La navigation à facettes est un sujet récurrent sur les sites à forte volumétrie de pages qui ont des listings produits ; si elle est implémentée correctement, elle peut être très bénéfique pour un site. En effet, la création de nouvelles pages plus précises permet de répondre à plus de requêtes pour plus de visibilité dans les résultats de recherche.
En plus de proposer une architecture de site logique et un maillage interne optimisé, la navigation à facettes permet aussi aux utilisateurs de trouver rapidement le(s) produit(s) qu’ils recherchent.
La mise en place d’une navigation à facettes demande de respecter certaines règles sinon elle peut entraîner d’importants problèmes comme la création en masse de pages inutiles / dupliquées ou l’apparition de spider traps.
Qu’est-ce qu’une facette ?
La navigation à facettes peut être généralement trouvée sur les pages listing de sites e-commerce ou immobilier : elle correspond aux différentes combinaisons qu’un utilisateur peut sélectionner pour affiner sa recherche.
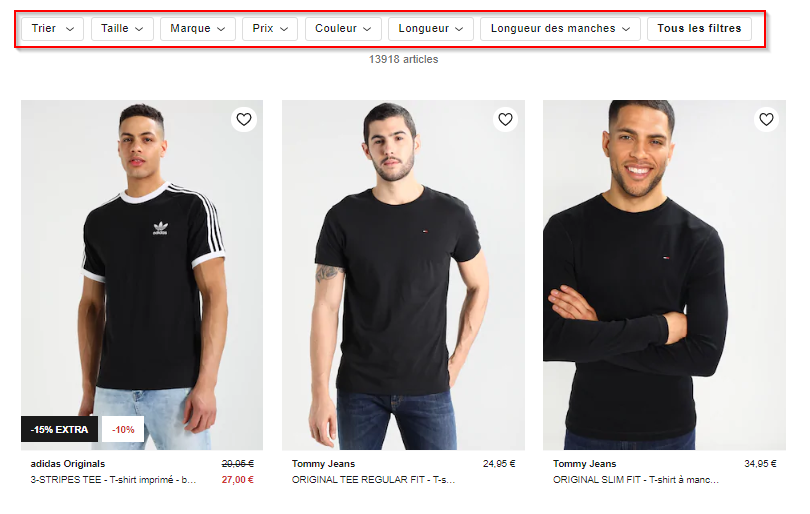
Exemple de navigation à facettes pour les t-shirts homme sur Zalando
Parmi ces combinaisons disponibles, il est important de faire la différence entre une facette et un filtre.
Facette : C’est une page catégorie filtrée que l’on souhaite rendre crawlable et indexable. Cette dernière répond à des requêtes d’utilisateurs ayant un certain volume de recherche, sa création apporte de la valeur et potentiellement du trafic au site.
Filtre : C’est une page catégorie filtrée uniquement pour l’utilisateur. Cette dernière ne répond pas à des requêtes ayant du volume de recherche mensuel ; elle permet seulement aux utilisateurs de rendre une page catégorie plus précise et de naviguer parmi les différents attributs d’un produit.
Pourquoi ouvrir des facettes ?
Comme mentionné précédemment, la navigation à facettes est bénéfique pour les sites à forte volumétrie de pages qui possèdent des listings de produits / biens. Une ouverture de facettes gérée de manière optimale aura principalement 3 avantages :
- Cibler des mots clés génériques ou issus de la de longue traîne. Il est donc intéressant d’ouvrir des facettes pour cibler des requêtes précises et proposer un listing de biens correspondant.
- t shirt : 74 000 volume / mois
- t shirt homme : 9 900 volume / mois
- t shirt noir homme : 590 volume / mois
- Automatiser la création de pages selon certaines règles : les sites concernés ayant en général un nombre de pages élevé, il est bénéfique d’automatiser la création de pages ;
- Automatiser le maillage interne de ces pages grâce à la création automatique des pages.
Comment choisir les facettes à ouvrir ?
Pour choisir les facettes intéressantes à ouvrir, il est important de respecter 3 étapes :
L’étude sémantique : Recherche sémantique classique où les mots clés relatifs au site sont récupérés ;
La catégorisation : Catégorisation des mots clés selon la méthode habituelle qui prend en compte les différentes segmentations pertinentes des facettes (ex : Prix, taille, marque, genre, matière, etc.)
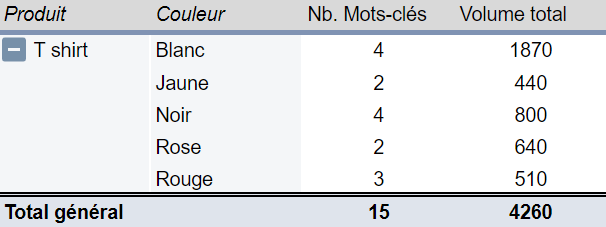
L’analyse des résultats : Analyse des résultats de la recherche sémantique avec des TCD qui mettent en avant les différentes catégories et combinaisons possibles. L’idée est de récupérer le volume de recherche associé à chaque croisement possible.
Par exemple, il est intéressant d’ouvrir certaines couleurs sur la catégorie T-shirt :
Crawl et indexation : Pourquoi est-il nécessaire de maîtriser l’ouverture des facettes ?
Si la navigation à facettes est implémentée correctement, elle permettra d’augmenter le nombre de pages qualifiées pour les utilisateurs et les robots, par contre si cette dernière n’est pas gérée de manière optimale, elle peut entraîner plusieurs typologies de problèmes :
- Risque de spider traps :
Un spider trap est la création d’un très grand nombre ou d’un nombre illimité d’URLs empêchant l’exploration correcte d’un site. Comme la navigation à facettes permet de créer un nombre de combinaisons importantes, elle peut facilement être sujette à des spider traps si elle n’est pas gérée correctement.
- Gaspillage de crawl :
Un nombre important de liens non indexables dans une structure de site entraînera forcément un gaspillage du crawl (même si à terme ces liens seront moins crawlés).
- Dilution de la popularité interne :
Un grand nombre de liens non crawlables au sein d’une structure de site n’est pas optimal pour la répartition de la popularité interne.
- Génération de doublons ou de quasi-doublons :
Parmi les pages créées automatiquement par la navigation à facettes, certaines peuvent avoir un contenu identique ou très similaire. Ce genre de cas doit être évité pour ne pas créer du contenu dupliqué interne.
- Génération de pages vides :
De la même manière que pour les pages ayant un contenu similaire, celles n’ayant pas de contenu ne doivent pas être générées.
Crawler SEO Oncrawl

Les règles à respecter pour maîtriser l’ouverture de facettes
Gestion du Multi-facettes
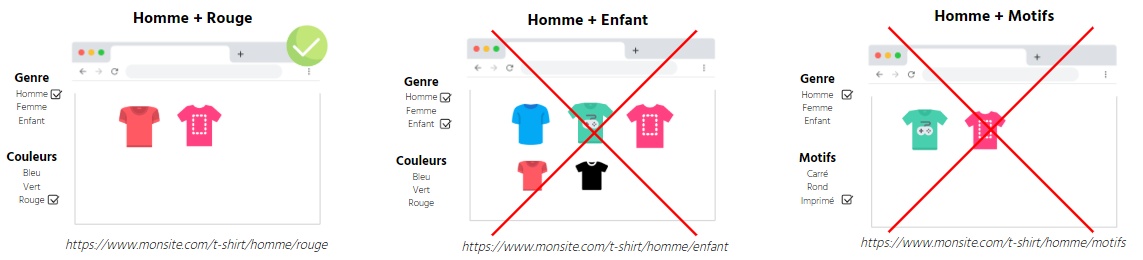
Tout d’abord, il faut définir si une facette doit être ouverte si plusieurs variables sont sélectionnées simultanément (au sein d’une même catégorie ou non)
Exemple: j’ouvre mes facettes genre + couleurs
Exemple: je n’ouvre pas mes facettes genre lorsque homme + enfant est sélectionné
Exemple: je n’ouvre pas mes facettes genre + motifs
Définition du nombre minimal de produits / biens
Une facette doit s’ouvrir automatiquement seulement lorsque le nombre de produits / bien est suffisant
Exemple: j’ouvre mes facettes genre (homme ou femme) lorsque j’ai au minimum 3 t-shirts à vendre

Mise en place du balisage SEO
Les facettes ouvertes doivent contenir un balisage SEO classique optimisé, il faut donc définir des règles de balisage automatique.
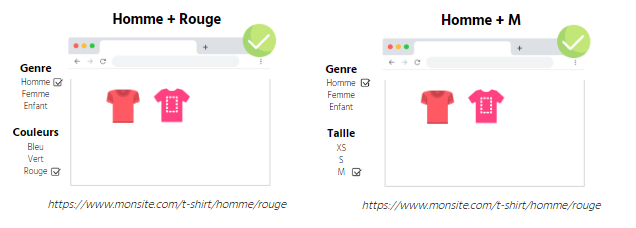

Mettre en place une ré-écriture d’URL
Les facettes étant initialement des filtres que l’on souhaite indexer, des URLs « ugly » seront créées lors de l’ouverture de celles-ci. Il faut alors ré-écrire ces URLs afin d’obtenir des URLs « propres » (donc sans caractères spéciaux comme des %, ? Ou &).
Exemple: Je cherche un t-shirt noir de la marque Nike

Ces URLs « propres » sont optimisées pour le crawl et l’indexation
Gestion de la stabilité des URLs
La structure d’URL ne doit pas changer selon le chemin suivi par l’internaute.
Exemple: Deux personnes cherchent un t-shirt noir de la marque Nike mais de manière différente.

Il faut donc définir un ordre par défaut, par exemple : [Catégorie d’habit] > [Couleur] > [Marque] et garder cet ordre quel que soit le chemin de l’internaute.
Optimisation du maillage interne
Comme pour une structure de site classique, pour qu’une facette ouverte soit crawlable et indexable, les URLs du site doivent avoir un lien en dur vers la facette ouverte. Ce dernier doit être présents dans le DOM et accessible même si le JavaScript et le CSS sont désactivés
Exemple: j’ai ouvert mes facettes sur les T-shirts Homme + Couleurs
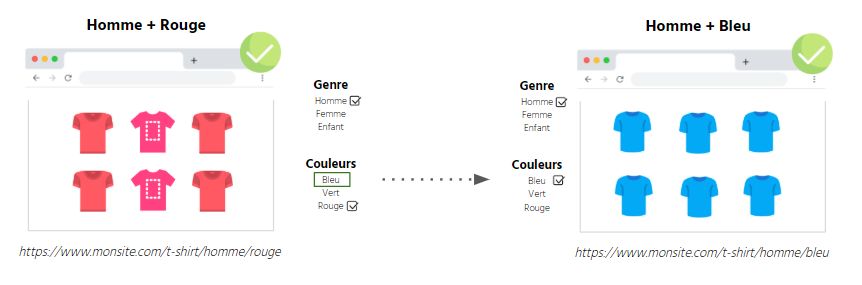
J’ai bien un lien en “dur” T-shirts Homme Bleus depuis ma page T-shirts rouges homme vers ma page T-shirts bleus homme.
Plusieurs façons de rendre inaccessibles des facettes
Maintenant que nous avons abordé les règles à respecter quant à l’ouverture de facettes, il faut définir un moyen de rendre non crawlable / non indexable les facettes qui ne doivent pas être ouvertes.
[Étude de cas] Gérer le crawl du robot de Google

Généralement, il est possible de bloquer les facettes non souhaitées de plusieurs manières, chacune d’entre elle ayant ses avantages et inconvénients.
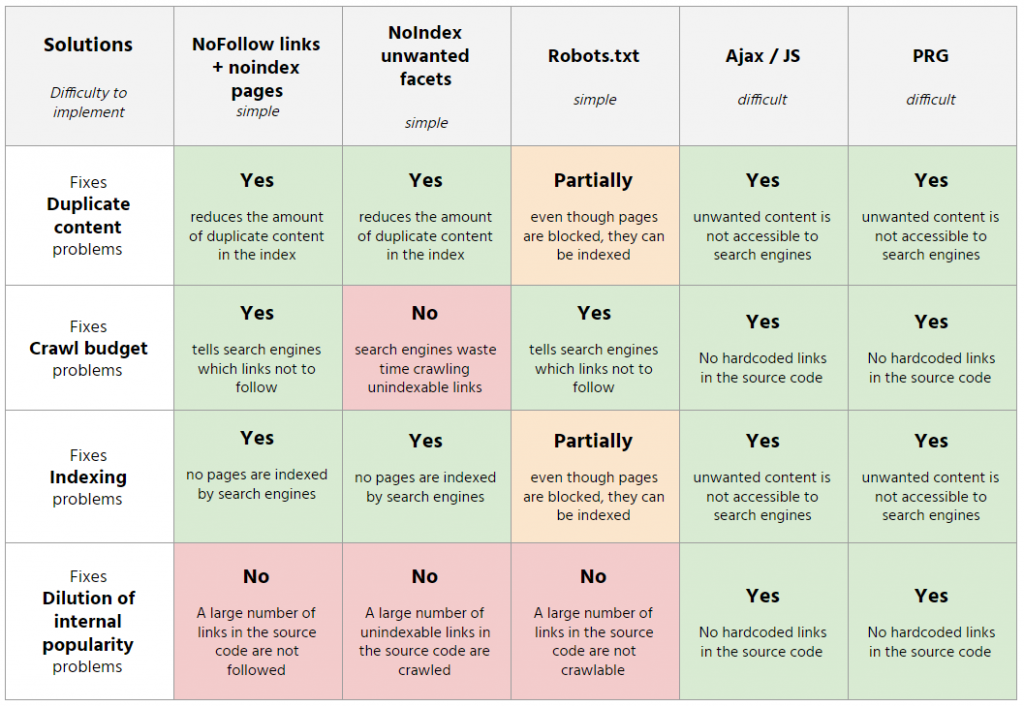
- Ajout du nofollow sur les liens des facettes fermées + meta robots noindex
Cette solution permet de limiter le gaspillage de crawl sur les pages non souhaitées ainsi que d’assurer la non indexation des pages fermées (dans le cas où elles seraient connues des moteurs de recherche par d’autres moyens). Cependant, cela ne résout pas les problèmes de dilution de popularité interne car un nombre de liens important non crawlable est présent sur la page.
Ajout d’une meta robots noindex sur les pages fermées
Avec cette approche, seuls les problèmes d’indexation et de contenu dupliqué sont résolus. En effet, le gaspillage de crawl et la dilution de la popularité interne seront toujours présents au sein du site.
- Blocage des facettes au robots.txt
Solution assez simple à mettre en place et en bloquant le pattern des facettes fermées au robots.txt. Bien que cette dernière permette de ne pas gaspiller de budget de crawl sur des pages inutiles, elle ne permet pas d’apporter de réelles réponses quant à l’indexation, le contenu dupliqué et la dilution de popularité interne.
- JS / Ajax
L’utilisation du Javascript / Ajax pour bloquer les facettes permet de répondre efficacement à toutes les problématiques. En effet, les liens vers les facettes fermées sont accessibles uniquement pour les utilisateurs et ne sont pas présents dans le code source de la page, ils sont donc inaccessibles pour les robots. A noter que Google exécute le Javascript et qu’une implémentation idéale de cette solution se fait côté client : le filtrage de la page catégorie se fait directement dans le navigateur et aucune nouvelle page n’est créée.
- PRG (Post-Redirect-Get) :
Tout comme l’utilisation du JS / Ajax, cette méthode permet de répondre efficacement à toutes les problématiques. Pour rappel, les requêtes GET permettent de transmettre des informations dans l’URL et sont exécutables par Google. A contrario, pour les requêtes POST, les informations sont incluses dans un formulaire et ne sont pas exécutables par Google.
Le but de la méthode PRG est donc d’utiliser un formulaire en mode POST pour les facettes non désirées afin que Google ne les exécute pas, ce qui donnerait :
- Étape 1 POST : l’utilisateur clique sur un filtre d’une facette non désirée et la requête envoyée est en méthode POST (non exécutable par Google) ;
- Étape 2 REDIRECT : le serveur répond à la requête par une redirection vers l’URL filtrée ;
- Étape 3 GET: la redirection est suivie et l’URL filtrée est renvoyée en méthode GET. L’utilisateur voit ses résultats filtrés

En résumé
En conclusion
Pour que la création de facettes se déroule sans encombre, il est nécessaire de suivre plusieurs règles et de prévoir tous les cas possibles en pré-production. Il est également important de noter que la gestion des facettes est spécifique au CMS utilisé sur un site et qu’il existe différentes solutions pour gérer la création et la restriction des facettes, chacune ayant des avantages et des inconvénients.
