
Demandez à des experts SEO ce qu’ils recommanderaient si le site web d’un client avait une fonctionnalité de recherche interne et 9 fois sur 10 ils vous diraient de ne pas indexer ces pages de résultats. Le rôle d’une balise noindex lorsqu’elle est placée sur un site, et si elle est respectée par les moteurs de recherche, est d’empêcher ces pages de recherche interne d’être indexées dans les résultats de Google ou de n’importe quel autre moteur de recherche.
Ma propre opinion était (et est toujours) la même – ces résultats devraient *normalement” être non indexés. Mais comme souvent dans le SEO, il y a de nombreuses nuances et situations dans lesquelles ce conseil n’est pas toujours aussi noir et blanc. Du moins pas autant que nous aimerions qu’il le soit !
Jusqu’à il y a quelques années, les Google Webmaster Guidelines indiquaient que ces résultats de recherche devaient en effet être non indexés afin d’empêcher les crawlers d’y accéder mais cette règle semble avoir été retirée des versions les plus récentes de ces directives.
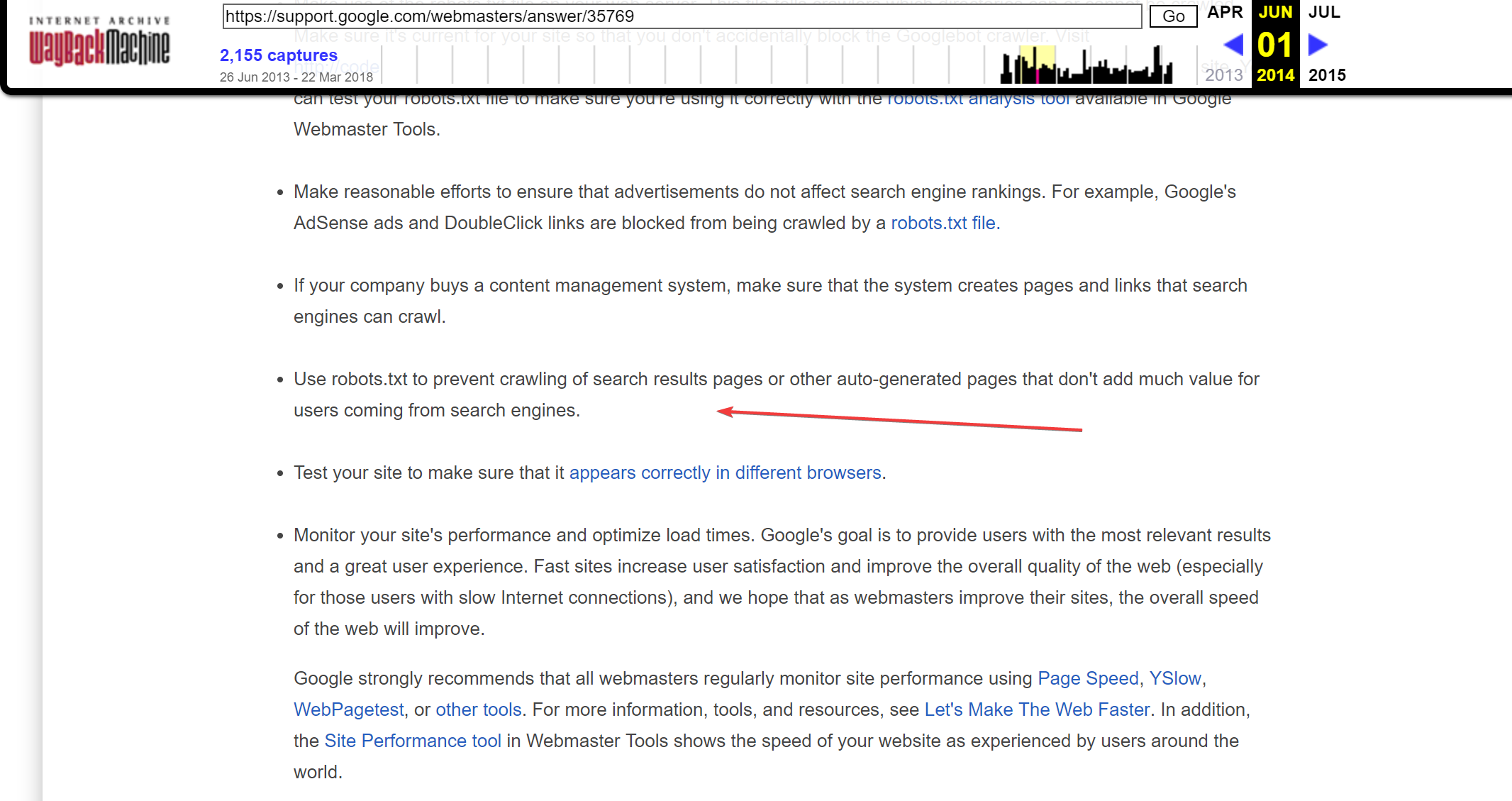
Capture d’écran des anciennes Google Webmaster Guidelines ou ils mentionnent l’utilisation de robots.txt pour empêcher le crawl de ces pages de résultats de recherche. (Issue de WayBackMachine en 2017).
De nombreux SEOs pensent que c’est toujours le cas, mais d’après mes observations, il y a beaucoup de sites qui ignorent ces recommandations et autorisent les crawlers à accéder aux pages de recherche.
J’ai tenté d’observer les potentiels dangers liés à l’indexation de ces contenus ; ce que cela signifie pour votre site web, et comment ils peuvent en réalité être utilisés à votre avantage.
Avant de plonger dans le reste de l’article, vous aimeriez peut-être entendre cette question être posée à John Mueller de Google durant son excellent rendez-vous hebdomadaire Webmaster Hangouts.
Video de John Mueller lisant/répondant à ma question au sujet de l’utilisation des résultats de recherche interne dans Google.
Que font les autres sites web au sujet de l’utilisation des résultats de recherche interne ?
Cela fait un moment que je fais des recherches sur le fait de ne pas indexer les recherches internes, plus ou moins depuis que Giphy.com a supposément été pénalisé pour cette exacte raison. Pour ceux qui n’en ont pas entendu parler, la majorité de leur trafic organique provenait de pages qui étaient des résultats de recherche interne.
Ils se sont d’ailleurs vantés de “posséder” les résultats de recherche pour “Happy Birthday” dans une célèbre interview, ce qui leur a valu d’être pénalisé du jour au lendemain. Depuis, ils n’indexent plus leurs résultats de recherche et commencent à se remettre de cette péripétie ; bien qu’il semble qu’ils aient également été affectés par une mise à jour récente de Google.
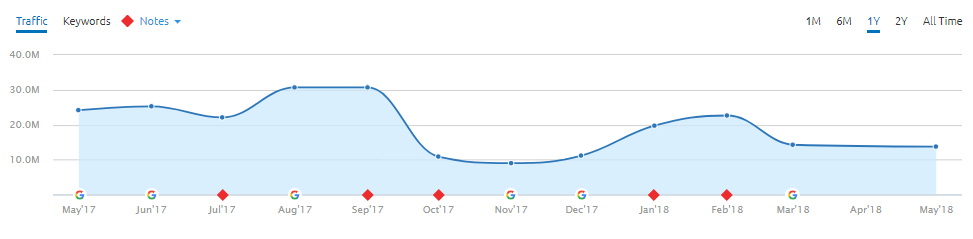
Capture d’écran de la chute du trafic organique de Giphy.com, suivie d’un léger rebond puis d’une nouvelle chute (Données provenant de SEMRush)
L’une des principales autres raisons que j’ai récemment découvert à ce sujet est issue de ma propre navigation web ; j’ai remarqué que de nombreux gros sites indexaient leurs résultats de recherche et visiblement s’en sortaient quand même très bien d’après les SERPs Google. Comme vous pouvez le voir sur l’exemple de Wayfair.com, le célèbre fournisseur de mobilier d’intérieur.
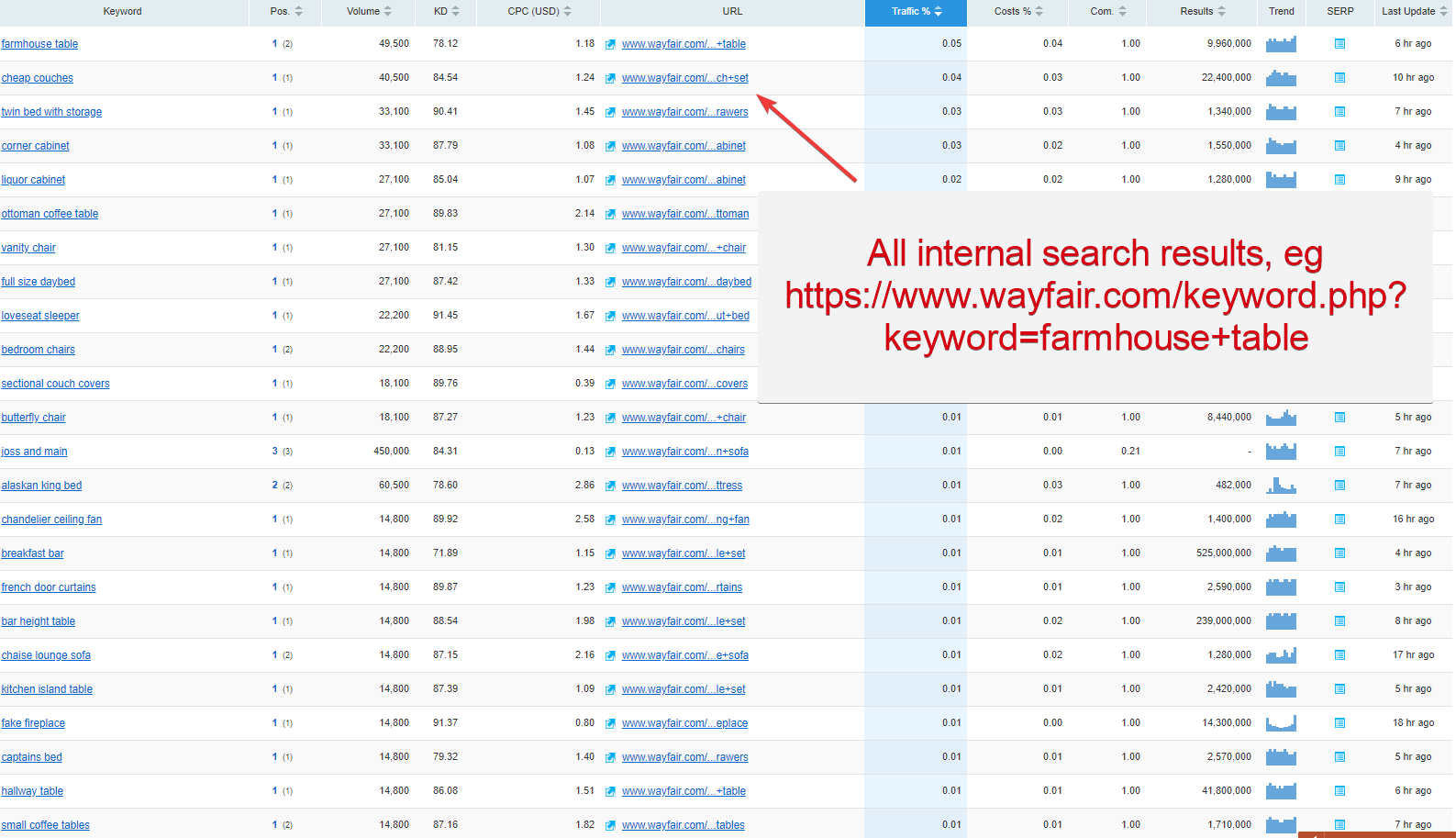
Classements organiques pour Wayfair.com qui montrent seulement les résultats basés sur leurs pages de résultats de recherche interne (données provenant de SEMRush)
Cela semble être plus courant dans certains secteurs que dans d’autres mais la pratique consistant à mettre les résultats de recherche interne à la disposition des moteurs de recherche est plutôt commune. Je pense personnellement que c’est souvent parce que beaucoup de sites ne se rendent pas compte de ce qu’ils font, ou lorsqu’ils le réalisent, ils ont peur d’arrêter ;car cela amène beaucoup de trafic.
Mais j’imagine que dans le cas de Wayfair.com, ils ont vu l’intérêt d’une telle pratique, donc tant que cela fonctionne (et qu’ils ne sont pas pénalisés), ils vont continuer et tant qu’ils en sont conscients et qu’ils le surveillent régulièrement, alors cela parait plutôt équitable.
Observons les quelques exemples ci-dessous qui montrent des sites qui ne désindexent pas leurs propres résultats de recherche ou leur contenu auto-générés.

FirstCry.com est une boutique en ligne basée en Inde pour les jeunes mamans. Ils disposent de plus de 180 000 pages indexées dans Google ; ce qui n’est pas surprenant puisqu’un grand nombre d’entre elles sont basées sur des recherches internes (à se demander si bébé n’est pas tombé sur l’ordinateur quand maman et papa ne regardaient pas?…)
Il en va de même pour les sites e-commere qui ne font pas suffisamment usage des balises essentielles noindex, PeoplePerHour.com, le fameux site anglais de freelance, rencontre également de gros problèmes. Leur fonction de recherche d’emploi freelance crée son propre contenu qui sert joyeusement à la consommation des moteurs de recherche. Il y a aussi des problèmes avec les freelances eux-même et la manière dont leur contenu est indexé.
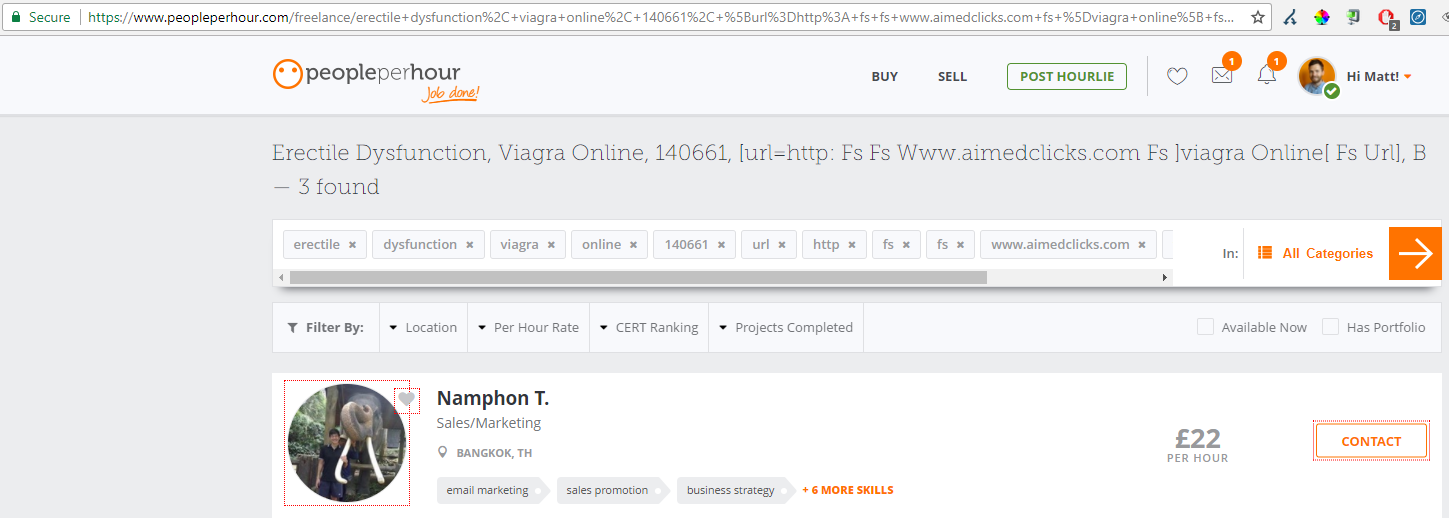
Freelance en dysfonction érectile, probablement pas le type de contenu qualitatif que vous aimeriez proposer aux utilisateurs, ou aux moteurs de recherche, ce que PeoplePerHour.com fait actuellement.
Avec la fonction “freelance search” ci-dessus qui génère une énorme quantité de contenus de faible qualité, ils ont beaucoup de ménage à faire pour nettoyer le contenu qui est déjà indexé dans Google.
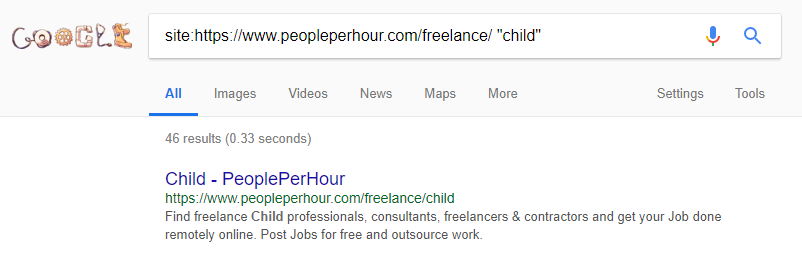
Il est difficile de déclencher ces recherches “naturellement” (heureusement pour PPH) mais l’exemple ci-dessus site:search montre qu’ils devraient vraiment contrôler le contenu auto-généré par le site et empêcher de grandes quantités d’être indexées.
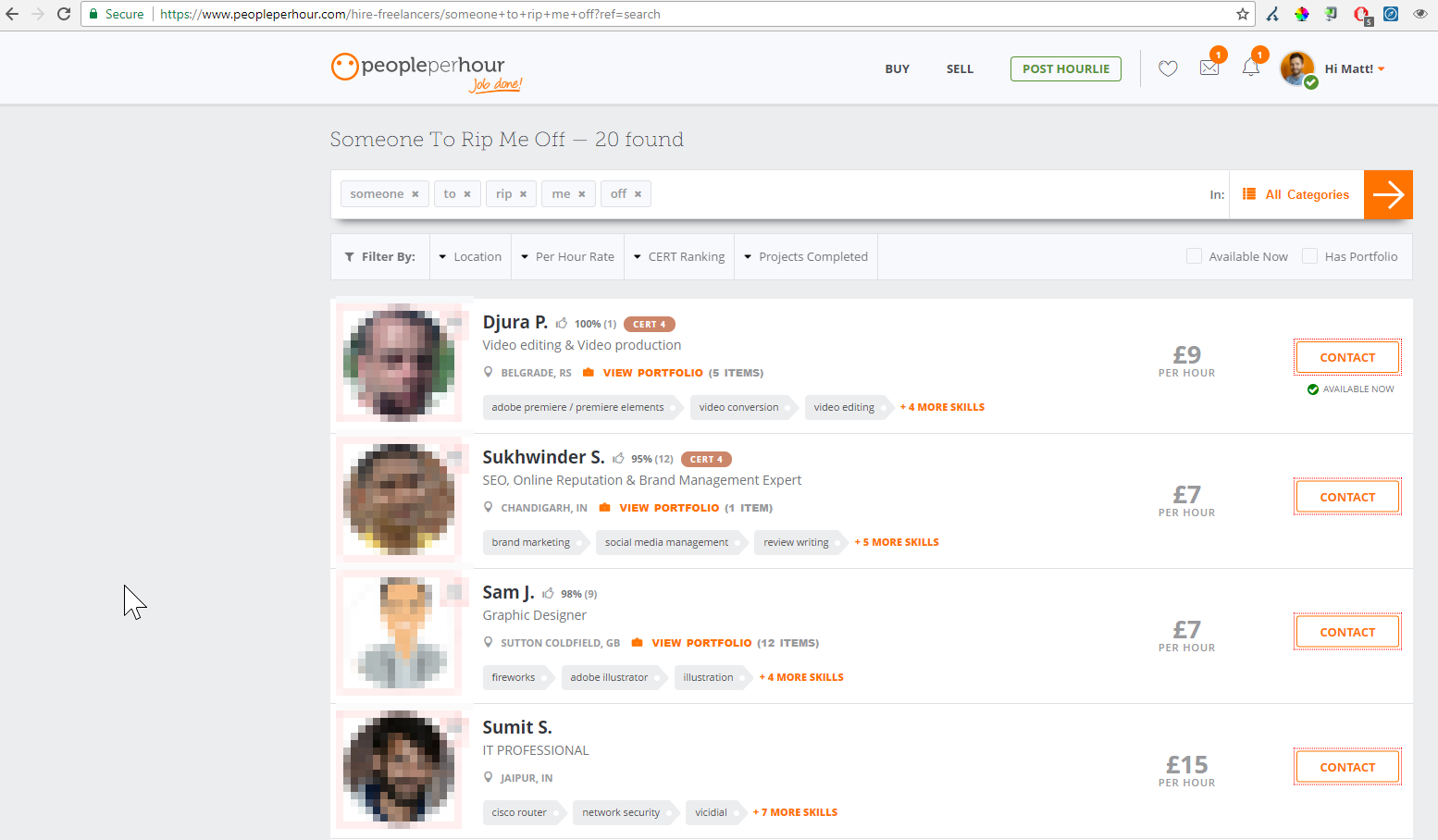
Vous êtes à la recherche de quelqu’un pour vous arnaquer ? PPH peut vous aider ! (désolé pour les utilisateurs montrés ci-dessus !). Cette fonction additionnelle de recherche dynamique (qui n’est pas indexée) crée beaucoup de contenu indexable qui ne sont pas nécessaires.
J’ai écris un peu plus précisément sur les problèmes SEO de PeoplePerHour. Le principal TLDR rencontrant les mêmes problèmes que ceux cités ci-dessus, ils lient également vers un grand nombre de résultats de recherche via leurs vastes sitemaps XML. Donc, à mes yeux, ils sont à 100 % responsables de l’indexation de ces contenus de pauvre qualité sur Google (j’ai essayé de les contacter à plusieurs reprises pour leur montrer ces erreurs mais ils n’ont jamais répondu, donc je considère cela comme équitable) ?

La balise canonique de la page ci-dessus pointe vers l’URL auto-générée, et qui n’est pas indexée non plus ; ce qui mène à toutes sortes de contenus indexés.
Les dangers avec l’indexation des résultats de recherche interne ou le contenu généré par les utilisateurs
Au-delà des points cités ci-dessus, il y a un certain nombre de raisons pour lesquelles il s’agit normalement d’une mauvaise pratique. Tout d’abord, il est très probable que les pages de résultats de recherche interne ne soient pas les pages les plus optimales que vous aimeriez proposer à un moteur de recherche.
Les pages de recherche ont probablement la recherche toujours visible, plus tous les produits qui s’approchent de la requête, mais il n’y a certainement pas grand chose d’autre sur cette page spécifique ; beaucoup de contenus répétés (header, footer) ou sinon du contenu du boilerplate.
Vous avez sûrement d’autres pages bien mieux que vous aimeriez montrer aux utilisateurs et à Google. Wayfair.com est encore un exemple typique d’un site avec ce problème particulier ; comme vous pouvez le voir ci-dessous avec leurs balises title / meta description.
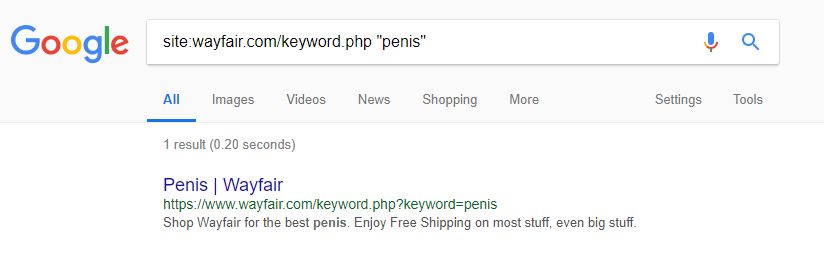
Il est vrai qu’il est difficile de déclencher cette page de résultats de recherche dans la requête renseignée ci-dessus, mais c’est un très bon exemple pour montrer que la recherche interne ne fonctionne pas toujours (surtout en combinaison avec les balises meta auto-générée !)
Si vous êtes suffisamment courageux pour cliquer sur les SERPs ci-dessus, vous obtiendrez la page suivante ; qui n’est pas le type de contenu que vous aimeriez que vos utilisateurs ou les moteurs de recherche découvrent chez un fournisseur de mobilier d’intérieur…
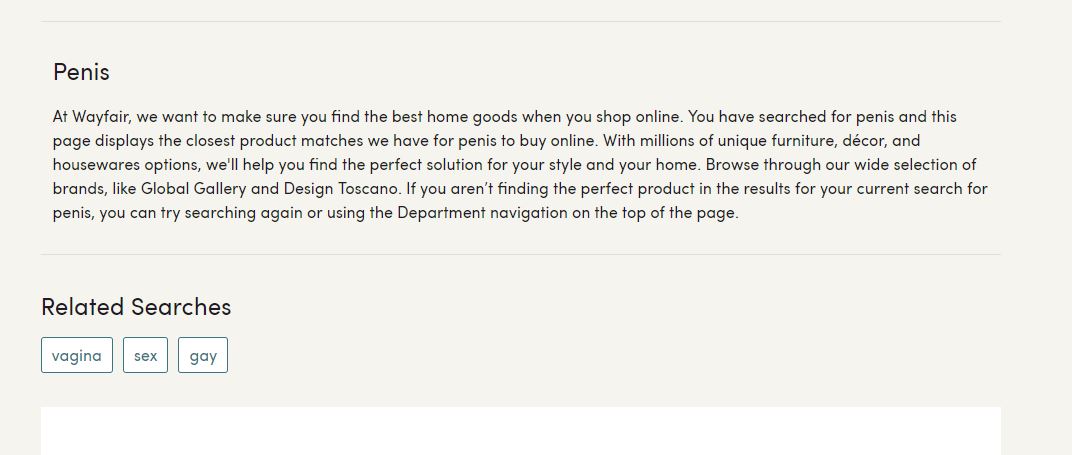
Vous pouvez constater l’utilisation de l’insertion de mots-clés dynamiques dans la balise title (H1) et dans la description. Ce type d’insertion dynamique est plutôt old school, mais semble générer un bon trafic organique pour Wayfair.com
L’autre risque dans l’autorisation du contenu de recherche indexable si vous avez un site e-commerce avec de nombreux produits listés c’est que les pages de résultats de recherche aient un énorme volume de résultats renvoyés (surtout lorsque l’on prend en considération les options de filtrage des produits qui créent des URLs supplémentaires) ; ou la page de recherche pourrait même renvoyer un nombre infini de résultats, créant des boucles quasiment interminables.
Pour tous ceux qui sont familiers avec les budgets de crawl, vous saurez que cela cause de gros problèmes SEO. Vous pouvez contrôler le Googlebot en n’indexant pas les pages des résultats de recherche pour les empêcher de gâcher leurs crawls et de passer à côté des ressources les plus utiles de votre site.Utiliser un crawler seo permet de trouver et de diagnostiquer ces problèmes de crawl en lançant simplement un crawl complet de ces zones de votre site.

Une partie du résumé de l’analyse du site fournie par le crawler Oncrawl, montre que le site a largement désindexé ses contenus à cause de ses préoccupations dues au manque de qualité. Mieux vaut prévenir que guérir !
Pirater les SERPs grâce à la recherche interne
Dernière de toutes, et certainement la plus grande raison d’éviter d’indexer les pages de recherche, c’est la possibilité que Google indexe et retourne ce que j’appelle des “mauvais SERPs”. Ce sont des résultats qui peuvent donner une mauvaise image de votre site à vos clients, comme vous avez pu le voir avec Wayfair.com précédemment.
Cette situation n’est pas commune mais peut arriver ; et c’est un risque lorsque vos pages de recherche interne créent des pages dynamiques indexables basées sur les recherches des utilisateurs. Par exemple, une recherche comme “Matt adore utiliser Oncrawl” va générer une nouvelle URL telle que “domain.com/?query=matt-loves-using-oncrawl” qui va potentiellement être sélectionnée et indexée.
C’est arrivé à Spotify récemment et j’ai été relativement surpris que cela soit largement ignoré parmi la communauté SEO. Google a proposé un featured snippet pour les recherches incluant “Spotify phone number”, certainement renseignées par des personnes cherchant le contact téléphonique de Spotify (qui n’a d’ailleurs jamais été configuré par la marque).
Wow, a brilliant bit of evil:
Spotify, like so many silicon valley companies, doesn’t believe in having a customer service #. So someone took their reflector search box, SEO’ed google with that URL, so « Spotify phone number » instead goes to a bunch of fraudsters. pic.twitter.com/7YcJV3Q3N4
— Nicholas Weaver (@ncweaver) March 17, 2018
Wouah, une belle catastrophe :
Spotify, comme bien d’autres entreprises de la Silicon Valley, ne croit pas au customer service#. Donc quelqu’un a pris leur boîte de recherche et l’a optimisée dans Google avec cette URL, pour que “Spotify phone number” renvoie vers une bande de fraudeurs. pic.twitter.com/7YcJV3Q3N4
— Nicholas Weaver (@ncweaver) March 17, 2018
Donc, comment Google peut renvoyer un featured snippet montrant le numéro de téléphone de Spotify si celui-ci n’existe même pas ? C’est simple, des spammers ont effectué cette recherche dans le site web de Spotify, et ont ensuite visé un certain nombre de liens vers cette page de recherche interne (c’est ce que j’image qu’il s’est produit).
Google a fini par détecter cela et a pensé qu’il s’agissait d’une bonne correspondance pour les utilisateurs des requêtes et a donc commencé à renvoyer vers cette URL spécifique dans un featured snippet. Le numéro de téléphone renvoyait probablement vers une ligne payante au lieu du standard de Spotify.
C’est plutôt rare que des recherches internes créent leurs propres pages de manière dynamique dans ce style, mais si elles le font, il devient vraiment difficile de contrôler ces types de pages ; cela peut créer un grand nombre de contenus non voulus, ce qui dilue la quantité globale du site et gâche du budget de crawl comme mentionné précédemment. Ou, alternativement, cela peut être un vrai cauchemar en termes de relations presse, comme ce qui s’est passé avec Spotify !
Améliorer votre stratégie de recherche interne
Pour ces sites qui comptent sur l’utilisation de nombreux résultats de recherche pour leurs utilisateurs ; peut-être pour les grands sites e-commerce où la fonction recherche est très demandée, une plateforme de partage de photo, ou encore une plateforme d’emploi où les offres d’emplois sont régulièrement mises à jour, heureusement, il y a des choses qui peuvent être faites pour améliorer l’expérience de recherche ; autant pour les utilisateurs que pour les crawlers.
Un exemple d’un site qui fait du bon travail avec sa fonction de recherche : Airbnb. Ils ont mis en place de nombreuses actions pour contrôler l’utilisation de la recherche sur leur site car cette fonction est une étape cruciale dans leur procédure de réservation.
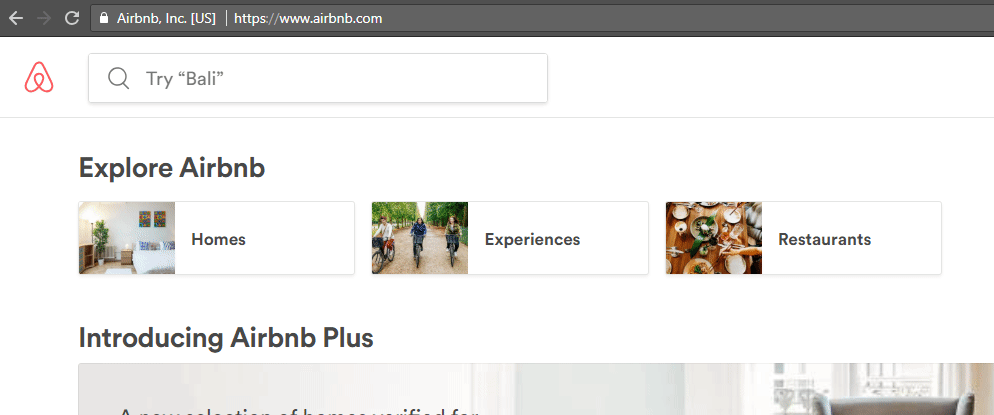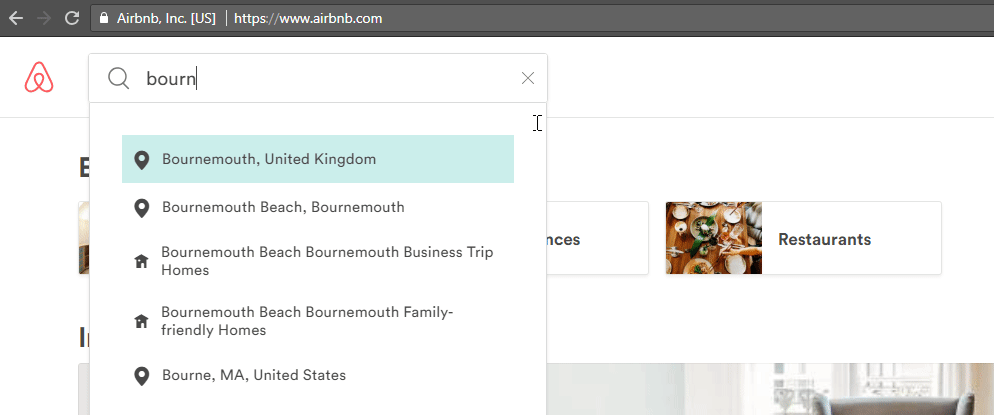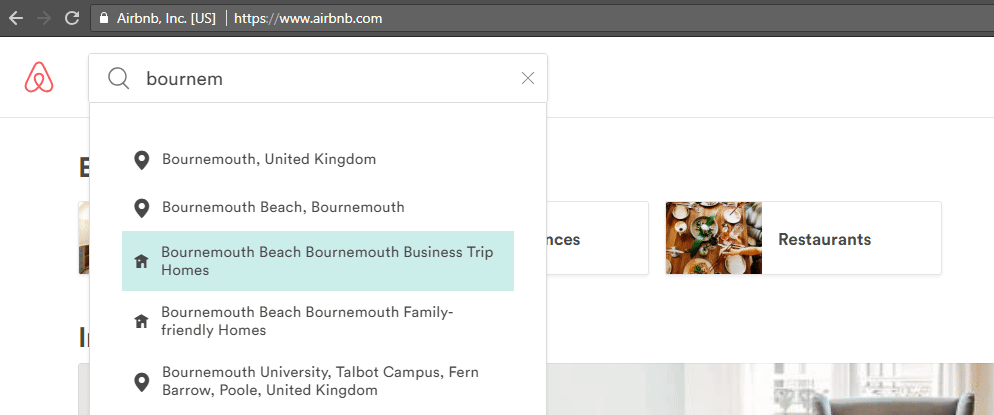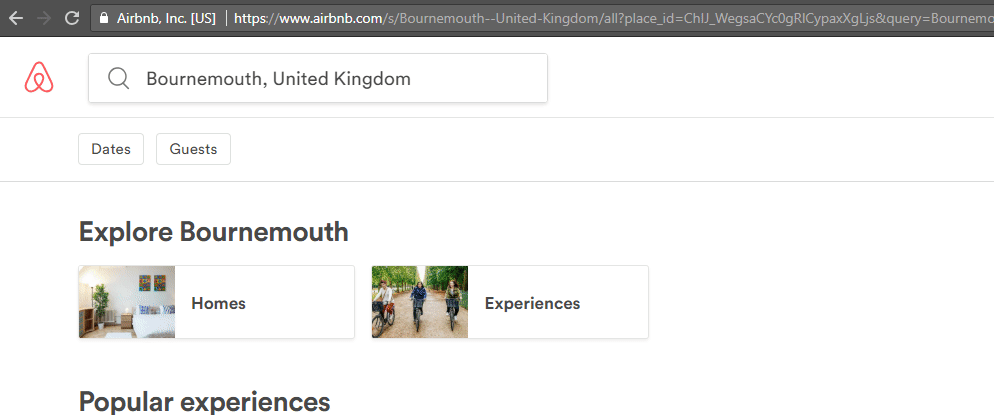
Il est très difficile de chercher quelque chose qui n’existe pas sur Airbnb, car la recherche est préalablement configurée pour que vous sélectionnez l’une des localisations proposées lorsque vous tapez ; comme vous pouvez le voir, lorsque je cherche “Bournemouth”. Ils accélèrent la procédure de recherche tout en vous guidant vers ce qu’ils pensent que vous cherchez. Ce type de “recherche contrôlée” améliore l’UI et permet une meilleure expérience utilisateur ; deux points importants pour une bonne stratégie SEO.
Si je devais chercher dans Google “Airbnb Bournemouth”, vous constaterai que les deux premiers résultats organiques pointent vers Airbnb.co.uk et Airbnb.com (Remarque : utiliser les ccTLDs est une bonne tactique pour des marques internationales afin de couvrir plus de SERPs) qui semblent renvoyer vers une page de résultats de recherche interne pour Bournemouth.
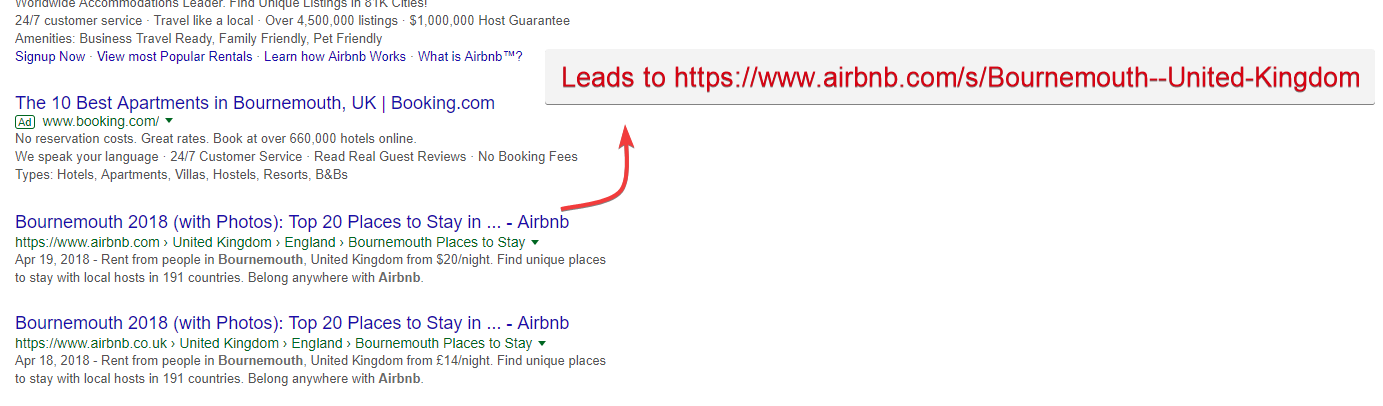
Recherche pour Airbnb Bournemouth : notez les “Top 20 Places to stay” et l’utilisation de l’année actuelle ; 2018 dans la balise title pour améliorer le CTR en augmentant sa pertinence
Cela pourrait apparaître comme un résultat de recherche interne typique mais c’est en fait bien mieux que votre contenu auto-généré, comme montré dans le cas de Wayfair.com précédemment.
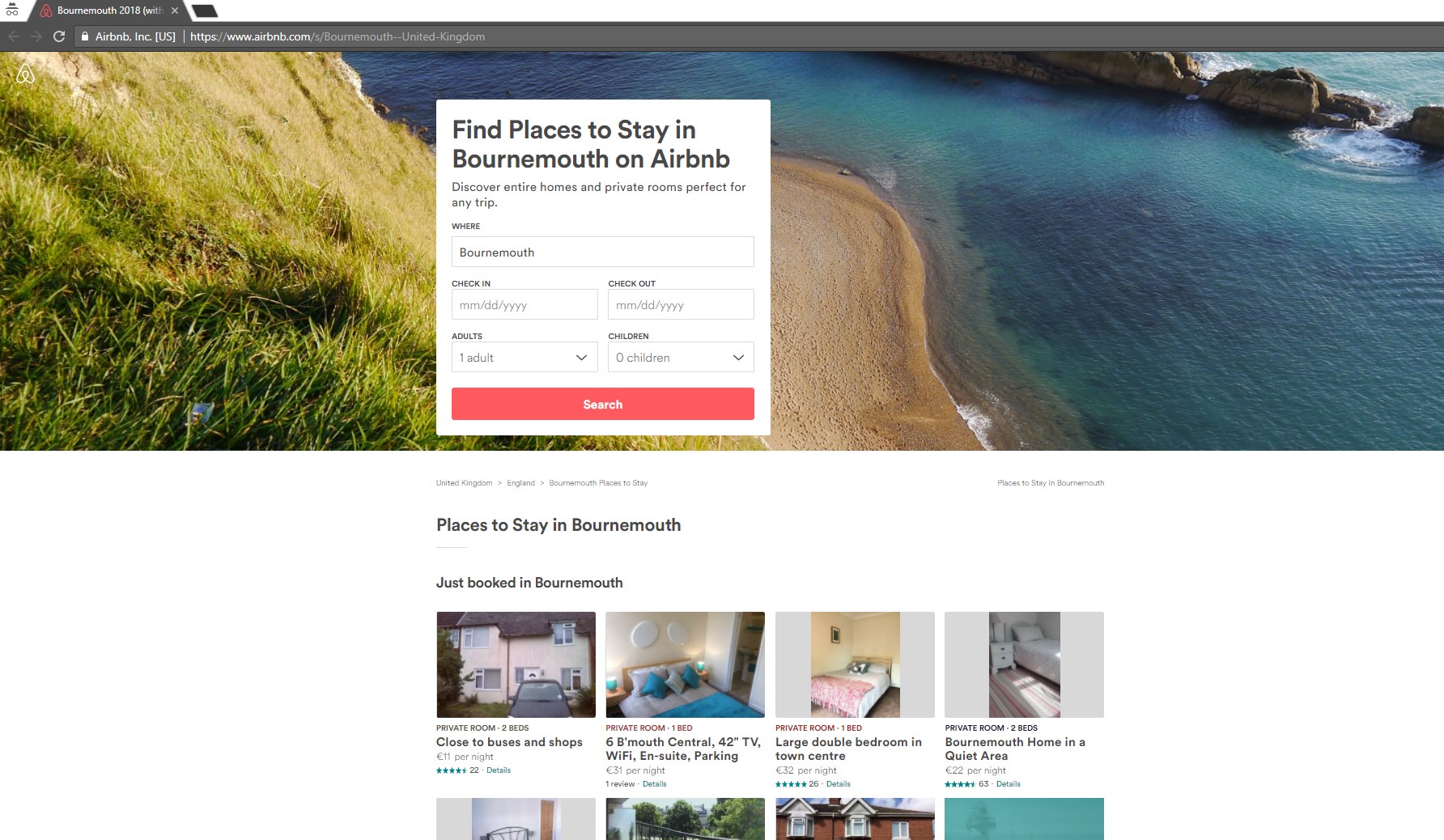
La landing page pour les requêtes précédentes ; bien optimisée pour cette requête particulière, et avec de nombreux listing pertinents pour Bournemouth (plus de 20 ; la balise title montrée précédemment était juste un piège à clics !)
Je n’ai pas eu la patience d’étudier la centaine d’ index de sitemaps XML que j’ai trouvé lorsque j’analysais les dossiers des robots.txt d’Airbnb mais je suis plutôt confiant sur le fait qu’ils renvoient tous vers des pages de recherche interne. Pointer vers elles depuis un sitemap XML est une méthode propre, fiable et rapide pour un site massif comme Airbnb afin qu’elles soient sélectionnées et indexées par Google et les autres.
Le fichier de robots.txt d’Airbnb, à l’image d’ une entreprise comme la leur…
Utiliser les résultats de recherche interne pour un site d’emploi
Un autre site qui fait du bon travail avec les résultats de recherche interne, c’est TotalJobs.com. Pas seulement parce qu’ils se classent #1 dans Google lorsque je recherche au hasard pour “SEO Jobs” mais aussi car je peux voir qu’ils utilisent très finement la fonction de recherche et les balises noindex.
Par exemple, les pages de résultats de recherche pour “SEO Jobs” ne sont pas indexées ; vous pouvez vous y attendre comme il s’agit d’un sujet clé, une recherche aléatoire avec des termes qui n’ont pas vraiment de sens, il vaut mieux ne pas les indexer et en effet, insérer une balise noindex. 20/20 pour l’équipe SEO Total Jobs !

Bon travail TotalJobs.com avec cette utilisation intelligente de la balise noindex en fonction d’un faible volume de recherche pour cette requête (espérons 0 !) que j’ai renseignée en tant que test
Proposer aux crawlers le bon contenu de recherche interne
Il existe d’autres actions à mettre en place pour aider les crawlers à trouver et indexer vos pages de recherche interne qui comptent pour votre site web. Par exemple :
- La pagination : ce qui signifie appliquer un bon plan de marquage (avant, après, etc) pour indiquer que des contenus s’étendent sur une ou plusieurs pages ou font partie d’une série. Le code de ce plan n’est pas visible pour l’utilisateur final mais aide les moteurs de recherche à comprendre comment le contenu est structuré et à en savoir plus sur le contexte du contenu.
- Les fils d’ariane : cela peut vraiment aider la navigation du site pour les utilisateurs mais aussi pour les crawlers afin qu’ils comprennent les sections prioritaires d’un site. Ils apparaissent derrière le header de cette manière :
Page d’accueil > Nom de catégorie > Nom de sous-catégorie > Produit. - La catégorisation : en séparant les sections clés du site en catégories. Cette forme de taxonomie aide les utilisateurs et les crawlers à naviguer dans le site. L’organisation de vos contenus en catégories est une partie vitale de l’architecture interne de votre site.
- La navigation multi-facettes : c’est un casse-tête à mettre en place mais au final (si c’est utilisé correctement) cela peut vraiment aider les crawlers et utilisateurs à naviguer à travers le contenu (généralement des produits) listé sur votre site en fonction d’attributs spécifiques.
Par exemple, pour les boutiques e-commerce sur mobile, vous pourriez inclure Android en tant qu’attribut produit, ainsi que le prix, la taille de l’écran, etc… Cela peut créer un nombre de variations d’URLs qui nécessitent toutes une certaine considération au sein de la structure globale de votre site. Gardez en tête le budget de crawl et le contenu dupliqué.
Vous souhaitez (idéalement) consolider les URLs avec des produits/catégories spécifiques, au lieu d’en créer avec différents attributs.
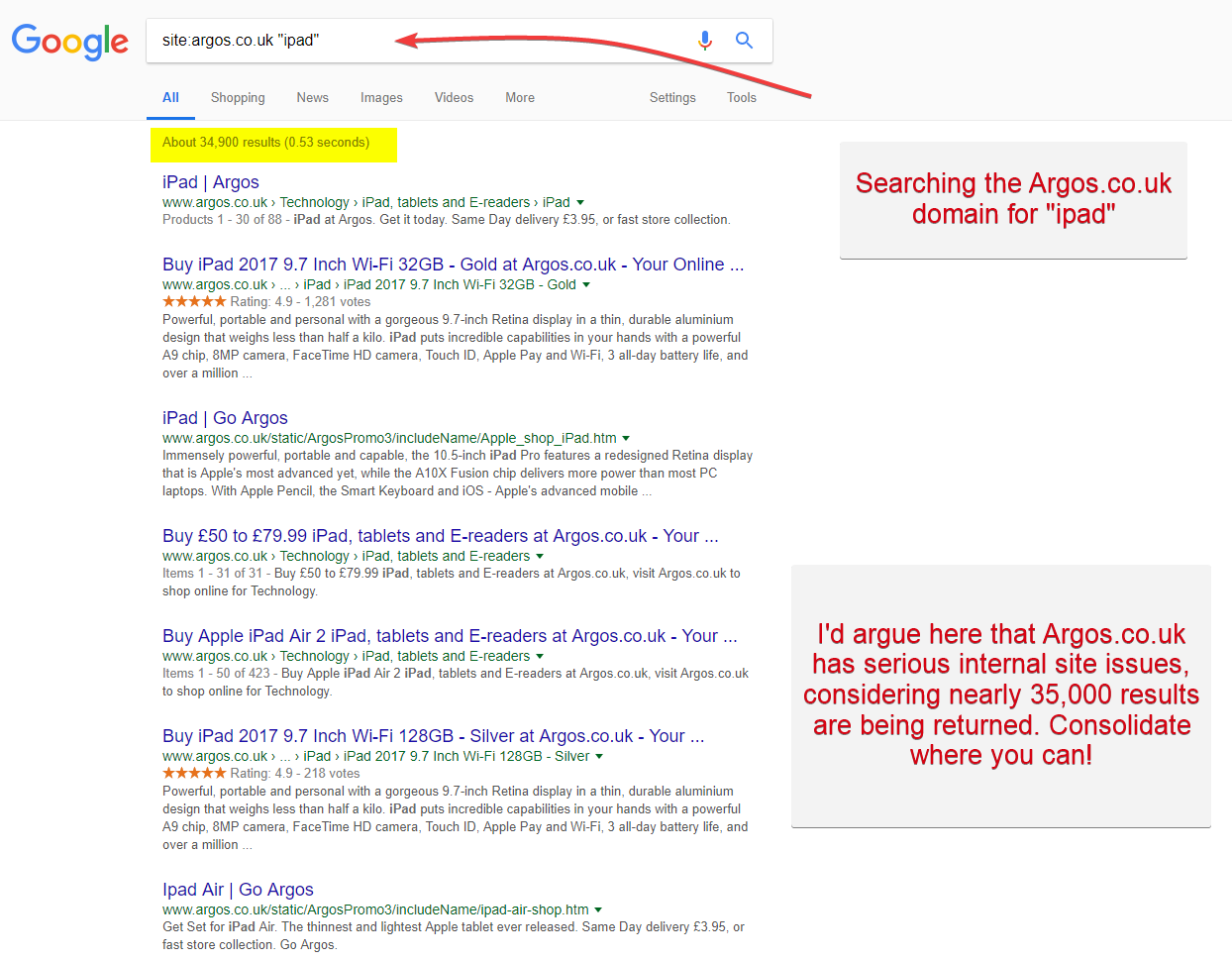
Argos.co.uk est un exemple de site qui a de gros problèmes de structure interne. Ils manquent de clarté dans la structure de leur site et doivent améliorer la catégorisation et la navigation multi-facettes afin de voir de véritables améliorations SEO.
Est-ce que Google aime utiliser les résultats de recherche interne en 2018 ?
Je pense que récemment, avec les grosses mises à jour de l’algorithme lancées par Google, le moteur de recherche s’emploie à utiliser le machine learning de manière plus avancée et sûre à grande échelle. Le machine learning peut facilement comprendre comment la fonction de recherche fonctionne sur la plupart des sites, ce qui génère une augmentation du nombre de sites qui sont renvoyés dans les résultats Google (ces résultats consistent en des pages de recherche interne).
En bref, Google est maintenant enclin à proposer des résultats de recherche interne dans ses résultats, mais avec le postulat que s’ils constatent un faible taux de clic pendant un certain temps, ou un fort taux de rebond, Google montrera beaucoup moins cette page spécifique. Il s’agit de ma propre théorie, basée sur ce que j’ai remarqué dans les SERPs au cours des derniers mois.
L’hypothèse ci-dessus semble logique. Si les résultats renvoyés par Google correspondent aux requêtes des utilisateurs et qu’ils satisfont les éléments d’intention de recherche, alors tout le monde est content.
À cause de la confusion au sein de la communauté SEO, j’ai l’impression que l’utilisation des résultats de recherche interne (et les récents classements positifs obtenus par les sites qui en font usage) méritent plus de recherche. Cet article ne couvre que la surface du sujet ; il y a encore bien d’autres découvertes à faire !
Encore plus de fun avec la recherche interne
Voyons si la communauté SEO peut aller plus loin. Quels résultats de recherche interne farfelus ou contenus générés par les utilisateur avez-vous trouvés ? Faites-le nous savoir avec une capture d’écran ou un commentaire ci-dessous !
