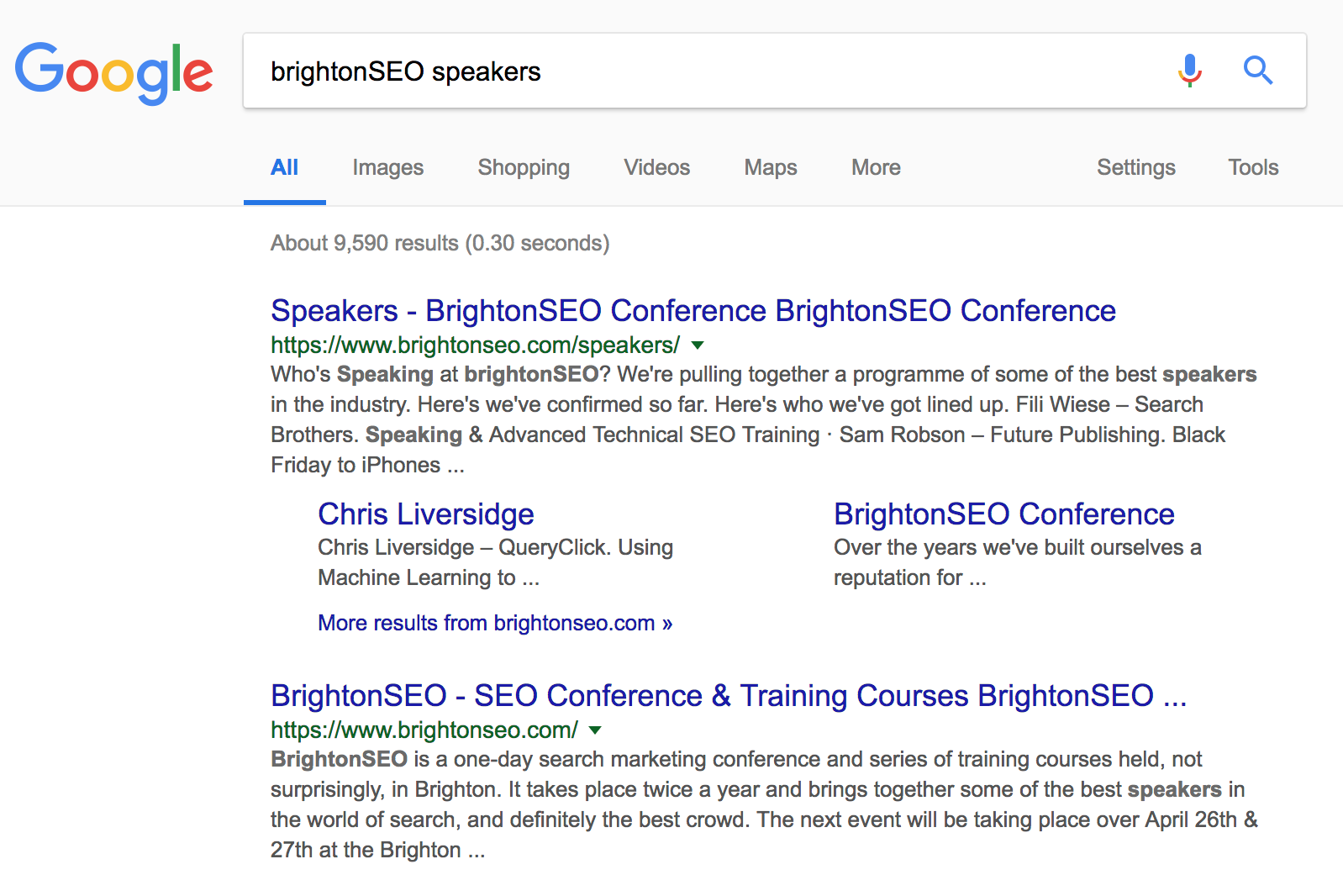
Sur cet exemple, les pages ciblant “BrightonSEO speakers” sont diffusées car elles appartiennent au site BrightonSEO. Ce site reçoit une faible fréquence de crawl et a besoin de s’appuyer sur optimisations sémantiques SEO,du Trust et du Citations Flow.
De plus, Rankbrain est basé sur le processus de langage naturel. Cela signifie que l’algorithme est capable de se représenter des chaînes de textes dans un espace dimensionnel élevé et de voir comment ils sont liés entre eux. Google maintient d’ailleurs une knowledge base sur les entités nommées et la compréhension des relations entre les entités :
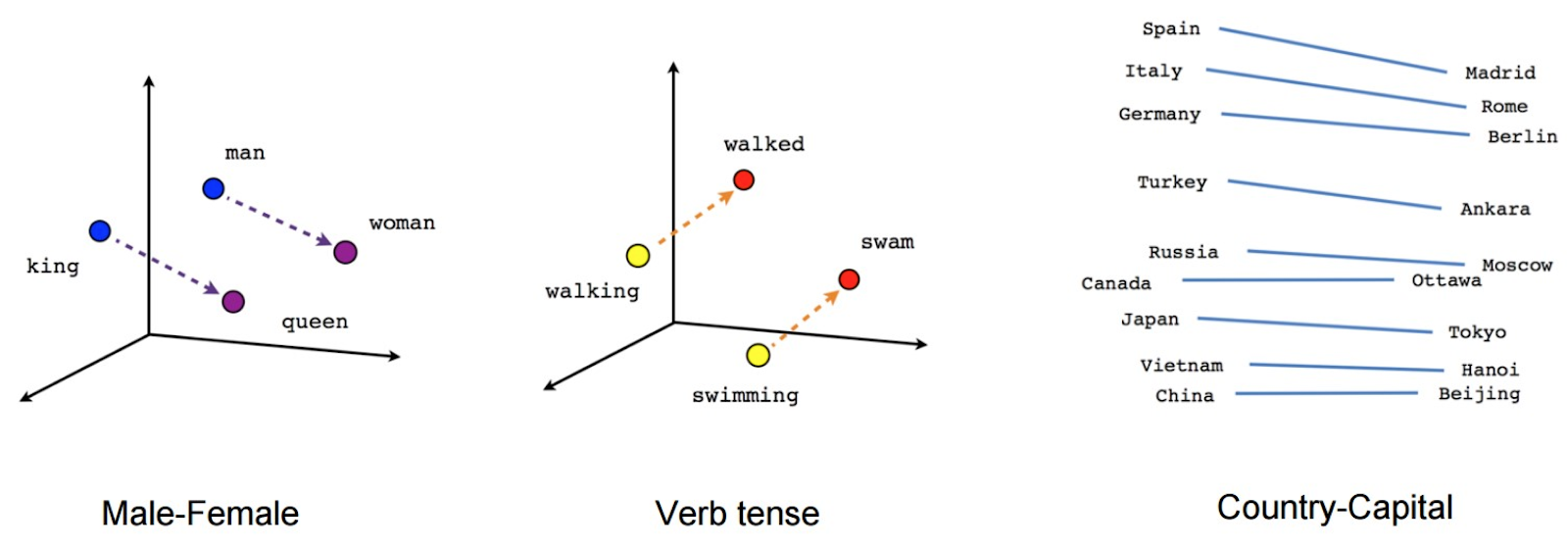
Dans un algorithme de moteur de recherche, un outil a besoin de calculer un score de “similarité” entre deux documents.
Cette note est stratégique pour créer un classement pertinent, mais est aussi utilisée en association avec un très grand nombre d’autres signaux, assez importants (comme la popularité d’une page) ou mineurs (comme la présence d’un mot-clé dans l’URL d’une page).
Chaque entité ou concept est vectorisé pour que les machines puissent les comprendre :
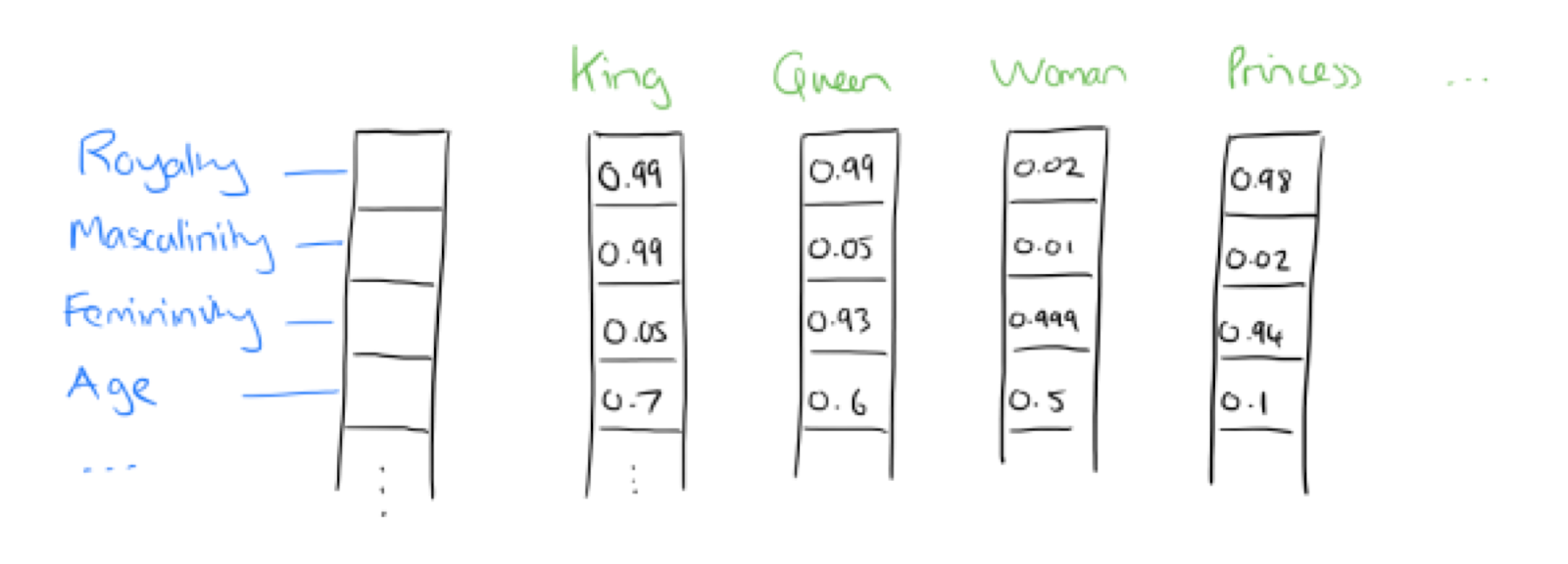
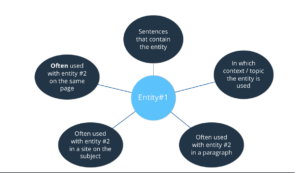
Puis, Google peut évaluer la distance entre deux concepts. Pour chaque entité, Google sait que :
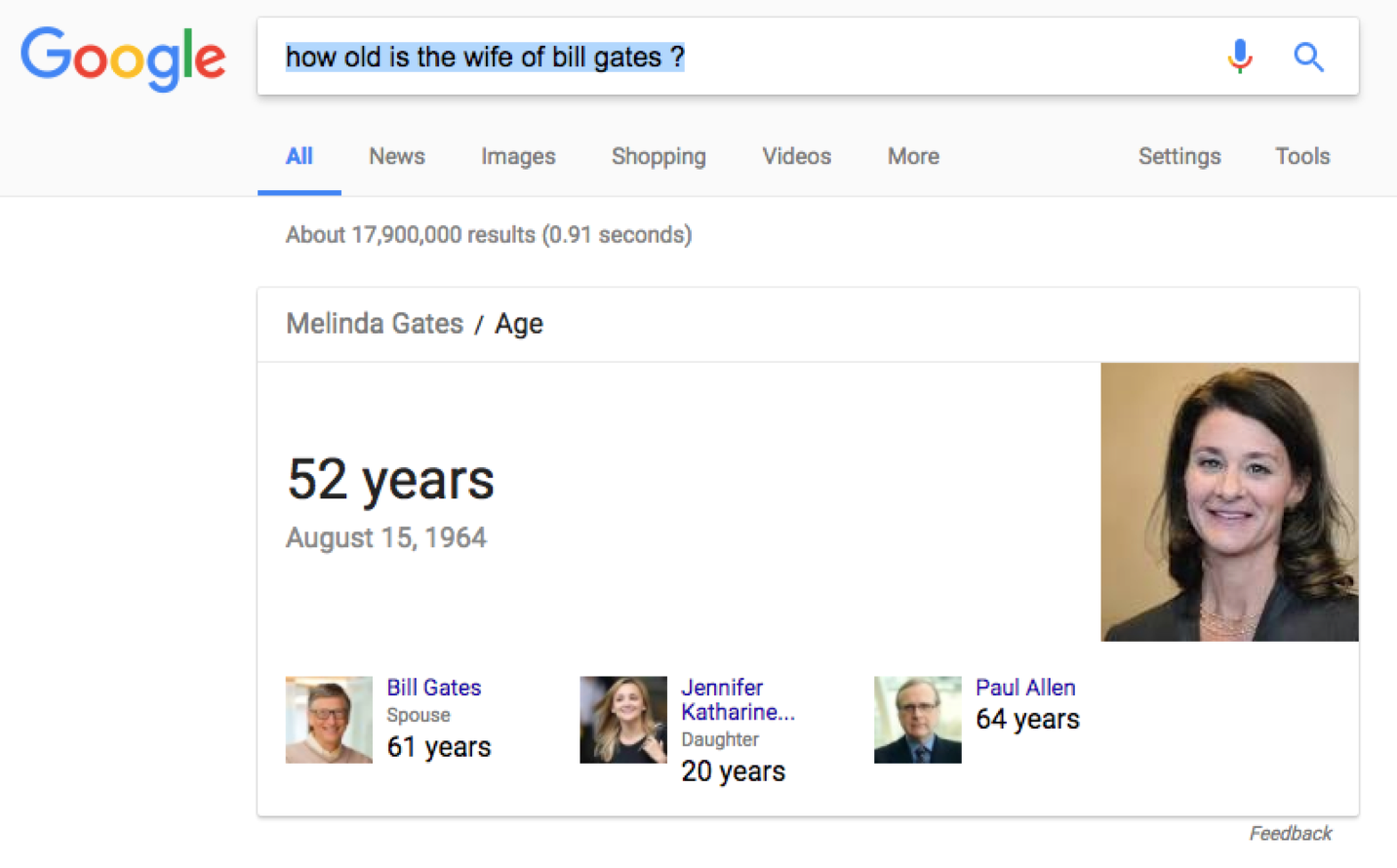
Pour utiliser un exemple plus concret, cherchons “how old is the wife of Bill Gates?”
- “How old is” : présomption d’une requête sur un âge
- “The wife of” : type de relation
- “Bill Gates” : individu / personnalité
Pour résumer, Google aura tendance à crawler des pages par “package” :
- Sur le même chemin (découverte) ;
- Sur le même sujet (recrawl).
Plus il rencontrera de contenu avec les entités attendues (liées au thème), plus il crawlera profondément. Le type d’entité, sa rareté ou popularité va directement impacter la fréquence de crawl.
Le maillage interne doit ensuite être pensé en fonction de la relation entre les entités présentes dans votre contenu. Vous pouvez vérifier vos entités nommées directement dans vos rapports de crawl.
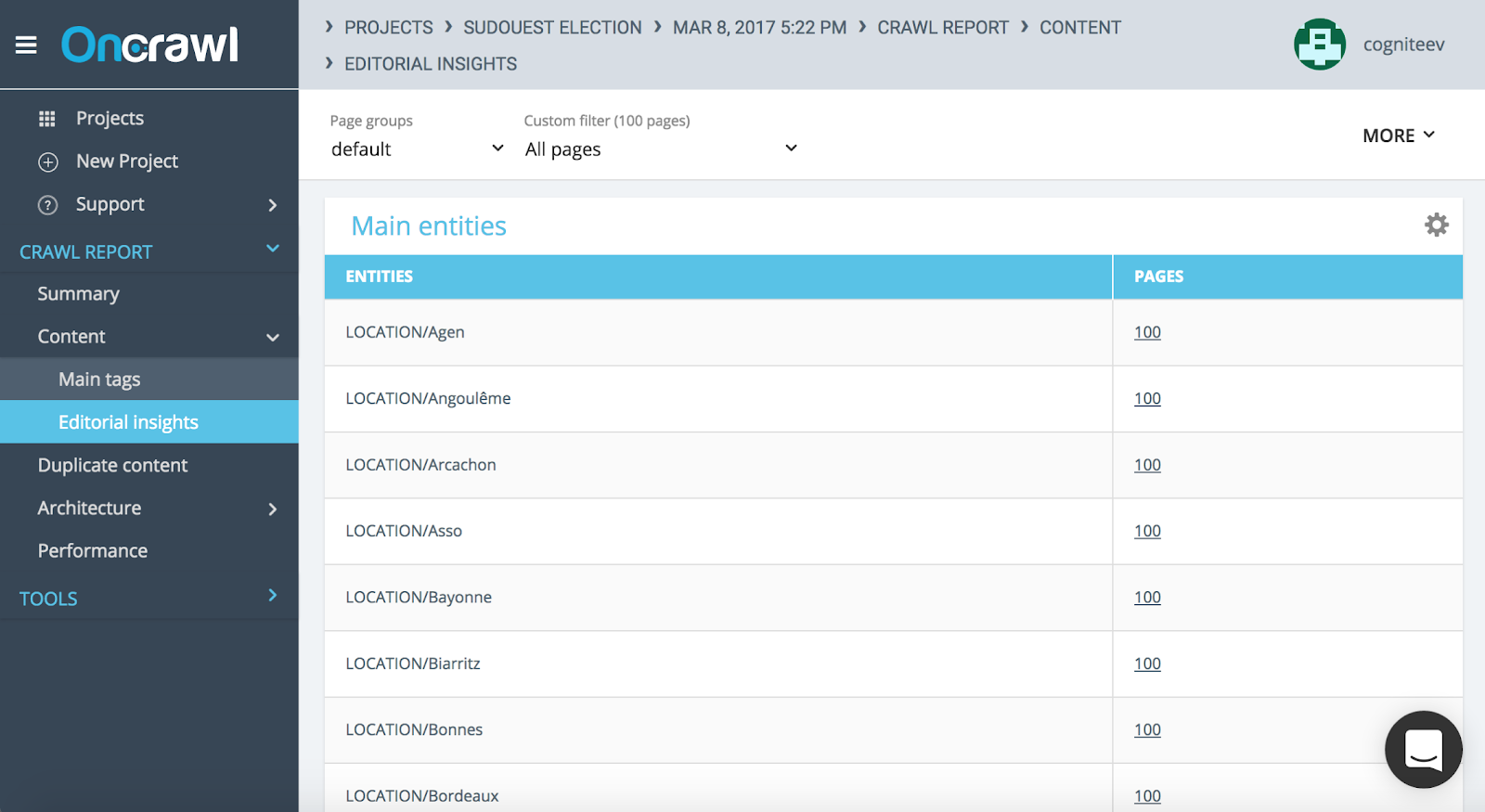
Tableau d’insights éditoriaux à propos des entités nommées avec le rapport de crawl Oncrawl
Comment maximiser vos efforts pour Rankbrain et les autres IA Google ?
Tout d’abord, cartographiez votre site web par :
- Type de contenu ;
- Catégories de pages ;
Puis, comprenez comment les entités sont présentes dans votre contenu et analysez la manière dont les pages avec entités sont liées.
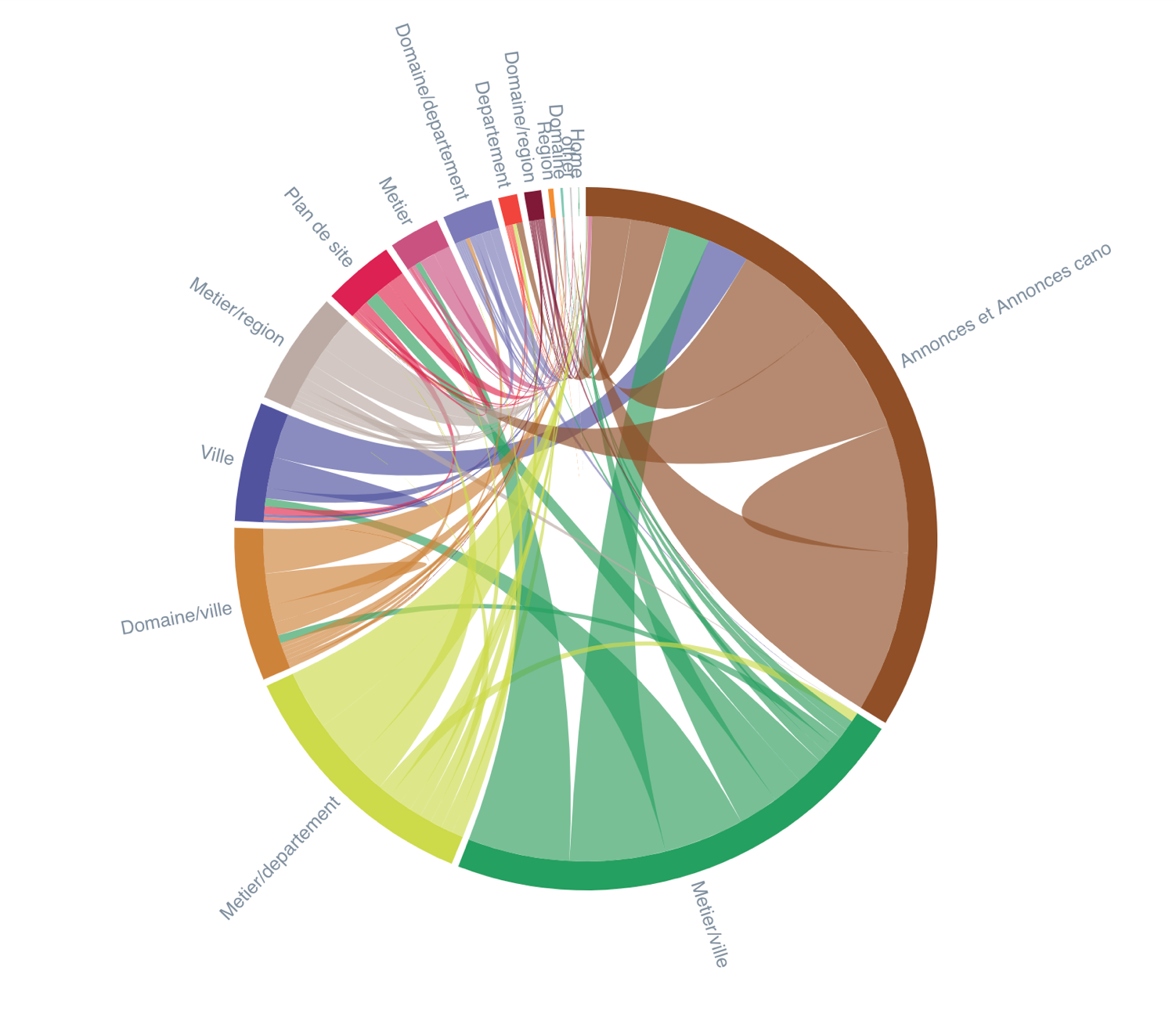
Inrank flow : montre comment la popularité du maillage interne se répand entre les groupes – Données Oncrawl
Pour ce faire, la première étape est de crawler votre site pour :
Catégoriser vos pages ;
- Extraire les entités nommées par groupes de pages ;
- Identifier les pages avec ou sans entités nommées pour ajuster votre contenu ;
- Surveiller le nombre de mots par groupes de pages ;
L’objectif est de définir les métriques de contenu idéales pour maximiser votre crawlabilité.
![]()
![]()
Puis, utiliser les entités nommées dans vos ancres liées et créez des ensemble de pages liées en fonction de la typologie d’entité. Voici l’exemple d’un site média :
Conclusions
Crawling, indexation, classements et re-classements sont tous basés sur des principes d’intelligence artificielle et de machine learning.
Ils ne sont pas si intelligents que cela puisqu’ils ont toujours besoin de nos modèles de validation. N’oubliez jamais qu’ils ne sont que des algorithmes : vous devez connaître et utiliser les métriques qu’ils prennent en compte pour les manipuler !
- Le crawl consomme de l’énergie ; simplifiez la vie des bots en prêtant attention à la profondeur, aux raccourcis de navigation, au contenu dupliqué et surtout au temps de chargement et au poids des pages dans le contexte actuel d’index mobile-first. Suivez le budget de crawl avec vos logs !
- L’indexation est basée sur des métriques de contenu internes/externes. Cependant, Google utilise le Knowledge Graph en tant que base d’apprentissage pour les entités nommées.
- Les classements renvoient à la cohérence de toutes ces données avec les intentions des utilisateurs et dépend de la qualité (technique) et de la pertinence (sémantique) des scores. De plus, le comportement de l’utilisateur et ses intentions sont pris en compte ainsi que ses informations personnelles de recherche et visite.
La clé est de satisfaire l’utilisateur pour qu’il revienne afin de manipuler le CTR et le taux de rebond !
En d’autres termes, favorisez les titres, meta descriptions, contenu, vitesse et l’UX/UI !