
L’extension de la recherche au-delà des requêtes textuelles et la suppression des barrières linguistiques sont des tendances récentes qui façonnent l’avenir des moteurs de recherche. Grâce à de nouvelles fonctionnalités alimentées par l’IA, les moteurs de recherche cherchent à promouvoir une meilleure expérience de recherche et, en même temps, à apporter de nouveaux outils pour aider les utilisateurs à retrouver des informations spécifiques. Dans cet article, nous aborderons le sujet croissant des systèmes de recherche multimodaux et multilingues. Nous montrerons également les résultats d’un outil de recherche de démonstration que nous avons construit chez Wordlift.
La prochaine génération de moteurs de recherche
Une bonne expérience utilisateur englobe de multiples aspects de l’interaction entre les utilisateurs et les moteurs de recherche. De la conception de l’interface utilisateur et de sa convivialité à la compréhension de l’intention de recherche et à la résolution de ses requêtes ambiguës, les grands moteurs de recherche préparent la prochaine génération d’outils de recherche.
Recherche multimodale
Une façon de décrire un moteur de recherche multimodal est de penser à un système capable de traiter du texte et des images dans une seule requête. De tels moteurs de recherche permettraient aux utilisateurs d’exprimer leurs requêtes en entrée par le biais d’une interface de recherche multimodale et offriraient ainsi une expérience de recherche plus naturelle et intuitive.
Sur un site de e-commerce, un moteur de recherche multimodal permettrait de récupérer des documents pertinents à partir d’une base de données indexée. La pertinence est évaluée en mesurant la similarité entre les produits disponibles et une requête donnée dans plusieurs formats tels que le texte, l’image, l’audio ou la vidéo. Par conséquent, ce moteur de recherche est un système multimodal puisque ses mécanismes sous-jacents sont capables de traiter simultanément différents modes d’entrée, c’est-à-dire différents formats.
Par exemple, une requête de recherche peut prendre la forme de « robe à fleurs ». Dans ce cas, un grand nombre de robes à fleurs sont disponibles sur la boutique en ligne. Cependant, le moteur de recherche renvoie des robes qui ne sont pas vraiment satisfaisantes pour l’utilisateur, comme le montre la figure suivante.
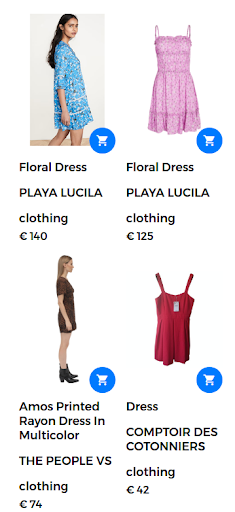
Résultats retournés pour la requête « robe à fleurs ».
Pour offrir une bonne expérience de recherche et renvoyer des résultats très pertinents, un moteur de recherche multimodal est capable de combiner un texte et une image dans une seule requête. Dans ce cas, l’utilisateur fournit l’image type du produit souhaité. Lorsque cette recherche est exécutée en tant que recherche multimodale, l’image d’entrée est une robe à fleurs, comme le montre l’image suivante.

Image fournie par l’utilisateur pour la recherche multimodale.
Dans ce scénario, la première partie de la requête reste la même (robe à fleurs) et la deuxième partie ajoute l’aspect visuel à la requête multimodale. Les résultats retournés donnent des robes similaires à la robe à fleurs fournie par l’utilisateur. Dans ce cas d’utilisation, la même robe est disponible et est donc le premier résultat renvoyé avec d’autres robes similaires.
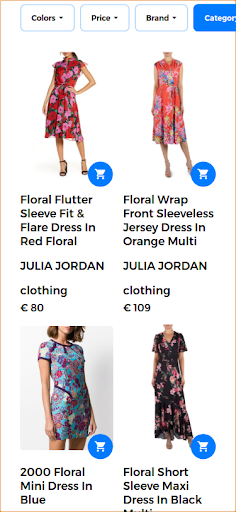
Résultats de recherche pertinents retournés en réponse à la requête multimodale.
MUM
Google a introduit une nouvelle technologie pour aider les utilisateurs à effectuer des tâches de recherche complexes. Cette nouvelle technologie, appelée MUM (Multitask Unified Model), est capable de faire tomber les barrières linguistiques et d’interpréter des informations dans différents formats de contenu tels que des pages Web et des images.
Google Lens est l’un des premiers produits à exploiter l’avantage de combiner images et texte en une seule requête. Dans le cadre d’une recherche, MUM permettrait aux utilisateurs de trouver plus facilement des motifs, par exemple un motif floral spécifique dans une image fournie par l’utilisateur.
MUM est un nouveau jalon de l’IA pour la compréhension de l’information telle qu’elle est présentée ici :
« Bien que nous n’en soyons qu’aux premiers jours de l’exploration de MUM, il s’agit d’une étape importante vers un avenir où Google pourra comprendre toutes les différentes façons dont les gens communiquent et interprètent naturellement les informations. »
Pour en savoir plus sur la recherche multimodale MUM de Google, consultez cet article Web :

Étendre la recherche à toutes les langues
Si l’image est indifférente à la langue, les termes de recherche sont spécifiques à la langue. La conception d’un système multilingue se résume à l’élaboration de modèles linguistiques dans un large éventail de langues.
Recherche multilingue
L’une des principales limites des systèmes de recherche actuels est qu’ils récupèrent les documents écrits, ou annotés, dans la langue dans laquelle l’utilisateur a rédigé sa requête. En général, ces moteurs sont uniquement en anglais. Ces moteurs de recherche monolingues limitent l’utilité de ces systèmes pour trouver des informations utiles écrites dans une autre langue.
En revanche, les systèmes multilingues acceptent une requête dans une langue et récupèrent les documents indexés dans d’autres langues. En réalité, un système de recherche est multilingue s’il est capable d’extraire des documents pertinents de la base de données en faisant correspondre le contenu du document, ou ses légendes, écrit dans une langue avec la requête textuelle dans une autre langue. Les techniques de mise en correspondance vont des mécanismes syntaxiques aux approches de recherche sémantique.
L’appariement de phrases dans différentes langues avec des concepts visuels est une première étape pour promouvoir l’utilisation de modèles vision-langage multilingues. La bonne nouvelle est que les concepts visuels sont interprétés presque de la même manière par tous les humains. Ces systèmes, capables d’intégrer des informations provenant de plus d’une source et dans plus d’une langue, sont appelés systèmes multilingues multimodaux. Cependant, l’appariement image-texte n’est pas toujours réalisable pour toutes les langues à grande échelle, comme nous le verrons dans la section suivante.
[Étude de cas] Stimuler la croissance sur de nouveaux marchés grâce au SEO on-page

De MUM à MURAL
Des efforts croissants sont déployés pour appliquer des techniques avancées d’apprentissage profond et de traitement du langage naturel aux moteurs de recherche. Google a présenté un nouveau travail de recherche qui permet aux utilisateurs d’exprimer des mots à l’aide d’images. Par exemple, le mot « valiha » fait référence à un instrument fait de cithare en tube et est joué par le peuple malgache. Ce mot n’a pas de traduction directe dans la plupart des langues, mais pourrait être facilement décrit à l’aide d’images.
Le nouveau système, appelé MURA, signifie « Multimodal, Multi-task Retrieval Across Languages« . Il permet de résoudre le problème des mots dans une langue qui n’ont pas forcément de traduction directe dans une langue cible. Avec de tels problèmes, de nombreux modèles multilingues pré-entraînés ne parviendraient pas à trouver des mots sémantiquement liés ou à traduire avec précision des mots vers ou à partir d’une langue sous-ressource. En fait, MURAL peut s’attaquer à de nombreux problèmes du monde réel :
- Les mots qui véhiculent des significations mentales différentes dans différentes langues : Un exemple est le mot « mariage » en anglais et en hindi qui véhicule des images mentales différentes comme le montre l’image suivante provenant du blog de Google.
- Rareté des données pour les langues sous-utilisées sur le web : 90 % des paires texte-image sur le web appartiennent aux 10 langues les plus riches en ressources.

Les images sont tirées de wikipedia, créditées à Psoni2402 (à gauche) et David McCandless (à droite) avec la licence CC BY-SA 4.0.
La réduction de l’ambiguïté des requêtes et la résolution du problème de la rareté des paires image-texte pour les langues sous-ressources constituent une autre amélioration en vue de la prochaine génération de moteurs de recherche alimentés par l’IA.
La recherche multilingue et multimodale en action
Dans ce travail, nous utilisons les outils existants et les modèles de langage et de vision disponibles pour concevoir un système multilingue multimodal qui va au-delà d’une seule langue et peut traiter plus d’une modalité à la fois.
Tout d’abord, pour concevoir un système multilingue, il est important de connecter sémantiquement des mots qui proviennent de différentes langues. Ensuite, pour rendre le système multimodal, il est nécessaire de relier la représentation des langues aux images. Il s’agit donc d’un grand pas vers l’objectif de longue date d’une recherche multimodale multilingue.
Le contexte
Le principal cas d’utilisation de ce système multimodal multilingue est de retourner les images pertinentes du jeu de données étant donné une requête combinant une image et un texte en même temps. Dans cette optique, nous allons montrer quelques exemples qui illustrent divers scénarios multimodaux et multilingues.
L’épine dorsale de cette application de démonstration est alimentée par Jina AI, un écosystème de recherche neuronale open-source. La recherche neuronale, alimentée par la recherche d’information par réseau neuronal profond (ou RI neuronale), est une solution intéressante pour construire un système multimodal. Dans cette démo, nous utilisons l’architecture MPNet Transformer de Hugging Face, multilingual-mpnet-base-v2, pour traiter les descriptions textuelles et les légendes. Pour la partie visuelle, nous utilisons MobileNetV2.
Dans ce qui suit, nous présentons une série de tests pour montrer la puissance des moteurs de recherche multilingues et multimodaux. Avant de présenter les résultats de notre outil de démonstration, voici une liste des éléments clés qui décrivent ces tests :
- La base de données est constituée de 1k images qui représentent des personnes jouant de la musique. Ces images sont extraites du dataset public Flickr30K.
- Chaque image a une légende écrite en anglais.
Étape 1 : Commencer avec une requête textuelle en anglais
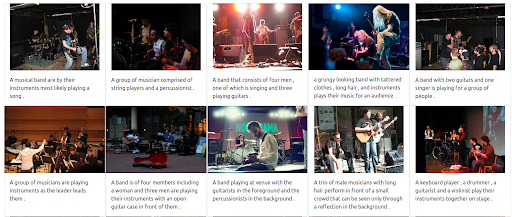
Nous commençons par une requête textuelle qui reflète le mode de fonctionnement actuel de la plupart des moteurs de recherche. La requête est « groupe de musiciens ».
La requête
Les résultats
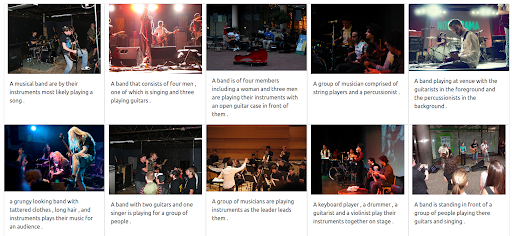
Notre moteur de recherche de démonstration basé sur Jina renvoie des images de musiciens qui sont sémantiquement liées à la requête d’entrée. Cependant, il se peut que ce ne soit pas le type de musiciens que nous voulons.
Étape 2 : ajout de la multimodalité
Ajoutons maintenant de la multimodalité en émettant une requête qui combine à la fois la requête textuelle précédente et une image. L’image représente une représentation plus précise des musiciens que nous recherchons.
Tout d’abord, l’interface utilisateur doit prendre en charge l’émission de ce type de requêtes. Ensuite, nous devons attribuer un poids pour équilibrer l’importance de chaque modalité lors de la récupération des résultats. Dans ce cas, le texte et l’image ont un poids égal (0,5). Comme nous pouvons le voir ci-dessous, les nouveaux résultats de recherche incluent un certain nombre d’images qui sont visuellement similaires à la requête d’image d’entrée.
La requête
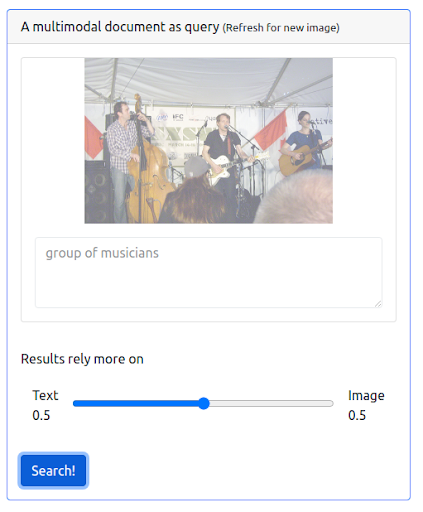
Les résultats
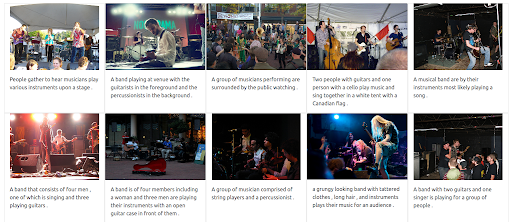
Étape 3 : Attribution d’un poids maximal à l’image
Il est également possible d’attribuer un poids maximal à l’image. Cela permet d’exclure le texte d’entrée de la requête. Dans ce cas, davantage d’images visuellement similaires à l’image d’entrée sont retournées et classées dans les premiers positionnements. Il faut garder à l’esprit que les résultats sont limités aux images disponibles dans l’ensemble de données.
La requête
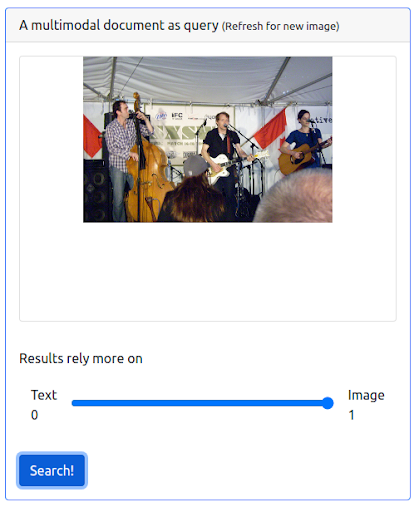
Les résultats
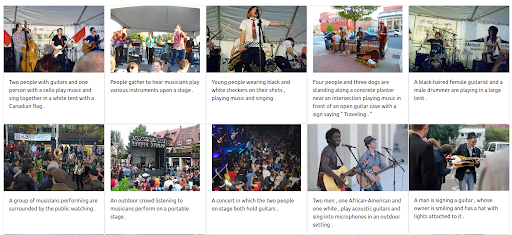
Étape 4 : Test de la recherche multilingue
Essayons maintenant d’émettre la même requête mais en utilisant différentes langues. Le poids du texte est maximisé afin d’illustrer toute la puissance de ce système multilingue. Rappelons que les légendes des images sont uniquement en anglais. La recherche est répétée pour couvrir les langues suivantes :
- Français : Groupe de musiciens
- Italien : Gruppo di musicisti
- Allemand : Gruppe von Musikern
Quelle que soit la langue de la requête d’entrée, les résultats renvoyés sont pertinents et cohérents dans les trois langues. Les résultats sont présentés ci-dessous.
Les résultats de la requête en français

Les résultats de la requête en italien

Les résultats de la requête en allemand
L’avenir multimodal et multilingue de la recherche
Dans les années à venir, l’intelligence artificielle transformera de plus en plus la recherche et ouvrira des voies entièrement nouvelles pour que les gens puissent exprimer leurs requêtes et explorer l’information. Comme Google l’a déjà annoncé, la compréhension des informations à l’aide du MUM représente une étape importante de l’IA. À l’avenir, les systèmes alimentés par l’IA comprendront des fonctionnalités et des améliorations allant de l’amélioration de l’expérience de recherche à la réponse à des questions sophistiquées, en passant par l’élimination des barrières linguistiques et la combinaison de différents modes de recherche en une seule requête.
