
Introduction au rapport de couverture et à l’interprétation de ses données
Le rapport de couverture de la Google Search Console fournit de nombreuses informations sur les pages de votre site qui sont indexées. Il liste également les problèmes rencontrés par le Googlebot lors du crawl et de l’indexation.
La page principale dans le rapport de couverture montre les URLs de votre site groupées par statuts :
- Erreur : la page n’est pas indexée. Il peut y avoir plusieurs explications à cela comme par exemple une page répondant en 404.
- Valide avec avertissement : la page est indexée mais rencontre des problèmes.
- Valide : la page est indexée.
- Exclue : la page n’est pas indexée, Google a suivi les règles de votre site comme les balises noindex dans le robots.txt, les balises meta et canoniques… Ces règles peuvent empêcher les pages d’être indexées.
Ce rapport de couverture fournit bien plus d’informations que celui de l’ancienne Search Console. Google a réellement amélioré les données qu’il partage mais il y a encore certains points qui ont besoin d’amélioration.
Comme vous pouvez le voir ci-dessous, Google montre un graphique avec le nombre d’URLs dans chaque catégorie. S’il y a une augmentation soudaine des erreurs, vous pouvez analyser les données et même les mettre en relation avec les impressions. Cela permettrait de déterminer si une augmentation des URLs en erreur ou des avertissements fait dangereusement chuter vos impressions.

Après le lancement d’un site ou la création de nouvelles sections, vous devriez voir apparaître une augmentation du nombre de pages indexées valides. Cela peut prendre quelques jours avant que Google indexe de nouvelles pages mais vous pouvez utiliser l’URL inspection tool pour demander une indexation et réduire le temps que Google met à trouver votre nouvelle page.

Cependant, si voyez le nombre d’URLs valides décliner ou des pics soudains apparaître, il est important d’identifier les URLs dans la section “Erreurs” et de réparer les erreurs listées dans le rapport.
Google fournit un bon résumé d’actions à mettre en place lorsqu’il y a des augmentations d’erreurs ou d’avertissements.
Google met également à votre disposition des informations à propos des erreurs et du nombre d’URLs concernées :

Rappelez-vous que la Google Search Console ne montre pas des informations 100 % fiables. En réalité, il y a eu plusieurs rapports à propos de bugs ou d’anomalies de données. De plus, la Google Search Console, met un certain temps avant de se mettre à jour. Certaines données datent de 16 à 20 jours.
Parfois, la Google Search Console montre des listes de plus de 1000 URLs en erreur ou en avertissement comme vous pouvez le voir sur l’image ci-dessous. Mais vous ne pouvez voir ou télécharger qu’un échantillon de 1000 URLs, pas plus.
Cependant, il s’agit tout de même d’un très bon outil pour identifier les problèmes d’indexation sur votre site.
Lorsque vous cliquez sur une erreur spécifique, vous pouvez voir la page détails qui montre des exemples d’URLs concernées :

L’image ci-dessus montre la page détails pour toutes les URLs répondant en 404. Chaque rapport dispose d’un lien “En savoir plus” qui renvoie à la documentation de Google fournissant des détails à propos d’une erreur spécifique. Google fournit aussi des graphiques qui montre le nombre de pages affectées au fil du temps.
Vous pouvez cliquer sur chaque URL afin de l’inspecter, ce qui reste similaire à la fonctionnalité “fetch as Googlebot” de l’ancienne Google Search Console. Vous pouvez aussi déterminer si la page est bloquée par votre robots.txt.
Après avoir réparé les URLs, vous pouvez demander à Google de les valider afin que l’erreur disparaisse de votre rapport. Vous devriez réparer les erreurs qui sont en état “échec” ou “non débutée” en priorité.
Il est important de mentionner que vous ne devez pas vous attendre à voir toutes les URLs de votre site indexées. Google a déclaré que l’objectif des webmasters devrait être d’avoir toutes les URLs canoniques indexées. Les pages dupliquées ou alternatives seront catégorisées comme exclues comme leur contenu est similaire à celui de la page canonique.
Il est normal que les sites dispose de pages dans la catégorie “exclues”. La plupart des sites auront plusieurs URLs avec des balises meta noindex ou bloquées via le robots.txt. Lorsque Google identifie une page dupliquée ou alternative, assurez-vous que ces pages ont une balise canonique pointant vers la bonne URL. Essayez également de trouver l’équivalent canonique de la catégorie valide.
Google a inclut un filtre déroulant en haut à gauche du rapport afin que vous puissiez filtrer le rapport pour toutes les pages connues, soumises ou les URLs dans un sitemap spécifique. Le rapport par défaut inclut toutes les pages connues et URLs découvertes par Google. Les pages soumises comprennent toutes les URLs que vous avez rapportées à travers un sitemap. Si vous avez soumis plusieurs sitemaps, vous pouvez filtrer par URLs dans chaque sitemap.
[Étude de cas] Augmenter le budget de crawl sur les pages stratégiques

Erreurs, avertissements et URLs valides et exclues
Erreurs
- Erreur serveur (5xx) : le serveur renvoie une erreur 500 lorsque le Googlebot tente de crawler la page.
- Erreur de redirection : lorsque le Googlebot a crawlé l’URL, il a détecté une erreur de redirection. Cela peut être causé par une chaîne trop longue, une boucle de redirection, des URLs excédant la longueur maximale d’URL ou une URL nulle ou non pertinente dans la chaîne de redirections.
- URL soumise bloquée par le robots.txt : les URLs dans cette liste sont bloquées par votre fichier robots.txt.
- URL soumise marquée en ‘noindex’: les URLs dans cette liste dispose d’une balise ‘noindex’ meta robots ou d’un header HTTP.
- URL soumise qui semble être une Soft 404 : une erreur soft 404 se produit lorsqu’une page qui n’existe pas (a été retirée ou redirigée) diffuse un message ‘page not found’ à l’utilisateur mais ne parvient pas à retourner un status code 404 HTTP. Les soft 404s arrivent aussi lorsque les pages sont redirigées vers des pages non pertinentes. Par exemple, une page redirigeant vers la page d’accueil au lieu de renvoyer un status code 404 ou de rediriger vers une page pertinente.
- URL soumise qui renvoie une requête non autorisée (401) : la page soumise pour indexation renvoie une réponse 401 HTTP non autorisée.
- URL soumise non trouvée (404) : la page renvoie une erreur 404 Not Found lorsque le Googlebot tente de crawler la page.
- URL soumise avec des problèmes de crawl : le Googlebot a détecté une erreur de crawl lors du crawl de ces pages qui ne correspond à aucune des autres catégories. Vous devez vérifier chaque URL et déterminer d’où provient le problème.
Avertissement
- Indexées mais bloquées par le robots.txt : la page a été indexée parce que le Googlebot l’a trouvée grâce à des liens externes pointant vers cette page. Cependant, si la page est bloquée par votre robots.txt, Google marque ces URLs en avertissement car il n’est pas sûr que la page devrait être bloquée. Si vous voulez bloquer une page, vous pouvez utiliser une méta balise ‘noindex’ ou un header de réponse HTTP noindex.
Si Google a raison et que l’URL a été bloquée par erreur, vous devriez mettre à jour votre fichier robots.txt afin d’autoriser Google à crawler la page.
URLs Valides
- Soumises et indexées : les URLs que vous avez soumises à Google à travers le sitemap.xml ont été indexées.
- Indexées, non soumises dans le sitemap : l’URL a été découverte par Google et indexée mais n’a pas été incluse dans votre sitemap. Il est recommandé de mettre à jour votre sitemap et d’inclure chaque page que vous voulez que Google crawle et indexe.
URLs Exclues
- Exclues par balise ‘noindex’ : lorsque Google tente d’indexer la page, il trouve une balise meta robots ‘noindex’ ou un header HTTP.
- Bloquées par l’outil de suppression de page : quelqu’un a demandé à Google de ne pas indexer cette page en utilisant une requête de suppression d’URL dans la Google Search Console. Si vous voulez que cette page soit indexée, connectez-vous à la Google Search Console et retirez la de la liste des pages supprimées.
- Bloquées par le robots.txt : le fichier robots.txt comporte une ligne qui empêche l’URL d’être crawlée. Vous pouvez vérifier quelle ligne est responsable en utilisant le testeur de robots.txt.
- Bloquées à cause d’une requête non autorisée (401) : comme dans la catégorie “erreurs”, ces pages sont retournées avec un header HTTP 401.
- Anomalie de crawl : c’est une catégorie “fourre-tout” qui désigne les URLs répondant avec des codes 4xx ou 5xx. Ces codes de réponse empêchent l’indexation de la page.
- Crawlées – actuellement non indexées : Google n’explique pas pourquoi l’URL n’a pas été indexée. Il suggère de re-soumettre l’URL pour indexation. Cependant, il est important de vérifier si la page dispose de contenu faible ou dupliqué, si elle est canonisée à une autre page, dispose d’une directive noindex, de métriques qui montrent une mauvaise expérience utilisateur, d’un temps de chargement élevé… Il pourrait s’agir de raisons pour lesquelles Google ne veut pas indexer votre page.
- Découvertes, non indexées actuellement : la page a été découverte par Google mais n’est pas encore incluse dans son index. Vous pouvez soumettre l’URL pour indexation pour accélérer le processus comme mentionné ci-dessus. Google a déclaré que cela est souvent dû à une surcharge du site et que le crawl doit être reprogrammé.
- Page alternative avec balise canonique : Google n’a pas indexé cette page car la balise canonique pointe vers une URL différente. Google a suivi la règle canonique et a correctement indexé l’URL canonique. Si vous ne souhaitiez pas que cette page soit indexée, alors il n’y a rien de plus à faire ici.
- Dupliquées sans canonique user-selected : Google a trouvé des dupliqués pour les pages listées dans cette catégorie et aucune n’utilise de balises canoniques. Google a sélectionné une version différente de la balise canonique. Vous devez vérifier ces pages et ajouter une balise canonique pointant vers la bonne URL.
- Dupliquées, Google a choisi une canonique différente de l’utilisateur : les URLs dans cette catégorie ont été découvertes par Google sans une requête de crawl explicite. Google les a trouvées via des liens externes et a déterminé qu’une autre page faisait une meilleure canonique. Google n’a pas indexé ces pages à cause de cette raison. Il recommande de marquer ces URLs comme dupliquées de la canonique.
- Non trouvées (404) : lorsque le Google tente d’accéder à ces pages, elles répondent avec une erreur 404. Google suppose que ces URLs n’ont pas été soumises, elles ont été trouvées grâce à des liens externes pointant vers elles. Il serait judicieux de rediriger ces URLs vers des pages similaires pour tirer profit de l’équité de liens et vous assurer que les utilisateurs atterrissent sur une page pertinente.
- Pages retirées à cause d’une plainte légale : quelqu’un s’est plaint de votre page et a relevé des problèmes légaux comme une violation du copyright. Vous pouvez faire appel de la plainte ici.
- Pages avec redirection : ces URLs sont redirigées et par conséquent exclues.
- Soft 404 : comme expliqué ci-dessus, ces URLs sont exclues car elles répondent avec une 404. Vérifiez les pages et assurez-vous qu’un message ‘not found’ a été paramétré pour apparaître avec le header HTTP 404.
- Dupliquées, URLs soumises mais non sélectionnées en tant que canoniques : cette situation est similaire à la situation “Google choisit une canonique différente que celle de l’utilisateur”. Cependant, les URLs dans cette catégorie ont été soumises par vous-même. Vérifiez vos sitemaps et assurez-vous qu’il n’y a pas de pages dupliquées incluses.
Demandez votre démo personnalisée

Comment utiliser ces données pour améliorer votre site ?
Travaillant au sein d’une agence, j’ai accès à beaucoup de sites différents et à leurs rapports de couverture. J’ai passé du temps à analyser les erreurs que Google rapporte dans les différents catégories.
Il est utile de trouver ces erreurs avec les contenus canoniques et dupliqués. Cependant, vous pouvez parfois tomber sur des anomalies comme celle reportée par @jroakes:
Looks like Google Search Console > URL Inspection > Live Test incorrectly reports all JS and CSS files as Crawl allowed: No: blocked by robots.txt. Test about 20 files across 3 domains. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) July 16, 2019
AJ Koh a également écrit un très bon article peu de temps après que la nouvelle Google Search Console soit sortie. Il y explique que la réelle valeur dans les données est de les utiliser pour dresser un état des lieux de chaque type de contenu sur votre site :
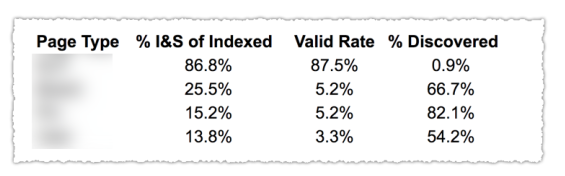
Comme vous pouvez le voir sur l’image ci-dessus, les URLs des différentes catégories dans le rapport de couverture ont été classées par template de page comme le blog, les pages service… Utiliser différents sitemaps pour les différents types d’URL pourrait vous aider car Google vous permet de filtrer les informations de couverture par sitemap. Puis, il a inclut 3 colonnes avec les informations suivantes : % de pages indexées et soumises, Taux d’URLs valides et % de pages découvertes.
Ce tableau fournit un très bon aperçu de la santé de votre site. Si vous souhaitez creuser dans ces sections, je vous recommande de parcourir les rapports et de vérifier à nouveau les erreurs que Google rapporte.
Vous pouvez télécharger toutes les URLs présentes dans différentes catégories et utiliser Oncrawl pour vérifier leur statut HTTPS, balises canoniques… et créer une feuille de calcul comme celle-ci :
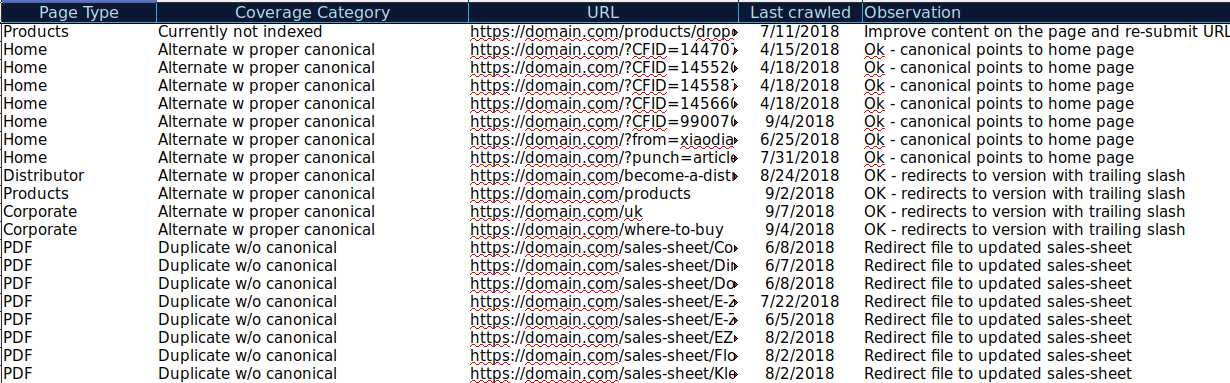
Organiser vos données comme cela peut vous aider à suivre les différents problèmes et à mettre en place des solutions pour les URLs qui ont besoin de réparation ou d’amélioration. Vous pouvez aussi vérifier les URLs qui sont correctes et qui n’ont pas besoin d’améliorations.
Vous pouvez même ajouter plus d’informations dans cette feuille de calcul provenant d’autres sources comme ahrefs, Majestic et Google Analytics avec Oncrawl Integrations. Cela vous permettrait d’extraire les données de lien, de trafic et de conversion pour chacune des URLs dans la Google Search Console.
Toutes ces données peuvent vous aider à prendre de meilleures décisions pour chaque page. Par exemple, si vous avez une liste de pages avec des 404s, vous pouvez les croiser avec vos données de backlinks pour vérifier que vous ne perdez pas d’équité de lien de domaines renvoyant vers des pages cassées de votre site. Ou vous pouvez vérifier les pages indexées et le volume de trafic organique reçu. Vous pourriez identifier les pages indexées qui n’obtiennent pas de trafic organique et travailler sur leur optimisation (améliorer le contenu et l’utilisabilité) pour conduire plus de trafic vers cette page.
Avec ces données supplémentaires, vous pouvez créer un sommaire sur une autre feuille de calcul. Vous pouvez utiliser la formule =COUNTIF (range, criteria) pour compter les URLs sur chaque type de page (ce tableau peut compléter le tableau qu’AJ Khon a suggéré ci-dessus). Vous pourriez aussi utiliser une autre formule pour ajouter des backlinks, visites ou conversions que vous avez extrait de chaque URL et les montrer dans le tableau sommaire avec la formule suivante =SUMIF (range, criteria, [sum_rang]). Vous obtiendrez quelque chose comme ceci :
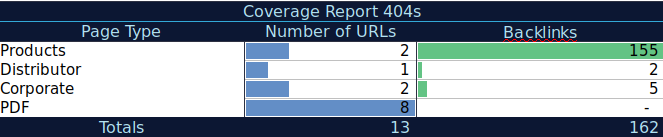
J’aime vraiment travailler avec des tableaux récapitulatifs qui apportent une vue globale des données et peuvent aider à identifier les sections sur lesquelles je dois me concentrer.
Conclusion
Lorsque vous réparez des problèmes et analysez des données dans le rapport de couverture, vous devez penser à : Est-ce que mon site est optimisé pour le crawl ? Est-ce que mes pages indexées et valides augmentent ou diminuent ? Est-ce que les pages avec des erreurs augmentent ou diminuent ? Est-ce que j’autorise Google à passer du temps sur les URLs qui apporteront plus de valeur à mes utilisateurs ou est-ce qu’il trouve trop de pages inutiles ?
Avec ces réponses, vous pourriez déjà commencer à mettre en place des améliorations sur votre site. Le Googlebot pourrait dépenser plus de budget de crawl sur les pages qui peuvent fournir plus de valeur aux utilisateurs au lieu de crawler les pages inutiles. Vous pouvez utiliser le robots.txt pour améliorer l’efficacité du crawl, retirer les URLs inutiles si possible ou utiliser les balises canoniques ou noindex pour éviter le contenu dupliqué.
Google ajoute régulièrement des fonctionnalités et des données mises à jour aux différents rapports de la Google Search Console. Espérons que nous continuerons à voir plus de données dans chacune des catégories du rapport de couverture ainsi que dans les autres rapports de la Google Search Console.
