
Le webinaire Créer du contenu fondé sur des entités qui génère des conversions fait partie de la série SEO in Orbit et a été diffusé le 15 mai 2019. Pour cette épisode, l’ambassadeur Oncrawl Murat Yatağan et JP Sherman se sont intéressés à la question de la création de contenu compris par les machines afin d’améliorer les classements, le CTR et les conversions. Rejoignez-nous pour recevoir des insights sur la la construction de contenu pour le SEO en 2019.
SEO in Orbit est la première série à envoyer le SEO dans l’espace. Tout au long de la série, nous avons débattu sur le présent et le futur du SEO technique avec certains des experts les plus qualifiés et avons envoyé leurs meilleurs conseils dans l’espace le 27 juin 2019.
Regardez le replay ici :
Présentation de JP Sherman
JP Sherman est un vétéran du search avec plus de 10 ans d’expérience dans la Findability et la Competitive Intelligence. Il travaille en tant qu’expert Search & Findability pour Red Hat Customer Portal. Sa mission est de créer une passerelle entre des dizaines de milliers de documents techniques et supports et les clients qui les recherchent dans Google et dans la recherche interne de Red Hat. Il dispose d’un talent naturel pour connecter les données, le comportement et le search et findability pour apporter des changements actionnables et utiles aux studios Paramount, Skechers, Performance Bike, Dewalt et bien d’autres.
Vous pouvez le trouver sur Twitter à @jpsherman où il aime parler magasins, de tout et rien et d’autres projets geek.
Cet épisode a été animé par Murat Yatağan, un consultant SEO avec plus de 9 ans d’expertise en SEO et UX dont 5 ans en tant que Senior Product Analyst chez Google Search Quality (= Trust & Safety) en Irlande. Au cours de sa carrière de consultant, il a construit une expertise sur le SEO technique, les stratégies de création de contenu de haute qualité, l’outreach et le SEO international en gérant une équipe de plus de 65 clients internationaux évoluant dans différents secteurs.
Qu’est-ce que les entités ?
Pour faire simple, les entités sont des choses qui ont des attributs. Par exemple, un chien a des attributs comme des jambes, un coeur… Lorsque vous cherchez dans les entités, ce sont les attributs qui vont réellement définir et différencier les choses décrites comme entités.
Ce ne sont pas toujours des concepts. Les marques peuvent aussi être des entités à cause de leur association avec des produits et d’autres “choses”.
Ce qui rend les entités intéressantes, ce que les attributs sont partagés. Un chien et un chat ont partagé des attributs.
Que sont les données structurées ?
Les données structurées, comme le nom le suggère, sont des informations structurées et organisées sur une page qui aident les moteurs de recherche à comprendre le sujet d’une page. Cela peut aussi aider les visiteurs à comprendre votre site, car avec le front-end, vous utilisez aussi des données structurées pour organiser vos informations : listes, tableaux…
Les moteurs de recherche, à l’inverse des visiteurs humains, utilisent des knowledge graphs basés sur les entités et définissent des relations entre les entités.
Par exemple, Google utilise les données structurés pour créer de nouveaux éléments dans les résultats de recherche, comme les page Q&A et FAQ. Plus généralement, ceux-ci sont connus sous le nom de rich results. Ils peuvent vous donner un avantage dans les résultats de recherche en rendant vos résultats plus importants dans les pages de résultat, parmi d’autres avantages.
Qu’est-ce que Schema.org ?
Schema.org est un standard développé par un consortium entre les principaux moteurs de recherche comme Google, Bing, Yahoo!, Yandex et d’autres. Il s’agit d’une définition sur la manière de construire des données structurées afin que les moteurs de recherche les comprennent.
Ceux-ci fournissent des règles structurées de codage à utiliser. Le standard complet est disponible sur le site web du projet Schema.org, ou vous pourrez trouver tous les détails et de l’aide pour vous accompagner sur les types de balisage comme JSON-LD.
Les contraintes biologiques sur la manière dont les personnes font des recherches
Il existe des contraintes biologiques qui pèsent sur la manière dont les personnes font leur recherche. C’est essentiellement une réponse en deux temps sur comment les internautes accèdent à l’information puis sur comment ils reconnaissent et suivent cette information pour rencontrer une intention de recherche.
Accessiblité
La première partie des contraintes biologiques sur le search est l’accessibilité. Physiquement, tout le monde ne consomme pas l’information de la même manière. Un exemple basique : tout le monde ne voit pas les couleurs de la même manière.
L’audience search dispose de nombreuses variations sur la manière dont elle consomme l’information. Donc des choses comme la taille du texte, la couleur ou la localisation sont extrêmement importants pour l’idée de trouvabilité ou pour la manière dont les personnes peuvent accéder aux résultats.
Google a sous entendu qu’il existait d’importantes corrélations, mais pas forcément des causes à effet, entre les classements et l’accessibilité de votre site. Cela revient au E-A-T (Expertise, Authority et Trust) dont Marie Haynes a beaucoup parlé récemment. Plus votre site est accessible, plus vous gagnerez en autorité et confiance.
Comportement de « recherche de schémas »
La seconde partie des contraintes biologiques dans le search est que les humains sont essentiellement des animaux à la recherche de schémas. Nous voyons des schémas lorsqu’il n’y a pas de schémas.
[Étude de cas] Améliorer les classements, visites organiques et ventes avec l’analyse des fichiers de log

Par exemple, prenons la phénomène de paréidolie : les humains voient des schémas là ou il n’y en a pas, comme le fait de voir un visage dans l’écorce d’un arbre.
En réalité, nous recherchons des données, et dans ces données, nous recherchons des schémas. Nous ne reconnaissons pas seulement les schémas, nous sommes aussi constamment à leur recherche.
Lorsqu’il s’agit du search, il y a des concepts et des aspects biologiques concernant la manière dont les humains interagissent avec leur environnement ou même une page web, qui s’appliquent au search. La manière dont les internautes scannent et reconnaissent l’information est plutôt prédictible.
Comme les entités sont des choses reconnaissables, elles peuvent être interprétées comme des signaux de schémas. Quelqu’un qui cherche des informations et qui tombe sur “Batman” par exemple, va subitement penser à des associations déjà construites autour de cette entité :
- Un endroit
- Des amis
- Des ennemis
- Des films
- Des media
- Etc…
Tout cela devient la reconnaissance d’entité. Lorsqu’un utilisateur reconnaît quelque chose comme une entité, cela crée ce qu’on appelle une “information scent trail”. Cela signifie que l’utilisateur commence à se concentrer sur l’entité pour voir si oui ou non il y a une relation avec ce qu’il recherche, ce qui correspond par essence à l’intention de recherche.
Une grande partie du comportement de recherche des humains est basée sur la reconnaissance d’entité d’une perspective humaine et sur la reconnaissance d’un schéma à travers la recherche de schémas.
Avant que le machine learning soit en vogue, Murat a travaillé sur les réseaux de neurones. Il pense qu’une meilleure compréhension de la manière dont les humains recherchent et reconnaissent les informations est très utile pour les recherches qui établissent la manière dont les machines réalisent et facilitent des tâches similaires.
Évolutions récentes dans les moteurs de recherche
Il y a eu de nombreuses évolutions dans les technologies des moteurs de recherche : recherches neuronales, traitement du langage naturel , meilleure compréhension du contenu et des requêtes et la lutte contre les spams. Une partie de cela est due au nombre élevé de recherches nouvelles qui n’ont jamais été enregistrées auparavant par Google.
Certaines évolutions ont un grand impact sur la manière dont nous trouvons l’information; il y a eu un nombre significatif de changements menés par Google qui ont influencé les idées de recherche et de trouvabilité.
Comprendre les individus et leur schémas
Les moteurs de recherche ont fait de grands progrès dans la compréhension de chaque utilisateur du search et leurs schémas de comportement de recherche.
Par exemple, lorsque JP part au travail le matin, Google l’informe qu’il va lui falloir 10 minutes pour récupérer son café favori, même s’il n’y pas d’interaction digitale avec le-dit café, mais son “téléphone” sait qu’il s’arrête toujours ici. Il s’agit d’un exemple de fonctionnalité learning “non-input”.
Le fait est que la capacité de Google à comprendre le contexte de manière prévisible et diffusable leur permet de présenter des résultats avant que l’internaute ne formule une requête de recherche. Cela permet à Google de fournir des informations non-interruptives.
Prise en compte du contexte
Dawn Anderson, qui fait partie des personnes les plus investies dans les domaines de l’extraction d’information SEO et la trouvabilité, a récemment cité le linguiste John Firth, affirmant que vous pouvez savoir ce qu’un mot signifie rien qu’en regardant son « entourage ».

Cela est vrai lorsqu’il s’agit de reconnaissance d’entité et de mots-clés. Dans le passé, et les habitudes persistent dans certains domaines du SEO, nous tendions à traiter les mots-clés comme un sac de mots sans contexte. Trop de SEOs se sont concentrés sur cette tactique. Mais en même temps que les algorithmes des moteurs de recherche commencent à contextualiser les mots et recherches, il est nécessaire de comprendre que les mots ont bien plus de sens dans le contexte :
- Les mots sont associés avec d’autres mots
- Les mots sont associés avec des entités
- Les mots peuvent être contextualisés à travers la localisation mobile
- Les mots peuvent être contextualisés à travers les précédentes visites
Cela signifie que les recherche de JP, par exemple, vont être très différentes de celles d’une autre personne car le contexte est très différent.
Appliqué au SEO, JP donne l’exemple de la manière dont il faisait du SEO pour une grande entreprise online de vélos. Le même mot-clé [pneus de vélo] a un sens différent à Colorado Springs et à Los Angeles. À Colorado Springs, l’intention est généralement concentrée sur les pneus pour les VTT. À LA, ce sont plutôt des pneus pour les vélos de route. Cependant, le mot-clé en lui-même est exactement le même : [pneus de vélo].
Comprendre que le même mot-clé peut avoir d’intentions divergentes au sein de groupes d’utilisateurs en fonction du contexte (dans ce cas : la localisation) a été incroyablement important dans le développement du contenu, du SEO et dans la manière de trouver le déclic au niveau émotionnel pour obtenir le clic de l’utilisateur depuis les SERPs.
Optimisation du positionnement dans les SERPs et du CTR
JP raconte ce qu’il a réalisé avec cette entreprise :
Le site n’avait jamais été positionné pour le mot clé [vélos de route]. JP a examiné les SERPs et s’est rendu compte que les titres des meilleurs résultats étaient structurés de la même façon : « Vélos de route – Marque » ou « Vélos de route | Marque ». JP trouvait que ce format n’était pas très intéressant d’un point de vue search.
Il n’a modifié que la balise titre de la page de l’entreprise portant sur les vélos de route à « Vélos légers et rapides pour la route ouverte ». Ce changement a mené à l’idée que ce qu’il faut optimiser dans le SEO est l’intention de recherche et l’émotion.
N’oubliez pas qu’un utilisateur passe typiquement moins d’une seconde à regarder chaque résultat. Il faut capturer l’attention et lui donner une impression immédiate de la valeur de votre site. Lorsqu’un utilisateur voit « Vélos de route – Marque » versus « Vélos légers et rapides pour la route ouverte » (ou, pour les vélos d’enfant, « Vélos d’enfant robustes et de bon rapport qualité-prix »), ce dernier marque un point parce qu’il remonte deux soucis principaux. Optimiser pour l’émotion et l’intention offre reconnaissance immédiate de valeur à partir des SERPs.
Plutôt que travailler sur le nombre de mots clés, JP a pu optimiser le taux de clic en utilisant les bons mots pour cibler la bonne intention. Le résultat ? Le site web se positionnait mieux que les grands surfaces et les franchises de sport comme REI, Target ou Walmart sur des mots clés pour lesquels il n’a jamais été positionné auparavant.
JP est de l’avis que la bataille SEO du futur se jouera sur les SERPs pour gagner cette reconnaissance immédiate de valeur. Cela aide à rapprocher les positions 1 et 4 si vous pouvez y démontrer, de façon immédiate et avec des mots, la valeur offerte par votre contenu.
Différence entre positionner une page avec la correspondance neurale et avec les mots clés
Il est important de se rappeler que Google évolue : Google ne regarde pas seulement le sujet de votre page et la fréquence des mots clés. Google possède également des équipes entières d’ingénieurs qui travaillent sur le fonctionnement du cerveau humain et sur comment Google peut satisfaire les intentions à l’origine des recherches des utilisateurs humains.
Cela veut dire que le type de contenu qui peut être positionné pour un mot clé tiré du sac de mots sans contexte n’est pas pareil que le contenu qui peut être positionné avec les algorithmes de correspondance neurale de Google.
Déclenchement des réseaux neuraux pour les intentions de recherche
Sachant qu’il ne travaille pas pour Google et donc ne connaît pas intimement leurs algorithmes, JP constate à partir des ses propres observations et expériences, qu’il faut qu’il y ait un élément déclencheur pour permettre aux réseaux neuraux de reconnaître le niveau de contexte et les entités.
Par exemple, si un utilisateur recherche [chaussures rouges], il ne s’agit pas d’une entité. L’utilisateur est probablement dans une mentalité e-commerce. JP estime qu’il y a un facteur de connaissance du mot clé qui mène à une hypothèse à haut niveau sur ce que l’utilisateur recherche : est-ce qu’il recherche des informations ? Est-ce qu’il a l’intention de réaliser un achat ?
Quant à la requête [chaussures rouges], l’algorithme est beaucoup plus direct et beaucoup plus discret.
Utilisation par Google des entités pour comprendre les requêtes
Par contre, une requête comme [comment nettoyer une moquette après un dégât des eaux] or [filme qui est une parodie de Star Wars] (en anglais : [movie that makes fun of Star Wars]) offre plusieurs notions contextuelles que Google doit interpréter. Dans le cas de la deuxième requête, la première réponse sur Google est La folle histoire de l’espace (en anglais : Spaceballs).
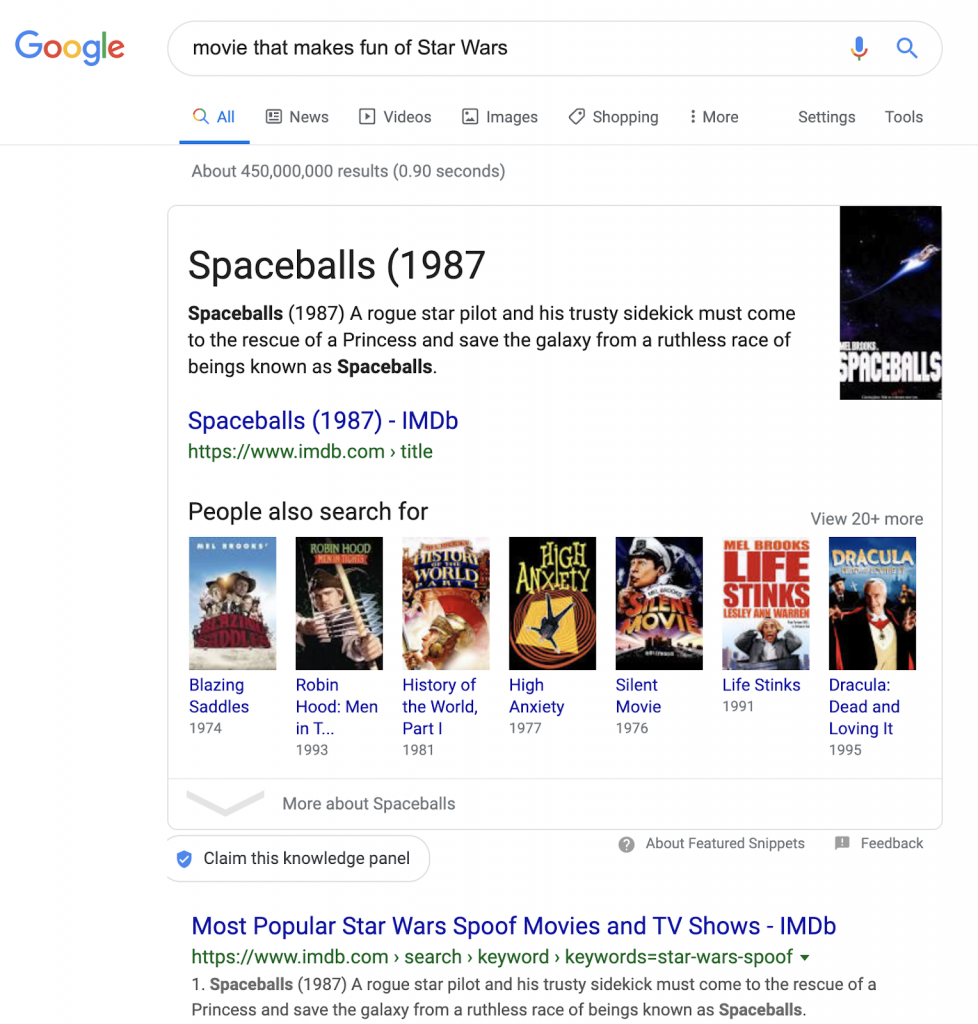
Pour produire ce résultat, Google doit comprendre :
- Filme (un type de média)
- « Être une parodie » (pas la chose en soi, mais quelque chose comme la chose)
- Star Wars
Lorsque quelqu’un recherche [movie that makes fun of Star Wars], Google est capable de comprendre qu’il recherche un filme qui n’est pas Star Wars.
Dans d’autres moteurs de recherche, vous tombez toujours sur du contenu Star Wars–mais sur Google, vous trouvez Spaceballs.
Pour JP, c’est une indice que Google réalise du parsing à haut niveau ainsi que de la reconnaissance de requête à haut niveau, et que Google est capable de traiter des synonymes hautement nuancés qui peuvent modifier le résultat.
Knowledge Graph
Il y a plusieurs années, Google a introduit son Knowledge Graph, construit à partir d’informations tirées de Wikipédia et d’autres sources.
Relations horizontales entre les entités qui partagent des attributs
Ce qui caractérise un knowledge graph est la création d’une couche horizontale d’attributs partagés, grâce aux données fournies par les entités et le markup Schema.org.
Les baleines, les êtres humains, les gorilles, et même les chauve-souris : presque tous les mammifères possèdent cinq doigts de trois os. C’est un exemple d’un attribut partagé par plusieurs entités. Le markup structuré a fourni à Google un moyen d’accéder à ce type de relation horizontale entre des entités différentes.
Remplir les espaces vides dans les templates
Les knowledge graph sélectionnaient les informations à inclure : il existait un algorithme conçu pour rechercher sur Google les informations manquantes selon les modèles des entités. Par exemple, s’il n’y avait pas de date de naissance dans le Knowledge Graph de Google pour Morgan Freeman, le programme chercherait sur Google pour déterminer par consensus la date la plus probable pour la naissance de Morgan Freeman, afin de remplir le modèle pour l’entité type Personnes/Comédiens connus.
Encodage structuré et apprentissage automatique
Le type d’apprentissage dont JP a parlé ci-dessus est facilité par l’encodage structuré. JP aime dire que l’encodage structuré est la nourriture du machine learning.
Le machine learning, malgré ce que l’on pourrait penser, ne fonctionne que s’il est nourri. Il a besoin de consommer des données.
Le conseil de JP ? Si vous vous apprêtez à acheter un produit qui intègre le machine learning, vous devrez également évaluer les données qui seront à sa disposition. Vérifiez donc les données disponibles sur votre site. Qu’est-ce que la machine va « consommer » ? Lorsqu’il y a peu de données ou peu de qualité, les améliorations qui peuvent être conseillées par l’outil n’auront que peu d’effet.
Dans l’expérience de Murat, le type de données consommées lors du développement des algorithmes de machine learning est essentiel. Les ingénieurs prennent en compte des questions comme : est-ce que les signaux sont assez convergents ? Est-ce que l’ensemble des données est cohérent ? Est-ce que les résultats sont fiables ? Les entrées de basse qualité dans le machine learning réduisent la qualité des résultats.
Encodage structuré pour attirer l’attention des moteurs de recherche sur le contenu
Le niveau de visibilité que vous fournissez à votre site web avec les données structurées est très important. Si vous pouvez transmettre aux moteurs de recherche les bons signaux concernant la thématique de votre contenu, l’effet peut être important.
Par contre, si vous transmettez des données ambigües ou peu propres, via une implémentation désordonnée des données structurées, vous n’obtiendrez pas les même résultats. Vos données ne seront pas très utiles aux moteurs de recherche.
Featured snippets
Google reconnaît beaucoup de types de structure de contenu et ils utilisent la structure du contenu afin de créer non seulement des rich snippets mais également les featured snippets.
Présenter les informations de façon claire et simple
JP aime utiliser la métaphore d’AJ Kohn au sujet de l’intelligence de Google : Google est comme un enfant doué de 5 ans. Il est intelligent, mais aussi un peu paresseux, et très limité dans sa compréhension du monde.
Lorsque vous essayez d’attirer l’attention de Google afin d’obtenir un featured snipped, vous devez expliquer votre contenu de façon claire et simple.
Renforcer le contenu avec une structure et de l’encodage structuré
Renforcez vos explications claires avec de la structure, par exemple une liste ordonnée.
Eric Enge, de Stone Temple (désormais Proficient Digital) a réalisé beaucoup d’études sur les featured snippets et comment en obtenir. Voici les conseils principaux :
- Répondre à une question de façon claire et concise
- Organisez votre réponse d’une manière à faire apparaître immédiatement sa valeur
- Renforcez-la avec du markup structuré (non obligatoire, mais très utile)
En ce qui concerne l’encodage structuré, son utilité n’est pas dû à la capacité de décrocher un featured snippet (il ne le fait pas), mais au fait que Google obtient une meilleure compréhension de l’idée ou de l’entité. Ainsi, Google peut plus facilement associer le contenu de votre page comme réponse idéale à une requête de recherche spécifique.
Rapidité de compréhension
L’idée globale que JP souhaite promouvoir est celle de la vitesse. Il faut qu’un être humain puisse comprendre votre sujet en moins d’une seconde. Si vous le faites, vous créez la trace informationnelle nécessaire pour qu’il puisse le suivre. En effet, l’utilisateur suit les informations parce que vous avez réussi à lui fournir une donnée qui corresponde à ce qu’il recherche.
D’un point de vue stratégique, cela veut dire que se concentrer sur l’optimisation du taux de clic apporte beaucoup de bénéfices.
Utilisation dans les recherches vocales et dans des nouvelles fonctionnalités Google
Les données structurées aident également au fonctionnement de la recherche vocale et d’autres technologies similaires à fournir aux utilisateurs les informations pertinentes. Cela évite que la recherche vocale offre des descriptions et titres non-optimisées qui n’ont sûrement pas été rédigés d’une façon optimale.
Il existe aussi des indices qui montrent que les données structures jouent une rôle dans les nouvelles fonctionnalités annoncées par Google et d’autres moteurs de recherche, par exemple Google Discover.
Collaborer avec des personnes intelligentes
L’astuce préférée de JP est de collaborer avec des personnes plus intelligentes que lui. Il n’a pas l’impression d’être un expert, mais il sait qu’il possède une expérience qu’il peut partager. Il a également découvert qu’il y a beaucoup de personnes dans l’industrie qui ont énormément à partager.
Une des compétences les plus importantes est de savoir vous améliorer, et comment en formuler la demande. Cela vous aide à apprendre d’autres personnes qui sont incroyablement douées pour des choses où vous n’avez que des notions, que ce soit Python ou JavaScript ou l’automatisation du reporting quotidien…
Comment Google gère l’intention dans les résultats de recherche
Lorsqu’il s’agit de comment les algorithme gèrent l’intention dans les résultats de recherche, il y a plusieurs idées principales à comprendre. Pour répondre à cette question d’un participant du webinaire, JP détaille quelques-uns des principes qu’il pense être exploités par Google.
Consommation de données historiques
Les données historiques produites par des recherches précédentes et par les comportements précédents peuvent aider Google à établir l’intention de l’utilisateur du search.
Analyse des données sur le comportement utilisateur au niveau de la plateforme
Comme Google est propriétaire de Chrome et d’Android, il est très probable qu’il y puise des informations, même anonymisées. Ces informations seraient exploitées par du data-mining au niveau de la plateforme plutôt qu’au niveau algorithmique. Tant Chrome comme Android transmettraient des données sur le comportement sur leur plateforme : lorsqu’un utilisateur recherche X, il a tendance à graviter vers une telle chose.
Affinage des recherches par mot clé
JP s’intéresse beaucoup à la recherche interne sur un site web, et son expérience dans ce domaine le fait croire que Google prend en compte l’affinement des recherches par mot clé. Si un utilisateur réalise une recherche, puis il revient à faire une recherche à nouveau, est-ce une nouvelle recherche ? Ou est-ce qu’il raffine la recherche initiale parce qu’elle ne lui a pas donnée le résultat qu’il souhaitait ?
Cela implique, du côté de Google, une capacité sophistiquée de traitement de langue qui s’applique à la compréhension des requêtes. Un exemple théorique serait que Google puisse reconnaître la présence d’une entité dans la recherche et savoir qu’un pourcentage très élevé de ses attributs forment une relation horizontale avec les idées dans la recherche initiale. Google pourrait ainsi déduire que la recherche actuelle est un raffinement de la première.
Recherches liées
Comme vous pouvons constater avec les résultats dans les blocs « Autres questions posées », Google travaille aussi sur les recherches liées. Les recherches liées sont intégrées dans la structure naturelle des pages de résultats. Cela peut inviter aux utilisateurs à cliquer sur les recherches conseillées plutôt que raffiner la recherche initiale.
Les recherches liées sont possiblement une solution business pour répondre à la question de l’intention de recherche dans les pages des résultats.
Meilleure recommandation
« Optimiser pour l’intention de recherche et pour l’émotion, et donner une perception immédiate de valeur en moins d’une seconde dans les SERPs. »
SEO in Orbit est parti dans l’espace
Si vous avez manqué notre voyage dans l’espace, découvrez quelles astuces nous avons envoyées le 27 juin dernier.
