
Certains sites web n’utilisent pas vraiment les sous-dossiers. Cela peut arriver lorsque, par exemple, un CMS spécialisé génère des pages recherche à facettes multiples pour filtrer les pages produits qui sont toutes, où presque toutes, situées à la racine du répertoire. Et ce n’est pas grave ! Cela signifie simplement que grouper les pages automatiquement dans des catégories utiles est plus difficile parce que beaucoup de groupements utilisent les sous-domaines dans le chemin de l’URL pour établir des catégories.
Nous avons paramétré des catégories personnalisées pour de nombreux clients pour qui notre segmentation d’URL par défaut ne fonctionnait pas. Voici l’une des approches que nous avons employée.
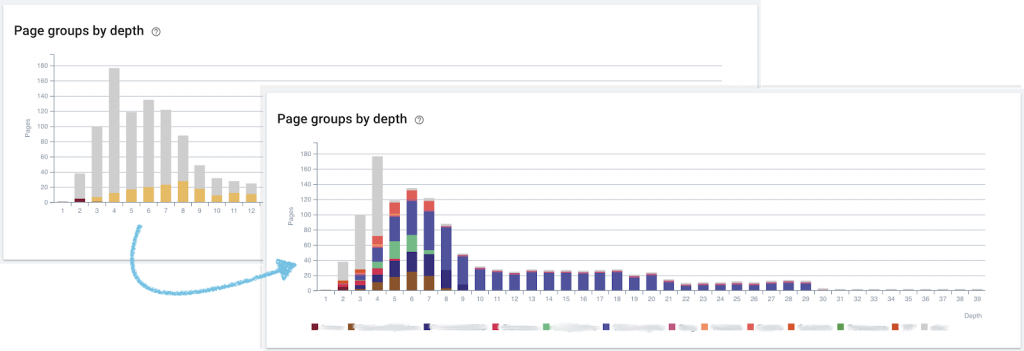
Aborder des URLs complexes avec Oncrawl
Comme avec n’importe quelle segmentation de site web, il faut d’abord définir vos catégories. Par exemple, si vous vendez des places de concerts, vous devriez savoir des pages pour les types de contenu suivants :
- Artistes
- Titre du concert
- Salle
- Type de siège ou de place
- Langue du concert
- Le blog de votre entreprise sur les actualités du secteur
- Des landing pages de recherche qui ciblent des genres de concerts
Une fois que vous savez dans quelles catégories vous allez grouper vos pages, nous pouvons commencer à regarder certaines caractéristiques de l’URL en elle-même. Les segmentations basées sur l’URL ont un avantage spécifique : elles peuvent s’appliquer à n’importe quel contexte ou crawl, peu importe les types de données et analyses disponibles.
Nous allons d’abord vous aider à rechercher des usages standards dont vous pourrez tirer profit pour trier vos pages :
- Est-ce que toutes vos pages artistes utilisent certains mots-clés comme “artistes” dans leur URL ?
- Est-ce que les URLs des pages dédiées aux salles commencent bien toutes avec la même structure telle que “NomDeSalle-Ville-NuméroId” ?
Une fois que vous avez trouvé autant de structures standardisées que possible, nous devons ensuite rechercher des listes de types de contenu qui apparaissent dans les slugs d’URL. Peut-être que vous vendez des dizaines de types de ticket, de catégories de sièges ou encore des concerts dans 4 langues différentes, qui à l’inverse des noms des concerts ne vont pas changer au fil du temps. Il peut parfois être intéressant de lister cela, surtout lorsqu’il n’y a pas d’éléments structurant qui vous aident à cibler cette catégorie.
S’il y a encore des URLs que vous n’avez pas réussi à classer, nous avons toujours d’autres options, bien que cela dépend des données additionnelles disponibles dans les crawls ou analyses.
Est-ce que vous gardez une liste d’items dans n’importe quelle catégorie spécifique, telle que tous les noms des concerts actuels ou toutes vos landing pages ? Nous pouvons les utiliser avec le data ingestion.
Est-ce que les pages dans certaines catégories contiennent un balisage spécifique sur la page en elle-même, telle que la présence d’une entité schema.org particulière, d’un ID de catégorie dans le header, ou même d’indications des traductions de page ? Nous pouvons réutiliser le balisage de cette page lorsque nous la crawlons et le mettre à contribution.
Une fois que nous avons trouvé un moyen de définir chaque catégorie, nous pouvons aussi définir les règles pour créer des groupes de pages selon l’analyse de vos URLs.
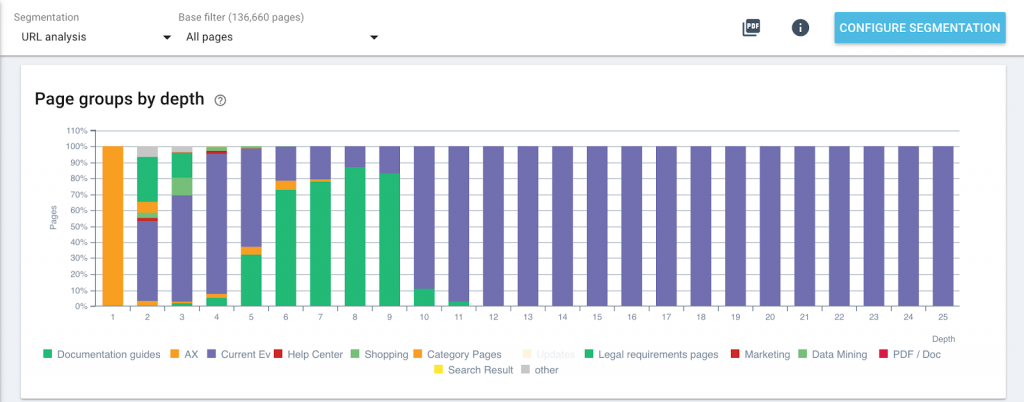
Essayez à la maison : exemple de règles de groupes de pages
Vous pouvez essayer vous même sans aucun risque pour vos données, quotas ou vos segmentations et analyses actuelles. En créant une nouvelle segmentation, vous ajoutez la capacité de passer à une nouvelle catégorisation de vos pages lorsque vous analysez un rapport de crawl. Cela n’a pas d’impact sur les données en elles-mêmes.
Vous pouvez être avantagé si vous êtes familier avec regex (expressions régulières). Vous pouvez également demander de l’aide à notre équipe de CSM expérimentés ou garder ouvert notre article sur le Lucene regex dans un autre onglet.
Dans l’application Oncrawl, ouvrez votre projet, cliquez sur “+ Create segmentation “ et choisissez de créer des groupes de pages “From scratch”.
Pour chaque groupe de catégories, nous allons créer un groupe de pages en cliquant sur “+Create page group » et définir une règle qui décrit ce que nous savons sur les URLs de cette catégorie. Voici quelques exemples.
Pour une catégorie “news” avec des mots-clés spécifiques dans l’URL :
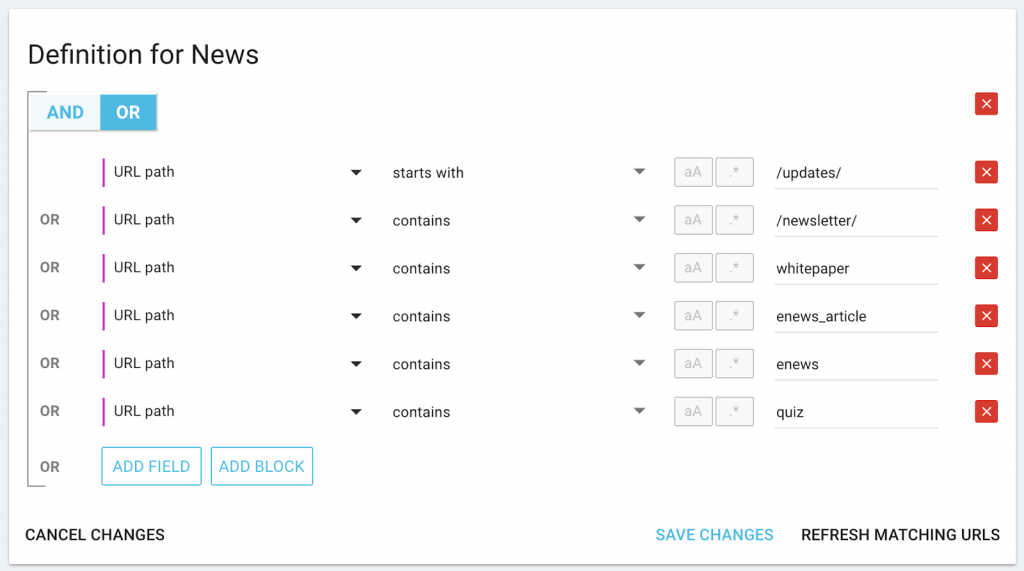
N’oubliez pas : vous pouvez utiliser “starts with” si le mot-clé apparaît toujours au début (ou “ends with” s’il apparaît toujours à la fin) de l’URL.
Pour les catégories avec des structures spécifiques, comme les villes et les combinaisons d’ID (« SanDiego-406VR ») au début de l’URL :
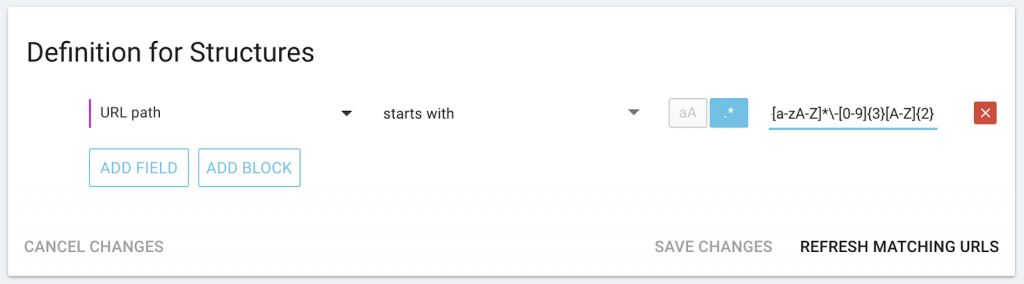
Pour les catégories avec une liste limitée d’items qui doivent apparaître quelque part dans l’URL :
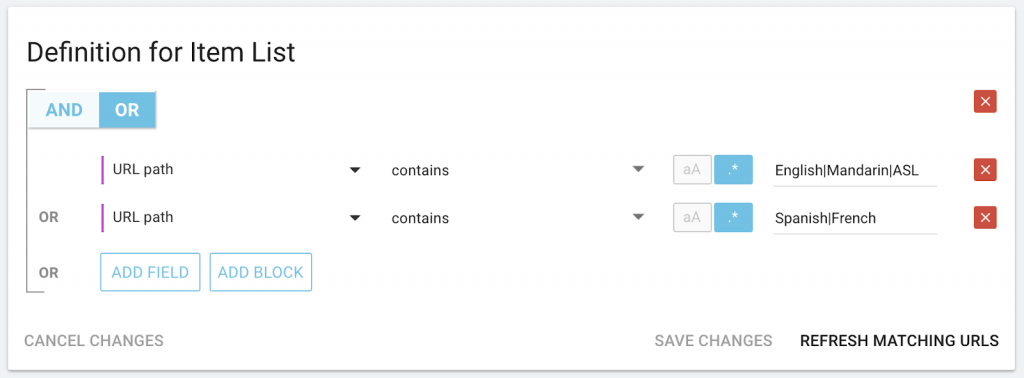
Pour les catégories basées sur des listes externes ou des données scrapées, dans ce cas, le nom du concert :
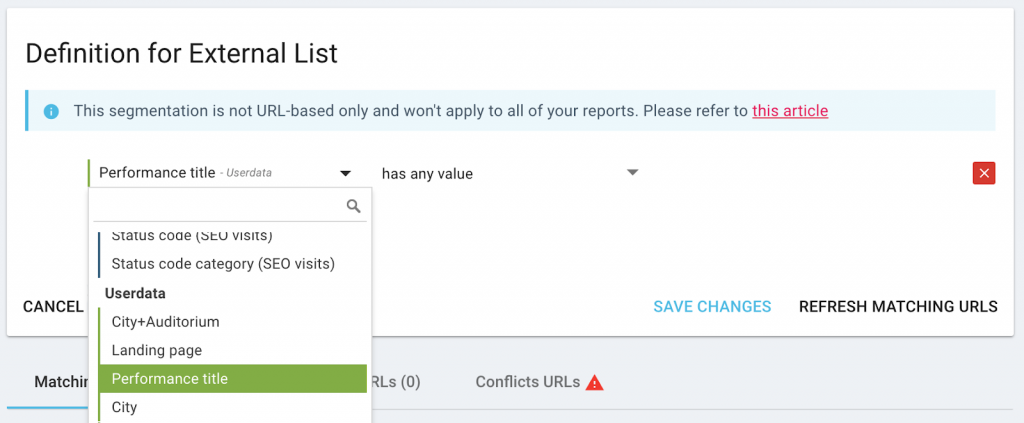
(Vous devrez lancer un crawl qui inclue ou scrape ces données avant de créer le groupe de pages).
À vous de rendre vos résultats d’audit parlant !
Continuez de chercher une segmentation logique pour votre site, même si vous ne pouvez pas obtenir des informations utiles des segmentations par défaut basées sur des sous répertoires.
Des stratégies créatives basées sur des caractéristiques d’URL, ou n’importe quelles autres caractéristiques de page, peut vous aider à filtrer vos pages dans les bonnes catégories pour obtenir une vue générale impactante des résultats de vos analyses.
