
La structure d’un site est l’un des leviers SEO les plus efficaces pour les grands sites grâce à sa scalabilité et à sa maniabilité. Mais c’est aussi l’un des outils les plus fragiles en SEO. Comprendre comment l’évaluer et l’optimiser est souvent compliqué et flou. Il n’existe pas vraiment de consensus sur la signification de la structure et son optimisation.
Je vais essayer de changer cela au cours de cet article.
Lorsque nous parlons de “structure de site”, nous parlons de la manière dont les pages et les contenus sont organisés. Mais cela touche de nombreux domaines ! Souvent, la structure du site est confondue avec la “profondeur de clic” qui correspond au nombre de clics depuis la page d’accueil vers une autre page, ou “structure d’URL”. Mais ce ne sont que des parties individuelles de la structure d’un site.
La chaîne complète d’optimisation de la structure contient :
- Le maillage interne
- La taxonomie
- La profondeur de clic
- La structure d’URL
L’objectif est d’optimiser ces 4 facteurs afin d’indiquer à Google et aux utilisateurs où sont les pages les plus importantes, quels sont leurs liens et quel est leur contexte.
L’importance de l’optimisation de la structure de site
La différence entre les jardins français et anglais est une excellente métaphore pour illustrer les éléments qui grandissent de manière ordonnée vs désorganisée.
Lors du 17ème siècle, les jardins français formels étaient très tendances. Le plus célèbre était celui du Château de Versailles. Il était complètement symétrique et organisé, jusqu’au moindre mètre carré.
Au cours du 18ème siècle, les anglais leur ont volé la vedette avec le “English Landscape Garden”, un jardin asymétrique et humain complètement opposé. Les français ont également développé un “French Landscape Garden” au 19ème siècle, qui était similaire et inspiré des “English Landscape Garden”.
La plupart des structures de site grandissent comme les jardins anglais : sauvagement. C’est un inconvénient pour les utilisateurs et les moteurs de recherche qui aiment les structures simples à comprendre. La structure fournit un chemin et un contexte à la fois aux utilisateurs et aux bots.
Les choses tendent à croître “naturellement”. Les plantes ont leur propre structure lorsqu’elles grandissent mais un jardin entier grandit sauvagement et aléatoirement s’il n’est pas entretenu. D’un point de vue extrême, un jardin qui grandit naturellement est une jungle. Vous ne pouvez pas y circuler (sauf à l’aide d’une machette). Il en va de même avec les sites web !

(La structure d’un site devrait être comme un jardin français)
C’est pourquoi vous devriez essayer de reproduire un jardin français avec votre structure de site : organisée, supervisée et entretenue.
L’élément qui va vous permettre de réaliser cela est l’échelle. Les choses à l’état sauvage ne grandissent pas bien mais les structures organisées et optimisées tirent profit de la croissance. Beaucoup de pages dans une bonne structure de site signifie des signaux plus forts pour les moteurs de recherche et une large sélection pour les utilisateurs sans le risque de s’égarer. Donc, plus un site est grand, plus la structure aura d’impact sur la croissance.
[Étude de cas] Optimiser les liens pour favoriser les pages les plus ROIstes

Éléments de la structure de site : maillage interne, taxonomie, profondeur de clic, structure d’URL
Je vais commencer en précisant que je ne vais pas approfondir l’ensemble de ces 4 sujets. Ces éléments sont trop complexes pour que je puisse tout couvrir en un seul article. Au lieu de cela, je vais plutôt expliquer ce qu’ils sont et pourquoi ils sont pertinents dans une structure de site.
Le maillage interne a un fort impact sur la structure de site et consiste en des liens entre des pages d’un site. Il dispose d’une grande influence car il impacte la profondeur de clic, la fréquence de crawl et le “pouvoir des liens” d’une page.
*Je vais utiliser le terme “pouvoir de liens” pour décrire comment une page est liée en interne et en externe. Les autres termes connus sont “l’autorité”, la “force d’une page” ou “l’autorité d’une page”. Je tente d’éviter le terme “PageRank” que je trouve confus comme Google ne l’utilise plus dans ses sources officielles.
John Mueller a mentionné que la structure d’URL est importante car elle permet de fournir du contexte : “Donc nous devrions pouvoir crawler depuis une URL vers une autre sur votre site juste en suivant les liens d’une page. […| Si ce n’est pas possible, alors nous perdons beaucoup de contexte. Si nous ne voyons ces URLs qu’à travers le sitemap, alors nous ne savons pas vraiment comment ces URLs sont liées entre elles et il devient très difficile de comprendre la pertinence de certains éléments dans le contexte de votre site. Il s’agit d’une chose… à surveiller.”
La taxonomie d’un site décrit comment l’information est organisée, par exemple : catégories, sous catégories, balises et d’autres classifications. La manière dont vous organisez votre contenu aide les utilisateurs à trouver les choses plus rapidement et fournit aussi du contexte aux moteurs de recherche.
La relation entre les pages joue un rôle important pour l’optimisation des entités. Si chaque page est une entité, plus vous fournirez d’informations sur cette relation, mieux c’est. La taxonomie est d’une grande aide pour cela car elle crée du contenu sur ces relations.
La profondeur de clic représente le nombre de clics nécessaires depuis la page d’accueil pour aller à une sous page du même site. Est-ce que cela est important ? Oui ! John Mueller a affirmé, que la profondeur de clic, aussi souvent appelée profondeur de page, est plus importante que la structure d’URL pour indiquer l’importance des URLs. Pour Google, moins il y a de clics depuis la page d’accueil vers une sous page, plus cette sous page sera présumée comme importante.
La structure d’URL est un label pour les éléments structurels d’une URL comme les sous-domaines, redirections et sous redirections. Cela aide Google avec l’indexation et joue un rôle sémantique. Par exemple, cela permet de clarifier les relations entre les pages.
I’ve seen that happen when a site has a hard-to-understand URL structure, with many URLs leading to the same content, making our systems assume that a part of the URL is irrelevant.
— ???? John ???? (@JohnMu) December 28, 2018
Vous devriez maintenant mieux comprendre comment ces 4 éléments s’articulent entre eux et pourquoi est-ce qu’ils sont si souvent mixés. Un changement dans la taxonomie, peut par exemple amener à des changements dans l’URL et le maillage interne, ce qui va probablement impacter la profondeur de clic. Cependant, ils ne sont pas identiques. Il est important de connaître les éléments différenciants.
Comment auditer les faiblesses d’une structure de site ?
Nous venons de répondre au “Pourquoi”, intéressons-nous maintenant au “Comment” et “Quoi”.
Vous contrôlez certainement les crawls et fichiers de log de votre site au moins une fois par semaine (ou une fois par jour, si vous avez des TOC comme moi). Mais un audit intégral de la structure d’un site prend du temps. La meilleure fréquence est une fois par trimestre, à moins que vous opériez une migration ou lancement ou que vous expérimentiez une chute du trafic entre temps.
Pour auditer la structure de votre site, vous aurez besoin d’un crawler, au moins. Le mieux est d’avoir un outil qui permet d’analyser les fichiers de log et de les comparer avec les données de la Search Console et/ou de l’outil web analytics de votre choix.
L’objectif est d’obtenir la meilleure compréhension possible de la manière dont les utilisateurs utilisent votre site et de comment les moteurs de recherche le crawlent. Les fichiers de log sont la meilleure source pour comprendre ce que font les moteurs de recherche sur votre site et les données web analytics vous montrent comment se comportent vos utilisateurs. Combiner ces deux sources est donc un outil de suivi puissant pour estimer les effets des changements dans la structure.
La grande question est : Comment auditer votre site ? Pour commencer, vous devez comprendre les informations à rechercher. Nous pouvons répartir les problèmes dans les 4 cas d’usage mentionnés précédemment.
Maillage interne
J’aimerai débuter cette section en rappelant que le maillage interne varie en fonction de votre business model. Tout le monde ne doit pas optimiser son maillage interne de la même manière. Il est important de prendre en compte si vous avez un point de conversion ou bien plusieurs.
Ceci étant dit, je vois 4 erreurs communes avec le maillage interne :
Les pages avec trop de liens sortants. Recherchez les pages (ou mieux, les templates de page) qui ont trop de liens internes sortants et pas assez de liens entrants. Selon mon expérience, ces pages souffrent souvent d’un CheiRank trop élevé et d’un PageRank trop faible, c’est-à-dire qu’elles donnent trop de pouvoir de liens et n’en reçoivent pas suffisamment en échange.
Quand le nombre de liens devient-il excessif ? Il n’y a pas de nombre magique. Appuyez-vous sur la moyenne de votre site ! Analysez le nombre moyen de liens sortants par template de page et observez si l’un d’entre eux est significativement élevé. Si c’est le cas, penchez-vous de plus près sur les liens sortants et essayez d’en retirer quelques uns.
Vérifiez aussi le taux de liens sortants par rapport aux liens entrants et à l’importance et la performance de la page. Si celle-ci est importante pour le business et qu’elle ne performe pas assez bien, les liens entrants vs. sortants pourraient être un facteur.
Les page importantes avec trop peu de liens entrants. De la même manière, vous devriez analyser les pages importantes de votre business afin de vous assurer qu’elles disposent de suffisamment de liens entrants. Vous pouvez faire cela avec un crawl.
Une véritable représentation du pouvoir des liens internes est issue de l’affacturage des backlinks lors du calcul des liens internes. C’est l’idée que je promeut avec le modèle T.I.P.R. Mais pour les débutants, analysez les liens entrants devrait suffire.
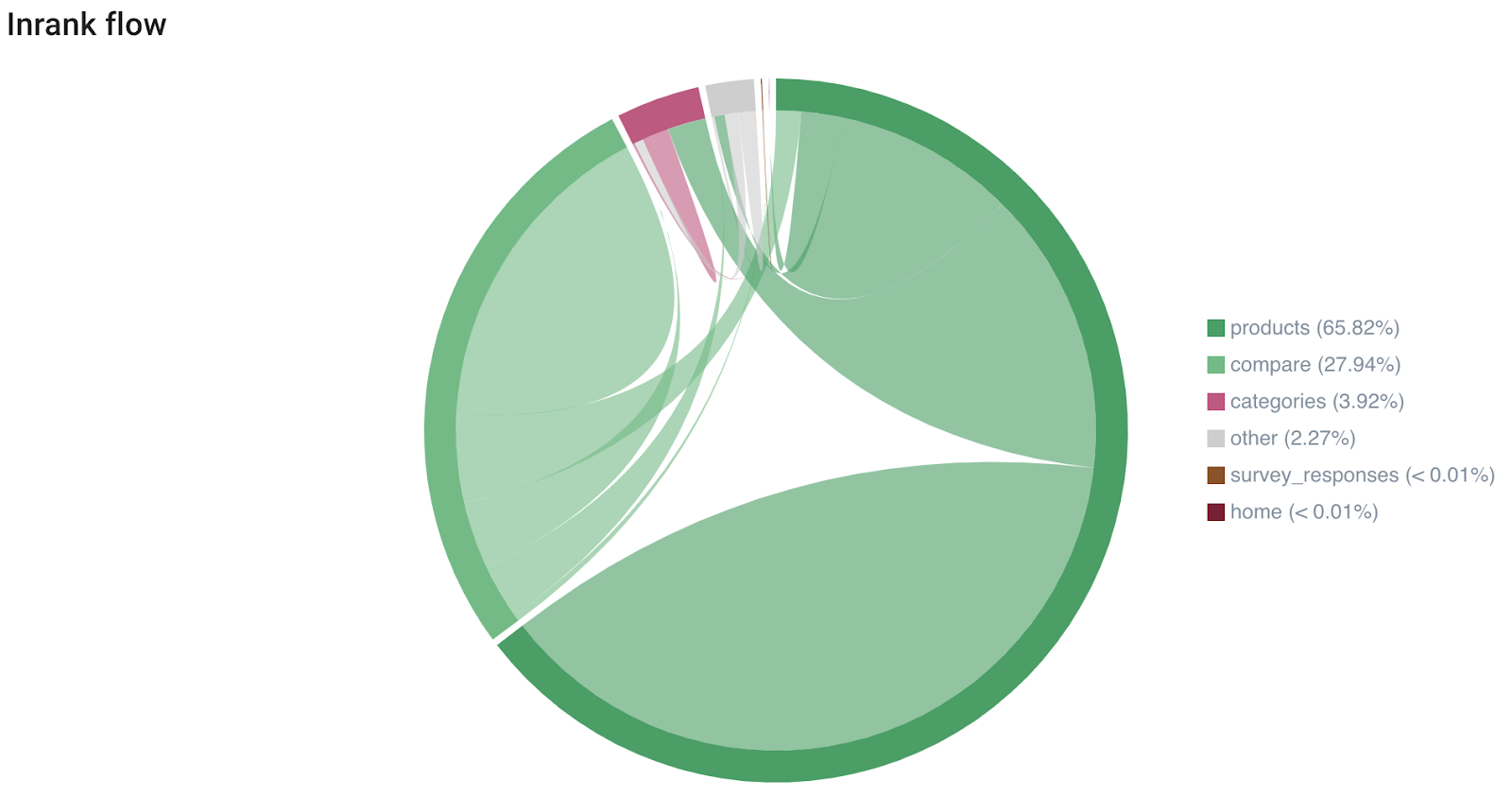
(Le graphique d’Inrank Flow d’Oncrawl vous aide à comprendre quels types de pages sont les plus liées entre elles)
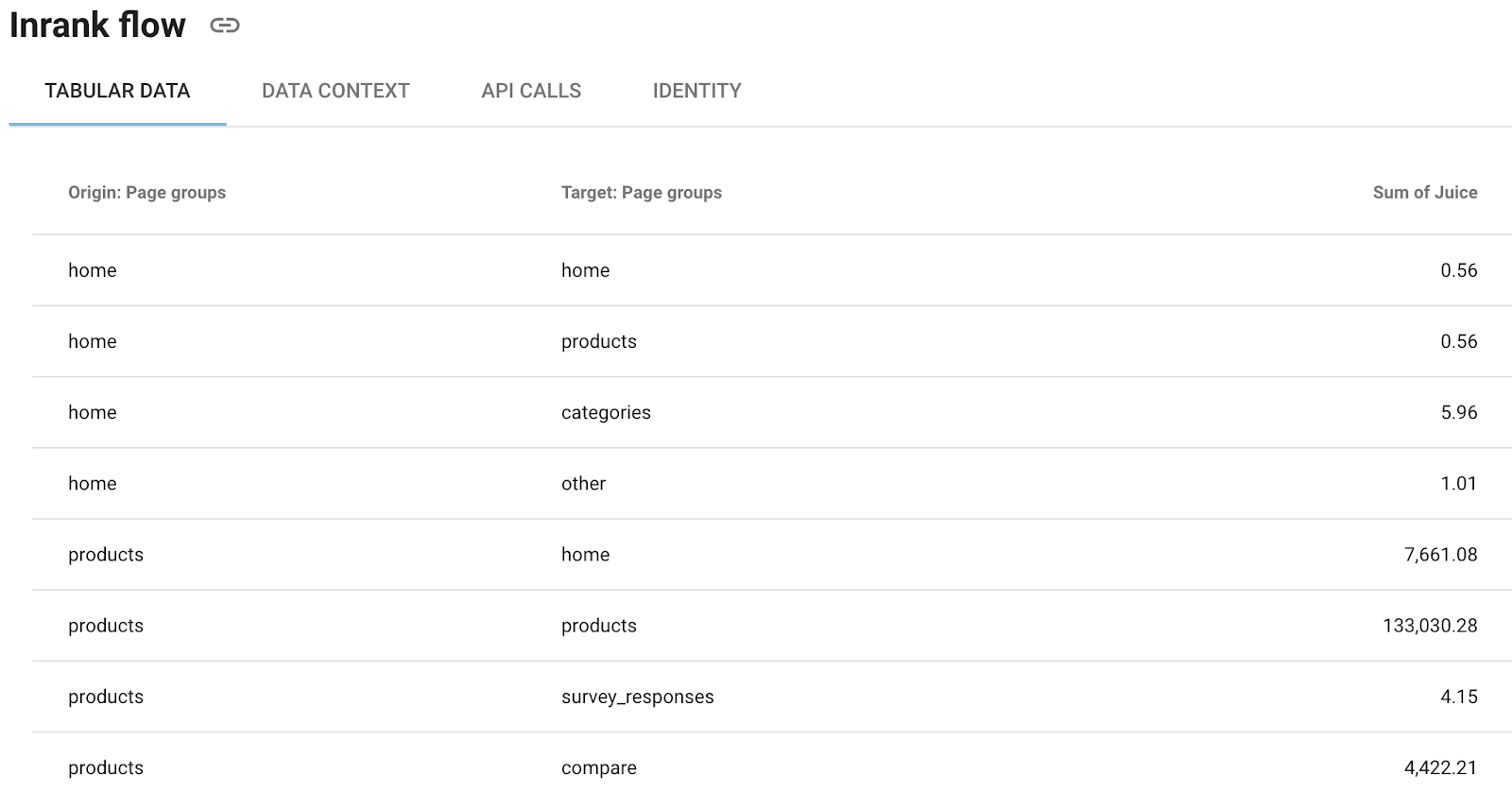
(Vous pouvez aussi obtenir les données brutes dans Oncrawl et les copier/coller dans une feuille de calcul ou les télécharger en CSV)
Les pages importantes ne sont pas crawlées assez souvent. Le taux de crawl, c’est-à-dire la fréquence à laquelle Google crawle une page, est un indicateur significatif de l’importance d’une page perçue par Google. Donc, lorsque vous analysez la structure d’un site, observez les fichiers de log et vérifiez à quelle fréquence une page est crawlée par rapport aux liens entrants et sortants. Google s’est longtemps appuyé sur le PageRank (où ce qu’ils utilisent actuellement) pour décider ce qu’il fallait crawler et à quelle fréquence. Il y a donc une corrélation notable entre la fréquence de crawl et les classements. Si vous vous rendez compte que des pages importantes sont crawlées moins souvent que d’autres, vous devriez augmenter le nombre de liens internes pointant vers elles.
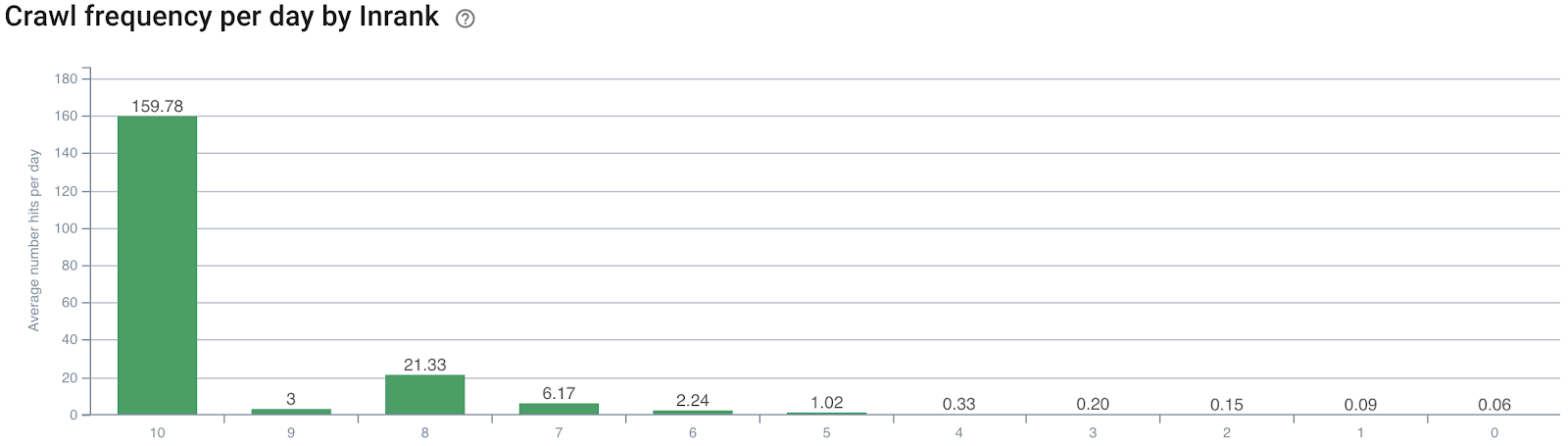
(La fréquence de crawl d’Oncrawl dans le rapport InRank montre clairement que les pages avec le plus de liens entrants sont crawlées plus souvent)
Les pages accumulant du pouvoir de liens. Tout comme il y a des pages qui renvoient trop vers l’extérieur, il y a aussi des pages qui ont trop de pouvoir de liens et n’en donnent pas assez. Attention, je ne suis pas en train de promouvoir le modelage de liens dans le sens classique ou encore l’idée que vous ne devriez pas lier vers l’extérieur. Lorsque je parle “d’accumulation de pouvoir de liens”, je suggère qu’elles ne renvoient pas assez de pouvoir de liens.
Identifiez le top 20 ou 50 des pages les plus liées en interne et tentez de les faire plus pointer vers l’extérieur, à moins qu’elles disposent déjà d’un nombre de liens sortants moyens supérieur à la moyenne.
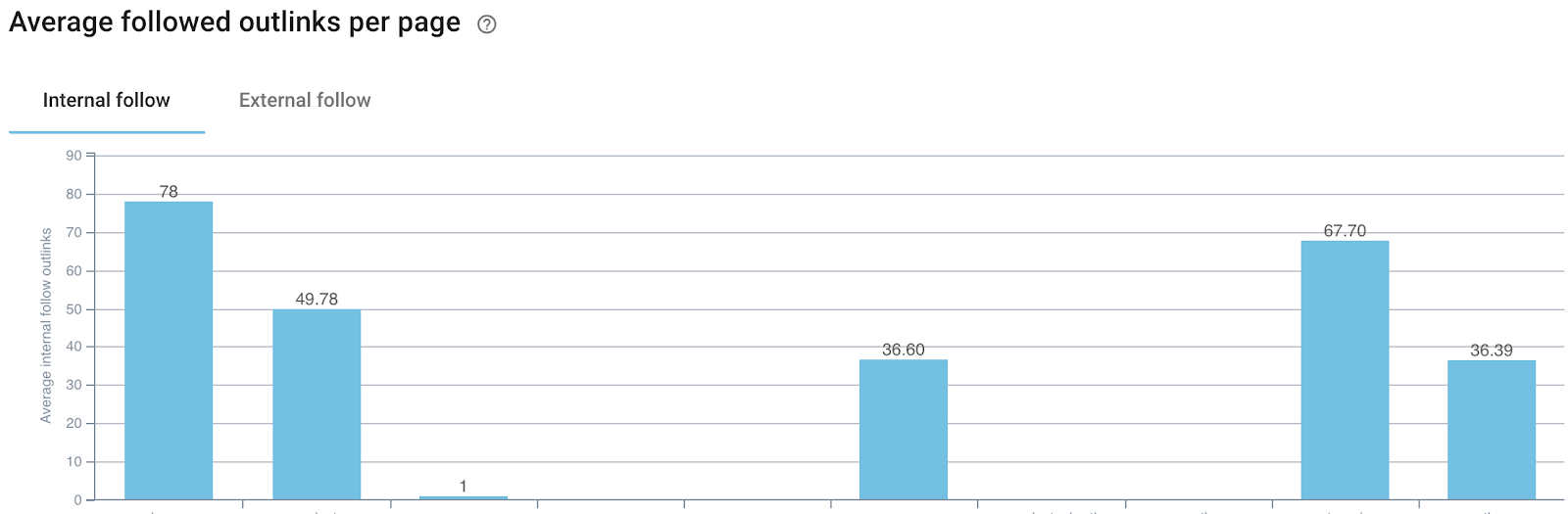
(Le graphique “Nombre moyen de liens sortants par type de page” d’Oncrawl vous permet de trouver les pages avec potentiellement trop ou pas assez de liens sortants)
L’optimisation du maillage interne suit souvent une distribution avec beaucoup de pages disposant de beaucoup de liens entrants / peu de liens sortants et l’opposé pour l’autre côté du spectre. Les sites avec peu de points de conversion (= des landing pages) devraient concentrer le pouvoir de liens autour des money pages. Les sites avec de nombreux points de conversion (= page produits pour les sites ecommerce ou articles pour les médias) devraient tenter d’équilibrer la distribution des liens entrants et sortants.
Cette prescription est très générale et des exceptions s’appliquent mais il est important de garder en tête que tous les sites ne doivent pas être optimisés de la même manière.
Le moyen le plus efficace de “scaler” les changements de maillage interne est de modifier les liens dans les pages catégories ou la barre de navigation supérieure. Cependant, de tels changements doivent être testés avant d’être mis en place car leur impact est trop complexe pour être estimé et est sujet aux évaluations de Google pour le contenu du boilerplate. Faire les modifications en pré production et comparer la structure du maillage interne à la version live avec un crawl est la meilleure solution dans cette situation.
Profondeur de clic
Avec la profondeur de clic, vous allez vouloir rechercher les pages importantes qui ont une profondeur de clic trop élevée, ce qui signifie qu’il faut trop de clics depuis la page d’accueil pour l’atteindre. Les solutions ici sont la pagination et les breadcrumbs.
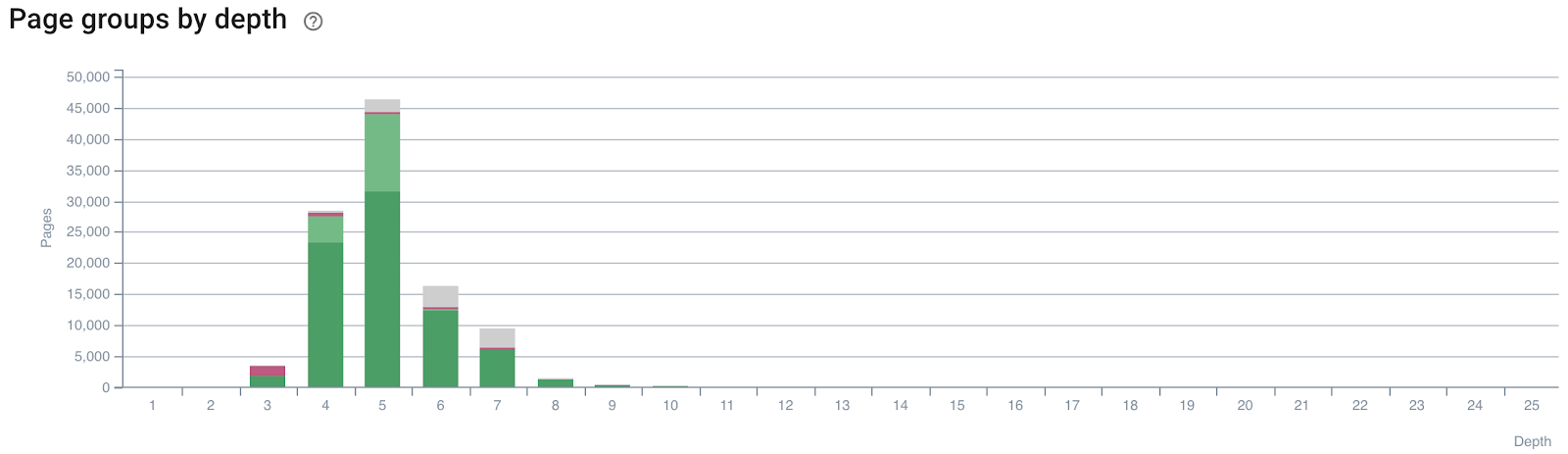
(Types de page ou groupes par profondeur montrant si les pages importantes sont trop loin de la page d’accueil)
Toutes les pages n’auront pas une faible profondeur de clic si le site atteint une certaine taille. Concrètement, ce n’est pas faisable, sauf si vous voulez vous retrouver avec des milliers de liens sur votre page d’accueil. Bien que l’ancien idéal implique que chaque page doit se situer à 3 clics de la page d’accueil, ne vous cassez pas trop la tête si certaines pages (surtout si elles ne sont pas importantes) se retrouvent plus loin que ça.
Les changements dans la profondeur de clic doivent être évalués dans un environnement de pré production et comparé à la version live. Il est simple de segmenter par type de pages et de voir comment l’ajout d’un breadcrumb ou d’une pagination va impacter la profondeur de clic.
Structure d’URL
Une structure d’URL idéale s’adapte à la taille du site et aux facteurs mentionnés dans cet article. Plus le site est large, plus je recommande de mettre en place une certaine hiérarchie dans la structure d’URL avec des redirections et sous redirections afin de donner du contexte aux utilisateurs et aux moteurs de recherche.
Les plus grands problèmes que j’observe sur les sites sont souvent liés au fait de donner trop ou pas assez de hiérarchie dans leur structure d’URL. En clair, générer du trafic organique n’est pas la plus grande priorité. Mais lorsque vous gérez un grand site et pouvez changer votre structure d’URL, ajouter un peu de hiérarchie n’est pas une mauvaise idée.
Taxonomie
La taxonomie est l’un de ces sujets sur lequel nous pourrions écrire un livre. Je vais essayer de le résumer en quelques phrases mais rappelez-vous que c’est un sujet à part entière.
L’idée de se rapprocher de l’optimum est souvent liée à un site spécifique et il y a souvent plusieurs options. Donc, je ne peux pas fournir un nombre qui indique si oui ou non la taxonomie est positive ou négative. Si vous n’avez jamais tenté différentes manières d’optimiser le contenu de votre site, vous n’avez probablement pas investi assez dans votre taxonomie.
Un exercice utile est le tri de cartes pour taxonomie. Écrivez toutes vos catégories, sous catégories, sujets (et balises) sur des fiches. Puis, consultez votre département marketing et discutez de la structure d’information optimale de votre site.
Allrecipes.com est un exemple de site avec une taxonomie bien structurée. Je ne sais pas si la taxonomie en elle-même est à l’origine du succès de ce site mais cela reflète certainement le maillage interne et la structure de contenu.
(Barre de navigation de allrecipes.com)
Se concentrer sur le contenu indexable
L’indexabilité ne fait pas partie de la structure du site mais il est important de savoir si le contenu est ouvert à l’indexation ou non. Si vous empêchez l’indexation de grosses parties de votre site, comme par exemple dans certains templates comme les profils de forum, la structure ne s’applique alors qu’aux humains.
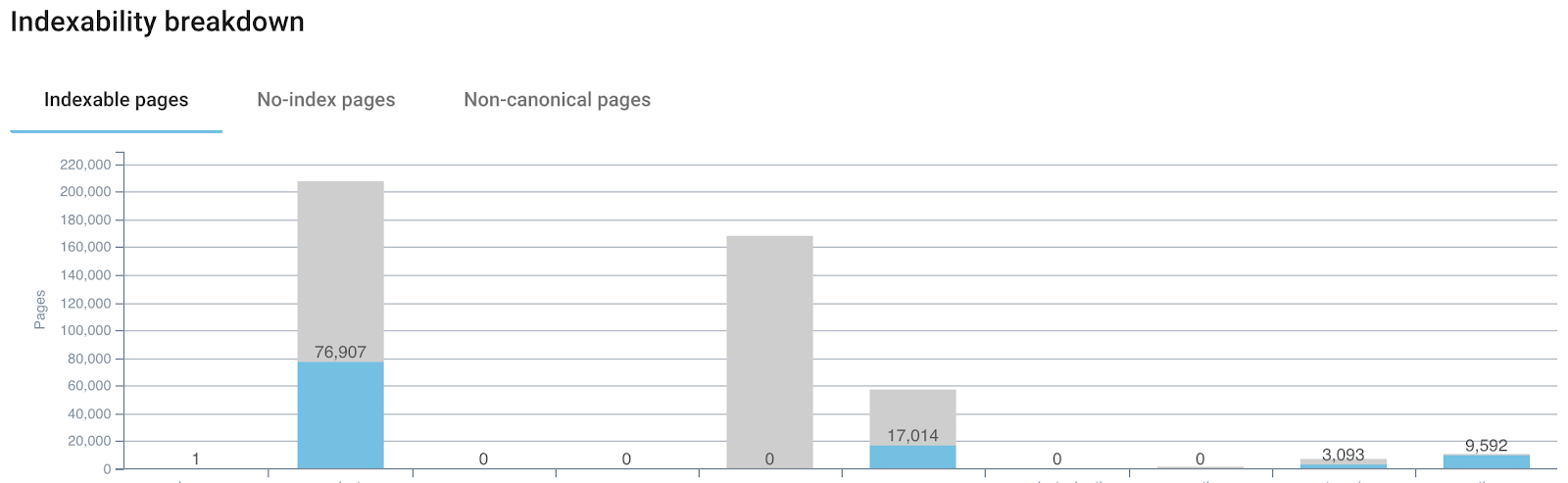
(Rapport d’indexabilité d’Oncrawl, il est important de garder l’indexabilité en tête lorsque vous optimisez la structure de site)
Dans cette situation, vous devez considérer deux points. Le premier est que la non indexation des parties d’un site ne fournit pas de contexte aux moteurs de recherche. Donc, attention à votre logique d’exclusion. Ensuite, au lieu d’utiliser des méta balises noindex, vous devriez envisager d’empêcher le crawl avec un robots.txt afin d’économiser du budget de crawl. Vous pourriez utiliser un rel=nofollow mais le robots.txt apporte plus de flexibilité, des changements plus rapides et un meilleur contrôle. Empêcher le contenu de mauvaise qualité de se retrouver dans l’index de Google est toujours une bonne idée et j’ai observé de bons résultats en économisant du budget de crawl. Donc, lorsque vous analysez le maillage interne, la profondeur de clic, la taxonomie et la structure d’URL, gardez en tête ce qui doit être indexé et ce qui ne doit pas l’être.
La structure de site change au fil du temps
L’optimisation de la structure de site est un processus continu. Les sites web sont des écosystèmes vivants : ils grandissent et changent au fil du temps. Tout comme les humains doivent aller chez le docteur pour un check-up de temps en temps, nous devons vérifier la structure du site régulièrement.
Pensez au graphique social d’une ville. Il y a un nombre défini de personnes vivant dans cette ville et la plupart se connaissent. Certaines sont très populaires, comme les maires. D’autres ne connaissent qu’une seule personne. La ville est connectée de manière optimale lorsque les bonnes personnes sont connues, comme par exemple, les membres du conseil de la ville.
L’un des principaux challenges est le flux. De nouvelles personnes vont emménager dans la ville, d’autres vont partir. Le graphique social change constamment, tout comme le maillage d’un site.

Dans cette métaphore, les personnes sont des noeuds et les relations entre eux sont des bordures. Nous pouvons transférer cela à la manière dont les pages sont liées dans un site. Les sites grossissent, certains plus rapidement que d’autres, et le graphique de maillage interne change également. C’est le challenge qui se cache derrière l’optimisation de la structure de site : c’est une réévaluation constante de la manière dont les noeuds sont connectés entre eux. Il faut s’assurer que les bons noeuds sont suffisamment populaires.
Effectuez un crawl hebdomadaire ou bihebdomadaire et analysez les fichiers de log par rapport à la fréquence de crawl au moins une fois par mois. Je suggère un audit trimestriel de la structure de site en examinant le maillage interne, la structure d’URL, la taxonomie et la profondeur de clic. Globalement, la taxonomie n’est nécessaire que lors de l’ajout d’une nouvelle section, d’un lancement / migration ou de la sortie d’un nouveau produit. Cela n’arrivera probablement pas si souvent que cela, peut être une fois par an seulement.
Plus votre structure de site est propre, mieux elle s’adapte à la croissance de votre site.
